开源问答服务系统专家推荐混合模型
2018-07-05赵文普赵逢禹上海理工大学光电信息与计算机工程学院上海200093
赵文普 赵逢禹 刘 亚(上海理工大学光电信息与计算机工程学院 上海 200093)
0 引 言
随着互联网技术的飞速发展与进步,网络用户之间的互动沟通成为人们获取知识的重要方式之一。问答服务系统因其开放性灵活性等特点,能够满足人们解决问题和获得并分享知识的需求,从而迅速成为人们共享知识的平台。目前,国内外最流行的问答系统包括知乎、百度知道、新浪爱问知识人、Yahoo Answers、Stack Overflow等。
在问答服务系统中,用户提出问题首先在系统搜索相似问题。当用户不能找到相似问题或者不能够从相似问题中找到满意的答案,用户将问题提交给系统,等待其他用户回答。当其他用户提供答案以后,用户对所提供答案进行分析、筛选,最终确定问题的答案。问答服务系统在给用户提供便利的同时,存在着一些问题。其中,最严重的问题是当用户提出新问题不能够快速得到满意的答案。已有调查数据显示在问答服务系统中存在大量的问题在24小时内得不到有效的答复[1]。与此同时,提问者希望自己提出的问题能够得到问答服务系统高质量用户的快速回答,从而增加获得正确答案的可能性。然而,问答服务系统存在大量的问题信息,回答者常常需要消耗许多的时间与精力去寻找自己喜欢并且擅长的问题,从而导致提问者得不到及时有效的回复,最终影响问答服务系统的性能。因此,研究在问答服务系统中如何为用户提出的新问题推荐最适合的专家尤为重要。
对于问答服务系统中专家的推荐,研究人员提出了各种不同的方法。主要分为两大类:链接分析法[2-5]和用户建模法[6-7]。
链接分析法主要利用HIFS与PageRank算法发现专家用户。针对HITS算法,宣慧明[2]首先找出与问题文本相似的问题集合,增加相似问题回答者与提问者之间边的权重,基于HITS算法确定问答服务系统的专家。PageRank算法将用户看作网页,用户问答形成链接关系,并反复迭代计算用户的权威值,然后通过权威值大小对专家用户进行排序。Hong等[3]在潜在语义分析PLSA的基础上提出了基于内容主题的PageRank算法,把它应用于专家发现。戴秋敏[4]依据用户对答案的反馈信息对PageRank算法中的问答关系进行加权处理,考虑了答案的质量,发现问答服务系统的专家。
用户建模法主要使用了信息检索方面的技术。Liu等[5]把曾经回答过这类问题的用户定义为问题的专家,分析用户回答过的问题形成专家概况,利用相似度模型和关联模型探寻新问题和专家概况之间的关系并应用到专家发现中。Riahi等[6]对比TF-IDF、LDA和STM模型,分析了不同模型在专家推荐中的效率。
最近几年,一些研究人员通过分析问答服务系统的问题类别,来建模以求更好的发现专家用户。林鸿飞等[7]采用PageRank算法计算用户在每一个类别的权威度,采用LDA主题模型计算类别之间的相似度,综合考虑权威度和类别之间的相似度来发现专家用户。王甜等[8]提出了基于类别的加权动态权威度和兴趣度相结合专家推荐方法。但如果问答服务系统不存在类别或者类别十分复杂,专家推荐的准确率不是很高。
在专家推荐方面已经有许多研究成果。这些成果一定程度上实现了专家推荐,但是这些研究的重点都集中于被推荐专家对问题的权威度与兴趣度方面,忽略了被推荐专家最近行为习惯即最近活跃度和被推荐专家的兴趣度随着时间的变化,从而导致问答服务系统专家推荐的准确率降低。针对上面的问题,提出了一种基于兴趣度、权威度、信誉度和最近活跃度的专家推荐混合模型IARA(Interest- Authority-Reputation-Activity)。
1 IARA专家推荐混合模型概述
IARA模型主要为新问题推荐对问题兴趣度高、能够及时提供正确答案的专家用户,达到减少提问用户的等待时间并得到有效的问题答案。为此,本文提出了专家用户推荐混合模型,包括专家用户对新问题的兴趣度、专家用户权威度、专家用户信誉度、专家用户最近活跃度和个性化推荐 5 个部分。本文推荐的专家来源于问答系统中高质量的用户。图 1为 IARA专家推荐混合模型的处理过程。
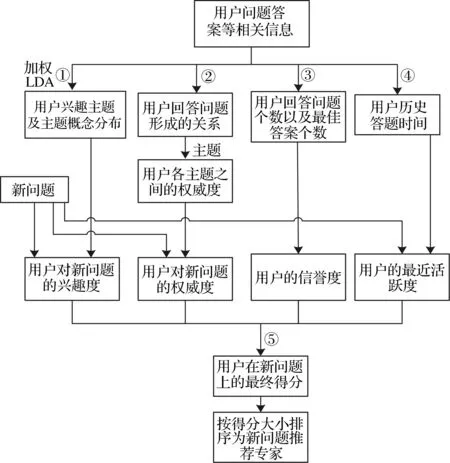
图1 IARA 模型流程图
第1步采用加权LDA主题模型对用户回答过的问题答案及问题建模,获得用户文档集合的主题概率分布,即用户的兴趣主题分布。根据用户兴趣主题分布和新问题主题分布的相似度,获得用户对新问题的兴趣度。
第2步采用基于主题的PageRank算法,计算用户在各个主题下的权威度,近一步求得用户对新问题的权威度。
第3步挖掘用户历史回答和提问信息,根据回答问题数量和被选择为最佳答案的比率,求得用户的信誉度。
第4步根据用户历史答题时间与新问题的时间间隔获得用户最近活跃度。
第5步根据用户的兴趣度、权威度、信誉度和最近活跃度四个方面,计算获得用户在新问题上的最终得分。按最终得分大小对专家用户排序,将新问题推荐给相应的专家用户。
2 IARA专家推荐计算
2.1 用户对新问题的兴趣度
用户兴趣度是指用户对各个主题关注程度。不同用户对同一个主题关注程度不同。只有把新问题推荐给用户兴趣度高的专家用户,才能够提高推荐的准确率。
因为用户的兴趣随着时间变化而变化,首先使用加权的LDA主题模型获得用户兴趣主题分布,然后根据用户兴趣主题分布和新问题的主题分布的相似性,计算用户对新问题的兴趣度。
2.1.1 用户兴趣主题提取
LDA 模型由Blei等[9]于2003年提出,是一种包含词、主题和文档三层结构的产生式概率模型。它首先解决文档中一词多意的问题,分析文档之间的语义关系。其次可以分析文档所包含的内在主题,获取用户未知的兴趣主题。最后LDA 模型刻画的用户文档信息是多个主题的,与现实中用户拥有多个兴趣主题相符合。已知LDA模型的以上优点,结合问答服务系统的特点,对每个用户活动所产生的文档进行建模,分析每个用户的兴趣主题分布。
问答服务系统用户兴趣建模流程如下:
第①步对于问答服务系统中的每个用户u∈U,从以α为参数的Dirichlet分布中抽取该用户的兴趣主题分布θu~Dirichlet(α);
第②步对于用户文档主题集中的每个t∈T,从以β为参数的Dirichlet分布中抽取主题t下的词分布,即φt~Dirichlet(β);
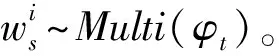
认知心理学认为人类兴趣和记忆一样会随着时间推移而衰减[10]。所以,在分析用户兴趣主题分布时候,采用动态加权的方式,使用户的兴趣主题分布向用户回答的最近的问答对进行倾斜。特征词的权值如下:
(1)
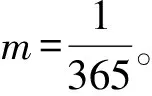
(2)
我们采用简单易懂的吉布斯采样进行推导和参数估计[11]。对于用户文档集中的特征词,主题分布从式(3)中获得:
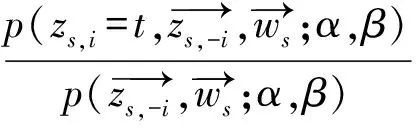
(3)

(4)
(5)

新问题的主题概率分布从文档的主题-词分布中取得,计算方法如下:
(6)
式中:φ(t,wq)从上述训练模型中推断获得。
2.1.2 用户对新问题兴趣度计算
专家用户对新问题的兴趣度通过其兴趣主题和新问题主题的相关性进行度量,两者之间的相似度越大,则用户对新问题的兴趣度越大。计算用户主题和新问题主题相似度即用户ui对新问题q的兴趣度,采用Jensen-Shannon[12]距离计算,计算方法如下:
NQI(ui,,q)=Sim(q,u)=JSD(θq,θui)
(7)
式中:θq表示新问题q的主题分布,可从式(6)获得,θui表示用户ui的兴趣主题分布,可从式(4)获得。
2.2 用户对新问题的权威度
用户权威度是指用户在各个主题下的相对重要程度。在问答服务系统中,不同的用户之间形成提问-回答的关系。在图2(a)中,用户3回答了用户1的问题,则表示为用户1指向用户3的有向边。对图2(a)进行简化,形成用户与用户之间的关系图如图2(b)。这种关系和网页之间的关系相似,网页代表用户,采用对网页质量排序的PageRank算法计算用户的权威度。传统的PageRank算法存在主题偏移的不足,结合用户的兴趣主题分布,对PageRank算法进行优化获得用户在各个主题下的权威度。然后根据新问题的主题分布,获得用户对新问题的权威度。
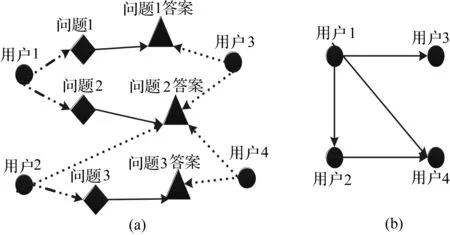
图2 用户问答形成的关系图
依据用户之间问答形成的关系,我们可以得到用户在某一个主题下的权威度计算规则:用户在某一个兴趣主题下,回答的用户问题个数越多,回答了高权威用户的问题,则用户的权威度越高。
构建用户关系有向图G=(U,E),U代表问答服务系统用户的集合,E代表不同用户之间关系的集合,箭头方向由提问者指向回答者。在主题z下,提问者ui向回答者uj的权威值转移概率计算方法如下:
(8)
式中:li,j表示回答者uj已经回答提问者ui的问题个数,Simz(ui,uj)表示在主题z下,提问者ui和回答者uj之间兴趣主题相似度。相似度使用Jensen-Shannon距离求得,计算方法如下:
simz(ui,uj)=JSD(θiz,θjz)
(9)
式中:θiz表示用户ui属于主题z的概率,θiz、θjz可由式(4)求得。
在主题z下,用户ui的权威度计算方法如下:
(10)
式中:ρ表示阻尼系数,行归一化矩阵Mi,j=Pz(ui,uj)。通过式(10)可以计算用户ui在各个主题下的权威度AU(ui),因此用户ui对新问题q的权威度计算方法如下:
(11)
式中:θqt表示新问题q分配到主题t上的概率,可以由式(6)获得。
2.3 用户信誉度
用户信誉度指用户历史回答问题的质量。一般,用户回答的问题正确率越高,即用户提供的答案被确定是最佳答案的概率越高,则用户的信誉度越高。例如,存在用户u回答的准确率为100%,但仅仅只回答了一个问题。如果在计算用户信誉度仅仅考虑回答的正确率,很显然是不正确的。因此,为了提高计算用户信誉度的有效性,在计算用户信誉度的时候,不但要考虑用户回答问题的正确率,还要考虑用户回答问题最佳答案的数量。
用户u信誉度计算方法如下:
(12)
式中:BAR(u)表示用户u回答问题的准确率,maxBAR(u′)表示准确率最高用户u′的准确率,ω∈[0,1]。通过调节准确率和用户提供最佳答案的相对重要程度,BAN(u)表示用户u提供最佳答案的数量,maxBAN(u″)表示提供最佳答案最多的用户u″的最佳答案个数。BAR(u)用式(13)求得:
(13)
式中:AN(u)表示用户u回答问题的个数。
2.4 用户最近活跃度
用户在最近一段时间在问答服务系统中越活跃,回答其他用户提问的新问题的可能性越大。如果用户在一年前回答问题获得较高的权威度和信誉度,然而最近的一段时间很少回答问题,则该用户的活跃度在降低。在计算用户的兴趣度、权威度和信誉度之后,把新问题推荐给用户时,还应考虑用户的最近活跃度。
用户在最近一段时间回答的问题越多,历史回答问题的时间与新问题发布的时间间隔越小(以天为单位),则用户的最近活跃度越高。用户最近活跃度随着时间的变化而变化。用户u最近活跃度计算方法如下:
(14)
式中:T表示用户u历史回答问题时间的集合,tq表示当前需要推荐专家的问题的提出时间,t表示用户u回答历史具体某个问题的时间。为了防止分母为0,我们在新问题与历史问题的时间间隔上加1。为了使用户的最近活跃度跳跃性不是太大,介于0到1之间,采用与最活跃用户最近活跃度比值的形式获得用户最终最近活跃度。用户u的最终最近活跃度计算方法如下:
(15)
式中:maxAC(u′)表示最活跃用户最近活跃度。
2.5 新问题专家推荐
对于提出的新问题q,根据用户对新问题的兴趣度、权威度、信誉度、最近活跃度,综合计算专家用户的得分。当不考虑用户最近活跃度的时候,得到专家用户ui的得分NacScore(ui,q),计算如下:
NacScore(ui,,q)=NQI(ui,q)×(w1NQAU(uj,q)+
(1-w1)R(ui)
(16)
式中:NQI(ui,q),NQAU(ui,q),R(ui)分别由式(7)、式(11)、式(12)计算得到。
当考虑用户的最近活跃度的时候,综合得到专家用户ui的最终得分Score(ui,q),计算方法如下:
Score(ui,q)=NacScore(ui,q)×ZAC(ui)
(17)
式中:ZAC(ui)可以由式(15)计算得到。
3 实验分析
3.1 实验的数据
Stack OverFlow 开源问答服务系统是一个计算机爱好者知识交流的问答网站。我们通过网络爬虫爬取Stack OverFlow 2015年1月到2016年2月的问题、答案等相关信息。去除未解决和无效的问题,共包含25 231个问题和102 585个答案以及7 012个用户。
在已经解决的问题中,其中21 016个答案包含最佳答案,4 008个用户提供了最佳答案,1 256个用户提供了至少5个最佳答案。我们把这1 256个用户称为“潜在的专家”,我们把新问题推荐给这样的用户。实验前,对用户的问答文本进行分词、除去停用词、词根还原。将2016年1月以后的提供最佳答案的用户问题作为测试用例集,其中包括2 108个问题。
3.2 实验的评测指标
本文选择S@N(success of N)作为实验的评测指标来验证本模型的有效性。当测试问题的最佳答案提供者在本模型推荐的用户中,证明这次推荐是合适的。
对于需要测试的用户问题q,如果推荐的N个用户中存在最佳答案提供者,S@N(q)的值取1,否则取0。针对所有的用户测试问题,S@N的取值越大,说明本模型的推荐越成功。S@N的取值计算方法如下:
(18)
式中:n表示用户测试问题的总个数,qi表示当前测试的问题,S@N(qi)表示问题qi的S@N的值,为0或1。
3.3 参数的设置
正如第三部分所描述的模型,一些参数需要设置。例如LDA主题模型中主题的个数T,Dirichlet先验分布α、β,迭代次数N;计算用户在各个主题下的权威度的式 (10)中的ρ;计算用户信誉度的式(12)中的ω;式(16)中控制声望度和权威度的权值w1。对于这些参数我们通过经验[12]或者控制变量法获得。具体取值如表1。
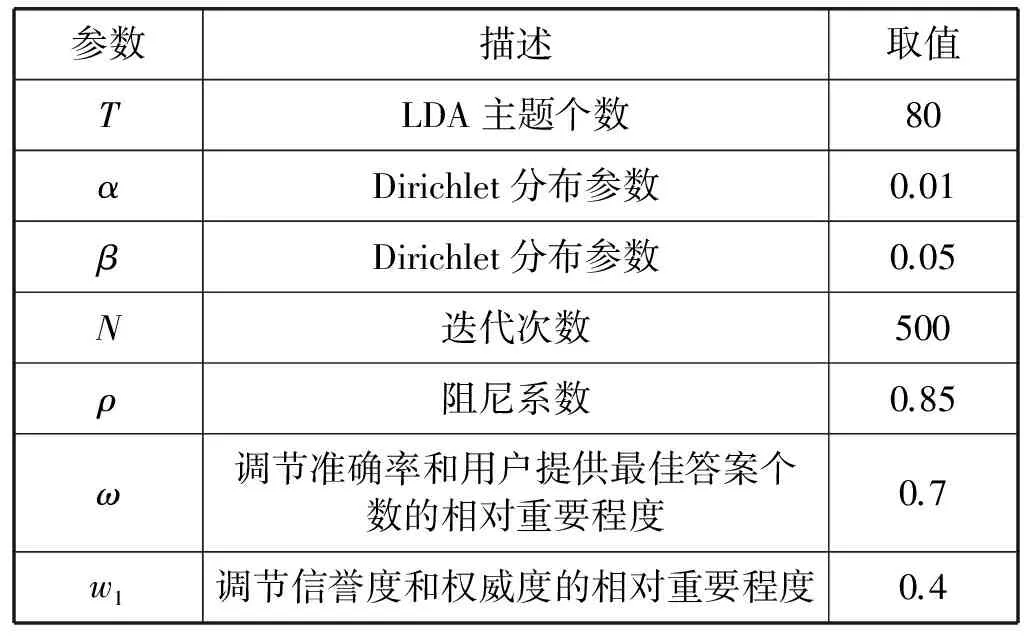
表1 IARA模型参数取值
3.4 实验及结果分析
3.4.1 实验1用户最近活跃度验证
在过去的研究中,新问题专家推荐常常忽略专家的最近活跃度。在我们模型的基础上,通过是否考虑最近活跃度进行对比,分析S@N的变化,验证最近活跃度对专家推荐的影响。实验结果见图3。

图3 是否考虑最近活跃度专家推荐结果对比
图3中横坐标表示新问题推荐专家个数,纵坐标表示专家推荐的准确率。IARA表示本文的推荐模型,IARNA表示不考虑用户最近活跃度的推荐模型。
通过图3实验结果分析,我们可以得出:在进行新问题专家推荐的时候,考虑专家用户最近的答题行为即专家用户的最近活跃度,能够有效提高新问题专家推荐的准确度。
3.4.2 实验2IARA模型验证
为了验证IARA模型对新问题推荐专家的有效性,采用2种不同的专家推荐方法与本文提出的IARA模型方法进行对比,具体对比方法如下:
1) InDegree(ID)[13]模型。依据用户提供最佳答案的数量从大到小来推荐专家。
2) TEM[14]模型。通过用户的问答记录以及答案的得票情况获取用户的兴趣以及专业程度,结合两方面推荐专家。
根据上面的方法以及我们的方法进行实验,实验结果见图4。
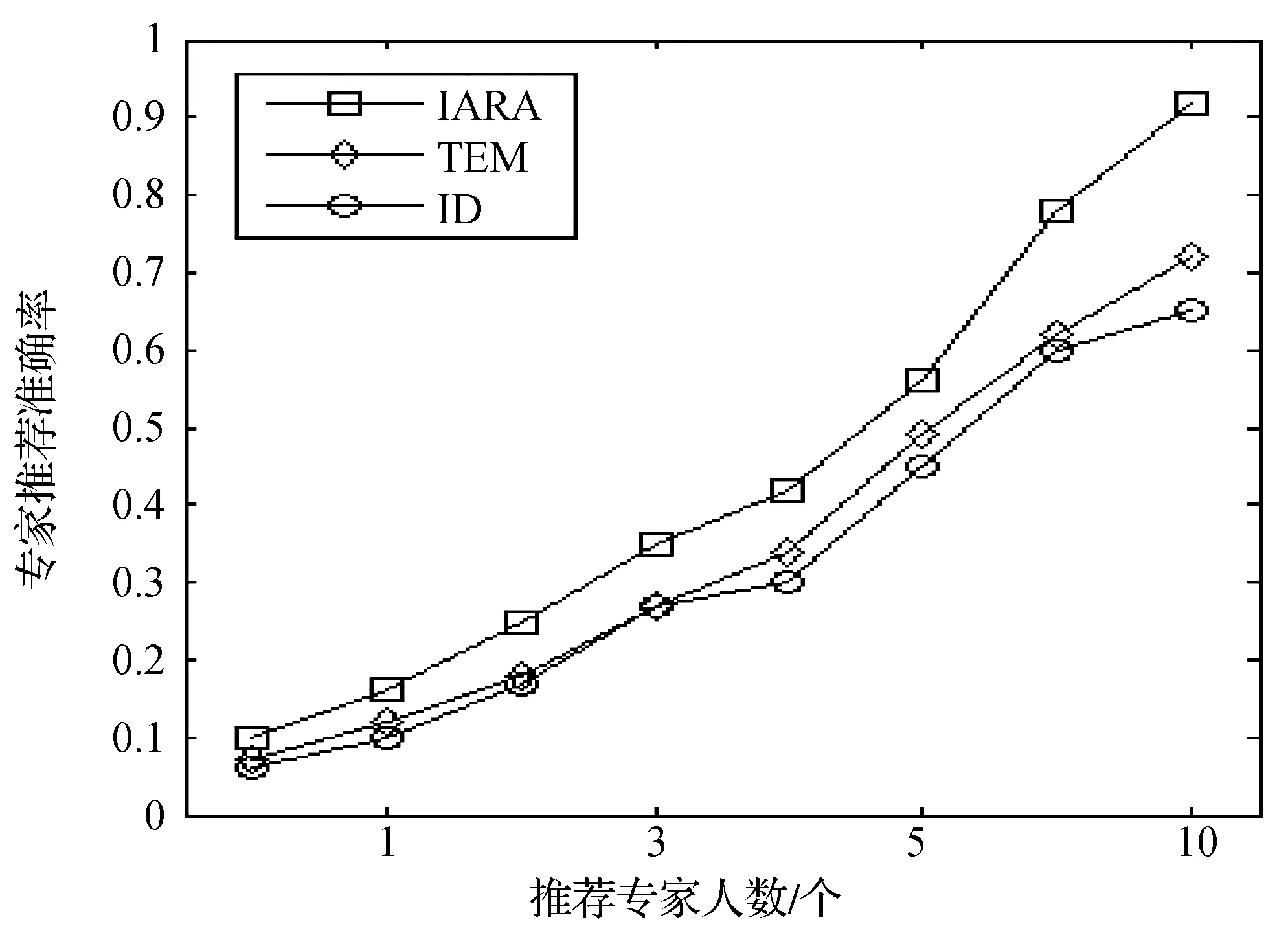
图4 各种方法推荐结果对比
通过分析图4可知,3种方法的推荐准确率是IARA>TEM>ID。ID方法仅仅根据用户提供问题最佳答案的个数推荐专家,具有一定的片面性。TEM方法考虑了用户的兴趣度和用户的专业程度,但是忽略了用户的最近活跃度以及用户的兴趣度随时间发生变化。我们的模型综合考虑兴趣度、权威度、信誉度的同时,还考虑了用户的最近行为习惯和兴趣变化规律,推荐准确度明显高于其他模型。这说明本文的方法是可行的。
4 结 语
本文提出了一个开源问答服务系统专家推荐混合模型。该模型从用户的兴趣度、权威度、信誉度、最近活跃度四个方面,分析专家用户的行为习惯和兴趣变化规律,为新问题推荐专家。实验结果表明,该模型能够有效地为新问题推荐最适宜的专家,达到用户问题快速、准确解决的目的。在今后的工作中,第一,将IARA的模型应用到其他的问答服务系统,例如知乎、百度知道、新浪爱问知识人等,进一步验证模型的有效性。第二,用户非正式的自然语言形成的问答对用户兴趣主题的挖掘带来巨大的挑战。名称的同义词或简称形式对于用户兴趣主题挖掘也是有问题的,因为它们被认为是不同的“术语”。为了解决上面的问题,计划在维基百科中利用语义知识来解决名称的同义词或简写形式。
[1] Furlan B,Nikolic B,Milutinovic V.A survey of intelligent question routing system[C]// Proceedings of the 6th IEEE International Conference on Intelligent Systems,Sofia,Bulgaria,2012: 1- 20.
[2] 宣慧明.基于交流平台QA系统的专家发现[D].南京:南京师范大学,2013.
[3] Hong L, Yang Z, Davison B D. Incorporating participant reputation in community-driven question answering systems[C]// International Conference on Computational Science and Engineering. IEEE Computer Society, 2009:475- 480.
[4] 戴秋敏.互动问答平台专家发现及问题推荐机制的研究[D].上海:华东师范大学, 2014.
[5] Liu X, Croft W B, Koll M. Finding experts in community-based question-answering services[C]// ACM international conference on information and knowledge management. New York: ACM, 2005: 315- 316.
[6] Riahi F, Zolaktaf Z, Shafiei M, et al. Finding expert users in community question answering[C]// International conference companion on World Wide Wed. New York: ACM,2012:791- 798.
[7] 林鸿飞, 王健, 熊大平,等. 基于类别参与度的社区问答专家发现方法[J]. 计算机工程与设计, 2014, 35(1):333- 338.
[8] 王甜, 曾承. 融合加权动态权威度和兴趣度的专家推荐方法[J]. 小型微型计算机系统, 2016, 37(10):2150- 2154.
[9] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. J Machine Learning Research Archive, 2003, 3:993- 1022.
[10] 黄希庭.认知心理学[M]. 北京:中国轻工业出版社,2000:70- 80.
[11] Griffiths T L, Steyvers M. Finding scientific topics[J]. Proceedings of the National Academy of Sciences, 2004, 101(S1): 5228- 5235.
[12] 肖宝, 李璞, 蒋运承.混合词汇特征和LDA的语义相关度计算方法[J]. 计算机工程与应用, 2017, 53(12):152- 157.
[13] Bouguessa M, Dumoulin B, Wang S. Identifying authoritative actors in question-answering forums: the case of Yahoo! answers[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2008:866- 874.
[14] Yang L, Qiu M, Gottipati S, et al.CQArank: jointly model topics and expertise in community question answering[C]// Paris: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management,ACM,2013:99- 108.
