投入驱动的存储与计算一体化的事务处理效率优化方法
2018-08-23段玉聪邵礼旭曹步清孙小兵齐连永
段玉聪,邵礼旭,曹步清,孙小兵,齐连永
(1.海南大学信息科学技术学院,海南 海口 570228;2.湖南科技大学计算机科学与工程学院,湖南 湘潭 411201;3.扬州大学信息工程学院,江苏 扬州 225127;4.曲阜师范大学信息科技与工程学院,山东 济宁 276826)
1 引言
知识图谱已经成为用带有标记的有向图的形式来表示知识,并能赋予文本信息语义的强大工具。知识图谱是以节点的形式将项目、实体或用户表示出来,以边的形式将相互作用的节点链接起来构造的图形,边可以表示任何语义关系。知识库包含一组概念、实例和关系[1]。刘峤等[2]将知识图谱的构建按照知识获取的过程分为信息抽取、知识融合和知识加工三个层次,定义知识图谱是一个具有属性的实体通过关系链接而成的网状知识库。Cowie等[3]将信息抽取划分为实体、关系和属性三个层次,Sekine等[4]提出了一种包含150种实体的命名实体分类体系。Sen[5]采用主题模型作为相似度计算的依据,从维基百科中获取了实体目录,消除不可见文本的引用。Malin等[6]提出利用随机漫步模型对演员合作网络数据进行实体消歧,并取得了比基于文本相似度模型更好的消歧效果。Wu等[7]选择维基百科作为数据源,通过自动抽取生成训练语料,将其应用于对非结构化数据的实体属性抽取。对于关系抽取,出现了大量基于特征向量或核函数[8]的监督学习方法、半监督学习方法[9]和弱监督学习方法[10]。Banko等[11]提出了面向开放域的信息抽取方法框架并发布了基于自监督学习方式的开放信息抽取原型系统。Chaim[12]定义了数据、信息和知识等概念,认为软件服务系统的开发可以从数据、信息和知识的角度分为数据共享、信息传递和知识创造等阶段[13]。Duan等[14]分别从数据、信息、知识和智慧方面阐明了知识图谱的架构并提出通过构建数据图谱、信息图谱和知识图谱的架构回答5W问题[15]。
2 资源类型及图谱定义
从拓展现有知识图谱(Knowledge Graph)概念的角度出发,本文提出了一种基于数据图谱DGDIK(Data GraphDIK)、信息图谱IGDIK(InformationDIK)和知识图谱KGDIK(Knowledge GraphDIK)三层的可自动抽象调整的解决架构,通过对海量资源进行合理组织和存储,达到在资源存储空间中以最高搜索效率找到满足用户检索需求资源的目标。本文对资源元素形态和图谱的定义如下所示:
定义1(资源元素(ElementsDIK)) 资源元素包括数据资源、信息资源和知识资源三种形态。ElementsDIK:=〈DataDIK,InformationDIK,KnowledgeDIK〉。
定义2(图谱(GraphDIK)) 本文对已有知识图谱的概念进行拓展,将图谱的表达分为数据图谱、信息图谱和知识图谱三层。
GraphDIK:=〈(DGDIK),(IGDIK),(KGDIK)〉。
本文对应于DataDIK、InformationDIK、KnowledgeDIK和智慧的递进层次在整体上澄清知识图谱的表达,将知识图谱划分为DGDIK、IGDIK、KGDIK和智慧图谱四个层面。现阶段本文基于前三层架构对类型化的资源进行构建、存储、处理和展示,在DGDIK层面上对通过直接观察到的DataDIK进行建模,在IGDIK和KGDIK上分析自适应的自动抽象的资源优化过程,以支持兼容经验知识的引入和高效的自动语义分析,在KGDIK上通过关系推理扩展图谱的点密度和边密度。表1为对DataDIK、IntormationDIK和KnowledgeDIK等形态的资源以及对应图谱层次的介绍。

Table 1 Explanation for resource type
定义3(数据图谱(DGDIK))
DGDIK:=collection{array,list,stack,queue,tree,graph}。
DGDIK是各种数据结构包括数组、链表、栈、队列、树和图等的集合。DGDIK上未对DataDIK的准确性进行分析,可能出现不同名称的DataDIK但表达相同含义,即冗余。DGDIK只能对图谱上表示的DataDIK进行静态分析,无法分析和预测DataDIK的动态变化。DataDIK是通过观察获得的数字或其他类型信息的基本个体项目,在没有上下文语境的情况下,DataDIK没有意义。
定义4(信息图谱(IGDIK))
IGDIK:=combination{relatedDataDIK}。
IGDIK是相互关联的DataDIK的组合,InformationDIK是通过DataDIK和DataDIK组合之后的上下文传达的,经过概念映射和相关关系组合之后的适合分析和解释的信息。在IGDIK上可进行数据清洗,消除冗余数据。
定义5(知识图谱(KGDIK))
KGDIK:=collection{StatisticRules}。
KGDIK实质是语义网络,包括由InformationDIK总结出的统计规则的集合。KGDIK蕴含丰富的语义关系,在KGDIK上通过信息推理和实体链接可提高KGDIK的边密度和节点密度,KGDIK的无结构特性使得其自身可以无缝链接。信息推理需要有相关关系规则的支持,这些规则可以由人手动构建,但往往耗时费力,得到复杂关系中的所有推理规则更加困难。使用路径排序算法将每个不同的关系路径作为一维特征,通过在KGDIK中构建关系路径来构建关系分类的特征向量和关系分类器提取关系。
3 面向事务处理的时空效率优化方法
3.1 问题的输入
首先,给出本文所讨论的问题的输入。
定义6(事务性搜索目标资源集合) 本文将事务性搜索目标资源集合定义为TSR:={TSRD,TSRI,TSRK},TSR的类型集合为TTSR={ttsrD,ttsrI,ttsrK},每种资源的规模为ATSR={atsrD,atsrI,atsrK}。
定义7(资源存储空间(RSS)) 本文将资源存储空间定义为RSS:={RSSD,RSSI,RSSK},RSS的类型集合为TRSS={trssD,trssI,trssK},每种资源的规模为ARSS={arssD,arssI,arssK}。
图1展示了事务资源的元模型,对资源处理框架的构建和资源建模可提供资源共享、个性化推荐等服务。在建模过程中,资源类型转换是有必要的,资源类型转换与目标类型和资源转换的规模有关,并取决于用户期望投入。
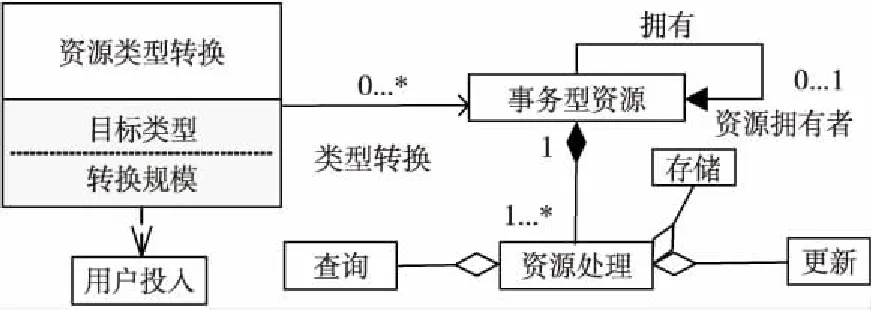
Figure 1 Meta model of transaction resources图1 事务型资源元模型
(1)DataDIK到InformationDIK的转换。
在没有上下文背景的情况下DataDIK没有语义,通过概念映射和聚类对直接观察得到的DataDIK进行处理,将DataDIK进行重组和分类,重组后的DataDIK集合对应不同的类或者概念,由此得到InformationDIK。
(2)InformationDIK到KnowledgeDIK的转换。
InformationDIK用来表达实体之间的交互和协作,通过分类和抽象交互记录或行为记录得到有关实体动态行为的统计规则,即KnowledgeDIK。KnowledgeDIK可以从已知资源中推断得出,推断过程中缺乏的必要信息可通过适当的研究技术来收集,例如实验、调查等。
(3)DataDIK到KnowledgeDIK的转换。
DataDIK可以从标准的模式中继承语义关系,被有效地集成并被其他应用重用,海量的DataDIK在集成融合过程中会存在冗余、不一致等现象,在DataDIK向KnowledgeDIK的转换过程中,通过链接数据来源以及纳入语义约束识别出最可靠的DataDIK进行融合得到KnowledgeDIK。
图2给出了由DataDIK转换成KnowledgeDIK的例子,不同来源的DataDIK(来源1的DataDIK和来源2的DataDIK)在集成融合过程中发生冲突,此时通过引入额外的语义约束“专利类型包括发明专利和实用新型专利”,排除错误DataDIK“A机构专利数量为100”。

Figure 2 An example of conversion from DataDIK to KnowledgeDIK 图2 DataDIK向KnowledgeDIK转换示例
(4)InformationDIK到DataDIK的转换。
InformationDIK到DataDIK的转换过程是从概念集合到资源实例的转换。InformationDIK表达了实体之间的动态交互和协作,观察实体对象在某一时刻的静态状态得到DataDIK。
(5)KnowledgeDIK到DataDIK的转换。
根据知识推理,对抽取出的KnowledgeDIK集合建立相关实例,知识节点之间的关系以属性的方式与实例相关联,得到DataDIK。
(6)KnowledgeDIK到InformationDIK的转换。
由已知的KnowledgeDIK通过逻辑推理挖掘隐式存在的资源,知识图谱的无结构特征使得其可以链接和利用更丰富的知识库帮助用户做决策,从知识检索到知识创造的过程中得到InformationDIK。
3.2 问题形式化描述
如图3所示,其特征在于以计算来决定存储,以存储来服务搜索,将以DataDIK、InformationDIK和KnowledgeDIK等形态存在的资源根据在DGDIK、IGDIK和KGDIK上搜索的代价进行存储,发现资源搜索和存储的最优方案,优化资源处理和存储的时空效率。
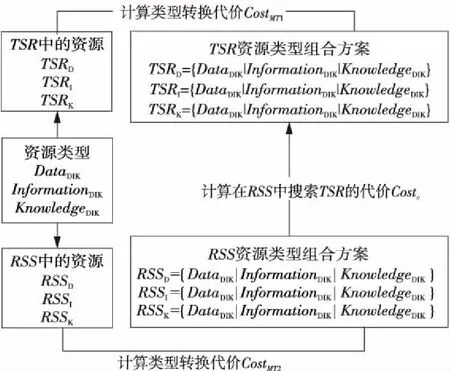
Figure 3 Resource type combination scheme图3 资源类型组合方案
3.2.1 资源类型转移代价计算
问题假定1:假定TSR中资源已在RSS中以任意一种方式存储完毕。
对TSR中资源的类型集合TTSR的每个元素依次取ElementsDIK中的值,形成组合情形TTSR={ttsrD,ttsrI,ttsrK},TSR中单位资源向ElementsDIK中定义的资源类型转换的原子代价如表2所示,则TSR中所有的资源向赋值后对应类型资源转移的代价(CostMT1)可根据公式(1)来计算:
*ARRS
(1)

Table 2 Atomic cost for conversionof unit resource type in TSR
*ARSS
(2)

Table 3 Atomic cost for conversion ofunit resource type in RSS
3.2.2 处理TSR中资源的计算代价
综合考虑存储代价和搜索代价的计算,在不超过用户投入的方案中选择综合代价最低的方案对资源搜索机制和资源存储方案进行调整,根据公式(3)计算在RSS中搜索TSR中资源所要花费的计算代价(Costc):
αARSS*SCost+βARSS′
(3)
其中,α和β分别表示图谱规模和资源类型转换代价占Costc的权重,均可通过数据训练得出,ARSS′表示进行类型转换之后的资源规模。RSS中搜索单位资源TSR的原子代价如表4所示。

Table 4 Atomic cost for searchingunit TSR resource in RSS
3.2.3 存储与计算协同调整的总代价计算
本文假定已提前获取到用户的预期投入(Inve0)和用户所能接受的最大总代价(Total_Cost0)。根据CostMT1、CostMT2和Costc,计算TSR资源从当前状态向TTSR中资源类型转移的代价和TRSS中资源向RSS中资源状态转移的代价以及计算代价的总和(Total_Cost),计算方式如公式(4)所示:
Total_Cost=CostMT1+CostMT2+Costc
(4)
将不同情形下Total_Cost的值与Total_Cost0进行比较,并将与计算所得的Total_Cost对应的方案所需用户投入(Inve)和Inve0作比较,判断是否满足条件“Total_Cost
Inve=γ*Total_Cost0-Total_Cost
(5)
其中,γ表示单位代价所需投入,可通过数据训练得出。
抓培训,干部队伍素质进一步提升。林芝市局领导班子高度重视干部培训工作,积极组织干部赴成都、北京、拉萨、广东、福建等地参加“四品一械”相关培训,自主举办食品安全、食品药品抽样、食品药品安全协管员培训班等各类培训16期,参训人数共计2000余人次。
算法1计算资源类型不同组合情形下的总代价
输入:TSR,RSS,ElementsDIK,TotalCost0,Inve0。
输出:TSR和RSS中资源类型组合的最小总代价。
FOR eachttsrDo
Assign value fromElementsDIK;
ComputeCostMT1;
FOR eachtrssDo
Assign value fromElementsDIK;
ComputeCostMT2,Total_Cost;
IF (Total_Cost Total_Cost0=Total_Cost; 事务处理效率优化方法的流程如图4所示。 Figure 4 Process of the collaborative storage and computation adaptation 图4 存储与计算一体化方法流程 算法1描述了TSR和RSS中资源不同类型的组合情况,计算每种情况下TSR中资源向TTSR中资源类型转移的代价,TRSS中资源状态向RSS转移的代价,以及每种组合情况下在RSS中搜索TSR中资源的计算代价,找出不超过用户投入且具有最小Total_Cost的方案作为协同调整资源的最优方案。 本文将提出的优化方法应用于以下场景:资源库中有一个用户订单表,并关联了用户信息表,订单表中有1 000万条用户记录信息,用户信息表中有100万条用户采购记录信息。依据用户的订单记录给用户推荐合适的产品时,传统方法是从这1 000万条记录中查找出对应用户id的记录然后通过分库、分表等操作进行查询,然而要在一台服务器的基础上不做分库、分表,就要从这100万个用户数据关联的1 000万个订单记录中,提取出用户消费相关产品的知识体系,例如按年龄划分等,依据知识来给用户进行推荐。本文构建的知识体系形成了新的表,这些新的包含知识的表比原有记录表的规模小很多,时间是查询某个用户id订单记录的时间和通过知识推理得出的时间。如图5所示,本文将不转换资源类型(方案0)推荐结果准确度设为1,通过比较不同方案向用户推荐的产品的相似度来衡量用户满意度。 Figure 5 Accuracy comparison of resource type conversion results图5 资源类型转换结果准确度比较 本文将用户订单表关联的用户根据年龄进行划分,再结合采购记录,建立不同年龄段对商品的偏好体系,例如15~20岁用户常买学习用品,20~40岁用户常买服装个护用品,40~55岁用户常买生活用品。同时为500个用户进行商品推荐,方案1~方案4分别是为100个、200个、300个、400个用户按推理出的商品采购偏好知识体系进行推荐,剩余用户按分库分表进行查询,根据查询结果进行相似商品推荐。不同方案之间资源类型转换的目标类型和转换规模不同,随着用户采购商品的记录数量增多,推荐商品一致性与传统方法的相似度逐渐升高。知识体系是经过抽象后的可推理的规则,在提取知识体系的过程中所消耗的计算资源和存储资源都会降低,通过计算未转换资源类型和转换资源类型后不同方案的代价差异,选择在用户投入范围内具有最大效益比的方案对优化资源存储和计算。 Mccarthy等[16]使用决策树来学习如何在商业合资企业领域分类不同短语的系统,解决共指消解问题。本体被用作语义网中的知识表示的标准形式[17],微软发布的Probase利用统计机器学习算法以数据驱动的方法构建本体[18]。MongoDB作为一种基于分布式文件存储的数据库,不适用于高度事务性的系统,基于DGDIK、IGDIK和KGDIK三层架构对资源进行建模,以节点和边的形式存储资源,图谱对自然语言的映射更完整,可以表达实体间任意的语义关系及与或非等逻辑关系。Wang 等[19]通过概念注释来促进跨语言知识链接,促进不同语言的知识共享。潘伟丰等[20]提出服务分类方法并用于服务注册管理系统中,为服务提供分类信息,提高服务发现、检索以及服务资源管理的效率。 本文的贡献在于将以数据、信息和知识等形态的资源根据资源的存储代价和搜索代价综合考虑来协同调整资源的搜索机制和存储方案,优化时空效率。基于DGDIK、IGDIK和KGDIK建立资源处理框架,对不同的资源需求在最匹配的资源层面上进行查找,有效提高查找效率。合理地处理系统中的类型化资源,通过分析和抽象事务处理中海量的DataDIK、InformationDIK和KnowledgeDIK等形态的资源,消除概念歧义,剔除冗余和错误概念,提高DataDIK、InformationDIK和KnowledgeDIK等资源的质量。当前工作在各个环节进行了实例讨论,下一步将扩大数据规模进行验证。
4 资源类型转换效果示意

5 相关工作
6 结束语
