改进的线性预测滤波算法在机载LiDAR点云中提取DEM的应用
2018-07-21程铁洪廖永福胡冬清
程铁洪廖永福胡冬清
(1.江西省电力设计院 江西南昌 330096;2.江西省交通设计研究院 江西南昌 330209)
1 概述
随着机载激光雷达 (Light Detection and Ranging,LiDAR)技术的发展,它在各行各业得到了广泛的应用,尤其是机载激光雷达能快速准确的获取地面物体的三维坐标,使得生成大规模、高精度的DEM已经越来越方便。但原始点云中不仅含有地面点,还有较多的非地面点。因此,通过机载激光雷达技术获取地面点的三维坐标,进而生成DEM,首先要解决的就是滤波问题,LiDAR点云数据滤波就是从原始的LiDAR点云中滤掉非地面点,保留有效的地形信息。目前主要的滤波算法包括Lindenberger[1]和 Kilian[2]等人提出的数学形态学滤波算法、Axelsson[3]提出逐渐加密三角网(TIN)滤波算法以及Kraus和 Pfeifer[4]提出的线性预测滤波算法等。
大部分的机载LiDAR点云滤波算法的基本原理是基于邻近激光脚点高程突变的原理,基于该原理有以下几个基本假设:(1)一定范围内的局部区域高程最低点为地面点;(2)扫描的区域相对比较平缓,没有剧烈的地形起伏[5-6];(3)地形曲面由一片片连续光滑的空间曲面所构成。各种滤波算法都有一定的局限性,而线性预测滤波算法对不同地形的适应性较好,处理结果精度较高,因此被广泛的使用。
传统的线性预测滤波算法仍存在以下不足:(1)噪声点的影响,噪声点对后期地形趋势面的拟合效果和滤波参数设置都有较大影响,原算法未考虑噪声点的影响;(2)数据分块大小固定,原算法未考虑不同地形条件应合理分块的情况;(3)滤波循环终止条件不够明确;(4)滤波参数计算复杂,当滤波效果不佳时经常需要对参数进行反复的调试,人工干预性较大;(5)在森林茂密地区,当地面点较少时,地形趋势面拟合效果不好,很难获得林区真实的地形情况。
针对上述不足,对传统线性预测在以下几个方面进行了改进:(1)噪声点剔除,通过分块内高程分布直方图对点云进行了有效的去噪;(2)数据格网化分块,根据地形条件和点云密度不同对点云进行分块处理,能有效提高滤波效率;(3)迭代终止条件判断,通过引入偏度的概念,计算迭代过程中点云残差的偏度sk值,可以有效的判定迭代次数;(4)滤波参数设置,通过分析残差分布直方图,确定滤波过程中的重要参数g和w,提高了算法对地形的适应性。
2 算法原理及技术流程
2.1 传统的线性预测滤波算法
传统的线性预测算法在进行滤波时,首先将原始数据划分为若干小块,通过对分块内点云拟合参考表面,这个参考表面一般为二次曲面[7],其解析式为:
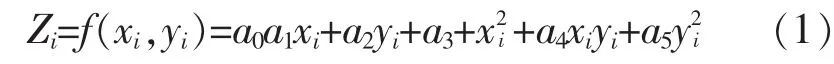
式中,i为点号,x,y为平面坐标,z为拟合后的点高程,a0至a5为拟合曲面参数。
然后用原始数据各点的高程值减去对应参考表面的拟合值,得到该点的拟合残差,根据残差确定该点在下一次迭代计算中的权值,权函数关系式为:

式中,pi表示第i个点的权值,vi表示第i个点的残差,参数a,b的值决定了权函数的陡峭程度,通常依靠经验a,b可分别取1和4,w为某分块区域内地形的最大起伏。在一次迭代过程中,依据权函数关系式和残差对点云进行分类时,引入了滤波重要参数偏移量g和w,用于判断点云的属性,权函数示意图如下图1所示:
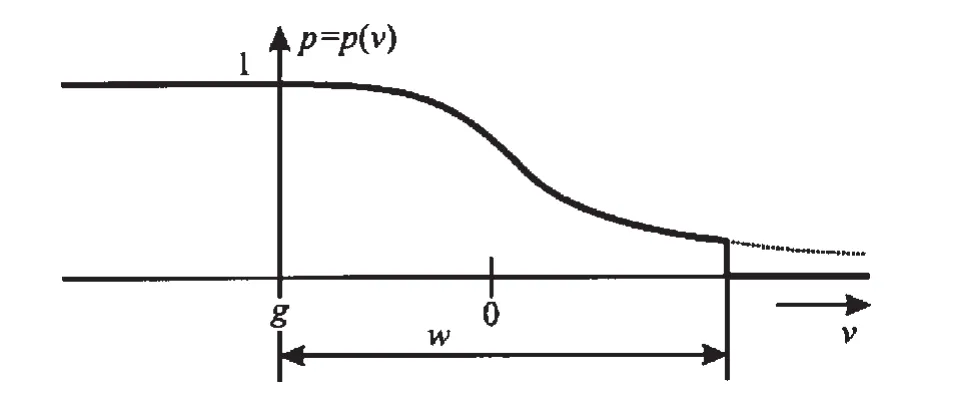
图1 权函数示意图
参数g的计算传统线性预测算法主要通过残差分布直方图计算,方法主要有:(1)用事先预期的地面点测量的精度来计算,从残差分布直方图的原点(残差为0)往左移,直到计算出的标准差与预先预期的地面点精度σT相同时,这个移动量就是的g值,如下图 2(a)部分所示;(2)从残差累计曲线图上计算出向左移动每个位置的标准差,然后绘制累计标准差曲线图,如下图2(b)部分所示,找出标准差达到极小值时,对应的向左移动的距离为g的值(3)根据激光雷达的穿透率,g的值就是残差直方图移动到地面点有一半处的值。

图2 计算g值所用方法示意图
2.2 改进后的算法流程
改进后的线性预测滤波算法流程如下图3所示,主要在噪声点剔除、数据格网化分块、迭代终止条件判断以及重要滤波参数设置上进行了改进。
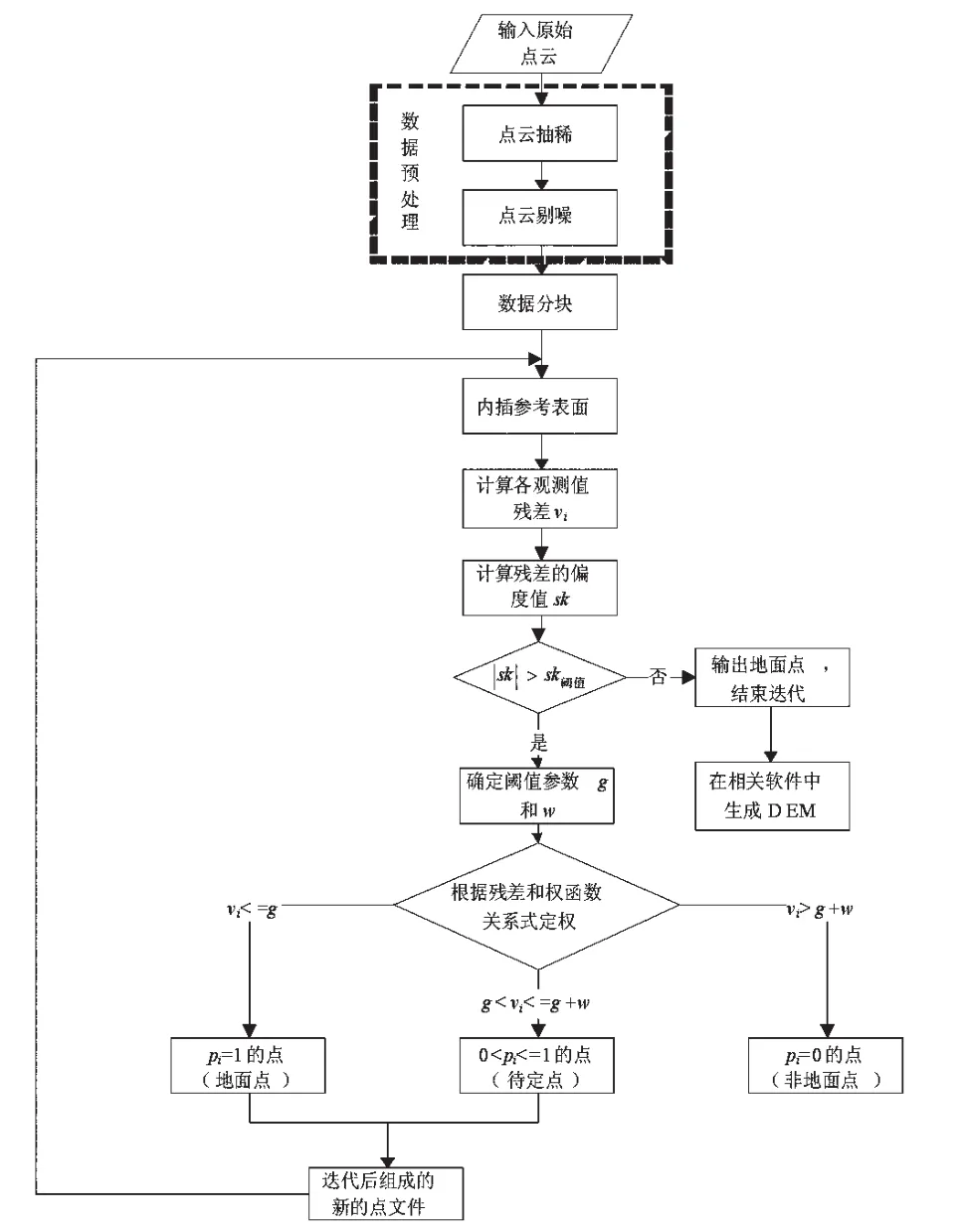
图3 改进后的线性预测滤波算法流程图
2.3 改进算法的关键技术
针对传统线性预测滤波算法存在的不足,做出以下改进:
(1)点云剔噪。根据噪声点和非噪声点在空间分布的特点,本文研究采用基于高程分布特点的点云去噪方法。该算法的基本思想是基于噪声点相对于局部邻近点在高程上存在显著的突变现象,非噪声点在高程分布上处于相对连续的状态,这也是目前大多数机载LiDAR点云去噪算法的基本假设。该算法需要对数据集进行分块,在每个分块内绘制所有点的高程分布直方图,如下图4所示,高程的间隔尽量要小,如1米较为适宜,从图中可以看出,非噪声点在高程上呈现连续分布状态,噪声点则呈现离散分布且与非噪声点分隔开,通过高程分布直方图可以将噪声点和非噪声点在空间的分布特点很好的展示出来,从而将噪声点剔除。

图4 sample11区某分块内点云高程分布统计直方图
(2)点云数据格网化。在进行数据格网化分块时,主要解决两个核心的问题,一是格网大小,另一个是建立区块索引机制。滤波时,一个格网就是一个滤波窗口,在考虑格网宽度时,主要是考虑窗口的大小不能小于窗口内最大地物面积,若滤波窗口小于最大地物区域,该窗口的滤波结果就会出现系统性误差,在城区地势较为平坦的地形,格网的宽度一般可设置为 40×40m[7],在大型建筑物密集的区块,设置为40~100m不等。依据实际情况做出调整,在地形陡峭的山区,格网的宽度应适当减小。建立区块索引机制是对分块后点云进行滤波时的快速定位,并且将所在该区块的点云集中处理,通常根据分块后各点所在的行列号来进行索引。
具体来说,在数据格网化分块时,具体流程如下:
(1)读取数据预处理后的点云数据;
(2)索引整个区域内平面坐标X和Y的最大最小值 Xmax、Xmin 以及 Ymax、Ymin;
(4)再根据各点的平面坐标将点云分到各个格网中并获得它们所在的行列号,分块的同时,计算落入各个格网的点云数。
格网索引信息获取由公式(3)计算得到,具体如下:

公式(3)中,row和column分别表示整个区域格网的行列数,c表示该区域内格网的宽度,Xmax、Xmin以及Ymax、Ymin分别表示整个区域内平面坐标的最大最小值,floor表示对计算结果取整数,xp、yp分别表示格网内任意点的平面坐标,i、j则分别表示该任意点所在格网的行列号。点云数据格网化示意图如下图5所示:
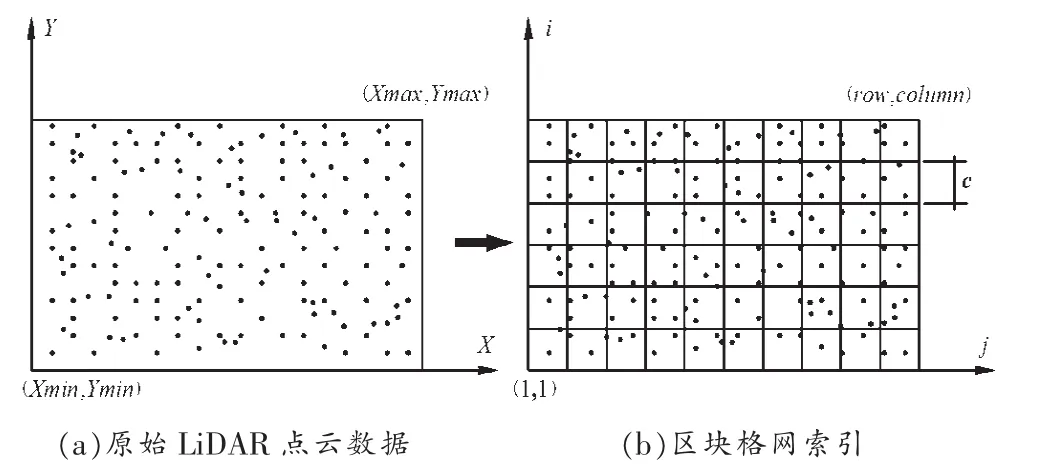
图5 点云数据格网化示意图
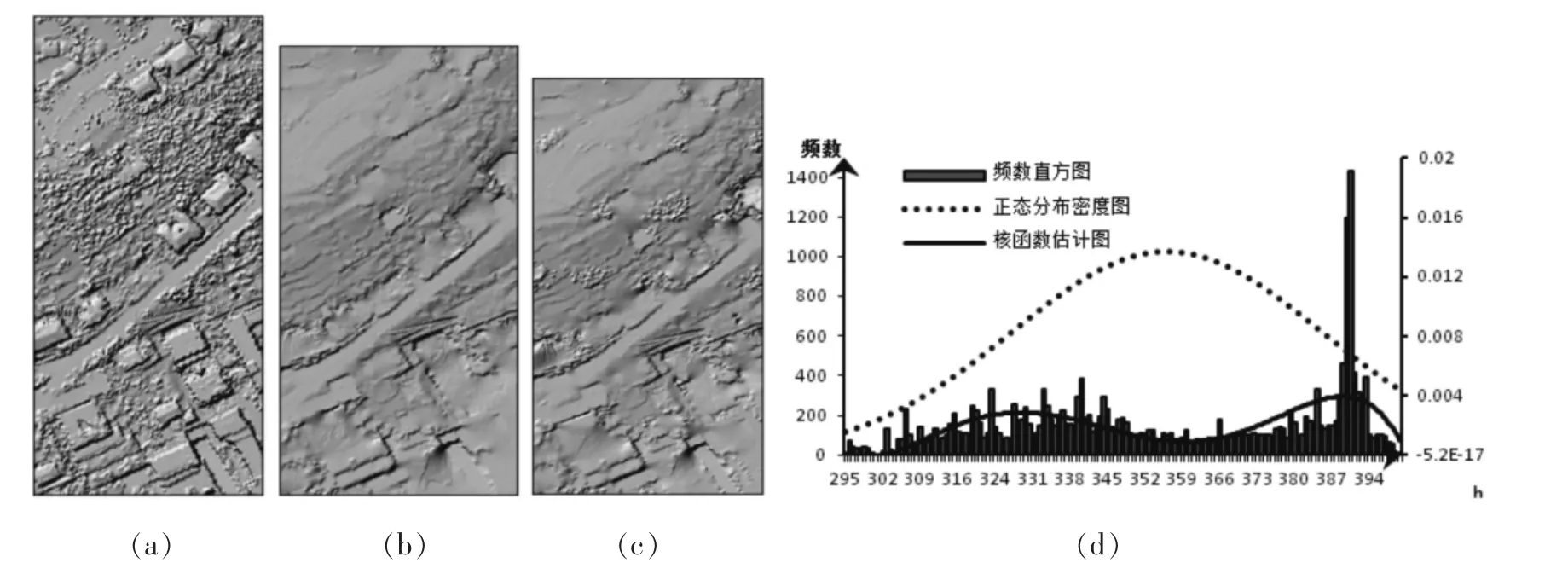
(3)迭代终止条件判断。引入偏度的概念用于判断迭代终止条件时,由数理统计中的中心极限定理可知,只含地面点的残差分布的概率密度函数会服从正态分布[8],点云中非地面点的存在干扰了原有的正态分布,使得点云的整体分布呈现某种偏态分布。因此,滤波的过程就是要剔除非地面点,只保留地面点,也就是使受到非地面点干扰的正偏态分布重新变为正态分布的过程,滤波直到sk=0或接近0即可结束。在实际的判断过程中发现,由于非地面点无法完全剔除,滤波后残差的概论密度函数并不会完全达到正态分布,也就是说偏度值很难达到0,如下图6所示,表示某平坦地区滤波结束后残差分布直方图和概率密度函数曲线,计算得偏度sk=0.43,概率密度函数曲线近似的服从正态分布,此时,该区域滤波已达到比较好的结果。因此,在判断时,根据实际地形考虑滤波难度时对迭代终止时的偏度值设置了一个阈值 sk阈值(sk阈值>0),若某次迭代结束残差分布的偏度的绝对值|sk|小于偏度阈值sk阈值,即|sk| ①平坦地区:0= ②地形起伏大山区:0= 图6 滤波后地面点残差频数分布直方图 改进后的迭代终止判断条件,无需考虑迭代次数,无需判断两次迭代间地形趋势面是否变化,避免了较大的人工干预。 (4)滤波参数g和w的确定。利用残差分布直方图来确定滤波参数,首先,要分析残差分布直方图的特点,本文从不同地形条件出发,总结了不同地形条件下残差分布直方图的共同特点,如下图7所示,主要特点表现为以下几个方面: ①从整体来看,残差分布直方图不服从正态分布,而是向非地面点(正残差部分)偏移,整体呈正偏态分布; 1.2.3 实验仪器和试剂 美国Waters生产的ACQUITYTM型串联质谱仪、PE公司生产的非衍生化多种氨基酸、肉碱和琥珀酰丙酮测定试剂盒(以后简称试剂盒)、艾本森MicBio-IV型孵育震荡器、Vortex Mixer XW-80A混匀器以及打孔钳(打孔柱直径3 mm)。 ②地面点(负残差部分)的残差分布比较集中,呈近似正态分布,非地面点分布较零散,且残差相差较大; ③在复杂地形条件下,地面点残差分布呈多峰现象。 图7 不同地形条件下的残差分布直方图(首次拟合) 采用原算法中提到的第三种方法,即:g的值就是残差直方图原点出发,向左移动到地面点的残差占整个残差一半位置时的值,移动的距离即为g的值。在通过残差分布直方图分析w的取值时,首先,w是用来区分哪些点为非地面点的外阈值,从残差分布直方图表现为正态分布曲线右半部分趋于0或残差发生新的突变处的地方,如下图8所示。 图8 通过残差分布直方图分析g和w取值方法 本文实验所用数据均来自国际摄影测量和遥感学会(ISPRS)在线发布的参考数据作为实验数据,该数据对每个点都做了人工分类,标定地面点和非地面点。本文实验选取了其中4处比较有代表性的地形进行实验,Sample11(陡峭山坡)、Sample12(密集建筑物)、Sample51(茂密的林区)以及 Sample71(大型构筑物)。 (1)定性分析 下图9至图12是4块实验区域滤波前后点云生成的DEM及滤波后地面点的高程频数直方图,其中(a)表示滤波前点云生成的DEM,(b)表示人工分类地面点生成的参考DEM,(c)表示滤波后点云生成的DEM,(d)表示滤波后地面点生成的高程频数直方图。 图9 Sample11滤波前后点云生成的DEM及滤波后地面点高程频数直方图(sk=2.78) 图10 Sample12滤波前后点云生成的DEM及滤波后地面点高程频数直方图(sk=1.34) 图11 Sample51滤波前后点云生成的DEM及滤波后地面点高程频数直方图(sk=1.25) 图12 Sample71滤波前后点云生成的DEM及滤波后地面点高程频数直方图(sk=1.92) 通过对实验区定性分析可以看出:在地形较陡峭的山区,Sample11滤波效果不佳;在地形较平坦的城区和林区,Sample12和Sample51滤波精度较高;在有大型构筑物的地形条件下,Sample71存在地形过分割现象,但总体保留了地形的趋势面,说明改进后的算法具有较好的适应性,并且从滤波后残差的偏度值也能反映滤波总结较好。 (2)定量分析 对四个实验区域 Sample11、Sample12、Sample51以及Sample71进行滤波算法的定量分析。用I类误差(将地面点漏分为地物点的错误率),II类误差(将地物点错分为地面点的错误率总误差)以及总误差(反应将点云错分漏分加权后的总误差)来评定滤波的准确性,算法改进前后三类误差对比图如下图13所示。 通过对实验区定量分析可以看出:改进后的算法I类误差总体减小,尤其是在地势坡度大,起伏度大的地方,如Sample11和Sample71区域,在地势较平坦或者起伏不大的区域,如Sample12和Sample51区域,I类误差和原算法相当;虽然造成II类误差有所增大,但II类误差的点在可视化条件下通过人工干预较容易剔除;从总误差来看,改进后的算法总误差明显降低,尤其是在坡度和地势起伏较大的地方,总误差的大小反映滤波算法的可行性。因此,从定量分析角度来看,改进后的算法在部分区域优于原算法,一定程度上提高了滤波精度,较好的保留了地形的趋势面。 图13 算法改进前后三类误差错误率比较 通过对改进后的滤波算法进行了定性和定量分析,从分析的结果来看,改进后的算法有以下特点和优势: (1)在地形平坦或地势起伏不大的区域,改进后的算法和原算法滤波效果相当,且都达到较高的精度。 (2)在坡度较大或地势起伏剧烈的区域,原算法的滤波效果显著降低,改进后的滤波算法更加注重对地面点的保留,虽然II类误差有所增大,但总误差却有所下降,且更好的保留了地形的趋势面,使得滤波后生成的DEM更加符合真实地形,显示出改进后的算法精度更高,增强了算法的适应性。 (3)改进的算法增加了滤波后点云高程分布图的偏度计算来评估滤波的质量,这在一定程度上能辅助对滤波结果的评估,尤其是在原始点云无人工分类的情况下,这种方法切实可行。


3 实验与分析
3.1 实验数据
3.2 滤波结果分析




4 结论
