大规模词序列中基于频繁词集的特征短语抽取模型
2018-07-05余琴琴彭敦陆
余琴琴,彭敦陆,刘 丛
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
近年来,文本数据的处理越来越受人们关注,如何将非结构化的文本转化为结构化数据是许多应用中的关键步骤之一.文本数据的特征选择和特征抽取是将文本数据转化为结构化数据的关键实现技术.在文本处理中,特征抽取本质上是选取能反映文档内容的重要词汇或短语,也称为关键词抽取.利用抽取的词汇或短语可以实现文本内容辅助理解,因而特征抽取是信息检索系统和自然语言处理的主要任务之一,在文本聚类、分类、摘要生成等方面具有广泛用途[1].
尽管目前针对文本特征抽取的算法有很多,如TF-IDF、互信息、信息熵等,但这些算法不能体现文档中共现词之间的关系.与单个词相比,短语表达的信息更丰富、更准确,在辨识力和合理性方面也具有明显优势.短语通常由两个及以上的词组成,事实表明,在不同文本中经常共现的词往往存在着一定的相关性[2].基于这一考虑,很多研究者使用关联规则挖掘方法研究共现词之间的关系,特别是针对词序列中的频繁词集的挖掘对理解文本数据的内容和情节具有重要意义.
传统的关联规则挖掘算法有很多,如Apriori、FP-Tree算法以及基于这两个经典算法改进的一些算法,它们可以有效地挖掘数据库中的频繁项集,但是这类算法不能完全适用于词序列的频繁项集挖掘.在频繁项集挖掘任务中,构成事务的项集是不重复、无序的,而词序列具有有序性的特点,使得无法直接使用传统的频繁项集算法挖掘来发现词序中的频繁词项集.迄今,也有一些研究是针对文本序列挖掘展开的,这些研究是将相邻词进行组合作为频繁k-项集,但对于实际的文本序列,这种方式不能很好的体现频繁词项集所表达的语义.基于这一问题,在挖掘频繁词集时,不仅考虑相邻词的组合,还考虑不相邻词间的组合,这与本文处理的中文文本数据中组成短语的词语通常不相邻、共现率高的特点有关.在中文词序列中,有序词可能在一个序列中重复出现,还有同义词这一因素的存在,使得挖掘频繁词项集成为挑战.另一方面,尽管频繁项集的挖掘算法有很多,但随着文本数据量的剧增,传统集中式的频繁项集挖掘算法无法保证计算效率,有必要研究新型分布式大规模的文本数据频繁词项集的挖掘算法.MapReduce是由Goolge提出的具有代表性的分布式并行计算编程模型,采用MapReduce模型可以高效地处理基于频繁词项集的文本序列特征抽取.目前,这方面研究开展得还不多,本文将MapReduce模型应用到大规模词序中的频繁词项集挖掘中,实现基于频繁词集的特征短语挖掘算法.结合实际法律文本处理应用场景,采用海量案件文本数据进行实验验证,表明所提算法具有较好的计算效果.
2 相关工作
文本的特征抽取在文本挖掘领域占有重要的地位,许多关于自然语言处理(Natural Language Process,简称NLP)中都提倡运用文本特征项来表示文本,以达到降维的目的.国内外已经有很多关于特征抽取方法的研究,按照抽取粒度分为基于关键词、关键短语和关键句子的抽取.与关键词相比,关键短语表达的信息更丰富、更准确,具有较高辨识力和合理性.在一些应用场景,由于文本数据的长度受限,相对而言,抽取关键句子意义不大,所以许多工作更加注重抽取关键短语的方法研究.
根据特征抽取方法的发展,可将其分为两大类,基于语法规则的方法和基于统计信息的方法.针对第一种方法,早期是通过科学家和语言学家写出合理的语言规则,现在可以通过预定义一些词性标注规则来产生名词性的短语.然而,这些基于规则的方法通常在领域范围内是受限的,往往还依赖某些NLP的特征,例如,采用句法依存解析树来提高短语抽取的准确性[3].在第二种方法中,文献[4]提出了基于序列模式挖掘的文本语言模式识别方法,并将其运用于诗歌、信、小说等文本体裁,但对于其他领域的文本挖掘存在局限性.文献[5]中F.Ye等人为解决采用传统语言方法,将关键字作为彼此独立的单元,相互间缺乏语义联系的问题,提出面向领域的方法适用于某些特定领域,特别是充分利用关联规则挖掘集成简单、容易解释和理解的优势,并能有效地实现捕捉数据集之间的重要关系.文献[6,7]中研究了在文本集合上将频率统计信息与语料库的各种统计信息相结合来评估短语质量.尽管此方法不依赖语言具体特性或特定领域的规则或大训练集,且可以有效地处理大规模语料库,对于短语质量的不确定性评估还存在问题.考虑到上述问题,在文献[8]中Liu等人提出了SegPhrase算法和SegPhrase+算法,一种基于频繁模式挖掘算法来发现有意义的短语,由于在挖掘短语的过程中,它们忽略了文本数据中词的先后顺序,产生了大量的候选短语,也未考虑词的重要程度.为了弥补这一缺陷,通过短语的质量评估方法来纠正基于频繁模式挖掘方法进行短语抽取的不足,以此达到提高短语抽取质量的目的.还有许多的研究关注抽取短语的排名算法,但这些算法忽略了候选短语识别的正确性这一影响因素[9].
本文试图通过改进传统的频繁项集挖掘算法来抽取高质量的文本特征短语.传统的频繁项集挖掘算法按有无权重可分为两类:无权重挖掘和加权挖掘.无权重挖掘代表算法有基于Apriori算法思想和基于模式增长思想(如FPGrowth);加权挖掘算法,即数据库中的每个项集带有不同的权重,权重表示他们的重要程度.考虑到词序列中词的先后顺序,而且在领域文本数据中,每个词的重要程度也不同,所以基于加权频繁模式挖掘的思想,提出了一种基于词序列的频繁短语挖掘算法,挖掘出高质量领域文本特征短语.在此基础上,针对海量文本的抽取效率以及内存消耗问题,将该算法结合MapReduce计算模型,实现大规模词序列特征短语识别.
3 频繁短语挖掘算法
在文本中,经常同时出现的两个或多个关键词之间往往存在一定的相关性.在传统的频繁项集挖掘算法中,数据库中各项具有同质性,但在词序列中,每个词扮演着不同的成分,对文本内容理解的重要性也不同,通常权重较大的一些词较为重要,即反映的文本内容能力较强,因此,在词序列的频繁项集挖掘中,采用改进加权关联规则算法挖掘有意义的特征短语.
3.1 问题描述
设∑={S1,S2,…,SN}为词序列集,词序列S由一个或多个有序的词集组成,记为S={is1,is2,…,isn}.每个词称为一个词项集,I={i1,i2,…,im}表示词序列集中所有词项集的集合.与之对应的词项集的权重集为W={wi1,wi2,…,wim},其中,wij表示了词项集ij的重要程度,wij∈[0,1],j={1,2…,m}.设p为短语由一个或多个词项集组成.指定最小加权支持度阈值和最小语义关联强度阈值分别为wminsup和wminsaw.
定义1.词项集X的加权支持度WS(X),表示词序列集中包含该词项集的词序列权重的总和:
(1)
其中∀ik∈X,Nx表示词项集X在词序列集中的计数;N是词序列集的总数.
定义2.若词序列中包含词项集X∪Y,则其加权置信度WC(X→Y)为词项集X∪Y的加权支持度与词项集X的加权支持度的比值.计算公式如下:
(2)
定义3.若词项集X为短语,则其语义关联强度SAW(X)定义为:
SAW(X)=α·WS(X)+(1-α)·WC(X)
(3)
其中,|X|≥2为短语个数,α是用来调整支持度与置信度之间的重要程度参数,0<α<1.
定义4.顺序性.若词项集X和词项集Y可组合成一个有意义的短语,则短语XY≠短语YX.例如:“被盗”、“手机”可分别组成两个不同的短语,“被盗手机”和“手机被盗”.
定义5.无重复性.假定一个短语序列P={p1,p2,…,pl},则满足pi∩pj=∅,其中1≤i,j≤l,且i≠j.
定义6.同义性.如果词项集X和词项集Y为同义词,则包含词项集X或Y的短语序列P在词序列中的计数为min {pi,Nx+Ny}.
定义7.若词项集X的加权支持度大于最小加权支持度阈值,即WS(X)≥wminsup,则称X为加权频繁词项集.
定义8.若词项集X的语义关联强度满足最小语义关联阈值,即SAW(X)≥wminsaw,则词项集X被称为特征短语.
3.2 频繁短语挖掘算法
传统的加权频繁模式挖掘算法,如MINWAL(O)、MINWAL(W)算法[10],因为每个项集的权值不同导致了加权频繁项目集的子集可能不是加权频繁项集,这使得其无法满足Apriori算法中频繁项向下封闭的性质.在此通过改进加权支持度的计算方式,使其在产生频繁项集时可以保持频繁项集的向下封闭特性.此外,当交易数据较大时,在频繁项集的计算过程中会产生大量的候选项集,占用大量的内存和计算时间,所以候选项的剪枝过程显得尤为重要.文献[11]中提出的FAMR算法是对Apriori算法在MapReduce环境上运行的改进.借鉴FAMR算法中通过筛选出1-频繁项集过滤非频繁项集减少候选项集和内存消耗的思想,并结合词序列集上顺序性和重复性的特点对产生候选项进行剪枝,将其运用到加权关联规则算法中,本文提出基于词序列的频繁短语挖掘算法(WS-FPMA).
该算法的主要思想是:首先找出所有的1-频繁词项集,在下次扫描词序列集时,将每个词序列中的非频繁词项集进行逻辑上的移除,然后在移除后的词序列集上产生k-频繁候选词集.另外,在实际情况中,一个短语一般为两个词或三个词组合而成.当词长度越长,即k越大时,满足条件的k-词项集也会越来越少.通过上述约束,两次大量减少候选项集,会显著提高算法的计算效率.算法的详细描述见图1.

图1 WS-FPMA 算法Fig.1 Algorithm of WS-FPMA
算法说明:算法第(6)行表示在第k次扫描词序列集时,将每个词序列中的非频繁的词项集移除,然后产生k-项频繁候选词集.在生成k-频繁词项集时,根据定义4和定义5,应满足以下两个条件:一是若词序列中没有重复出现的词,则一个词只能与其后面的词进行组合;二是若词序列中有相同的词重复出现,则以第i个相同的词(i>2)为分界线分别进行组合,组合方法同上面一样.需要注意的是,通常词序列中每个词都是具有不同的意义,即使重复出现在词序列中的词,不管出现几次计数均为1,例如:无 驾驶 资格证 驾驶 小型 轿车,从第二个“驾驶”处划分成两部分,分别进行组合,在计算“驾驶”的支持度计数时仍计算为1.算法第(7)行表示组合成候选频繁词集后,进行支持度计数时,根据定义6来给出支持度的最后计数结果,避免了频繁词的同义词作为非频繁词而被过滤掉的情况,这里的同义词是根据《哈工大信息检索研究室同义词词林扩展版》中整理的同义词典来判断的.算法第(11)行表示将频繁词集生成满足语义关联强度的特征短语.
4 基于MapReduce的频繁短语挖掘算法
实际应用中,运用在进行频繁模式挖掘时,随着原始数据量的快速增长,会使得挖掘算法的问题集中提高执行效率和I/O负载上.特别地,在单处理器上即使使用优化后的串行算法也无法满足挖掘性能的需求,利用多处理器系统进行并行计算,是提高挖掘效率的有效途径[12].第3部分中提出WS-FPMA算法,随着数据量的增加,会发生内存溢出而终止,而且运行的时间也难以保证.基于上述考虑,下面对该算法进行改进,实现并行环境下对大规模的词序列集进行频繁词集挖掘的计算.
4.1 MR-FPMA算法框架
给定一个词序列数据集,采用MapReduce的并行计算环境,对WS-FPMA算法进行MapReduce改造,需要经过2步来完成特征短语的挖掘,图2描述了算法的基本计算模型.具体过程如下:
第1步.并行产生1-项频繁词项集.此过程多节点并行扫描一次数据库,统计其中每个词的次数,得到大于支持度阈值的1-项频繁词集.
第2步.并行产生k-项频繁词项集.在上一步的基础上对词序列集扫描时进行逻辑上的修剪,每个节点上的各词序列产生满足组合条件的k-项候选频繁词集,通过设定的阈值筛选满足条件的k-项频繁词集作为输出结果.

图2 MR-FPMA流程Fig.2 MR-FPMA process
4.2 并行产生1-项频繁词项集
对应于WS-FPMA算法中的第2到第4步可通过一个MapReduce过程获得1-项频繁词集.在Map阶段读取词序列集,输出中key为每个词项集,将该词的权重和出现的次数作为value.Reduce函数负责将相同的key合并,统计每个词的总次数,并判断是否大于设定的支持度阈值,将大于阈值的词的

图3 产生1-项频繁词算法Fig.3 Algorithm of 1-frequent words
4.3 并行挖掘k-项频繁词项集
从图2中可看出,该阶段的处理过程和上阶段基本一致,只是Map阶段有所不同.Map函数将上阶段产生的1-项频繁词集作为一个全局共享的输入数据,同时接收词序列集.对存在多个1-频繁词项集的词序列,依次按该序列中出现先后顺序将频繁词项集进行组合生成长度为2-k的候选词项集.将候选词项集作为key,候选词项集的权重和和出现次数作为value,value的计算方式依然采用定义6进行计算.处理完后,将具有相同key值的候选项集发送到同一个Reduce节点进行合并产生最终结果,其实现方式与第一步相同.这一阶段的Map函数的伪代码见图4.

图4 产生k-项频繁词Map函数Fig.4 Map function for generating k-frequent words
5 实验结果与分析
5.1 数据集
实验中使用的数据集是从全国各级法院网站下载的真实案件裁判文书集,该数据集有300万篇覆盖10大主要罪名的判决书.

图5 文本预处理的流程图Fig.5 Preprocess for judicial documents
实验任务是抽取出案件的案情特征短语,在正式抽取之前,需要对实验数据进行预处理,图5是进行预处理的流程图.在提取出每篇判决书中关于案情描述的段落文本后,对段落文本进行分词,去除停用词、用TF-IDF过滤掉一些低频词及通用词.然后,以主要的标点符号,包括逗号、分号、句号,将分词后的文本划分成多个序列,对每个序列利用词性标注去除人名、地名、时间等,每个序列中仅保留动词和名词词性的词语.处理后的词序列与短语的顺序性(定义4),使得所有候选短语均与组成短语的词集在文本中出现的顺序保持一致,这样可以保证对短语有较好的语法规则约束.
5.2 实验结果分析
实验中短语的最大词语数N设置为3较为符合中文短语的特点,共做了三组实验.第一组考察不同阈值下WS-FPMA算法抽取短语的数目;第二组利用准确率和召回率指标衡量该算法同其他短语抽取算法比较抽取短语的效果;第三组将该算法与抽取短语结果较为优秀的算法SegPhrase算法进行比较计算效率,并验证该算法在并行环境下的MR-FPMA算法的计算效率的提升.下面对实验结构进行分析.
实验1.不同阈值下WS-FPMA算法的实现效果.
通常,不同的阈值对频繁词项集数和特征短语数目的挖掘结果有很大的影响.在此,为将计算过程中的产生短语数控制在一个合适的范围,便于考察抽取短语的质量,随机抽取了部分文档6.54M(10类文档共1万篇)进行了本实验,将WS-FPMA算法和Apriori算法进行对比测试,实验结果如图6.
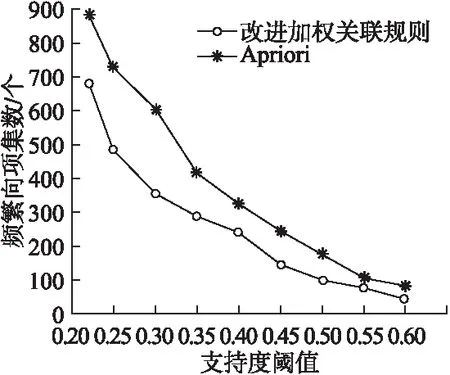
图6 不同阈值在频繁词集数上的比较Fig.6 Number of frequent words with different thresholds
从图6可见wminsup变化时,频繁词集的数目变化情况.总体来看,两种算法都是wminsup越大,得到的频繁词集数目越少.但在支持度阈值一定时,提出的WS-FPMA算法比Apriori算法得到的频繁词集要少,通过具体验证发现这些频繁词集都是有效词集.因为每个词项集具有不同的权重,且重要的词具有较高的权重,所以挖掘出的频繁词项集质量较高,而不是返回一些频率较高但表征性较弱的词项集.图6中当阈值在0.35至0.4之间时,曲线较为平缓,且挖掘的频繁词集较为有效,因此实验中将wminsup分别设置为0.35,0.38和0.4对挖掘出的短语数目和质量进行了专门的考察.
支持度和置信度反映了关联程度的强弱,若阈值设置得过低,会将关联关系较弱的规则也放入到结果集中;若设置得过高,则导致结果集中的规则过少不能反映实际情况.而定义3中wminsaw是支持度、置信度的加权和,参数α为权重取值的重要因子.综上,本实验中结合频繁词项集的共现关系特征,将α设置为{0.45,0.5,0.55}、wminsaw设置为{0.35,0.4,0.45}.根据二者与wminsup的组合关系,分别进行了三组共九个实验考察了它们对挖掘出的短语数目的影响.从图7中可看出,当α = 0.45时,其挖掘短语的数目较多,随着支持度阈值wminsup和语义关联强度阈值wminsaw的增大,短语的数目逐渐减少.当wminsaw=0.4时,虽然其短语数目相对较少,却体现出短语之间的共现性和相关性,并保留了较多的高质量短语.随着wminsaw继续增大,抽取的短语质量较高但数量较少,会导致部分特征短语被忽略了.由此可见,将wminsup、wminsaw和α分别设置为0.35、0.4和0.45较为合理.

图7 不同阈值在挖掘短语数上的比较Fig.7 Number of phrases with different thresholds
实验2.WS-FPMA算法在准确率和召回率上的比较.
为了验证所提出的基于词序列挖掘关键短语算法(WS-FPMA)抽取效果,将该算法与已有KEA算法[13]、TextRank算法[14]和SegPhrase算法进行比较,结果如表1和图8所示.

表1 各算法的抽取结果示例Table 1 Examples of extraction results
首先以对段落“被告人张某携带一把弹簧刀在福州市晋安区鼓山镇某店门口,乘坐被害人宋某所驾驶的某出租车,当车行驶至仓山区义序望峰路上的偏僻处时,张某将该车车钥匙拔下,并持刀、架在被害人宋某的脖子上进行威胁,抢走被害人宋某身上一部联想A60型手机及现金人民币91元.”抽取为例,从表1中可见:
KEA和TextRank算法只能抽取出单个词语,无法抽取短语,对原文本的语义表达较弱,而SegPhrase和WS-FPMA算法抽取的是频繁词或短语,但相比前者WS-FPMA抽取的结果更加完整,能够更好地表达原文的语义.
从图8可以看出,四种算法的总体趋势是相似的,即准确率和召回率呈现出负相关关系.通过比较可见,提出的WS-FPMA算法的计算效果要优于其它三种算法.由于考虑单个词在词序列中的实际语义,以及同义词的计数,实验表明,所提算法抽取较多的短语,且在召回率一定的情况下,具有较高的准确率.

图8 召回率和准确率上的比较Fig.8 Comparison of precision and recall
实验3.考察MR-FPMA算法的计算效率.
为说明前文提出的在MapReduce环境下实现WS-FPMA的并行计算方法,在计算效率上有着显著的提高,本组实验分别选取SegPhrase算法、WS-FPMA算法与之进行比较.

图9 运行时间的比较Fig.9 Comparison of runtime for different size of data
图9显示的实验结果可以看出,所有算法随着文档数据量的不断增加,算法的运行时间会越来越长.在相同计算规模下,SegPhrase算法需要的计算时间最长,这是因为其在候选短语挖掘时产生了大量的非频繁候选集.WS-FPMA算法在数据量不是很大的情况下,其运行性能要比SegPhrase略高一点.但在文档量逐渐增大时,会发生内存溢出的问题,所以运行时间量无法确定.由于MR-FPMA算法是基于 MapReduce计算模型的,不会出现内存溢出的问题,同时还具有较好的可伸缩性.图9表明,采用8个Reduce节点的MR-FPMA-8和比采用5个Reduce节点节点的MR-FPMA-5具有更好的性能,且在实验过程中未出现内存溢出现象.
6 结 论
从大规模的文本数据中提取出特征短语,在海量文本数据挖掘和分析中具有重要理论研究意义和实现应用价值.通过分析发现,中文文本语句中的词语存在着有序性、可重复性和同义性等特点,结合词语在句子中的角色表达,通过对加权频繁词集算法进行改进,提出基于词序列的频繁短语挖掘算法——WS-FPMA.同时,为了保证处理海量文本数据的计算效率,利用MapReduce计算模型思想,提出了基于MapReduce的频繁短语挖掘算法——MR-FPMA.实验表明,WS-FPMA可以较好地提升特征短语的挖掘质量,但其内存消耗较大.实验表明,无论是计算效率,还是挖掘效果,MR-FPMA均有较好的表现.在今后的工作中,将研究短语质量评估的量化模型,通过对所提算法进行优化,以获得更高的计算效率和更好的计算效果.
:
[1] Zakariae A M,Bouchra F,Brahim O.Automatic keyphrase extraction:an overview of the state of the art[C].2016 4th IEEE International Colloquium on Information Science and Technology(CiSt),2016:306-313.
[2] Xu Ya-bin,Li Zhuo,LV Fei-fei,et al.Rapid discovery of new topics in microblogs based on frequent words sets clustering[J].Systems Engineering Theory and Practice,2014(S1):276-282.
[3] Koo T,Pérez X C,Collins M.Simple semi-supervised dependency parsing[C].Association for Computational Linguistics,2008:595-603.
[4] Quiniou S,Cellier P,Charnois T,et al.What about sequential data mining techniques to identify linguistic patterns for stylistics[C].International Conference on Computational Linguistics and Intelligent Text Processing,2012:166-177.
[5] Ye F,Xiong J,Xu L.A text association rules mining method based on concept algebra[C].Green Computing and Communications,IEEE,2013:2153-2158.
[6] Danilevsky M,Wang C,Desai N,et al.Automatic construction and rankingoftopicalkeyphrasesoncollectionsofshortdocuments[M].Proceedings of the 2014 SIAM International Conference on Data Mining,2014:398-406.
[7] El-Kishky A,Song Y,Wang C,et al.Scalable topical phrase mining from text corpora[J].Proceedings of the Vldb Endowment,2014,8(3):305-316.
[8] Liu J,Shang J,Wang C,et al.Mining quality phrases from massive text corpora[C].ACM SIGMOD International Conference on Management of Data.ACM,2015:1729-1744.
[9] Ali C B,Wang R,Haddad H.A two-level keyphrase extraction approach[M].Computational Linguistics and Intelligent Text Processing,Springer International Publishing,2015:390-401.
[10] Cai C H,Fu A W C,Cheng C H,et al.Mining association rules with weighted items[C].Database Engineering and Applications Symposium,1998,Proceedings,IDEAS′98,International,IEEE,2000:68-77.
[11] Yu R M,Lee M G,Huang Y S,et al.An efficient frequent patterns mining algorithm based on MapReduce framework[C].International Conference on Software Intelligence Technologies and Appliations,2014:1-5.
[12] Cui Yan,Bao Zhi-qiang.Survey of association rule mining [J].Application Research of Computers,2016,33(2):330-334.
[13] Witten I H,Paynter G W,Frank E,et al.KEA:practical automatic keyphrase extraction[C].ACM Conference on Digital Libraries,August 11-14,1999,Berkeley,Ca,Usa.DBLP,1999:254-255.
[14] Mihalcea R,Tarau P.TextRank:bringing order into texts[J].Unt Scholarly Works,2004:404-411.
附中文参考文献:
[2] 徐雅斌,李 卓,吕非非,等.基于频繁词集聚类的微博新话题快速发现[J].系统工程理论与实践,2014(S1):276-282.
[12] 崔 妍,包志强.关联规则挖掘综述[J].计算机应用研究,2016,33(2):330-334.
