基于Storm的实时海量轨迹数据查询系统设计
2018-08-29谢小丽
谢小丽 卢 山
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火软件科技有限公司 南京 210019)
1 引言
随着科技的快速发展,大数据[1~2]时代的到来,数据对于整个社会具有至关重要的作用,而海量轨迹数据具有较大的科研、经济、社会等价值,已经引起了各行业的高度重视。由于轨迹数据具有时空特性,轨迹数据的价值容易流失,有效期短。如何高效地查询这些实时的海量异构轨迹数据,己经成为业内的研究热点。在智慧城市的建设中,能实时定位某公共交通的位置或了解其实时移动轨迹对市民的出行以及城市交通规划等方面意义重大,对这些实时的流式轨迹数据的查询成为智慧城市建设中的研究重点。本文以智慧城市建设中,南京某城区各种公共交通实时产生的轨迹数据作为本查询系统研究对象。
20世纪80年代末的实时数据查询系统主要为集中式的查询架构,比如Stream系统[3~4]、Aurora系统[4],集中式查询架构由单个节点进行查询运算,能很好地解决数据量较少情况下的查询运算,但在数据量增加到一定量的情况下就会因为单一服务器数据源计算效率低、存储空间受限等缺点而遇到查询运算瓶颈。分布式[5]架构相对集中式架构在处理效率,可扩展性方面具有明显优势,能够克服数据量增多时带来的计算效率低等难题,因此分布式查询框架在大数据时代被广泛使用。文献[4]提出了一种基于广域网的车辆轨迹数据分布式挖掘方法,实现了从海量的轨迹原始数据挖掘出具有指导意义的参考决策数据。文献[15]提出了一种动态自调节的SDN控制器负载均衡算法,能够有效实现分布式系统各工作节点的负载均衡。数据显示,南京某城区公共交通导航系统实时产生的轨迹数据大约为150万/秒,这种实时的流式数据量远远超过集中式查询框架的处理范围,因此选择分布式框架作为本课题的查询框架。本文结合实时海量轨迹查询系统的需求分析,对比分析分布式框架Samza、Spark、Storm,针对海量轨迹数对查询系统的需求,选择Storm框架作为本系统的查询框架,对查询模块以及查询流程进行了相应的描述,然后针对数据量较大情况下引起的负载问题,引用动态负载均衡算法来解决,针对节假日实时轨迹数据持续性增长时,本文提出减少接入数据流的方案,来降低整个系统负载。最后通过实证对比分析证明在数据量大时,本系统的负载得到了有效的均衡,查询的实时性得到了提高。
2 实时查询系统现状
目前被广泛使用的实时计算系统实例有Berkeley的交互式实时计算系统Spark Streaming、Microsoft的Time Stream系统、Hadoop之上的数据分析系统HStreaming、IBM的商业流式计算系统Stream Base、Twitter的Storm系统、Linkedin的Sam⁃za系统等。
本文主要对比分析了使用比较广泛的分布式实时计算架构Samza、Spark、Storm,如表1所示,对三种分布式架构的相关特性进行对比发现,Samza、Spark系统较Storm系统的吞吐量较高,而Storm系统的时延比较低,这是由于Strom系统一旦收到新数据或者新任务立刻开进行处理;而Spark系统是在处理前按时间间隔预先将其切分为批处理作业,系统的延时性会受批量作业大小的影响[9]。Samza系统处理的数据流单位是一条条消息,这些消息由数据流切分成的有序数列构成,处理过程比Storm复杂。因此Storm系统相对Spark具有低时延特性,相对Samza处理更简单。Storm平台具备高容错性,一旦topology(拓扑)递交给Storm,系统会运行到topology废除或者被关闭,当执行过程中出现错误时,Storm会重新分配任务。基于Storm的低延时性和高容错性,故本文选用Storm系统作为海量轨迹查询处理框架。
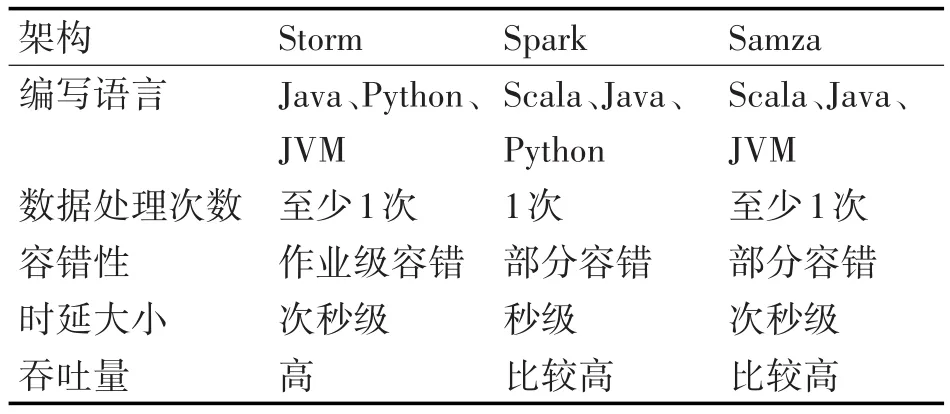
表1 三种大数据计算框架特点比较
3 实时查询系统分析与设计
3.1 实时流查询系统分析
该系统主要是针对智慧城市建设中南京某城区公共交通导航系统产生的实时海量轨迹数数据的查询系统。轨迹数据是在时空环境下,对移动对象的运动过程进行采样,采样的信息主要包含地理位置信息、移动个体的属性信息以及时间信息,将这些信息按照时间顺序接起来的数据,属性信息主要包含采样点速度、位置、时间以及协议等。海量轨迹数据具有实时性、异构性、易失性、突发性、无序性、无限性等特点。基于以上特征本查询系统需要解决的查询难题有:实时的轨迹数据流到来后需要系统即时处理,只有少部分数据会被保存下来,故要求系统能够有一定的容错性;轨迹数据的价值容易流失,有效期短,对系统的实时性要求高;各种公交通的导航系统各不相同,导致轨迹数据的结构互异,因此需要系统能处理异构的数据;实时轨迹数据量较大时,系统的负载均衡以及数据过大超过系统的处理范围时的应对措施。
3.2 基于Storm的查询系统架构设计
为满足海量异构轨迹数据查询系统的实时性要求,本查询系统主要由数据接入层,开发层组成,逻辑层,用户交互层组成[16],查询系统架构图如图1所示。
数据接入层,将实时的轨迹数据接入系统,对源数据进行预处理,主要包括原始数据清洗和轨迹压缩。轨迹数据清洗的目的主要是剔除数据中的冗余点,本设计采用的是免费的数据清洗工具OpenRefine,清洗的途径包含去除或补全有缺失的数据;去除内容有错误的数据;修改数据格式;关联性验证等。轨迹压缩的目的是减少查询系统负载。采用的是Top-Down数据压缩算法[12],该算法主要目的是对轨迹数据进行抽稀、去重,以达到对轨迹数据压缩的目的;
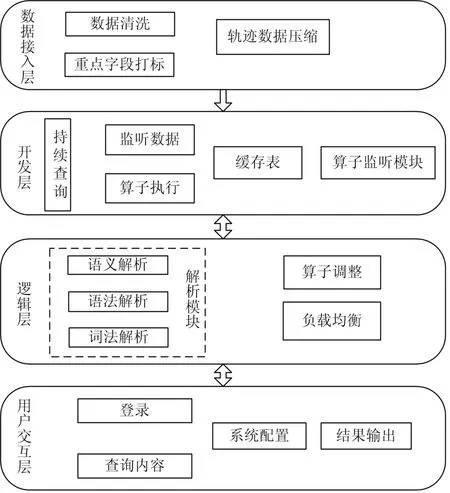
图1 查询系统架构图
开发层,在查询的过程中主要是执行逻辑的查询算子,逻辑层产生的查询算子进入开发层,在Strom集群中按查询计划依次执行,在查询结果返回过程中将缓存表里的数据传给逻辑层。
逻辑层,作为整个查询系统的核心层,由解析模块、算子调整、负载均衡组成。
1)解析模块:使用Antlr开源工具,先逐一读取输入的cql语句中的字符进行词法分析,识别cql中每个单词即词法单元是否符合词法要求。将其传递给语法分析器,语法分析器检验词法单元是否符合语法,然后构造语法分析树,语义解析模块将语法树进行解析,将关键字和关键字对应参数分离,以关键字为节点,参数为叶子节点,构成一颗语法逻辑树。
2)算子调整:查询算子的顺序会直接影响系统的资源利用率,针对某些具体查询过程时需要改变其查询算子的顺序[15],比如连接算法中,开销巨大,如果先进行连接再进行过滤操作,则会对系统的资源造成浪费,包括分组算子也是非常消耗系统资源的操作,所以通过将过滤操作,投影操作等低消耗资源的算子设为较高优先级,而对于部分资源消耗高的算子设为较低优先级,从而减小资源的开销。
3)负载均衡:主要为数据流量较大过快,系统负载不均衡情景设计,引用动态负载均衡算法对系统负载进行调整;
用户交互层,用户可以自定义查询符合要求的数据,查询结果的输出。
3.3 基于Storm的查询系统流程设计
该系统主要是针对智慧城市建设中南京某城区公共交通导航系统产生的实时海量轨迹数数据的查询系统。系统查询海量轨迹数据具体流程图如图2所示。
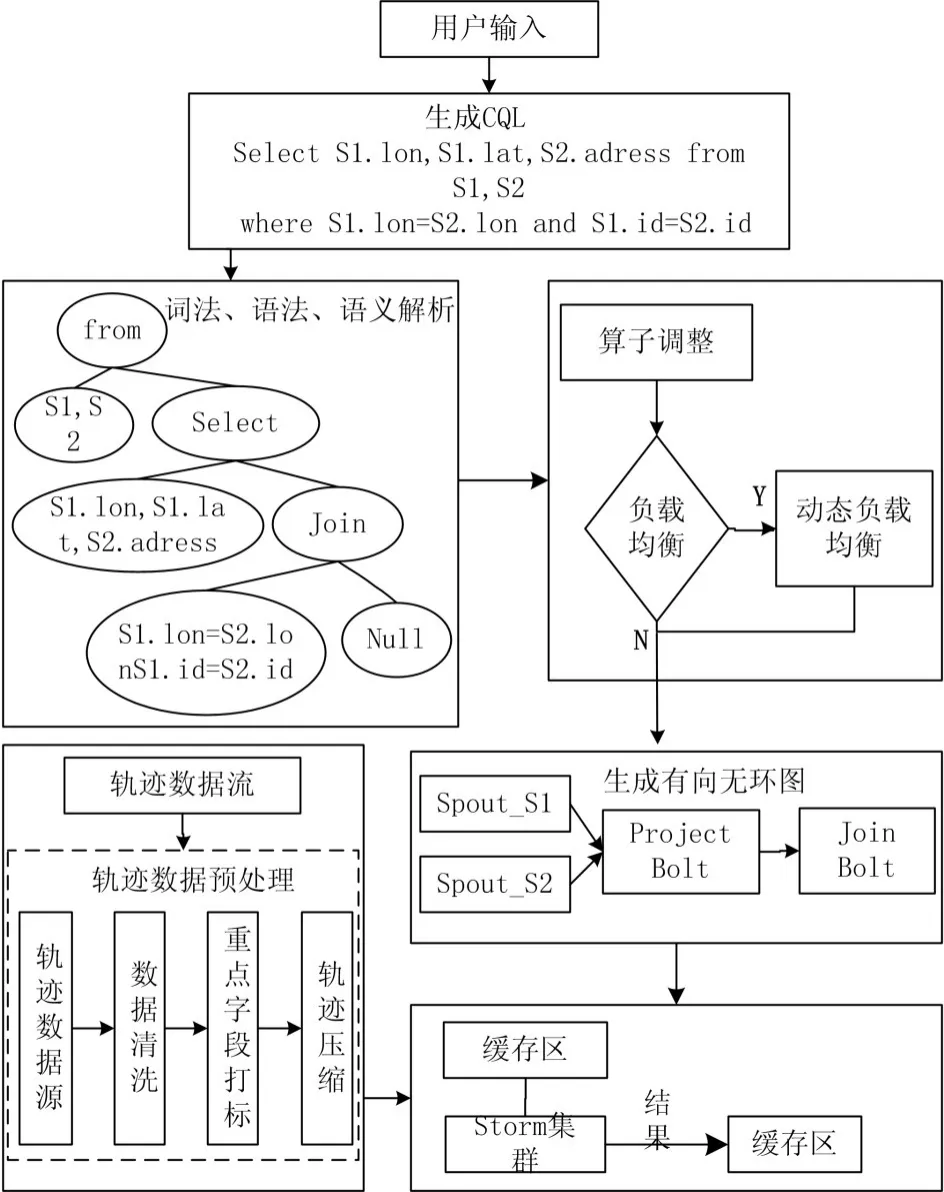
图2 系统流程图
4 实时查询系统难点解决
实时轨迹数据流的增长具有不确定性,数据量较大时,系统会出现负载不均衡的问题,数据量过大或者超过系统的处理上限时,可能会导致查询系统崩溃。为此,在数据量较大时引入动态负载均衡算法;数据量过大时,如超过系统的处理上限220万/s时,本文根据轨迹数据的连续性特点,提出一种过载处理方法。
4.1 动态负载均衡
负载均衡的目的是合理分配任务到各处理节点,当流入查询系统的轨迹数据量大于某一阈值流速时,开始使用动态负载均衡的算法来处理本查询系统的负载问题。
动态负载均衡分别从节点负载、负载预测和负载迁移三个方面对动态负载均衡问题进行了分析,首先对节点各个分量负载值 V={V1,V2,…,Vn}进行分析,Vi分别表示第i个长度为t的极短时间内的平均负载,利用加权移动平均,由公式(1)预测第i+1个t时间内平均负载Vn+1:
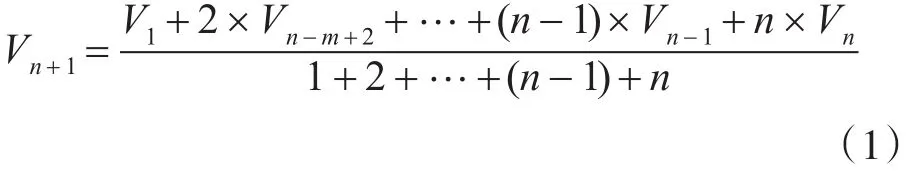
根据平均负载预测值设定相应阈值,Mp、Ms、ML,Mp代表准备负载迁移阈值,Ms代表开始负载迁移阈值,ML代表低负载阈值。若本查询系统有n个节点,某极短时间内每个节点的平均负载为M1,M2,M3,…,Mn主节点监测各个分节点负载,若某节点i存在Mi<ML,则将i节点纳入低负载节点集合CL内,将Mj>Mp则将j节点纳入高负载节点集合CH内,对其分析,拟定其需要迁移的算子,然后将CL与CH中的元素进行合理的配对,如i与j配对,当Mj>Ms,将之前拟定的需要迁移的算子算子迁移到i节点上。
4.2 过载处理方法
由于节假日期间车流量突增,导致实时轨迹数据产生量相对平时明显增加,数据显示南京市在2016国庆期间所产生的实时轨迹数据量约400万/s,大约是平时数据量的2.67倍,远远超出了本系统的处理上限220万/s,数据量的突增会直接导致查询效率低甚至系统崩溃,针对此类数据量突增的情况,在考虑运行成本、不增加服务器集群数量的基础上,结合轨迹数据自身的特点,如已知某运动实体当前位置,根据其运动速度可推出下一秒此实体所在位置,设计了一种解决方案,核心思想如下:根据南京城市交通规定,城市道路上的行驶车辆被限速在60km/h(16.67m/s)以下,结合轨迹数据特点,每秒最大轨迹变化为mmax=16.67m,对于轨迹数据量持续过大的节假日,采取将轨迹数据流间断性的接入系统,间隔时间为t=0.2s,并进行连续化处理,可使数据吞吐量有效降低,实现400万/s的数据流降至200万/s,且查询结果最大误差为dmax=mmax*t=3.33m,属于正常误差范围。该方法使系统的负载及查询性能得到了明显的优化,查询接结果的误差在可接受的范围内。
5 测试验证与分析
5.1 测试平台
本系统采用的是C/S模式,通过在服务器端部署海量数据处理平台Storm,采用6台计算机作为主从节点,配置如下:系统版本:Linux CentOS 6.4,CPU:Intel Core i7 6700,单机计算内存:DDR4 16GB,Storm版本:1.0.1。其中2台作为nimbus启动,4台作为supervisor启动,达到增强系统计算能力的目的。数据源采用的是交通部门的实测数据,数据包含车编号、速度、经度、纬度、帧号。
5.2 系统动态负载均衡性能测试
为测试系统运行时的负载均衡效果,将交管部门的实测轨迹数据作为数据源,以实时查询某一车辆的轨迹为查询任务,对集群的各个节点的cpu负载进行检测。开始时将数据源以约100万/s的流速入集群,随后以10万/s的速率增长,直至增长到400万/s,此过程不进行任何的负载调整,测试得出集群中各个节点的cpu负载如图5所示。
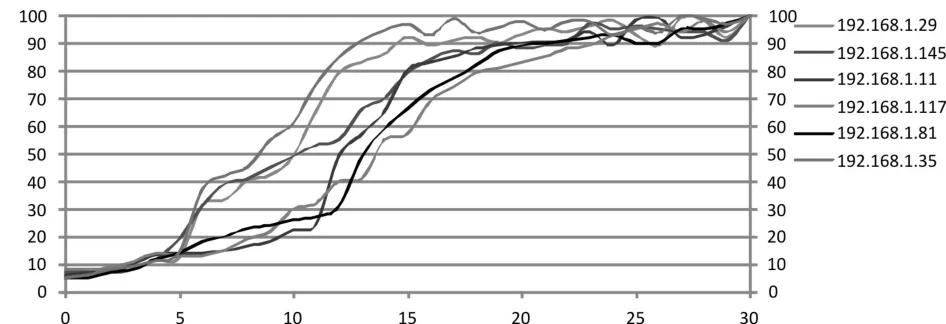
图5 无负载均衡时节点cpu负载
由图5可知,在系统约第6秒时节点192.162.1.29、192.162.1.145、192.162.1.117cpu负载增长速度明显高于节点 192.162.1.11、192.162.1.81、192.162.1.35,导致系统出现负载不均衡问题。
重复上述实验过程,在第6秒时引入动态负载均衡算法,测试得出集群中各个节点的cpu负载如图6所示。
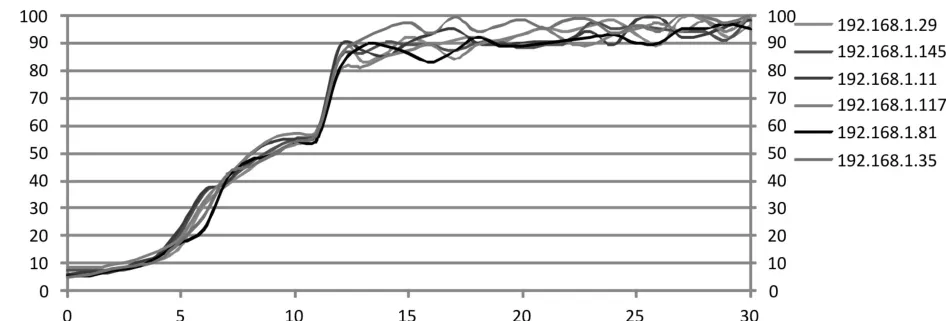
图6 引入负载均衡时cpu负载
由图6可知,系统在第6秒引入动态负载均衡算法后各节点cpu负载增长趋势基本保持一致,第12秒时即流速达到系统上限220万/s后系统各节点cpu负载基本处于过载状态,此时动态均衡负载算法并不能有效降低各节点负载,为此本文设计了下文中的一种过载处理方法。
再次重复上述实验过程,第6秒引入负载均衡算法,当流速达到220万/s上限时,引入过载处理方案,测试得出集群中各个节点的cpu负载如图7所示。
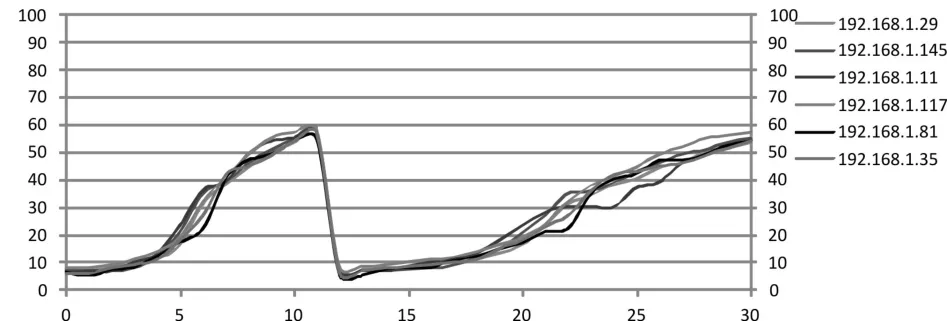
图7 引入过载处理方法时节点cpu负载
当轨迹数据流速超过220万/s时,系统采用过载方案处理,由于该处理过程包含对数据流的时间采样,导致一定程度上会影响轨迹查询结果的准确性,为测试查询结果的准确性,随机抽取上述实验数据中10条数据与其真实轨迹进行对比,通过动态时间规整(Dynamic Time Warping,DTW)算法得出与真实轨迹的相似度如表2所示。
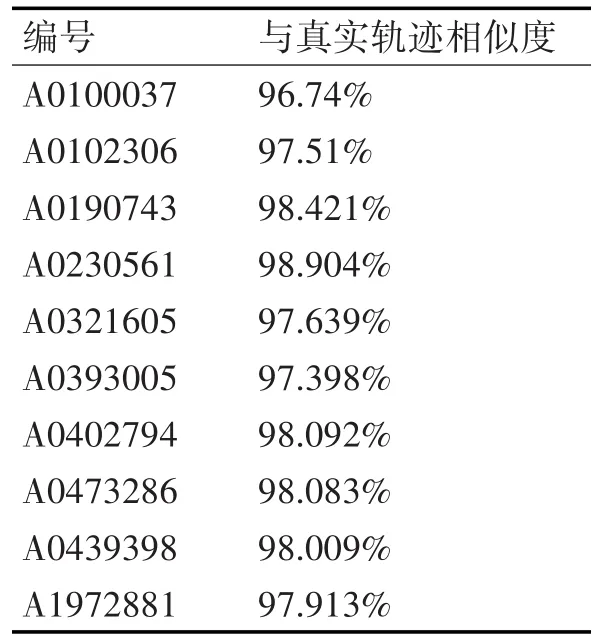
表2 轨迹相似度对比表
6 结语
本文通过对实时海量轨迹数据查询系统的研究,进行了Storm计算架构的查询系统设计,发现在处理海量轨迹数据时,本文设计的利用Storm平台处理海量数据的查询系统能够解决实时性差,负载不均衡等问题,并为用户的查询需求提供了统一的数据格式以及易于操作的查询界面,在查询请求增加的情况下,系统响应时间趋于稳定,负载均衡问题得到了有效解决,但本文设计的海量数据查询系统仍然存在些许问题需要解决,主要包括算子调度优化、降载优化,下一步将针对这些问题展开研究。
