Deep Scalogram Representations for Acoustic Scene Classification
2018-08-11ZhaoRenKunQianStudentMemberIEEEZixingZhangMemberIEEEVedhasPanditAliceBairdStudentMemberIEEEandBjrnSchullerFellowIEEE
Zhao Ren,Kun Qian,Student Member,IEEE,Zixing Zhang,Member,IEEE,Vedhas Pandit,Alice Baird,Student Member,IEEE,and Björn Schuller,Fellow,IEEE
Abstract—Spectrogram representations of acoustic scenes have achieved competitive performance for acoustic scene classification.Yet,the spectrogram alone does not take into account a substantial amount of time-frequency information.In this study,we present an approach for exploring the benefits of deep scalogram representations,extracted in segments from an audio stream.The approach presented firstly transforms the segmented acoustic scenes into bump and morse scalograms,as well as spectrograms;secondly,the spectrograms or scalograms are sent into pre-trained convolutional neural networks;thirdly,the features extracted from a subsequent fully connected layer are fed into(bidirectional)gated recurrent neural networks,which are followed by a single highway layer and a softmax layer;finally,predictions from these three systems are fused by a margin sampling value strategy.We then evaluate the proposed approach using the acoustic scene classification data set of 2017 IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events(DCASE).On the evaluation set,an accuracy of 64.0%%%from bidirectional gated recurrent neural networks is obtained when fusing the spectrogram and the bump scalogram,which is an improvement on the 61.0%%%baseline result provided by the DCASE 2017 organisers.This result shows that extracted bump scalograms are capable of improving the classification accuracy,when fusing with a spectrogram-based system.
I.INTRODUCTION
ACOUSTIC scene classification(ASC)aims at the identification of the class(such as ‘train station’,or‘restaurant’)of a given acoustic environment.ASC can be a challenging task,since the sounds within certain scenes can have similar qualities,and sound events can overlap one another[1].Its applications are manifold,such as robot hearing or contextaware human-robot interaction[2].
In recent years,several hand-crafted acoustic features have been investigated for the task of ASC,including frequency,energy,and cepstral features[3].Despite such year-long efforts,recently,representations automatically extracted from spectrogram images with deep learning methods[4],[5]are shown to perform better than hand-crafted acoustic features when the number of acoustic scene classes is large[6],[7].Further,compared with a Fourier transformation for obtaining spectrograms,the wavelet transformation has the ability to incorporate multiple scales,and for this reason locally can reach the optimal time-frequency resolution[8]concerning the Heisenberg uncertainty of optimal time and frequency resolution at the same time.Accordingly,wavelet features have already been applied successfully for many acoustic tasks[9]−[13],but often,the greater effort in calculating a wavelet transformation is considered not worth the extra effort if gains are not outstanding.In the theory of wavelet transformation,the scalogram is the time-frequency representation of the signal by wavelet transformation,where the brightness or the colour can be used to indicate coefficient values at corresponding time-frequency locations.Compared to spectrograms,which offer(only)a fixed time and frequency resolution,a scalogram is better suited for the task of ASC due to its detailed representation of the signal.Hence,a scalogram based approach is proposed in this work.
We use convolutional neural networks(CNNs)to extract deep features from spectrograms or scalograms,as CNNs have proven to be effective for visual recognition tasks[14],and ultimately,spectrograms and scalograms are images.Several specific CNNs are designed for the ASC task,in which spectrograms are fed as an input[7],[15],[16].Unfortunately,those approaches are not robust and it can also be time-consuming to design CNN structures manually for each dataset.Using pre-trained CNNs from large scale datasets[17]is a potential way to break this bottleneck.ImageNet1http://www.image-net.org/is a suited such big database promoting a number of CNNs each year,such as ‘AlexNet’[18]and ‘VGG’[19].It seems promising to apply transfer learning[20]through extracting features from these pre-trained neural networks for the ASC task—the approach taken in the following.
As to handling of audio besides considering ‘images’(the spectrograms and/or scalograms)by pre-trained deep networks,we further aim to respect its nature as a time series.In this respect,sequential learning performs better for time-series problems than static classifiers such as support vector machines(SVMs)[21]or extreme learning machines(ELMs)[17].Likewise,hidden Markov models(HMMs)[22],recurrent neural networks(RNNs)[23],and in the more recent years in particular long short-term memory(LSTM)RNNs[24]are proven effective for acoustic tasks[25],[26].As gated recurrent neural networks(GRNNs)[27]—a reduction in computational complexity over LSTM-RNNs—are shown to perform well in[13],[28],we not only use GRNNs as the classifier rather than LSTM-RNNs,but also extend the classification approach with bidirectional GRNNs(BGRNNs),which are trained forward and then backward within a specific time frame.Likewise,we are able to capture ‘forward’and ‘backward’temporal contexts,or simply said the whole sequence of interest.Unless moving with the microphone or changes of context,acoustic scenes in the real-world usually prevail for longer amounts of time,however,with potentially highly varying acoustics during such stretches of time.This allows to consider static chunk lengths for ASC,despite modelling these as a time series to preserve the order of events,even though being only interested in the ‘larger picture’of the scene than in details of events within that scene.In the data considered in this study based on the dataset of 2017 IEEE AASP Challenge on Detection and Classification of Acoustic Scenes And Events(DCASE),the instances have a(pre-)specified duration(10s per sample in the[29]).
In this article,we make three main contributions.First,we propose the use of scalogram images to help improve the performance of only a single spectrogram extraction for the ASC task.Second,we extract deep representations from the scalogram images using pre-trained CNNs,which is much faster and more efficient in terms of conservative data requirements than manually designed CNNs.Third,we investigate the performance improvement obtained through the use of(B)GRNNs for classification.
The remainder of this paper is structured as follows:some related work for the ASC task is introduced in Section II;in Section III,we describe the proposed approach,the pipeline of which is shown in Fig.1;the database description,experimental set up,and results are then presented in Section IV;finally,conclusions are given in Section VI.
II.RELATED WORK
In the following,let us outline point by point related work to the points of interest in this article,namely using spectrogramtype images as network input for audio analysis,using CNNs in a transfer-learning setting,using wavelets rather or in addition to spectral information,and finally the usage of memory-enhanced recurrent topologies for optimal treatment of the audio stream as time series data.
Extracting spectrograms from audio clips is well known for the ASC task[7],[30].This explains why a lion’s share of the existing work using non-time-signal input to deep network architectures and particularly CNNs use spectrograms or derived forms as input.For example,spectrograms were used to extract features by autoencoders in[31].Predictions were obtained by CNNs from mel spectrograms in[32],[33].Feeding analysed images from spectrograms into CNNs has also shown success.Two image-type features based on a spectrogram,namely covariance matrix,and a secondary frequency analysis were fed into CNNs for classification in[34].
Further,extracting features from pre-trained CNNs has been widely used in transfer learning.To name but two examples,a pre-trained ‘VGGFace’model was applied to extract features from face images and a pre-trained ‘VGG’was used to extract features from images in[17].Further,in[6],deep features of audio waveforms were extracted by a pre-trained ‘AlexNet’model[18].
Wavelet features are applied extensively in acoustic signal classification,but in fact,in their history they were broadly used also in other contexts such as for electroencephalogram(EEG),electrooculogram(EOG),and electrocardiogram(ECG)signals[35].Recent examples particularly in the domain of sound analysis include for example successful application for snore sound classification[10],[11],besides wavelet transform energy and wavelet packet transform energy having also been proven to be effective in the ASC task[12].
Various types of sequential learning are repeatedly and frequently applied for the ASC task.For example,in[36],experimental results have shown superiority when employing RNNs for classification.There are also some special types of RNNs that have been applied for classification in this context.As an example,LSTM-RNNs were combined with CNNs using early-fusion in[25].In[37],GRNNs were utilised as the classifier,and achieved a significant improvement using a Gaussian mixture model(GMM).
To sum the above up,while similar methods mostly use spectrograms or mel spectrograms,minimal research has been done about the performance of scalogram representations extracted by pre-trained CNNs on sequential learning for audio analysis.This work does so and is introduced next.
III.PROPOSED METHODOLOGY
A.Audio-to-Image Pre-Processing
In this work,we first seek to extract the time-frequency information which is hidden in the acoustic scenes.Hence,the following three types of representations are used in this study,which is a foundation of the following process.
1)Spectrogram:The spectrogram as a time-frequency representation of the audio signal is generated by a short-time Fourier transform(STFT)[38].We generate the spectrograms with a Hamming window computing the power spectral density by the dB power scale.We use Hamming windows of size 40ms with an overlap of 20ms.
2) ‘Bump’Scalogram:The bump scalogram is generated by the bump wavelet[39]transformation,which is defined by


Fig.1.Framework of the proposed approach.First,spectrograms and scalograms(bump and morse)are generated from segmented audio waveforms.Then,one of these is fed into the pre-trained CNNs,in which further features are extracted at a subsequent fully connected layer fc7.Finally,the predictions(predicted labels and probabilities)are obtained by(B)GRNNs with a highway network layer and a softmax layer with the deep features as the input.

Fig.2.The spectrogram and two types of scalograms are extracted from the acoustic scenes.All of the images are extracted from the first audio sequence of DCASE2017’s ‘a0011020.wav’with a label‘residential area’.
where s stands for the scale,µ and σ are two constant parameters,in which σ affects the frequency and time localisation,and Ψ(sω)is the transformed signal.
3) ‘Morse’Scalogram:The morse scalogram[40]generation is defined by
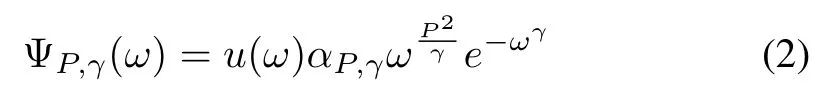
where u(ω)is the unit step,P is the time-bandwidth product,γ is the symmetry,αP,γstands for a normalising constant,and ΨP,γ(ω)means the morse wavelet signal.
The three image representations of one instance are shown in Fig.2.While the STFT focuses on analysing stationary signals and gives a uniform resolution,the wavelet transformation is good at localising transients in non-stationary signals,since it can provide a detailed time-frequency analysis.In our study,the training model is proposed based on the above three representations and comparisons of them are provided in the following sections.
B.Pre-Trained Convolutional Neural Networks
By transfer learning,the pre-trained CNNs are transfered to our ASC task for extracting the deep spectrum features.For the pre-trained CNNs,we choose ‘AlexNet’[18], ‘VGG16’,and ‘VGG19’[19],since they have proven to be successful in a large number of natural image classification tasks,including the ImageNet Challenge2http://www.image-net.org/challenges/LSVRC/.‘AlexNet’consists of five convolutional layers with[96,256,384,384,256]kernels of size[11,5,3,3,3],and three maxpooling layers.‘VGG’networks have 13([2,2,3,3,3], ‘VGG16’),or 16([2,2,4,4,4], ‘VGG19’)convolutional layers with[64,128,128,256,256]kernels and five maxpooling layers.All of the convolutional layers in the‘VGG’networks use the common kernel size ‘three’.In these three networks,the convolutional and maxpooling layers are followed by three fully connected layers{fc6,fc7,fc},and a soft-max layer for 1000 labelled classifications according to the ImageNet challenge,in which fc7 is employed to extract deep features with 4096 attributes.More details on the CNNs are given in Table I.We obtain the pre-trained ‘AlexNet’network from MATLAB R2017a3https://de.mathworks.com/help/nnet/ref/alexnet.html,and ‘VGG16’and ‘VGG-19’from MatConvNet[41].As outlined,we exploit the spectrogram and two types of scalograms as the input for these three CNNs separately and extract the deep representations from the activations on the second fully connected layer fc7.
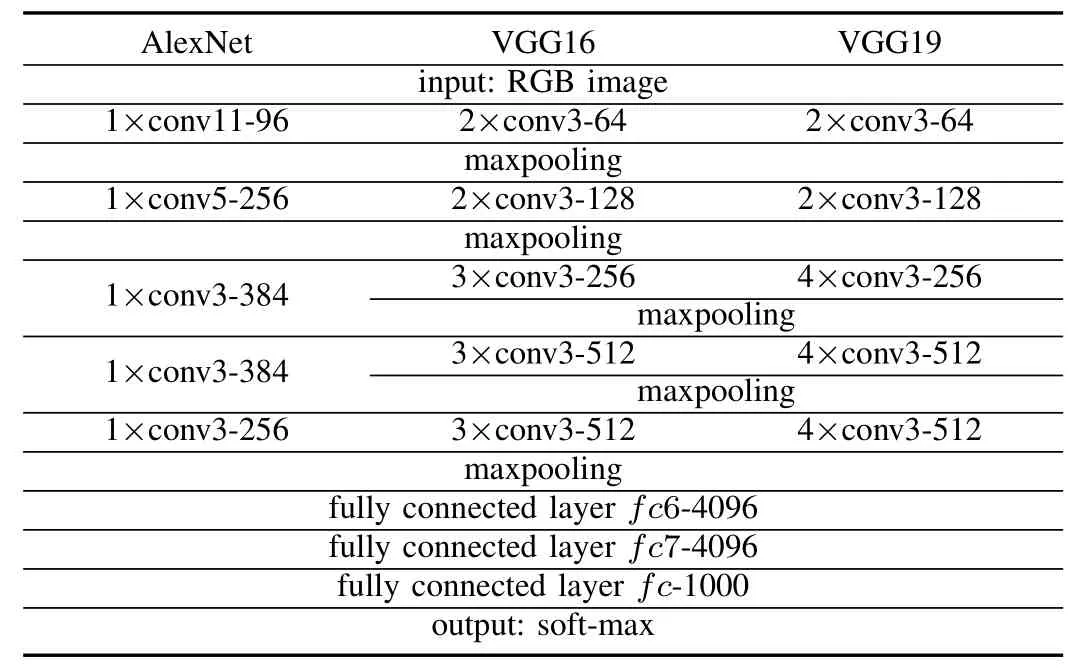
TABLE ICONFIGURATIONS OF THE CONVOLUTION ALNEURAL NETWORKS.‘ALEXNET’,‘VGG16’,AND ‘VGG19’AREUSED TO EXTRACTDEEP FEATURES OF THESPECTROGRAM,‘BUMP’,AND ‘MORSE’SCALOGRAMS.‘CONV’STANDS FOR THE CONVOLUTION ALLAYER
IV.EXPERIMENTS ANDRESULTS
A.Database
C.(Bidirectional)Gated Recurrent Neural Networks
As a special type of RNNs,GRNNs contain a gated recurrent unit(GRU)[27],which features an update gate u,a reset gate r,an activation h,and a candidate activation.For each ith GRU at a time t,the update gate u and reset gate r activations are defined by

where σ is a logistic sigmoid function,Wu,Wr,Uu,and Urare the weight matrices,and ht−1stands for the activation function.At time t,the activation function and candidate activation function are defined by
As mentioned,our proposed approach is evaluated on the dataset provided by the DCASE 2017 Challenge[29].The dataset contains 15 classes,which include ‘beach’,‘bus’,‘cafe/restaurant’, ‘car’, ‘city centre’, ‘forest path’, ‘grocery store’,‘home’,‘library’,‘metro station’,‘office’,‘park’,‘residential area’, ‘train’,and ‘tram’.As further mentioned above,the organisers split each recording into several independent 10s segments to increase the task difficulty and increase the number of instances.We train our model using a cross validation on the officially provided 4-fold development set,and evaluate on the official evaluation set.The development set contains 312 segments of audio recordings for each class and the evaluation set includes 108 segments of audio recordings for each class.Accuracy is used as the final evaluation metric.
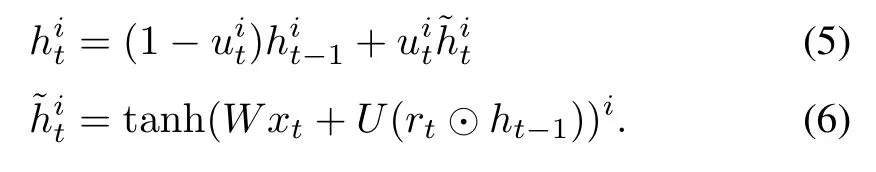
B.Experimental Setup
The information flows inside the GRU with gating units,similarly to,but with separate memory cells in the LSTM.However,there is not an input gate,forget gate,and output gate which are included in the LSTM structure.Rather,there are a reset and an update gate,with overall less parameters in a GRU than in a LSTM unit so that GRNNs usually converge faster than LSTM-RNNs[27].GRNNs have been observed to be comparable and even better than LSTM-RNNs sometimes in accuracies,as shown in[42].To gain more time information from the extracted deep feature sequences,bidirectional GRNNs(BGRNNs)are an efficient tool to improve the performance of GRNNs(and in fact of course similarly for LSTM-type RNNs),as shown in[43],[44].Therefore,BGRNNs are used in this study,in which context interdependences of features are learnt in both temporal directions[45].For classification,a highway network layer and a softmax layer follow the(B)GRNNs,as highway networks are often found to be more efficient than fully connected layers for very deep neural networks[46].
D.Decision Fusion Strategy
It was found in a recent work that the margin sampling value(MSV)[47]method,which is a late-fusion method,was effective for fusing training models[48].Hence,based on the predictions from(B)GRNNs for multiple types of deep features,MSV is applied to improve the performance.For each prediction{Lj,pj},j=1,...,n,in which Ljis the predicted label,and pjis the probability of the corresponding label,n is the total number of models,MSV is defined by
First,we segment each audio clip into a sequence of 19 audio instances with 1000ms and a 50%overlap.Then,two types of representations are extracted:hand-crafted features for comparison,and deep image-based features,which have been described in Section III.Hand-crafted features are as follows:
Two kinds of low-level descriptors(LLDs)are extracted due to their previous success in ASC[29],[49],including Melfrequency cepstral coefficient(MFCC)1−14 and logarithmic Mel-frequency band(MFB)1−8.According to feature sets provided in the INTERSPEECH COMPUTATIONAL PARALINGUISTICS CHALLENGE(COMPARE)[50],in total 100 functionals are applied to each LLD,yielding 14×100=1400 MFCCs features and 8×100=800 log MFBs features.The details of hand-crafted features and the feature extraction tool openSMILE can be found in[3].
These representations are then fed into the(B)GRNNs with 120 and 160 GRU nodes respectively with a ‘tanh’activation,followed by a single highway network layer with a ‘linear’activation function,which is able to ease gradient-based training of deep networks,and a softmax layer.Empirically,we implement this network using TensorFlow4https://github.com/tensorflow/tensorflowand TFLearn5https://github.com/tflearnwith a fixed learning rate of 0.0002(optimiser ‘rmsprop’)and a batch size of 65.We evaluate the performance of the model at the kth training epoch,k∈{23,30,...,120}.Finally,the MSV decision fusion strategy is applied to combine the(B)GRNNs models for the final predictions.
C.Results

We compute the mean accuracy on the 4-fold partitioned development set for evaluation according to the official protocols.Fig.3 presents the performance of both GRNNs and BGRNNs on different feature sets when stopping at the multiple training epochs.From this we can see that,the accuracies of both GRNNs and BGRNNs on MFCCs,and log MFBs features are lower than the baseline.However,the performances of deep features extracted by pre-trained CNNs are comparable with the baseline result,especially the representations extracted by the ‘VGG16’and the ‘VGG19’from spectrograms.This indicates the effectiveness of deep image-based features for this task.
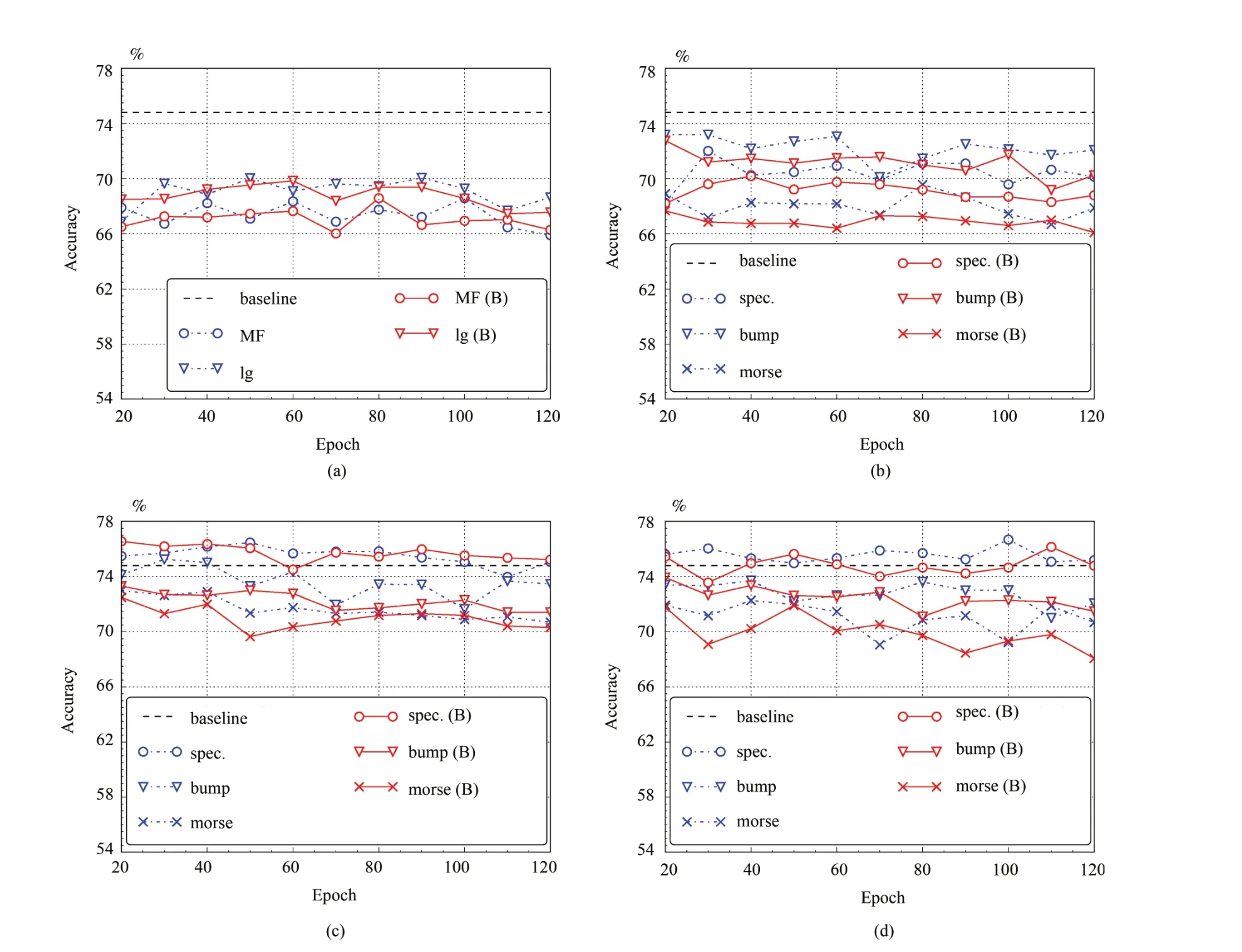
Fig.3.The performances of GRNNs and BGRNNs on different features.(a)MFCCs(MF)and log MFBs(lg)features.The performances of features from the spectrogram and scalograms(bump and morse)extracted by three CNNs.(b)AlexNet.(c)VGG16.(d)VGG19.
Table II presents the accuracy of each model from each type of feature.For the development set,the accuracy of each type of feature is denoted as the highest one of all epochs.For the evaluation set,we choose the consistency epoch number of the development set.We find that the accuracies after decision fusion achieve an improvement based on a single spectrogram or scalogram image.In the results,the performances of BGRNNs and GRNNs are comparable on the development set but the accuracies on the BGRNNs are slightly higher than those of the GRNNs on the evaluation set,presumably because the BGRNNs cover the overall information in both the forward and backward time direction.The best performance of 84.4%on the development set is obtained when extracting features from the spectrogram and the bump scalogram by the‘VGG19’and classifying by GRNNs at epoch 20.This is an improvement of 8.6%over the baseline of the DCASE 2017 challenge(p<0.001 by a one-tailed z-test).The best result of 64.0%on the evaluation set is also obtained when extracting features from the spectrogram and bump scalogram by the‘VGG19’,but classifying by BGRNNs at epoch 20.The performance on the evaluation set is also an improvement upon the 61.0%baseline.
V.DISCUSSION
The proposed approach in our study improves on the baseline performance given for the ASC task in the DCASE 2017 Challenge for sound scene classification and performs better than(B)GRNNs based on a hand-crafted feature set.The accuracy of(B)GRNNs on deep learnt features from a spectrogram,bump,and morse scalograms outperform MFCC and log MFB in Fig.3.The performance of fused(B)GRNNs on deep learnt features is also considerably better than on hand-crafted features in Table II.Hence,the feature extraction method based on CNNs has proven itself to be efficient for the ASC task.We also investigate the performance when combining different spectrogram or scalogram representations.In Table II,the bump scalogram is validated as being capable of improving the performance of the spectrogram alone.
Fig.4 shows the confusion matrix of the best results on the evaluation set.The model performs well on some classes,such as ‘forest path’, ‘home’,and ‘metro station’.Yet,other classes such as ‘library’and ‘residential area’are hard to recognise.We think this difficulty is caused by noises or that the waveforms have similar environments within the acoustic scene.
To investigate the performance of each spectrogram or scalogram on different classes,a performance comparison ofthe spectrogram and the bump scalogram from the best result on evaluation set is shown in Table III.We can see that,the spectrogram performs better than the bump scalogram for‘beach’, ‘grocery store’, ‘office’,and ‘park’.However,the bump scalogram is optimal for the ‘bus’,‘city’,‘home’,and‘train’scenes.After fusion,the precision of some classes is improved,such as ‘cafe/restaurant’, ‘metro station’, ‘residential area’,and ‘tram’.Overall,it appears worth using the scalogram as an assistance to the spectrogram,to obtain more accurate prediction.

TABLE IIPERFORMANCE COMPARISONS ON THE DEVELOPMENT AND THE EVALUATION SET BY GRNNS AND BGRNNS ON HAND-CRAFTED FEATURES (MFCCS (MF) AND LOG MFBS (LG)) AND FEATURES EXTRACTED BY PRE-TRAINED CNNS FROM THE SPECTROGRAM (S), BUMP SCALOGRAM (B), AND MORSE SCALOGRAM (M)

TABLE IIIPERFORMANCE COMPARISONS ON THE EVALUATION SET FROM BEFORE AND AFTER LATE-FUSION OF BGRNNS ON THE FEATURES EXTRACTED FROM THE SPECTROGRAM (S) AND THE BUMP SCALOGRAM (B)

Fig.4.Confusion matrix of the best performance of 64.0%on the evaluation set.Late-fusion of BGRNNs on the features extracted from the spectrogram and the bump scalogram by ‘VGG16’.
The result from the champion on the ASC task of the DCASE challenge 2017 is 87.1%on the development set and 83.3%on the evaluation set[51],using a generative adversarial network(GAN)for training set augmentation.There is a significant difference between the best result reached by the methods proposed herein which omit data augmentation,as we focus on a comparison of feature representations,and this result of the winning DCASE contribution in 2017(p<0.001 by one-tailed z-test).We believe that in particular the GAN part in combination with the proposed method shown herein holds promise to lead to an even higher overall result.Hence,it appears to be highly promising to re-investigate the proposed method in combination with data augmentation before training in future work.
VI.CONCLUSIONS
We have proposed an approach using pre-trained convolutional neural networks(CNNs)and(bidirectional)gated recurrent neural networks((B)GRNNs)on the spectrogram,bump,and morse scalograms of audio clips,to achieve the task of acoustic scene classification(ASC).This approach is able to improve the performance on the 4-fold development set of the 2017 IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events(DCASE),achieving an accuracy of 83.4%for the ASC task,compared with the baseline of 74.8%of the DCASE challenge(P<0.001,one-tailed z-test).On the evaluation set,the performance is improved from the baseline of 61.0%to 64.0%.The highest accuracy on the evaluation set is obtained when combining models from both the spectrogram and the scalogram images;therefore,the scalogram appears helpful to improve the performance reached by spectrogram images for the task of ASC.We focussed on the comparison of feature types in this contribution,rather than trying to reach overall best results by combination of‘tweaking on all available screws’such as is usually done by entries into challenges.Likewise,we did for example not consider data augmentation by generative adversarial networks(GANs)or similar topologies as for example the DCASE 2017 winning contribution did.In future studies on the task of ASC,we will thus include further optimisation steps as the named data augmentation[52],[53].In particular,we also aim to use evolutionary learning to generate adaptive‘selfshaping’CNNs automatically.This avoids having to hand-pick architectures in cumbersome optimisation runs.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Advances in Vision-Based Lane Detection:Algorithms,Integration,Assessment,and Perspectives on ACP-Based Parallel Vision
- A Mode-Switching Motion Control System for Reactive Interaction and Surface Following Using Industrial Robots
- Adaptive Proportional-Derivative Sliding Mode Control Law With Improved Transient Performance for Underactuated Overhead Crane Systems
- On“Over-sized"High-Gain Practical Observers for Nonlienear Systems
- H∞Tracking Control for Switched LPV Systems With an Application to Aero-Engines
- Neural-Network-Based Terminal Sliding Mode Control for Frequency Stabilization of Renewable Power Systems