稳健回归分析
2018-07-14胡良平
胡良平
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029
1 概 述
1.1 何为稳健回归分析
设用Y代表因变量,X1、X2、…、Xm分别代表m个自变量,则多重线性回归模型可以表示为:
Y=β0+β1X1+β2X2+…+βmXm+ε
(1)
式中β0为总体截距,β1、β2、…、βm分别为各个自变量所对应的总体偏回归系数,ε为随机误差,常假定其服从正态分布。偏回归系数βi(i=1,2,…,m)表示在其他自变量固定不变的情况下,Xi每改变一个测量单位时所引起的因变量Y的平均改变量。多重线性回归模型的样本回归方程可以表示为:
(2)
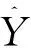
如何求出模型(1)中的参数(包括截距项和回归系数)呢?当资料满足一些前提条件(例如模型的误差项服从正态分布、自变量互相独立、不存在严重的异常点)时,只需要采取普通的最小二乘法(简称OLS估计法,也叫做最小平方法)来构造求解回归系数的正规方程组,然后解此方程组,就可获得全部参数的估计值。但是,当资料中存在严重异常点时,就需要采用“稳健回归分析方法”来给出参数的估计值。
所谓稳健回归分析,就是在构建多重线性回归模型(1)时,不以普通的最小二乘法来构造求解回归系数的正规方程组,而是依据某些改进的做法来构造求解回归系数的正规方程组。其目的就是依据推导出来的用于估计回归参数的计算公式使参数的估计结果具有尽可能好的稳定性,即尽可能降低或消除异常点对回归分析结果的影响。
1.2 稳健回归分析应用的场合
当拟做多重线性回归分析的原始数据存在较大比例的“异常点”且自变量间不存在严重多重共线性时,采用此方法构建多重线性回归模型,可以最大限度地消除“异常点”对建模结果造成的影响。
1.3 稳健回归分析的原理
此法的关键在于使估计出来的回归系数比较稳定,其实质就是设法修改“普通最小二乘法”,使构造出来的正规方程组对“异常点”不敏感,再通过类似于“迭代再加权最小二乘法”等方法求解正规方程组,从而获得各回归系数相对稳定的估计值。具体的方法有多种,例如L估计、R估计、M估计、S估计和MM估计等[1-2]。其中有些估计方法还可以作进一步细分,例如M估计可进一步分为“Huber估计”“Tukey估计”和“中位数估计”。由于这些估计方法涉及很深的数学知识,在文献[1]中用了8页篇幅介绍了前述提及的估计方法,感兴趣的读者可参阅有关文献,故此处从略。
2 基于稳健回归分析解决实际问题
2.1 此法可否解决多重共线性问题
2.1.1问题与数据结构
【例1】沿用文献[3]中的“问题与数据”,并基于派生变量得到的“最优回归模型”所决定的“数据集”,来提出下面的“新问题”:即“weight”的回归系数为“-88.00801”,这个“负值”表明:体重越重的人收缩压(SBP)越低,这似乎不符合临床专业知识。尽管计算出来的因变量的预测值在专业上都成立,且模型残差的方差=122.32418、R2=0.9931,这些结果都提示所构建的多重线性回归模型很好。但毕竟存在回归系数的正负号不符合专业知识的“严重瑕疵”,这是一个需要彻底解决的“疑难问题”!
2.1.2所需要的SAS程序
尝试采用“稳健回归分析方法”解决上述提及的“疑难问题”。所需要的SAS程序如下:
data a1;
input id age height weight bmi sbp;
cards;
(此处输入文献[3]表1中50行6列数据)
;
run;
/* 以上程序为了创建数据集a1 */
data a2;
set a1;
x1=age*age; x2=age*height; x3=age*weight;
x4=age*bmi; x5=height*height; x6=height*weight;
x7=height*bmi; x8=weight*weight; x9=weight*bmi;
x10=bmi*bmi;
run;
/* 以上程序是在数据集a1基础上创建数据集a2,它增添了10个派生变量 */
proc reg data=a2;
model sbp=age weight x3 x6-x10/noint;
quit;
/* 以上程序是调用REG过程并基于数据集a2拟合文献[3]中那个‘最佳’回归模型 */
proc robustreg data=a2 method=m seed=100;
model sbp=age weight x3 x6-x10/noint;
quit;
/* 以上程序是调用ROBUSTREG过程并基于数据集a2和M估计方法拟合文献[3]中那个‘最佳’回归模型 */
/*接下去,将上面SAS过程步中的关键词“method=m”依次修改为:method=lts、method=s和method=mm,就是调用ROBUSTREG过程并基于数据集a2且分别用LTS估计法、S估计法和MM估计法来拟合文献[3]中那个“最佳”回归模型 */
【SAS程序说明】在以上的SAS程序中,用“/* ……… */”注释语句作了说明。
2.1.3SAS输出结果及其解释
以下将上面SAS程序中的5个过程步的输出结果以浓缩的方式呈现出来,见表1。
【说明】比较上述由“REG过程”与基于“ROBUSTREG过程”并分别采用“M估计法”“LTS估计法”“S估计法”和“MM估计法”对同一个具有严重共线性问题的资料进行多重线性回归分析的结果可知:它们估计的“参数值”比较接近,但仍没有消除多重共线性对回归系数的严重影响(尤其是weight前的回归系数为负值且其绝对值还比较大,不符合临床专业知识)。也就是说:SAS/STAT中的“ROBUSTREG过程”不能解决“多重共线性问题”。要想消除自变量间多重共线性的影响,常用的方法有两种,第一种就是采用“主成分回归分析”,见文献[3];第二种就是采用“岭回归分析”,参见本期中的《岭回归分析》一文。
2.2 此法可否解决资料中有较多异常点问题
2.2.1问题与数据结构
【例2】假定有一个总样本含量n=1000的数据集中包含10%异常点的资料,每组数据(即每个个体)包含三个变量(x1,x2,y)的观测值,见表2。

表1 五种估计参数方法估计“例1资料”的主要结果
注:C与E分别代表“参数估计值”与“标准误”;OLS、M、LTS、S、MM分别代表估计回归模型中参数的方法依次为普通最小二乘法、M估计法、LTS估计法、S估计法和MM估计法;第7列上为空,因为LTS估计法给出的误差项是“标准差”,与其他方法不一致(其他为“标准误”),故未呈现出来

表2 某资料中首尾各10组数据(n=1000)
注:此表省略编号为11到990之间的980行数据;在全部1000行数据中,最后100行数据为“异常点”,占10%
【特别说明】例2是人为构造的,它来自SAS 9.3的ROBUSTREG过程中的“样例”。三个变量“x1、x2和y”没有实际的专业含义,仅为了造出一个样本含量为1000且含10%异常点的数据集。
设定x1和x2及测量误差e都是服从标准正态分布的随机变量(其均值为0、方差为1),前900个y的数值按下面的模型(3)计算出来;最后100个y的数值按下面的模型(4)计算出来:
y=10+5*x1+3*x2+0.5*e
(3)
y=100+e
(4)
比较式(3)与式(4)可知:y的前900个数据中的每一个都在基数“10”基础上再加上三项并不大的数值,其平均值大约为“10+5+3=18”;而y的后100个数据中的每一个都在基数“100”基础上再加上一个随机误差,其平均值大约为100。由此可知:表2的1000行数据中,对因变量y而言,后100个y值明显大于前900个y值,故属于“异常值”,它们所对应的那100行数据点就属于“异常点”了。
【问题】试拟合表2中y依赖x1、x2变化的二重线性回归模型。
2.2.2所需要的SAS程序
(1)先用下面的一段SAS数据步程序产生表2中的1000行3列数据,创建数据集aa。
data aa (drop=i);
do i=1 to 1000;
x1=rannor(1234);
x2=rannor(1234);
e=rannor(1234);
if i>900 then y=100 + e;
else y=10+5*x1+3*x2+0.5*e;
output;
end;
run;
/* 以上程序产生1000组数据(x1,x2,y),其中,有10%的是异常值 */
(2)再用下面的SAS程序将数据集aa(即表2中的数据)拷贝成数据集a,然后再调用SAS过程进行建模(也可用前面例1中创建数据集a1的方法,此处从略)。
data a;
set aa;
proc reg data=a;
model y=x1 x2;
run;
proc robustreg data=a method=m seed=100;
model y=x1 x2;
run;
分别将上面的“method = m”后面的“m”替换成“lts”“s”和“mm”,就可得到另三种回归系数的稳健估计结果。
【SAS过程步程序说明】第1个过程步调用REG过程创建二重线性回归模型;从第2到第5个过程步都是调用ROBUSTREG过程构建二重线性回归模型,其区别在于它们分别采用M估计、LTS估计、S估计和MM估计方法来估计模型中的参数值。
2.2.3SAS输出结果及其解释
以上SAS程序中5个SAS过程步输出的主要结果列入表3中。

表3 五种估计参数方法估计“例2资料”的主要结果
注:C与E分别代表“参数估计值”与“标准误”;OLS、M、LTS、S、MM分别代表估计回归模型中参数的方法依次为“普通最小二乘法”、M估计法、LTS估计法、S估计法和MM估计法;第7列上为空,因为LTS估计法给出的误差项是“标准差”,与其他方法不一致(其他为“标准误”),故未呈现出来
由表3可知:当资料中存在10%异常点时,基于普通最小二乘法(OLS)给出的参数估计值偏离其真值(截距=10、x1前的斜率=5、x2前的斜率=3)很远,而基于“M估计法”“LTS估计法”“S估计法”和“MM估计法”给出的参数估计值都与其真值非常接近。再列出这5种算法对应的复相关系数平方[即y与(x1和x2)的相关系数的平方]分别为:0.0234(OLS法)、0.7788(M估计法)、0.9932(LTS估计法)、0.9928(S估计法)和0.7520(MM估计法)。其中,OLS估计法的复相关系数平方非常小,而LTS估计法的复相关系数平方最大。
2.3 小结
用ROBUSTREG过程时应选择哪一种“稳健估计”方法创建多重线性回归模型很难一概而论。一般来说,在拟合优度“Goodnes-of-Fit”评价的四个指标中,R-Square取值越大、另三个评价指标(因篇幅所限,在本文中省略了)取值越小,并且,回归系数的“标准误”越小越好,该估计方法的拟合效果就越好。就本例而言,总体来看,LTS估计法的效果最好。
最关键的问题在于:本例中的数据是基于上面的二重线性回归模型(3)产生出来的。这个模型意味着:截距项为10、x1前的回归系数为5、x2前的回归系数为3,在此基础上,加一个随机误差的二分之一。此处的“随机误差”是服从均值为0、方差为1的正态分布的随机误差。基于表3中的计算结果,可以写出五个模型的具体表达式,见式(5)-式(9)。

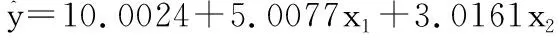

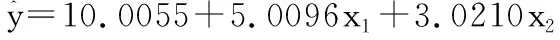

【结论】以模型(3)为“金标准”,模型(5)偏离很远;模型(6)-(9)的质量都很高。
若再结合“复相关系数平方”等评价指标综合评价,就本例而言,LTS估计法所得的结果最稳健。
