基于自学习深度卷积神经网络的姿态变化人脸识别
2018-07-04邹国锋傅桂霞高明亮尹丽菊王科俊
邹国锋,傅桂霞,高明亮,尹丽菊,王科俊
1(山东理工大学 电气与电子工程学院,山东 淄博 255049)
2(哈尔滨工程大学 自动化学院,哈尔滨 150001)
1 引 言
自动人脸识别因其良好的隐蔽性、快速采集性,在很多实际应用中起着重要作用,特别在公共安全领域具有非常好的应用前景[1].非约束环境中,人脸容易受到很多可变因素(姿态、光照、遮挡等)干扰,导致现有人脸识别算法和技术的可靠性严重下降.姿态变化是对非约束环境下人脸图像采集和人脸识别系统性能影响最严重的因素.因此,针对非受约束环境下的姿态变化人脸识别开展分析研究具有重要的理论意义和应用价值.
因姿态变化已成为人脸识别在非约束环境下应用的重要瓶颈之一,因此有众多研究者从事这一领域的研究工作,并取得了很多卓越的研究成果[2].例如基于单样本的姿态变化人脸识别[3-5],基于二维多视图姿态矫正的人脸识别[6-8],三维姿态变化人脸识别[9-11],针对多视图姿态人脸的新特征提取方法[12-16]等.姿态变化的人脸图像采集通常无法得到被采集者的有效配合,获取的人脸图像分布在高维非线性流形空间.因此,有效提取姿态人脸图像的深层非线性特征是解决姿态人脸识别问题的关键.
深度学习作为模拟人脑进行分析和学习的深层神经网络,其基本思想是通过有监督或无监督方式学习层次化特征表达,建立底层信号到高层语义的映射关系.卷积神经网络作为典型的深度学习模型,在图像识别中展现出独特优越性.Qin等人[17]提出基于级联卷积神经网络的无约束自然状态人脸检测算法,采用一种联合训练算法实现多个卷积神经网络的级联和快速运算,并获得一个端到端的最优化卷积网络检测器,实现人脸检测.Liu等人[18]采用新的深度学习理论框架训练卷积神经网络用于自然状态人脸属性识别,在类别信息明确的大训练样本集上效果明显.Iacopo Masi[19]基于深度卷积神经网络提出一种姿态感知模型学习姿态变化人脸的多个判别性表示,并通过多特征融合获得姿态人脸单一模型用于识别,自然状态下的姿态人脸识别效果得到一定改善.石祥滨等[20]提出一种对称神经网络模型,将两个特征维度相同的深度神经网络作为对称模型的左右子网络,通过前向传播得到有差异的图像特征,并在联合层对差异特征进行融合,实验表明该方式集成的对称深度模型能取得较好的分类性能.
尽管卷积神经网络在图像识别中取得了一些令人满意的成果,但在理论和应用方面仍有一些亟待解决的关键问题.网络模型结构设计主要依赖于人为经验,网络深度、特征图个数等参数设置缺乏理论依据,模型构建与处理的样本没有直接关联;网络训练需要大量训练样本支持,当样本采集受到限制时,如何实现样本扩充等等.这都是卷积神经网络研究和应用的重点和难点问题.因此,针对卷积网络结构设计缺乏理论依据、模型结构与样本缺乏关联性和姿态变化人脸样本的扩充等问题,本文提出了姿态变化人脸的样本扩充方法和深度卷积神经网络模型结构的自学习方法.
鉴于姿态变化人脸图像分布于非线性流形空间的特点,本文提出一种基于局部子空间的姿态变化人脸样本扩充思路.首先依据人脸图像俯仰角的不同,将姿态变化人脸流形空间划分为不同流形层;然后在每个流形层内,依据人脸图像左右视角的不同,将每个流形层划分为不同的局部子空间.基于不同流形层和不同局部子空间,分别在子空间内、子空间之间,构建一种能够有效克服人脸样本中存在孤立点或噪声干扰的人脸底层特征,实现姿态变化人脸的扩充.
针对卷积神经网络模型构建缺乏理论依据和模型结构与样本缺乏关联性的问题,本文提出一种关联训练样本的深度卷积神经网络模型结构的自学习算法,实现姿态变化人脸的深层特征提取和识别.该算法根据参与训练样本的情况实现网络结构的自学习扩展,直到获得最优的分类结果.首先,将卷积神经网络模型的卷积层和池化层设置为仅含一幅特征图;然后,以卷积神经网络的收敛速度作为评价指标,对网络进行全局学习,直到网络系统平均误差达到预设期望值,则全局网络学习结束.最后,采用交叉验证样本测试全局学习所得网络的识别率,若识别率未达到期望值,则对卷积神经网络展开局部学习,直到识别率达到预设期望值后停止网络学习.通过自学习产生的网络模型与训练样本密切关联,不需要人为设置网络结构深度和特征图个数,实现了基于数据驱动的网络模型构建.多个人脸图像库的识别实验验证了本文所提算法在网络训练时间和识别效果上的有效性.
2 姿态变化人脸样本的扩充
2.1 人脸底层特征图构建
姿态变化人脸数据集包含多人的多幅人脸图像,且这些图像分布于高维非线性流形空间.图1展示了某人的典型人脸图像的2维嵌入结果,小方块表示原始输入人脸图像的低维映射,一些代表图像显示在相应的样本点位置.从这些代表图像可以看出,嵌入结果的坐标轴对应于原始数据隐含的自由度.横轴表示这些图像中的人脸从左转向右发生了视角变化,而纵轴则表示这些图像发生的俯仰角度变化.分析发现,姿态变化人脸图像都分布于非线性流形上,而该流形结构可以被划分为多个局部线性的子空间结构.因此,根据姿态变化人脸数据集合的分布特点,姿态变化人脸数据集被划分为若干子集合.

图1 人脸在2维空间的可视化Fig.1 Face visualization in the 2 dimensional space
本文结合姿态变化人脸的高维非线性流形分布特点,提出了一种针对姿态变化人脸非线性流形结构的划分方法,并基于此划分方法提出基于局部线性子空间的人脸底层特征构建方法.具体描述如下:
2.1.1 人脸非线性流形结构的划分策略
首先,按照人脸图像俯仰角度的不同,将姿态变化人脸流形划分为不同的流形层,流形层的层数可根据需要人为设定,例如最简单的可分为3个流形层,即仰视流形层(俯仰角度在[5°,30°]间)、平视流形层(俯仰角度在[5°,5°]间)、俯视流形层(俯仰角度在[-30°,5°]间).
然后,在每个流形层内,按照人脸左右视角变化的不同,将该流形层划分为不同的局部子空间.图2所示为某一流形层内,根据人脸左右视角不同划分出局部子空间的示意图.

图2 某流形层划分为局部线性子空间的示意图Fig.2 Schematic diagram of manifold layer divided into local linear subspace
2.1.2 人脸底层特征构建
在每个局部子空间内,将不同的人脸图像通过加权平均的方式形成人脸底层特征,这样一张特征图像能够反映不同姿态的人脸变化情况.人脸底层特征不具有明显的周期性,它表示的是不同俯仰角度和不同摇摆角度的人脸姿态变化.具体定义如下:
对于给定的姿态变化灰度人脸图像Ij(x,y),人脸底层特征的定义如(1)所示:
(1)
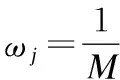
在相邻的两局部子空间之间,可采用分布于两子空间边界处的姿态变化人脸图像通过加权平均的方式形成新的人脸底层特征图,其计算公式与式(1)相似.通过构建局部子空间内部和子空间之间的加权平均人脸图像,形成较多的人脸底层特征图像,这部分新产生的特征图和原始人脸共同作为训练样本,用于深度卷积神经网络的训练学习.
2.2 人脸底层特征的优点
人脸底层特征融合了多幅人脸图像的综合信息,蕴含了姿态变化情况下人脸轮廓信息和纹理信息,不仅能够很好的节省存储空间,降低计算的复杂度,而且能够弱化单帧图像中出现的噪声干扰和人脸空间分布中的孤立点现象.
设Ii(x,y)为一幅含有噪声的人脸图像,它是由人脸信息图像fi(x,y)和噪声图像γi(x,y)叠加而成,即Ii(x,y)=fi(x,y)+γi(x,y).假设坐标(x,y)处,不同图像帧中噪声γi(x,y)是互不相关的,但具有相同的概率分布.
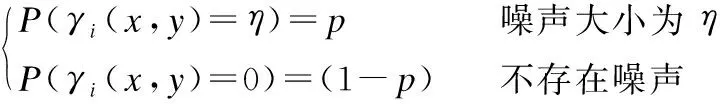
其中,p是一幅图像出现噪声的概率.结合噪声的均值和方差,本文给出了人脸底层特征像抑制图像中加性噪声影响的结论,即下面的定理:


3 卷积神经网络简介
卷积神经网络结构如图3所示,其中包含三层结构:卷积层、池化层和全连接层.而深度卷积神经网络是指由多个卷积层、池化层和全连接层共同构成的复杂多层神经网络.
卷积层运算如下:
(2)

池化层,主要通过针对不同位置的特征进行聚合统计,可以有效降低特征图的维度,能够降低神经网络过拟合现象出现的概率,改善网络训练效果.通过池化操作降低了特征图的分辨率,同时降低了网络输出对于位移和变形的敏感程度.池化层运算公式如下:
(3)
其中,f(°)表示激活函数,S(°)表示降采样函数,采样运算实现了输入图中每个不同的n×n区域均值运算或取最值运算,使得输出图比输入图在不同维度都减小n倍.δ为每个输出图的乘子偏差,b为附加偏差.
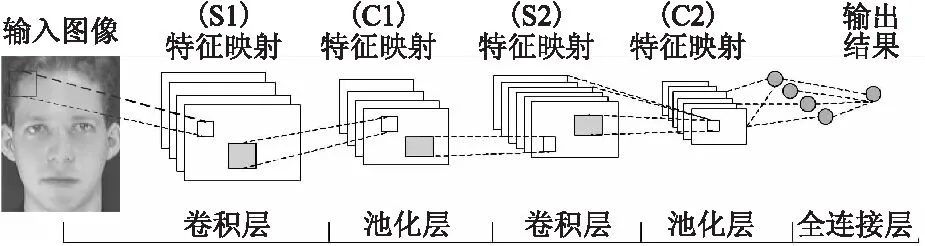
图3 卷积神经网络结构图Fig.3 Structure of convolutional neural network
全连接层,主要实现从特征到类别输出的转换,运算公式如下:
(4)
其中,ω为全连接层的权重取值,bi为全连接层第i个神经元的偏置项,yi表示第i个神经元的输出值,N最后一个池化层包含特征图的个数,M表示每个特征图上包含M个神经元,f(°)表示激活函数,m表示类别数,Q表示输出层激活函数的作用值,Q与y均为m维向量.
4 自学习卷积神经网络
传统卷积神经网络模型的定义往往需要较多的人工干预,忽略了数据样本对网络模型的需求和影响.尽管卷积神经网络性能会随网络中神经元数目的增加而提高,但卷积运算复杂,增大网络规模,需耗费大量训练时间,且网络规模增加后所提升的性能相对于所增加的计算开销而言不成比例,识别精度有时略微提升,有时反而下降.因此,本文根据姿态变化人脸的特点,设计了一种对网络深度和特征图个数具有自学习能力的网络模型构建方法,优化了网络的层次结构和性能.
4.1 自学习深度卷积神经网络结构初始化
已有研究表明[21],当深度卷积神经网络的层级超过7层后,网络的训练难度明显增加,误差反传过程中的梯度为零,使网络训练陷入中断状态,无法实现参数学习和更新.因此,本文在网络结构初始化时,将网络深度设置为5层,且每层仅包含一幅特征图.如图4所示.

图4 初始网络结构Fig.4 Initial network structure
初始网络仅包含一条支路,其中含两个卷积层(C1、C2)、两个池化层(S1、S2)和一个全连接层,每层仅含一幅特征图,结构简单,参数较少,减少了训练时间.训练过程中,采用BP算法更新权值,并通过收敛速度的大小判断当前训练的网络是否达到最优,网络收敛速度定义如下:
errhope-errreal≥T
(5)
其中,errhope表示初始系统的期望平均误差,errreal表示当前系统的真实平均误差,T为收敛速度的期望阈值,设定为0.1.
当前系统平均误差err计算公式为:
(6)
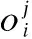
若式(5)成立,表明初始网络具有训练至系统平均误差达到期望平均误差值的能力,则不需要添加新支路;若式(5)不成立,则初始网络结构不能达到收敛,需要对当前网络结构展开全局扩展学习.
4.2 深度卷积神经网络结构的全局扩展学习
深度卷积神经网络的全局扩展是在网络初始结构基础上扩展出一条新支路,如图5所示.扩展新支路前,先保留初始网络卷积层和池化层的相关参数及输出结果oA.添加新支路B具有与初始支路A相似的结构,支路B输出oB.最后的输出层为新添加的全连接层,融合了支路A和B的输出结果.此时网络深度扩展为6层,含两个卷积层、两个池化层和两个全连接层.最终输出结果为:

图5 全局扩展网络Fig.5 Global expanded network
o=f(oA+ωBoB)
(7)
其中,oA和oB是m×1的二值向量,ωB是m维的列向量,表示了B支路输出的权重值,而A支路输出的权重值则设置为1.
训练过程中初始网络结构和相关参数固定不变,通过BP算法只更新增B支路权值,直到网络系统平均误差达到期望值,完成网络全局扩展学习.
4.3 深度卷积神经网络结构的局部扩展学习
全局扩展后,网络系统平均误差低于期望值,但网络识别性能可能并未达到最优.因此,本文采用交叉验证样本对网络性能进行评估,即通过交叉验证样本的识别率进行判断.当不同批次交叉验证样本的识别率趋于某一个稳定值,且此稳定值为非理想状态,此时需对已有全局支路进行融合,构建形成新的局部支路,实现网络结构的局部扩展学习,图6展示了局部扩展后的网络结构.
本文采用的局部扩展是对经过一次卷积和池化之后的特征图执行的卷积和融合运算.在执行局部扩展前,首先需要保存全局扩展模型的相关权重参数以及网络输出值.
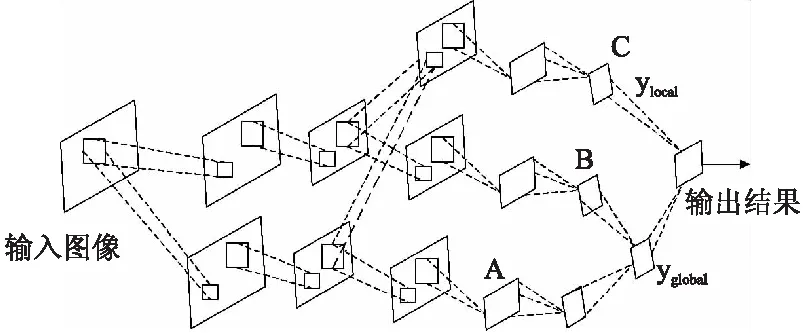
图6 全局和局部扩展后的网络结构图Fig.6 Network structure of global and local expansion
在训练局部支路时,将全局扩展模型中池化层S1的特征图作为输入,进行特征融合,公式如下:
C1Local=f(S1A*kA+S1B*kB)
(8)
其中,C1Local表示局部支路C1层的特征图,S1A、S1B分别为全局支路A、B在S1层的特征图,kA、kB为卷积核,融合方法采用简单的求和运算.
将全局输出yGlobal值叠加到局部支路的输出层上,通过激励函数f(°)输出:
o=f(yGlobal+ωLocalyLocal)
(9)
经过局部扩展学习后,网络中又添加一个新的全连接层,此时网络深度已扩展为7层,含两个卷积层、两个池化层和三个全连接层.
训练过程,全局支路网络结构固定,在BP算法中只更新局部支路权值,直到交叉验证样本的识别率达到期望值后停止学习,此时网络结构具有最高的精确度.
显然,通过网络收敛速度的大小控制网络结构全局扩展学习,采用交叉验证样本识别率判断是否需要执行局部扩展学习,深度卷积神经网络深度和每个卷积层的特征图个数实现了自适应的学习,而且网络训练也由原来的整个网络参数同时训练转化为分批次的参数训练,一定程度上降低了训练难度和复杂度.本文的网络构建方法克服了传统卷积神经网络构建过度依赖经验知识的弊端,避免了盲目通过增加训练次数改善识别率的弊端,减少无效训练,提升了识别准确度.
5 实验分析
5.1 人脸库及实验条件介绍
本文使用了卡耐基梅隆大学CMU-PIE人脸数据库*http://vasc.ri.cmu.edu/idb/html/face/ 2016, October和麻省理工学院生物和计算学习中心人脸库MIT-CBCL*http://cbcl.mit.edu/softwaredatasets/heisele/facerecognition-database.html 2016, October.实验中从CMU-PIE人脸库随机选取每人姿态变化明显的人脸50幅,共3400幅图像(包含姿态,光照变化)构建人脸底层特征和训练自学习深度卷积神经网络,人脸尺寸归一化为28×28.随机选取每人20幅人脸,共1360幅作为交叉验证样本.随机选取每人20幅人脸,共1360幅作为测试样本.图7所示为人脸库中某人姿态变化时的人脸.

图7 CMU-PIE人脸库中的人脸图像Fig.7 Face images in the face database CMU-PIE
MIT-CBCL人脸库共10人,每人200幅图像,包括大范围连续的姿态变化、微弱的光照和表情变化,人脸尺寸归一化为28×28.图8给出了该人脸库中部分人脸图像.实验中,每人选取80幅人脸,共800幅图像用于构建人脸底层特征图和训练卷积神经网络,其余1200幅人脸中,选取400幅作为交叉验证样本,800幅作为测试样本.

图8 MIT-CBCL人脸库中的人脸图像Fig.8 Face images in the face database MIT-CBCL
通过实验数据分析,CMU-PIE人脸库中的人脸图像存在明显的俯仰角变化和左右视角变化.根据俯仰角的变化范围,训练人脸图像可划分为3个流形层(俯视、平视、仰视),根据视角变化情况每个流形层又可划分5个局部子空间.所以每类人可构建出27幅人脸底层特征图像,则每人最终用于网络训练的样本共77幅.
MIT-CBCL人脸库中的人脸图像无俯仰角变化,只存在明显的左右视角变化,所以该人脸库只包含1个流形层,而每个流形层中的左右视角变化连续性较好,可划分多个不同的局部子空间.本文将其划分为7个局部子空间:子空间1视角变化范围为[-90o,-70o);子空间2视角范围为[-70o,-50o);子空间3视角范围为[-50o,-30o);子空间4视角范围为[-30o,-5o);子空间5视角范围为[-5o,5o];子空间6视角范围为(5o,30o];子空间7视角范围为(30o,50o];子空间8视角范围为(50o,70o];子空间9视角范围为(70o,90o].显然,9个局部子空间可产生17幅人脸底层特征图像,每人用于网络训练的人脸图像变为97幅.
5.2 结合深度特征提取的姿态变化人脸识别
传统卷积神经网络中通常采用2个卷积层、2个池化层和1个全连接层的5层结构.网络结构通常采用卷积层和池化层的特征图个数进行表示,例如传统卷积神经网络结构表示为:2-2-6-6,则说明网络中卷积层C1和池化层S1包含2幅特征图,卷积层C2和池化层S2包含6幅特征图.本文基于不同结构的卷积神经网络实现姿态变化人脸识别实验.实验中学习率设为固定值0.3,池化运算采用平均池化,卷积核的大小可设为5×5或3×3,实验中对不同卷积核组合进行了对比,结果如图9所示.
上述实验表明,基于不同人脸库和不同结构卷积神经网络实验结果具有明显差异.网络中卷积层和池化层的特征图个数对识别效果产生了严重影响.另外,针对不同的人脸数据,达到最优识别效果时的网络结构和卷积核等参数配置是完全不同的.因此,仅基于经验或先验知识而构建的网络结构不能充分反映样本数据的本质特点.而针对某一样本集合,通过大量的实验确定最优的网络结构则通常需要消耗较多的时间和资源,且网络结构不具备普适性.因此,基于样本数据本身具有的特点研究一种能够自适应的调整网络结构,实现网络特征图个数自主学习和调节的深层卷积神经网络,对于完善深度网络构建理论具有重要意义.

图9 结合深度特征提取的姿态变化人脸识别Fig.9 Pose-varied face recognition results based on deep feature extraction
另外,分别采用原始姿态变化人脸图像和引入人脸底层特征图扩充样本后的识别效果进一步证明了样本扩增对于网络识别性能的提升,也说明构建得到的人脸底层特征图蕴含了姿态变化人脸的部分非线性信息,对于具有视角变化的姿态变化人脸识别是关键的.
在华人社区,李老头结识了同样喜欢中医的朋友,与他们一起分享中医文化与养生之道,也吸引了不少外国友人。谈起健康养生之道,李先生说:“养生贵在按时,按时饮食,按时运动和睡眠,按时进行各种身心活动,生活要有规律。”
5.3 基于自学习卷积神经网络的姿态变化人脸识别
本文基于两个不同人脸库,分别进行了基于自学习深度卷积神经网络模型构建和识别实验.网络的初始结构设置为1-1-1-1结构,如图4所示.通过卷积核大小的调整和网络结构的自适应学习,可以获得最佳网络.由于输入图像的像素归一化为28×28,所以深度卷积神经网络结构全局扩展学习中卷积层1的卷积核仅能设置为5×5,卷积层2的卷积核可设置为5×5或3×3,网络结构局部扩展卷积层的卷积核可选5×5或3×3.不同卷积核组合情况下的实验结果如表1和表2.

表1 深度卷积神经网络全局扩展中不同卷积核组合的实验Table 1 Experimental results of different convolution kernel combinations in the global expansion of deep CNN
表1数据表明,在全局扩展中不同大小的卷积核对识别率产生了不同影响.卷积核大小影响到网络结构中的连接权重个数,所以卷积核5-3(卷积层1卷积核为5×5,卷积层2卷积核为3×3)组合的训练时间比5-5组合的训练时间明显降低.而不同数量连接权重作用下,网络识别性能也受到一定影响.卷积核5-3组合的权重个数较少,但识别性能却优于5-5组合,因此并不是权重数量越多越好,同时也说明每层的特征图个数也不是越多越好.在合理调整卷积核大小时,根据数据样本的自身情况,按需添加神经元,实现网络结构的自适应扩展有利于提高运算效率,改善网络识别性能.
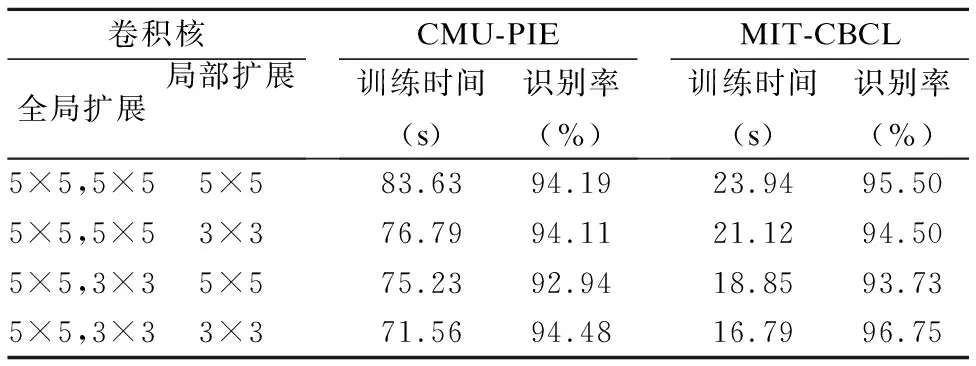
表2 全局与局部扩展结合时不同卷积核组合的实验结果Table 2 Experimental results of different convolution kernel combinations in global and local expansion
表2的实验结果表明,全局扩展卷积核5-3组合,局部扩展采用卷积核3×3时,网络的误分类率最低,本文实验中选此组合作为深度卷积神经网络构建过程中的卷积核.而利用两个人脸数据库上的样本,通过自学习训练得到的最优网络结构均为1-1-3-3结构.
由于学习率影响着每次循环训练中所产生的权值变化量,较大学习速率可以加快训练速度,但易导致系统不稳定,而较小学习速率则导致训练时间较长,网络收敛速度变慢,但是能保证网络误差最终趋于最小误差值.因此,网络设计中倾向于选取较小的学习速率以保证系统的稳定性.本文通过实验确定了最优学习率取值为0.6.
基于自学习的深度卷积神经网络构建过程简单,无需人工干预和多次重复实验,网络结构与数据密切相关.从识别性能看,传统卷积网络在CMU-PIE人脸库和MIT-CBCL人脸库中获得的最优识别率分别为93.38%和96.875%.自学习深度卷积网络中,通过网络结构全局扩展在CMU-PIE人脸库和MIT-CBCL人脸库中获得的最优识别率分别为93.16%和95.25%.而经过局部扩展后获得的最优识别率为94.48%和96.75%.从网络构建时间看,传统卷积网络获取最优的网络结构需通过大量重复实验确定,耗费较多的时间.而本文提出的网络构建思想尽管识别率没有达到传统卷积网络的最优值,但是训练时间大大降低.综合考虑识别率和训练效率,本文提出的网络结构自学习策略是有效可行的.
5.4 与其他方法的对比实验
为说明人脸底层特征和自学习卷积神经网络模型构建在姿态变化人脸识别中的有效性,本文分别与其他几种典型姿态变化人脸识别方法进行了实验对比,其中主要包括基于姿态校正的方法、基于流形学习的方法和基于Gabor变换的方法,分类过程都采用最近邻分类器,实验结果如表3所示.

表3 与其他方法的识别效果对比Table 3 Comparison of recognition effect on our method with other methods
针对训练样本和测试样本进行Gabor小波变换的姿态变化人脸识别中,选取了5个尺度,8个方向的Gabor滤波器人脸图像进行卷积运算,然后采用卷积图像的幅值响应作为特征进行分类识别.实验中分别采用了训练样本中的正面人脸(或近似正面的人脸)和具有明显姿态变化的人脸作为标准样本用于识别.采用正面人脸作为标准人脸的情况下,两个人脸库中的识别效果表现优秀,CMU-PIE库中的识别率达到90.22%,MIT-CBCL人脸库中的识别率为91.75%;在采用具有明显姿态变化的人脸图像作为标准样本时,CMU-PIE测试人脸库中得到的平均识别率为88.09%,MIT-CBCL测试人脸库中得到的平均识别率为87.25%.实验数据表明,Gabor变换在一定程度上能够克服光照和姿态对人脸识别的影响,但是当人脸出现大角度姿态变化时,Gabor函数无法准确提取面部纹理特征,识别效果变差.另外由于Gabor变换分别增加了标准人脸和测试人脸的特征维数,极大的增加了数据量,使识别速度慢,实时性较差.
基于流形学习的方法,本文采用了局部保持鉴别投影算法(LPDP)对姿态变化原始人脸训练图像直接进行特征提取获取变换矩阵,该方法在CMU-PIE人脸库上达到的最优识别率为86.17%,在MIT-CBCL人脸库上的识别率为87.375%.综合考虑识别率和识别时间,该方法是较优秀的,这表明流形学习方法在提取姿态变化人脸的非线性特征中具有一定的优势.
总之,采用深度学习算法比传统姿态变化人脸识别方法的总体识别率要高,且通过构建人脸底层特征图实现姿态变化人脸样本扩充后,训练得到的网络识别效果具有明显提高.而自学习深度卷积神经网络的构建则更好地改善了最优网络构建的重复训练思想,提高了运算效率.
6 结束语
本文提出基于自学习深度卷积神经网络的姿态变化人脸识别方法.首先基于姿态变化人脸的空间分布信息将姿态人脸划分为不同流形层和子空间,通过构建人脸底层特征实现姿态变化人脸的样本扩充,克服了原始人脸较少时训练样本较少,特征提取不充分等缺点.然后针对传统卷积神经网络构建过分依赖经验,提出自学习深度卷积神经网络构建策略,并将该方法成功应用于样本扩充后的姿态变化人脸识别.本文所提方法降低了网络训练难度,避免了无效训练,且能有效提取姿态变化人脸中的非线性信息.
:
[1] Huang Kai-qi,Chen Xiao-tang,Kang Yun-feng,et al.Intelligent visual surveillance:a review[J].Chinese Journal of Computer,2015,38(6):1093-1115.
[2] Zou Guo-feng,Fu Gui-xia,Li Hai-tao,et al.A survey of multi-pose face recognition [J].PR&AI,2015,28(7):613-625.
[3] Du Cheng,Su Guang-da,Lin Xing-gang,et al.Synthesis of face image with pose variations[J].Journal of Optoelectronics·Laser,2004,15(12):1498-1451.
[4] Lin Z X,Yang W J,Ho C C,et al.Fast vertical-pose-invariant face recognition module for intelligent robot guard[C].The 4th International Conference on Autonomous Robots and Agents,2009:613-617.
[5] Wang Ke-jun,Zou Guo-feng,Fu Gui-xia,et al.An approach to fast eye location and face plane rotation correction[J].Journal of Computer-Aided Design & Computer Graphics,2013,25(6):865-872.
[6] Chai Xiu-juan,Shan Shi-guang,Chen Xi-lin,et al.Local linear regression for pose invariant face recognition[J].IEEE Trans on Image Process,2007,16(7):1716-1725.
[7] Chen Hua-jie,Wei Wei.Multi pose face recognition based on correlative sub region mapping [J].Journal of Image and Graphics,2007,12(7):1254-1260.
[8] Maria De Marsico,Michele Nappi,Daniel Riccio,et al.Robust face recognition for uncontrolled pose and illumination changes[J].IEEE Transactions on Systems,Man,and Cybernetics:Systems,2013,43(1):149-163.
[9] Yin Bao-cai,Zhang Zhuang,Sun Yan-feng,et al.Pose variant face recognition based on 3D morphable model[J].Journal of Beijing University of Technology,2007,33(3):320-325.
[10] Ye Chang-ming,Jiang Jian-guo,Zhan Shu,et al.3D facial depth map recognition in different poses with surface contour feature[J].PR & AI,2013,26(2):219-224.
[11] Zhang Yan-ning,Guo Zhe,Xia Yong,et al.2D representation of facial surfaces for multi-pose 3D face recognition[J].Pattern Recognition Letters,2012,33(5):530-536.
[12] Abhishek Sharma,Murad Al Haj,Jonghyun Choi,et al.Robust pose invariant face recognition using coupled latent space discriminant analysis[J].Computer Vision and Image Understanding,2012,116(11):1095-1110.
[13] Zhang Hai-chao,Nasser M Nasrabadi,Zhang Yan-ning,et al.Joint dynamic sparse representation for multi-view face recognition[J].Pattern Recognition,2012,45(4):1290-1298.
[14] Lian Shu-fen,Liu Yin-hua,Li Li-chen.Face recognition under unconstrained based on LBP and deep learning[J].Journal on Communications,2014,35(6):154-160.
[15] Chen Yong,Huang Ting-ting,Liu Hua-lin,et al.Multi-pose face ensemble classification aided by Gabor features and deep belief nets[J].Optik,2016,127(2):946-954.
[16] Chu Xiao,Leng Ze,Wang Yan-ling,et al.Face recogniton with pose variation based on fusion of multi-scale MRF and SCT [J].Application Research of Computers,2016,33(8):2519-2523.
[17] Qin Hong-wei,Yan Jun-jie,Li Xiu,et al.Joint training of cascaded CNN for face detection[C].IEEE International Conference on Computer Vision and Pattern Recognition,2016:3456-3465.
[18] Liu Zi-wei,Luo Ping,Wang Xiao-gang,et al.Deep learning face attributes in the wild[C].IEEE International Conference on Computer Vision,2015:3730-3738.
[19] Iacopo Masi,Stephen Rawls,G′erard Medioni,et al.Pose-aware face recognition in the wild[C].IEEE International Conference on Computer Vision and Pattern Recognition,2016:4838-4846.
[20] Shi Xiang-bin,Yang Ke,Zhang De-yuan.Symmetric deep neural network for image classification[J].Journal of Chinese Computer Systems,2017,38(3):578-583.
[21] Li Xin-hua,Yu Qian.Face recognition based on deep neural network[J].International Journal of Signal Processing,Image Processing and Pattern Recognition:2015,8(10):29-38.
[22] Wang Ke-jun,Zou Guo-feng.A sub-pattern gabor features fusion method for sigle sample face recogniton[J].PR & AI,2013,26(1):50-56.
[23] Zhao Zhen-hua,Hao Xiao-hong.Linear locality preserving and discriminating projection for face recognition [J].Journal of Electronics & Information Technology,2013,35(2):463-467.
附中文参考文献:
[1] 黄凯奇,陈晓棠,康运锋,等.智能视频监控技术综述[J].计算机学报,2015,38(6):1093-1115.
[2] 邹国锋,傅桂霞,李海涛,等.多姿态人脸识别综述[J].模式识别与人工智能,2015,28(7):613-625.
[3] 杜 成,苏光大,林行刚,等.多姿态人脸图像合成[J].光电子·激光,2004,15(12):1498-1451.
[5] 王科俊,邹国锋,傅桂霞,等.一种快速眼睛定位与人脸平面旋转校正方法[J].计算机辅助设计与图形学学报,2013,25(6):865-872.
[7] 陈华杰,韦 巍.基于关联子区域映射的多姿态人脸识别[J].中国图象图形学报,2007,12(7):1254-1260.
[9] 尹宝才,张 壮,孙艳丰,等.基于三维形变模型的多姿态人脸识别[J].北京工业大学学报,2007,33(3):320-325.
[10] 叶长明,蒋建国,詹 曙,等.基于曲面等高线特征的不同姿态三维人脸深度图识别[J].模式识别与人工智能,2013,26(2):219-224.
[14] 连淑芬,刘银华,李立琛.基于LBP和深度学习的非限制条件下人脸识别算法[J].通信学报,2014,35(6):154-160.
[16] 初 晓,冷 泽,王艳玲,等.基于多尺度MRF结合超级耦合变换的姿态变化人脸识别[J].计算机应用研究,2016,33(8):2519-2523.
[20] 石祥滨,阳 柯,张德园.基于对称神经网络的图像分类[J].小型微型计算机系统,2017,38(3):578-583.
[22] 王科俊,邹国锋.基于子模式的Gabor特征融合的单样本人脸识别[J].模式识别与人工智能,2013,26(1):50-56.
[23] 赵振华,郝晓弘.局部保持鉴别投影及其在人脸识别中的应用[J].电与信息学报,2013,35(2):463-467.
