一种应用于旅游签到数据的聚类算法
2018-07-04史绍亮文益民高文翔庞承杰
文 坚,史绍亮,文益民,3 ,高文翔,庞承杰
1(桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
2(中国科技开发院广西分院,南宁 530022)
3(广西可信软件重点实验室,广西 桂林 541004)
1 引 言
随着经济的发展,旅游人数逐年上升,人们对旅游的期望越来越高.通过分析大量的微博签到数据,可以挖掘出旅游景点及其位置、流行度,为游客的旅游安排提供有价值的参考.
旅游信息挖掘与个性化推荐的研究很多,文益民等人对此进行了综述[1].随着基于位置的社交网络(LBSN)的流行,利用位置数据挖掘旅游行为并进行旅游推荐成为新的热门方向[2-5].这方面的研究大多是利用实验仪器采集的GPS数据[6,7]、签到数据[8-10]和Flickr网站上含有时间、地理标记的照片数据[11-14].国内缺乏类似特征的数据资源,相关研究无法应用于国内的旅游分析.越来越多的游客选择在旅游目的地签到、发微博,产生的大量签到数据为挖掘国内旅游景点提供了可靠的大数据.而目前新浪微博的签到数据并没有得到很好的利用,有关研究还只是停留在统计分析层面[15,16].
本文将从新的视角,借助新浪微博的签到数据,用一种新的聚类算法挖掘旅游景点及其位置、流行度.聚类分析是在无监督条件下进行数据挖掘的一个重要研究手段,已有聚类算法着重考虑数据本身的分布,对每个坐标点等同对待,同时忽视坐标点具有的用户和时间属性,因此用于旅游签到数据分析的效果不理想.本文针对这个问题,定义权重和可扩展邻域的概念,并在局部中心点的选取条件中引入用户和时间属性,提出了一种基于局部中心点,以权重递减方式扩展簇边界的聚类算法.在桂林市2015年的新浪微博签到数据集上进行实验,取得了较好的效果.
2 相关工作
聚类分析用于在无标记的数据中挖掘有用的知识,是很多领域的数据分析方法,在位置数据中应用相对广泛的主要是基于距离的聚类,基于密度的聚类和基于网格的聚类.
基于距离的聚类,以距离来度量划分簇的标准,使得簇内的对象距离较近,各簇之间的距离相对较远,实现简单.K-means算法是最早被提出来的聚类算法,也是基于距离的聚类算法的典型.为提高适应性,Dhillon等人将核函数与K-means算法结合[17].王波等人在对签到数据进行城市的活动时空变化分析时,利用K-means算法将南京市区粗略地划分为多个子区域[18].实际应用中,K值的不确定、无法区分噪声和基于距离的方式确定簇,K-means算法常会导致不合理的聚类结果.
基于密度的聚类,以数据在空间分布上的稠密程度为依据进行聚类,无需设定簇的数量,适合未知内容的数据分析.Ester等人提出了DBSCAN算法,通过半径和密度阈值来筛选核心点,将密度相连的对象标记为同一个簇[19].因为能发现任意形状的簇和识别噪声点,DBSCAN算法被用于一些位置数据的旅游景点提取中[20].但DBSCAN算法对参数敏感,不同的密度参数聚类结果差异明显.因其在空间数据中表现较好,DBSCAN的研究一直很热门,在其基础上提出了大量的改进方法[21,22].其中,Kisilevich等人改进的P-DBSCAN算法,在Flickr照片数据集上能够更加准确地挖掘出旅游景点的位置[23].P-DBSCAN算法常被应用于含有地理标记的Flickr照片数据集上进行聚类分析和旅游景点提取[24,25],但它并没有解决DBSCAN对参数敏感的问题.
基于网格的聚类,将数据划分为有限个网格,所有聚类操作皆以单个网格为对象,在高维数据和大数据量的聚类上表现乐观.Zhao等人利用网格聚类方法对采集的芬兰地区的GPS位置数据进行了聚类分析[26].针对网格大小如何划分的问题,程国庆等人提出了网格相对密度的方法[27].黄红伟等人提出了利用网格相对密度差的扩展方法[28].改进的网格聚类算法虽然在一定程度上为网格的划分提供了思路,但也引入了其他不易确定的参数.此外,徐正国等人提出了一种利用簇内密度下降搜索的聚类算法,可以比较好地判断簇的范围[29].但该算法在计算局部密度时依赖截断距离,截断距离选择太小,不能很好体现坐标点的密度;截断距离选择太大,则会导致相邻的簇被合并.在位置数据挖掘的应用上,Gennip等人利用谱聚类的方法对洛杉矶的位置数据进行分析,挖掘帮派团体[30].Wang等人提出了一种基于多边形的聚类和分析框架,挖掘地理空间数据的隐藏关系,对德克萨斯州臭氧污染进行了分析[31].
3 数据分析与挑战
签到是用户利用移动终端,在发布微博的同时定位并显示其所在位置的行为,详细记录了包括用户位置信息(经纬度坐标)、时间信息、文本信息等内容.通过调用新浪微博开放平台的API,获取了覆盖桂林市2015年1月1日至2015年12月31日的签到数据,经过预处理,共有来自67262名用户的190584条签到数据.每条签到数据包含签到时间、用户名、位置坐标、微博内容、签到位置的地点名等信息,如图1所示.本文算法在聚类时利用的信息为:位置坐标(经度,纬度)、用户名和签到时间.地点名用于在聚类结束后,提取每个聚类簇在地理上的名字.为更好地理解签到数据与一般聚类对象的不同,将签到数据的几个主要特点分析如下.

图1 签到数据信息Fig.1 Check-in data information
1)签到数据的分布极不均匀.签到数据往往集中在旅游景点、高校、商场等人流量大的区域,与其他签到稀少的区域形成鲜明对比;而同属于旅游景点,由于知名度和位置不同,签到密集程度也会相差甚远.将签到坐标映射到地图上,每个点代表一个签到位置,高度代表签到次数.图2为桂林市中心的签到分布图,包含18个景点,其签到数据比较密集,而且部分位置的签到次数较多;图3为桂林兴安县的签到分布图,包含3个景点,相比较而言,其签到数据明显稀疏,且在单个坐标点的签到次数也明显减少.虽然同属于旅游景点,但其签到数据明显极不均匀.对于这种极不均匀分布的聚类对象,基于距离和基于网格的聚类算法会将市中心位置相邻的多个景点聚类为一个簇,将偏远区域少数零散的签到也聚类为一个簇.

图2 桂林市中心签到分布图Fig.2 Map of check-in data distribution in guilin city center
而基于密度的聚类,若参数设置严格,能区分市中心的各个景点,却会将签到相对稀疏的景点当作噪声处理;若参数设置宽松,又会导致签到密集且位置相邻的多个景点被合并为一个簇,而当作一个景点.
2)签到次数呈现由中心向周围递减的分布.不同于一般的聚类对象,签到数据存在大量用户在同一位置签到的情形.对于一个局部区域,如一个景点、一条商业街,会有一个位置的签到次数特别多,以它为中心距离越远的位置,其签到次数越少,呈递减趋势,可以抽象为图4所示.这与微博签到机制和用户签到方式有关系,一种情况是用户使用微博的签到功能时手动选择签到地点,而不是系统通过定位自动识别用户所在位置,因此该条签到数据的位置坐标是由系统根据用户手动选择的签到地点给出的;另一种情况是用户发布微博时上传了照片,则系统会根据识别出的照片拍摄地点给出签到位置坐标.因为这两种情况,使得局部区域某个位置的签到次数明显多于附近的位置.本文提出的算法充分利用了签到数据的这一特点,从而能有效确定簇的边界.

图3 兴安县签到分布图Fig.3 Map of check-in data distribution in Xing′an County

图4 签到数据在局部区域的分布抽象图Fig.4 Abstract map of check-in data in a local area
3)不同类型用户签到次数差异明显.一般情况下,游客去外地旅游,一个地方每年只去一次,而且旅游时间一般在7天内(国家最长假期为7天),本文将数据集中最后一次与第一次签到时间之差不大于7天的用户或者只签到了1次的用户称为外地游客,否则称为当地居民.本文统计了最后一次与第一次签到时间的间隔天数与符合条件的用户数量.表1列出其中1到12天的结果,可以观察到签到时间间隔为1天的用户非常多.这与生活中很多游客去一个地方旅游,只发一条微博并签到相符.随着时间间隔的增长,用户数量不断减少,从7天开始,用户数量的变化趋于比较平稳的状态,这应该与随着假期时间结束外地游客离开有直接关系.对数据集进行统计后还发现,所有签到用户中仅有22.7%为当地居民,但其签到次数却占总签到次数的59.3%.可以看到,当地居民虽然不多,但其签到比例却很高.现有聚类算法基本都是对用户同等看待,不区分用户类型,这会导致当地居民签到较多的高校、商场等地方被聚类为簇,而误认为是旅游景点.此外,当地居民往往在小范围区域内多次签到,在本文采集到的数据中,单一用户签到最多达931次.这有可能导致聚类算法得到的某些簇中签到次数很多,但却只包含少数几个用户的签到数据.本文将外地游客的签到比例作为局部中心点的选择条件,只有外地游客签到占比多的地方才会判定为局部中心点,很好地避免了上述两种不合理情况.

表1 时间间隔天数及对应的用户数量Table 1 Time interval and the corresponding number of users
以上为旅游签到数据相比一般聚类对象存在的不同特点,利用签到数据挖掘桂林的旅游景点,还存在以下困难:
1)景点位置相邻.对于孤立的景点,如银子岩、世外桃源,容易在聚类时发现;但是对于两个或者多个位置相邻的景点,如象山公园和两江四湖、大榕树和聚龙潭,现有聚类方法必须严格挑选参数,才能有效区分,否则容易导致不同景点被聚类为一个簇,或者某些景点不能被发现.而桂林多数景点的位置是相邻的.
2)景点集中在市中心.市中心作为商业、餐饮和娱乐场所集中的繁华区域,同时还分布了18个旅游景点,流动人口多,各种类型的签到密集分布.如何在签到密集的市中心区分旅游景点和非旅游区域的签到数据,从而挖掘旅游景点的位置,现有算法很难实现.
3)酒店数量多.作为一个旅游胜地,桂林拥有不同类型酒店达2000余家,而且多数分布在旅游景点附近.不少游客旅行一天后,回到酒店才签到分享当天的旅行体验,这导致酒店签到数据的变化规律与景点一样,聚类算法可能会将签到次数多的酒店错误地判断为旅游景点.
微博签到数据的这些特点使得现有聚类算法很难准确地挖掘旅游景点.本文针对这些问题,提出了基于局部中心点权重递减的聚类算法(local center object weight decreasing based clustering algorithm,CWDC).
4 基于局部中心点权重递减的聚类算法
4.1 基本定义
为更好地体现算法的设计思路与实现原理,在描述算法之前,先给出一些基本定义.
定义1. 权重(Weight):对于任意坐标点p(lon,lat),其权重W(p)是在坐标点p的签到次数.如p点有10条签到信息,则W(p) = 10.
定义2. 可扩展邻域(Extended Neighborhood):坐标点p(lon,lat)的可扩展邻域E(p),为p可以向周围扩展的范围.给定扩展半径R,在数据集D上,p的邻域N(p)由公式(1)表示,其中dis(q,p)为q到p的欧式距离.邻域内权重大于W(p)的坐标点集合H(p)由公式(2)表示,则p的可扩展邻域E(p)可用公式(3)表示,其中WH为H(p)中坐标点的权重之和,WN为N(p)中坐标点的权重之和,λ为容忍度,即能容忍邻域内权重大于W(p)的坐标点的限度.
N(p)={q∈D|dis(q,p)≤R,q≠p}
(1)
H(p)={o∈N(p)|W(o)>W(p)}
(2)
(3)
当满足WH/WN≤ λ的条件时,p的可扩展邻域就是p的邻域.当邻域内出现个别权重小幅增大的坐标点时,容忍度λ可以避免误认为即将进入另一个簇的范围,而将当前坐标点作为簇的边界,从而使簇的范围界定更加合理.λ的取值对不同数据集不敏感,实验表明取值在0.1到0.5之间对聚类结果影响并不大,以选择0.3为宜.结合图5来理解可扩展邻域,图中虚线圈出的是一个簇.当一个点的邻域内坐标点的权重递减或者保持不变,这个点才会有可扩展邻域,如图5中p1点;簇的边界坐标点已经没有可以继续扩展的坐标点,如图中p2点;或者即将进入另一个簇的范围,权重呈现递增趋势,不满足WH/WN≤λ的条件,如图中p3点.因此簇的边界坐标点没有可扩展邻域.图中p4点,虽然其权重为2,邻域内有一个坐标点的权重为5,但WH/WN=5/18<0.3,所以p4有可扩展邻域,此时不会因为权重为5坐标的出现而误将p4点作为簇的边界.
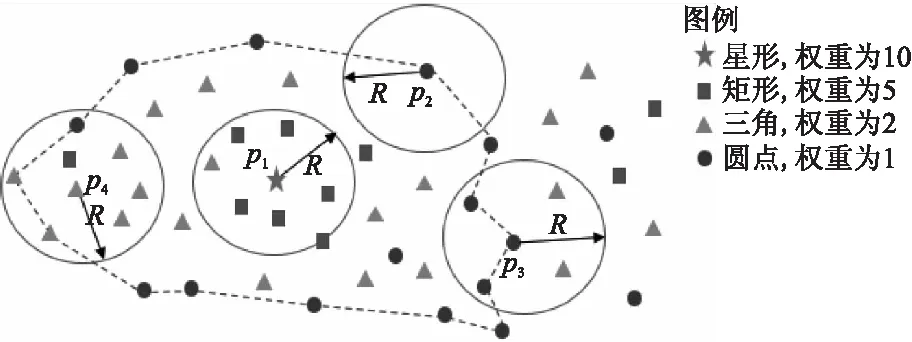
图5 可扩展邻域Fig.5 Extended neighborhood
定义3. 坐标点p的外地游客签到比例K(p):对于坐标点p(lon,lat),外地游客签到比例K(p)可用公式(4)表示.其中WT(p)为外地游客在p签到次数之和,W(p)为p的权重.
K(p)=WT(p)/W(p)
(4)
例如:坐标点p有10条签到信息,其中5条是来自外地游客的签到,则坐标点p的外地游客签到比例K(p)=WT(p)/W(p)=5/10=0.5.
定义4. 外地游客的平均签到比例α:数据集D中外地游客的平均签到比例α可用公式(5)表示.其中WT为所有外地游客签到的总次数,WD为所有用户签到的总次数,也就是数据集的大小.
α=WT/WD
(5)
外地游客的平均签到比例α对一个数据集来说是固定的,本文数据集大小为190584,外地游客签到总次数为77567,则α=77567/190584≈0.407.
定义5. 局部中心点(Local Center Object):局部中心点是满足K(p)>α且在局部区域内权重最大的坐标点.
4.2 算法描述
本文通过定义坐标点的权重和可扩展邻域,并将坐标点的用户和时间属性用于局部中心点的选取,设计了基于局部中心点权重递减的聚类算法,用于利用微博签到数据挖掘旅游景点的位置和流行度.
算法的执行过程如算法1所示.第1行首先计算外地游客的平均签到比例α;2-7行对数据集D中的所有坐标点进行遍历,得到每个坐标点的权重W(p)、外地游客签到比例K(p),去除相同的坐标点,组成新的数据集D′;8-15行对数据集D′中每个坐标点标记为未访问,并计算其可扩展邻域E(p);16-28行以满足K(p) >α且为当前未访问过的权重最大的坐标点为局部中心点建立新簇,按照权重递减的思想,迭代地将坐标点的可扩展邻域E(p)纳入簇内,并标记为已访问,以此方式不断向周围扩展簇的边界,直到没有可扩展邻域时,结束扩展,确定当前簇的边界.循环执行上述过程,没有被纳入任何簇的坐标点则为噪声数据.
簇的扩展过程可用图6表示,局部中心点p1首先扩展到p2、p3,然后p2迭代地扩展到p4、p5,p3迭代地扩展到p6、p7.p5由于不满足WH/WN≤λ的条件,因此没有可扩展邻域,而结束扩展;p7由于没有可以继续扩展的坐标点,也没有可扩展邻域,而结束扩展.p1、p2、p3、p4、p5、p6、p7组成了以p1为局部中心点的簇.
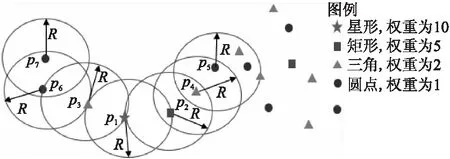
图6 簇的扩展过程Fig.6 Process of cluster expansion
为了排除高校、商场等非旅游区域,算法在确定局部中心点时,要求中心点的外地游客签到比例高于数据集中外地游客的平均签到比例.因为非旅游区域大部分是当地居民的签到数据,而旅游景点往往外地游客签到比例更高.

图7 CWDC聚类结果示意图Fig.7 Illustration of CWDC clustering results
若两个簇相邻,从局部中心点以权重递减的方式向四周扩展簇的范围,权重会呈现递减趋势.当扩展到簇的边缘区域,这时因为边界点没有可扩展邻域而结束该簇的继续扩展,不至于将相邻的簇合并为一个.因此能有效区分位置相邻的旅游景点,如图7所示.
本算法的创新之处在于:(1)提出权重的概念,使每个坐标点具有权重,权重的计算不需要任何参数;(2)引入坐标点的用户和时间属性,与权重一起确定聚类时的局部中心点;(3)定义可扩展邻域,从局部中心点以权重递减的方式扩展簇的边界.
算法1.CWDC算法伪代码
Input:
D:datasets of points with coordinate,user and time
R:neighborhood radius for extend
Output:Set of cluster
1. Computeα//计算外地游客的平均签到比例α
2. For each coordinate pointpinD
3. ComputeW(p) //坐标点p的权重W(p)
4. ComputeK(p) //坐标点p的外地游客签到比例K(p)
5. The same coordinates only keep one //相同坐标点只保留一个
6. End For
7.D′ is a new data set of non-repeating coordinates //D′为去除重复坐标组成的新数据集
8. For each coordinate pointPinD′
9. MarkPis unvisited //标记P为未访问
10. ComputeN(P) //N(P)为P的邻域
11. ComputeH(P) //H(P)为邻域内权重大于W(P)的坐标点集合
12. IfWH/WN≤λ //若满足条件,建立P的可扩展邻域E(P)
13. Set extended neighborhoodE(P)
14. End If
15. End For
16. For eachPinD′ meetsK(P)>α&&W(P)is maximum of unvisited coordinates //对每个局部中心点执行
17. MarkPis visited //标记P已访问
18. Create a new clusterC,addPtoC//创建一个新簇,并将P添加到簇C中
19. For each pointP′ inE(P) //迭代地将可扩展邻域中不属于任何簇的坐标点添加到C
20. IfP′ is unvisited
21. AddP′ toC
22. MarkP′ is visited
23. IfP′ have extended neighborhoodE(P′) //迭代扩展
24. Add them toE(P)
25. End If
26. End If
27. End For
28. End For
29. For eachOinD′ is unvisited mark as noise //不属于任何簇的坐标点即为噪声
30. Output the Set of cluster //输出聚类结果
5 实验与分析
5.1 聚类簇命名
为了计算各聚类算法从签到数据中挖掘出旅游景点的数量,聚类结束后,统计每个簇中坐标点对应的地点名,以多数表决的方式,出现次数最多的地点名作为该簇的名字.
5.2 实验设计与评价指标
将在位置数据聚类分析中经常使用的聚类算法K-means、DBSCAN、P-DBSCAN,以及近期由文献[29]提出的LDCDS作为对比算法,并在桂林市2015年的新浪微博签到数据集上进行实验,通过以下4个评价指标对实验结果进行比较,其中前两个是结合应用背景由本文提出的,后两个是推荐系统中常见的评价指标.
1)景点簇数量:名字是景点的聚类簇的数量,该指标越大表示越多的聚类簇是景点.
2)景点数量:由于存在地理位置不同的聚类簇,而其名字却是相同的.比如“漓江”会至少在两个簇的名字中出现,这是因为“漓江”是一个跨度很长的景点,在不同精华段,游客签到的地点名都是“漓江”.对于这种情况,本文视为只挖掘出了一个景点,用景点数量表示聚类簇的名字中含有相互不同的景点名数量,该指标越大表示挖掘出的景点越多.
3)准确率:准确率=景点簇数量 / 聚类簇总数,该指标越大表示景点簇数量占聚类簇总数的比例越高.
4)覆盖率:覆盖率=景点数量 / 桂林景点总数,该指标越大表示挖掘出的景点数量占景点总数的比例越高,将桂林流行度较高的62个景点作为考虑对象,设置景点总数为62.
5.3 实验结果与分析
本文的数据集为从新浪微博API接口获取的2015年1月1日到2015年12月31日桂林市的.各比较算法均选择最优参数,实验结果如表2所示.
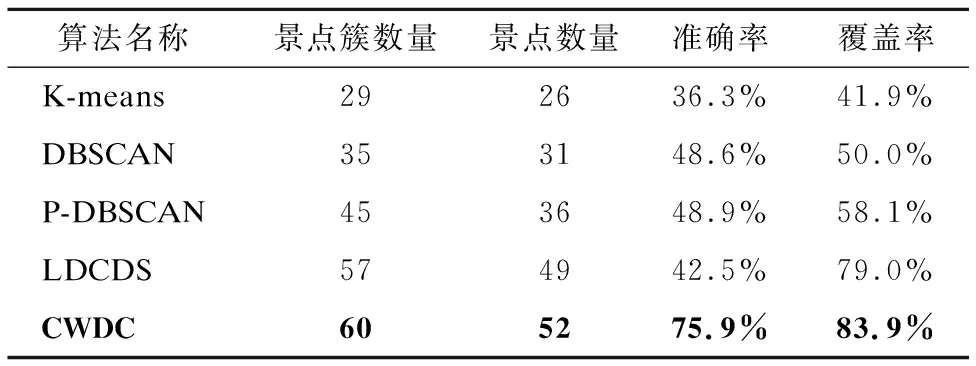
表2 不同算法聚类结果比较Table 2 Clustering results of different algorithms comparison
通过实验结果对比,本文算法CWDC在景点簇数量、景点数量、准确率和覆盖率四个指标上都优于其他算法.因为在局部中心点的选取条件上,综合考虑了坐标点的权重和外地游客签到比例,所以本文算法CWDC能排除非旅游区域,在分布极不均匀的签到数据中准确定位旅游景点位置;从局部中心点以权重递减的方式扩展簇的范围,有效判断了每个旅游景点的边界,可以区分相邻的旅游景点;此外,在簇从局部中心点向周围扩展的过程中,可扩展邻域避免了权重小幅度增大的坐标点对簇边界的干扰,使旅游景点的范围界定更加合乎现实.正是因为这些原因,而其他聚类算法不能很好地实现,所以CWDC算法能更加准确地挖掘出旅游景点.

表3 不同算法执行时间比较Table 3 Comparison of different algorithm calculating time
各算法均用C++语言实现,用Visual Studio2013作为编译工具.实验平台为Intel Core i5-4460S处理器,8GB内存,Windows 7操作系统.在算法的执行时间上,K-means能得到快速响应.因为DBSCAN与P-DBSCAN核心点的判断、LDCDS局部密度的计算,都需要耗费较长时间,并将很多时间浪费在了相同坐标点的距离计算上;而CWDC计算坐标点权重、外地游客签到比例只需做简单的比较,相同的坐标只保留一个,大幅度减少了可扩展邻域部分欧氏距离的计算量,所以CWDC在计算时间方面会有一定优势,如表3所示.此外,本文提出的CWDC算法还具有以下几个优点.
1)能准确定位旅游景点位置.桂林市流行度较高的62个景点,本文提出的CWDC算法挖掘出了其中52个,且聚类簇的位置与真实景点相符,有效排除了市中心签到密集的非旅游区域.将CWDC的聚类结果映射到地图上,为方便观察,截取市中心区域,图上大面积分布的点是聚类得到的噪声点,其他标识的是算法判断的不同景点,如图8所示.可以看到,算法能在签到构成复杂、分布密集的市中心区域,准确定位旅游景点所在位置,且其中多数景点相距较近.

图8 CWDC在桂林市中心挖掘出的旅游景点位置Fig.8 CWDC mining the tourist attractions location in Guilin city center
2)能判断旅游景点的流行度.签到越多意味着景点越流行,以簇内所有坐标点的权重之和表示流行度,将CWDC发现的52个不同的景点按照流行度从高到低排序(如表4所示),与百度旅游、携程等旅游网站上桂林市景点排名大致吻合,其中排名前44的景点全部被发现.
值得说明的是,CWDC算法聚类得到的79个簇中,除了60个簇是景点,另外19个簇虽然不是景点,但也是游客常去的地方.这些地方的外地游客签到比例也高于数据集中外地游客的平均签到比例,具有和景点相同的签到特征.这19个簇表示的地点,分别是2个火车站、1个汽车站、3个去景点途中需要经过的乡镇、2个特色餐厅(椿记烧鹅、星巴克)和11家桂林人气最高的五星级酒店.而其他聚类算法得到的结果中包含了多个高校、商场、医院等非旅游区域.
6 结 论
本文在分析已有聚类算法实现原理和不足的基础上,通过定义权重和可扩展邻域,并将坐标点的用户和时间属性引入到局部中心点的选取条件中,提出了一种能在签到数据上有效挖掘旅游景点及其位置、流行度的新聚类算法.算法在确定局部中心点后,以权重递减的方式扩展簇的边界.通过在桂林地区2015年的微博签到数据集上与其他典型聚类算法进行对比实验,本文提出的基于局部中心点权重递减的聚类算法在四个评价指标上都优于其他算法,表明本文的算法更适合从旅游签到数据中挖掘景点信息.如何将本文算法应用于实时数据中,是下一步研究的重点.

表4 CWDC聚类得到的旅游景点流行度排名Table 4 Popularity ranking of tourist attractions clustered by CWDC
:
[1] Wen Yi-min, Shi Yi-fan, Cai Guo-yong, et al. A survey of personalized travel recommendation[EB/OL]. Sciencepaper Online,http://www.paper.edu.cn/releasepaper/content/201407-56,2014.
[2] Yu Z,Xu H,Yang Z,et al.Personalized travel package with multi-point-of-interest recommendation based on crowdsourced user footprints[J].IEEE Transactions on Human-Machine Systems,2016,46(1):151-158.
[3] Guo L,Shao J,Tan K L,et al.WhereToGo:personalized travel recommendation for individuals and groups[C].Proceedings of the 15th International Conference on Mobile Data Management,IEEE,2014:49-58.
[4] Chen Y Y,Cheng A J,Hsu W H.Travel recommendation by mining people attributes and travel group types from community-contributed photos[J].IEEE Transactions on Multimedia,2013,15(6):1283-1295.
[5] Wang H,Terrovitis M,Mamoulis N.Location recommendation in location-based social networks using user check-in data[C].Proceedings of the 21st ACM SIGSPA-TIAL International Conference on Advances in Geographic Information Systems,ACM,2013:374-383.
[6] Zheng Y,Zhang L,Xie X,et al.Mining interesting locations and travel sequences from GPS trajectories[C].Proceedings of the 18th International Conference on World Wide Web,ACM,2009:791-800.
[7] Huang Xiao-ting,Ma Xiu-jun.Study on tourists′ rhythm of activities based on GPS data [J].Tourism Tribune,2011,26(12):26-29.
[8] Hsieh H P,Li C T,Lin S D.Exploiting large-scale check-in data to recommend time-sensitive routes[C].Proceedings of the 14th ACM SIGKDD International Workshop on Urban Computing,ACM,2012:55-62.
[9] Yin H,Zhou X,Shao Y,et al.Joint modeling of user check-in behaviors for point-of-interest recommendation[C].Proceedings of the 24th ACM International Conference on Information and Knowledge Management,ACM,2016:1631-1640.
[10] Song Xiao-yu,Xu Hong-fei,Sun Huang-liang,et al.Short-term experience route based on check-in data[J].Chinese Journal of Computers,2013,36(8):1693-1703.
[11] Zheng Y T,Zha Z J,Chua T S.Mining travel patterns from geotagged photos[J].ACM Transactions on Intelligent Systems & Technology,2012,3(3):1-18.
[12] Lim K H.Recommending tours and places-of-interest based on user interests from geotagged photos[C].Proceedings of the 2015,ACM SIGMOD on PhD Symposium,ACM,2015:33-38.
[13] Kurashima T,Iwata T,Irie G,et al.Travel route recommendation using geotags in photo sharing sites[C].Proceedings of the 19th ACM International Conference on Information and Knowledge Management,ACM,2010:579-588.
[14] Majid A,Chen L,Chen G,et al.GoThere:travel suggestions using geotagged photos [C].Proceedings of the 21st International Conference on World Wide Web,ACM,2012:577-578.
[15] Zhang Zi-ang,Huang Zhen-fang,Jin Cheng,et al.Research on spatial-temporal characteristics scenic tourist activity based on sina microblog:a case study of nanjing zhongshan mountain national park[J].Geography and Geoinformation Science,2015,31(4):121-126.
[16] Han Hua-rui,Dai Zhen-yong.The analysis of space difference of check-in activities in hubei province:an expirical analysis of sina micro-blog[J].Geomatics & Spatial Information Technology,2016,39(10):159-162.
[17] Dhillon I S,Guan Y,Kulis B.Kernel k-means:spectral clustering and normalized cuts[C].Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM,2004:551-556.
[18] Wang Bo,Zhen Feng,Zhang Hao.Dynamics changes of urban space-time activity and activity zoning based on check-in data in sina Web[J].Scientia Geographica Sinica,2015,35(2):151-160.
[19] Ester M,Kriegel H P,Sander J,et al.A density-based algorithm for discovering clusters in large spatial databases with noise[C].Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining,ACM,1996:226-231.
[20] Memon I,Chen L,Majid A,et al.Travel recommendation using Geo-tagged photos in social media for tourist[J].Wireless Personal Communications,2015,80 (4):1347-1362.
[21] Feng Zhen-hua,Qian Xue-zhong,Zhao Na-na.Greedy DBSCAN:an inproved DBSCAN algorithm on multi-density clustering[J].Application Research of Computers,2016,33(9):2693-2696.
[22] Birant D,Kut A.ST-DBSCAN:an algorithm for clustering spatial-temporal data[J].Data & Knowledge Engineering,2007,60(1):208-221.
[23] Kisilevich S,Mansmann F,Keim D.P-DBSCAN:a density based clustering algorithm for exploration and analy sis of attractive areas using collections of geotagged photos[C].Proceedings of the 1st International Conference and Exhibition on Computing for Geospatial Research & Application,ACM,2010:38:1-38:4.
[24] Vu H Q,Gang L,Law R,et al.Exploring the travel behaviors of inbound tourists to Hong Kong using geotagged photos[J].Tourism Management,2015,46(1):222-232.
[25] Majid A,Chen L,Mirza H T,et al.A system for mining interesting tourist locations and travel sequences from public geotagged photos[J].Data & Knowledge Engineering,2015,95(1):66-86.
[26] Zhao Q,Shi Y,Liu Q,et al.A gridgrowing clustering algorithm for geospatial data[J].Pattern Recognition Letters,2015,53(53):77-84.
[27] Cheng Guo-qing,Chen Xiao-yun.Clustering algorithm for multi-density based on grid relative density[J].Computer Engineering and Applications,2009,45(1):156-158.
[28] Huang Hong-wei,Huang Tian-min.Extension clustering algorithm based on relative grid density difference[J].Application Research of Computers,2014,31(6):1702-1705.
[29] Xu Zheng-guo,Zheng Hui,He Liang,et al.Self-adaptive clustering based on local density by descending search [J].Journal of Computer Research and Development,2016,53(8):1719-1728.
[30] Gennip Y V,Hunter B,Ahn R,et al.Community detection using spectral custering on sparse geosocial data[J].Siam Journal on Applied Mathematics,2012,73(1):67-83.
[31] Wang S,Eick C F.A polygon-based clustering and analysis framework for mining spatial datasets[J].GeoInformatica,2014,18(3):569-594.
附中文参考文献:
[1] 文益民,史一帆,蔡国永,等.个性化旅游推荐研究综述[EB/OL].中国科技论文在线,http://www.paper.edu.cn/releasepaper/content/201407-56,2014.
[7] 黄潇婷,马修军.基于GPS数据的旅游者活动节奏研究[J].旅游学刊,2011,26(12):26-29.
[10] 宋晓宇,许鸿斐,孙焕良,等.基于签到数据的短时间体验式路线搜索[J].计算机学报,2013,36(8):1693-1703.
[15] 张子昂,黄震方,靳 诚,等.基于微博签到数据的景区旅游活动时空行为特征研究——以南京钟山风景名胜区为例[J].地理与地理信息科学,2015,31(4):121-126.
[16] 韩华瑞,代侦勇.湖北省微博签到活动空间差异分析——以新浪微博为例[J].测绘与空间地理信息,2016,39(10):159-162.
[18] 王 波,甄 峰,张 浩.基于签到数据的城市活动时空间动态变化及区划研究[J].地理科学,2015,35(2):151-160.
[21] 冯振华,钱雪忠,赵娜娜.Greedy DBSCAN:一种针对多密度聚类的DBSCAN改进算法[J].计算机应用研究,2016,33(9):2693-2696.
[27] 程国庆,陈晓云.基于网格相对密度的多密度聚类算法[J].计算机工程与应用,2009,45(1):156-158.
[28] 黄红伟,黄天民.基于网格相对密度差的扩展聚类算法[J].计算机应用研究,2014,31(6):1702-1705.
[29] 徐正国,郑 辉,贺 亮,等.基于局部密度下降搜索的自适应聚类方法[J].计算机研究与发展,2016,53(8):1719-1728.
