社交网络中基于影响力的紧密子图发现算法
2018-07-04简兴明游进国梁月明贾连印
简兴明,游进国,梁月明,贾连印
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
对于社会团体中的成员,社交网络影响力主要研究他们之间的意见或行动相互作用或相互影响的现象.社交网络影响力分析对于理解信息、观念和创新跨社交网络传播的方式有很大的用处.随着越来越多的人参与社交网络,社交网络以多种形式呈现出来,比如:聊天工具上用户之间的好友关系、DBLP上作者之间的合著关系、电影中演员之间的合作关系、科学家之间的合作关系等.分析与挖掘社交网络中的社交网络影响力可以为社交网络中的人们如何相互作用和相互影响,以及为什么不同主体的想法和意见在社交网络中的传播方式不同提供了新的见解.
社交网络研究的发展和社交网络规模的进一步扩大,对数据挖掘领域提出了更多的要求.如预测某一作家下次的合著对象,朋友圈的好友推荐等.在社交网络中,人与人之间的关系就是一个庞大的交互网络,在社交网络中寻找交流频繁的群体可以帮助广告商更有效地投放发布信息;在科研合作关系图中,紧密子图可以发现诸如研究领域中具有紧密合作关系的团队,这类团队可能具有更强的综合竞争力;在商品交易网络中,寻找具有紧密关系的客户群,可以更快的打入市场,具有更高的商业价值.
在社交网络的大多数应用中,边一般用来描述实体之间的关系.由于社交网络规模庞大且关系稀疏,顶点及边的存在性并不明确,所以紧密子图自然成为研究这些网络的重要模型.然而到目前为止,紧密子图的相关的研究工作并不多,而且大多是关于无向图的.但是在真实社交网络中,人与人之间的关系通常是相互的.例如对社交网络影响力的分析,如图1在成员b与成员d的合作中,b可以影响d,而同时d也对b也产生了影响,而且b与d的合作也对整个社交网站中其它的成员顶点产生了影响.本文同样是在社交网络中寻找较密集的子图,但本文是基于社交网络环境下的数据规模较大和网络拓扑结构动态变化的特征,结合社会网络中顶点的相似度来分配权重,设计了一种基于影响力动态演化传播的紧密子图发现算法,再自适应地设定紧密阈值,发现紧密子图,这在实际中具有更好的实用性.

图1 加权图Fig.1 Weighted graph
2 相关工作
2.1 社交网络影响力分析和紧密子图发现
近年来社交网络影响力的分析越来越重视.[1]介绍了一种社交网络中影响力最大化算法.[2]提出了一种级联病毒式营销的算法.[3]提出了以前K个最有影响力的节点为主的病毒营销模式.[4]在特定的一颗小小的种子集合上,利用用户的隐含的社交网络产生一个朋友圈的集群.[5]提出了一种信息可以通过社交网络拓扑结构传播的模型.[6]结合自身的影响力和各种活动的影响力来解决异构社交网络中聚类的问题.
然而到目前为止,紧密子图的相关的研究工作才刚刚开始,而且主要是针对无向图的.[7]提出了一种多目标跟踪的紧密子图发现算法.[8]提出了一种结合图的结构特征和节点属性的紧密子图发现算法.对不确定图的紧密查找算法主要包括计算不确定图中的最可靠子图[9],对不确定图进行TOP-K稠密子图挖掘[10],挖掘不确定图中的频繁模式[11],极大频繁模式[12],从不确定图中发现K紧密子图[13].然而将紧密子图应用到社交网络的却很少.[14]提出了一种社交网络中连接紧密的子图结构的社团发现算法.
本文同样是在社交网络中寻找紧密子图,但本文是根据社交网络拓扑中顶点间的相似度来分配权重,改进PageRank算法计算每一个顶点潜在的影响力,自适应地设定紧密阈值,再发现紧密子图,这在实际中具有更好的实用性.据目前研究所知,这项工作是第一个通过动态的结合社交网络图中的个人影响力和成员顶点间的共同影响力,来解决影响力在社交网络中的紧密子图发现问题.
2.2 基本的PageRank算法及其改进和应用
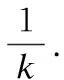
(1)
那么第一步之后随机浏览者的概率分布向量为M·Rank.反复使用转移矩阵M左乘向量Rank,直到得到随机浏览者的分布逼近一个极限概率分布Rank*.随机浏览者的浏览过程实际上是一个典型的马尔可夫过程.只有满足图是强连通图和图不存在终止点两个条件时,随机浏览者的概率分布才趋于收敛.
在实际过程中,随机浏览者并不一定会按照网页的链接结构前进.所以该算法以一个小的概率β允许随机浏览者跳转到链接外的其它页面上,根据之前的迭代过程,修改转移矩阵M,公式为
M′=βM+(1-β)D/n
(2)
其中D是n阶的全1矩阵,M′为新的转移矩阵.PageRank算法提出来以后,很多学者对它进行了改进.[15]将Google的网页排名算法PageRank应用到在线社交网络中.[16]间接修改了PageRank平均分配权重的方式,提出了一种有效防止主题漂移的领域相关自适应的算法.本文同样是采用不平均分配权重的方法,以M′顶点间的有向相似性来分配权重,以为转移矩阵,改进PageRank算法计算每一个顶点的潜在的社交网络影响力.
3 模型
3.1 问题引入
本文将在线社交网络及其中的关系抽象为图,形式化描述如下:
定义1.(社交网络图)社交网络图是一个三元组SG(U,E,R),U是图中的节点集合,即社会网络中用户集合,E是边的集合,R是权重,对于无向边Euv,其中u,v∈U,且有权重Ruv=Rvu.
给定一个无向社交网络图SG(U,E,R).如图1所示:顶点a-f表示社交网络中6个不同的人,顶点之间的边表示成员之间在社交网络中有合作关系,顶点之间的边上的权重代表成员顶点之间的合作的强度,权重值越大说明两个人的关系越紧密.与成员顶点a合作的有成员顶点b和c,所以与成员顶点a的合作总强度为(Rab+Rac)=0.8而与成员顶点f合作的有成员顶点d.成员顶点f的合作总强度为(Rdf)=0.4.所以使用文献[10]或文献[13]中的方法进行紧密子图发现,紧密子图发现结果如图2所示.
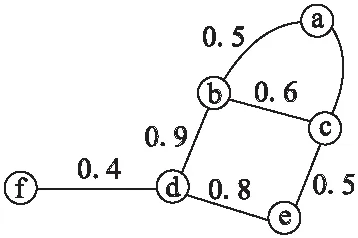
图2 紧密子图发现Fig.2 Result of close subgraph

对此,本文提出了新的加权图的紧密子图发现算法.本文对加权图的紧密子图发现算法的目标包括:(1)紧密子图简洁、显著;(2) 紧密子图包含的发现算法不仅要考虑边上权值的大小,还应考虑顶点所在网络的拓扑结构.
3.2 问题陈述
社交网络图表示为SG=(U,E,R),其中U是代表的社交网络的成员顶点集合,E表示了对成员协作网络之间的协作关系的边集,R代表两个社交网络顶点之间的权重,代表社交网络中顶点之间的合作强度.
定义2(影响力图)影响力图是一个四元组IG=(U,E,T,W),其中U在社交网络图SG中有相同的定义.每条边Euv,连接成员顶点u,v∈U.Tuv代表边Euv上SG中成员顶点u在多大程度上与成员顶点v相似.给定一个社交网络图SG,一个影响力图IG的社交网络影响力为基础的紧密子图发现算法的问题是对于成员顶点u∈U,遍历其邻接点v∈U,并计算顶点间的相似度Tuv,并生成社交网络图上以相似度为基础的两个顶点间的影响力大小.对于顶点u∈U,Wu表示成员顶点u所包含的影响力总量,则Wuv表示SG中成员顶点u与成员顶点v间的综合影响力的大小,例如一次购买或出版活动.所期望的影响力图结果应达到以下两个属性之间的良好平衡:(1)在每一个社交网络中两个成员顶点的影响力是相互的,例如A可以影响B,同时B也影响A;(2)在社交网络的影响力图中,影响力应该在它们之间的相似度和社交网络拓扑结构间取得平衡.
4 基于影响力的紧密子图发现
本节将介绍如何在共同影响力模型下计算顶点间的紧密度.首先,利用顶点间的权重来计算社会网络图中的成员顶点之间的相似度.其次,使用PageRank技术,以成员顶点之间的相似度为权重,在社交网络图中计算每个顶点的潜在的影响力,构成一个共同的影响力的模型.最后,基于共同影响力的模型,计算并生成社交网络图上以影响力为基础的紧密子图.
4.1 相似度的计算
对于给定的社交网络图SG(U,E,R)中,本文根据顶点间的合作关系和合作强度计算影响力图IG=(U,E,T,W)中的相似度T.
目前,大多数的算法都是直接使用边的权重作为社交网络中成员顶点之间的相似度或者作为成员顶点之间的距离[9-13].边的权重虽然可以直观的衡量成员顶点之间的合作强度,但社交网络中两个成员顶点之间的相似度还应考虑到边的权重所占的比例.文献[6]提出了一种计算方法,该方法先计算每个成员顶点的总强度,然后通过边的权重计算相邻两个成员顶点的相似度.该计算方法的优点在于在计算两个成员顶点之间的相似度时综合考虑了每一个成员顶点的工作强度及合作强度所占的比例,而且在两个成员顶点总强度相差较大时,两个成员顶点之间的相似度较小.计算相似度的算法如下:
对于u,v∈U,遍历u所有的邻接顶点l∈U和v所有的邻接顶点k∈U,来计算邻接顶点间的相似度.那么对于相似度Tuv,当∑l∈uRlu=0或∑k∈URkv=0时,有Tuu=1或Tvv=1,否则有
(3)
在影响力图IG=(U,E,T,W)中,对于任意的u,v∈U,都有Tuv=Tvu.Tuv即为两点之间的相似度.
4.2 影响力的传播
一个在某一领域有很多优质作品的作家可以有很多的合作者,他们之间彼此影响并影响着该领域中的大多数人.为了有效地测量在社交网络图中的顶点成员的紧密度,本文首先定义社交网络中的影响力传播方式.通过第2.2节中的公式(1)和4.1节中的公式(3),通过计算两点之间的相似度来改进转移矩阵M.对于转移矩阵Muv,有
(4)
然后本文使用2.2节中的公式(2)和本节中的公式(3)、(4)来计算新的转移矩阵M′.
M′=βM+(1-β)D/n
(5)
对于社交网络图SG(U,E,R)和影响力图IG=(U,E,T,W),通过本节中的公式(3)、(4)和(5)得到的任意两点u,v之间的相似度Tuv以及新的转移矩阵M′.在此,以第1节中的图1为例.

表1 图1的邻接矩阵WTable 1 Adjacent matrix W of Fig.1
根据本节中的公式(3)处理后的邻接矩阵为表2所示:
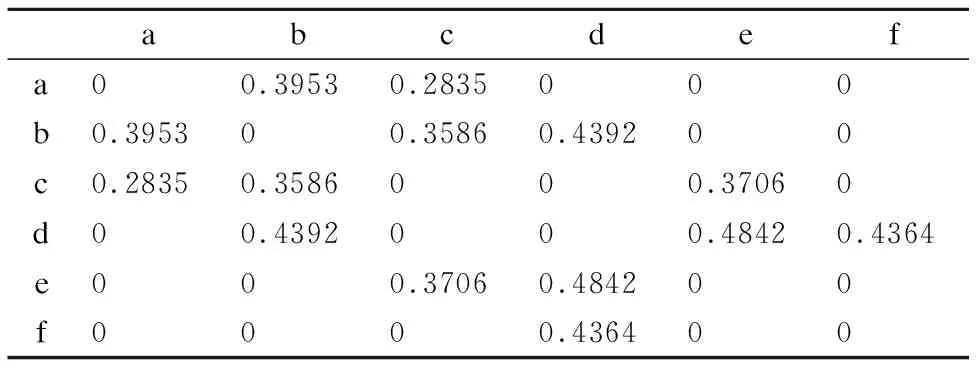
表2 图1的相似度矩阵TTable 2 Similar matrix T of Fig.1
根据上表和本节中的公式(4)、公式(5),采用阻尼系数为0.85处理后的转移矩阵M′为表3所示:

表3 图1的转移矩阵M′Table 3 Transfer matrix M′ of Fig.1
为了计算方便,本文初始化概率分布向量为一个所有分量均为1的n维向量Rank.反复使用转移矩阵M′左乘向量Rank,直到得到概率分布向量的分布逼近一个极限概率分布Rank*.这时Rank*就代表社交网络中顶点的潜在的影响力的分布的列向量,即影响力图IG中的W的列向量.
4.3 以统一的影响力为基础的紧密度测量
通过4.2节得到了成员顶点影响力分布的列向量Rank*,本节使用两点之间影响力的大小来衡量两点之间的紧密度.对于影响力图IG=(U,E,T,W),本文使用成员顶点的潜在的影响力乘以该成员顶点与其它顶点间的相似度,来计算两点之间影响力的大小.Wuv定义如下,
(6)
目前的大多数算法都是将数据直接或者间接处理为顶点间的权重进行聚类或者紧密子图发现的.而本文综合了网络间的拓扑结构,联合顶点间的相似度,使用公式(6)计算成员顶点间的共同影响力,来发现紧密子图.
如图3,的数值为根据4.2中的转移矩阵M′计算得出的顶点的潜在的影响力Wu;括号中的数值即为两点之间影响力流动的数值Wuv,为了方便表示,本文去掉了顶点间影响力小于0.05的表示.当社交网络中的影响力分布趋于一个动态平衡时,本文通过设定阈值,根据顶点间的影响力的大小来计算两点之间的紧密度了.

图3 影响力图Fig.3 Influence graph图4 紧密子图Fig.4 Close subgraph
当本文设置阈值为0.3,由于Wac小于0.3所以本文称,在社交网络影响力阈值为0.3,其中阈值0.3下的紧密子图如图4所示.
5 算法
为了解决社交网络中的紧密子图发现的问题,本文提出了新的紧密子图发现算法.首先,本文介绍一种新颖的顶点间的有向相似度.其次,本文通过顶点度量方面的有向相似度来分配权重,改进PangeRank算法计算每一个顶点潜在的影响力.最后,本文通过设置阈值,量化两点之间的影响力得分发现社交网络中的紧密子图.分别描述如下:
5.1 紧密阈值的设置
本文将分别设置紧密度阈值β来运行生成基于影响力的紧密子图.通过阈β值的设定可以更好的把握成员顶点之间的紧密程度,从而更好的发现紧密子图.
5.2 影响力的传播与计算与影响力图的生成
根据相似度分配每一个顶点的影响力到其它的节点,通过K次迭代传播,两次迭代后Rank向量的欧氏距离小于一定值时,称社交网络的影响力趋于稳定.趋于稳定后的Rank向量即为社交网络中成员顶点的潜在影响力.对于影响力图的生成,有如下定义.
5.3 紧密子图发现
对于5.2中的生成的影响力图IG=(U,E,T,W),设定一个阈值β,通过不断调整β的值来发现基于社交网络的紧密子图.在影响力图IG中,我们通过比较Wuv与β来进行紧密子图的查找.如果两个成员顶点的值大于β,在基于影响力的紧密子图查找算法中,就保留社交网络图SG中这条边;否则,剪掉这条边.在此,我们称为influence-based close subgraph algorithm.算法过程如下:

图5 产生紧密子图算法描述Fig.5 Description of close subgraph algorithm
5.4 算法时间复杂度分析
本算法包含三个步骤.(1)计算成员顶点间的相似度.(2)使用改进的PageRank算法计算每一个顶点潜在的影响力.(3)使用成员顶点的影响力和成员顶点间的相似度计算每两个成员顶点间的共同影响力.其中,计算成员顶点间的相似度复杂度为O(|U||E|).使用成员顶点间的相似度计算成员顶点间的共同影响力的相似度为O(|E|).
本文基于影响力的紧密子图发现算法是基于PageRank改进而来,反复使用转移矩阵M′左乘向量Rank,直到得到概率分布向量的分布逼近一个极限概率分布Rank*.所以本算法的时间复杂度最坏为O(|U||E|).其中|U|为给定社交网络的顶点数,|E|为给定社交网络的边数.
综上,本算法的时间复杂度为O(|U||E|).
6 实验结果及分析
6.1 实验环境
本文的算法是采用Java实现的,实验平台是Java开发工具Eclipse.所有实验都是在一台PC机上运行的,PC机的配置如下:处理器Intel四核,2.4GHz,内存 8GB,Windows7操作系统.
6.2 实验数据
第一组数据集来自小说维克多·雨果的悲惨世界的人物角色关系图(co-appearances between characters)1,简称novel.顶点表示小说中出现的角色,边表示两个角色共同出场的次数.数据是以GML格式进行加载和使用的.图中的顶点数是77个,边数是254条.
第二组来自networks理论中作家的合著关系图(co-authorships in networks)2,简称networks.图中的顶点代表作家,边代表作家之间存在的合著关系,边的权重值表示作家之间的合作强度.数据是以GML格式进行加载和使用的.图中的顶点数是1589个,边数是2742条.
第三组来自arXiv中的科学家之间的合作关系图(cooperation between scientists)3,简称arXiv.图中的顶点代表科学家,边代表科学家之间存在的合作关系,边的权重值表示科学家之间的合作强度.数据是以GML格式进行加载和使用的.图中的顶点数是12946个,边数是23626条.
6.3 阈值的设置和初始化
本文将分别设置紧密度阈值β为0.1-0.7来运行生成基于影响力的紧密子图.为了便于计算,本文初始化概率分布向量为一个所有分量均为1的n维向量Rank.
6.4 实验结果及分析
本文将6.2中的实验数据处理为实验所用的数据.对于经典的PageRank算法,A,B顶点间有合作关系,则A有一条边指向B,B也有一条边指向A.对于基于影响力的改进PageRank算法,本文根据4.1节中的方法计算顶点间的相似度,以4.2节中的M′作为转移矩阵.经典的PageRank算法、基于影响力的改进PageRank算法计算所得的影响力值对比如图5所示,其中横轴表示成员顶点的分布情况,纵轴则表示该顶点的影响力值.
从整体上看,在图5(a),图5(b)和图5(c)中的三组数据集中,当影响力在1附近时时,顶点数最多.影响力的分布具有明显的层次结构,数量分布是“两头小,中间大”,且超过一定范围的顶点数目很少.经对比可发现,三个数据集的影响力分布具有相似性.

图6 数据集实验结果对比Fig.6 Experiment result of datasets comparison
比较图5(a),图5(b)和图5(c)中的三组数据,不难发现,在经典的PageRank算法中,顶点的影响力的差异值要比基于影响力的改进PageRank算法顶点之间的差异更显著.因为在基于影响力的紧密子图发现算法中,较大的权值为合作的双方所共享,所以顶点间的影响力差距并不显著,从而有利于寻找图中具有紧密关系的子图.
目前大多数的紧密子图发现算法,如文献[7]-[11]都是基于特定场景下将数据处理顶点间边的权重进行紧密子图对比的.本文将数据处理为顶点间的相似度,以顶点间的相似度为边的权重与基于影响力的紧密子图发现算法进行了对比.在此,简称为similarity-based和influence-based算法.
本文将基于影响力的紧密子图发现算法与文献[10]中的社交网络中的Top-k紧密子图挖掘算法进行了对比.在阈值β下,本文分别使用紧密子图中连通子图个数对比、平均每个连通子图所含的顶点个数对比、最大连通子图所含顶点个数对比和紧密子图中的稠密度对比,来衡量图的紧密程度.对于稠密度,本文定义为ρ=|L|/|U|,其中|L|表示紧密子图中顶点间的相似度总和,|U|表示紧密子图顶点的个数.
由图7(a)、图8(a)和图9(a)对比结果可知,随着社交网络中阈值β的增加,两种算法的结果中关于连通子图的数量都是先增加后减少的.因为当阈值还较小时,有较多的点对会大于阈值β.所以连通子图的个数也相对较少.随着阈值β的逐渐增加,大于阈值β的点对数量会相对分散,所以连通子图的个数会暂时增加.随着阈值β的进一步增大,连通子图的个数又随之而减少.不难发现,在基于影响力的紧密子图发现算法中,连通子图个数则趋于平稳的缓慢增长或缓慢下降的.由图7(b)、图8(b)和图9(b)对比结果可知:当阈值β缓慢增加时,平均每一个连通子图中所含的顶点个数.由图可知,基于影响力的紧密子图发现算法拥有更好的效果.随着阈值β的进一步增大,两算法的结果逐渐接近.
1http://www-personal.umich.edu/~mejn/netdata
2https://snap.stanford.edu/index.html
3http://www.socialysis.org/data/dataset/dataset
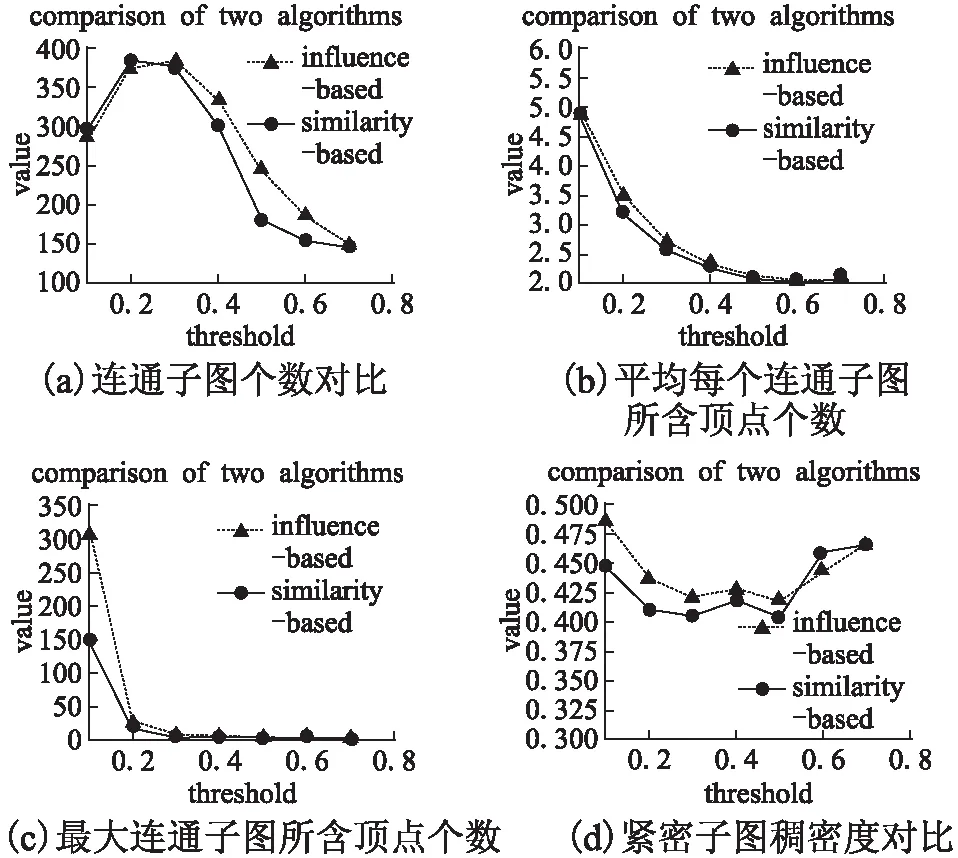
图7 networks数据集实验结果对比Fig.7 Experiment results of the networks dataset
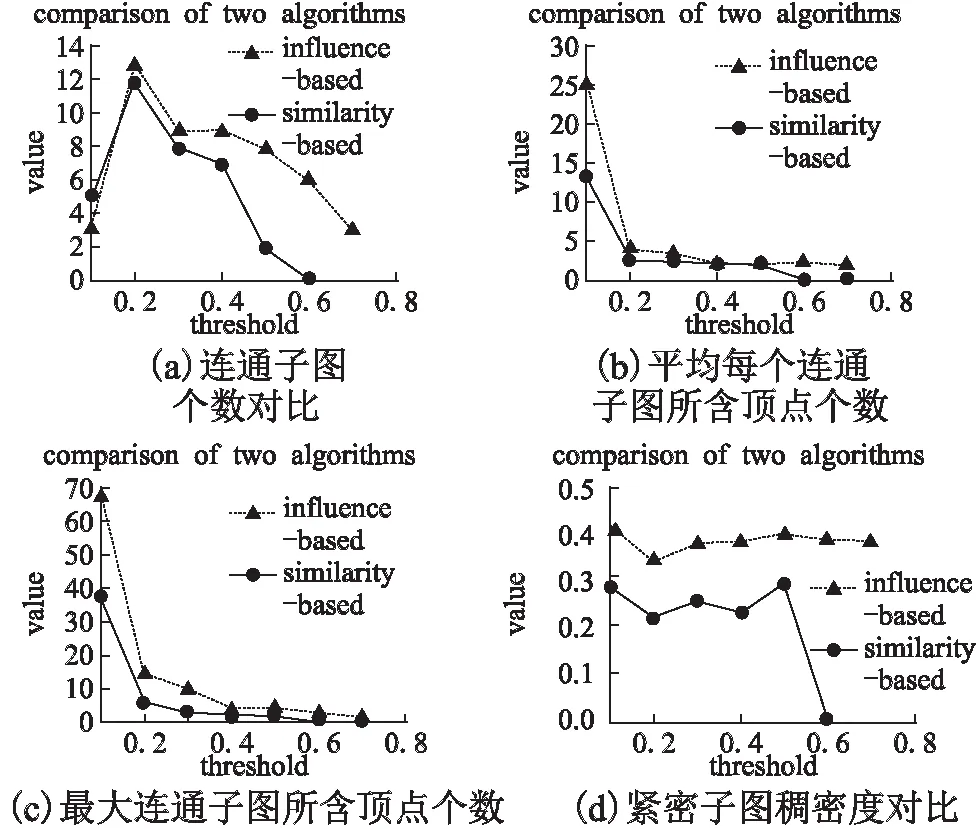
图8 novel数据集实验结果对比Fig.8 Experiment result of the novel dataset
当阈值为0.1时,arXiv数据集的节点个数较多,数据差异较大.为了方便表示,图9(c)从0.2开始取值.在图7(c)中,当阈值β为0.1时,基于影响力的紧密子图发现算法中,最大的连通子图包含316个成员顶点;top-k紧密子图挖掘算法中,最大的连通子图包含147个成员顶点.随着阈值的进一步增加,两算法的结果逐渐接近.
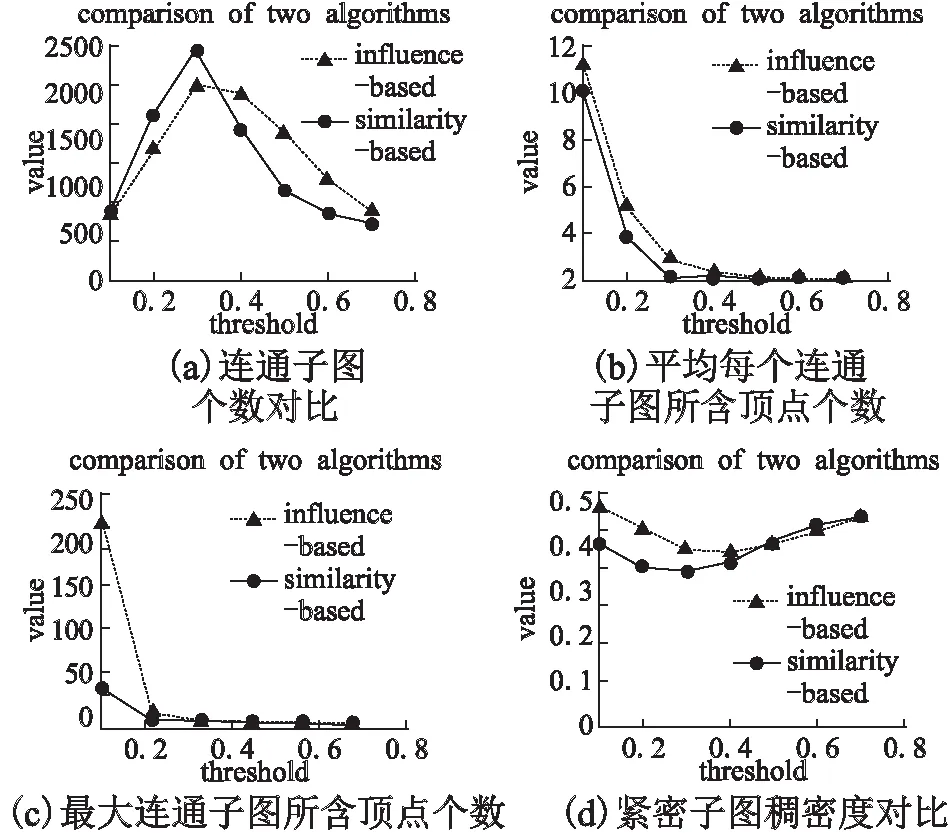
图9 arXiv数据集实验结果对比Fig.9 Experiment result of the arXiv dataset
在图7(d)、图8(d)和图9(d)中,当阈值β较小时,较多的边被包含在紧密子图中,所以稠密度较大.但是基于影响力的紧密子图发现算法顶点间的差距并不明显,所以稠密度更高.随着阈值β的进一步增加,两算法的结果逐渐接近.
对比图7、图8和图9中的networks数据集、novel数据集和arXiv数据集发现:三种数据集实验结果的曲线趋势大致上是一致的;但相对来说,novel和networks数据集的顶点较少,顶点间的联系相对密集,结果也相对平缓;arXiv数据集中的顶点多,数据也相对稀疏,所以结果差异相对较大.
7 总结与展望
成员顶点间边权重的计量方式的有效性是衡量聚类或者紧密子图发现算法有效性的重要标准.本文提出了一种新的有效的紧密子图发现算法,该算法先将数据集处理为成员顶点间的相似度,然后结合改进的PageRank算法计算成员顶点的共同影响力.使用novel数据集、networks数据集和arXiv数据集,将数据处理为顶点间的相似度,以顶点间的相似度为边的权重算法与基于影响力的紧密子图发现算法进行了对比.对比连通子图个数、平均每个连通子图所含顶点个数、最大连通子图所含顶点个数、紧密子图稠密度,说明本文的算法能提高紧密子图发现的效果和效率.
本文使用的加权图都是同构图,即:图中顶点的属性是一致的,如科学家合作网络中的数据,顶点代表的是科学家.现实生活中还存在异构图,即顶点的属性是不一致的,如:消费者购买商品,消费者和商品在图中用不同的顶点表示,两者之间存在的边表示购买关系.所以,下一步将研究带权重的异构社交网络中紧密子图的发现算法.
:
[1] Wang Y,Huang W J,Zong L,et al.Influence maximization with limit cost in social network[J].Science China Information Sciences,2013,56(7):1-14.
[2] Domingos P,Richardson M.Mining the network value of customers[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2001:57-66.
[3] Ma H,Yang H,Lyu M R,et al.Mining social networks using heat diffusion processes for marketing candidates selection[C].ACM Conference on Information and Knowledge Management,ACM,2008:233-242.
[4] Roth M,Ben-David A,Deutscher D,et al.Suggesting friends using the implicit social graph[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Dc,Usa,July.DBLP,2010:233-242.
[5] Myers S A,Zhu C,Leskovec J.Information diffusion and external influence in networks[C].Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2012:33-41.
[6] Zhou Y,Liu L.Social influence based clustering of heterogeneous information networks[C].ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2013:338-346.
[7] Bozorgtabar B,Goecke R.Efficient multi-target tracking via discovering dense subgraphs[M].Elsevier Science Inc,2016,144:205-216.
[8] Sun Huan-liang,Lu Zhi,Liu Jun-ling,et al.Top- k attribute difference q-clique queries in graph data[J].Chinese Journal of Computers,2012,35(11):2265-2274.
[9] Hintsanen P.The most reliable subgraph problem[M].Knowledge Discovery in Databases:PKDD 2007.Springer Berlin Heidelberg,2007:471-478.
[10] Zhu Rong,Zou Zhao-nian,Li Jian-zhong.Mining top-k dense subgraphs from uncertain graphs[J].Chinese Journal of Computers ,2016,39(8):1570-1582.
[11] Zou Z,Li J,Gao H,et al.Mining frequent subgraph patterns from uncertain graph data[J].Journal of Software,2010,22(9):1203-1218.
[12] Han M,Zhang W,Li J Z.RAKING:An efficient K-maximal frequent pattern mining algorithm on uncertain graph database[J].Chinese Journal of Computers,2010(8):1387-1395.
[13] Han Meng,Li Jian-zhong,Zou Zhao-nian.Finding K close subgraphs in an uncertain graph[J].Journal of Frontiers of Computer Science & Technology,2011,5(9):791-803.
[14] Yu Le.Research community detecting and evolution analysis in social network[D].Beijing:Beijing University of Posts and Telecommunications,2014.
[15] Shao Jing-jing,Feng Bo,Li Bo.A new algorithm of PageRank ranking technology[J].Journal of Huazhong Normal University(Natural Sciences),2008,42(4):504-508.
[16] Pan Hao,Tan Long-yuan.Adaptive PageRank algorithm search strategy for specific topics[J].Journal of Computer Applications,2008,28(9):2192-2194.
附中文参考文献:
[8] 孙焕良,卢 智,刘俊岭,等.图数据中Top-k属性差异q-clique查询[J].计算机学报,2012,35(11):2265-2274.
[10] 朱 鎔,邹兆年,李建中.不确定图上的 Top-k 稠密子图挖掘算法[J].计算机学报,2016,39(8):1570-1582.
[13] 韩 蒙,李建中,邹兆年.从不确定图中发现K紧密子图[J].计算机科学与探索,2011,5(9):791-803.
[14] 于 乐.社会网络中社团发现及网络演化分析[D].北京:北京邮电大学,2014.
[15] 邵晶晶,冯 波,李 波.PageRank排名技术的新算法[J].华中师范大学学报(自科版),2008,42(4):504-508.
[16] 潘 昊,谭龙远.领域相关自适应的PageRank算法搜索策略[J].计算机应用,2008,28(9):2192-2194.
