基于Hadoop的监控数据存储与处理方案设计和实现
2018-07-05池亚平杨垠坦杨建喜北京电子科技学院通信工程系北京00070西安电子科技大学通信工程学院陕西西安7007中国科学院信息工程研究所中国科学院网络测评技术重点实验室北京0009
池亚平 杨垠坦 许 萍 杨建喜(北京电子科技学院通信工程系 北京 00070)(西安电子科技大学通信工程学院 陕西 西安 7007)(中国科学院信息工程研究所中国科学院网络测评技术重点实验室 北京 0009)
0 引 言
云计算是当前IT行业研究的主流趋势,各互联网巨头皆向云计算模式转型,亚马逊、谷歌、阿里巴巴、华为等都陆续推出自己的云平台。监控技术则是掌握云平台运行状况,并根据监控数据预测分析云平台未来态势的有效方法[1]。云平台的稳定性是提升云平台提供服务的质量的重要保障,因此,有必要对云平台的资源及服务状态进行实时监控。但是,在实际部署中,每个云平台有多个数据中心,每个数据中心有上千个节点,每个节点又要提供多项服务,实时产生的监控数据量达千万级。同时在运维监控系统中,采集数据非常频繁,一般每隔几秒或几十秒就要遍历所有设备进行采集,监控系统必然要面临海量的监控数据存储与处理问题。而且传统的关系型数据库并不适合用于存储具有时序性、异构性的监控数据。如何对海量监控数据进行高效的存储,是一个重大挑战。
近年来,国内外学者开展了关于云平台监控系统设计及云监控数据存储的相关研究。洪斌等[2]阐述了云监控系统所面临的一些问题,但并没有给出相应具体的解决方案;单莘等[3]提出了基于大数据流处理的监控方案,解决了大规模云计算平台监控问题,并提高了监控的实时性,但是其监控层次单一,只能监控主机状态;陈琳等[4]提出了一种多层次可扩展的监控框架,实现了应用服务、中间件和基础设施资源等不同层次的监控。从上述研究文献可以看出,随着云监控技术的发展,对云平台的监控逐步细化,这将产生更多监控数据,但是这些监控方案并未提出行之有效的监控数据的存储和处理方案。文献[5-6]提出的方案降低了数据冗余,提高了对海量数据的存储效率,但其只针对关系型数据库,并不适用于异构数据。相比之下,非关系型数据库更适合监控数据的存储。鞠瑞等[7]提出一种异构监控数据存储方法,以反范式化为基础,采用统一数据表达方式兼容异构源数据,提高了写入效率,实现了云平台监控数据更为高效的存储,但是并没有解决单机处理大规模数据时具有的计算瓶颈问题。
本文通过大数据平台Hadoop搭建云计算环境,采用提升字段法改进的宽表HBase非关系型数据库模型存储时序的和异构的监控数据,针对监控数据中的流量数据利用MapReduce并行计算架构对监控数据进行分布式处理。经测试提高了数据存储和检索速率,突破单机监控模型计算瓶颈,提升了对监控数据的分析效率。
1 Hadoop相关技术
Hadoop是Apache最大一个开源项目,可编写和运行分布式应用处理大规模数据。包含HDFS、MapReduce、HBase、Yarn、Zookeeper、Hive等工具。其生态系统如图1所示。
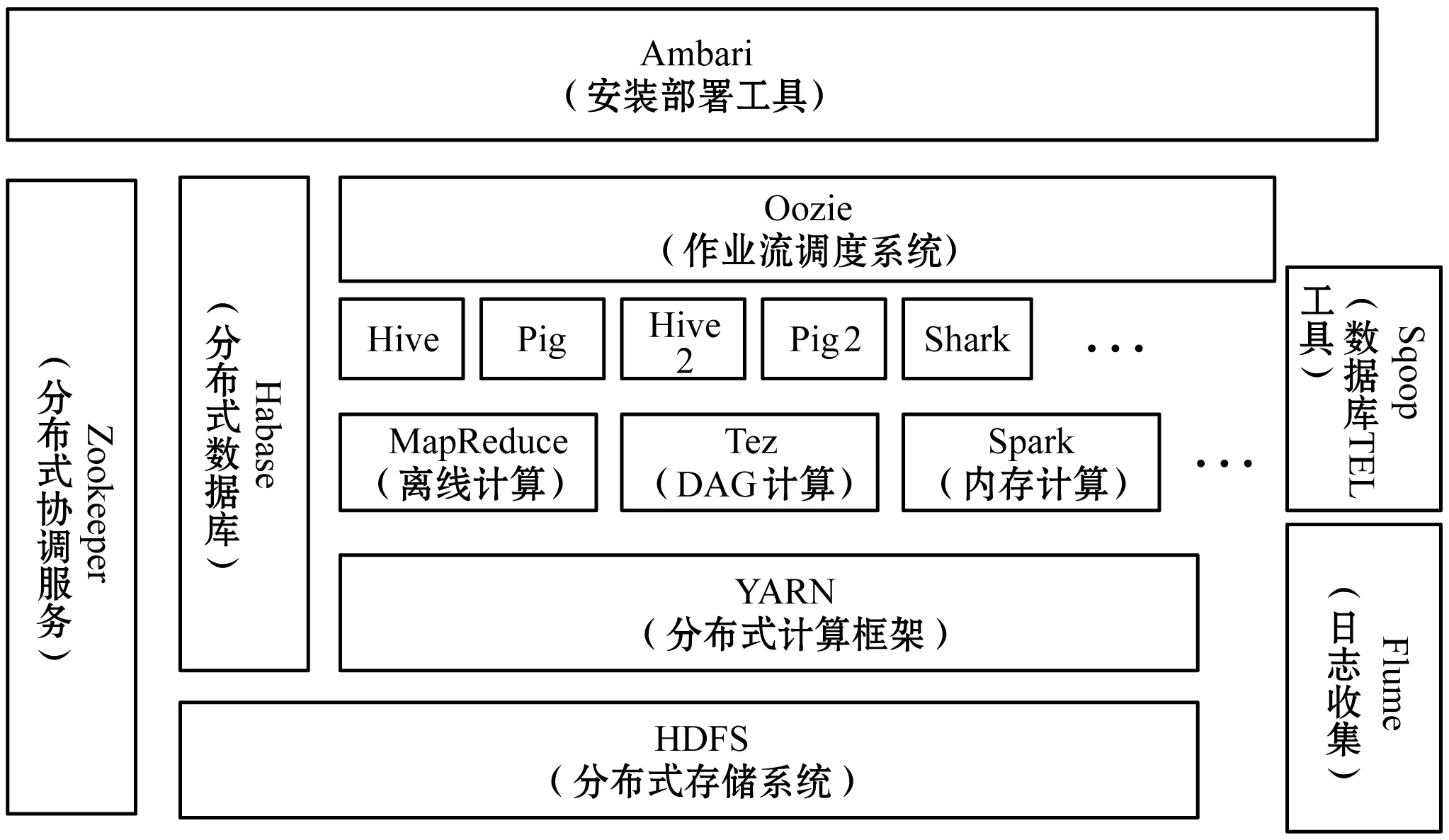
图1 Hadoop生态系统
1.1 HBase数据库
监控系统采集数据本质上是一种时间序列数据。本文要研究解决的是云监控系统中大规模时间序列数据的存储与处理问题,使得监控系统性能不会随着数据规模的增大而下降,从而造成系统故障或延迟的问题。目前,时间序列数据存储系统按照底层技术的不同主要分为三类:基于文件的简单存储、基于关系型数据库和基于非关系型数据库。而非关系型数据库最适合云环境下的监控数据存储需求。HBase是一个开源的、分布式的NoSQL数据库,具有良好的线性可扩展性、强一致性及出色的读写性能,主要用于大规模数据的存储[8]。
图2所示为HBase的基本组成架构,HBase建立在Hadoop分布式文件系统HDFS之上,依赖于Zookeeper提供集群的同步和协调,数据以规定的格式存储在HBase数据库中,数据库文件则存储在HDFS服务中。

图2 HBase基本架构
1.2 MapReduce并行计算
MapReduce是一种用于大规模数据分布式处理的编程模型,提供了一个庞大的、设计精良的并行计算框架。面对大规模的数据处理,MapReduce基于对数据“分而治之”的思想来完成并行化的计算处理,如图3所示。

图3 MapRedue数据基本处理思想
流量监控技术对云平台中的网络流量进行全方位的监控和统计分析,发现网络存在的安全问题,使云平台的安全、稳定运行得到有力的保障[9-10]。针对网络流量数据量大的特点采用MapReduce对其进行分析,提升对流量监控数据的处理效率。
2 方案设计
2.1 总体方案设计
针对云环境下监控数据的存储和处理需求,本文利用Hadoop提供的存储和处理框架,改进海量时序数据下HBase数据库的存储结构,并引入分布式处理思想,解决单机处理流量数据的计算瓶颈问题。方案总体框架如图4所示。
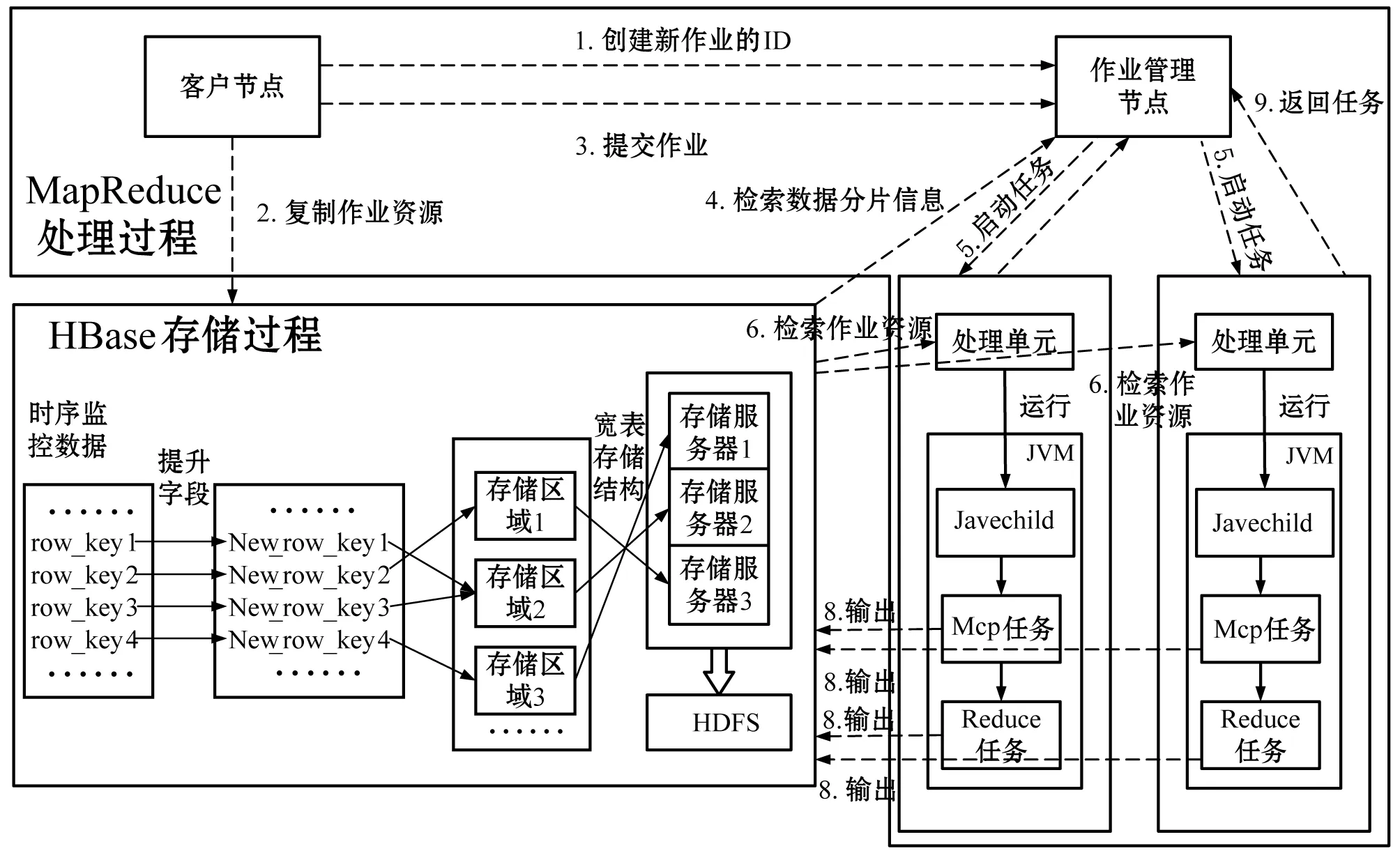
图4 方案总体框架
该方案可分为两个模块:HBase存储模块和MapReduce处理模块。在HBase模块中,先将时序监控数据的行健(row_key)离散化,然后根据新行健(new_row_key)把数据分配到不同存储区域,最后按一定的表规则存储于相应服务器。在MapReduce处理模块中,首先客户节点创建新的作业并将流量数据复制到HBase数据库;然后作业管理节点把作业分成若干不同的子任务,并放入任务池;接着处理单元在资源池中领取子任务,子任务在处理单元经Map和Reduce两个阶段的处理分别向Hbase返回中间值和最终结果。
2.2 HBase存储模块设计
从上述研究可知HBase数据库适合存储时序的监控数据,但是在实际应用中仍有两个问题需要解决。其一是存储海量监控数据时的“热点现象”,其二是大数据下HBase表检索的效率问题。为解决这两个问题,分别用提升字段法和宽表存储结构改进HBase数据库在海量监控数据下的存储模型。
2.2.1 提升字段法HBase存储方案设计
一条监控记录包括时间、测量值及监测指标等信息。在时序监控数据中,行健代表事件发生的时间。HBase对所有记录按行健进行字典排序,相邻记录在存储时亦是相邻存放的。这也就使得时序数据会被存储到一个具有特定起始键和停止键的区域中[8]。由于一个区域只能被一个服务器管理,所以所有的更新都会集中在一台服务器上。这将引起 “读写热点”现象,如果写入数据过分集中将导致存储性能下降。图5展示了大量数据按顺序键方式写入HBase所造成的“热点现象。

图5 热点现象
通过上面分析,解决上述”存储热点”问题关键在于行健的设计,需通过设计离散的行健将数据分散到所有存储服务器上,而不能直接将时间戳作为行健。
为解决这一问题主要有下三种方法:
(1) 加盐法 这种方法是通过给原来的行键(row_key)添加Hash前缀来保证数据的写操作均匀地分布到各个存储服务器上,起到负载均衡的效果,提升数据库的写入性能。该方法先对时间戳进行Hash运算,然后将得到的值对存储服务器的个数取模。
(2) 行键随机化法 这种方式是将行键随机化,可以采用散列函数将行键分散到所有的存储服务器上,例如:
row_key = MD5(timestamp)
这种方法生成的行键是随机的,比加盐法中的行健还要分散。
(3) 提升字段法 提升字段是指将时间戳字段移开或添加其他字段作为前缀,利用组合行键的思想来让连续递增的时间戳在行键中的位置后移。如果原行键已经包含了多个字段,则调整空位的位置就可以。如果行键只包含时间戳,则需要将其他字段从列键或值中提取出来,然后放到行键的前端。使用提升字段法后,一条记录的行键(row_key)如下:
row_key = Cpu.Host1-1461056400
当监控指标较多时,row_key会很分散,所有的更新操作将被分散开,最后能够得到与加盐法类似的效果。
这三种方法各有利弊,为此本文对不同行键下HBase数据库的读写性能进行了测试,测试数据大约100万行。测试结果如表1所示。
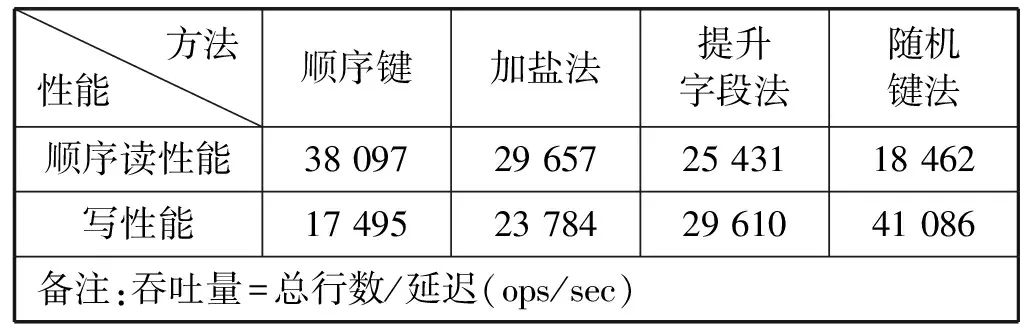
表1 不同行键下HBase的读写性能 ops/sec
从实验结果可以看出,提升字段法和加盐法的综合性能较好,两者效果相近。但监控系统一般要进行大量的写操作,读操作较少,所以要求写性能较好。同时,对监控数据来说需要根据监控指标名称能够进行快速查询一段时间内监测数据的结果,而加盐法不利用数据检索。因此,本文最终选择基于字段提升的行键设计方法。
2.2.2 基于HBase的宽表存储结构设计
根据上述实验结果,解决了大量数据在写入时的 “热点现象”的同时。为了能匹配MapReduce的处理速度,还要解决HBase检索效率的问题,这就要求对HBase中的数据进行检索的延时尽可能小,为了提高数据库检索速度,本文设计了一种宽表的存储结构。
HBase每张表都有一个或者多个列族,每个列族中存放多个列,HBase表每行可以拥有多达上百万的列,这种结构可以用来在每行存放多个数值,这就使数据可以被更高速地检索。因为,监控代理每隔几秒就采集一次数据,这样产生的数据点规模是非常大的,如果每个数据点占一行,则表的行数将相当多,而扫描数据的最大速度部分取决于需要扫描的行的数据,减少行的数量就大幅减少了一部分检索开销,检索速度就会大大提升。图6所示为监控数据存储表结构。
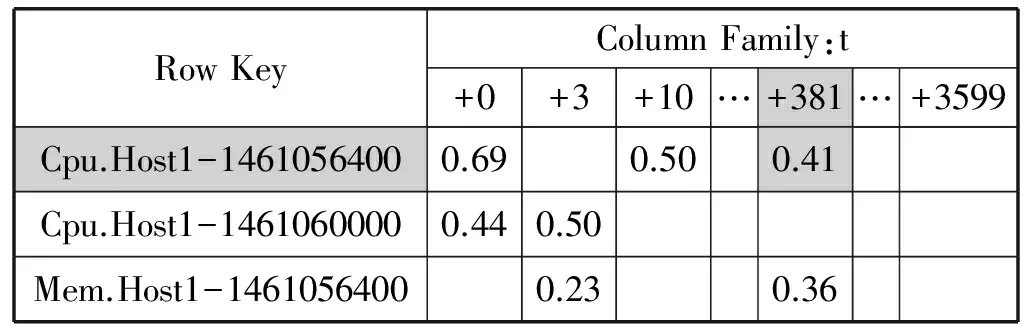
RowKeyColumnFamily:t+0+3+10…+381…+3599Cpu.Host1-14610564000.690.500.41Cpu.Host1-14610600000.440.50Mem.Host1-14610564000.230.36
图6 基于提升字段法的宽表存储结构
该表结构中,将一小时的数据存储为一行,行键为监控指标和整点时间戳的组合,每一列对应具体时间点的监控数据。以2016-04-19 17:06:18这个时间点采集的服务器host1的CPU利用率(41%)为例(图6中的阴影部分)。
首先,将这个时间点转化为时间戳1461056781,则17:00对应的时间戳为:
TimeStamp= 1461056781-(1461056781 mod 3600)=
1461056781-381=1461056400
图6中,行键为:row_key=cpu.host1-1461056400;列名为:381;测量值为:41。
如果隔1秒采集一次监控数据,则该存储方式将使得HBase存储表的行数缩小为原来的1/3 600,当检索一小时内数据时只需扫描一行数据。而原来高表的存储方式下每个数据点存储为一行,当检索一小时内的监控数据时,需要扫描3 600行。
2.3 MapReduce处理模块设计
在MapReduce处理模块中,利用Hadoop提供的并行处理计算的功能,设计MapReduce流量统计分析程序对大规模网络流量日志进行快速处理,统计分析各个主机的网络流量情况。这种数据处理方式突破了传统单点网络流量分析的局限性。
图7所示为基于MapReduce的流量统计分析算法流程。

图7 基于MapReduce的流量统计分析算法流程
首先,进行数据划分得到初始键值对
Map阶段:调用mapper的map()函数对每个单独的键值对
Reduce阶段:Reducer分别处理每个被聚合的
(1)
得到流量统计结果。其中Length为list(length)中每个length(报文长度)相加的和,SampleRate为采样率,两者相乘得到每一行记录的流量大小F,则在监测时间T范围内,该主机的上行网络流量为list(
3 方案实现与测试
3.1 测试环境
为测试所提出云数据的存储和处理方案的性能,首先要搭建相关监控系统,用以产生监控数据,本文以OpenStack搭建云平台,/proc读取物理机监控信息,Libvirt API接口获取虚拟机相关信息,sFlow流采样技术对云平台的网络流量进行监控。
根据实验室的云平台规模,搭建了一个3个节点的Hadoop的分布式监控平台,有一个主节点master和2个从节点slave。主节点作为监控服务器,负责接收部署在OpenStack云平台上的监控代理采集的监控数据,然后在Hadoop上实现监控数据的分布式存储与处理,最后用户通过监控终端管理查看监控状态信息。监控系统的硬件配置如表2所示。
3.2 数据存储的实现
将Hadoop平台中的master节点作为监控服务器,监控服务器上的HBase客户端(TSD)负责接收发送来的数据,并将监控数据写入HBase数据库中。TSD接收到数据后需要将其写入HBase存储表中,向HBase中写入时序监控数据过程如下:
(1) 接收监控代理发送来的时序监控数据,格式为“TimeStamp,metric,value”。
(2) 生成组合行键RowKey,RowKey=Metric-TimeStamp1,其中TimeStamp1为整点时间戳,其计算公式如下:
TimeStamp1=TimeStamp-(TimeStamp mod 3600)
(2)
(3) 生成列名colfam:qual,其中colfam为列簇名(只有一个列簇),qual为列名,且qual=TimeStamp mod 3600。
(4) 根据生成的行键RowKey创建一个Put:
put=new Put(Bytes.toBytes(″RowKey″))
(5) 向该行添加列名为colfam:qual的列:
put.add(Bytes.toBytes(″colfam″)
Bytes.toBytes(″qual″),Bytes.toBytes(″value″))
(6) 将该数据存入HBase表中:table.put(put)
3.3 MapReduce处理算法实现
监控数据存入HBase后,使用Java编写MapReduce流量统计分析算法,对流量数据进行快速处理分析,得到云平台的监控信息。算法分为两个阶段实施:
(1) Map阶段。Map接收到的数据是经Hadoop处理后的键值对
输入:
输出:
Class FlowSumMapper
{
map(String input_key, String input_value) {
String line=value.toString();
//读取日志中的一行数据;
String[] fields=StringUtils.split(line,′ ′);
//分解成若干字段;
String IP=fields[1];
//提取主机IP字段;
long length=Long.parseLong(fields[7]);
//读取报文长度;
context.write(“IP”, “up_flow”);
//输出键值对
}
}
(2) Reduce阶段。在进入Reduce阶段前,Map-Reduce框架会将每个Map输出的中间结果进行整合处理形成新键值对
输入:
输出:
Class FlowSumReducer
{
reduce (String input_key, Iterator input_value) {
long length_counter=0;
for(FlowBean b: value){
length_counter +=b.getUp_flow();
//聚合
}
flow=length_counter*SamplingRate;
//计算流量
context.write(“IP”, “flow”);
//输出结果
}
}
图8所示为后端MapReduce程序执行流量统计分析任务的过程。
图8 流量统计分析程序执行过程
3.4 方案测试
3.4.1 与单机处理对比
将采集的流量日志数据分别由本文的分布式处理方案和传统单机处理方案进行基于IP地址的流量统计,测试数据选用大小分别为0.2、0.5、1、3、5 GB流量日志数据。两种方式进行统计分析的耗时结果如表3所示。
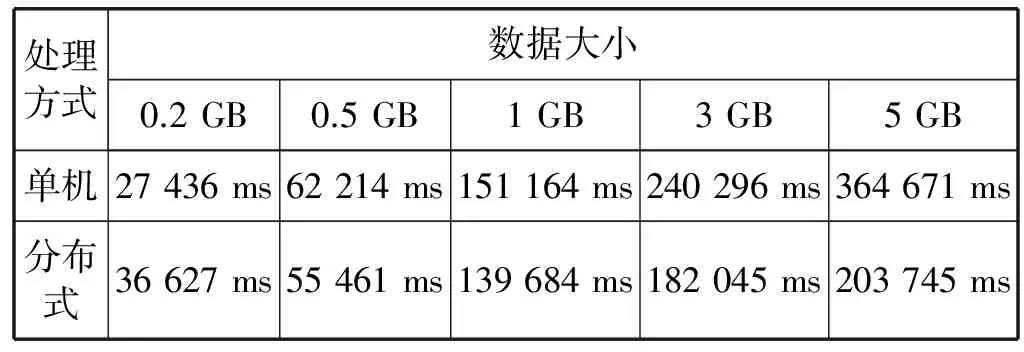
表3 单机处理与分布式处理性能对比
从表3可以看到数据量不大时,Hadoop平台的处理速度和单机系统的处理速度相差不大,甚至还没有单机的处理速度快。这是因为Hadoop在进行计算前要做一些集群间的通信和初始化工作,在小数据集处理上并不占优势。当数据量增大后,该分布式处理方案具有明显的优势。
3.4.2 HBase数据库性能测试
本文设计的是一种基于提升字段法的HBase 存储模型来存储时序监控数据。为了测试该存储模型下HBase读性能的高效性,本文分别测试了高表和宽表两种存储方式下,从HBase数据库中检索1小时、5小时、1天和1周的监控数据时系统延迟。如图9所示。

图9 HBase读性能测试
4 结 语
本文针对云监控系统中存在的实时数据量大,以及单机系统计算瓶颈等问题,提出了一种基于Hadoop大数据平台的云监控数据存储与处理方案。实验结果表明,用提升字段法提高了Hbase数据库的存储效率,宽表存储结构提升了检索速度,用MapReduce对流量数据统计分析,有效解决了单机系统计算瓶颈的问题。为进一步的研究奠定了良好的基础。
[1] Aceto G,Botta A,Donato W D,et al.Cloud monitoring:A survey[J].Computer Networks,2013,57(9):2093- 2115.
[2] 洪斌,彭甫阳,邓波,等.云资源状态监控研究综述[J].计算机应用与软件,2016,33(6):1- 6,12.
[3] 单莘,祝智岗,张龙,等.基于流处理的云计算平台监控方案的设计与实现[J].计算机应用与软件,2016,33(4):88- 90,121.
[4] 陈林,应时,贾向阳.SHMA:一种云平台的监控框架[J].计算机科学,2017,44(1):7- 12,36.
[5] 丁治明,高需.面向物联网海量传感器采样数据管理的数据库集群系统框架[J].计算机学报,2012,35(6):1175- 1191.
[6] Cao W, Yu F, Xie J. Realization of the low cost and high performance MySQL cloud database[C]// IEEE, International Conference on Data Engineering. 2014:1468- 1471.
[7] 鞠瑞,王丽娜,余荣威,等.面向云平台的异构监控数据存储方法[J].山东大学学报(理学版),2017,52(5):104- 110.
[8] George Lars.HBase权威指南[M].代志远,刘佳,蒋杰,译.人民邮电出版社,2013:344- 348.
[9] 李亮,姚熙.基于云平台的虚拟化流量监控方法及装置:中国,CN104917653A[P].2015.
[10] Afaq M,Song W C.sFlow-based resource utilization monitoring in clouds[C]//Network Operations and Management Symposium(APNOMS),2016 18th Asia-Pacific.IEEE,2016:1- 3.
