CNN支持下的领域文本自组织映射神经网络聚类算法
2018-07-04贾声声彭敦陆
贾声声,彭敦陆
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
文本自动化聚类是文本信息检索、文本信息挖掘、推荐算法等自然语言处理应用的基础,其目的是将大规模文本数据按照某种模型将文本聚集成不同簇,各个簇中的文本满足簇间文本相似性小而簇内文本相似性大的特点.通常,在文本聚类之前,需要对原始数据抽取特征词并进行向量化.随着文本规模的增大,为高效地进行文本特征抽取向量化及文本聚类提出了新的挑战.
文本特征抽取及向量化表示是将文本转化为计算机能够处理的数学形式,它是文本聚类的前提.最早出现在自然语言处理领域的是基于BOW(Bag-of-words model)模型向量表示,该模型忽略了原文本的语法和语序,采用一组无顺序的词语来表示文本向量.文献[2]中,作者利用基于BOW模型的特征抽取方法进行文本特征抽取.然而实际应用表明语法和语序都是提高文本特征提取准确度的关键因素,而基于BOW模型向量表示进行特征抽取的方法缺少对二者考虑,从而使直接运用该模型进行特征抽取及向量化难以保证其准确度.近些年,随着神经网络和机器学习的不断发展,在自然语言领域提出了词嵌入(word embedding)的词向量模型[3].该模型具有能够表达词与词之间的语义且不存在维数灾难问题等优点.文献[4]提出的C-LSTM 神经网络模型是将RNN(Recurrent Neural Networks)和CNN(Convolutional Neural Network)结合建立混合模型来实现文本特征提取及向量化表示.C-LSTM能捕获局部短语来代表全局句子的语义,以此提高文本分类的正确率.文献[5]通过word2vec获得词向量,将静态词向量和动态词向量作为CNN模型的两个通道,从而提高了分类效果.这些研究表明,利用神经网络的方法对文本特征提取及文本向量化表示,可以在一定程度上提高文本分类的准确度.
本文在对神经网络文本向量表示模型进行深入研究的基础上,利用领域文本内在的规范性,对CNN算法进行扩展,提出一种基于动态词窗口的CNN文本特征提取新算法.利用提取的文本特征向量,采用一种基于森林结构的自组织映射神经网络聚类算法实现了文本的聚类分析.通过将所提算法应用于海量法律文本聚类分析,验证其有效性.
2 相关工作
多年来,文本聚类算法已有众多专家对其进行了研究,提出了许多与聚类算法有关的研究成果.与本项研究最为相关的是基于自组织网络SOM(Self-organizing Maps)的文本聚类方法.在文献[6]中,Kohen提出自组织映射网络理论,它是基于无监督学习方法的自组织神经网络SOM.SOM模型结构由上层竞争层(输出层)和下层输入层两部分组成.对于每一个样本的输入,当前网络模型会对输入的样本执行一次自组织适应过程,持续调节输入层和输出层之间的权数矩阵W,直到网络模型稳定为止.SOM模型聚类之前,竞争层需要预先设定权数矩阵和神经单元个数,且训练过程中是恒定不变的.因此,需要经过若干次仿真训练才能确定竞争层神经元的数目.为了解决上述问题,在文献[7]中,Alahakoon等人提出了动态增长自组织映射模型GSOM(Growing Self-Organizing Maps).GSOM模型的竞争层初始是四个神经元组成的正方形结构,对输入样本基于当前网络来寻找最佳神经元,而调整最佳神经元和相邻结点权值以及累积误差时,利用与SOM相似的方法进行.当增长阈值小于当前累积误差时,根据邻域是否有空闲结点决定是生成新的结点还是将误差分布给相邻结点.文献[1]中,Damminda Alahakoon等人在GSOM的基础上,利用语义相关性策略,提高文本聚类效率.由于GSOM模型生成新的结点比较有局限性,算法执行效率低,文献[11]提出了一种新的树形动态自组织映射神经网络TGSOM(Tree Growing Self-Organizing Maps).TGSOM算法采用了灵活的树型结构解决了GSOM模型生成新结点的局限,竞争层初始有且仅有一个根节点,对输入样本基于当前网络寻找最佳匹配结点,如果误差大于生长阈值,则生成最佳匹配结点的孩子结点即新的神经元.TGSOM模型结构虽然灵活,但需要多次聚类才能够实现层次聚类,网络训练过程中某些部分使用的计算方法对网络聚类速度有很大的影响,例如,获胜神经元的计算策略.
对于特定的大规模领域文本数据集(如法律文书),利用文本集表达的规范性和专业性,在基于动态词窗口的CNN新的文本特征提取算法的基础上,本文从聚类数目的自增长、获胜神经元的计算策略对SOM聚类算法进行了改进,提出了基于森林结构的FGSOM模型.在FGSOM模型中,每一棵树代表大类别,树中的结点代表所属类别的子类别,一次计算实现文本的层次聚类.根据最佳匹配结点的误差与生长阈值的关系,决定是产生大类别的根结点还是产生已有大类别的子结点.在计算输入样本和神经元的误差时,结合竞争层森林的特殊分布结构,采用局部最优策略,提高聚类速度及计算效果.
3 基于动态词窗口的CNN的文本特征提取模型
下面讨论如何通过动态词窗口卷积神经网络提取文本特征.3.1部分给出下文出现的相关术语解释;3.2部分介绍文本预处理过程;3.3部分描述文本抽象特征提取算法的详细过程.
3.1 术语解释
文本向量表示:非结构化文本转化为计算机能够处理的数值形式,记为d(x1,x2,x3,…,xn):.其中,n代表向量的维数.
文本聚类:文档数据集D(d1,d2,d3…dm)按照某种模式将相似文本聚集到一起,组成不同簇的过程,其中m代表文本的总数量.
停用词:文档中出现频率极高但没有具体含义(不能代表文档所表达的语义)、类别区分度较低的词语(比如“的”,“了”等).
特征模式:分析案件文本,构建符合特定句法结构的文本片段,即特征模式.譬如,交通肇事案件文本中,可以建立“醉酒[*]驾驶”、“未让[*]先行”等正则表达式特征模式.
词性模板:对案件文本进行分词、词性标注处理,得到词性片段,挖掘频繁出现的n-gram词性,被称为词性模板.以句子“盗窃/v一/m部/q苹果/n手机/n”为例,应用词性模板/m/q/n/n就可以挖掘出短语“一部苹果手机”.
3.2 数据预处理
词语作为能够单独成义的最小语言成分,在不同的语言中有着不同的区分方法.例如,英文单词以空格作为自然分界符,而中文则是以字作为基本的书写单位,词语之间没有明显的区分标记.因此,中文分词是解决文本向量表示、文本聚类等问题的基础.对中文分词的研究已取得了一些研究成果,如中国科研院研发的NLPIR汉语分词系统可以完成文本的分词任务.分词准确度在很大程度上受分词器所使用的词库影响,为了提高分词的准确度,本文在分词过程中不使用分词器自带的分词库,而是采用领域(如法律领域)分词库.分词还进行了过滤停用词等操作,以提高抽取词的代表性.抽取词语后,利用 Mikolov[8,9]提出word2vec计算模型来求得词库中每一个词语的向量表示.在文本特征抽取过程中,本文提出基于动态词窗口的卷积神经网络模型进行词向量训练,实现文本片段的向量表示,并降低了向量的维数,以此提高后续计算效率.
3.3 基于动态词窗口的 CNN文本特征抽取模型
CNN是一种前馈神经网络,它包括卷积层、池化层、全连接层,模型结构主要特点是:局部感受野(local receptive fields)、共享权值(share weights,权重矩阵和偏置)、池化(pooling).其利用了图像中局部像素点联系比较紧密,而距离较远的全局像素点联系比较疏远的特征.在文本数据中,词语类似于图像中的像素点,其相互间的关系与像素点相类似.因此,在计算过程中,每个神经元先对局部进行感知,而在下一层将信息进行综合得到全局信息.在神经元局部进行感知过程中,权重和偏置是共享的.池化层对卷积层输出的特征图进行抽取,一方面简化卷积层输出的信息,一方面提取最具有代表性的特征,通常有最大池化和平均池化两种,即选取区域中特征的最大值或者平均值.
这里提出一种基于动态词窗口的CNN文本特征提取模型(如图1所示),该模型在Yoon Kim提出的基于英文句子级别分类模型的基础上而来.Yoon Kim利用word2vec训练好的词向量作为输入,通过CNN来实现短文本的分类,这一模型的缺陷是没有利用与领域相关的文本特征.例如,在处理法律文书时,法律文本具有规范性以及专业术语表达的规律性.本文利用基于词语的属性(包括词性模板、特定模式)进行动态词窗口卷积,可以确保窗口内的文本更具有连贯性、语义性(比如,“一台笔记本电脑”,如果基于大小为3的固定窗口卷积,“一台笔”“记本电”“脑”出现在同一个窗口中没有实际意义.而基于动态词窗口卷积,利用词性模板,“一台笔记本电脑”将出现在同一个窗口中,卷积结果会更有语义性).卷积层每次滑动窗口的大小通过当前词语属性进行动态计算来确定.池化层采用最大化和平均值相结合的方法来提高文本特征提取的质量.
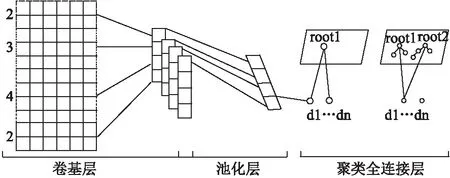
图1 基于CNN的SOM聚类结构Fig.1 Som Clustering Structure Base on
在对文本进行特征抽取的时候,传统的CNN根据n-gram依次提取固定词窗口的卷积特征.词窗口n值的大小直接决定最终的卷积特征的有效性.但n值大小难以准确确定,不恰当的n值对文本特征提取准确度影响较大.一个卷积核通过固定窗口对文本特征提取只能获得一个特征项,在实际计算中,通常使用多个卷积核来获取不同特征.为了解决这一问题,在建立词性模板集合和特征模式词库的基础上,提出CNN在进行卷积操作时,根据当前词语的属性采用DDW-CNN(DDW,Dynamic dictionary window)算法(算法描述见图2)动态地获取词窗口的大小.新特征映射过程中,词窗口大小n取不同值,但其共享矩阵是唯一的.一个词窗口中的单词Xi,i+n对应产生一个新的映射特征cl:
ci=f(w+xi,i+h-1+b)
b是偏置项,f是非线性的函数如双曲正切函数.当过滤器滑动所有位置后,得到特征图c:
c=[c1,c2,c3…cn]
采用动态词窗口,在卷积的过程中能够获取更多隐含在文本中的特征.在池化层采用最大值(Max-Pooling)和平均值(Mean-Pooling)混合池化模型,这一模型的优点是不仅表达最有价值的特征,而且还可以捕捉隐含的特征,很好地解决了文本长度及特征图大小不一致的问题.如公式所示:
基于词语属性的动态词窗口获取算法DDW-CNN
输入:索引Index,文本序列Ts,文本词性序列Tpos,词性模板集合Stc,特征模式词库集合Fplc,文本的长度len;
输出:动态词窗口n

图2 DDW-CNN算法Fig.2 Algorithm of DDW-CNN
如图2所示,在DDW-CNN算法中subTs函数用来获取连续i个词(第2行),而subTpos是获取连续i个词的词性(第3行).算法采用最长序列优先策略来确定词窗口的大小,即如果特征模式满足subTs函数获得的短语,则返回当前短语的长度作为词窗口的大小(第5-9行).相似地,如果词性模板集合中包含subTpos获得的词性短语,则返回当前词性短语的长度作为词窗口的大小(第10-14行).考虑到中文词特点,算法默认返回的词窗口大小为2(第15行).
4 FGSOM层次模型聚类
FGSOM是基于森林结构的自组织映射神经网络聚类算法,为提高计算效率,本研究还通过局部最优策略对FGSOM模型的计算过程进行优化.前文给出了基于动态词窗口的CNN文本特征提取模型,通过该模型可以获得文本向量表示,并将其作为FGSOM模型的输入层.
4.1 基本概念
为了描述方便,在FGSOM模型建模之前,先给出基本定义和算法中用到的定义和规则.
定义1.文本相似度(记作),衡量文本间相似度的重要指标是文本向量间的余弦距离.当前状态竞争层所有神经元与输入文本向量d相似度最小的神经元结点为的最佳匹配结点,记作bmn(best matching node),bmn所属于的树称为bmt(best matching tree).
定义2.决定是否生成新的神经元的临界值称为生长阈值,记作GT(growth threshold).生长阈值分为大类根结点生长阈值(BGT,big growth threshold)和子类结点生长阈值(CGT,child growth threshold).
规则1.新结点生成策略
(a)最佳匹配结点的相似度大于BGT,则产生新类别的root根;否则跳转(b)
(b)最佳匹配结点的相似度大于CGT,则产生bmn的孩子节点.否则跳转(c)
(c)不生成任何节点,进行权值矩阵更新
4.2 FGSOM 算法
FGSOM 处理过程如下:
4.2.1 网络初始化
网络正式计算前需要进行一些必要的准备,如进行各种参数设置等,包括以下内容:
(a)初始网络有且仅有1个神经单元,即根节点(随机选择文档向量进行初始化) .
(b)设置最大迭代次数、终止迭代误差、初始学习速率.
(c)设置生长阈值.
4.2.2 网络训练
网络训练是用来获取稳定的FGSOM网络拓扑结构,本文所提网络的训练阶段完成以下任务:
(a)文本数据集中随机选取文档向量,利用局部最优算法(下文给出)寻找的.
(b)结合规则1结点生成策略,判断是否生成相应的结点.若生成操作,则转(d),否则转(c),对权值进行调整.
(c)利用式(1)对最佳神经元所属树的权值进行调整.
(1)
其中LR(k)为学习率,当k趋于无穷时,LR趋于0.wj(k+1),wj(k)分别为结点j在调整前后的权值;bmt为最佳匹配结点所在的树,如果神经元属于bmt,则对权值进行更新,否则不更新.
(d)LR(t+1)=LR(t)*α,其中α为LR的调节因子,0<α<1.
(e)重复(a)-(d),直到中全部样本训练完毕.
4.2.3 循环学习
重复(2)进入下一个训练周期,直到网络稳定.如果达到最大迭代次数或者达到最小迭代误差则终止网络的训练.
4.3 网络结构
FGSOM网络结构与SOM一样由输入层和竞争层两部分组成,其网络结构如图1中聚类全连接层所示,其中d1…dn是训练的文本向量.图1中聚类全连接层左边部分为FGSOM模型网络的初始状态,此时竞争层只包含一个根结点root1;右边部分为网络生长至7个结点时的状态.两棵树代表两个父类别(root1,root2).root1树中有三个子类别,root2中有四个子类别.例如,在进行法律文本处理时,root1可代表刑法,三个子类别代表盗窃罪、抢劫罪、故意伤害罪.FGSOM模型通过生长阈值的控制,通过一次仿真训练就可以达到层次聚类.模型中的一棵树属于一个父类别,树的内部结点表示父类的子类别.
4.4 选择bmn的局部最优算法
传统bmn的计算方法首先依次计算所有神经元与输入文本之间的相似度,然后对相似度进行排序来选择bmn.这种计算方法的缺陷是需要计算神经元与输入向量的每一维作差和遍历求解,这是一个比较耗时的动作.为了克服这一缺陷,在计算神经元和输入向量相似度时,采用累加求和的策略求解最优bmn,减少维数计算,提出SDUA算法(见图3).
最短距离更新算法 SDUA
输入:最短距离dmin,两个文本向量d1,d2
输出:当前的最短距离dmin


图3 SDUA算法Fig.3 Algorithm of SDUA
算法先行遍历每一维向量(第1行),再利用Distance函数用来求解当前维数的距离(第2行),如果当前维数的距离已经大于dmin,则不再计算后边维数的向量(第3-5行);如果所有维数计算完毕,则更新dmin的值.
在森林结构的基础上,采用局部最优策略,尽早抛弃不可能成为bmn的节点,提出LO-BMN算法(如图4).LO-BMN算法,遍历当前神经元的根集合R,求解最佳bmt(第1-9行),然后求解bmt中的bmn(第10-19行).在两个过程中,都使用了SDUA算法来提高计算效率.针对图3给出的网络模型,输入向量d首先和root1、root2节点计算最佳根节点.若root1>root2,则root1树中的所有神经元不可能成为bmn,那么,在这一阶段抛弃root1树中的所有结点.然后遍历root2中所有的结点,最终求出bmn.在集合中选择最佳结点时,采用维数累加求和SDUA算法,来提高计算速度.
局部最优求解最佳神经元算法:LO-BMN
输入:输入文本d,神经元根集合R,树结点Map结构集合T
输出:最佳神经元节点bmn,最短距离dmin

图4 LO-BMN算法Fig.4 Algorithm of LO-BMN
5 实验与分析
5.1 数据集
实验所用数据集是从Web(浙江法院公开网网址链接:http://www.zjsfgkw.cn/Document/JudgmentBook)下载的某省高级人民法院公开的法律文书(判决书),为真实数据集.数据集涵盖了刑事、民事、商事、行政共计10000篇案件文本.为保证计算的有效性和规范性,在进行特征提取和聚类计算之前,先对原始数据进行了处理,剔除掉乱码等无效的文本片段,最后获得有8126个有效文本段.
5.2 实验结果分析
实验1.考察基于动态词窗口的CNN 特征提取性能
为了验证动态词窗口的CNN模型特征提取性能,实验先利用NLPIR对数据集进行分词,获得以词为单位的数据集,再利用word2vec构建对应的词向量.一个文本片段集的大小为N*300(N指文本片段选取词的数量,大小固定为50).实验中,CNN模型采用一层动态词窗口的卷积层,一层为池化层,最后获得文本的向量表示,作为标准SOM模型的输入层.模型参数具体设置如下:词向量维数300,dropout率(神经元被丢弃的概率)为0.5,迭代次数为30.实验评价采用聚类问题中常用的轮廓系数(silhouette coefficient)作为测试指标,它结合了内聚度和分离度两种因素,如公式所示:
(2)
(3)
其中a(i)代表第i个样本到它所属于簇中其它样本的平均距离.b(i)代表第i样本到所有非本身所在簇的样本平均距离的最小值.公式(3)是聚类结果总的轮廓系数.由公式(2)可见轮廓系数的值介于[-1,1],越趋近于1代表分离度和内聚度都相对较优.
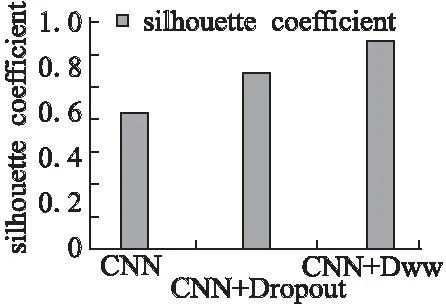
图5 不同模型的轮廓系数Fig.5 Value of silhouette coefficient
为进行比较,实验选取三种类型的CNN模型进行测试,这三种CNN模型为:基本的CNN[5]、加入dropout的CNN[10]、及本文提出的基于动态词窗口的CNN.采用这些网络模型获取文本向量表示,然后对文本进行聚类,根据轮廓系数对模型的计算效果进行评价.图5描述了实验结果,从图中可以看出,使用在基于动态词窗口的CNN模型基础上得到的词向量进行聚类得到的轮廓系数明显优于另外两种模型.基于动态词窗口的CNN聚类轮廓系数在0.8左右,这是因为有的案件文本片段同时属于两个类别,无法准确确定,对聚类结果产生一定的影响.在实际应用中,可以对这类案件文本进行预先过滤,然后对过滤后得到的案件文本进行聚类,可以明显提高聚类效果.

图6 生长阈值对比Fig.6 Comparison of growth threshold
实验2.考察生长阈值(BGT/CGT)对聚类结构的影响
选择合适的生长阈值(BGT/CGT),对提高FGSOM算法的计算效果至关重要.FGSOM模型参数具体设置如下:最大迭代次数设置为1000,终止迭代误差设置为0.01,初始学习速率为0.7,学习速率的调节因子α设置为0.3.实验考查了不同的生长阈值对聚类结构的影响,由图6显示的实验结果可见,BGT/CGT值的大小对最后最终的聚类结构图有较大影响.对于BGT在0.5到1.0之间进行变化可知,当BGT=0.65时,大类别聚类效果最好;当CGT在0到0.5之间变化,CGT=0.3、BGT=0.65时,小类别聚类效果最好.基于此,在对法律案件文本片段聚类时,本文将BGT设置为0.65,CGT设置为0.3.
实验3.考察FGSOM 聚类模型效率
为了验证本文提出的FGSOM层次聚类模型聚类效果和计算效率,选取现有的GSOM算法[7]、TGSOM算法[11]作为对比来进行本组实验.模型参数具体设置如下:BGT设置为0.65,CGT设置为0.3,其他参数和实验二保持一致.

图7 轮廓系数对比Fig.7 Comparison of silhouette coefficien图8 运行时间对比Fig.8 Comparison of runtime
图7描述了不同聚类模型的轮廓系数,从图中可以看出,FGSOM聚类的轮廓系数明显高于另外两种算法.图8给出了在相同数据集上,不同聚类方法进行聚类运算所需时间的对比.GSOM 算法所消耗的时间大于TGSOM、FGSOM 算法,原因在于GSOM 算法在产生新的结点的策略没有其他算法灵活,进而消耗了较多的计算时间.当数据量较小的时候,三种聚类方法差距不明显,无法体现出FGSOM 算法具有优越性,但随着数据集的增大(例如大于3000时),FGSOM算法表现出较好的计算优势.
6 结 论
在分析现有文本处理聚类算法的基础上,文本向量表示及SOM聚类算法存在的缺陷,提出基于动态词窗口的改进型CNN算法进行文本特征提取,以此为输入提出基于森林结构的自组织映射神经网络聚类算法——FGSOM,对大规模文本数据的进行层次聚类.实验结果表明,采用本文提出计算模型可以获得较好的文本聚类效果.通过与现有的基于SOM聚类算法(如GSOM、TGSOM)进行比较可知,FGSOM算法在处理大规模领域文本时,在计算效率和计算效果上表现出一定优势.
:
[1] Nathawitharana N,Alahakoon D,Silva D D.Using semantic relatedness measures with dynamic self-organizing maps for improved text clustering[C].International Joint Conference on Neural Networks,2016:2662-2671.
[2] Hingmire S,Chougule S,Palshikar G K,et al.Document classification by topic labeling[C].International Conference on Information Retrieval,2013:877-880.
[3] Bengio Y,Schwenk H,Senécal J S,et al.A neural probabilistic language model[J].Journal of Machine Learning Research,2003,3(6):1137-1155.
[4] Zhou C,Sun C,Liu Z,et al.A C-LSTM neural network for text classification[J].Computer Science,2015,1(4):39-44.
[5] Kim Y.Convolutional neural networks for sentence classification[C].Proc of Conference on Empirical Methods in Natural Language Processing,2014:1746-1751.
[6] Kohonen T.Self-organization and associate memory[J].Spinger-Verlag,1984,8(1):3406-3409.
[7] Alahakoon D,Halgamuge S K,Srinivasan B.Dynamic self-organizing maps with controlled growth for knowledge discovery[J].IEEE Transactionson Neural Networks,2000,11(3):601-614.
[8] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].Computer Science,2013.
[9] Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013,26:3111-3119.
[10] Hinton G E,Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[J].Computer Science,2012,3(4):212-223.
[11] Wang Li,Wang Zheng-ou.Tgsom:a new dynamic self-organizing maps for data clustering[J].Journal of Electronics & Information Technology,2003,25(3):313-319.
附中文参考文献:
[11] 王 莉,王正欧.TGSOM:一种用于数据聚类的动态自组织映射神经网络[J].电子与信息学报,2003,25(3):313-319.
