生成式对抗网络在抑郁症分类中的应用
2018-07-05北京工业大学信息学部北京100124磁共振成像脑信息学北京市重点实验室北京100124脑信息智慧服务北京市国际科技合作基地北京100124
刘 宁 杨 剑(北京工业大学信息学部 北京 100124)(磁共振成像脑信息学北京市重点实验室 北京 100124)(脑信息智慧服务北京市国际科技合作基地 北京 100124)
0 引 言
抑郁症是一种的精神障碍疾病,轻度抑郁症患者与有抑郁情绪的正常人表现很接近,不易诊断,且严重者会采取一些极端行为。目前,抑郁症难以有效诊断,这与其主要根据医师临床经验诊断的诊断方式有关。近年来,功能磁共振成像fMRI技术被广泛用于大脑的功能和结构研究,尤其在精神疾病的辅助诊断方面得到了研究者的高度关注,取得了很多成果[1-3]。但是,抑郁症研究仍面临fMRI数据难采集、样本少的问题,对此本文采用生成式对抗网络解决这个问题。
fMRI技术通过血氧水平依赖信号测量脑活动并推断不同脑区间的功能作用[1],是当前研究脑功能连接的主要手段。分析静息态fMRI数据的功能连接,常用的两种方法是: 1)基于种子的分析方法[2];2)纯数据驱动的方法,例如:独立成分分析ICA(Independent Component Analysis)[3]。ICA是一种无需借助先验脑图模板,直接分离出相互独立信号源的多元模式分析方法[4]。以它为基础得到的功能连接网络更合理、有效,因此本研究以组ICA分离出的独立成分构建动态功能连接网络。
目前,在探究抑郁症的发病原因和构建抑郁症的辅助诊断方法方面已取得了很多成果,如Sikora等[5]发现前扣带回凸显网络的功能连接增强、Kang等[6]通过多属性相关图构建区域功能连接网络并采用基于网络的分类器进行抑郁症预测、Perti等[7]对多种功能连接方法做了全面的分析[7]。然而,fMRI数据难采集、可用样本数远小于特征数,导致一些机器学习算法无法使用。例如,线性判别分析算法,由于样本维度远小于特征维度,导致该算法无法求出逆矩阵。在图像研究中常通过旋转、放缩、对折等操作增加图像样本,这样增加的样本实际上未出现新的样本,无法有效解决我们的问题。
深度学习领域中热门的生成式对抗网络GAN(Generative Adversarial Networks)是一种基于数据分布的生成模型,能够生成与训练数据同分布的样本[8],因此受到图像领域研究者广泛关注。通过GAN生成的样本保留了训练数据的属性,但GAN本身存在模型不可控和网络不稳定的问题。针对这些问题,研究者在GAN上做了一些改进以构成更强的网络:1) 增加限制条件构成条件生成式对抗网络CGAN(Conditional Generative Adversarial Networks)[9]以解决模型不可控的问题;2) 引入神经网络优化网络结构构成深度卷积生成式对抗网络DCGAN(Deep Convolutional Generative Adversarial Networks)[10]以解决网络不稳定问题。在DCGAN的基础上,对其增加条件限制构成条件卷积生成式对抗网络(CDCGAN),这种网络相对容易训练、模型可控且生成的样本更符合研究者的预期。因此,本文采用CDCGAN解决fMRI可用样本少的问题,同时需要说明的是目前还未有人将CDCGAN应用于fMRI数据分析,本文是首次应用此方法。
本文采用基于CDCGAN的分类方法研究了抑郁症分类问题,主要包括以下四个步骤:1)采用组ICA提取静息态fMRI数据的独立成分,以其中可以体现自发神经活动的独立成分为节点构建全脑的动态功能连接网络并提取特征;2)采用肯德尔排序相关系数法选取辨别能力强的前100维特征作为初始数据集,并使用CDCGAN扩充样本;3)构建扩充数据集,并采用我们提出的混合特征选择方法进行特征选择;4)应用多元模式分析法对抑郁症患者和正常被试进行分类。扩充数据集(采用CDCGAN)的最高正确率达92.68%远高于初始数据集(未采用CDCGAN)的最高正确率68.29%,说明了把CDCGAN应用于抑郁症分类是一种有效的探索,同时说明了本文提出的混合特征选择法更有效。
1 被试与fMRI数据
1.1 被 试
本研究使用的数据包括来自北京安定医院的20名抑郁症患者(平均年龄35.25±9.54岁,8名男性)和21名正常人(平均年龄34.19±9.01岁,8名男性),所有被试均签署了实验知情书。正常被试均未曾患过神经紊乱病且满足精神卫生筛选表和神经症筛选表的量化标准,抑郁症患者均符合美国精神障碍诊断与统计学手册(DSM-IV)和17项汉密尔顿评定量表(HAMD)的抑郁症诊断标准。
1.2 数据采集与预处理
本研究使用德国Siemens Trio Tim 3T磁共振扫描仪采集fMRI数据。采用平面回波成像进行序列扫描,在扫描过程中被试头部采用海绵垫固定,且要求保持闭眼、全身放松、尽量不进行思维活动。仪器扫描参数如下:重复时间TR=2 000 ms、回波时间TE=31 ms、旋转角FA=90°、视野FOV=24 cm×24 cm、矩阵大小Matrix=64×64、层间距Gap=0.8 mm、体素Voxel=3.75 mm×3.75 mm×4 mm。所有被试的扫描时长均为310 s,采集了152帧功能像数据。为了消除设备磁场初始不稳定性对数据采集的影响,剔除前10帧功能像数据,对剩余的142帧功能像数据进行预处理。本研究采用DPARSF软件对数据进行预处理,主要步骤包括时间层校正和头动校正、空间标准化、空间平滑。
2 基于CDCGAN的抑郁症分类
对预处理后的数据,采用组ICA提取独立成分,选择其中噪声相对小的成分构建动态功能连接网络并提取特征构建初始数据集,再通过CDCGAN构建扩充数据集,最后应用多元模式分析法进行分类。基于DCGAN的分类流程图如图1所示。

图1 基于DCGAN的分类流程图
2.1 组独立成分分析与后处理
ICA是一种多元数据驱动的分析方法,从数据出发,提取数据的特征,抽象出数据的模型,这些特性十分有利于fMRI数据的分析研究。本文采用空间ICA算法分析fMRI,通过GIFT工具箱中的组ICA算法提取经过预处理的数据的组水平空间独立成分。提取组独立成分的主要步骤:1) 对数据进行中心化和白化处理;2) 采用主成分分析对数据进行两次降维;3) 采用信息极大化算法(Infomax)进行空间独立成分的估计与分离;4) 数据反重构。
根据以往的研究经验[11],设定大脑fMRI信号独立成分的个数为70,且在ICASSO软件中重复了50次Infomax算法。采用组ICA所提取的70个独立成分的一部分是我们需要的脑网络成分,另一部分则是噪声信号。依据独立成分选择标准[11]采用视觉观察法,我们剔除了31个噪声较多的独立成分,并且通过匹配典型脑网络成分[11],最终确定这些独立成分分别为视觉网络、默认网络、感觉运动网络、听觉网络、注意网络、前额叶网络和基底核网络。
对每个被试所提取的39个独立成分的时间序列进行后处理以消除扫描仪漂移和高频生理噪声的影响。具体操作包括:1) 去除时间序列的线性、二次、三次趋势;2) 多元线性回归头动参数;3) 对时间序列异常值进行三阶样条插值;4) 高频截止频率为0.15 Hz的低通滤波。
2.2 提取动态功能连接特征
对每个被试,首先采用滑动时间窗技术构建其全脑动态功能连接网络,主要步骤如下:1) 用滑动时间窗(窗宽w=30,步长s=5)对经过后处理的39个独立成分的时间序列进行切割,得到23个窗;2) 对每个窗,以39个独立成分作为网络节点,以独立成分时间序列之间的Pearson相关系数作为连接边构建39×39的功能连接网络;3) 连接23个功能连接网络形成39×39×23的动态功能连接网络。Pearson相关系数计算公式:
(1)

2.3 特征选择
提取到的特征维度大且可能含有一些噪声,通过特征选择去除冗余特征进而加快运算速度、增强模型泛化能力。本文应用了两种特征选择方法:肯德尔排序相关系数法[4]和本文提出的混合特征选择法。
肯德尔排序相关系数法KTRCC(Kendall Tau Rank Correlation Coefficient)是一种基于非参数检验的度量方法,能够通过组间信息选出具有较强辨别能力的特征,但其没有考虑组内信息的影响。而基于Fisher准则的特征选择算法根据辨别能力越强的特征具有组内距离越小、组间距离越大的特性,以单个特征的Fisher比(组间离差和组内离差的比值)作为度量准则,对特征进行排序[12]。这种特征选择方法可以同时兼顾组内和组间信息,但由于它的度量准则采取比值的方式,可能会出现判别能力不同的特征有相同的Fisher比值。对此,本文提出了一种基于KTRCC和Fisher的混合特征选择方法,其能够兼顾组内和组间信息选出判别能力强的特征。混合特征选择法使用基于Fisher准则的特征选择算法对KTRCC选出的具有较强辨别能力的特征进行重排序。混合特征选择的具体步骤如下:1) 预选出由KTRCC得到的前N维具有较强辨别能力的特征;2) 用基于Fisher准则的特征选择方法对预选出的N维特征进行降序排序;3) 选取最前面一定数目(小于N)的特征作为分类预测样本的特征。
2.4 构建扩充数据集
我们通过CDCGAN扩充数据。首先,采用KTRCC特征选择法对41×23×741的数据集进行特征排序,并选取具有较强辨别能力的前100维特征作为初始数据集(41×23×100),这样可以去除冗余特征进而加快运算速度。然后,采用CDCGAN生成与初始数据具有相同分布的样本(生成样本的数目和初始数据中样本的数目相同)。最后,对同一被试的生成数据集和初始数据集进行连接,构成(41×46×100)扩充数据集。
DCGAN是GAN在卷积神经网络(CNN)上的扩展,由生成网络D与判别网络G构成。DCGAN的网络G增加约束条件y构成CDCGAN,且CDCGAN的网络G和网络D同样是经过结构调整的CNN,具体的结构调整如下:1) 取消所有的池化层,网络G中采用反卷积进行上采样,D网络中使用加入步幅的卷积代替池化;2) 网络G和网络D均采用batch normalization;3) 去掉全连接层,使网络变成全卷积网络;4) 网络G的最后一层使用tanh函数作为激活函数,而其他层均采用ReLU函数作为激活函数;5) 网络D的最后一层采用softmax函数,其他层采用LeakyReLU函数作为激活函数。CDCGAN结构图如图2,其中z表示服从某一分布的随机噪声,y表示约束条件,x表示真实训练数据,G(z|y)表示模型G生成的数据,D(x|y)表示模型D的判别结果。
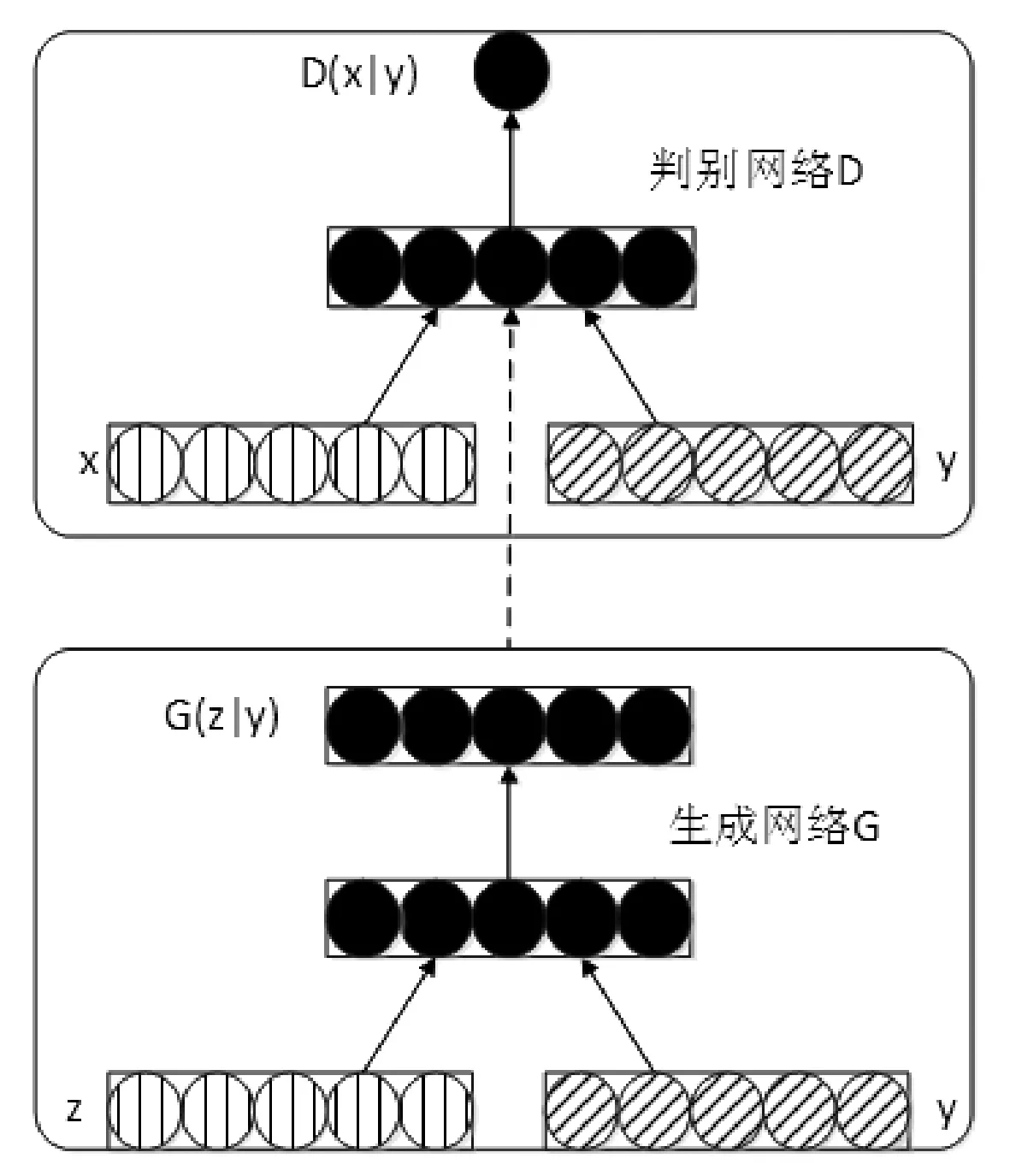
图2 CDCGAN结构图
生成网络G用于捕捉生成数据的分布,其与训练数据具有相同的分布,由服从某一分布的噪声z生成;判别网络D是一个二分类器,用于判别其输入是训练数据还是生成数据。CDCGAN的优化过程是一个“二元极小极大博弈”问题,训练时固定一方,更新另一方的网络权重,交替迭代,使对方错误最大化,最终双方达到纳什均衡。此时生成模型G估测出训练数据的分布,判别模型D的准确率保持50%。上述优化过程可表述为式(2):
Εz~pz(z)[log(1-D(G(z|y)))]
(2)
实验中CDCGAN的详细构件如下:1) 生成网络G和判别网络D采用了carpedm20提供的网络;2) y是被试的ID编号(1,…,41),且同一被试的所有窗拥有相同的ID编号;3) 噪声z是服从标准高斯分布的100维随机数;4) x为初始数据集。
2.5 分类器
在本研究中,我们采用线性支持向量机(LSVM)和线性判别分类器(LDC)对抑郁症患者和正常被试进行分类。LSVM对解决高维小样本问题有着良好的性能,其采用最小间隔最大化的思想通过训练集寻找最优分类决策面,并用此决策面预测测试样本的标签。LDC具有理论简单、速度快的优点,其将Bayes统计理论应用于判别分析,通过训练集学习出数据的后验概率分布并根据Bayes判据预测测试样本的标签。在分类时,由于每名被试的数据由多个时间窗对应的数据样本构成,因此每名被试的分类标签根据其所包含数据样本的分类结果按照投票机制确定(即少数服从多数)。
3 实验结果及分析
这一节展示了采用不同组合方法的最优结果、多次实验的平均结果以及分类正确率的平均增长率,并且对其中一组数据进行具体分析、比较了特征选择方法,也比较了不同数据生成方法的分类结果。在分类时,训练集为扩充数据集,而测试集为扩充数据集或初始数据集,分类器为LSVM或LDC,因此有四种采用了CDCGAN的组合(测试集- 分类器)方法:扩充数据集-LSVM(M-LSVM)、扩充数据集-LDC(M-LDC)、初始数据集-LSVM(O-LSVM)和初始数据集-LDC(O-LDC)。训练集和测试集均是初始数据集,采用LSVM和LDC分类器的组合方法分别为(T-LSVM)和(T-LDC)。
3.1 分类结果
应用混合特征选择法,采用T-LSVM和T-LDC组合方法的最佳分类正确率分别为0.658 5和0.682 9。这两种没有采用CDCGAN的组合方法,作为实验的基线对照。
对扩充数据集,本文采用混合特征选择方法进行特征选择,并利用LSVM分类器和LDC分类器进行分类。在采用留一交叉验证法分类时,训练集为40个被试的扩充数据集,测试集分别为剩余1个被试的初始数据集和扩充数据集。在两种测试集上采用不同的分类器都可以达到92.68%的分类正确率。由于CDCGAN中的噪声z与网络权重W的初始值采用随机值,这会影响生成的数据,因此我们运行了10轮CDCGAN实验,且每轮实验迭代1 000次,每迭代50次提取一次生成样本,共提取了20组生成样本,也就构造了10×20组扩充数据集。图3所示为其中4组扩充数据集在不同方法下的最优分类结果。
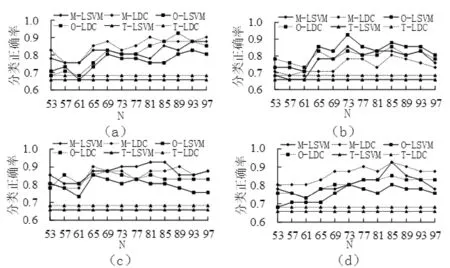
图3 采用CDCGAN及未采用CDCGAN的分类结果
由图3可看出,在采用相同的特征选择和分类器情况下,采用CDCGAN的最佳分类结果明显高于未采用CDCGAN的最佳分类结果。图中拐点是三角形的折线代表没有采用CDCGAN的基线对照分类结果,拐点为菱形和正方形的折线代表采用了CDCGAN的分类结果。实线表示采用LSVM分类器的分类结果,虚线表示采用LDC分类器的分类结果。
由于实验中的CDCGAN有随机初始值,为了评估采用CDCGAN模型的性能,对10×20组扩充数据集的总体情况做了汇总。图4表示参数N变化时,扩充数据集采用四种组合方法的最佳分类正确率相对于基线对照最佳分类正确率的平均增长率(均值±方差)结果。
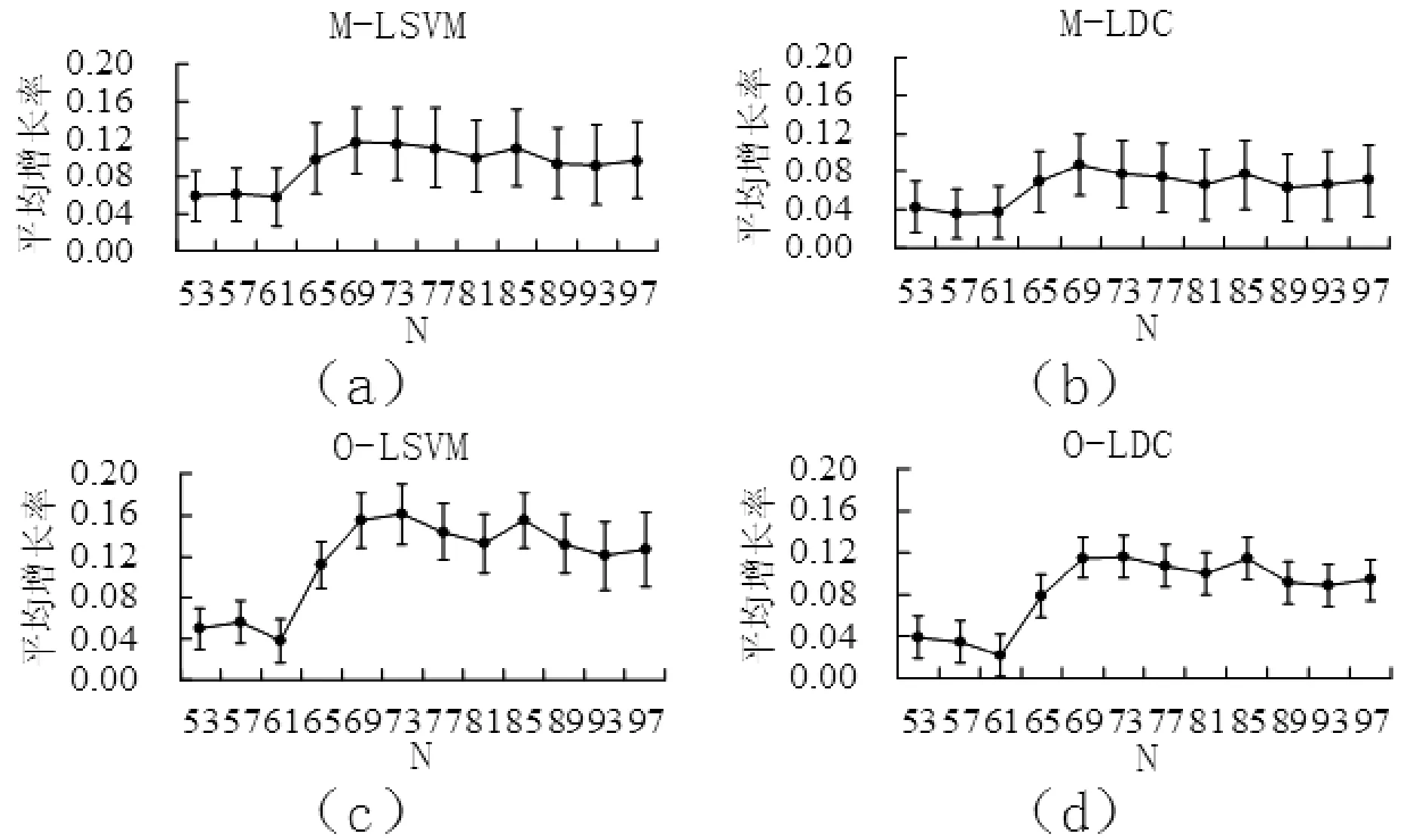
图4 关于N的最佳正确率的平均增长率
由图4可以看出,四种组合方法的最佳分类正确率的平均增长率均为正值。这说明CDCGAN方法有助于fMRI数据分类。为了进一步分析不同特征组合对分类的影响,我们在图5中展示了N=85时,不同特征维数的分类正确率的平均增长率。

图5 不同特征维数的分类结果
以上实验结果表明了应用CDCGAN可以显著地提高抑郁症分类正确率,也表明了抑郁症fMRI数据应用CDCGAN的可行性。
3.2 结果分析
分类过程中,采用留一交叉验证法对每名被试进行特征选择与分类,由于每次交叉验证中的训练集存在微小的差异,这将导致每次通过特征选择选出来的特征很可能不同。我们对图3中的(c)组数据进行了具体分析,比较了两种特征选择方法采用不同组合方法的最佳分类正确率。具体结果如表1所示。
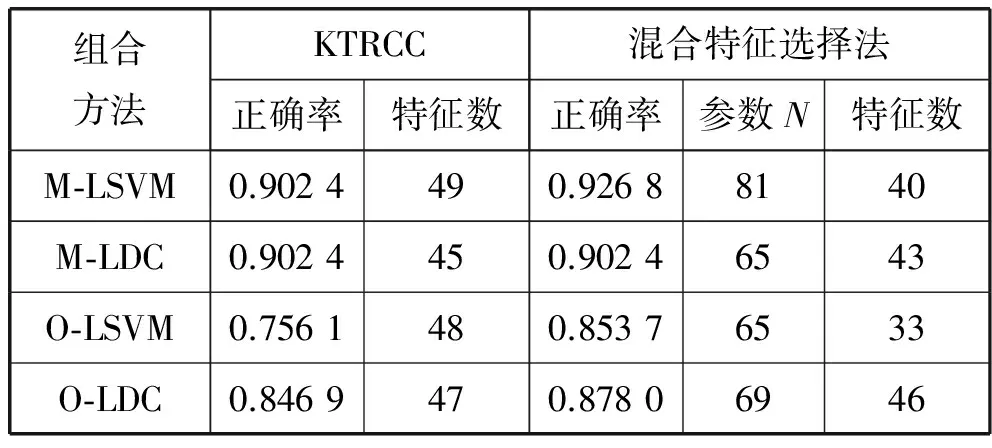
表1 采用不同特征选择法和不同组合方法的最佳分类结果以及相应的参数取值
由表1可以看出,相同的训练集和测试集,采用混合特征选择法可以取得更高的分类正确率。采用混合特征选择法和M-LSVM组合方法,在表1中给出的最佳参数下,整个交叉验证过程共出现了59个功能连接特征,涉及34个独立成分。为了评估不同独立成分对分类的贡献,首先统计了整个交叉验证中每个功能连接特征出现的次数(即统计了每个特征所连接的两个独立成分组合所出现的次数),再统计每个独立成分在整个过程中出现的次数,然后对独立成分出现的次数进行归一化,并以此作为独立成分在分类过程中的贡献权重。图6给出了贡献权重最大的前10个独立成分,其中贡献最高的前4个独立成分分别为视觉网络、视觉网络、默认网络、默认网络。通过分析独立成分的贡献,可得视觉网络和默认网络内部节点之间的连接存在异常,这与前人的研究成果基本一致[13-14]。
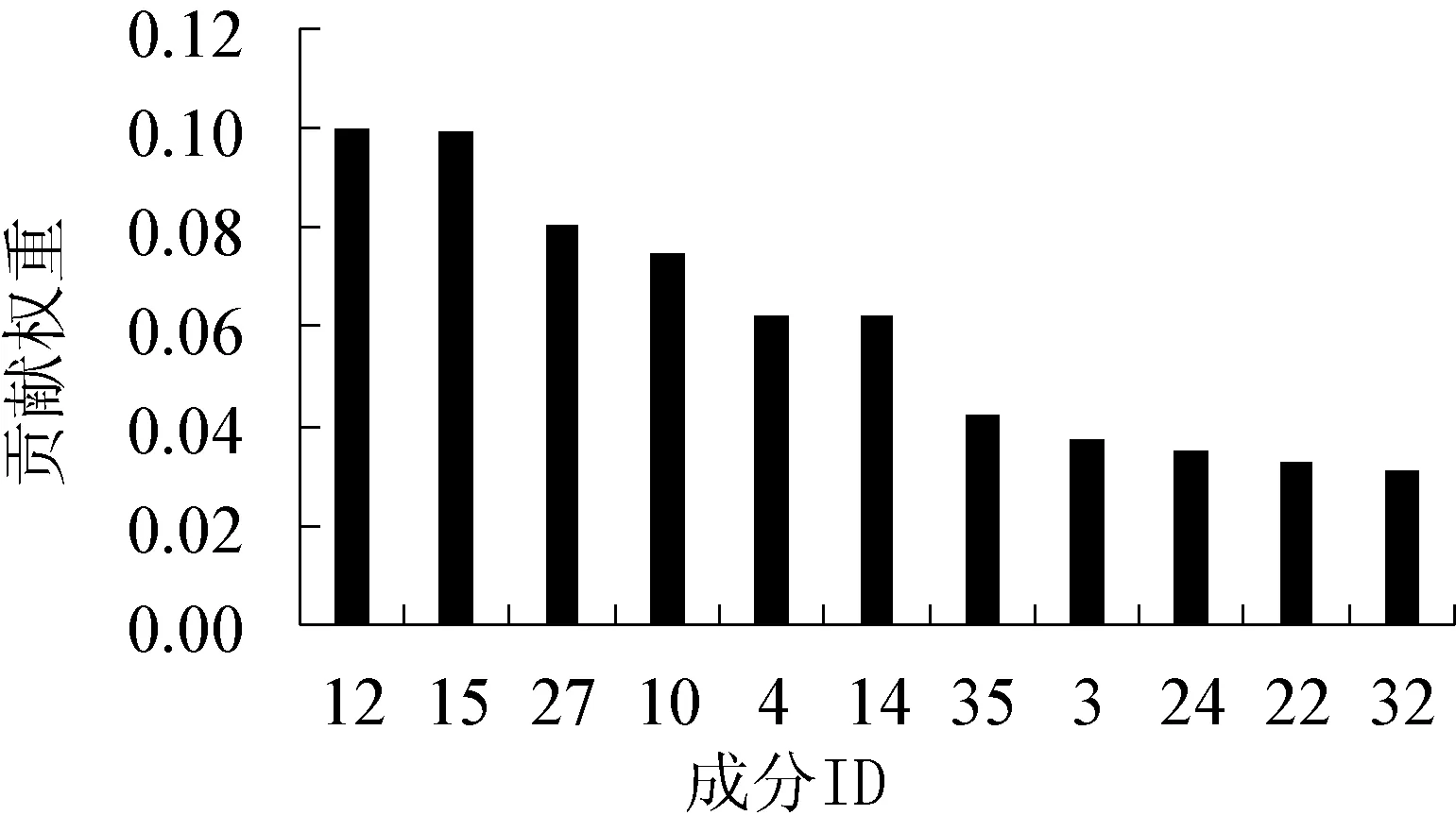
图6 贡献权重最大的10个独立成分
3.3 不同数据生成方法的分类结果
目前常用的数据生成方法有对数据增加高斯噪声生成新数据、使用GAN及其变形生成数据、使用自编码及其变形生成数据,并且据我们了解还未有人把数据生成方法应用于fMRI领域。表2对比了由CDCGAN、自编码、增加高斯噪声这三种数据生成方法构建的扩充数据集,采用不同组合方法的最佳分类结果(特征选择方法均为混合特征选择法,且通过自编码和增加高斯噪声的方法均构建了50组扩充数据集)。

表2 采用不同数据生成方法和不同组合方法的最佳分类结果
4 结 语
CDCGAN能够生成与训练数据具有相同分布的样本。本文实验结果表明,我们提出的方法可以得到较高的分类正确率,这说明了抑郁症fMRI数据采用CDCGAN方法扩充数据样本的可行性,同时说明了通过CDCGAN生成的数据有利于分类研究。另外,由于CDCGAN生成图片数据时可通过视觉观察法选取高质量的生成样本,因此CDCGAN在图像研究中可能会有较理想的效果。本文提出的混合特征选择法可选择出有助于提高分类精度的特征,CDCGAN和混合特征选择法在图像分类中的应用是我们下一步的探索目标。
[1] 张兵,董云云,邓红霞,等.基于体素的fMRI数据分类研究及其应用[J].计算机应用与软件,2015,32(2):138- 142.
[2] Hale J R, Mayhew S D, Mullinger K J, et al. Comparison of functional thalamic segmentation from seed-based analysis and ICA[J]. Neuroimage, 2015, 114:448- 465.
[3] 马士林, 梅雪, 李微微,等. fMRI动态功能网络构建及其在脑部疾病识别中的应用[J]. 计算机科学, 2016, 43(10):317- 321.
[4] Zeng L L, Shen H, Liu L, et al. Identifying major depression using whole-brain functional connectivity: a multivariate pattern analysis[J]. Brain A Journal of Neurology, 2012, 135(5): 1498- 1507.
[5] Sikora M, Heffernan J, Avery E T, et al. Salience Network Functional Connectivity Predicts Placebo Effects in Major Depression[J]. Biological Psychiatry Cognitive Neuroscience & Neuroimaging, 2016, 1(1):68- 76.
[6] Kang J, Bowman F D, Mayberg H, et al. A depression network of functionally connected regions discovered via multi-attribute canonical correlation graphs[J]. Neuroimage, 2016, 141:431- 441.
[7] Preti M G,Bolton T A W,Ville D V D.The dynamic functional connectome: state-of-the-art and perspectives[J].NeuroImage,2017,160:41- 45.
[8] Goodfellow I J, Pouget-Abadie J,Mirza M,et al.Generative adversarial nets[C]//International Conference on Neural Information Processing Systems.MIT Press,2014:2672- 2680.
[9] Mirza M, Osindero S.Conditional generative adversarial nets[DB]. arXiv:1411.1784, 2014.
[10] Radford A,Metz L,Chintala S.Unsupervised representation learning with deep convolutional generative adversarial networks[C]//International Conference on Learning Representations,2016.
[11] Allen E A, Erhardt E B, Damaraju E, et al. A baseline for the multivariate comparison of resting-state networks[J]. Frontiers in Systems Neuroscience, 2015, 5(5):2.
[12] 胡洋,李波.基于Fisher准则和多类相关矩阵分析的肿瘤基因特征选择方法[J].计算机应用与软件,2016,33(7):76- 78.
[13] 皇甫浩然,杨剑,杨阳.基于fMRI动态连接的抑郁症患者分类研究[J].计算机应用研究,2017,34(3):678- 682.
[14] 朱雪玲, 袁福来. 基于区域的抑郁症默认网络内部功能连接研究[J]. 中国临床心理学杂志, 2016, 24(2):218- 220.
