结合代价敏感半监督集成学习的糖尿病视网膜病变分级
2018-08-27任福龙赵大哲
任福龙,曹 鹏,万 超,赵大哲
(1.东北大学 计算机科学与工程学院,沈阳 110089; 2.东北大学 软件架构国家重点实验室,沈阳 110179;3.中国医科大学附属第一医院 眼科,沈阳 110001)(*通信作者电子邮箱hundred2005@126.com)
0 引言
近年来糖尿病已发展成为世界流行的重大疾病,而糖尿病视网膜病变(Diabetic Retinopathy, DR)(简称糖网)是糖尿病最为严重的并发症之一。糖网以其发病早、发病率高、波及广,已成为西方国家成年人致盲的首位原因[1]。目前我国约有1亿人正受到糖尿病的威胁,由糖尿病引起的视力下降和失明的发病率正与日俱增。临床上,糖网的早期病变可通过眼底图像中视网膜病变的医学征兆进行检测,而对于糖尿病患者而言,尽早的诊断和治疗是控制糖网病情发展的关键,因此,利用眼底图像进行及早的、定期的糖网筛查是防治糖网病变的唯一有效手段。
糖尿病患者由于长期的血糖过高,导致视网膜毛细血管形状和结构发生改变,毛细血管壁因受损造成膨出从而形成微动脉瘤(MicroAneurysms, MAs)。MAs作为糖网最早期的病变表现,在眼底图像中表现为红色小圆点,直径在10~100 μm,也是眼底图像上能观测到的最小病变。而之后下一个呈现的病变是出血斑(Hemorrhages, HEMs)。HEMs是脆弱的毛细血管破裂所致,在眼底表现为灰度不均匀、大小不一的红或暗红色区域,其直径一般大于125 μm[2],这也是与MAs的主要区分特征。MAs和HEMs统称为红色病灶[3],图1显示一幅标记眼底结构和红色病灶的图像实例。在糖网的临床分级标准中,红色病灶作为糖网早期的病灶,它们的出现与否以及数目决定了疾病的严重级别,因此,糖网分级的准确性主要依赖于红色病灶检测的精度。近年来,针对糖网的自动分级诊断,国内外许多学者进行了研究并提出相关算法[3-6]。尽管达到了较高的敏感性,但由于病灶在眼底图像上呈现的尺寸差异、对比度差以及部分组织(如血管片段等)在颜色特征和形状特征方面与红色病灶很相似,而易被误解为病变区域等因素,造成病变的检测中不可避免地产生了大量的假阳性,如何降低假阳性一直是病变检测中的难点。在解决糖网检测假阳性过多的过程中,有两个关键问题亟待解决。
1)标注信息不完备。
假阳性去除的通常方法是利用有标记的样本构建监督学习的分类模型,来有效区分真假阳性;但现有的糖网公开数据集存在标注信息不完备的问题。如DIARETDB1(http://www.it.lut.fi/project/imageret/diaretdb1)数据集只有病灶标注却缺失糖网分级信息,而MESSIDOR(http://messidor.crihan.fr/index-en.php)数据集只提供了糖网分级信息,并没有提供病灶的标注。由于不同的数据集采集方式、采集来源等因素差异,如果利用其他有病灶标注的数据集构建监督性的分类模型,对MESSIDOR数据集产生的疑似病灶区域进行分类,将会面临不同数据集的数据分布不一致的问题,很难达到很高的准确率。
2)类别分布不均衡。
初始检测产生的疑似病灶区域的正负类别的样本数量存在差异,又会面临不均衡数据的分类问题[7],造成分类模型倾向于多数类别的预测而忽略少数类别,最终也会影响分类器的分类性能。
半监督学习[8-9]允许训练集和目标集的样本之间存在差异,能够利用训练数据中有类别标记的样本和无类别标记的样本进行训练,有效地预测训练数据中无类别标记样本的类标记;而基于代价敏感的分类模型是解决不平衡数据分类问题的一种有效手段,它在分类时为不同类别的错误分配不同的代价,使高代价错误产生的数量和错误分类的代价总和最小[10]。此外,单一分类模型很难实现在整个样本空间上的准确分类,研究表明半监督集成学习充分利用了集成学习的优势,能明显改进单一分类器的性能,让每一个分类模型都在其优势空间区域内发挥作用,提高模型的准确性[11-13]。综合以上思路,本文将半监督学习技术与代价敏感的方法相结合,并引入到集成学习的Bagging框架中以提高算法的泛化能力和精准性,最终构建基于代价敏感的半监督Bagging(Cost-Sensitive based Semi-supervised Bagging, CS-SemiBagging)模型。通过对MESSIDOR数据集提供的1 200幅眼底图像进行糖网分级评估,获得准确率为90.2%,敏感性为87.4%,特异性为96.7%,F1-score为0.873的结果。结果表明了本文提出的方法在糖网分级中的有效性。
1 基于代价敏感的半监督Bagging模型
在样本类别分布不平衡的环境下,本文研究的基于代价敏感的半监督Bagging模型的构建流程如图2所示。整个流程主要包括3个阶段:1)建立基于代价敏感的支持向量机模型作为基分类器;2)利用半监督技术预测无标记样本的伪类别标记,并基于高置信度的策略进行采样;3)以Bagging方式构建多个不同的训练样本集,分别在其上训练多个基分类器,将各基分类器集成为强分类器,并通过投票方式得到最终的分类结果。
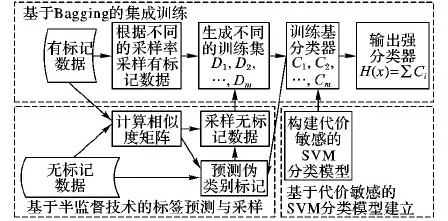
图2 CS-SemiBagging模型的构建流程
1.1 基于代价敏感的SVM分类模型
近年来,由类别分布不均衡数据的分类而引发的不平衡学习问题已成为了机器学习领域中的一个重要研究内容。本文采用基于代价敏感的支持向量机(Cost Sensitive Support Vector Machine, CS-SVM)作为集成学习中的基分类器。支持向量机是机器学习领域中解决非线性分类问题的一种有效手段,其目标函数为:
(1)
s.t.yi[(wTxi)+b]≥1-ξi;i=1,2,…,N,ξi≥0
其中:ξi为松弛因子,惩罚系数C>0。传统SVM是基于所有类被错分的代价相等。为了提高不均衡数据下分类器的性能,采用不同的惩罚参数C+和C-代替原来的参数C,使得分类时针对不同的类别采用不同的错分代价以提高少数类别的识别能力,则式(1)可转化为:
(2)
s.t.yi[(wTxi)+b]≥1-ξi,i=1,2,…,N,ξi≥0
其中:C+为正类误分的代价,C-为负类误分的代价。重新设置参数C+和C-,令C-=C,C+=C×Cf,其中,C为SVM的惩罚参数,Cf为错分代价因子,则式(2)变为:
(3)
s.t.yi[(wTxi)+b]≥1-ξi;i=1,2,…,N,ξi≥0
通过求其对偶问题:
(4)

(5)
其中k(xi,x)=exp(γ‖xi-xj‖2)作为高斯核函数,γ为核参数。
1.2 基于半监督技术的标签预测与采样
半监督学习能够在保持数据样本分布的情况下对未标记样本进行标记。在半监督学习中,给无标注样本分类常常遵循两个准则:1)无标记样本的类别一定与其相似度高的标记样本的类别一致;2)相似度高的无标记样本一定属于相同的类别[12]。基于这两个准则,本文在给无标记样本分类时,通过准则1)在样本空间与其最相似的K个有标记样本,以及准则2)在决策空间与其最相似的K个无标记样本的分类一致性来决定无标记样本的伪类别标记。通过衡量无标记样本与有标记样本的相似度来判断无标记样本的类别标记,同时计算无标记样本的置信度,选取高置信度的无标记样本,可避免或减缓在半监督学习中错误地标记样本对分类器分类性能的影响。

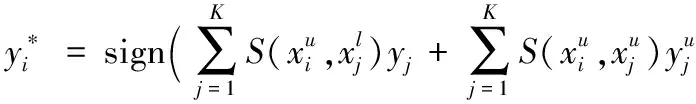
(6)

(7)

1.3 基于Bagging的集成学习框架
Bagging方法是一种通过组合随机生成的训练集而改进分类的集成算法,它通过随机采样方式抽取训练子集,从而构造多个基分类器,最终组合生成强分类器。Bagging作为一种集成学习方法,要求各基分类器之间尽可能相互独立,并且各基分类器之间尽可能有较大的差异[14],因此,本文通过变化训练集中有标记样本数量来增加基分类器间的差异,即在不同采样率lp下对有标记样本进行bootstrap采样,并与训练集中的无标记样本一起进行半监督训练,将训练得到的多个基分类器组合为强分类器,并使用多数投票法得到最终的分类结果。
本文CS-SemiBagging算法流程描述如下。
1)样本的采样率LP={lp1,lp2,…,lpM},近邻参数K,U中被采样加入到标记样本集的样本占U中全部样本的比率Tup,其可作为半监督学习收敛的条件。


4)form=1,2,…,M

②Repeat

表1 MESSIDOR的糖网分级标准
2 实验验证
2.1 实验设置
为了验证本文方法在眼底图像上糖网分级的效果,本文选用两个国际公开的数据集:DIARETDB1和MESSIDOR数据集。DIARETDB1数据集包含了89幅分辨率为1 500×1 152的眼底图像,每幅图像都提供了糖网的病灶标注(包括微动脉瘤、出血斑、棉絮斑和硬性渗出),这个数据集主要作为红色病灶分类实验中有标记样本的来源;而MESSIDOR数据集用于糖网分级结果的验证,它提供了糖网分级标准(分为4级,如表1所示),包含了分辨率分别为1 400×960、2 240×1 488和2 304×1 536的1 200幅眼底图像。其中:0级的图像有547幅,1级图像有153幅,2级图像有246幅,3级图像有254幅。为了评估算法的性能,本文采用了准确率(Accuracy)、敏感性(Sensitivity)、特异性(Specificity)以及F1分数(F1-score)4种评价指标,并采用10倍交叉验证进行评估。评价指标通过真阳(True Positive, TP)、假阳(False Positive, FP)、真阴(True Negative, TN)、假阴(False Negative, FN)、精度(Precision, P)和召回率(Recall, R)进行计算,具体定义如下:
Sensitivity=TP/(TP+FN)
Specificity=TN/(TN+FP)
Accuracy=(TP+TN)/(TP+FP+TN+FN)
F1-score=2*P*R/(P+R)
P=TP/(TP+FP)
R=TP/(TP+FN)
如果疑似病灶区域50%以上的像素落在参考标准的区域内,则被认为真阳。在CS-SemiBagging模型中惩罚参数C设为10,代价因子Cf设为正负样本的数量比例,核函数中的γ设为1,有标记样本的采样率LP={30%,40%,50%,60%,70%,80%,90%,100%},而近邻参数K和无标记样本采样率Tup均采用内部交叉验证得到其最优值作为最终参数值。

表2 特征列表
2.2 疑似病灶检测及特征提取
图3为在DIARETDB1数据集上进行红色病灶检测的例子,图中的白色圆圈表示病灶的参考标准。由于红色病灶和血管在绿色通道图像中具有较好的对比度,所以将原始灰度图像(如图3(a))转换为绿色通道的灰度图像(如图3(b))。基于绿色通道的灰度图像,采用之前工作中的图像处理方法[7],包括Top-hat变换方法、高斯滤波、区域生长等一系列操作,获得主要的血管分割结果(如图3(c))和疑似病灶区域(如图3(d))。
为了获得具有足够区分度的特征来描述疑似病灶区域,本文从颜色、形状和纹理方面对每个疑似病灶的感兴趣区域(Region Of Interest, ROI)提取多维(22维)特征(如表2所示)。由于微动脉瘤和出血斑等红色病灶在眼底图像上表现为红色或暗红色,其在绿色通道图像上具有更高的亮度值和对比度,并且由于LAB色彩空间的亮度信息分离度高于其他色彩空间,LAB色彩空间的A通道表示从红色到绿色的信息范围,其上红色的病灶也体现了较高的亮度值,所以特征f1到f12分别从RGB、绿色通道和LAB的A通道图像上提取ROI的颜色特征,以增加红色病灶的区分度。特征f13到f17体现了微动脉瘤的形状信息,真正的微动脉瘤的形状上近似圆形,其外接矩形的长轴和短轴更加接近,并具有更高的紧凑度,此外,微动脉瘤的直径在100 μm左右,而出血斑的直径要大于125 μm,因此,ROI的面积特征能够更好地区分微动脉瘤与出血斑。特征f18到f22描述红色病灶的纹理信息,眼底图像上暗色的红色病灶区域一般具有相对明显的边界,其边界上具有较高的梯度值,并且区域内部具有较小的灰度变化,其外接矩形内具有较低的熵值。
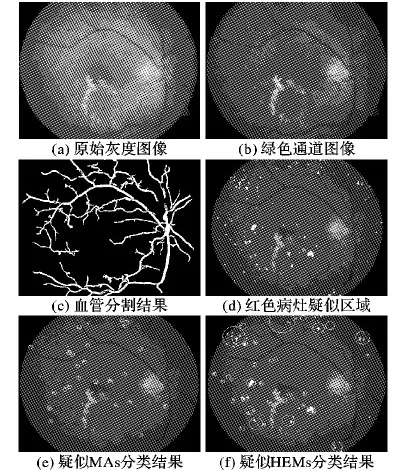
图3 红色病灶的检测
2.3 病灶分类与糖网分级
在对每个疑似病灶区域提取底层视觉特征后,构建本文提出的CS-SemiBagging模型,并训练优化模型进行病灶的分类,在具体的MAs与HEMs的分类上,本文采用了两阶段二分类的策略(如图4所示),在第一阶段中将疑似病灶区域分类为红色病灶与非病灶区域,以去除假阳性,第二阶段中将红色病灶分类为MAs与HEMs,图3(e)和图3(f)分别为MAs与HEMs的检测结果。最终依据MAs与HEMs的数目并参照糖网分级的标准(如表1)进行糖网分级。
2.4 模型参数有效性验证
在CS-SemiBagging模型中,需要对近邻参数K和无标记样本采样率Tup进行参数调优和有效性验证。
2.4.1 近邻参数K对性能的影响
参数K表示在模型的每一次半监督学习的迭代过程中,计算每个无标记样本的相似度矩阵时选取的近邻数。本文分别令K=5,10,15,20,25,并暂时令Tup=50%,K值的选择与糖网分级的性能之间的关系如图5所示。实验表明:随着K值的增加,模型的分类性能会先提升再下降,最后趋于平稳。这是因为K值的增加使选取的无标记样本的近邻样本数增多,则根据样本的置信度和伪类别标注的计算公式,样本置信度的可信度得到提升的同时,样本被错误标记的可能性也逐渐减小,因此,模型的分类性能会升高。由于近邻样本数的增加也会引入噪声数据,当噪声数据达到一定量时,导致了样本的伪类别标注的准确度和置信度的可信度下降,进而降低了模型的分类性能。另外,由于实验中无标记样本采样率Tup不变,即引入训练中的无标记样本的数量一定,所以当K值达到一定数值后,模型的性能不会再有大的变化。实验中K值在10时获得最优的结果。
图4 微动脉瘤与出血斑的分类
2.4.2 参数Tup对性能的影响
参数Tup表示训练集的U中被采样加入到标记样本集的样本占U中全部样本的比率,其也是半监督迭代训练中模型的收敛条件。本文实验中分别令Tup=30%,40%,50%,60%,70%,80%,90%,同时设置K值为10。实验结果如图6所示。实验表明:Tup值的增加,即目标数据集中参与模型训练的样本数目的增加,也就会相应地提升目标数据集的分类性能,但由于不同数据集之间的差异,当被采样的无标记样本的总数目增加到一定量后,样本的伪类别被错误标注的可能性将增加,同时样本置信度的可信度也会下降,也就导致了模型的分类性能的下降。实验中Tup值在70%时获得最优的性能。
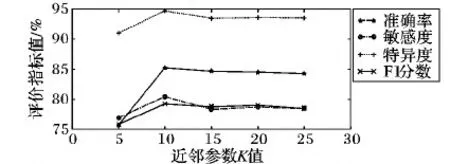
图5 不同K值下CS-SemiBagging算法的性能

图6 不同Tup值下CS-SemiBagging算法的性能
2.4.3 分类结果
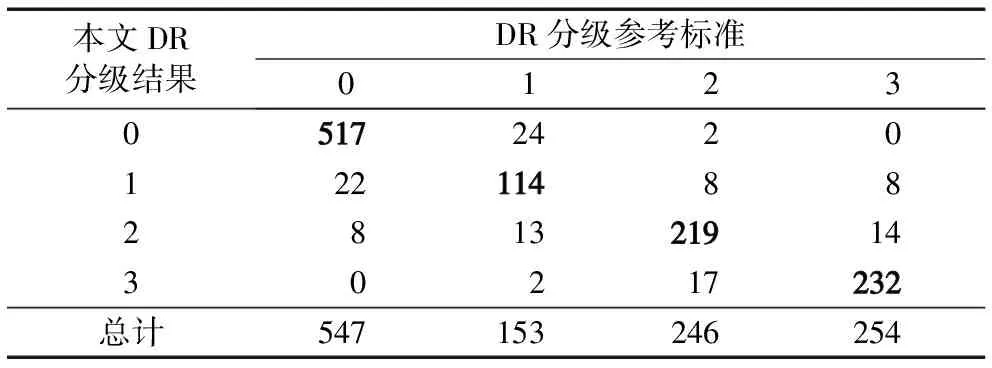
图7显示了在患有糖网的眼底图像上病灶(微动脉瘤和出血斑的)的检测结果,其中白色圆圈标记了检测到的微动脉瘤的位置,白色矩形标记了检测到的出血斑的位置。从检测结果中可以观察到一些比较小的和邻近血管的病灶都得到了很好的识别。在MESSIDOR数据集的1 200幅图像上得到的糖网分级的详细结果如表3所示。结果显示虽然糖网0级的图像所占总图像数目的比例较高,但由于引入代价敏感的方法,使得实验结果没有严重地向糖网0级进行倾向。

图7 糖网图像上红色病灶的检测结果
Tab. 3 Results of DR grading on MESSIDOR dataset
为了比较本文的CS-SemiBagging方法与其他方法的性能,分别选择了监督学习中的SVM和CS-SVM方法,以及半监督学习中的Self-training和Co-training方法进行测试,其中两个半监督方法的基分类器均采用CS-SVM,其相关参数设置与CS-SemiBagging模型中的设置相同。此外,测试中也选择了基于Radon变换的图像分类方法[3]与本文方法进行比较,通过Radon变换可以计算图像在某个角度下径向线方向的投影,进而利用Radon变换数据标准差的差异来区分图像上的线状目标(血管片段)和点块状目标(微动脉瘤或出血斑)。各方法性能比较的结果如表4所示,从表4中可以看出基于机器学习的方法要好于Radon变换的图像分类方法,这是由于红色病灶在颜色、形状、对比度等方面的多样性决定了基于多特征描述的机器学习方法要比依赖于单一形状特征描述的Radon变换方法更适合病灶假阳性的去除,如Radon变换方法对于形状不一的出血斑病灶不能达到完全有效的识别,此外,Radon变换数据标准差的阈值决定了此方法的分类精度,而不同数据集间的差异严重影响了此阈值选择的有效性,导致了此方法的性能不高。实验结果中CS-SVM的性能要好于SVM的性能,这是考虑了不均衡数据的分类问题的结果。另外,半监督学习方法的性能要好于监督学习的方法,这是由于半监督学习能够很好地解决不同数据集的数据分布不一致的问题,从而提高目标数据集分类性能的缘故。从结果中也可以看出CS-SemiBagging方法的性能要优于其他方法,这主要由于此方法除了考虑以上提到的两个问题之外,还采用了多分类器集成学习思想的缘故,实验结果也表明了本文提出的方法在糖网分级中的有效性和一定的优势。
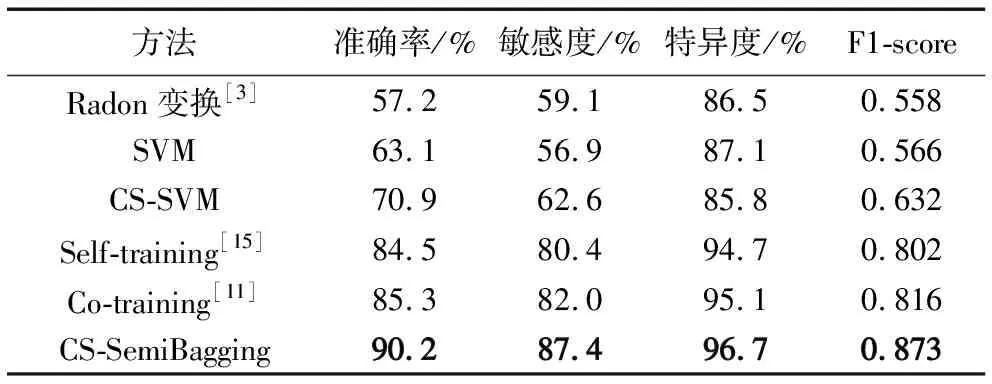
表4 不同糖网分级方法的比较
3 结语
本文在糖网的分级诊断应用中提出了基于代价敏感的半监督集成学习的算法,将半监督学习技术与代价敏感的SVM方法相结合,并融入到集成学习的Bagging框架中,提升了分类的泛化能力和精准性,进而有效地实现对眼底图像的糖网分级诊断。该算法一方面考虑了糖网病灶样本的类别分布不平衡对分类性能的影响;另一方面在半监督技术上采用K近邻样本的一致性对无标记样本进行伪类别标签的标注和置信度计算,从而大幅度降低了无标记样本采样过程中引入噪声的可能性。实验结果表明本文提出的方法能够很好地解决医学图像分类中病灶没有标注的问题和假阳性去除中存在的不均衡数据分类问题,同时获得了更好的结果。本文工作只是进行糖网病变程度的分级诊断,未来在本文研究的基础上,如何利用半监督集成学习的方法进行其他眼底疾病如糖网黄斑水肿的风险分级等,将是今后的研究重点。
