基于SMOTE和深度信念网络的异常检测
2018-08-27沈学利覃淑娟
沈学利,覃淑娟
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)(*通信作者电子邮箱qinshujuanup@163.com)
0 引言
随着网络规模的日益扩大和网络攻击的日益增加,入侵检测(Intrusion Detection, ID)依然是人们研究的热点之一。为了提高入侵检测系统(Intrusion Detection System, IDS)对未知网络攻击的识别能力和用户数据的关联性分析能力,许多研究学者将机器学习的方法引入到入侵检测系统中[1-2],如支持向量机(Support Vector Machine, SVM)[3-5]在处理小样本数据集时检测率较高,但是由于其时间复杂度(为O(n3))和空间复杂度(为O(n2))的局限性,处理海量数据集时性能较差;神经网络(Neural Network, NN)[6-7]在一定程度上具有适应性和可扩展性,但是处理海量数据集时鲁棒性仍有待提高;深度学习(Deep Learning, DL)[8-10]能够挖掘高维数据的潜在特征,分类识别能力较强,但是现有的方法没有考虑到少数类别样本的入侵检测问题。而在入侵检测系统中,把提权(User to Root, U2R)攻击识别为正常用户数据,比把拒绝服务(Denial of Service, DoS)攻击识别为正常用户数据对系统的危害更大,因此,在保证较高检测率和较低误报率的基础上,识别并阻断少数类别的攻击有着重要的现实意义。
针对上述问题,本文提出了一种基于合成少数类过采样技术(Synthetic Minority Oversampling Technique, SMOTE)和深度信念网络的异常检测(anomaly detection based on SMOTE and Deep Belief Network, SMOTE-DBN)方法,在保证其他类别样本检测率的前提下,能够提高少数类别样本的检测率,同时降低误报率。
1 异常检测框架
基于SMOTE和深信网的异常检测框架包含三部分内容,如图1所示。
1) 数据预处理。如图1(a)部分所示,通过合成少数类过采样技术(SMOTE)降低数据集的不平衡度,再将数据集中的符号型特征数据数值化,并对数据型特征数据进行归一化处理,详见3.1节内容。
2) 数据特征降维。如图1(b)部分所示,将预处理后的数据集用深度信念网络(Deep Belief Network, DBN)进行特征抽取,先用受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)对数据集自底向上进行预训练,获得模型的初始参数,再用BP(Back Propagation)网络微调模型参数,获得较优模型参数,更好地将原始高维数据映射至低维数据,详见2.3、2.4节内容。
3)逻辑回归(Logistic Regression, LR)分类器。如图1(c)部分所示,通过softmax逻辑回归分类器,对较优低维数据集进行5种用户数据状态的识别,详见2.5节内容。
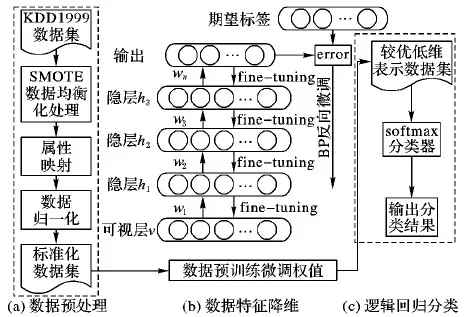
图1 基于SMOTE-DBN模型的异常检测框架
2 相关算法
2.1 SMOTE
SMOTE算法是一种典型的过取样方法[11-12]。它用少数类样本控制人工样本的生成与分布,实现均衡数据集的目的。核心思想是在某少数类别样本中随机地选取一个样本点,并在其最近邻的k个样本之间,插入n个人工合成的少数类别样本,从而增加少数类别样本的数量,均衡化数据集。
由于入侵检测基准数据集中的数据分布很不均匀,现有检测方法对少数类别样本的检测率很低[13-14],因此采用SMOTE方法来消除非均衡样本集对检测精度的影响。
此外,由于SMOTE选取样本的随机性,可能会选取在样本集边缘的样本点进行近邻插值,引起模糊样本边界的问题。为了避免新合成的样本点具有极少的少数类样本特征,致使数据集的原始分布改变,要尽可能地选取不在样本边缘的样本点,K-means算法[15]能有效解决这个问题。用K-means计算出样本点的簇心m,选取簇心的k个近邻进行插值操作,得出新样本xnew:
xnew=m+rand(0,1)*(x-m)
(1)
其中x为簇心m的近邻样本,rand(0,1)表示0~1的随机数。
插入新样本的步骤如算法1所示。
算法1 插入新样本。
输入:原始少数类训练样本集,需要合成的样本数n,循环变量k。
输出:少数类训练样本集。
fort=1,2,…,k
用K-means算法记录少数类样本的簇心m
fori=1,2,…,n
随机选取簇心m的近邻样本点x,用式(1)在x与m之间插入新的样本点
end
2.2 DBN模型
DBN[16]是由若干层非监督的RBM网络和单层BP神经网络构成的深层神经网络。训练模型的主要步骤如下:
1)用对比分歧(Contrastive Divergence, CD)算法[17]单独无监督地训练每一层RBM网络,确保特征向量映射到不同特征空间时,尽可能多地保留特征信息。
2)BP网络接收RBM的低维输出特征向量作为输入特征向量,有监督地训练实体关系分类器。由于每一层RBM网络只能确保自身层内的权值对该层特征向量映射达到最优,并不是对整个DBN的特征向量映射达到最优,所以反向传播网络将错误信息自顶向下传播至每一层RBM,微调整个DBN。RBM网络训练模型的过程可以看作对一个深层BP网络权值参数的初始化,使DBN克服了BP网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点。
通过上述步骤,能够构建出具有多隐藏层的非线性网络结构,挖掘海量数据集的潜在特征,从而学习出高维数据的较优低维表示,得到更易分类的入侵检测数据特征。
2.3 预训练
RBM是DBN的核心模块之一[18],由可见层单元(v)和隐藏层单元(h)构成。可见层与隐藏层的层内无连接,层级之间全连接。如图2所示,可见层单元为v=(v1,v2,…,vm)描述输入数据的特征,隐藏层单元为h=(h1,h2,…,hm),通过学习输入数据的特征自动生成。

图2 RBM结构
已知v的情况下,隐藏层节点的条件概率分布满足:

(2)
同理,在已知h的情况下,可见层节点的条件概率分布满足:
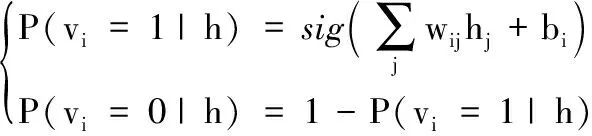
(3)
关于RBM建立的能量函数为:
(4)
其中:θ={W,b,c}为RBM的模型参数,W为可见层到隐藏层间的权值连接矩阵,b和c分别表示可见层和隐藏层上的乘性偏置。
基于能量函数,可以建立v,h的联合分布函数:

(5)
为了求得联合概率分布的最大值,更新模型参数,本文采用CD算法获取样本。首先,初始可见单元状态被设置为一个训练样本,并由初始可见层单元v学习得到第一层隐藏层单元h1,获得后验概率P(h1|v)。再由隐藏层单元h1确定每个可见单元取值为1的概率,重构获得新的可见层单元v1。接着采用梯度下降法求解参数,训练样本的梯度为:
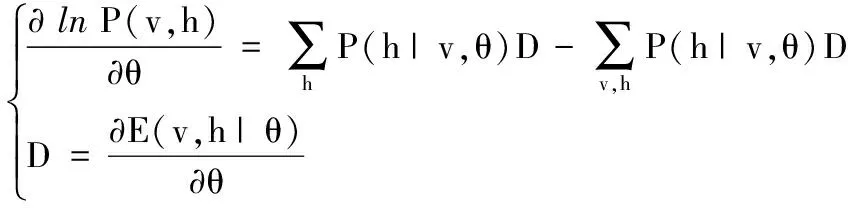
(6)
获得模型参数的更新规则:
(7)
预训练过程如算法2所示。
算法2 预训练过程。
输入:可见层特征变量v=(v1,v2,…,vm),初始权重W,乘性偏置b、c,学习率ε,迭代次数k。
输出:RBM的模型参数θ={W,b,c}。
fort=1,2,…,k
forj=1,2,…,n
fori=1,2,…,m
P(vi|h(t))
fori=1,2,…,m
forj=1,2,…n
由式(7)更新模型参数θ={W,b,c}
end
2.4 BP微调权重
BP神经网络是带监督的前馈神经网络[19],有监督的训练经过预训练的DBN模型,利用输出误差自顶向下地估计每一层RBM的传播误差,获得更优的模型参数。BP微调权重过程如算法3所示。
算法3 BP微调权重过程。
输入:可见层特征变量v=(v1,v2,…,vm),预训练得到的模型参数θ={W,b,c},迭代次数k,学习率ε。
输出:微调后的模型参数θ={W,b,c}。
fort=1,2,…,k
对所有vi的输出单元oi,计算其误差梯度σi(ei为期望输出):
σi=oi(1-oi)(ei-oi)
(8)
对所有隐藏层单元hj,计算其误差梯度σj,并更新模型参数θ:
(9)
(10)
end
2.5 softmax分类器
测试数据集中有五种用户数据状态[20-21],分别为正常状态(Normal)、拒绝服务(Denial of Service, DoS)攻击、远程未授权(Remote to Local, R2L)攻击、提权(User to Root, U2R)攻击、端口扫描(Probing),依序标记为1~5,如表1所示。
由表1可知,数据集中有多类用户数据状态,而softmax分类器能够适应多分类问题,且相较于SVM等分类器结构简单,因此,构建一个softmax分类器,对训练后获得的较优低维表示的数据进行分类。
如式(11)所示,对测试数据集进行五种用户数据状态的识别:
(11)
其中:θ′={W′,b′}为模型参数,W′表示权值矩阵,b′表示加性偏置。

表1 测试数据集分布
将要分类的较优低维数据x′输入到一套超平面中,每个超平面代表一个类,以输入的数据到第j类超平面的距离表示该数据属于第j类的概率,概率最大的类即为数据的所属类别:
P(y=j|x(i),θ′)=softmaxj(W′x′(i)+b′)
(12)
3 实验验证
3.1 数据预处理
本文采用KDD 1999数据集[22]作为测试数据集。该数据集中的每一项数据共有41项特征属性和1项标签属性,特征属性包括传输控制协议(Transmission Control Protocol, TCP)基本连接特征(No.1~No.9)、TCP连接的内容特征(No.10~No.22)、基于时间的网络流量特征(No.23~No.31)以及基于主机的网络流量统计特征(No.32~No.41),特征属性的类型分别为连续型(Continuous, C)和离散型(Symbolic, S)[23],如表2所示。实验所选取的数据集如表3所示。

表2 数据集特征
数据预处理分3个步骤。
1)降低数据集的不平衡度。
由表3可知,KDD 1999数据集的数据状态分布很不均衡,训练集中样本U2R的数量远小于DoS和Normal的样本数,因此,本文采用SMOTE技术,将U2R的样本数增大至原来的10倍,以均衡样本数。
2)字符型特征数值化。
用属性映射法将字符型特征数据数值化,分别为TCP、用户数据报协议(User Datagram Protocol, UDP)、网际控制报文协议(Internet Control Message Protocol, ICMP),如表4所示。
3)数据型特征归一化。
将数值化后的数据取对数,再根据式(13)归一化到[0,1]区间内:
y=(y-min)/(max-min)
(13)
其中:y为属性值,min为对应特征属性的最小值,max为对应特征属性的最大值。
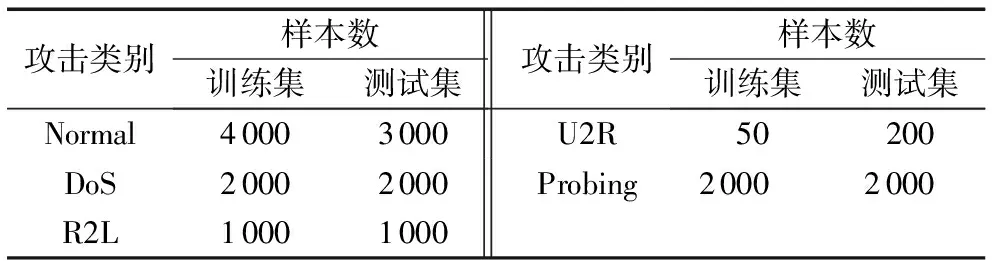
表3 实验数据集

表4 字符型特征数值化
3.2 实验评价标准
评价标准定义如下。
TP(True Positive):样本正确判断为正类的样本数。
TN(True Negative):样本正确判断为负类的样本数。
FP(False Positive):样本错误判断为负类的实际正类样本数。
FN(False Negative):样本错误判断为正类的实际负类样本数。
则检测率(Detection Rate, DR)、误报率(False Alarm, FA)、精确率(Accuracy, AC)分别如下:
DR=TN/(TN+FN)
(14)
FA=FP/(TP+FP)
(15)
AC=(TP+TN)/(TP+FP+TN+FN)
(16)
3.3 实验分析
实验环境:Windows 7 (64位)操作系统,Intel Core i5- 5200U CPU @2.2 GHz,4 GB RBM,Python3.5。
实验内容:
1)设置实验参数。
2)在相同分类方法的基础上验证SMOTE技术对异常入侵检测的影响。
3)在相同数据集上分析不同分类技术对异常入侵检测的影响。
3.3.1 实验参数设置
实验过程中,用DBN对选取的数据集进行训练,由于DBN的参数设置会影响到模型的训练结果,根据文献[24-25]对模型的部分参数进行了设置,训练参数如表5所示,同时通过固定参数,验证了微调的迭代次数对检测率结果的影响,如图3所示。
由图3可知,当迭代次数大于100时,精确率曲线逐渐趋于平缓。为了避免过拟合,后续实验中选取微调的迭代次数为100。
3.3.2 SMOTE算法的有效性验证
为了验证SMOTE算法的有效性,将经过SMOTE技术处理前后的数据集在DBN算法上进行验证。实验结果表明,经过SMOTE预处理的数据集相较于未经过SMOTE的数据集在精确率方面提高了2.01个百分点,检测率结果如图4所示,DoS的检测率有所降低,但是对少数类样本U2R的检测率有明显提高,其他类别样本的检测率与未经过SMOTE处理的数据集检测率相当。

表5 实验参数

图3 精确率随微调迭代次数的变化

图4 SMOTE处理前后检测率对比
3.3.3 对比实验
将SMOTE-DBN方法与DBN和SVM方法在相同数据集上进行对比实验,如表6所示,SMOTE-DBN方法的检测率相对略高于DBN和SVM方法,且在误报率方面相对较低。

表6 SMOTE-DBN与DBN、SVM实验结果对比 %
4 结语
本文提出了一种基于SMOTE和深度信念网络的异常检测方法,提高了入侵检测的数据分析能力。通过SMOTE处理技术,均衡化非均衡数据集,在一定程度上解决了分类器倾向于将用户数据归类到多数类类别样本的问题。同时结合softmax算法改进了DBN算法,并与DBN和SVM方法进行对比实验。实验结果表明,SMOTE-DBN算法的性能相对较优,对高维数据有很强的特征提取能力和信息识别能力,可应用于网络分布复杂的环境下;但DBN中的结构参数为人工设置,不一定是最优的网络结构,因此如何选取合理的网络参数是下一步解决的问题。
