互联网软件错误日志聚类
2018-07-05程世文王长进
程世文,裴 丹,王长进
1(清华大学 计算机系,北京 100084)2(北京小桔科技(滴滴出行)有限公司,北京 100193)
1 引 言
互联网服务已经深入到用户生活的方方面面,用户对互联网服务体验的要求越来越高,这正是互联网内容提供商所面临着的巨大的挑战.互联网内容提供商在实际运营过程中,所维护的各项服务业务随时可能会遇到各种各样的问题,这就需要收集相应的日志,并对错误日志进行分析和处理.因此,将问题对应的错误日志及时反馈给相应的研发人员是排除问题的首要因素.
在互联网内容提供商收集日志的过程中,即使采用采样的方式,收集到的日志的数量也是十分巨大的,往往也是以TB甚至PB为单位.并且,很多错误日志是完全相同或者相似的,错误日志的不同种类仅占极少数.仅以错误日志举例,本文研究的某互联网公司每天采样收集到的错误日志量约10-20TB,但其中错误日志的不同种类只占到了400-800种左右.将如此巨大数量的错误日志直接反馈给研发人员进行逐条人工排错,显然是不可行的.因此,对海量错误日志进行预先聚类则显得非常重要.
在实际收集的错误日志中,往往具有如下挑战:
1)日志数量巨大;
2)格式不规范,变量较多,无法全部清洗;
3)干扰数据较多,较难提取特征信息;
4)聚类效果、性能要求较高,难度较大.
在日志聚类方面,国内外的一些研究学者也进行了不少的研究与应用.Xu[1]等人提出了对控制台日志(Console logs)的预处理,但这些日志是形如“starting:xact (.*)is (.*)”的模板日志,非常规范且种类有限,通过相应的正则表达式即可匹配识别.Qiu[2]等人设计并实现了SyslogDigest系统,提出了对路由设备的syslog的压缩和提取算法,通过进行词频统计分析构建出syslog的模板树,模板树中根节点到叶节点的所有路径就是syslog的模板,也即所有syslog的种类.但syslog词数有限、日志规范、易模板化,不适应中文,且同一类型下不同形式的日志不能通过该算法区分.
在特征提取方面,目前常用的方法是基于统计的特征选择方法,包括信息增益方法(IG)、互信息方法(MI)、开方拟合检验方法(CHI)、文档频率方法(DF)等[3,4].文档频率方法与其它方法比较,算法实现简单、复杂度低,且效果、性能相差不多[5].杨凯峰等[6]实验结果表明,在进行特征选择时,高词频特征词对类别的贡献可提高传统DF方法的分类性能.
针对以上提到的问题,本文提出互联网软件错误日志聚类方法.该方法通过引入日志模板提取、日志压缩方法降低日志规模;通过引入计算文档频率提取特征词方法提高聚类准确性并降低数据维度;结合Canopy聚类和K-means聚类算法提升聚类效果.本文的聚类方法有效地解决了实际运维中海量非规范日志的聚类问题,并在某互联网公司中进行了实际验证.
2 错误日志介绍
互联网公司运维部门一般需要将从各个业务收集上来的海量错误日志进行聚类处理,将聚类结果及时反馈给相应业务的研发人员,用于排除业务中存在的问题,从而及时止损.本文研究的公司为一个在中国领先的移动出行公司,日订单量1000万以上.
2.1 错误日志信息
该公司中的日志格式示例如下:
[日志级别][时间戳][扩展区域] 日志信息
其中日志级别用于区分不同的日志类别(严重程度),包括FATAL、ERROR、WARNING、INFO、DEBUG,错误日志则是日志级别为FATAL、ERROR或WARNING的日志.扩展区域用于自定义,作为扩展字段,可以打印一些用于调试的必要信息等.日志信息记录了日志的具体信息,如运行时信息、参数信息、状态信息等.
本文中,错误日志的日志信息简称为错误日志信息,因此,对错误日志聚类即是对错误日志信息聚类.错误日志信息举例如表1所示.
2.2 错误日志分类
由于实际研发过程中并没有完全统一日志信息规范,所以收集的日志信息形式可能千差万别并且无法预期.由表1示例,错误日志主要分为三类:
1)常量型,如编号1、2、3;
2)变量型,如编号4、5,含少数不重要的变量,比如进程号;
3)任意型,如编号6、7、8、9,常为非规范的、无法预期的结构形式.
2.3 聚类挑战
由于公司业务的快速发展,带来日志量急速增长,同时相应的日志规范没有跟上,以及研发人员素质参差不齐,导致收集的错误日志不规范、干扰数据较多.这些都给错误日志聚类带了巨大的挑战:
1)日志数量巨大
某互联网公司某运维场景下错误日志的收集数量约为150万条每分钟,大小约3.3GB每分钟;以此推算,相应的数据为9000万条每小时,200GB每小时;21.6亿条每天,2.4TB每天.
2)变量较多,无法全部清洗
错误日志信息中的变量名、变量名与变量间的格式无法预知,且变量较多,无法通过清洗变量来分析出所有的错误日志模板.

表1 某互联网公司某运维系统下的错误日志信息示例Table 1 Error log message examples in an operation system of an Internet company
3)干扰数据较多,难以提取特征信息
错误日志信息可能包含如token、id、key、ticket、等md5、base64编码的干扰数据,此外还有中文、Unicode等干扰,对提取错误日志的特征信息造成了很大的难度.
4)聚类效果、性能要求较高,难度较大
对海量非规范的错误日志进行聚类,要达到聚类效果较好、性能较高,并且需要经得起公司运维系统的实际验证,难度较高.
3 解决思路
本文提出,对几个不同时间段内的错误日志数据(每个时间段时间跨度约30分钟,数量约4500万条,大小约100GB),分别进行聚类分析,对所有聚类结果计算平均频度占比,可以得到如下结果:
1)错误类别总数约270个;
2)将错误类别的频度由高到低排序,前80个错误类别的频度较高,高于100,长尾的是频度较低的错误类别;
3)前5个错误类别的平均占比总和约为57.1%,前10个错误类别的平均占比总和约为68.5%,前15个错误类别的平均占比总和约为74.2%,如图1所示.
因此,在短时间内出现的错误类别总数较少,同时容易出现大量相同类别的错误日志,且频度较高.
针对前述挑战和以上错误日志特点,本文提出解决思路如下:
1)日志数量巨大
由于错误类别总数较少,可以将完全相同或较为相似的错误日志进行压缩合并.常量型的日志可以直接压缩合并,而变量型和任意型的日志则需要进一步进行清洗处理,提取出日志模板后才能继续压缩合并.
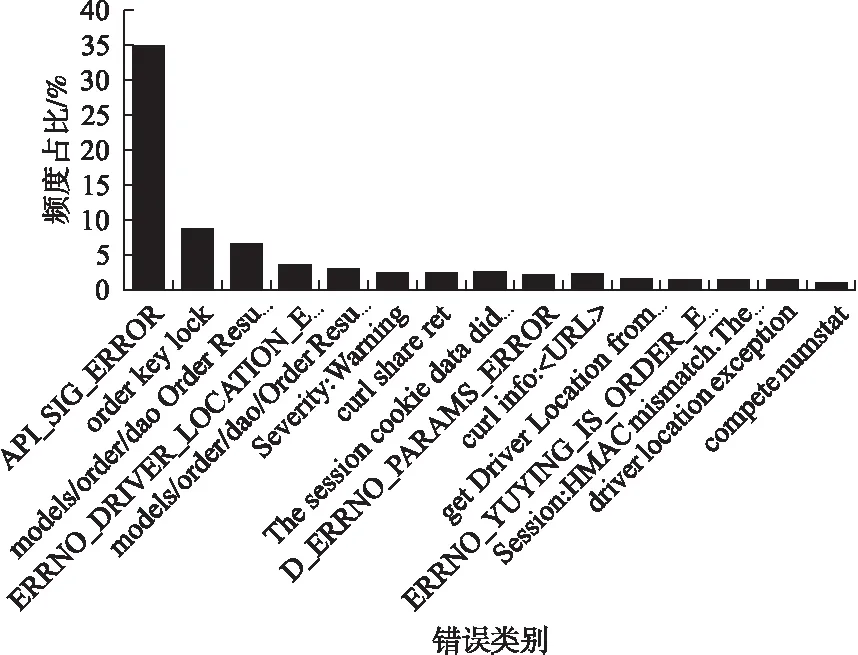
图1 前15个错误类别平均频度占比图Fig.1 Average frequency ratio of the top 15 error categories
2)变量较多,无法全部清洗
通过对错误日志中的变量进行清洗替换处理,可以提取相应的日志模板.提取模板可以大大减少变量对聚类的干扰,但模板中仍然可能存在着无法预期的变量,这个问题可以通过后续特征词提取来减少甚至避免这类变量造成的聚类干扰.模板提取后再进行日志压缩,将会得到更好的压缩效果.
3)干扰数据较多,难以提取特征信息
由于同种类别的错误日志在某些特征信息上表现相同或者较为相似,而不同类别的错误日志的特征信息则表现完全不同或者相差较大.因此,可以根据特征信息来对错误日志进行聚类.由于一条错误日志中可能包含干扰的数据项,如变量,它们并不能表征错误日志的特征信息,所以不能采用日志的所有信息作为它的特征信息.
本文采用基于文档频率的统计方法,来提取日志模板中的特征词,并用特征词来表征错误日志的特征.其核心思想为:在所有日志中出现频率越高的词,越能表征该词所在日志的类别特征;而在所有日志中出现频率越低的词,如变量,则表征日志的类别特征的可能性越低.
然后使用提取的特征词来建立向量空间模型(Vector Space Model,VSM)[7],从而确定特征向量,并用特征向量来表征错误日志的特征.提取特征词可以有效地减少建立向量空间模型的维度,从而降低计算复杂度.
4)聚类效果、性能要求较高,难度较大
通过日志模板提取、日志压缩,可以大大减少日志的数据规模.通过文档频率的方法来提取日志模板的特征词,建立特征向量,不但能很好地表征错误日志的特征,而且降低了数据维度.
对特征向量进行聚类,采用经典的K-means聚类算法[8],其原理简单,计算时间短,速度快,聚类效果较好,但需要确定K值和K个初始质心,这里事先采用Canopy聚类算法[9].Canopy聚类算法是无监督的预聚类算法,通常用于K-means算法或层次聚类算法之前的处理阶段.相对于传统的聚类算法,Canopy聚类算法不需要事先指定聚类的个数(如K-means的K值),并且在大规模的高维度数据上速度较快,在实际工程中有很大的价值及优势.其缺点是聚类精度较低,准确度不高.
因此,可以使用Canopy聚类算法进行粗聚类,得到的聚类数和聚类中心作为K-means的K值和初始质心.这样可以有效地确定合理的K值,同时可以避免K个初始质心选择的不合理导致对聚类结果产生较大的影响.
通过上述方法,错误日志聚类可以很好地达到聚类效果较好、性能较高的要求.
4 系统架构与实现
4.1 系统架构
错误日志聚类系统架构如图2所示.

图2 错误日志聚类系统架构图Fig.2 System architecture of the error log clustering
该系统架构由错误日志(数据输入)、模板提取、日志压缩、计算文档频率提取特征词、建立特征向量、Canopy粗聚类、K-means细聚类、错误类别(结果输出)组成,各个功能如下:
1)错误日志:错误日志数据输入端,每条数据为一条错误日志信息.
2)模板提取:根据替换规则,清洗替换掉错误日志中不相关、不重要的变量和干扰项,进而提取出日志模板.替换规则可由人工进行配置.
3)日志压缩:对提取后的日志模板中大量完全相同的模板进行去重压缩,输出相应的日志模板条数.
4)计算文档频率提取特征词:使用文档频率方法提取出每条错误日志模板的一些特征词,用来表征相应错误日志的特征信息.
5)建立特征向量:将所有错误日志模板提取出来的特征词合并成一个集合,其中每一个元素构成向量空间的一个维度,建立向量空间模型,从而每条错误日志可以由提取出来的特征词确定相应的特征向量.
6)Canopy粗聚类:使用Canopy聚类算法先对数据进行粗聚类,得到聚类数和聚类中心后再使用K-means聚类算法进行进一步细聚类.
7)K-means细聚类:取K=Canopy聚类数,并且选择Canopy粗聚类后的K个中心点作为K个初始质心,使用K-means聚类算法进行细聚类.
8)错误类别:错误类别数据输出端,每条数据为一种聚类类别,及其对应的原错误日志样本和错误日志数量.
4.2 系统实现
4.2.1 模板提取
根据给定的替换规则,对错误日志进行清洗替换,提取出日志模板.替换规则越多,则提取后的错误日志模板的质量更好,干扰项数据更少.以下给出部分初始的替换规则,基于正则表达式进行依次替换,如表2所示.

表2 部分初始的替换规则Table 2 Part of the initial replacement rule
例如,“the request url is http://example.com/test”提取的日志模板为“the request url is
4.2.2 日志压缩
本文采用的压缩条件为提取后的日志模板完全相同,日志压缩的实现算法如下:
算法1.日志压缩算法
输入:提取后的日志模板列表LOGS
输出:压缩后的日志、统计条数键值对MLOGS,其中每个条目为
1)MLOGS= HashMap()
2)for log in LOGS:
3)if MLOGS has key log:
4)MLOGS.set(log,MLOGS.get(log)+ 1)
5)else:
6)MLOGS.set(log,1)
4.2.3 计算文档频率提取特征词
本文中,每条错误日志模板都视作一篇文档,每篇文档进行分词后都会得到若干词,其中一些词可以表征类别特征,它们对聚类有贡献;另外一些词,则不能表征类别特征,它们会干扰聚类.因此,应对这些分词根据一定特征进行选择,选择的分词作为特征词来表征错误日志的类别特征,即从原始的分词中选取一个子集,将干扰大、表征信息少、不重要的分词移除,从而得到特征词集合.对一个特征词,统计该词的文档频率,即包含该词的文档数,则文档频率越大,说明该词越能表征某种类别特征.所以,出现的文档数越多的分词被留作特征词的可能性越大.在文档频率方法中,将每篇文档进行分词,根据分词的文档频率对分词进行排序,保留文档频率高的前若干个分词构成特征词集合.
实际聚类过程中,可能遇到一类词,其出现次数较多,可能在一部分类别中都会出现,但对聚类几乎无贡献、没有较大的表征意义,如“a”“X”“2”等,其被称作为停用词(Stop Words)[10].在提取特征词过程中,需要对停用词进行过滤.停用词支持运维人员调整修改,初始的停用词为数词和单字母词.
计算文档频率提取特征词算法如下:
算法2.计算文档频率提取特征词
输入:压缩后的日志、统计条数键值对MLOGS
输出:日志、特征词键值对FWS,其中每个条目为
1)// 分词、过滤停用词
2)SWS = HashMap()// Split Words
3)for
4)words = split_words(log)
5)words = unique(words)
6)words = remove_stop_words(words)
7)SWS.set(log,words)
8)// 计算文档频率
9)DF = HashMap()// Document Frequency
10)for
11)words = SWS.get(log)
12)for word in words:
13)if DF has key word:
14)DF.set(word,DF.get(word)+num)
15)else:
16)DF.set(word,num)
17)// 提取特征词
18)FWS = HashMap()// Feature Words
19)for
20)words = SWS.get(log)
21)features = calc_top10_df_words(words)
22)SWS.set(log,features)
4.2.4 建立特征向量
提取出所有错误日志模板的特征词后,设所有特征词的集合为S={fw1,fw2,…,fwn},并依次构成n维向量空间的各个维度,则对于错误日志L及其特征词集合FWL,其特征向量定义为
VL=[v1,v2,…,vn],其中
所有错误日志的特征向量构成特征向量集合D.
4.2.5 Canopy聚类
Canopy聚类算法需要首先设定两个阈值T1(松散距离),T2(紧凑距离),要求T1 > T2;然后计算数据点之间的距离,会将距离相接近的数据点放入到一个子集中,这个子集被称作Canopy;最后通过一系列计算得到若干个Canopy,Canopy之间可以重叠,但不会存在某个数据点不属于任何Canopy的情况.
使用Canopy算法聚类后,结果如图3所示.
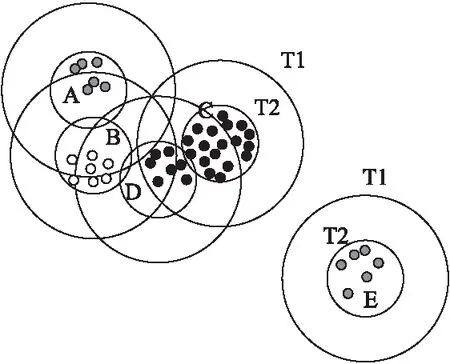
图3 Canopy聚类结果图Fig.3 Result of Canopy clustering
其中,T1过大,则会导致较多的迭代次数,形成较多的Canopy;T1过小则效果相反.T2过大,则会导致一个Canopy中的数据较多;T2过小则相反.由于本文使用Canopy聚类算法仅进行粗聚类,即计算出Canopy聚类数,用作下游K-means聚类算法的K值,所以聚类精度要求不高,实际工程中设定T1=2*T2,T2初始值为2.
4.2.6 K-means聚类
K-means聚类算法需要首先设定K值,从数据集中选定K个点作为最初的质心;然后将D中的每个数据划分到离质心最近的簇中,形成K个簇,并重新计算每个簇的质心;重复上述过程,直到簇不发生变化.
在K-means聚类算法中,取K=Canopy聚类数,并且选择Canopy粗聚类后的K个中心点作为K个初始质心.
5 评 估
5.1 效果评估
由于聚类没有统一的评价指标,并且错误日志数据量巨大,无法事先人工标注,目前只能根据实际问题和场景,由相应的领域专家和工程师对聚类之后的结果进行确定和评价.

表3 聚类效果部分结果Table 3 Part results of clustering effect
本文经过一段时间对聚类类型和相应的样本进行了评估,合作的领域专家和工程师认为聚类有效且达到比较理想的效果.某个时间段里聚类效果部分结果如表3所示.
其中类别是聚类类别的编号,总数是这一时间段中相应的错误日志总数,日志模板即为提取的日志模板信息.例如,错误类别11、日志模板为“stop pay fail ret_info errno errmsg”的一个日志样例为“errno:80051 errmsg:stop pay fail | ret_info:{″errno″:″80051″,″errmsg″:″\u5173\u5355\u5931\u8d25″}”;错误类别12、日志模板为“Warning getBillInfo empty orderId passengerId”的一个日志样例为“Warning:getBillInfo empty|orderId:3267678|passengerId:159631166”.
5.2 性能评估
本地测试所用硬件环境为一台双核i5-3337U,1.80GHz,4GB内存的笔记本电脑,操作系统为Windows 10,所使用的语言为Java和Python2.7.
5.2.1 模板提取性能
语言为Java,部分测试结果如表4所示,在几个不同场景下的测试结果中,处理速度达到7.31-9.91万条每秒.处理速度跟日志信息具体内容有较大关系,每条日志信息越长则处理速度较慢,每条日志信息越短则处理速度较快.

表4 模板提取性能Table 4 Performance of template extraction
5.2.2 日志压缩性能
语言为Java,部分测试结果如表5所示,在几个不同场景下的测试结果中,压缩比达到342.1-1095.8,处理速度达到40.33-85.47万条每秒.压缩比跟日志条数大致呈现正相关,即压缩比随着日志条数增加而增大.这表明在短时间内错误类别数量维持在一定水平,日志条数大幅增加不会使得错误类别数量急剧上升.
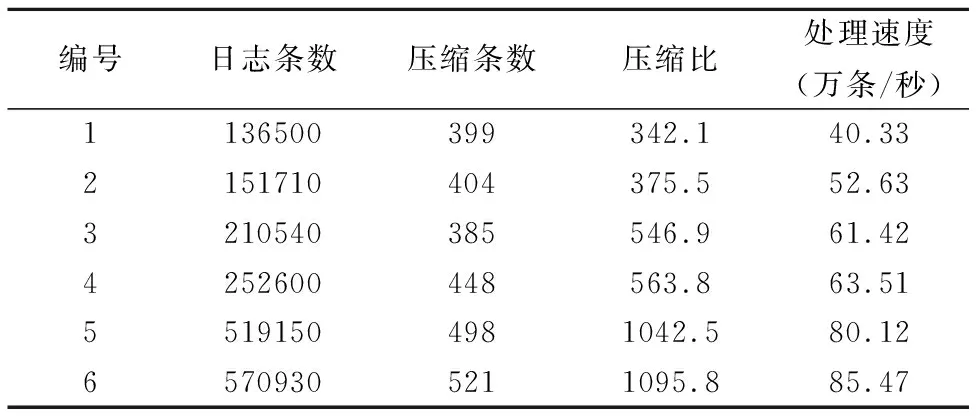
表5 日志压缩性能Table 5 Performance of log compression
5.2.3 Canopy粗聚类性能
语言为Python2.7,部分测试结果如表6所示,其反映了不同压缩条数和向量维度下Canopy的处理时间.压缩条数越大、向量维度越高,处理时间越长.
5.2.4 K-means细聚类性能
语言为Python2.7,使用scikit-learn机器学习库中的K-means聚类算法,部分测试结果如表7所示,其反映了不同压缩条数和向量维度下K-means的处理时间.压缩条数越大、向量维度越高,处理时间越长,但远远优于Canopy粗聚类处理时间.

表6 Canopy粗聚类性能Table 6 Performance of Canopy clustering
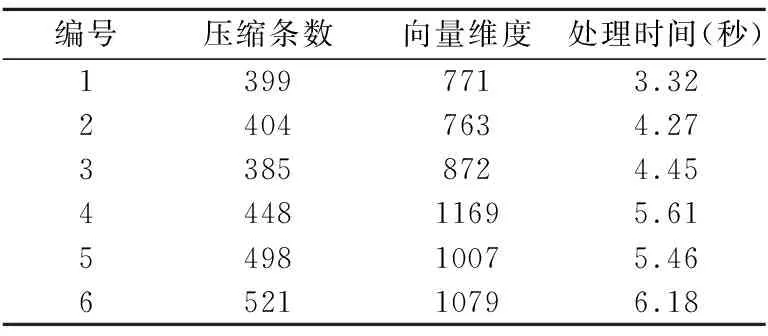
表7 K-means细聚类性能Table 7 Performance of K-means clustering
5.2.5 整体系统性能
实际生产环境中的性能要远优于本地单机硬件环境.在某互联网公司某子系统下错误日志量产生速度约为2万条每秒,压缩后处理时间完全满足性能要求.
6 结 语
在互联网公司对海量非规范的错误日志进行聚类的过程中,往往会遇到几大挑战:
1)日志数量巨大;
2)变量较多,无法全部清洗;
3)干扰数据较多,难以提取特征信息;
4)聚类效果、性能要求较高,难度较大.
针对上述挑战,本文提出了互联网软件错误日志聚类方法,通过引入日志模板提取、日志压缩方法降低日志规模;通过引入计算文档频率提取特征词方法提高聚类准确性并降低数据维度;结合Canopy聚类和K-means聚类算法提升聚类效果.通过在某互联网公司运维中实际系统的检验,本文提出的错误日志聚类方法,不但具有比较理想的聚类效果,而且满足生产环境中的性能要求.
:
[1] Xu W,Huang L,Fox A,et al.Detecting large-scale system problems by mining console logs[C].Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles,ACM,2009:117-132.
[2] Qiu T,Ge Z,Pei D,et al.What happened in my network:mining network events from router syslogs[C].Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement,ACM,2010:472-484.
[3] Galavotti L,Sebastiani F,Simi M.Experiments on the use of feature selection and negative evidence in automated text categorization[C].European Conference on Research and Advanced Technology for Digital Libraries,Springer-Verlag,2000:59-68.
[5] Shan Song-wei,Feng Shi-cong,Li Xiao-ming.A comparative study on several typical feature selection methods for Chinese web page categorization [J].Computer Engineering and Applications,2003,39(22):146-148.
[6] Yang Kai-feng,Zhang Yi-kun,Li Yan.Feature selection method based on document frequency[J].Computer Engineering,2010,36(17):33-35.
[7] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[8] MacKay,David.Chapter 20.an example inference task:clustering[M].Information Theory,Inference and Learning Algorithms,Cambridge University Press,2003:284-292.
[9] McCallum A,Nigam K,Ungar L H.Efficient clustering of high-dimensional data sets with application to reference matching[C].Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2000:169-178.
[10] Rajaraman A,Ullman,J D.Data mining[M].Mining of Massive Datasets,2011:1-17.
附中文参考文献:
[5] 单松巍,冯是聪,李晓明.几种典型特征选取方法在中文网页分类上的效果比较[J].计算机工程与应用,2003,39(22):146-148.
[6] 杨凯峰,张毅坤,李 燕.基于文档频率的特征选择方法[J].计算机工程,2010,36(17):33-35.
