Advances in Vision-Based Lane Detection:Algorithms,Integration,Assessment,and Perspectives on ACP-Based Parallel Vision
2018-08-11YangXingChenLvMemberIEEELongChenHuajiWangHongWangDongpuCaoMemberIEEEEfstathiosVelenisFeiYueWangFellowIEEE
Yang Xing,Chen Lv,Member,IEEE,Long Chen,Huaji Wang,Hong Wang,Dongpu Cao,Member,IEEE,Efstathios Velenis,Fei-Yue Wang,Fellow,IEEE
Abstract—Lane detection is a fundamental aspect of most current advanced driver assistance systems(ADASs).A large number of existing results focus on the study of vision-based lane detection methods due to the extensive knowledge background and the low-cost of camera devices.In this paper,previous vision based lane detection studies are reviewed in terms of three aspects,which are lane detection algorithms,integration,and evaluation methods.Next,considering the inevitable limitations that exist in the camera-based lane detection system,the system integration methodologies for constructing more robust detection systems are reviewed and analyzed.The integration methods are further divided into three levels,namely,algorithm,system,and sensor.Algorithm level combines different lane detection algorithms while system level integrates other object detection systems to comprehensively detect lane positions.Sensor level uses multi-modal sensors to build a robust lane recognition system.In view of the complexity of evaluating the detection system,and the lack of common evaluation procedure and uniform metrics in past studies,the existing evaluation methods and metrics are analyzed and classified to propose a better evaluation of the lane detection system.Next,a comparison of representative studies is performed.Finally,a discussion on the limitations of current lane detection systems and the future developing trends toward an Artificial Society,Computational experiment-based parallel lane detection framework is proposed.
I.INTRODUCTION
A.Background
TRAFFIC accidents are mainly caused by human mistakes such as inattention,misbehavior,and distraction[1].A large number of companies and institutes have proposed methods and techniques for the improvement of driving safety and reduction of traffic accidents.Among these techniques,road perception and lane marking detection play a vital role in helping drivers avoid mistakes.The lane detection is the foundation of many advanced driver assistance systems(ADASs)such as the lane departure warning system(LDWS)and the lane keeping assistance system(LKAS)[2],[3].Some successful ADAS or automotive enterprises,such as Mobileye,BMW,and Tesla,etc.have developed their own lane detection and lane keeping products and have obtained significant achievements in both research and real world applications.Either of the automotive enterprises or the personal customers have accepted the Mobileye Series ADAS products and Tesla Autopilot for self-driving.Almost all of the current mature lane assistance products use vision-based techniques since the lane markings are painted on the road for human visual perception.The utilization of vision-based techniques detects lanes from the camera devices and prevents the driver from making unintended lane changes.Therefore,the accuracy and robustness are two most important properties for lane detection systems.Lane detection systems should have the capability to be aware of unreasonable detections and adjust the detection and tracking algorithm accordingly[4],[5].When a false alarm occurs,the ADAS should alert the driver to concentrate on the driving task.On the other hand,vehicles with high levels of automation continuously monitor their environments and should be able to deal with low-accuracy detection problems by themselves.Hence,evaluation of lane detection systems becomes even more critical with increasing automation of vehicles.
Most vision-based lane detection systems are commonly designed based on image processing techniques within similar frameworks.With the development of high-speed computing devices and advanced machine learning theories such as deep learning,lane detection problems can be solved in a more efficient fashion using an end-to-end detection procedure.However,the critical challenge faced by lane detection systems is the demand for high reliability and the diverse working conditions.One efficient way to construct robust and accurate advanced lane detection systems is to fuse multi-modal sensors and integrate lane detection systems with other object detection systems,such as detection by surrounding vehicles and road area recognition.It has been proved that lane detection performance can be improved with these multi-level integration techniques[4].However,the highly accurate sensors such as the light/laser detection and ranging(LIDAR/LADAR)are expensive and not available in public transport.
B.Contribution
In this study,the literature reviews on the lane detection algorithms,the integration methods,and evaluation methods are provided.The contribution of this paper can be summarized as follows.
A considerable number of existing studies do not provide enough information on the integration methodologies of lane detection systems and other systems or sensors.Therefore,in this study,the integration methodologies are analyzed in detail and the ways of integration are categorized into three levels:sensor level,system level,and algorithm level.
Due to the lack of ground truth data and uniform metrics,the evaluation of the lane detection system remains a challenge.Since various lane detection systems differ with respect to the hardware and software they use,it is difficult to undertake a comprehensive comparison and evaluation of these systems.In this study,previous evaluation methods are reviewed and classified into off line methods,which still use images and videos,and online methods,which are based on real time confidence calculation.
Finally,a novel lane detection system design framework based on the ACP parallel theory is introduced toward a more efficient way to deal with the training and evaluation of lane detection models.ACP is short for Artificial society,Computational experiments,and Parallel execution,which are three major components of the parallel systems.The ACP-based lane detection parallel system aims to construct virtual parallel scenarios for model training and benefit the corresponding real-world system.The construction method for the lane detection parallel vision system will be analyzed.
C.Paper Organization
This paper is organized as follows:Section II provides a brief overview of existing lane detection algorithms.Section III summarizes the integration methods used in lane detection systems and three levels of integration methods are discussed.In Section IV,the online and off line evaluation methods for lane detection systems will be presented,followed by an analysis of evaluation metrics.In section V,the limitations of current approaches and discussion on developing advanced lane detection systems in the future developing trend will be proposed.The ACP-based parallel theory,as one of the powerful tool to assist the design of lane detection systems will also be introduced.Finally,we will conclude our work in Section VI.
II.VISION-BASED LANE DETECTION ALGORITHM REVIEW
Literature reviews of lane detection algorithms and their corresponding general frameworks have been proposed in[4]−[6].Hillel et al.concluded that road color,texture,boundaries,and lane markings are the main perception aspects for human drivers[4].In[5],McCall and Trivedi classified the lane detection objectives into three categories,which are lane departure warning,driver attention awareness,and automated vehicle control system design.However,they paid much attention to the design of lane detection algorithms and incompletely review the integration and evaluation methods.This study tries to comprehensively review the lane detection system from the perspective of algorithms,integration methods,and evaluation methods.Firstly,in this section,lane detection algorithms and techniques are reviewed from the scope of conventional image processing and novel machine learning methods.In the first part of this section,basic lane detection procedures and general frameworks will be analyzed.The second part will concentrate on the review of commonly used conventional image processing methods.In the last part,lane detection algorithms based on machine learning and deep learning methods,especially the utilization of convolutional neural network(CNN),will be discussed.
A.General Lane Detection Procedure
Vision-based lane detection systems described in studies usually consist of three main procedures,which are image preprocessing,lane detection and lane tracking.Among these,the lane detection process,which comprises feature extraction and model fitting,is the most important aspect of the lane detection system,as shown in Fig.1.The most common procedures in the pre-processing step include region of interest(ROI)selection,vanishing point detection,transferring color image into greyscale image or a different color format,noise removal and blur,inverse perspective mapping(IPM),also known as birds-eye view,segmentation,and edge statistics,etc.Among these tasks,determining the ROI is usually the first step performed in most of previous studies.The main reason for focusing on ROI is to increase computation efficiency and reduce false lane detections.ROI can be roughly selected as the lower portion of an input image or dynamically determined according to the detected lanes.It can also be more efficiently determined with prior road area detections[7],[8].Details of these methods are described in the next section.Generally speaking,a carefully-designed ROI will significantly improve lane detection accuracy as well as computation efficiency.
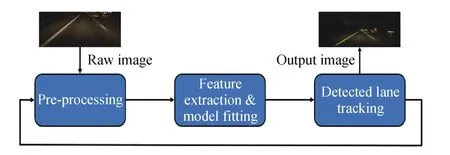
Fig.1.General architecture of lane detection system.The feedback loop indicates that the tracked position of the lane markings can be used to narrow the searching and processing range of the pre-processing unit.
Once the input images have been pre-processed,lane features such as the colors and edge features can be extracted and,therefore,can be detected based on these features.The Hough Transform algorithm,which uses the edge pixel images,is one of the most widely used algorithms for lane detection in previous studies.However,this method is designed to detect straight lines in the beginning and is not efficient in curve lane detection.Curve lanes can often be detected based on model fitting techniques such as random sample consensus(RANSAC).RANSAC fits lane models by recursively testing the model fitting score to find the optimal model parameters.Therefore,it has a strong ability to cope with out lier features.Finally,after lanes have been successfully detected,lane positions can be tracked with tracking algorithms such as Kalman filter or particle filters to refine the detection results and predict lane positions in a more efficient way.
B.Conventional Image-Processing-Based Lane Detection Algorithms
Vision-based lane detection can be roughly classified into two categories:feature-based[9]−[19]and model-based[20]−[29].Feature-based methods rely on the detection of lane marking features such as lane colors,textures,and edges.For example,in[9],noisy lane edge features were detected using the Sobel operator and the road images were divided into multiple subregions along the vertical direction.Suddamalla et al detected the curves and straight lanes using pixel intensity and edge information with lane markings being extracted with adaptive threshold techniques[10].To remove camera perspective distortions from the digital images and extract real lane features,lane markings can be efficiently detected with a perspective transform.Collado et al.created a bird-view of the road image and proposed an adaptive lane detection and classification method based on spatial lane features and the Hough transform algorithm[11].A combination of IPM and clustered particle filters method based on lane features was used to estimate multiple lanes in[12].The authors claimed that it is less robust if a strong lane model is used in the context and they only used a weak model for particle filter tracking.Instead of using color images,lanes can also be detected using other color format images.The general idea behind the color format transform is that the yellow and white lane markings can be more distinct in other color domain,so the contrast ratio is increased.In[13],lane edges were detected with an extended edge linking algorithm in the lane hypothesis stage.Lane pixels in the YUV format,edge orientation,and width of lane markings were used to select the candidate edge-link pairs in the lane verification step.In[14],lanes were recognized using an unsupervised and adaptive classifier.Color images were first converted to HSV format to increase the contrast.Then,the binary feature image was processed using the threshold method based on the brightness values.Although in some normal cases the color transform can benefit the lane detection,it is not robust and has limited ability to deal with shadows and illumination variation[4].
Borkar et al.proposed a layered approach to detect lanes at night[15].A temporal blur technique was used to reduce video noise and binary images were generated based on an adaptive local threshold method.The lane finding in another domain algorithm(LANA)represented lane features in the frequency domain[16].The algorithm captured the lane strength and orientation in the frequency domain and a deformable template was used to detect the lane markings.Results showed that LANA was robust under varying conditions.In[17],a spatiotemporal lane detection algorithm was introduced.A series of spatiotemporal images were generated by accumulating certain row pixels from the past frames and the lanes were detected using Hough transform applied on the synthesized images.In[18],a real-time lane detection system based on FPGA and DSP was designed based on lane gradient amplitude features and an improved Hough Transform.Ozgunalp and Dahnoun proposed an improved feature map for lane detection[19].The lane orientation histogram was first determined with edge orientations and then the feature map was improved and shifted based on the estimated lane orientation.
In general,feature-based methods have better computational efficiency and are able to accurately detect lanes when the lane markings are clear.However,due to too many constraints are assumed,such as the lane colors and shapes,the drawbacks of these methods include less robustness to deal with shadows and poor visibility conditions compared to model-based methods.
Model-based methods usually assume that lanes can be described with a specific model such as a linear model,a parabolic model,or various kinds of spline models.Besides,some assumptions about the road and lanes,such as a flat ground plane,are required.Among these models,spline models were popular in previous studies since these models are flexible enough to recover any shapes of the curve lanes.Wang et al. fitted lanes with different spline models[20],[21].In[20],a Catmull-Rom spline was used to model the lanes in the image.In[21],the lane model was improved to generate a B-snake model,which can model any arbitrary shape by changing the control points.In[22],a novel parallel-snake model was introduced.In[23],lane boundaries were detected based on a combination of Hough transform in near- field areas and a river- flow method in far field areas.Finally,lanes were modelled with a B-spline model and tracked with a Kalman filter.Jung and Kelber described the lanes with a linear parabolic model and classified the lane types based on the estimated lane geometries[24].Aly proposed a multiple lane fitting method based on the integration of Hough transform,RANSAC,and B-spline model[25].Initial lane positions were first roughly detected with Hough transform and then improved with RANSAC and B-spline model.Moreover,a manually labelled lane dataset called the Caltech Lane dataset was introduced.
The RANSAC algorithm is the most popular way to iteratively estimate the lane model parameters.In[26],linear lane model and RANSAC were used to detect lanes,and a Kalman filter was used to refine the noisy output.Ridge features and adapted RANSAC for both straight and curve lane fitting were proposed in[27],[28].The ridge features of lane pixels,which depend on the local structures rather than contrast,were defined as the center lines of a bright structure of a region in a greyscale image.In[29],[30],hyperbolic model and RANSAC were used for lane fitting.In[30],input images were divided into two parts known as far- field area and near- field area.In near- field area,lanes were regarded as straight lines detected using the Hough transform algorithm.In far- field area,lanes were assumed to be curved lines and fitted using hyperbolic model and RANSAC.
In[31],a conditional random field method was proposed to detect lane marks in urban areas.Bounini et al.introduced a lane boundary detection method for an autonomous vehicle working in a simulation environment[32].A least-square method was used to fit the line model and the computation cost was reduced by determining a dynamic ROI.In[33],an automated multi-segment lane-switch scheme and an RANSAC lane fitting method were proposed.The RANSAC algorithm was applied to fit the lines based on the edge image.A lanes witch scheme was used to determine lane curvatures and choose the correct lane models from straight and curve models to fit the lanes.In[34],a Gabor wavelet filter was applied to estimate the orientation of each pixel and match a second-order geometric lane model.Niu et al.proposed a novel curve fitting algorithm for lane detection with a two-stage feature extraction algorithm(LDTFE)[35].A density based spatial clustering of application with noise(DBSCAN)algorithm was applied to determine whether the candidate lane line segments belong to ego lanes or not.The identified small lane line segments can be fitted with curve model and this method is particularly efficient for small lane segment detection tasks.
Generally speaking,model-based methods are more robust than feature-based methods because of the use of model fitting techniques.The noisy measurement and the out lier pixels of lane markings usually can be ignored with the model.However,model-based methods usually entail more computational cost since RANSAC has no upper limits on the number of iterations.Moreover,model-based methods are less easy to be implemented compared to the feature-based systems.
C.Machine Learning-Based Lane Detection Algorithms
Despite using conventional image processing-based methods to detect lane markings,some researchers focus on detecting lane marking using novel machine learning and deep learning methods.Deep learning techniques have been one of the hottest research areas in the past decade due to the development of deep network theories,parallel computing techniques,and large-scale data.Many deep learning algorithms show great advantages in computer vision tasks and the detection and recognition performance increases dramatically compared to conventional approaches.The convolution neural network(CNN)is one of the most popular approaches used for the object recognition research.CNN provides some impressive properties such as high detection accuracy,automatic feature learning,and end-to-end recognition.Recently,some researchers have successfully applied CNN and other deep learning techniques to lane detection.It was reported that by using CNN model,the lane detection accuracy increased dramatically from 80%to 90%compared with traditional image processing methods[36].
Li et al.proposed a lane detection system based on deep CNN and recurrent neural network(RNN)[37].A CNN was fed with a small ROI image that was used for multiple tasks.There are two types of CNN outputs.The first is a discrete classification result indicating if the visual cues are lane markers or not.If a lane is detected,then the other output will be the continuous estimation of lane orientation and location.To recognize the global lane structures in a video sequence instead of local lane positions in a single image,RNN was used to recognize the lane structures in sequence data with its internal memory scheme.Training was based on a merged scene with three cameras facing front,left side and rear area,respectively.It was shown that RNN can help recognize and connect lanes that are covered by vehicles or obstacles.
Gurghian et al.proposed another deep CNN method for lane marking detection using two side-facing cameras[38].The proposed CNN recognized the side lane positions with an end-to-end detection process.The CNN was trained with both real world images and synthesized images and achieved a 99%high detection accuracy.To solve the low accuracy and high computational cost problem,authors in[36]proposed a novel lane marking detection method based on a point cloud map generated by a laser scanner.To improve the robustness and accuracy of the CNN result,a gradual up-sampling method was introduced.The output image was in the same format as the input images to get an accurate classification result.The reported computation cost of each algorithm is 28.8s on average,which can be used for the off line high-precision road map construction.
In[39],a spiking neural network was used to extract edge images and lanes were detected based on Hough transform.This was inspired by the idea that a human neuron system produces a dense pulse response to edges while generating a sparse pulse signal to flat inputs.A similar approach can be found in[40].The study proposed a lane detection method based on RANSAC and CNN.One eight-layer CNN including three convolution layers was used to remove the noise in edge pixels if the input images were too complex.Otherwise,RANSAC was applied to the edge image directly to fit the lane model.He et al.proposed a dual-view CNN for lane detection[41].Two different views,which were the front view and top view of the road obtained from the same camera,were fed into the pre-trained CNN simultaneously.The CNN contained two sub-CNN networks to process two kinds of input images separately and concatenate the results eventually.Finally,an optimal global strategy taking into account lane length,width,and orientations was used to threshold the final lane markings.
Instead of using the general image processing and machine learning methods,some other researchers used evolution algorithms or heuristic algorithms to automatically search lane boundaries.For example,Revilloud et al.proposed a novel lane detection method using a confidence map and a multi-agent model inspired by human driver behaviors[42].Similarly,an ant colonies evolution algorithm for the optimal lane marking search was proposed in[43].A novel multiplelane detection method using directional random walking was introduced in[44].In that study,a morphology-based approach was used to extract lane mark features at the beginning.Then,the directional random walking based on a Markov probability matrix was applied to link candidate lane features.The proposed algorithm required no assumption about the road curvatures or lane shapes.
In summary,it can be stated that machine learning algorithms or intelligent algorithms increase the lane detection accuracy significantly and provide many efficient detection architectures and techniques.Although these systems usually require more computational cost and need a large number of training data,these systems are more powerful than conventional methods.Therefore,many novel efficient and robust lane detection methods with lower training and computation requirements are expected to be developed in the near future.
III.INTEGRATION METHODOLOGIES FOR VISION-BASED LANE DETECTION SYSTEMS
A.Integration Methods Introduction
Although many studies have been done to enable the accurate vision-based lane detection,the robustness of the detection systems still cannot meet the real-world requirements,especially in urban areas,due to the highly random properties of the traffic and the state of roads.Therefore,a reasonable way to enhance the lane detection system is to introduce redundancy algorithms,integrate with other object detection systems or use sensor fusion methods.It is a common agreement among automotive industries that a single sensor is not enough for vehicle perception tasks.Some companies such as Tesla,Mobileye,and Delphi developed their own intelligent on-vehicle perception systems using multiple sensors like cameras,and radar(especially the millimeter-wave radar).In this section,the integration methods will be classified into three levels,which are algorithm level,system level,and sensor level,as shown in Fig.2.
Specifically,the algorithm level integration combines different lane detection algorithms together to comprehensively determine reasonable lane positions and improve the robustness of the system.In the system level integration,different object detection systems work simultaneously with real-time communication with one another.Finally,in the sensor level integration,multi-modal sensors are integrated.The proposed sensor fusion methods in this level are believed to improve the robustness of the lane detection system most significantly.In the following sub-sections,the aforementioned multi-level integration techniques will be described in detail and the studies conducted within each scope will be discussed.
B.Algorithm Level Integration
Integration of vision-based lane detection algorithms has been widely used in the past.Previous studies focused on two main integration architectures,which can be summarized as parallel and serial combination methods.Moreover,feature based and model-based algorithms can also be combined together.Serial combination methods were commonly seen in the past.Studies in[20],[21],[25]demonstrate the examples of methods that serially combined the Hough transform,RANSAC,and spline model fitting methods.Another method followed in multiple studies involves applying a lane tracking system after the lane detection procedure to refine and improve the stability of the detected lanes[5],[21],[22],[45]−[47].For lane tracking,Kalman filter and particle filter were two most widely used tracking algorithms[4].Shin proposed a super-particle filter combining two separate particle filters for ego lane boundary tracking[48].In[49],a learning-based lane detection method was proposed and tracked with a particle filter.The learning-based algorithm requires no prior road model and vehicle velocity knowledge.
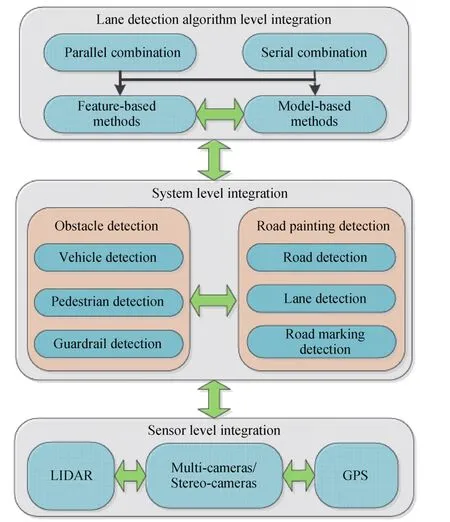
Fig.2.Diagram for lane detection integration level.
Parallel combination methods can be found in[50],[51].In[50],a monocular vision-based lane detection system was combined with two independent algorithms in parallel to make a comprehensive judgement.The first algorithm used a lane marking extractor and road shape estimation to find potential lanes.Meanwhile,a simple feature-based detection algorithm was applied to check the candidate lanes chosen by the first algorithm.If the final results from the two algorithms are comparable with each other,the detection result is accepted.Labayrade et al.proposed three parallel integrated algorithms to pursue a robust lane detection with higher confidence[51].Two lower level lane detection algorithms,namely,lateral and longitudinal consistent detection methods,were processed simultaneously.Then,the sampling points of the detected lanes given by these two lower level detection algorithms were tested.If the results were close to each other,the detection was viewed as a success and the average position from the two algorithms was selected as the lane position.
Some studies also combined different lane features to construct a more accurate feature vector for lane detections.In[52],the lane detection system was based on the fusion of color and edge features.Color features were used to separate road foreground and background regions using Otsus method,while edges were detected with a Canny detector.Finally,curve lanes in the image were fitted using the Lagrange interpolating polynomial.In[53],a three-features based automatic lane detection algorithm(TFALDA)was proposed.Lane boundary was represented as a three-feature vector,which includes intensity,position,and orientation values of the lane pixels.The continuity of lanes was used as the selection criteria to choose the best current lane vector that was at the minimum distance with the previous one.
Although parallel integration methods improve the robustness of the system by introducing redundancy algorithms,the computation burden will increase correspondingly.Therefore,a more efficient way is to combine algorithms in a dynamic manner and only initiate a redundancy system when it is necessary.
C.System Level Integration
Lane detections in the real world can be affected by surrounding vehicles and other obstacles,which may have similar color or texture features to the lane markings in the digital images.For instance,the guardrail usually shows strong lane-like characteristics in color images and can easily cause false lane detections[54]−[56].Therefore,integrating the lane detection system with other on board detection systems will enhance the accuracy of the lane detection system.Obstacle detections and road painting detections are two basic categories of vision-based detection techniques,as shown in Fig.2.By introducing an obstacle,noise measurement or out lier pixels can be filtered.Similarly,road recognition can narrow down the searching area for lane detections and lead to a reasonable result.
Lane detection algorithms usually require lane features for model fitting tasks.Nearby vehicles,especially passing vehicles are likely to cause a false detection result due to occlusion and similar factors.With the detection of surrounding vehicles,the color,shadow,appearance,and the noise generated by the vehicles ahead can be removed and a higher accuracy of lane boundaries can be achieved[30].In[30],[57]−[60],the lane detection result was reported to be more accurate with a front-vehicle detection system.This reduces the quantities of false-lane features,and improves the model fitting accuracy.Cheng et al.proposed an integrated lane and vehicle detection system.Lane markings were detected by analysing road and lane color features,and the system was designed so as not to be influenced by variations in illumination[57].Those vehicles that have similar colors to the lanes were distinguished on the basis of the size,shape,and motion information.
Sayanan and Trivedi[58]proposed a driver assistance system based on an integration of lane and vehicle tracking systems.With the tracking of nearby vehicles,the position of surrounding vehicles within the detected lanes and their lane change behaviours can be recognized.Final evaluation results showed an impressive improvement compared to the results delivered by the single lane detection algorithm.In[61],a novel lane and vehicle detection integration method called an efficient lane and vehicle detection with integrated synergies(ELVIS)was proposed.The integration of vehicles and lane detection reduces the computation cost of finding the true lane positions by at least 35%.Similarly,an integrated lane detection and front vehicle recognition algorithm for a forward collision warning system was proposed in[62].Front vehicles were recognized with a Hough Forest method.The vehicle tracking system enhanced the accuracy of the lane detection result in high-density traffic scenarios.
In terms of road painting recognition,Qin et al.proposed a general framework of road marking detection and classification[63].Four common road markings(lanes,arrows,zebra crossing,and words)were detected and classified separately using a support vector machine.However,this system only identified the different kinds of road markings without further context explanation of each road marking.It is believed that road marking recognition results contribute to a better understanding of ego-lanes and help decide current lane types such as right/left turning lanes[64],[65].Finally,a large amount of research was dedicated to the integration of road detection and lane detection[4],[7],[66]−[68].The Tesla and Mobileye are all reported to use a road segmentation to refine the lane detection algorithms[69],[70].Road area is usually detected before lanes since an accurate recognition of road area increases the lane marking searching speed and provides an accurate ROI for lane detection.Besides,since the road boundaries and lanes are correlated and normally have the same direction,a road boundary orientation detection enhances the subsequent lane detection accuracy.Ma et al.proposed a Bayesian framework to integrate road boundary and lane edge detection[71].Lane and road boundaries were modelled with a second-order model and detected using a deformable template method.
Fritsch et al.proposed a road and ego-lane detection system particularly focusing on inner-city and rural roads[7].The proposed road and ego-lane detection algorithm was tested in three different road conditions.Another integrated road and ego-lane detection algorithm for urban areas was proposed in[72].Road segmentation based on an illumination invariant transform was the prior step for lane detection to reduce the detection time and increase the detection accuracy.The outputs of the system consisted of road region,ego-lane region and markings,local lane width,and the relative position and orientation of the vehicle.
D.Sensor Level Integration
Sensor fusion dramatically improves the lane detection performance since more sensors are used and perception ability is boosted.Using multiple cameras including monocular,stereo cameras,and combining multiple cameras with different fields of view are the most common ways to enhance the lane detection system[46],[55],[73].In[73],a dense vanishing point detection method for lane detections using stereo cameras was proposed.The combination of global dense vanishing point detection and stereo camera makes the system very robust to various road conditions and multiple lane scenarios.Bertozzi and Broggi proposed a generic obstacle and lane detection(GOLD)system to detect obstacles and lanes based on stereo cameras and IPM images[55].The system was tested on the road for more than 3000km and it showed robustness under exposure to shadow,illumination,and road variation.In[74],three wide- field cameras and one tele-lens camera were combined and sampled at the frequency of 14Hz.Raw images were converted to the HSV format and IPM was performed.In[75],an around view monitoring(AVM)system with four fish eye cameras and one monocular front-looking camera were used for lane detection and vehicle localization.The benefit of using the AVM system is that a whole picture of the topview of the vehicle can be generated,which contains the front,surrounding,and rear views of the vehicle in one single image.
Instead of using only camera devices,the lane detection system can also be realised by combining cameras with global positioning system(GPS)and RADAR[76]−[82].An integration system based on vision and RADAR was proposed in[71].RADAR was particularly used for the road boundary detection in ill-illuminated conditions.Jung et al.proposed an adaptive ROI-based lane detection method aimed at designing an integrated adaptive cruise control(ACC)and lane keeping assistance(LKA)system[76].Range data from ACC was used to determine a dynamic ROI and improve the accuracy of the monocular vision-based lane detection system.The lane detection system was designed using a conventional method,which includes edge distribution function(ED),steerable filter,model fitting and tracking.If nearby vehicles were detected with the range sensor,all the edge pixels were eliminated to enhance the lane detection.Final results showed that recognition of nearby vehicles based on the range data improved the lane detection accuracy and simplified the detection algorithm.
Cui et al.proposed an autonomous vehicle positioning system based on GPS and vision system[77].Prior information like road shape was first extracted from GPS and then used to refine the lane detection system.The proposed method was extensively evaluated and found to be robust in varying road conditions.Jiang et al.proposed an integrated lane detection system in a structured highway scenario[78].Road curvatures were determined using GPS and digital maps in the beginning.Then,two lane detection modules designed for straight lanes and curved lanes,repectively,were selected accordingly.Schreiber et al.introduced a lane marking-based localisation system[83].Lane markings and curbs were detected with a stereo camera and vehicle localisation was performed with the integration of a global navigation satellite system(GNSS),a high accuracy map and a stereo vision system.The integrated localisation system achieved an accuracy up to a few centimetres in rural areas.
An integrated lane departure warning system using GPS,inertial sensor,high-accuracy map,and vision system was introduced in[84].The vsion-based LDWS is easily affected by various road conditions and weather.A sensor fusion scheme increases the stability of the lane detection system and makes the system more reliable.Moreover,a vision-based lane detection system and an accurate digital map help reduce the position errors from GPS,which leads to a more accurate vehicle localization and lane keeping.
Lidar was another widely used sensor and was the primary sensor used in most autonomous vehicles in the DARPA challenge[85],[86],due to its high accuracy and robust sensing ability.Lane markings are on-road paintings that have higher reflective properties than the road surface in the 3D points cloud map given by Lidar.Lidar can detect lane markings according to those high reflectance points on the road.Lidar uses multiple channel laser lights to scan surrounding surfaces and build 3D images.Therefore,Lidar and vision integrated lane detection systems can be more accurate and robust to shadows and illumination change than vision-based systems[87].Shin et al.proposed a lane detection system using camera and Lidar[88].The algorithm consists of ground road extraction,lane detection with multi-modal data,and lane information combination.The proposed method shows a high detection accuracy performance(up to 90%accuracy)in real world experiments.Although camera and Lidar-based methods can cope with curved lanes,shadow,and illumination issues,they require a complex co-calibration of the multimodal sensors.Amaradi et al.proposed a lane-following and obstacle detection system using camera and Lidar[89].Lanes were first detected with Hough transform.Lidar was used to detect obstacles and measure the distance between the egovehicle and front obstacles to plan an obstacle free driving area.In[56],a fusion system of multiple cameras and Lidar was proposed to detect lane markings in urban areas.The test vehicle was reported as the only vehicle that used vision-based lane detection algorithm in the final stage of the DARPA urban challenge.The system detected multiple lanes followed by the estimation and tracking of the center lines.Lidar and cameras were first calibrated together to detect road paint and curbs.Then,Lidar was used to reduce the false positive detection rate by detecting obstacles and drivable road area.
According to the implementation angle and surveying distances,the laser scanner device can efficiently identify the lane marking.Lane detection using this laser reflection method has also been widely applied[80],[90]−[94].Li et al.proposed a drivable region and lane detection system based on Lidar and vision fusion at the feature level[80].The test bed vehicle used two cameras mounted at different angles and three laser scanners.The algorithm detected the optimal drivable region using multi-modal sensors.The system was able to work under both structured and unstructured roads without any prior terrain knowledge.A laser-camera system for lane detection was introduced in[91].The two dimensional laser reflectivity map was generated on the roof of the vehicle.Instead of using constrained rule-based methods to detect lanes on the reflectivity map,a density-based spatial clustering of application with noise(DBSCAN)algorithm was applied to automatically determine the lane positions and the number of lanes in the field according to the 2D map.In[93],an integration system with laser scanner and stereo cameras was proposed.The system achieved an accurate driving area detection result even in the desert area.However,in some unstructured road or dirty road,the signals from laser scanner can carry more noise than the frame signals from the camera.Therefore,a signal filtering for the laser scanner and a sensor fusion are usually needed for the integrated systems.

TABLE IFACTORS INFLUENCING LANE DETECTION SYSTEM

Fig.3.Lane detection evaluation architecture with two different evaluation methodologies.
In this section,some sensors that are relevant to lane detection task are reviewed.Other sensors such as vehicle CAN-bus sensor and inertial measurement unit(IMU)are also commonly used in the construction of a complete vehicle perception system.Although Lidar-based lane detection system can be more precise than other systems,the cost is still too high for public transport.Therefore,recent studies like[79]tend to fuse sensors such as GPS,digital map,and cameras,which are already available in commercial vehicles,to design a robust lane detection and driver assisting system.
IV.EVALUATION METHODOLOGIES FORVISION-BASED LANE DETECTION SYSTEMS
Most of the previous lane detection studies used visual verification to evaluate the system performance due to the lack of ground data,and only a few researchers proposed quantitative performance analysis and evaluation.In addition,lane detection evaluation is a complex task since the detection methods can vary across hardware and algorithms.There are not yet common metrics that can be used to comprehensively evaluate each aspect of lane detection algorithms.An accurate lane detection system in one place is not guaranteed to be accurate in another place since the road and lane situation in different countries or areas differ significantly.Some detection algorithms may even show significantly different detection results in days and nights.It is also not fair to say that a monocular vision-based system is not as good as a system with vision and Lidar fusion since the costis of the second systems are higher.
Therefore,the performance evaluation of lane detection systems is necessary and it should be noted that the best index for the lane detection performance is the driving safety issue and how robust the system is to the environment change.In this section,the evaluation methodologies used in studies are divided into off line evaluation and online evaluation categories,where the online evaluation can be viewed as a process of calculating the detection confidence in real time.The main evaluation architecture is shown in Fig.3.As mentioned earlier,a common vision-based lane detection system can be roughly separated into three parts,which are the pre-processing,lane detection,and tracking.Accordingly,evaluation can be applied to all these three parts and the performance of these modules can be assessed separately.In the following section,influencing factors that affect the performance of a lane detection system will be summarized first.Then,the off line and online evaluation methods used in past studies and other literature are described.Finally,the evaluation metrics are discussed.
A.Influential Factors for Lane Detection Systems
The vision-based lane detection systems previous studies are different from the hardware,algorithms,and application aspects.Some focused on the highway implementation while some were used in urban areas.An accurate highway-oriented lane detection system is not guaranteed to be accurate in urban road areas since more disturbance and dense traffic will be observed in such areas.Therefore,it is impossible to use one single evaluation method or metric to assess all the existing systems.Some important factors that can affect the performance of lane detection system are listed in Table I.A fair evaluation and comparison of lane detection systems should take these factors and the system working environment into consideration.Since different lane detection algorithms are designed and tested for different places,different road and lane factors in different places will affect the detection performance.Moreover,the data recording device,the camera or the other vision hardware is other aspects that can significantly influence lane detection systems.For example,the lane detection systems may have different resolutions and fields of view with different cameras,which will influence the detection accuracy.Finally,some traffic and weather factors can also lead to a different lane detection performances.
As shown in Table I,many factors can cause a less accurate detection result and make the performance vary with other systems.For example,some lane detection systems were tested under a complex traffic context,which had more disturbances like crosswalks or poor quality lane markings,while some other systems were tested in standard highway environments with few influencing factors.Therefore,an ideal way is to use a common platform for algorithm evaluation,which is barely possible in real life.Hence,a mature evaluation system should take as many influential factors as possible into account and comprehensively assess the performance of the system.One potential solution for these problems is using parallel vision architecture,which will be discussed in the next section.
In the following part,the methodologies and metrics that can be used to propose a reasonable performance evaluation system are described.
B.Off line Evaluation
Off line evaluation is commonly used in previous literatures.After the framework of a lane detection system has been determined,the system performance is first evaluated off line using still images or video sequences.There are some public datasets such as KITTI Road and Caltech Road[7],[25]that are available on the internet.KITTI Road dataset consists of 289 training images and 290 testing images separated into three categories.The road and ego-lane area were labelled in the dataset.The evaluation is usually done by using receiver operating characteristic(ROC)curves to illustrate the pixellevel true and false detection rate.Caltech Road dataset contains 1224 labelled individual frames captured in four different road situations.Both datasets focus on evaluating road and lane detection performance in urban areas.The main drawbacks of image-based evaluation methods are that they are less reflective of real traffic environments and the datasets contain limited annotated test images.
On the other hand,video datasets depict much richer information and enable the reflection of real-life traffic situations.However,they normally require more human resources to label ground-truth lanes.To deal with this problem,Borkar et al.proposed a semi-automatic method to label lane pixels in video sequences[95].They used the time-sliced(TS)images and interpolation method to reduce the labelling workload.The time-sliced images were constructed by selecting the same rows from each video frame and re-arranging these row pixels according to the frame order.Two or more TS images were required and the accuracy of ground truth lanes was directly proportional to the number of images.The lane labelling tasks are converted to point labelling in the TS images.After the labelled ground truth points were selected from each TS image,the interpolated ground-truth lanes can be recovered into the video sequence accordingly.The authors significantly reduced the ground truth labelling workload by converting lane labelling into few points labelling tasks.This method was further improved in[49]by using a so-called modified min-between-max thresholding algorithm(M2BMT)applied to both time-slices and spatial stripes of the video frames.
Despite the manual annotated ground truth,some researchers use the synthesis method to generate lane images with known position and curvature parameters in simulators[28],[56].Lopez et al.used MATLAB simulator to generate video sequences and ground truth lanes[28].Lane frames were created with known lane parameters and positions.This method was able to generate arbitrary road and lane models with an arbitrary number of video frames.Using a simulator to generate lane ground truth is an efficient way to assess the lane detection system under ideal road conditions.However,there are few driving simulators that can completely simulate real world traffic context at this moment.Therefore,the detection performance still has to be tested with real-world lane images or videos after evaluation using simulators.Another way is to test the system on real-world testing tracks to assess the lane detection system compared to the accurate lane position ground truth provided by GPS and high precision maps[79].
C.Online Evaluation
The online evaluation system combines road and lane geometry information and integrates with other sensors to generate a detection confidence.Lane geometry constraints are reliable metrics for online evaluation.Once the camera is calibrated and mounted on the vehicle,road and lane geometric characteristics such as the ego lane width can be determined.In[96],a real-time lane evaluation method was proposed based on width measurement of the detected lanes.The detected lanes were verified based on three criteria,which were the slopes and intercept of the straight lane model,the predetermined road width,and position of the vanishing point.The distribution of lane model parameters was analysed and a look-up table was created to determine the correctness of the detection.Once the detected lane width exceeds the threshold,re-estimation is proposed with respect to the lane width constraints.
In[5],the authors used a world-coordinate measurement error instead of using errors in image coordinates to assess the detection accuracy.A road side down-facing camera was used to directly record lane information,generate ground truth,and estimate vehicle position within the lanes.In[50],[51],real-time confidence was calculated based on the similarity measurement of the results given by different detection algorithms.The evaluation module usually assess whether the detected lane positions from different algorithms are within a certain distance.If similar results are obtained,then the detection results are averaged and a high detection confidence is reported.However,this method requires performing two algorithms simultaneously at each step,which increases the computation burden.
In[56],vision and Lidar-based algorithms were combined to build a confidence probability network.The travelling distance was adopted to determine the lane detection confidence.The system was said to have a high estimation confidence at certain meters in front of the vehicle if the vehicle can travel safely at that distance.Other online evaluation methods like estimating the offsets between the estimated center line and lane boundaries were also used in previous studies.Instead of using single sensor,vision-based lane detection results can be evaluated with other sensors such as GPS,Lidar,and highly accurate road models[56],[77].A vanishing point lane detection algorithm was introduced in[97].Vanishing points of the lane segments were first detected according to a probabilistic voting method.Then,the vanishing points along with the line orientation threshold were used to determine correct lane segments.To further reduce the false detection rate,a real time inter-frame similarity model for evaluation of lane location consistency was adopted.This real time evaluation idea was also under the assumption that lane geometry properties do not change significantly within a short period of continuous frames.
D.Evaluation Metrics
Existing studies mainly use visual evaluation or simple detection rates as evaluation metrics since there are still no common performance metrics to evaluate the lane detection performance.Li et al.designed a complete testing scheme for intelligent vehicles mainly focusing on the whole vehicle performance rather than just the lane detection system[98].In[20], five major requirements for a lane detection system were given:shadow insensitivity,suitable for unpainted roads,handling of curved roads,meeting lane parallel constraints,and reliability measurement.Kluge introduced feature level metrics to measure the gradient orientation of the edge pixels and the angular deviation entropy[99].The proposed metrics are able to evaluate the edge points,the road curvatures,and the vanishing point information.
Veit et al.proposed another feature-level evaluation method based on a hand labelled dataset[100].Six different lane feature extraction algorithms were compared.The authors concluded that the feature extraction algorith,which combines the photometric and geometric features achieved the best result.McCall and Trivedi examined the most important evaluation metrics to assess the lane detection system[101].They concluded that it is not appropriate to merely use detection rates as the metrics.Instead,three different metrics,which include standard deviation of error,mean absolute error,and standard deviation of error in rate of change were recommended.
Satzoda and Trivedi introduced five metrics to measure different properties of lane detection systems and to examine the trade-off between accuracy and computational efficiency[102].The five metrics consist of the measurement of lane feature accuracy,ego-vehicle localisation,lane position deviation,computation efficiency and accuracy,and the cumulative deviation in time.Among these metrics,the cumulative deviation in time helps determine the maximum amount of safety time and can be used to evaluate if the proposed system meets the critical response time of ADAS.However,all of these metrics pay much attention to the detection accuracy assessment and do not consider the robustness.
In summary,a lane detection system can be evaluated separately from the pre-processing,lane detection algorithms,and tracking aspects.Evaluation metrics are not limited to measuring the error between detected lanes and ground truth lanes but can also be extended to assess the lane prediction horizon,the shadow sensitivity,and the computational efficiency,etc.The specific evaluation metrics for a system should be determined based on the real-world application requirements.Generally speaking,there are three basic properties of a lane detection system,which are the accuracy,robustness,and efficiency.The primary objective of the lane detection algorithm is to meet the real-time safety requirement with acceptable accuracy and at low computational cost.Accuracy metrics measure if the algorithm can detect lanes with small errors for both straight and curved lanes.Lane detection accuracy issues have been widely studied in the past and many metrics can be found in literatures.However,the robustness issues of the detection system have not yet been sufficiently studied.Urban road images are usually used to assess the robustness of the system since more challenges are encountered in such situations.However,many other factors can also affect lane performances,such as weather,shadow and illumination,traffic,and road conditions.
Some representative lane detection studies are illustrated in Table II.Specifically,in Table II,the pre-processing column records the image processing methods used in the literature.The integration column describes the integration methods used in the study,which may contain different levels of integration.Frame images and visual assessment in the evaluation column indicate that the proposed algorithm was only evaluated with still images and visual assessment method without any comparison with ground truth information.As shown in previous studies,a robust and accurate lane detection system usually combines detection and tracking algorithms.Besides,most advanced lane detection systems integrate with other objects detection systems or sensors to generate a more comprehensive detection network.
V.DISCUSSION
In this part,the current limitations of vision-based lane detection algorithm,integration,and evaluation are analyzed based on the context of above sections.Then,the framework of parallel vision-based lane detection system,which is regarded as a possible efficient way to solve the generalization and evaluation problems for lane algorithm design,is discussed.
A.Current Limitation and Challenges
Lane detection systems have been widely studied and successfully implemented in some commercial ADAS products in the past decade.A large volume of literatures can be found,which use vision-based algorithms due to the low cost of camera devices and extensive background knowledge of image processing.Although the vision-based lane detection system suffers from illumination variation,shadows,and bad weathers,it is still widely adopted and will continue dominating the future ADAS markets.The main task of a lane detection system is to design an accurate and robust detection algorithm.Accuracy issues were the main concerns of previous studies.Many advanced algorithms that are based on machine learning and deep learning methods are designed to construct a more precise system.However,the robustness issues are the key aspects that determine if a system can be applied in real life.The huge challenge to future vision-based systems is to maintain a stable and reliable lane measurement under heavy traffic and adverse weather conditions.
Considering this problem,one efficient method is to use the integration and fusion techniques.It has been proved that a single vision-based lane detection system has its limitation to deal with the varying road and traffic situation.Therefore,it is necessary to prepare a back-up system that can enrich the functionality of ADAS.Basically,a redundancy system can be constructed in three ways based on algorithm,system,and sensor level integration.Algorithm integration is a choice with the lowest cost and easy to implement.A system level integration combines lane detection system with other perception systems such as road and surrounding vehicle detection to improve the accuracy and robustness of the system.However,the two aforementioned integration methods still rely on camera vision systems and have their inevitable limitations.Sensor level integration,on the other hand,is the most reliable way to detect lanes under different situations.
Another challenging task in lane detection systems is to design an evaluation system that can verify the system performance.Nowadays,a common problem is the lack of public benchmarks and data sets due to the difficulty of labelling lanes as the ground truth.Besides,there are no standard evaluation metrics that can be used to comprehensively assess the system performance with respect to both accuracy and robustness.Online confidence evaluation is another important task for lane detection systems.For ADAS and lower level automated vehicles,the driver should be alerted once a low detection confidence occurs.In terms of autonomous vehicles,it is also important to let the vehicle understand what it does in the lane detection task,which can be viewed as a self-aware and diagnostic process.
B.Apply Parallel Theory Into Vision-Based Lane Detection Systems
Considering the aforementioned issues,a novel parallel framework for lane detection system design will be proposed in this part.The parallel lane detection framework is expected to be an efficient tool to assess the robustness as well as the lane detection system.
Parallel system is the product of advanced control systems and the computer simulation systems.It was introduced by Fei-Yue Wang and developed to control and manage complex systems[105]−[107].The parallel theory is an efficient tool that can compensate the hard modelling and evaluating issue for the complex systems.The main objective of parallel system is to connect the real-world system with one or multiple artificial virtual systems that are in the cyberspace.The constructed virtual systems will have similar characteristics as the real world complex system but not exactly the same.Here,parallel refers to a parallel interaction between the real-world system and its corresponding virtual counterparts.By connecting these systems together,analyzing and comparing their behaviors,the parallel system will be able to predict the future statuses of both the real-world system and the artificial one.According to the response and behaviors of the virtual system,the parallel system will automatically adjust the parameters of the realworld model to control and manage the real-world complex system such that an efficient solution is applied.
The construction of parallel system requires the ACP theory as the background knowledge.ACP is short for Artificial Society,Computational experiments,and Parallel execution,which are three major components of parallel systems.The complex system is firstly modeled using a holistic approach,whereas the real-world system is represented using an artificial system.After this step,the virtual system in the cyberspace becomes another solution domain of the complex system,which contributes to the potential complete solution along with the natural system in the physical space.It is hard to say that one solution will satisfy all the real world challenges.An effective solution for the control of complex systems should have the ability to deal with various situations occurring in the future.However,the limited testing scenarios in the real world cannot guarantee the potential solution being comprehensively tested.Therefore,the computation experiment module will execute a large number of virtual experiments according to the constructed artificial system in last step.Finally,since there are normally no unique solution for complex systems,the parallel execution provides an effective fashion to validate and evaluate various solutions.The parallel execution module will online update the local optimal solution to the real world system that is found in the cyberspace for better control and management[108].
Recently,a parallel vision architecture based on the ACP theory has been summarised and introduced to the computer vision society[109].The parallel vision theory offers an efficient way to deal with the detection and evaluation problems of the vision-based object detection systems.Similarly,the general idea of ACP theory within the parallel vision scope is to achieve perception and understanding of the complex real world environment according to the combination of virtual realities and the real world information.In terms of lane detection tasks,the first artificial society module can be used to construct a virtual traffic environment and various road scenes using computer graphics and virtual reality techniques.Next,in the computation experiment module,the unlimited labelled traffic scene images and the limited real world driving images can be combined together to train a powerful lane detector using machine learning and deep learning methods.This process also contains two sub-procedures,namely,learning and training,testing and evaluating.The large-scale dataset will benefit the model training task.After that,a large amount of near-real data will sufficiently facilitate the model evaluation.Finally,in the parallel execution process,the lane detection model can be trained and evaluated with a parallel scheme in both real world and virtual environment.The lane detector can be online optimized according to its performance in the two parallel worlds.
In addition,the application of ACP parallel vision systems will efficiently solve the generalization and evaluation problems due to the utilization of the large-scale near-real synthesis images.To improve the generalization of the lane detection system,the detectors can be tested on virtual environments that have high similarity with the real world.The performance can also be sufficiently evaluated from the accuracy and robustness perspectives.Various computational experiments and model testing procedures can be continuously executed.In the computational experiments,the cutting-edge deep learning and reinforcement learning techniques can be applied to improve the accuracy and generalisation of the system without considering the lack of labelled data.Meanwhile,some deep learning models like the generative adversarial networks(GAN)can be used to generate near-real road scene images which can reflect the real world road characteristics such as illumination,occlusion,and poor visualization.In addition,in the virtual computational world,the GAN can be trained to discriminate whether the lane markings exist in the input image.
Fig.4 shows a simplified architecture of the ACP-based lane detection system.The road and lane images are in parallel collected from the real world and the artificial cyberspace.The real world data is then used as a guide for generating nearreal artificial traffic scenes,which are automatically labeled.Both the real world data and synthesis data are fed into the data-driven computational level.

Fig.4.Simple architecture of the ACP-based parallel lane detection and evaluation system.
Machine learning and deep learning methods are powerful tools in this level.For various driving scenarios occurred in both real world and the parallel virtual world,the model training process will try to come up with the most satisfying model.After that,the lane detection model will be exhaustively evaluated and validated in the cyberspace world according to large scale labeled data.Once a well-trained and evaluated lane detection model is constructed,the model can be applied in parallel to both the real world environment and the virtual world for real-time lane detection evaluation.Due to the safety,human resource limitation,and energy consumption,the number of experiments in real world is limited,which may not be able to deal with all the challenges from the road[110],[111].In contrary,the experiments in the parallel virtual world are safer and economical to be applied.Moreover,the virtual world can simulate many more situations that are less possibly occur in the real world.Meanwhile,by using the online learning technique,the experience from the continuous learning and testing module in the virtual world will improve the real world performance.
Some previous literatures have partially applied the parallel vision theory into the construction of lane detection systems[28],[56].These studies try to simulate the lane detection model within the simulation environment,and process the lane detection model with the first two steps of the ACP architecture.However,to construct an actual parallel system,the ACP architecture should be treated as a whole.The final parallel execution step of the ACP theory is the core of a parallel system.This step will online update the real world model and adjust the corresponding model parameters according to the testing results in the parallel worlds.This step is also the core step,which guarantees that the learned lane detection model can be satisfied by various real-world driving scenarios.Beside applying parallel the theory to the design of intelligent transport and vehicles,one has widely used it in some other domains.For example,Deep Mind use multiple processors to train their Alpha Go based on the deep reinforcement learning methods[112].The idea behind the reinforcement learning in this case is actually to construct a parallel virtual world for the virtual go player to do exercise.In summary,the parallel theory is drawing increasing attention from the researchers.The utilization of parallel vision techniques in the future is expected to become another efficient way to solve the generalization and evaluation problems for the lane detection algorithms.The ACP-based parallel lane detection system will not only assist to build an accurate model that is well tested and assessed,but also enable the intelligent vehicles to carefully adjust their detection strategies in real-time.Meanwhile,since there are too many different lane detection methodologies which can hardly be evaluated uniformly,a public virtual simulation platform can be used to compare these algorithms in the future.Those algorithms which achieve satisfactory performances in the parallel virtual worlds can then be implemented in the real world.
VI.CONCLUSION
In this study,vision-based lane detection systems are reviewed from three aspects,namely,algorithms,integration,and evaluation methods.Existing algorithms are summarized into two categories,which are conventional image processing based,and novel machine learning(deep learning)-based methods.Next,previous integration methods of the lane detection system are divided into three levels,which are algorithm level,system level,and sensor level.In algorithm level,multiple lane detection and tracking algorithms are combined in a serial or parallel manner.System level integration combines vision-based lane detection with other road marking or obstacle detection systems.Sensor fusion enhances the vehicle perception system most significantly by fusion of multi-modal sensors.Finally,lane detection evaluation issues are analyzed from different aspects.Evaluation methods are divided into off line performance assessment and online real time confidence evaluation.
As mentioned earlier,although the vision-based lane detection system has been widely studied in the past two decades,it is hard to say that research in this area has been mature.In fact,there are still many critical studies that need to be done,such as efficient low-cost system integration and the evaluation system design,especially the construction of parallel lane detection systems.Moreover,an increasing number of advanced object detection algorithms and architectures have been developed to optimize the lane detection systems.The continuous studies and the applications of these techniques will further benefit the ADAS and automated driving industry.The ACP-based parallel lane detection approach holds significant potentials for future implementation.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Deep Scalogram Representations for Acoustic Scene Classification
- A Mode-Switching Motion Control System for Reactive Interaction and Surface Following Using Industrial Robots
- Adaptive Proportional-Derivative Sliding Mode Control Law With Improved Transient Performance for Underactuated Overhead Crane Systems
- On“Over-sized"High-Gain Practical Observers for Nonlienear Systems
- H∞Tracking Control for Switched LPV Systems With an Application to Aero-Engines
- Neural-Network-Based Terminal Sliding Mode Control for Frequency Stabilization of Renewable Power Systems