K近邻协同过滤推荐算法中的最优近邻参数
2018-08-29李晓瑜
李晓瑜
(安康学院电子与信息工程学院 安康 725000)
1 引言
协同过滤(collaborative filtering)作为目前个性化推荐系统中广泛使用的最成功的推荐算法[1],使用统计技术寻找与目标用户有相同或相似兴趣偏好的邻居用户,根据邻居用户的爱好推荐或者预测目标用户可能喜欢的物品。协同过滤推荐系统主要有基于内容协同过滤、基于模型协同过滤和混合协同过滤[2]。协同过滤推荐使用K最近邻算法从全局用户群中将K个最近的邻居用户找出来。KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别[3]。
K-近邻算法应用在协同过滤推荐中,用于寻找最近邻用户,从而实现推荐目的。KNN算法的结果很大程度上取决于参数K的取值。本文通过实验分析在使用K-近邻算法寻找近邻用户时,近邻参数K对结果带来的的影响主要有哪些,当K取何值时使得K-最近邻算法的精度达到最大,也就是寻找一个最佳K值。
2 协同过滤
2.1 算法基本概念
协同过滤推荐技术通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品,主要有两种。一种是基于用户的协同过滤推荐,一种是基于项目的协同过滤推荐。这两种都是基于内存的协同过滤推荐算法。基于用户的协同过滤推荐,先查找与目标用户评分相似的用户,然后把他们感兴趣的项目推荐给目标用户。基于项目的协同过滤推荐是先计算项目在评分数据上的相似程度,然后给目标用户推荐那些和他之前偏好类似的项目[4]。协同过滤推荐算法的实现主要包括以下三个步骤[4]:
1)数据收集,通过数据收集获取用户在各个领域的兴趣和偏好。主要是收集用户的偏好,用户以多种方式向系统表达其偏好,既可以是直接打分、投票、打标签、评论等显式方式(Explicit Rating),也可以是购买、浏览等隐式形式(Implicit Rating)。
2)寻找最近邻,寻找目标用户的K个最近邻居集或者项目的K个最近邻居集。通过使用Jaccard系数、余弦相似性(或修正的)、Pearson相关性等度量用户或项目之间的相似度,寻找历史评分上的最近邻居。
3)预测评分:根据最近邻居集合计算目标用户对目标项目的预测评分,并在此基础上给出推荐。
2.2 详细步骤
2.2.1 创建用户评分表
传统的协同过滤推荐算法的输入数据是一个m×n的用户-项目评分矩阵[5],其中m代表用户数量,n代表项目数量,Rij代表第i个用户Ui对第j个项目Ij的评分,如表1所示。
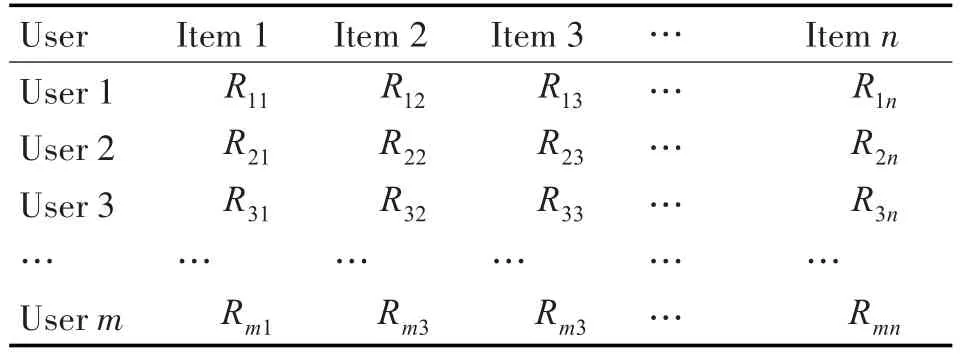
表1 用户-项目评分表
Rij的表现方式可以是多种方式的,比如Rij可以取值为0或者1,分别代表用户对该项目的喜好状态(不喜欢/喜欢),购买状态(未购买/购买)或者浏览记录(未浏览/浏览)等;也可以采用分级的数字来表示用户对项目的喜好程度,比如电影评分系统中经常用到的1~5分制评分体系,值越大表明用户的喜好程度越高。如果用户未对项目评分,则对应的评分用空值或者零值来代替。根据用户-项目评分矩阵,每个用户的评分或者每个项目的得分都可以用其对应的行/列向量来表示。
2.2.2 近邻选择
协同过滤算法的推荐原理就是查找与目标用户相似的近邻用户,通过近邻用户的评价对目标用户产生推荐。近邻用户的选择方法如下:计算目标用户与推荐系统中其他所有用户的相似性,根据相似性排序从大到小依次选择前面的K个最相似的用户作为目标用户的近邻集合。
2.3 进行推荐
协同过滤算法一个基本的假设就是具有相似喜好的用户,对于同一个项目会给出相似的评分。因此,目标用户的近邻集合生成后,就可以根据近邻集合中用户的评分,来预测目标用户对于未评分项目的评分。例如我们要根据用户P,Q,R,X,Y和Z来预测用户A对电影M的评分。应用K-最近邻算法来实现,若参数K=2其中距离用户A最近的邻居是用户X和Y如图2.1所示。其中X(4,1),Y(2,2),用户X与用户A的距离为4,对电影M的评分为1;用Y与用户A的距离为2,对电影M的评分为2。那么我们可以计算出用户A对电影M的评分为
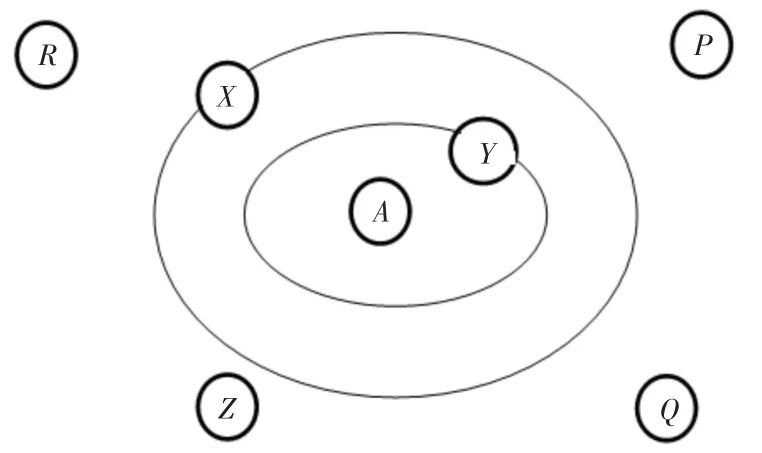
图1 用户A近邻图
((1/2)*2+(1/4)*1)/(1/2+1/4)=1.25/0.75=1.67
那么我们如何来评价推荐的质量如何,召回率和准确率是协同过滤推荐衡量推荐质量的常用评价标准。
1)召回率(Recall)反映了待推荐项目被推荐的比率[7]。
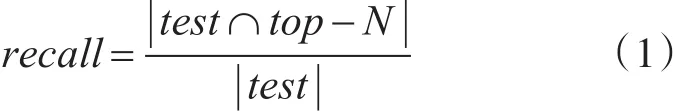
其中test表示测试数据集中的项目数量,top-N表示系统推荐给用户的N个项目。
2)推荐准确率(Precision)表示算法推荐成功的比率[8]。
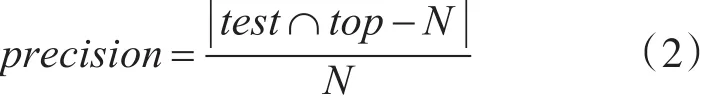
其中test表示测试数据集中的项目数量,top-N表示系统推荐给用户的N个项目。
召回率Recall和推荐准确度Precision二者是相互矛盾的,当top-N个数增加时,召回率(Recall)升高而推荐准确率(Precision)却下降。一个推荐结果的召回率和推荐精度同样重要,故而综合考虑算法的这两个方面的性能是比较科学的。如式(3)所示的参数F1采用相同的权重将召回率和推荐精度结合起来在二者之间找到最佳平衡点[9]。
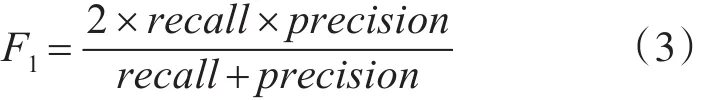
召回率和推荐准确率这两个值越高表明推荐质量越好。
3 K近邻算法
(K-Nearest Neighbor algorithm),邻近算法也称为K最近邻分类算法,它是在1968年由Cover和Hart首次提出,K-近邻算法是模式识别中一种重要的非参数法[10]。KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。KNN方法在类别决策时,只与极少量的相邻样本有关[11]。将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。
KNN近邻算法,通常有两种相似度计算方法,即欧氏距离公式[12]和余弦距离[13]。
设 两 个 n 维 向 量 A1=(a11,a12,a13…a1n)和 A2=(a21,a22,a23…a2n)它们之间的欧氏距离可以表示为
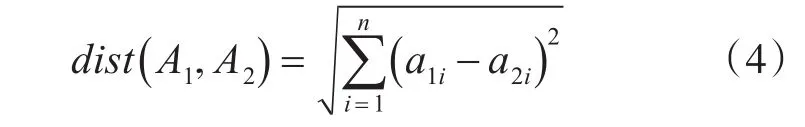
欧式距离通常采用的是原始数据,而并非规划化后的数据,比如有一属性在1~100内取值,那么便可以直接使用,而并非一定要将其归一到[0,1]区间使用。这样的话,新增对象不会影响到任意两个对象之间的距离。然而,如果对象属性的度量标准不一样,如在度量分数时采取十分制和百分制,对结果影响较大。标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:现将各个维度的数据进行标准化:标准化后的值=(标准化前的值-分量的均值)/分量的标准差,然后计算欧式距离。假设样本集X的均值(mean)为m,标准差(standard deviation)为S,那么X的“标准化变量”表示为

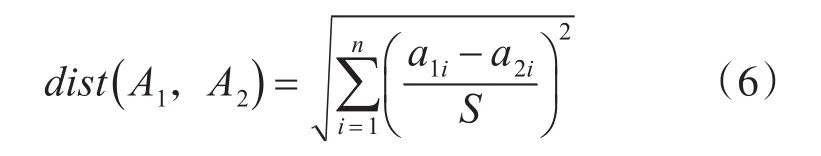
余弦相似性将用户评分被看做是n维项目空间上的向量如果用户对项目没有进行评分,则将用
标准欧氏距离,计算公式为户对该项目的评分设为0,用户间的相似性通过向量间的余弦夹角度量设用户i和用户在n维项目空间上的评分分别表示为向量→i。→j,则用户i和用户j之间的相似性sim(i,j)为
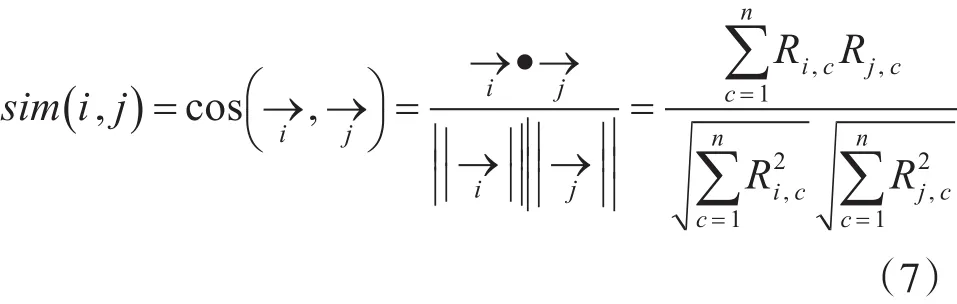
分子为两个用户评分向量的内积,分母为两个用户向量模的乘积。其中 Ri。c和 Rj。c分别代表用户i和用户j对项目c的评分。
KNN算法的伪代码描述如下:
1)输入测试数据集X={xi|i=1,2,3…,n},并确定参数k的值
2)For i=1,2,3…,n
3)计算测试数据与各个训练数据之间的距离dist()
4)Ifi≤ k
5)将xi放入最近邻集合中
6)Else if
7)删除xi
8)选取距离最小的K个点
9)End if
10)endfor
4 实验结果及分析
4.1 数据集
将 Weka[14~15]data 文件中自带的 UCI数据库中的 iris、Labor、Glass、Ionosphere、vote五个数据集作为实验数据集。数据集相关信息如表2所示,其中Dataset代表数据集的名称,Instances数据集实例个数,数据集类型Class,数据集属性个数Attributes。
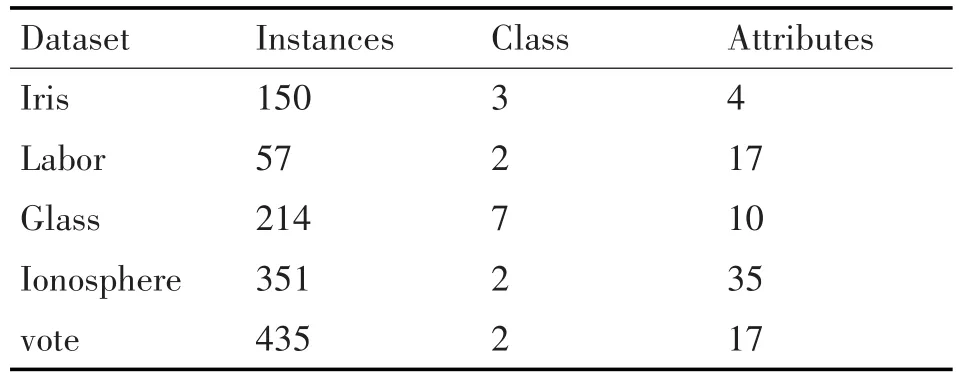
表2 数据集信息
在不同数据集应用KNN算法,当参数K取不同值时,所得到的精度值如表3所示(数据来源Weka工具)。其中每个数据集上面的最大精度值用粗体表示。
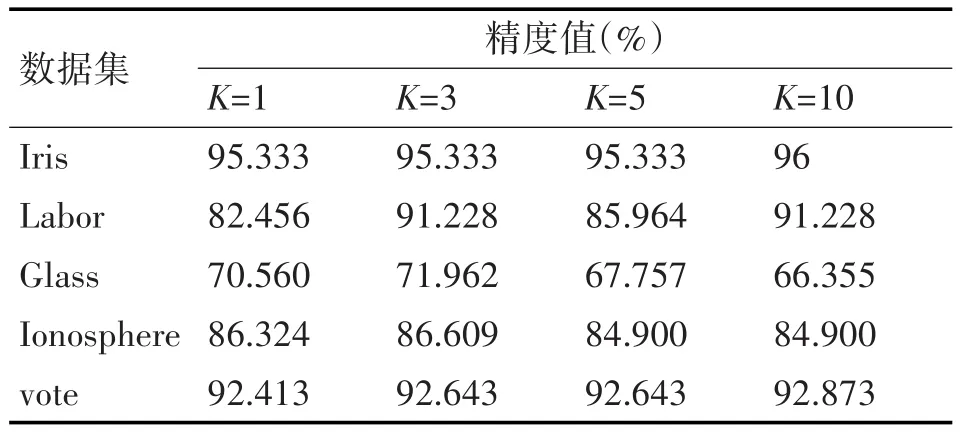
表3 不同K值对应精度值
在不同数据集上面应用KNN算法,最近邻参数K取不同的值,所对应的算法精确度如图2所示。
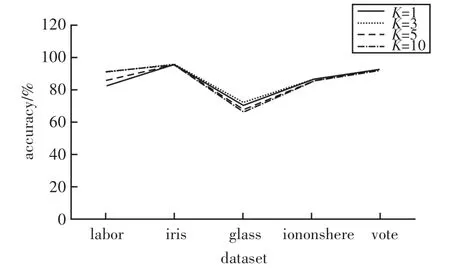
图2 数据集算法精度图
4.2 结果分析
根据上述输出结果,可作如下分析:
1)通过对比观察表3在5个测试数据集上面应用KNN算法,将近邻参数K的取值分别设为1,3,5,10,其中当K=3时,有3个数据集的算法精度为最大值。
2)通过对图2进行观察发现,当KNN算法的近邻参数K=3时,所对应的算法精度值折线要高于其他取值。
由此当近邻参数K=3时,使得KNN算法的精度最优,故我们得到在协同过滤推荐算法中,KNN算法的最优近邻参数值为3。
5 结语
基于K-近邻算法的协同过滤是推荐系统中广泛采用的一种预测和推荐方法。使用KNN算法从训练数据集中找出K个与目标用户相似的用户,然后计算其相似性,并对目标用户进行推荐。通过对实验结果分析,发现当近邻参数K=3时,使得KNN算法的精度最优,故我们得到在协同过滤推荐算法中,KNN算法的最优近邻参数值为3。
