基于任务分配与调度的GSAT算法求解3-SAT问题
2018-08-23付慧敏何星星宁欣然
付慧敏,徐 扬,何星星,宁欣然
(1.西南交通大学信息科学与技术学院,四川 成都 610031;2.西南交通大学系统可信性自动验证国家地方联合工程实验室,四川 成都 610031)
1 引言
1971年Cook证明了SAT(SATisfiability)问题是NP完全问题,具有广泛的实际应用。许多学者将一些组合问题例如人工智能、超大规模集成电路VLSI(Very Large Scale Intergration)设计、积木世界规划、Job shop排工等转化为SAT问题来求解[1]。经过国内外学者的努力,求解SAT问题的优化算法已经有很多,总体分成两类:一是完备的方法,适应于应用类问题和组合问题,例如基于DPLL(Davis Putnam Logemann Loveland)的SATO(SAtisfiability Testing Optimized)[2]、BerkMin(Berkeley-Minsk)[3]、CDCL(Conflict-Driven Clause Learning)[4]等。其优点是对于任意SAT问题都能正确地判断其可满足或者不可满足,缺点是随着问题规模的不断增大,其解空间的复杂度成指数增长,计算效率很低,不适应于大规模问题[5]。二是不完备的方法,适应于随机生成问题。虽然对于任意SAT问题不能都正确地判断其可满足或者不可满足,但是对于可满足SAT问题其效率整体上超过完备的方法,因此受到很多学者的青睐,使得这种方法得以快速地发展。例如,MP(Message Passing)算法[6]、Local Search算法[7]、遗传算法[8]、不完备算法之间的结合[9,10]、组织进化算法[11]、多智能体社会进化算法[5]、GSAT算法[12,13]、完备算法和不完备算法相结合的混合算法[14]等。
GSAT算法是一个很有效的局部搜索算法,其主要的技术是贪心搜索,即通过一系列的搜索得到问题的最优解,而每一次搜索都是当前状态下某种策略的最好选择。早期在求解SAT领域中,贪心搜索很容易陷入“早熟”,Selman等人[15]用WalkGSAT的局部搜索算法跳出局部最优,大量的实验表明这个技术很适应于随机生成的3SAT问题。1998年梁东敏等人[1]在WalkGSAT的基础上,引进了子句权重的概念,实验表明其性能优于WalkGSAT,尤其对于结构SAT问题。2002年林智勇等人[16]提出的Learning+Weighting+GSAT算法和2010年Bouhmala等人[17]提出的LA-GSATRW算法都是在GSAT算法的基础上进行了改进,但是其优势不是很明显。2015年张玉安等人[8]将局部搜索的GSAT算法与具有全局搜索的改进遗传算法相结合,明显弥补了GSAT算法容易出现早熟的缺点,该算法的实验结果表明其性能得到了明显提高。虽然近几年贪心搜索在SAT领域的研究学者并不多,但是在其他一些领域得到了快速的发展与应用,例如组合优化问题[18]、风机布局优化[19]、优化贪心算法[20,21]、自动车辆群内的信息传播[22]等等,所以贪心算法具有一定的使用价值和研究意义。2004年刘静等人[11]将组织进化的思想用到求解3-SAT问题上,而且根据SAT问题的特点重新定义了组织的概念,并根据组织和SAT问题的特点提出了新的算子;2014年潘晓英等人[5]的多智能体社会进化算法,将智能体对环境的感知能力的思想用到求解SAT问题上,而且根据SAT问题的特点重新定义了智能体的概念,并根据智能体的行为和SAT问题的特点提出了新的3种行为,对于3-SAT问题这两种算法的性能都得到了显著提高。
为了进一步提高GSAT算法的效率,即提高贪心算法的性能,本文根据组织进化算法、多智能体社会进化算法和李炳芬等人弥补GSAT算法具有局部搜索的缺点的思想,在Weighting+WalkGSAT的基础上,将任务分配与调度的主要目的与3-SAT问题的特点相结合,并重新定义了任务分配与调度的概念,提出了基于任务分配与调度的GSAT算法求解3-SAT问题。在文献[23,24]中,任务分别指的是数据并行交换和用户提交的需求,本文算法的任务指的是3-SAT问题中的所有变量,与文献[23,24]中的定义完全不同;而且分配与调度的概念与文献[23,24]中的概念也完全不同,文献[23]中的分配与调度是根据任务的特点和每个影响因素决定任务的顺序,文献[24]中的分配与调度是通过不同的分配策略和调度策略合理高效地处理用户提交的任务,通过任务分配与调度的思想,他们都取得了很好的效果。不仅文献[23,24]中的作者使用分配与调度,而且许多领域的国内外研究人员[25 - 28]都用到了这种思想,他们的目的都是为了高效地完成任务。本文的分配与调度是在搜索最优真值指派的过程中所用到的策略。在该算法中,与传统的GSAT算法不同,根据任务的特点和分配与调度的思想设计了新的贪心策略。实验结果表明,本文算法能更快地跳出局部最优,减少翻转次数,提高成功率,具有一定的使用价值。
2 3-SAT问题及其表示
3-SAT问题是可满足性问题,寻找一个给定的布尔值公式是否可满足[29]。在本节中,首先定义一些相关概念,然后精确定义3-SAT问题。
定义1真值指派(Value-Assignment)[29]:用符号Xn表示n个布尔变量的集合,xi,i∈{1,2,…,n}表示布尔变量,则Xn={x1,x2,…,xn}。n个布尔变量的真值指派是一个函数v:{x1,x2,…,xn}→{0,1},其中每个布尔变量x1,x2,…,xn都被指派为1或0,1表示真,0表示假。在本文的算法中1表示真,-1表示假。
定义2文字(Literal)[29]:每个文字是一个布尔变量或者一个布尔变量的否定,分别表示为xi或者xi(xi的非),被分别称为正文字和负文字,其中i∈{1,2,…,n}。
定义3子句(Clause):m个子句的集合表示为:Cm={c1,c2,…,cm},每个子句ci由3个文字的析取(∨)组成[29,30]。若文字xi出现在Cm中且xi不出现在Cm中,则称文字xi为纯文字。
定义4合取范式(CNF):每个合取范式由若干子句的合取(∧)组成,形如F=c1∧c2∧…∧cm。
合取范式F在真值指派下为真当且仅当每个子句c1,c2,…,cm在真值指派下都为真[5]。
3-SAT问题就是∀ck∈F,k∈{1,2,…,m},是否存在一个真值指派使F为真,若存在这样的真值指派,则称3-SAT问题可解决[29]。
3 基于任务分配与调度的GSAT算法
3.1 求解3-SAT问题的任务定义
定义5任务i是布尔变量集合Xn中的一个变量xi,i∈{1,2,…,n},任务的取值只有两种,分别为真和假。
子句ck权重记为Weight(ck),k∈{1,2,…,m},这里的权重与Weighting+WalkGSAT的权重定义相同。根据对任务的赋值,包含该任务的子句有两种—取值为真的子句称为可满足子句,取值为假的子句称为不可满足子句;包含该任务的子句权重有两种—取值为真的子句其权重称为可满足子句权重,取值为假的子句其权重称为不可满足子句权重;包含该任务的不可满足子句权重有两种,分别是翻转该任务前称为前不可满足子句权重和翻转该任务后称为后不可满足子句权重。本文的大任务指所有任务的集合,即包含问题的所有变量,与文献[31]中的类似。任务贪心搜索是大任务的前不可满足子句权重之和与后不可满足子句权重之和的差达到最大,若这个差值的最大值(记为best_Diff)不小于0,则进行翻转[16]。
在搜索最优真值指派的过程中,每个任务在当前真值指派下需要记录一些信息,一个任务i的结构表达如下:
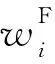
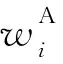
任务贪心搜索策略:记录该任务翻转的条件,即:

best_Diff>0,k∈{1,2,…,n}
大任务规模:所有子任务的个数记为Size,即Size=n。
从任务的结构可以看出,一个任务就是原问题的一个变量,而当该任务达到搜索策略要求时,翻转这个任务,使得假子句权重之和减少,真子句权重之和增加,同时通过增加不可满足子句的权重提高了假子句为真的几率,加快搜索的进程。当假子句权重之和减少到0时,该变量就找到了一个解。显然,当假子句权重之和为0的任务集合等于大任务规模时,就得到大任务的一个最优解。因此,要解决原问题,就要解决含有所有子句的大任务,这就要使不同任务间进行相互作用。
任务分配与调度问题是NP完全问题[32]。本文并不关心如何分成适当的子任务,如何将子任务分配给各个处理机,如何安排子任务的执行顺序,而是将重点放在子任务的相互作用上。任务分配与调度的主要目的是为了寻找一个合适的分配调度,使得任务执行结束后所花费的时间尽量地小。受此启发,我们另外设计了两种任务贪心策略来引导任务的完成。
3.2 贪心策略
本文的另外两种任务贪心策略分别为分配策略和调度策略。分配策略是提前指导任务贪心搜索的趋势,它利用原问题本身的信息进行贪心指派任务,本质是减少搜索空间,实际上起到快速找到最优解的作用。调度策略是当不能满足任务贪心搜索策略条件时,起用调度策略决定翻转的子任务,有效地防止搜索陷入局部最优,加快搜索进程。
3.2.1 如何任务分配
在SATLAB库[33]中,“Uniform Random-3-SAT”问题集共有3 700个3-SAT问题,文献[5,11]表明该问题集已经被大量用于测试求解SAT问题算法的性能,这些问题的子句个数和变量个数之比均为4.3左右,此类问题属于不可满足和可满足的概率几乎是相等的,属于难解的一类问题集,所以通过测试这些问题更能反映出算法性能的优越性。根据变量的个数可以将这3 700个问题分成10个集合,分别记为S1,S2,…,S10,以下通过表1给出这10个集合所包含的问题和相应的参数。

Table 1 Uniform Random-3-SAT problems in experiments
SAT问题类似数学约束问题,所以我们可以先分析问题库中变量之间的关系以及SAT问题的解空间,然后分配一些变量的真值指派,最后通过算法搜索加快解的进程。通过分析SATLAB库中的每个问题集和每个问题集所对应的解可以发现,最优的真值指派T与问题集中的每个布尔变量的正负比例值有关,即当某个布尔变量的正负比例值大于某个恰当的数或者小于某个合适的数时,此布尔变量的最优真值指派直接确定为真或者假的成功率是90%左右。在GSAT类算法和其他类解决SAT问题的不完备算法中,它们大多数都是通过随机产生一个真值指派作为搜索的起点[34]。若一个问题的布尔变量个数为n且只有一个最优真值指派,则随机产生的真值指派有2n种情况且一次产生最优真值指派的概率为1/2n。在2n种情况中,我们的想法是通过每个布尔变量的正负比例值分配一个求解3-SAT问题的初始指派,即提前指导最优真值指派搜索的趋势,从而加快找到最优解。这种利用每个问题集中每个布尔变量的正负文字比例值确定初始指派的想法,叫做“分配”,以下定义给出了本文算法中所使用的公式。
定义6变量分配度Vad(Variable allocation degree),∀i∈{1,2,…,n},它的变量分配度等于:
(1)
其中,在一个3-SAT问题中,pi为所有子句中含有正文字i的总个数,ni为所有子句中含有负文字i的总个数(问题集中负文字的形式为-i),当Vad(i)≥1时,称为i的正变量分配度,当Vad(i)<1时,称为i的负变量分配度。pad(positive variable allocation degree)为正变量分配度参数,nad(negative variable allocation degree)为负变量分配度参数。在求解3-SAT问题的过程中,不同的变量分配度参数值对于算法的性能有着直接的影响,在时间运行上,甚至会相差10倍以上,而且也会影响解的成功率。
定义7变量分配值Vav(Variable allocation value),∀i∈1,2,…,n,它的变量分配值等于:

(2)

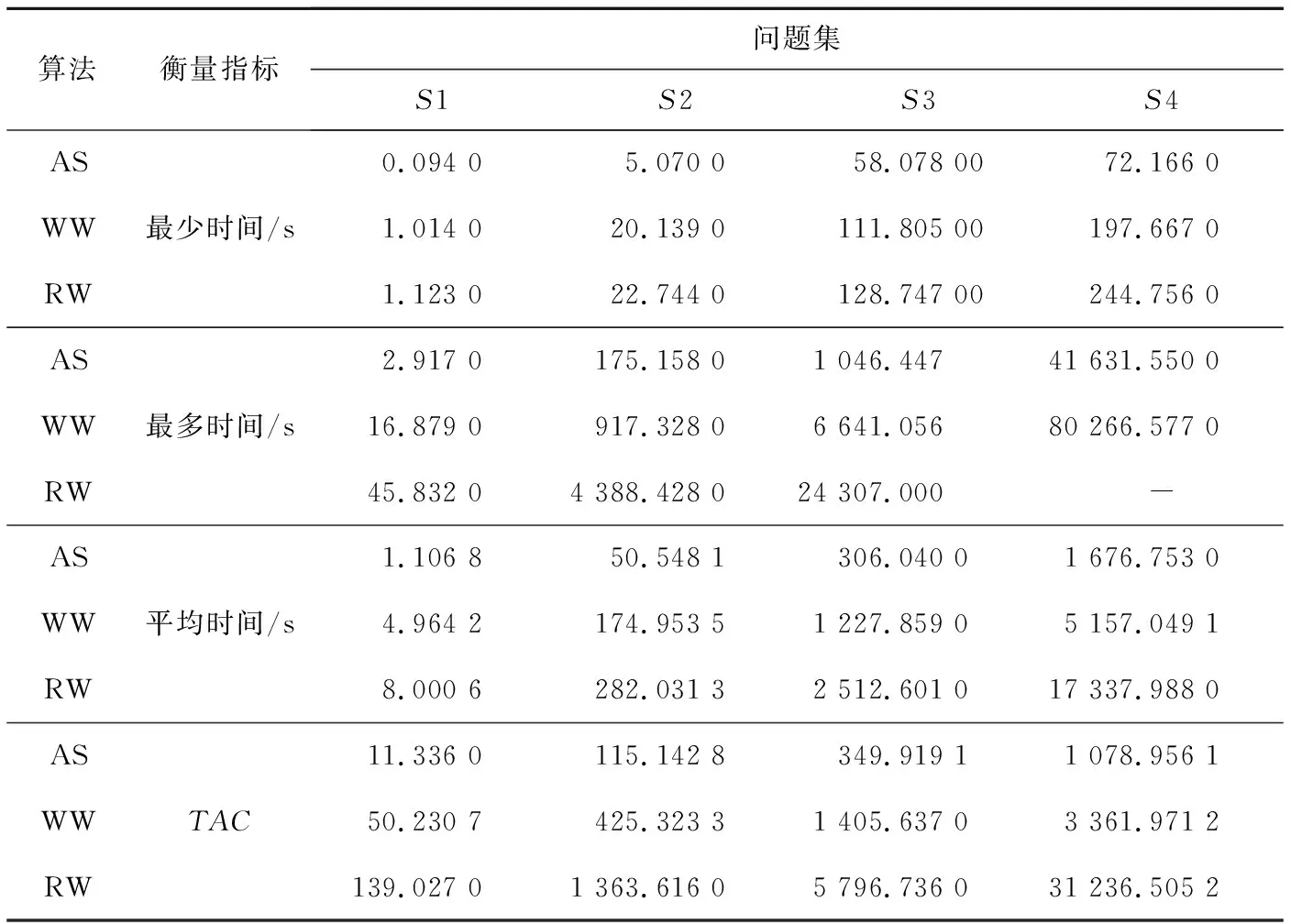
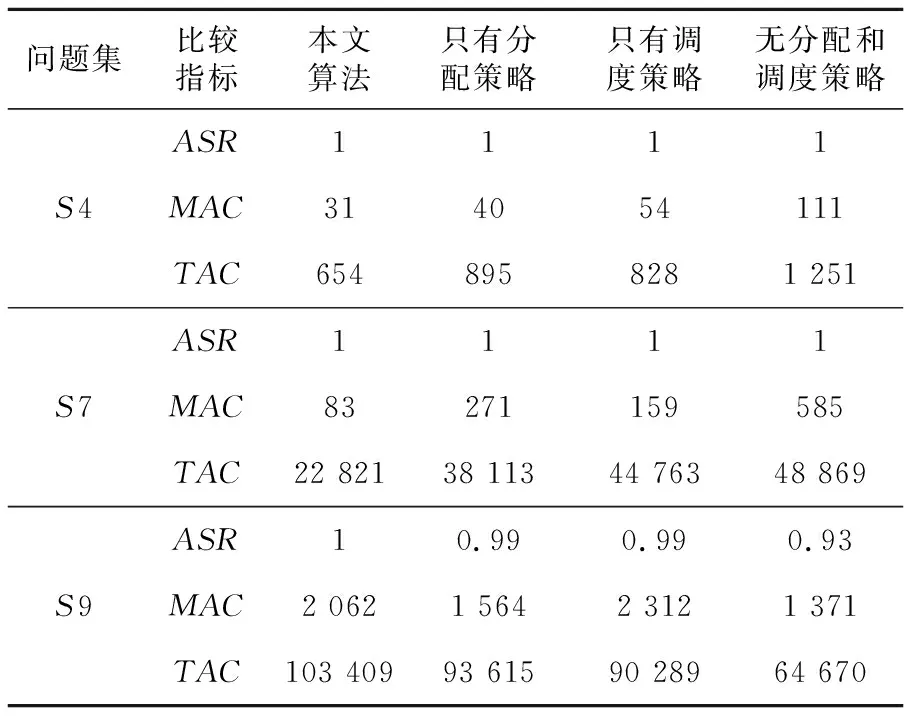
Vad(i)>pad或者Vad(i) (3) 若任务不满足分配策略,则其变量分配值是由随机数决定的。通过变量分配度的定义我们可以发现,当ni=0或者pi=0时,i一定满足分配策略,因为此时的i或者-i为纯文字,在搜索最优真值指派的过程中,只需要将i或者-i的变量分配值为1或者-1,若此情况对i或者-i进行翻转,不会使不可满足子句的总和减少。因此,通过分配策略缩小了搜索空间。 定义8满足度Sd(Satisfaction degree),是在一个3-SAT问题中满足分配策略的任务在大任务中所占的比例 ,即: (4) 3.2.2 分配的直观解释 子句集C4={x1∨x3∨x4,x1∨x2∨x4,x2∨x3∨x4,x2∨x3∨x4},若nad=0.3,则分别通过计算各个任务所对应的分配度、分配值、分配真值和满足度,得到任务的分配流程,如表2所示。 Table 2 Distribution flow sheet 表2中,x2和x4的分配值是随机产生的,而且所有变量的分配值刚好是子句集C4的一个最优真值指派。因为对分配度的定义是为了更好地提前确定容易判定的变量的最优真值指派,减少搜索过程中的翻转次数和减小搜索的解空间,因而加快算法搜索的进程。若randomf(0,1)表示产生(0,1)的随机数,Vad(N)={Vad(1),Vad(2),…,Vad(n)},Vav(N)={Vav(1),Vav(2),…,Vav(n)},则分配策略的具体算法描述如下: 算法1Allocation Strategy 步骤1读取子句集Cm; 步骤2计算所有任务的分配度Vad(N); 步骤3计算所有任务的分配值Aav(N),分配一个搜索的初始指派。 3.2.3 调度策略 算法2Scheduling Strategy 步骤1IFbest_Diff小于或等于0 THEN 从cF中随机选择一个子句cr,在该子句中随机选择一个变量task1; 步骤2IFtask1满足分配策略THEN 翻转task1。 三种任务贪心策略起着不同的作用,我们只有有序地采用上面的三种策略才能达到求解3-SAT问题的目的。在整个搜索过程中,本文算法采用贪心的方式控制任务间的相互作用。设满足任务贪心搜索策略的第一个任务记为temp,具体描述如下: 输入:各初始化参数:最大翻转次数MAXFLIPS,最大尝试次数MAXTRIES,pad,nad,pad′,nad′,子句集元素总个数,Size,p。 输出:任务的最优解或“no solution found!”。 步骤1读取子句集Cm; 步骤2计算每个任务的分配度; 步骤3所有子句的权重初始化为1; 步骤4FORi:=1toMAXTRIESDO 步骤5根据分配策略的条件,计算每个任务的分配值,作为搜索的起点;∥分配策略条件 步骤6FORj:=1toMAXFLIPSDO 步骤7产生一个[0,1)的随机数r; 步骤8IF (r 步骤9ELSE 步骤10IF(best_Diff>0)THEN 翻转temp ∥任务贪心搜索策略 步骤11ELSE 步骤12执行任务调度策略;∥调度策略 步骤13IFSizecF不等于0 THEN 从cF中随机挑选一个子句,并将它的权加1。 步骤14ENDFOR 步骤15ENDFOR 步骤16RETURN “no solution found!”; 本文的实验环境为:处理器(Intel(R) Core(TM)i5-4590 CPU @ 3.30 GHz),RAM(8.00 GB),Windows 7 64位操作系统。实验数据是SATLAB库中的“Uniform Random-3-SAT”标准问题集。因为GSAT算法容易导致早熟的缺点,自2002年以后,从文献中可以发现,很少有学者单独研究GSAT算法求解3-SAT问题,大多都是将GSAT算法与具有全局搜索的算法相结合。2002年以前比较优秀的GSAT算法有WalkSAT、Weighting+WalkGSAT和Learning+Weighting+GSAT,2002年以后在文献[17]中提到了两种新的GSAT算法LA-GSATRW和GSATRW。我们主要选择具有高性能的Weighting+WalkGSAT算法、普通性能的GSATRW算法和2016年将GSAT算法与云计算相结合的遗传算法进行比较,用于验证本文算法中分配策略和调度策略的有效性。 将本文算法、Weighting+WalkGSAT算法和GSATRW算法的最大任务(变量)改变次数都设为MAXFLIPS*MAXTRIES=107。若一次运行在规定的时间和最大变量改变次数内找到3-SAT问题的一个最优解,则此次运行成功。成功率是成功运行的次数与总运行次数之比。 实验中这三种算法每个问题独立运行10次,而且参数pad和pad′在0.3~0.6,nad和nad′在1.8~2。在表3中分别给出每个问题集中的最大平均变量改变次数、最小平均变量改变次数、总平均变量改变次数和平均成功率,其中将Weighting+WalkGSAT算法在以下表中用WW表示,本文算法用AS表示,GSATRW算法用RW表示,最小平均变量改变次数用MAC表示,总平均变量改变次数用TAC表示,平均成功率用ASR表示。 从表3中的结果可以看出,本文算法具有较好的性能。在这三种算法中,本文算法的成功率是最高的,它对SATLAB库中的8组问题集中的所有问题都能找到最优真值指派,另外两组都是只有一个问题没有完全找到最优解。与Weighting+WalkGSAT算法相比,虽然它们前7组问题集中的每一个问题都能找到解,但是本文算法比Weighting+WalkGSAT算法所需的变量改变次数明显减少,尤其MAC分别减少了6倍左右;而且对于后3组问题集,其成功率分别提高了5%左右;对于前8组问题集,本文算法都是以更少的变量改变次数得到了更好的结果;对于后2组问题集,虽然本文算法所需的变量改变次数明显增多,但是其成功率提高了6%左右。这说明Weighting+WalkGSAT算法在规定的时间内找到最优真值指派的比例明显少于本文算法,即本文算法的时间复杂度明显较低,体现了本文算法具有更好的时间性能。与GSATRW算法相比,本文算法更具有优势,其成功率分别提高了10%左右,MAC总体减少了12倍左右,TAC分别减少了5倍左右。因为算法所需变量改变次数的多少影响时间效率,所以在表中没有列举出算法花费的时间,即在成功率一样的情况下,变量改变次数越少,算法花费的时间越少。总体来说,对于前8组问题集,与另外两种算法相比本文算法都体现了较好的性能,但是对于S9和S10集合它的MAC性能较弱,仍存在一定的改进空间。 Table 3 Results comparison with other improved GSAT algorithms with 10 times running for 3-SAT problem 我们考虑到这些算法都是不完备算法,其结果有一定的随机性,即在相同实验环境下,在不同时间段内所测的结果可能会出现很大的偏差,所以为了使算法的性能比较更具有说服力,实验中对问题集中的每个问题独立运行10 000次,且参数设置与表3相同。我们考虑到一方面运行次数太多,另一方面随着变量的不断增加,解空间的复杂性也随着增加,算法所花费的时间也随着增加,其中对于含有100个变量问题集中的某个问题,本文算法需要花费10个小时左右,所以如果对10组问题集中的每个问题都运行10 000次,总共需要花费的时间至少5个月,所以实验中我们只选择了前4组问题集进行分别测试。表4分别给出了每个问题集中的最多时间、最少时间、平均时间和总平均变量改变次数。 Table 4 Results comparison with different improved GSAT algorithms with 10000 times running for 3-SAT problem 另外,求解3-SAT问题的本文算法是通过设计两种新的策略来完成整个贪心过程的,为了进一步明确两种策略在整个搜索过程中所起的作用,分别对这两种策略的性能进行了测试分析。我们在10组问题集中随机选择了3组问题集进行测试,它们分别为S4、S7和S9,然后逐一对只有分配策略、只有调度策略、无分配策略和调度策略来完成整个贪心搜索过程,其中参数设置与表3中的实验完全相同,实验结果见表5。 Table 5 Algorithm comparision 从表5的结果可以看出,分配策略对算法性能的影响比较大,若除去该策略,变量改变次数大多明显增加,所以相对花费的时间也增加,贪心策略的作用是局部搜索,而分配策略的作用是全局搜索,刚好弥补了贪心策略的不足,通过分配策略指导贪心搜索的全局方向,减小搜索空间,从而减少变量改变次数和相应的搜索时间。另外,调度策略在整个贪心搜索过程中也起到了不同程度的影响,通过调度策略防止算法陷入早熟,加快搜索的进程。 本文根据任务分配与调度的主要目的提出了一种新的求解3-SAT问题的GSAT算法,并结合3-SAT问题的特点设计了两种相应的贪心策略。实验中采用标准数据库中的3-SAT问题对算法进行了全面的测试,并与其他改进的GSAT算法进行了比较,结果表明,不管在成功率方面还是总体平均变量改变次数方面,本文算法都优于所比较的高效和普通性能改进的GSAT算法。
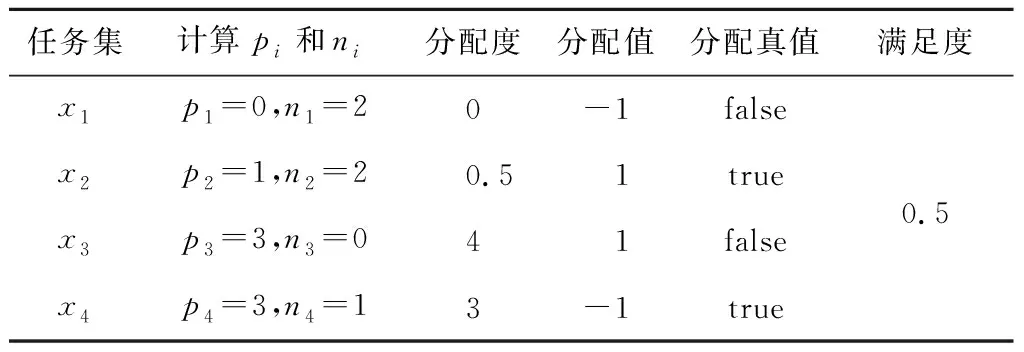
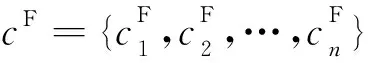
3.3 基于任务分配与调度的GSAT算法
4 仿真实验结果和分析

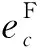
5 结束语
