基于Kinect手势识别的应用研究
2018-08-29王攀官巍
王攀官巍
(西安邮电大学计算机学院 西安 710061)
1 引言
随着计算机技术的发展和硬件设备的不断更新,电子设备已充斥着人们的日常生活,而设备传统的交互方式已经不能满足现代人的需求。传统设备的交互方式是单向的,用户只能单方面被动的去接受,人机交互技术[1]的出现就是为了改变现有被动的接收方式,并朝着自然化、智能化的方向发展。手势识别[2]是人机交互的一个重要途径,它摆脱了传统交互方式受硬件设备的限制,通过手势和简单外部设备进行交互操作,进一步的增强了用户的体验。目前,手势识别技术已经广泛的应用到了手机、电脑的控制以及体感游戏中。
手势识别的研究主要分为基于硬件设备的研究和基于计算机视觉的研究。一般借助外部设备收集手势数据,将收集到的手势数据利用算法经过一系列的处理得到相应的识别结果。本文是基于Kinect[3]的手势识别的应用研究,Kinect是由深度传感器、RGB摄像头和多点麦克风阵列组成的三维体感摄像头,能够实时获取场景图像和捕捉语音或者动作输入等信息。现如今,已经有很多学者将Kinect运用到手势分割、手势识别中,如文献[6]一种改进DTW算法的动态手势识别,通过采用改进的DTW算法对Kinect获取的深度信息进行模板训练和匹配,最后得到识别手部运动的目的。文献[7]基于深度图像信息的人体运动检测,提出了新的基于前景点的背景模型更新策略,解决了黑影现象以及鬼影现象,在识别率上有明显的提高。文献[9]基于视觉的匹配模板优化方法,提出了一种选择特定双目图像的优化模板尺寸方法,进行灰度匹配,匹配精度高,抗噪声能力强,运算速度快,而且误匹配率低。本文针对动态手势识别进行研究,通过将深度图像与彩色图像相结合的方法获得手部信息,然后利用动态时间规整算法和多项式时间算法结合计算,减少算法计算过程中的冗余计算,匹配出最佳的规整路径进而得到有效的识别结果。最后将手势识别方法运用到视力检测中,实现了基于手势的视力测试平台,改变了传统视力测试的方式,提高了人机交互的体验。
2 手势识别的算法与流程
本文利用Kinect的人体骨骼追踪技术。Kinect将人体骨骼标定为20个关键节点,如图1所示。并且对这20个人体骨骼的关键节点位置进行实时追踪,通过这些骨骼点信息可以获取人体骨骼实时运动的数据。
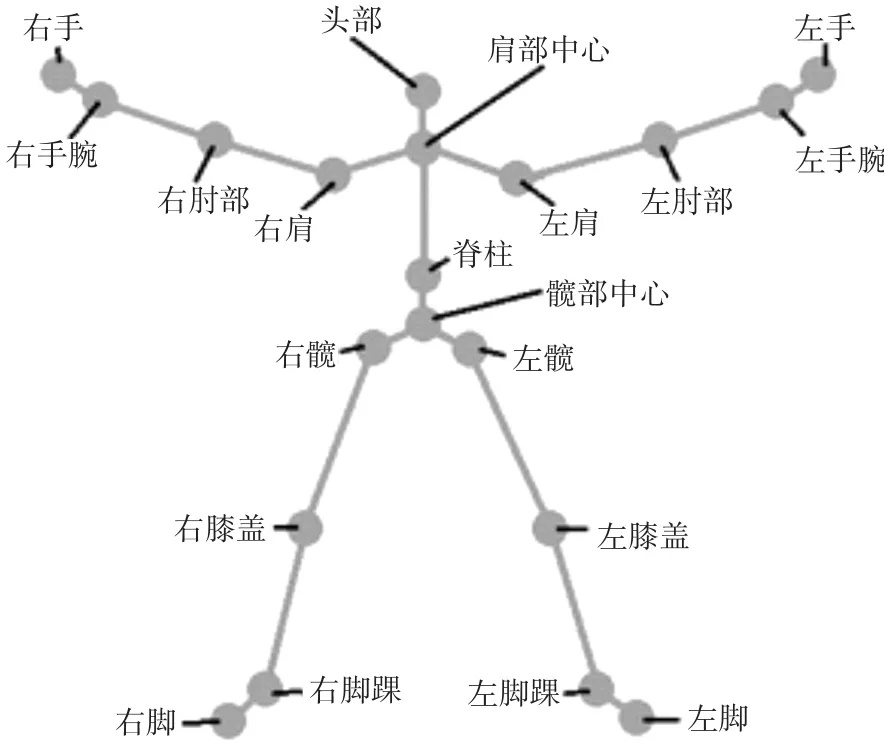
图1 Kinect捕获人体的20个关键节点图
本文使用动态时间规整(DTW)[4~6]算法实现对动态手势识别的研究。首先使用Kinect获取到手势的深度图像[7~8],进而提取人体手部骨骼的关键特征节点,从获取的人体手部数据中进行特征提取,得到有效的特征集。根据特征集去匹配相应的轨迹模板[9],最后得到识别结果。其手势识别的流程如图2所示。
2.1 对测试样本和特征序列的提取
对测试样本特征序列的提取是整个手势识别研究中最重要的一步,提取的测试样本的有效性将直接决定着手势识别算法的准确率。本文定义了四种动态手势[10]和一种静态手势[11],分别为向上、向下、向左、向右、悬浮五种手势,选取骨骼数据进行研究。Kinect可以追踪到人体骨骼的20个关键节点,本文借助该设备获取其中的8个人体骨骼的关键节点进行计算,分别为左手、右手节点,左手腕、右手腕节点,左肘部、右肘部节点,左肩、右肩节点。在录制手势测试样本时,每一种手势分别由5个人在不同环境下完成的,每种手势录制50个测试样本,共提取了1250个测试样本,每个样本包含了RGB图像和深度图像。由于图片包含大量数据信息,且本文主要针对手势进行研究,因此需要对手部图像进行分割提取。在分割过程中采用深度图像与彩色图像相结合的方法,获取有效的手部图像以利于对手势识别的研究。从得到的1250个手部图像的测试样本中,提取出其中合适的特征数据信息来描述采集到的手势样本。
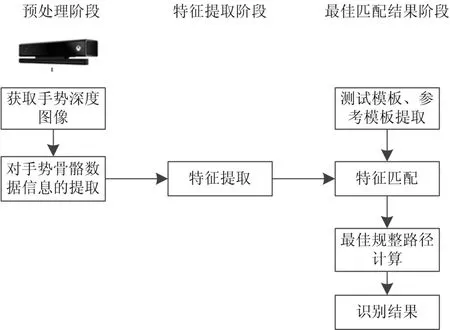
图2 手势识别流程图
2.2 DTW算法原理
动态时间规整(DTW)是一种基于动态规划的方法,对非线性时间[12]进行归一化再模式匹配的算法,DTW通过调整时间轴来满足一定条件的时间规整函数描述测试样本和参考样本的最佳匹配关系,求解两模板匹配[13]时累计距离最小所对应的规整函数,实际上是优化问题。所以手势识别的准确率和有效性与提取的测试样本有很大关系。下面具体介绍如何用DTW算法计算测试样本序列和参考模板序列的相似度。
假设一个手势的模板序列为:X={x1。x2。…。xn},n为模板序列的长度,一个测试样手势的序列为:Y={y1。y2。…。ym},m为测试样本的序列长度。如果两个序列的长度相等,则可以直接计算两个序列的对应特征点的特征向量的累加距离,如果两个序列长度不相等,则可以利用差值算法[14]对两个序列长度进行调整,使最终达到最佳匹配[15]的目的。但是由于现实中各种条件的影响,测试样本序列和模板序列长度总是不相等的,需要对两序列进行简单的压缩或者扩展,这时就必须使用动态时间规划(DTW)算法对两序列进行压缩或者扩展。动态时间规整(DTW)算法主要是计算两个序列中相对应帧之间距离的累加,计算出的总累加距离越小,则表明测试模板序列和参考模板序列两者的相似度越大,如果距离越大,则两序列的相似度越小。但是由于手势序列中同一动作在某一时间段持续的长短是不一样的,所以很难准确的找到手势序列之间的对应关系。因此构造了一个二维坐标模型来寻找手势序列之间的对应关系,如图3所示。此矩阵模型是有测试模板和参考模板组成的,其中有许多条满足规整路径的条件,但是只需要最短距离的规整路径,也就是矩阵网络中折线部分的路径,这就是测试模板和参考模板之间寻求的最佳匹配路径。
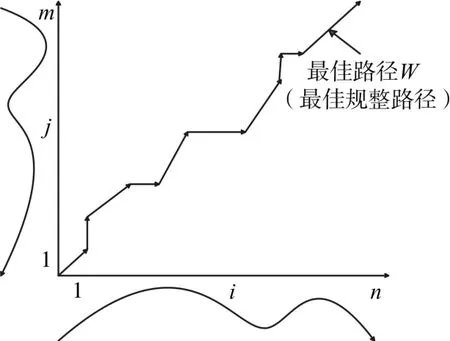
图3 矩阵网络模型
用W来表示规整路径,W的第k个元素定义为Wk=(i。j)k,定义了序列X和Y的映射。这样可以得到归整路径的形式为 W=(w1。w2。…。wk),其中Max(n。m)≤K≤|n|+|m|。
选择的规整路径需要满足三个约束条件,分别是:
1)边界条件:W1=(1。1)和W2=(n。m)。任何一种手势的同一动作的快慢都是不一样的,但是手势序列的先后次序不可能改变,则选取的路径必须是从上图矩阵中左下角开始,到右下角结束。确保所有的特征点都在所选取的路径上。
2)连续性:如果一个特征点Wk-1=(a'。b'),对于选取路径的下一个特征点Wk=(a。b)需要满足(a-a')≤1和(b-b')≤1。也就是只能和自己相邻的特征对应,是不能跨过别的某一个特征点去匹配。这样主要可以保证X和Y中的每个坐标特征点都在选取的路径上。如图4所示。
3)单调性:如果一个特征点Wk-1=(a'。b'),对于选取路径的下一个点Wk=(a。b)满足0≤(a=a')和0≤(b-b')。这限制选取路径上面的特征点必须是随着时间单调进行的。这样确保了X和Y两序列特征点之间不会交叉。
由上面的三个约束条件可以得出:当前节点的前面节点的方向分别是:(n-1,m),(n,m-1),(n-1,m-1)这三个方向,如图5所示。也就是说各一个节点的路径只有三个方向,如图5所示。
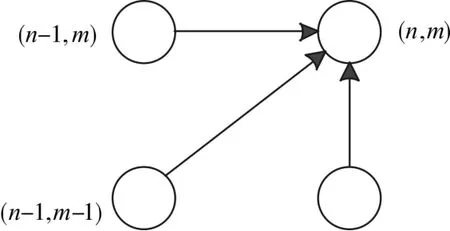
图4 相邻特征点示意图
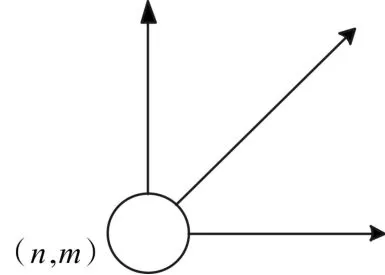
图5 特征点的规划路径图
从矩阵模型的(0,0)点开始进行匹配X和Y两个序列,将每到一个点的计算距离累加起来,在到达终点(n,m)之后,所得到的累加总距离就是上文中用来描述序列X和序列Y之间相似度的距离。由此可以得到的相邻特征点累计距离之和越小,两者序列的相似度越高。故最后要得到的归整路径是距离最短的一个归整路径:
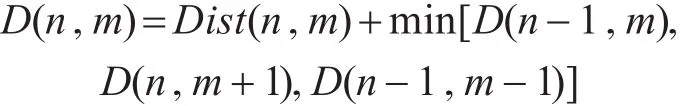
2.3 手势识别和多项式时间算法的运用
手势识别分为静态手势识别和动态手势识别,静态手势识别是指在手部位置不变的情况下,手指和手掌作出不同的动作和形状;动态手势识别是指手的位置和形状随着时间的变化也改变,但是动态手势可以丰富地表达执行者的意愿。手势识别的整个过程主要是对所建立的手势模型进行评估和特征提取[16]。本文首先通过Kinect获取到手部的深度图像,进而通过获取的深度图像追踪到人体手部骨骼的关键节点,然后对获取到的手部数据进行特征提取得到有效的特征集,最后根据特征集去匹配轨迹模板得到识别结果。
在2.2中运用DTW算法计算出测试样本序列和参考模本序列的之间的规整路径,从而得出两序列之间的相似度。由于实际情况中不同用户对同一个动作的理解存在着差异,并且对作出的同一动作都是不一样的,可能存在一些该类型的手势轨迹序列(测试样本序列)与该类型的手势模板序列之间的相似度仍然较低。在本文中将测试样本序列和模板样本序列中的特征节点分别提取出来,分解成若干个子问题进行计算,由于提取的特征节点之间并不是相互独立的,存在许多相似重复的计算,传统的方法造成了最优规整路径计算的复杂化。本文使用多项式时间算法对计算过程进行简化,通过将相似重复的计算结果保存起来进行直接利用,避免对提取的特征节点进行重复的计算,减少了相似重复的冗余计算,使得到的结果更加的准确和有效。
3 实验结果验证及分析
本文利用的手势识别算法,开发了一款基于手势的视力测试平台。在传统的视力检测过程中,需要被检测者配合验光师来识别视力表中字母E的开口方向。而本平台利用手势识别技术,通过手势表示字母E的开口方向,然后由计算机判别识别准确与否,从而判定被检测者的视力。该平台在界面上随机的出现不同开口方向的字母E,字母E的尺寸按从大到小进行依次出现。该平台规定,当同一尺寸的字母E答对次数达5次时,显示的字母E尺寸变小,当同一尺寸的字母E答错次数达3次时,测试结束,计算并显示被测者视力结果。视力测试平台界面由三部分组成,分别是:识别方向结果、字母E开口显示结果、手势识别结果。其中识别方向结果和手势识别结果的方向是一致的,而此时显示字母E开口方向为下一个即将识别的对象图。视力测试界面的实验结果如图6所示,图6(a)、(b)、(c)、(d)展示了对不同大小字母E开口方向的识别,图6(e)、(f)分别展示了根据对字母E开口发方向的识别检测出的视力结果。

图6 手势的视力测试平台部分实验结果示意图
本文在进行视力检测时,总共定义了5种单手手势指令,分别是向上、向下、向左、向右,以及一个静态手势悬浮。四个动态手势用来表达视力表中字母E的开口方向,静态手势悬浮用来表示测试开始或重测。动态手势和静态悬浮手势对应的指令如表1所示,动态手势和静态悬浮手势的结果识别率如表2所示。

表1 动态手势对应指令
利用Kinect传感识别和手势识别算法,在计算机上模拟开发了基于手势的视力检测系统。主要实现了利用动态手势识别表达视力表中字母E的开口方向,用静态手势悬浮用来表示测试开始或重测。
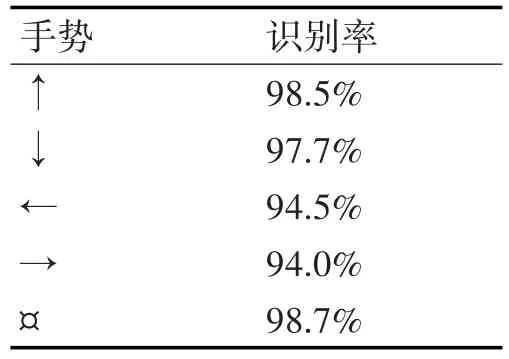
表2 动态手势识别率
4 结语
本文主要研究了基于Kinect设备的动态手势识别方法,在预处理阶段,利用Kinect获取的深度图像,将深度图像与彩色图像相结合,对动态手势样本进行手势分割。然后利用动态时间规整(DTW)算法对动态手势进行识别,将手势序列分解成若干个子序列并进行累加计算,利用多项式时间算法减少DTW算法中最佳匹配过程中的冗余计算,然后进行最佳匹配得出最优的规整路径。最后将手势识别方法运用到视力检测中,实现了基于手势的视力测试平台,改变了传统视力测试的方式,较好地提高了人机交互的体验。
