面向个性化产品服务方案的推荐方法与应用
2018-09-08耿秀丽
杨 珍 耿秀丽
上海理工大学管理学院,上海,200093
0 引言
目前,企业市场竞争愈发激烈,制造型企业面临资源利用率、产品同质化等挑战,开始注重产品的后市场需求,通过与产品服务结合来触发更多的用户需求。制造和服务的结合改变了传统的企业运营模式,使得服务不再以产品的附加要素存在,产品服务系统(product service system,PSS)应运而生。PSS系统主要为企业提供一种“产品+服务”的整体解决方案。方案规划作为PSS系统中的重要环节,与方案设计及选择都有密切联系,因此,在提供服务方案前,需要确定用户需求,定制出个性化的产品服务方案,并成功地将优选的个性化服务方案推荐给合适的用户,从而提高企业的核心竞争力。如何高效地给用户推荐满意的产品服务方案,与推荐算法性能优化息息相关。
个性化推荐算法是方案推荐过程中必不可少的技术,主要分为基于协同过滤、基于内容、基于知识、基于关联规则的算法。其中,最为成功的算法为协同过滤(collaborative filtering,CF)算法,通过计算用户行为或偏好的相似性,找到目标用户的最近邻及其对应项目进行推荐,但是传统CF算法对不完整数据以及对零历史记录的用户难以给出准确推荐。面对此挑战,人们提出新型CF算法,即隐语义模型(latent factorm odel,LFM)。通过隐类关联用户和项目,采用矩阵分解技术建立用户-隐类、隐类-项目间的关系矩阵,利用矩阵乘积获取用户喜爱的项目并进行推荐。传统LFM研究侧重于减少数据稀疏和解决冷启动问题,如文献[1]针对LFM数据稀疏的问题,提出基于学习自动机的矩阵优化算法代替奇异值矩阵分解方法;文献[2]为减少数据稀疏性,采用基于隐类的似然估计法来优化LFM,在用户不了解相关知识的前提下,根据用户个性化需求定量化预测;文献[3]针对LFM的冷启动和稀疏性问题,提出融入用户属性的推荐算法,通过分类模型得到其他用户属性重要度,结合用户评分计算属性相似度并推荐;文献[4]针对冷启动问题,将历史浏览记录转化为用户评分,融入基于LFM的相似评分并推荐。上述文献主要通过改进LFM来解决稀疏性和冷启动问题,以提高产品服务方案推荐的准确率。实际上,推荐技术不仅重视结果的精确性,也注重推荐过程的效率性,而文献[5⁃6]就是为提高推荐效率,引入服务方案因子约束的LFM模型,采用一阶线性方法拟合服务方案推荐结果;文献[7]在此基础上,采用Hessian工具中的二阶求解器获取产品的高斯逼近矩阵,既提高了推荐精度,又提高了推荐效率;文献[8]利用主题将潜在因子应用于查找项目关联的文本数据,建立潜在因素模型,提高用户查找项目的效率。
本文基于文献[4]的推荐方法,引入偏置量,形成加权LFM。偏置量是由用户等主观因素引起的用户-隐类间的兴趣偏差值、隐类-产品服务方案间的评分偏差值。热门产品服务方案推荐过程往往忽略用户主观评分的偏差量,导致推荐结果未必符合最近邻目标用户真正的需求。本文的加权LFM算法基于矩阵分解技术,根据用户兴趣特征找出新用户的最近邻,无需新用户对产品服务方案的评分,就可以推荐最近邻的相应产品服务方案,从而解决用户冷启动问题。考虑新用户和最近邻用户兴趣特征的差异,求出兴趣特征的相似度,作为整个最近邻用户兴趣值的权重;通过矩阵P和Q的积,得到用户偏好服务方案并推荐,改变了以往逐渐查找最近邻产品服务方案的方式,从而提高推荐效率。但是采用LFM算法推荐前,数据稀疏可能会影响推荐结果。当用户兴趣特征较多时,采用余弦相似度计算出的用户相似度就会偏高,难以体现用户间的差异。而云模型可以反映用户概念的模糊性、不确定性和随机性,较为完整地刻画用户特征。利用生成的用户云,通过计算云滴距离测度可以间接计算用户的相似性,从而弥补余弦相似度精度的不足。但是云滴数据的生成过程也具有偶然性,单独应用云距离测度时准确性也受到约束。因此,本文提出采用正向云发生器求解出云滴,并将云滴距离和用户-特征间的余弦相似度的加权综合值作为新相似度,根据最近邻用户预测评分并填充空缺值,形成完整的数据集,从而提高数据的推荐精度。实际上,云相似度在个性化推荐技术中也有广泛的应用,如文献[9⁃11]基于云模型计算用户偏好的相似性并匹配目标用户进行推荐;文献[12]采用基于云的特征相似度计算方法,压缩数据,降低维度,节约存储空间;文献[13]采用云相似度的计算方法,结合反向传播网络进行预测。此外,云相似度也会在数据聚集过程得到具体应用,如文献[14]采用基于云相似度和云的距离模型,处理并聚类语言变量,求解出群体偏好值,给出合适决策。因此,本文采用结合正向云的加权LFM推荐算法,既能减少数据稀疏,又能通过用户兴趣特征相似度解决冷启动问题,并且能够通过LFM的矩阵分解技术,获取合适的推荐产品服务方案,提高推荐效率。
由于传统LFM的研究未考虑数据库在动态更新的过程中,推荐内容可能会随之改变的情况,因此,本文提出采用动态增量更新机制,在不影响先前数据处理工作的前提下,采用差值平均法对预测公式更新产品服务方案推荐结果,降低时间复杂度。本文针对传统LFM算法数据稀疏、冷启动、未考虑实时更新等问题,采用云相似度预测填充空缺数据,弥补稀疏性;采用基于用户兴趣特征的相似度寻找最近邻用户,并获取最近邻用户兴趣相似度作为用户兴趣特征的权重,结合用户评分差异偏置量,约束主观评分差异性;通过LFM方法获取用户产品服务方案评分并进行推荐;采用差值平均法更新推荐结果,解决因数据库动态更新导致推荐结果变化的问题,力求达到产品服务方案实时推荐的效果。
1 研究框架
为提高个性化产品服务方案的推荐效率,针对推荐技术中的稀疏性、冷启动以及未考虑实时更新等问题,本文考虑用户、方案与隐类间的关系,提出了加权LFM。首先,基于用户ui(i=1,2,…,s),方案aj(j=1,2,…,t)及隐类ck(k=1,2,…,n)的数据信息,采用正向云发生器,输入用户与隐类、方案与隐类的定性信息,输出用户-隐类的兴趣度矩阵P、方案-隐类的比重矩阵Q。将用户-方案评分划分成P和Q两朵云,采用云滴距离和余弦相似度的加权结果进行预测评分,填充矩阵P和Q的空缺数据。然后,考虑评分的偏置量,通过融入偏置量的加权LFM模型建立用户-服务方案间的关系,输入P、Q矩阵,输出新用户对产品服务方案的预测评分并排名,选择前N项方案予以推荐。其中,新用户对服务方案的预测评分主要通过如下方式获得:基于新用户兴趣特征的相似度找出最近邻用户,将该相似度作为每个最近邻的评分权重,采用加权LFM方法获取新用户对方案的评分。为了深入了解用户需求,本文在LFM中添加一个成分:方案特征fg(g=1,2,…,e),并与方案构成产品服务方案-特征评分矩阵O,可以具体到某一服务方案特征的推荐优先性,精准地了解用户需求。最后,提出差值更新法对新用户评分数据进行实时更新,从而更新产品服务方案推荐。本文框架思路见图1。

图1 本文的框架Fig.1 Fram e d iagram of this paper
2 基于云模型的数据处理
2.1 云模型相关概念
云模型是张光卫等[15]提出的处理定性描述和定量概念间不确定性的转换模型,通过结合自然语言中的模糊随机性,实现定性语言与定量数值间的转换,为研究数据挖掘的不确定信息处理提供了新方法。为解决个性化推荐的稀疏性问题,本文考虑到产品服务方案评分信息的主观性和模糊性,提出采用云模型实现定性定量数据的转换,通过加权相似度对稀疏数据预测填充。云模型相关概念定义如下。
定义1[1]云和云滴 设U是一个用数值表示的定量论域,C是U上的定性概念。若定量值x∈U是定性概念C上的一次随机实现,x对C的确定度μ(x)∈[0,1]是有稳定倾向的随机数:μ:U →[0,1],∀x∈U:x→ μ(x),则x在论域U上的分布称为云(cloud),记为云C(x);每个x称为一个云滴(drop)。
定义2 正向云是将独立参数表示为云的数字特征,描述事务的不确定性。采用参数期望Ex、熵 En、超熵 He三个特征描述云,即 C(Ex,En,He),当随机变量x满足x~N(Ex,E2n)时,其中,En~N(En,H2e),则对定性概念C的确定度满足μ(x)=

论域上若干个云滴组成云,云滴对隶属度函数的映射是一对多转换的关系,不同于模糊聚类一对一的转换,云定性概念的整体特征由云滴表现出来。由参数(Ex,En,He)表示云的数字特征模型,称为云模型。云模型的核心处理过程主要分两种:正向云发生器和逆向云发生器,正向云发生器主要将定性描述的整体向量C(Ex,En,He)转换为描述个体定量数值的云滴,逆向云算法主要将定量数据转换为云滴(x,μ(x))。针对项目评分稀疏性,以及用户评分主观性问题,提出采用正向云算法,将定性评分转换为云滴,并利用云滴距离以及特征向量的加权相似度来预测未知评分,提高推荐精度。以云(0.5,0.05,0.01)的3个特征值及N=1 000为输入值,通过正向云发生器输出云图,见图2。

图2 正向发生器输出的云图Fig.2 C loud drop model
其中,期望Ex表示云滴在论域空间分布的期望值,即最能代表定性概念的点;熵En表示定性概念的不确定量,反映云的离散程度;超熵He是熵的不确定概念,可以描述云的厚度。
2.2 基于改进的正向云模型对稀疏数据填充
本文利用云模型的随机模糊性,将用户对产品服务方案主观评分转化为云滴,利用云滴距离和余弦相似的综合相似度对用户兴趣度矩阵P、方案评分矩阵Q预测填补空缺数据。假设云向量C(Ex,En,He)表现为用户特征兴趣值,即 Ex是用户对隐类的评分均值,En、He对应评分值的熵、超熵。通过引入云的综合相似度预测评分,填充用户评分或隐类中方案比重的缺失数据。用户选择方案时,会选择高热搜度、推荐次数多的方案而忘记本身个性偏好,导致所获取的方案并没有实际用处。很多推荐算法对此引入罚函数来减弱外界影响因素,本文考虑用户兴趣多样性的影响,基于随机性的云滴距离来减轻用户偏好的影响,采用正向云发生器将云的特征值((Ex,En,He)转换为离散的云滴Drop(xc,μ(xc)),具体特征指标的计算方式如下:

式(1)~式(3)将定性描述转换为云的特征指标,本文采用正向云算法将特征指标转换为云滴,输入为表示定性概念的三个特征值(Ex,En,He),输出为云滴Drop(x1,μ(x1)),Drop(x2,μ(x2)),…,Drop(xN,μ(xN)),xc为处理后的评分值。具体过程如下:①生成以En为期望值、He为方差的一个正向随机数E′n=N(En,He);②生成以Ex为期望值、E′n为方差的一个正向随机数x=N(Ex,E′n);③计算μ(xc)=将带有确定度μ(xc)的xc称为数域中的一个云滴;重复步骤①~③,直到产生要求的N个云滴(xc,μ(xc)),c=1,2,…,N。
其中,N(Ex,)为生成以Ex为期望值、为方差的正向随机数函数。给定云的3个数字特征值(Ex,En,He)。上述算法可以生成任意云滴组成的正向云,比如用户u和用户v的特征向量Cu=(Exs,Ens,Hes),Cv=(Ext,Ent,Het)。用户间的相似度可以用余弦相似度、皮尔森相似度、云距离测度等求解,考虑到余弦相似度局限于向量个体间的关系,忽略个体差异值的影响。皮尔森相似度实际上是数据中心化的余弦相似度,并不能针对离散的、差异大的数据点求解合适的相似度。云距离测度可以求解离散数据的相似度,但是忽略了核心用户的相似特征关系。因此,本文针对用户兴趣差异性问题,结合基于实际用户特征数据的余弦相似度和基于生成用户云滴数据的云滴距离测度,来计算最终的用户相似度,具体计算方式如下:


其中,simc(u,v)是用户u和v评分向量的余弦相似度,simd(u,v)是用户u和v评分映射的云滴距离测度,sim(u,v)是由设定的权值α对simc(u,v)和simd(u,v)的加权综合相似度。ru,c为用户u对c的评分,rv,c为用户v对c的评分,-ru是用户u对所有共同评分产品服务方案的评分均值,-rv是用户v对所有共同评分隐类的评分均值,Spred表示预测评分。本文通过正向云发生器获取云滴距离并与云的特征余弦相似度加权求和,来预测填充稀缺数据,提高个性化推荐的准确率。同理,产品服务方案对特征因子f的评估值为rac,其计算方式类似于用户-隐类评分过程。例如,两朵云的特征向量 Cu=(0.5,0.05,0.01),Cv=(0.6,0.055,0.033),利用正向云发生器拟合出两者的云图,见图3。

图3 云模型Fig.3 Cloud m odel
由图3可知,两朵云间距虽小,但Cu跨度小,离散程度低;而Cv跨度大,离散程度高。针对云滴距离的不确定性,本文采用云滴距离测度来预测并填充缺失数据有失准确度。引入特征向量间相似度以增加约束量并与距离相似度加权集合,以增加预测的准确度。如果某个用户数据有所缺失,可以利用该用户其他完整数据找出高相似性最近邻,进行预测填充,得到完整的用户数据。
3 基于改进LFM的个性化实时推荐
基于云模型处理后的用户数据,本文采用加权偏置量的加权LFM进行预测,即通过新用户的兴趣值来预测产品服务方案评分,并采用加权法优化预测评分结果。与其他推荐模型进行比较,以证明本文算法推荐方案的精度。
3.1 基于偏置量的LFM处理数据过程
LFM是奇异值分解矩阵的改进算法,算法基于用户项目间的隐含特征建立矩阵R。矩阵R的元素ruj表示用户u对产品服务方案j的兴趣度,本文通过计算并排序兴趣度,给予产品服务方案推荐。LFM算法从数据集中提取出若干个主题,用于连接用户和方案,R表示成矩阵P与矩阵Q的乘积。P是用户-类矩阵,其元素pu,c表示用户u对类c的兴趣度;Q是方案-类矩阵,其元素qa,c表示方案a在类c中的权重,比重越高,越可能作为该类的代表。因此,需获取P和Q中的元素值,即可得到u对产品服务方案a的预测评分,采用Top⁃N排序并推荐。pu是由pu,c组成的用户-类向量集,即;qa是由qa,c组成的产品服务方案-类向量集,即预测评分=pu·。
LFM是基于改进奇异值矩阵分解模型提出的,由于奇异值分解模型在处理稀疏数据时,子模型分解过程会增加运算成本,且不准确填充可能会导致数据推荐结果有误差,故人们考虑采用基于梯度下降的LFM,构建误差最小化的损失函数来弥补数据稀疏缺陷。事实上,实际应用过程中,产品或服务方案的评价意见并非是单一选项值,用户兴趣及选择也会有所偏差。例如,品牌类型以及热度等都会使用户打出差异明显的分值。就不同用户而言,同类型产品评分差距明显也会导致预测值偏差过大,如热度高、影响力大的产品容易受到用户青睐。因此,引入用户评分偏差量bu及项目打分偏差量ba来改善差异性[7],即

其中,μ是数据库中所有记录评分的平均值;N表示所有用户对项目的评分集数量[16];bu为用户评分偏差,即用户评分过程中和物品无关的因素。ba是指方案特征差异值,即产品服务方案评分值与用户特征无关的因素;bua为考虑偏置量bu、ba后的评分结果;R(a)是产品服务方案评分总数;R(u)是用户评分总数;rca为方案a在类中权重比值;ruc为用户u对类c的评分值。
考虑用户-项目间的偏差值,将μ、bu、ba融入预测分值r^ua中,即

如果用户有更精细的产品服务方案需求,就会精确到产品服务方案特征的分析和推荐。本文引入产品服务方案a与特征f组成的类O,Of为方案特征向量集,为最终的方案推荐对应的特征值,预测函数预测产品服务方案特征评分

3.2 基于改进LFM的实时推荐及更新过程
考虑到用户和产品服务方案相关数据随时间不断更新,且新用户没有产生相关历史行为记录,难以推荐其所需产品服务方案,若要对新用户实时推荐产品服务方案,需要基于之前数据集进行动态更新。为提高推荐效率,且考虑到新用户的冷启动问题,基于用户特征相似度推荐产品服务方案来解决该问题。考虑用户特征多元性,引入用户对类的兴趣相似度wuc:

其中,puc、pvc分别为用户u、v对类c的兴趣度评分;u分别为用户u、v对类的评分均值。
将用户特征相似度wuc作为预测评分的权重,再次预测方案评分,通过差值平均法更新预测计算公式,从而降低时间复杂度。预测公式由式(10)变为

当数据集更新时,即数据库增加新用户行为记录,此时如果对新评分数据能够增量更新,则在不影响前期数据工作下,基于Slope算法提出差值增量更新法,在预测评分中引入差值平均值,将新评分值平均到所有预测分值中,计算方式为其中是新用户对产品服务方案的评分是已有用户的平均评分,N(u)是新用户前的用户总数,wuc是更新数据前的用户特征相似度。对评分差值的权重进行约束。
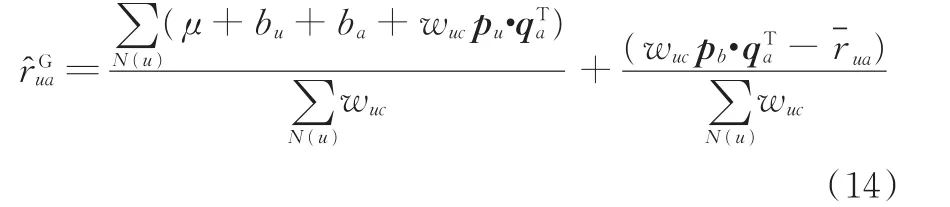
为突出本文算法的优势,通过对比不同算法的推荐效果,采用协同过滤算法常用的度量指标即平均绝对误差(mean absolute error,MAE)来度量策略预测的精度。将其用于比较本文推荐算法、基于云模型的推荐算法以及基于梯度的LFM推荐精确度,MAE值越小,表明预测结果计算误差越小,推荐精度越高。M AE值计算公式为

其中,N为评分总数,rua为实际评分,r^ua为预测评分。本文选取误差最小的预测评分,将用户pu及对应产品服务方案qi予以推荐。
4 案例分析
4.1 个性化产品服务方案推荐过程
某企业针对机床再制造的销售问题,即如何提高产品服务方案的销售效率,提出采用个性化服务方案给予推荐。通过整理以往顾客购买产品记录,本文选取10种具有代表性的产品服务方案a1,a2,…,a10,对其进行评估。方案评估指标分为主传动变速系统(c1),刀架更换系统(c2),安全防护装置(c3),进给系统(c4),废旧机床利用率(c5),机床防护系统(c6),节能环保方案(c7)。通过问卷调查,选取其中10位用户的评分数据作为本文的实验数据,虽然有随机性,但是将其作为本文的例证,具有普适性。将新用户对评估指标的打分高低表示为用户对机床的兴趣程度,用1~6来表示兴趣度的程度,即非常不满意、不满意、一般、好、满意、非常满意,本文的兴趣值见表1。

表1 用户兴趣度Tab.1 User in terest
若要将产品服务方案推荐给适合的用户,就需建立用户与方案间的联系,而已有产品服务方案推荐,一般采用基于产品服务方案特征或者用户特征的推荐算法予以推荐。本文采用LFM,将产品指标作为隐类,建立用户与服务方案间的关系,即建立用户-类表和类-方案比重表。由于用户对方案的偏好不同,表现为对方案指标的喜爱程度,所以根据方案推荐的历史数据,得出10种方案指标评估比重矩阵,见表2。

表2 机床产品服务方案比重Tab.2 Program p roportion ofm achine p roduct service
为了更精准地给用户推荐方案,如具体到方案某一性能特征,可以参照表3和表4。机床服务方案特征包括:床身(f1),主轴箱(f2),自动回转刀

表3 产品服务方案特征Tab.3 Program features of p roduct service
架(f3),压力控制阀(f4),环保节能(f5),进给传动(f6),安全性能(f7),动力元件(f8)。根据专家的语义评估,将各个产品服务方案属性值定量化转换,分别用1~4表示特征较差、中、较好、好四个等级,具体指标以及等级见表3,每个方案对应方案特征指标值见表4。

表4 产品服务方案特征数据Tab.4 Product service solution feature data values
随着用户购买量的增加,评分数据量也在增加,此时就会面临有些用户不愿对已购买产品打分等情况,产生稀疏数据。面对此挑战,已有学者通过梯度算法改进LFM,使得预测评分偏差最低。考虑梯度算法未填充数据,因此直接通过近似下降法搜索相似最近邻进行预测填充来避开稀疏数据的影响,仍会有误差存在。本文提出采用云相似度预测空缺数据的评分以弥补数据稀疏性,形成完整数据。如以表2填充数据为例,找出某类稀疏数据的最近邻,采用加权云相似度进行预测。本文先计算方案-兴趣特征类的评分的相似度,通过删掉缺失数据对应类的同样数据,再计算相似度,如类c1和类c2间的相似性是在去除产品服务方案a3的基础上根据式(6)求解,再通过式(7)求解预测分值,以此类推,根据式(4)求解余弦相似度,具体见表5、表6。由上述求解的余弦相似度可知,云相似度都很高,难以选取最优值,故本文采取云滴间距离进行约束,以c1、c4、c7的云图为例,见图4、图5。

表5 方案-兴趣特征向量Tab.5 Schem e-in terest featu re vector

表6 兴趣特征类的余弦相似度Tab.6 Cosine sim ilarity of interest feature class

图4 c1和c7的云图关系Fig.4 C loud relations of c1 and c7
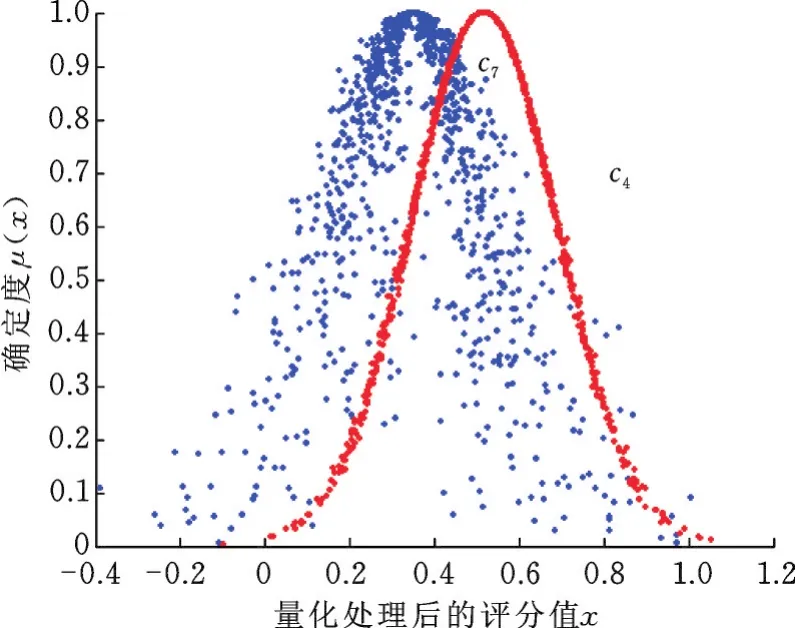
图5 c4和c7的云图关系Fig.5 Cloud relations of c4 and c7
由图4和图5可知,即使c1、c4、c7间余弦相似度很高,但在云图中明显看出,c1和c7的距离分散太多,云厚度小,离散性高,而c4云图紧密性好,这也验证了余弦相似性的不精确性,因此,引入式(5)计算云滴间距离相似度,结果见表7,并与表6余弦相似度加权求和,找出最优解。
将表6和表7中对应相似度加权求和,设置不同的α值,记录下α分别为0.3、0.5、0.7时根据式(6)求解加权相似度的结果。由图4和图5可知,相对于余弦高相似度,云滴数据的生成过程也具有偶然性,单独应用云距离测度准确性也受到约束,但当用户兴趣特征较多时,计算出的余弦相似度就会偏高,难以体现用户间的差异。因此,本文结合基于实际用户特征数据的余弦相似度和基于生成用户云滴数据的云滴距离测度,来计算最终的用户相似度。本方法避免了单一采用余弦相似或云距离测度的缺陷。所以本文根据α值的变化趋势,选取α=0.3时的加权相似值,并选取高相似的特征类最近邻,采用式(6)计算方式给予预测填充数据。表2弥补后的数据见表8,其中,加粗的数字是预测填充后得到的数据。同理,其他稀疏矩阵的稀疏数据的弥补过程亦如此。
考虑数据评分因人而异,尤其对于机床的资深研究者,会对机床性能的评分比较苛刻,导致评分数据发生偏差,引入基于偏差量的LFM预测评分,具体计算公式为r^ua=pu·qTa。将表1中用户对类ck的评分作为p,表8中填充后的机床方案比重值作为q,得出乘积即用户对方案的评分。以表1中的u1对c1的评分向量p1=(2,4,1,2,5,6,3)与c1对a的比值向量q1=(0.835,0.452,0.513,0.391,0.412,0.093,0.121)T为例,将 p1和 q1相乘得到用户对方案a1的评分为7.753,依此类推,Rua=puc·qca,其中,puc为表1形成的用户-类矩阵,qca为表8形成的类-方案矩阵,Rua为用户-方案矩阵。计算结果见表9。

表8 机床产品服务方案填充后的完整值Tab.8 Com p lete value ofm achine tool product service p rogram after filling

表9 用户对产品服务方案的评分Tab.9 User ratings of product service solutions
由表9可知,以用户u1为例,方案评分由高到低为 a9、a10、a8、a7、a6、a2、a5、a4、a3、a1,方案 a9是用户u1的最佳首选服务方案,对照表3、表4,可以得出方案9的机床具有以下特征:水平床身,直流数字化的主轴箱,回转刀架,减压阀,切削回收盘,闭环,敞开式,齿轮泵。
当该企业出现购买机床的新用户时,由于用户对机床性能认知不够,但根据问卷调查得到其对机床性能ck兴趣度,预测其最近邻以及相应的推荐产品服务方案,新用户vx(x=1,2,3)的兴趣度分值见表10,根据余弦相似度求出用户相似最近邻见表11。

表10 新用户兴趣度值Tab.10 Interest value of new user

表11 新用户与旧用户兴趣相似度Tab.11 Sim ilar interestsbetween new usersand old users
由表 11 可知,新用户 v1和 u1,v2和 u5,v3和 u10有高相似的兴趣度,对于完全未了解或零购买记录的用户,采用基于用户特征改进的推荐算法,如式(12)的计算方式,得到兴趣度权重见表12。
由表10和表1可得出用户偏置量bv1=-0.428 56,bv2=0.428 586,bv3=-0.142 84,根据式(10)和式(13)计算找出最近邻用户并推荐高相似的产品服务方案,结果见表13。

表12 高相似用户的兴趣度权重Tab.12 Interestweight of high sim ilar user

表13 新用户产品服务方案预测结果Tab.13 Forecast results of new user p roduct in service solu tions
由表13可以看出,对于新用户v1,机床方案优先级由高到低依次为 a7、a8、a5、a6、a9、a10、a2、a1、a4、a3,所以给其推荐方案首选是 a7、a8,新用户 v2推荐 a7、a8等产品服务方案,新用户 v3推荐 a4、a7。如果具体到产品服务方案特征推荐,可采用式(11),得出高评分性能特征给予推荐,以用户v1对应方案a7,v2对应方案a8以及v3对应方案a4的特征为例,具体见表14。由表14可知,对于方案a4,推荐交流无极变速的主轴箱,开环的进给传动系统,带刀库式的刀架的机床;对于方案a7,选择带有交流无级变速的主轴箱,溢流控制阀,齿轮泵的机床;对于产品服务方案a8,选择开环的传动,敞开式性能,环保性能高,交流无级变速的机床。

表14 产品服务方案特征推荐表Tab.14 Product service p rogram featu rerecomm endation form
4.2 产品服务方案推荐实时更新以及算法对比分析
在产品服务方案推荐过程中,新用户数据的产生使得数据库不定期更新,但为了实时推荐用户感兴趣的服务方案且不影响前期计算过程,首先计算该用户特征评分与推荐最近邻用户的相似度,如果相似度达到阈值0.85以上,采用式(14)对最后方案预测分值进行更新,虽然会略失准确度,但降低了时间复杂度,提高了方案推荐实时性。针对表13的用户v1方案推荐,采用新用户b的评分rba,更新产品服务方案推荐结果,见表15。

表15 实时更新的产品服务方案推荐结果Tab.15 Recomm endation results of real-tim e update of p roduct service solu tion
由表15可知,方案的优先级由高到低依次为a7、a8、a5、a6、a9、a10、a1、a2、a4、a3,与更新前的总体推荐方案次序变化不大,只是产品服务方案a1和a2的优先性调换了,说明更新数据少对结果影响力较小。
为了验证本文算法的合理性,考虑预测数据的推荐精度,以数据库中50~400个等量样本数据作为训练集进行试验。由于数据量过小,得到的速度差异不明显,故本文未考虑算法执行速度的比较,仅考虑了推荐精度的比较。通过式(15),对本文推荐算法、文献[16]中的基于云模型的协同过滤算法、文献[2]中的基于梯度算法的LFM三者推荐结果与实际结果的误差值进行对比,具体见图6。

图6 三种算法推荐得平均绝对误差Fig.6 M ean average error of three recomm endation algorithm
由图6可知,当训练集较少时,三种算法推荐精度误差不大,都在0.08左右;随着训练集样本数增加,误差较小,但是本文算法误差减小速度最快,说明对于数据量大的数据库,本文推荐算法更加有效。另外,也能看出基于云模型的CF算法比LFM的推荐准确率高,并且当训练集数量为350时,基于云模型的CF算法与本文算法的误差很接近。
5 结论
本文针对评分数据具有主观性、随机模糊性等问题,且余弦相似度难以区别用户对方案的偏好度,提出采用云滴距离测度和余弦相似度的综合相似度来预测填充空缺数据,弥补数据稀疏性。考虑到冷启动问题,即对零记录用户推荐合适的方案,本文基于问卷调查得到用户特征值并求相似度找出最近邻用户,并采用融入偏置量的加权LFM,提高推荐方案的效率。考虑到数据库是动态更新的,采用基于差值评分预测方法更新预测结果。最后在不同训练集下,拟合实际和预测平均误差值的变化趋势并分析结果,实验结果证明了本文算法的优先性。
本文将推荐算法与个性化产品服务方案相结合,虽然在方案推荐过程和结果的精度有所提高,但是在前期填充数据过程中会耗费很多时间。考虑在下一步研究中优化空缺数据的填充过程。
