基于文本特征的企业微博转发效果影响因素研究
2018-06-28王晓耘范晶晶
王晓耘,范晶晶,陈 思
(杭州电子科技大学 管理学院,浙江 杭州 310018)
自微博兴起以来,对微博转发机制的研究就成为了当前学术界和营销界的热点问题。从企业的角度出发,高转发量的微博提升了自身的影响力,对于产品推广也显得更加快捷迅速,与客户之间的沟通也更为方便。目前,较为有名的制造高转发微博的例子有,如杜蕾斯、野兽派花店、小米手机官方微博等。尽管国内多数企业对微博平台营销的热情较为高涨,但成功毕竟是少数,大部分企业对于如何发布高转发量的微博、以及对影响微博转发率的因素的探究等仍处于摸索时期。从根本上讲,企业亟待解决的问题在于如何快速有效识别对企业微博转发情况造成影响的因素,如何通过确保微博内容本身的吸引力进而提高企业微博的影响力。
然而对企业微博转发情况造成影响的要素复杂繁多,目前相关研究正处于起步阶段且大多为定性的研究,现有的研究中多考虑外部因素,往往忽视了微博内容本身对其的影响。基于此,本文主要围绕微博文本进行特征分析,结合定量的方法,提取特征。在此基础上,根据选择的最优特征建立基于支持向量机转发趋势预测模型,通过对转发情况的具体分析,以揭示微博文本特征与微博转发情况之间的关系。
一、基于微博文本的特征分析及模型构建
(一)微博文本特征分析
本文主要从微博内容特征的角度出发,构建企业微博转发效果影响因素理论模型。其中,自变量包括微博内容特征、微博表现特征、微博时间特征三大类因素。
1.内容特征
(1)微博是否为原创。在微博平台上,针对用户浏览到的微博内容,按发布类型可分为原创和转发他人微博两种方式。本文抓取小米官方微博10 890条,通过统计发现,有近 50.7%的内容(5 516条微博)属于原创微博,49.3%(5 373条)的微博转发自他人,其中原创微博与转发微博的转发量大小不一。因此,本文将微博是原创或是转发纳入研究范围。
(2)微博主题类型。根据微博信息涉及到的内容,可将微博内容划分为不同的主题。2011年,Eun和Yong jun研究了Twitter上微博信息内容类型,它们分别是:企业品牌相关信息、企业本身相关信息、企业产品或服务相关信息、含有链接的信息和生活资讯类信息。2012年中国学者孙泳颖[1]针对三家企业的官方微博进行分析,将微博发送的内容分成五大类:新闻类信息、调研问卷类信息、有奖转发活动类信息、投票类信息和微活动类信息。
结合已有的研究,本文对微博主题类型的描述如表1所示。

表1 微博主题类型描述
在对微博主题确定的过程中涉及到文本分类的问题。通常较为经典的文本分类方法包括:决策树分类算法、朴素贝叶斯分类方法、Rocchio方法[2]、K近邻算法等[3]。其中,朴素贝叶斯方法是最直接的概率分类方法,它的使用最为广泛且贝叶斯分类方法具有易使用、只需一次扫描训练集、善于处理缺失值以数据具有连续性等优点[4]。因此本文选择朴素贝叶斯方法来对微博主题类型进行分类确定。
朴素贝叶斯[5]方法的分类思想可以粗略理解为,针对未知分类项,通过求解在此项出现的条件下每一个类别出现的概率来判断的,哪个类别概率最大,就将该待分类项归于哪个类别。算法流程如下:

第一,计算先验概率及条件概率:
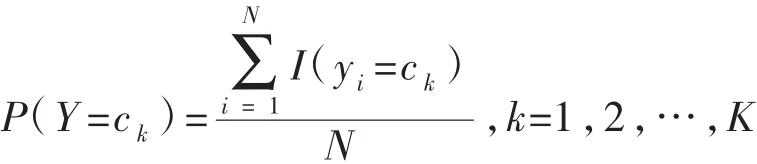

j=1,2,…,n;l=1,2,…,Sj;k=1,2,…,K
第二,对于给定的待分类项 x=(x(1),x(2),…,x(n))T,计算:
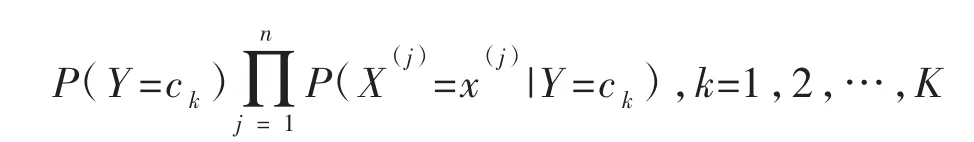
第三,确定待分类项的类:
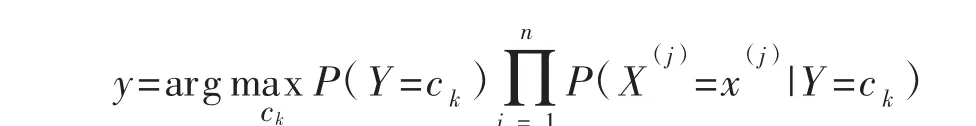
(3)被转发微博的转发量。微博的转发数是评价企业微博影响力的一个重要指标,也是微博与其他网络信息发布平台的最重要的不同之处。Kim等[6]研究表明被转发微博的转发量是一个十分显著的特征,用户很容易受到从众信息的影响进而转发微博信息,从而造成微博信息的瀑布式转发。但并没有与对应的高转发的微博内容联系起来,本文则是根据通过对以往被转发微博的转发情况进行研究,进一步了解受众感兴趣的内容是什么。
2.表现特征
在以往的研究中,Suh等[7]人以twitter数据作为研究对象,研究得出微博是否包含链接和话题标记对微博的转发率有着直接的影响,且微博作者发布的总微博数对其发布微博的转发率基本没有影响。
本文选用微博长度、微博是否含有图片、是否含标签、是否含链接、是否含视频等作为微博的表现特征。
3.时间特征
一条微博的生命周期是有限的。文献[8]将微博的发布时间、发布日期、发布距今时间归纳为微博转发情况的环境影响因素。
本文将微博的时间特征细分微博发布时段、微博发布时长、微博发布日期。
(二)企业微博转发效果影响因素的理论模型构建
本文将微博信息转发情况作为衡量企业微博转发效果的指标,分析转发情况及其影响因素。
根据上述分析的结果,本文构建出企业微博转发效果影响因素的理论模型如图1所示。

图1 企业微博转发效果影响因素理论模型图
二、基于支持向量机的转发趋势预测模型
本文针对企业发布的微博集合M进行研究,将微博信息的转发情况作为企业微博营销效果的衡量指标。基于企业的历史微博转发情况进行训练,主要从微博信息内容的角度出发,对于一条新的企业微博,预测其转发量的高低。
在企业发布的所有微博中,并非所有的微博都具有高转发量。而在影响微博转发量的主要因素中,微博文本内容尤为显著。因此,本文立足微博文本内容,首先对采集到的微博实验数据中的每一条微博主题运用贝叶斯分类方法进行分类,其次,采用信息增益算法缩小特征集合的范围,进而筛选出对转发情况影响较大的因素,同时也可以通过减少转发预测模型的输入变量来提升模型的训练效率。最后,基于筛选出的特征建立转发预测模型,具体分析微博的转发情况。
(一)问题的定义
考虑到本文的预测问题为微博转发量的高低,因而可将其看作一个二分类问题。本文将所用到的数据集样本定义为 d=(a,c,t),其中 a表示微博内容特征,c表示微博表现特征,t表示微博时间特征。同时将某条微博的转发量定义为y。由于微博转发量y只有两个可能的取值,即分类的结果只有两种,分别是C1(高转发量)或 C2(低转发量)。所以本文中的预测模型,总结为一个根据给定的自变量进行二分类的模型。结合支持向量机的特点,因变量y可能的取值及意义由下式给出:

(二)信息增益算法
特征选择[9],是指从全部的特征中选取一个特征子集,使得给定的系统指标最优化。特征子集选择的途径有三种:Filter方法、Wrapper方法、Embedded方法。其中Filter方法是针对每一维的特征赋予权重,这样的权重代表着特征的重要性,然后依据权重排序。
结合本文的目的,即对特征进行重要性排序,因此本文选择Filter方法中的信息增益算法来进行特征选择。具体算法描述如下:
设训练数据集合D,|D|则为整个数据样本的容量,即样本的个数,设有K个类Ck来表示,|Ck|为 Ci的样本个数,|Ck|之和为 |D|,k=1,2,…,根据特征 A 将 D 划分为 n 个子集 D1,D2,…,Dn,|Di|为Di的样本个数,|Di|之和为 |D|,i=1,2,…,记 Di中归属于Ck的数据样本集合为交集Dik,|Dik|为Dik的样本个数,具体算法如下:
输入:D,A
输出:信息增益 g(D,A)
D的经验熵H(D)为:
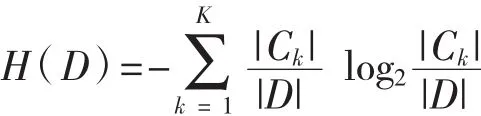
上式可作如下理解:由于训练样本总个数为|D|,某项分类的个数为|Ck|,在某项分类的概率为:|Ck|/|D|
则选定A的经验条件熵H(D|A)
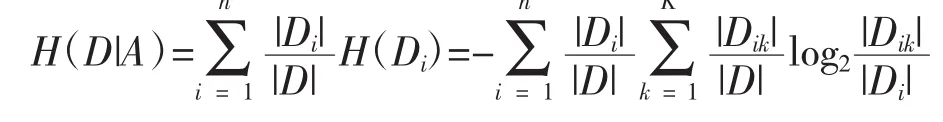
信息增益为:
g(D,A)=H(D)-H(D|A)
(三)基于支持向量机的预测模型构建
1.核函数。一般在解决分类问题时,并不是所有的数据集都是线性可分的。当数据集在低维空间中并不是线性可分时,选用经典的线性可分支持向量机模型,必然得到不理想的分类效果。若此时将低维空间的特征向量映射至高维空间,经过映射处理后的特征即有可能线性可分。因此可以构造映射函数来对数据集进行处理。
核函数的基本定义如下:
设χ是输入空间(欧式空间Rn的子集或离散集合),同时,设η为特征空间(希尔伯特空间),假设存在一个从χ到η的映射φ(x):χ→η使得对所有 x,z∈χ,函数 K(x,z)满足条件 K(x,z)=φ(x)·φ(z),则认为 K(x,z)为核函数,φ(x)为映射函数。式中 φ(x)·φ(z)为 φ(x)和 φ(z)的内积。
选择一个适合的核函数对于模型的分类效果影响巨大。常用的核函数有以下几种:
(1)线性核函数:线性核函数即线性可分支持向量机,表达式为:K(x,z)=x·z
此时可以将线性可分支持向量机与线性不可分支持向量机归为一类,区别仅仅在于线性可分支持向量机用的是线性核函数。
(2)多项式核函数:多项式核函数是线性不可分SVM常用的核函数之一,表达式为:
K(x,z)=(γx·z+r)d,其中,γ,r,d 都需要自行调参定义。
(3)高斯核函数。高斯核函数在SVM中也称为径向基核函数,它是应用于非线性分类支持向量机算法中最主流的核函数。libsvm默认的核函数就是它。表达式为:
K(x,z)=exp(-γ||x-z||2),其中,γ 大于 0,需要自行调参定义。
(4)Sigmoid核函数。Sigmoid核函数是线性不可分SVM常用的核函数之一,表达式为:
K(x,z)=tanh(γx·z+r),其中,γ,r 都需要自行调参定义。
2.预测模型构建。通常情况下,线性可分的数据较为少见。面对线性不可分的低维数据,人们一般采用的方法是将其映射至高维,引入核函数来解决问题。通过引入核函数,构建的预测模型如下:
假设输入是 m 个样本 (x1,y1),(x2,y2),…,(xm,ym),其中x为n维特征向量。y为二元输出,值为1,或者-1。输出是分离超平面的参数ω*和b*和分类决策函数。
算法过程如下:
(1)选择适当的核 K(x,z)和一个惩罚系数C>0,构造约束优化问题:
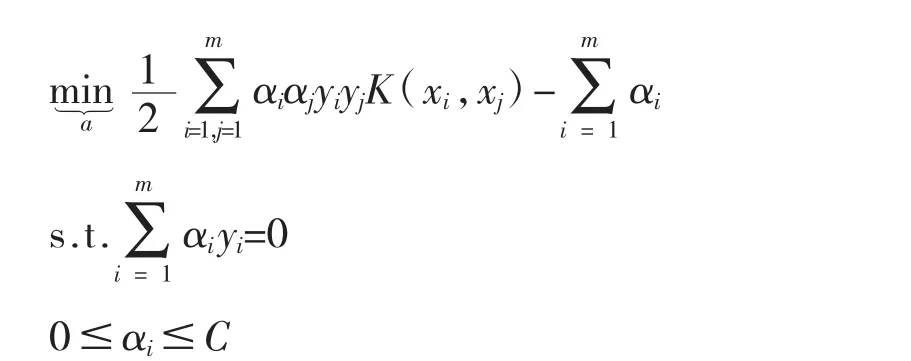
(2)运用SMO算法进行求解,得出上式最小时对应的α*向量。
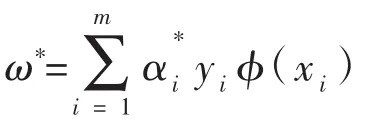
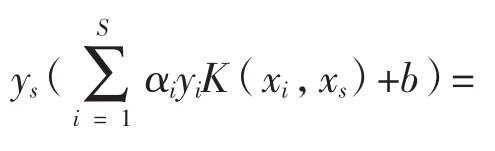
最终的分类超平面为:
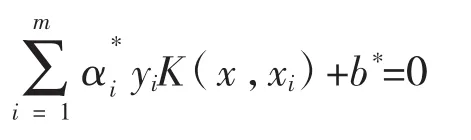
最终的分类决策函数为:
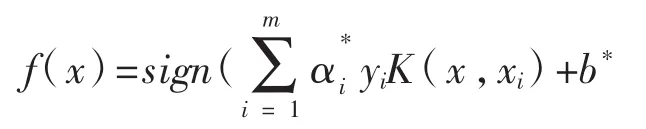
3.评价指标。本文采用分类算法常用评价指标:精确率、查全率、F1值以及准确度,来对预测效果及分类模型进行具体评价。精确率在本文中即为所有被预测为高转发的微博中真实高转发的微博比率。一般情况下,精确率越高,模型的效果越好。查全率为所有高转发微博中被模型正确预测为高转发的比例,准确度即为全部微博被模型正确分类的比例,F1值为查全率与精确率的调和平均值。
分类器在数据集上的预测情况的混淆矩阵如表2所示。

表2 混淆矩阵
下面给出精确率(precision),以下简写为p;查全率recall,以下简写为r;F1度量值的计算公式:
p=TP/Tp+FP
r=TP/Tp+FN
F1=2pr/p+r
准确率的计算公式如下:
Accuracy=TP+TN/TP+FP+FN+TN
三、实验及结果分析
(一)实验数据
小米公司通过在微博营销领域的不断探索,为自身企业的发展提供了良好的营销支持,本文将小米手机作为具体的研究对象。为了获取实验所需数据,本文使用java语言编写数据抓取程序,通过单线程访问新浪微博提供的API接口,采取了小米手机近年来的微博数据作为研究样本,最终得到14 251条微博信息,记录每条微博的基本信息,包含微博id,发表时间,微博内容,图片,视频,转发微博的原微博内容,评论数,点赞数,转发数等字段。
(二)实验数据预处理
1.数据筛选。通过筛选去掉了转发量低于100条以下的微博,最后选定进行研究的微博一共有10 890条。
2.主题的确定。微博主题需要通过对微博文本进行分类处理后才能确定,因此需要对抓取到的微博数据进行文本分类预处理,运用的贝叶斯分类方法对所抓取微博数据中关于词频统计的部分结果如表3所示。

表3 词频统计部分结果表
通过上述方法得到测试集微博对应的话题类型取值。各主题对应的微博数如图2所示。

图2 各主题对应微博图
(三)实验特征选择
为了明确各个特征对转发行为的影响力和减少支持向量机预测模型的输入变量,根据信息增益算法对本文所选取的各个特征信息增益值进行计算,得到特征信息增益值如表4所示。

表4 特征排序表
由此可以看出,在本文选取的11个特征中,微博发布时长、被转发微博的转发量、是否含有视频、是否为原创等4个特征对微博转发的影响较大。本文选取前8个特征作为支持向量机预测模型的输入向量。
(四)预测转发实验
1.基于训练集的模型训练。由于本文采用的分类属性为{高转发量、低转发量},因而对于高转发量与低转发量之间的界定对于整个实验的有效性而言,十分关键。且对于本文运用的基于支持向量机的预测模型而言,选择一个合适的核函数是至关重要的。
因而在训练模型的过程中,确定分类属性边界值的同时,本文使用不同的核函数进行训练,以求能够得到最优的边界值与最适合本数据集的核函数。本文将10 890条数据样本分为训练集3267条(30%)和测试集7623条(70%),分别采取四种不同的核函数基于最优特征集合进行支持向量机预测实验。
通过观察实验数据集的转发量,如图3所示。

图3 微博转发量统计
根据上述统计结果,本文将最开始的边界值设置为1 000,即高于1 000条以上为高转发,低于1 000条则认为是低转发。本文利用libsvm软件包,通过划分好的训练集进行训练,结合四种不同的核函数,不断调整边界值,最终得到如下不同边界值时的分类预测结果如表5、表6、表7、表 8 、表 9 所示。
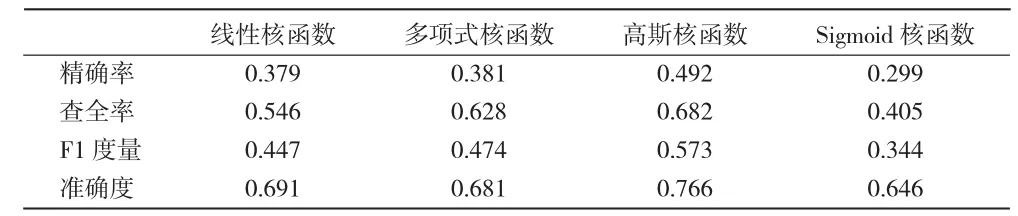
表5 边界值定为1 000时
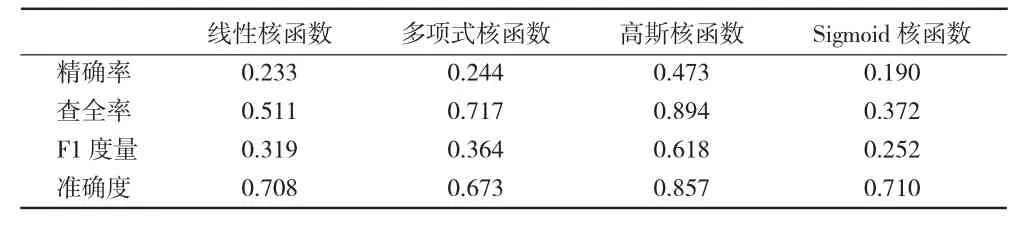
表6 边界值定为2 000时
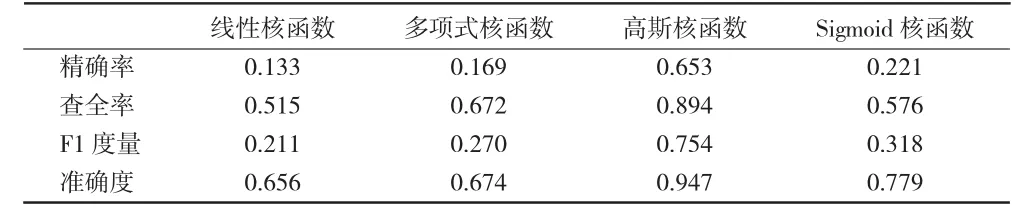
表7 边界值定为3 000时的预测结果

表8 边界值定为4 000时的预测结果
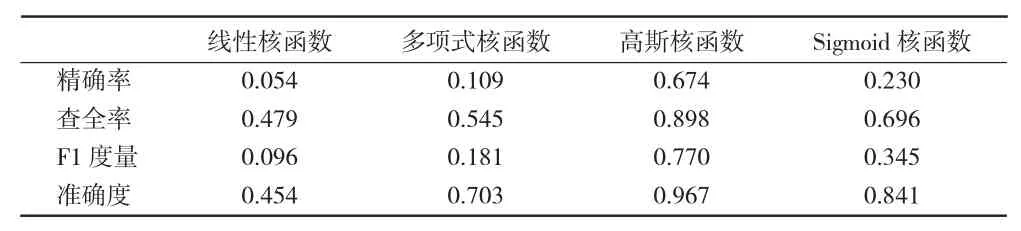
表9 边界值定为5 000时的预测结果
根据上述表中数据对比可知,当转发量的边界值定为4 000时,引入高斯核函数构建的分类预测模型得到的准确度可达到0.974,明显高于其他条件,且精确率为0.783,查全率为0.882。对比其他条件下的评价指标,说明当分类边界值为4 000时,使用高斯核函数来构造基于支持向量机的预测模型,得到的结果较为理想。
2.基于测试集的预测转发实验。本文在选定边界值为4 000和高斯核函数的情况下,本文采用libsvm软件包,采用构建好的支持向量机预测模型进行计算,得到基于最优特征和全特征的混淆矩阵如表10、表11所示。据此计算得到对应的准确率、查全率、F1值、准确度如表12所示。

表10 基于全特征的预测结果混淆矩阵

表11 基于最优特征的预测结果混淆矩阵

表12 基于支持向量机的预测模型对比结果
从表10可以看出,基于全特征集合和最优特征集合的分类模型的各项评价指标相近,最优集合的准确度为0.964仅略低于全特征集合的准确度0.967,这充分说明最优特征对微博转发量的影响近乎接近于全特征,从而验证了最优特征的有效性。
基于对本文转发预测实验结果的分析,以及对可能会影响到微博转发的规律进行总结,本文为帮助企业提高微博转发量,进而在一定程度上对企业微博营销效果造成良好影响,提出以下几点建议:
(1)微博主题类型通常对微博的转发量会造成一定影响,企业在发布微博时,应尽量发布与产品有关或与活动相关性比较大的内容,尽量避免谈及生活信息。根据本文实验结果得出的特征集合可总结出,由于产品信息型多包含有价值的专业信息,这类微博更容易得到用户的认同感进而得到转发,而活动信息类型的微博则是由于会涉及到更多抽奖、促销等与用户利益相关的信息,也很容易吸引到用户,企业可以考虑将产品型与活动型的主题结合到一起发布。
(2)微博是否含标签、图片等表现特征以及微博发布日期这些特征对微博的转发量有一定的影响,但是效果并不显著。因此,可以认为微博的表现特征虽然使得企业发布的微博更加的丰富多彩,但对企业提高微博转发量并没有实质性的影响。其中,根据本文的研究成果,是否含图片与是否含链接这两个特征与微博转发量之间的关联性较弱,企业在发布微博时,不用刻意考虑。
(3)除却考虑微博主题内容的影响外,企业在转发微博时,还应该考虑微博源的转发量。若企业对转发量大的微博进行转发,也会得到较大的转发效果。因此,企业在进行微博转发时,应从微博内容质量和微博源的转发量两方面来考虑。
四、讨论
本文将企业微博的转发量作为企业微博转发效果的衡量指标。同时主要从微博内容的角度对微博特征进行分析,在此基础上,建立了企业微博转发影响因素理论模型。随后运用信息增益方法对分析得出的特征全集合进行影响力大小排序,由此得出最优的特征集合。最后分别基于微博文本全特征集合和最优特征集合建立基于支持向量机的转发预测模型,通过对比实验结果,得到对微博转发量影响较大的特征集合,同时,也验证了本文所采取方法的有效性。本文针对的微博文本信息对企业微博转发效果影响因素进行了研究,着重突出了微博内容的重要性,对企业制定微博营销策略有一定的借鉴意义,但仍然存在一些局限性和改进之处:
(1)对微博内容在不同类型企业中的影响因素进行研究,本文并未针对不同类型的企业进行研究,微博内容对于不同企业微博转发的影响可能存在一定的局限性。
(2)本文主要从微博内容出发,考虑对企业微博转发情况的影响,没有将用户对于内容的喜爱程度等加入到特征集合中,在后面的研究过程中,可以增加用户等方面的特征因素,使得研究的准确度更高。
(3)在分类方法的选择上,可采用多种分类算法,以期发掘出更为精准的分类器。
[1]孙泳颖.组织传播学视角下的企业新浪官方微博研究[D].复旦大学,2012.
[2]刘红光,马双刚,刘桂锋,2016.基于机器学习的专利文本分类算法研究综述[J].图书情报研究(3):79-86.
[3]Farid D M,Zhang L,Rahman C M,et al.Hybrid decision tree and naïve Bayes classifiers for multi-class classification tasks[J].Expert Systems with Applications An International Journal,2014,41(4):1937-1946.
[4]Farid D M,Rahman M M,Almamuny M A.Efficient and scalable multi-class classification using naïve Bayes tree[C].2014.
[5]Jiang L,Li C,Wang S,et al.Deep feature weighting for naive Bayes and its application to text classification[J].Engineering Applications of Artificial Intelligence,2016,52(C):26-39.
[6]Kim E,Sung Y,Kang H.Brand followers'retweeting behavior on Twitter:How brand relationships influence brand electronic word-ofmouth[J].Computers in Human Behavior,2014,37(C):18-25.
[7]Suh B,Hong L,Pirolli P,et al.Want to be Retweeted?Large Scale Analytics on Factors Impacting Retweet in Twitter Network[C].2010.
[8]赵蓉英,曾宪琴,2014.微博信息传播的影响因素研究分析[J].情报理论与实践(3):58-63.
[9]Bolón-Canedo V,Sánchez-Maroño N,Alonso-Betanzos A.Feature selection for high-dimensional data[J].Progress in Artificial Intelligence,2016,5(2):65-75.
