密集帧率采样的视频标题生成*
2018-06-19汤鹏杰谭云兰李金忠
汤鹏杰,谭云兰,李金忠,谭 彬
1.井冈山大学 数理学院,江西 吉安 343009
2.井冈山大学 流域生态与地理环境监测国家测绘地理信息局重点实验室,江西 吉安 343009
3.同济大学 计算机科学与技术系,上海 201804
4.井冈山大学 电子与信息工程学院,江西 吉安 343009
1 引言
视频标题生成是根据一段给定的视频,使用文字的形式将其主要内容重新表述出来,生成人们能够理解的自然语言语句。它在人机智能交互、视觉功能障碍者辅助、视频过滤与检索等领域具有极大的应用价值[1-2]。但由于视频数据量大,需要应用多种计算机视觉技术和自然语言处理技术,其数据处理流程复杂,具有较大的挑战性。不同于静态图像的标题及描述生成模型,视频的长度难以固定,且视频中各帧之间具有时序性和结构性,因此生成视频标题需要考虑更多的影响因素。
在前期的工作中,人们倾向于使用基于模板的方式生成标题,如因子图模型(factor graph model,FGM)[3],它首先在视频中获得主题、动作、物体及场景(S,V,O,P)的置信度信息,然后结合使用因子图从语言模型中得到的置信度,进而推导出最合适的(S,V,O,P)元组,生成视频标题。随着深度学习在视觉领域的快速发展,尤其是卷积神经网络(convolutional neural network,CNN)的大规模应用[4-8],人们也开始将其应用在视频标题生成这一领域。其基本流程为提取视频帧的CNN特征,然后将其作为一个整体,使用马尔科夫随机场(Markov random field,MRF)或者长短时记忆(long short term memory,LSTM)网络逐个生成单词。由于CNN特征的表达能力更强,LSTM网络生成句子更加灵活,将CNN和LSTM模型相结合已经成为解决该问题的主流方法[1-2,9-12]。
在以往的方法中,人们通常采用间隔固定时间采样视频帧的CNN特征[1]或者对所有视频帧的CNN特征进行平均的方法[9]。取固定时间间隔的视频帧CNN特征能够降低模型的复杂度,减少处理时间,同时也保证了数据的稀疏性,系统鲁棒性较强。但间隔采样的方法,尤其是较长的时间间隔,极有可能导致视频中很多重要信息丢失,造成生成的标题中用词不准确,语义信息较弱。而使用将所有视频帧的CNN特征进行平均的方法则保证了视频中的所有信息都能够参与最终的决策。但由于它将所有的CNN特征进行了均值运算,使得最终特征缺乏更强的可辨别能力;同时其均值运算也使得特征失去了视频的运动信息,最终导致系统对视频中物体、动作及场景的检测准确率低,生成的句子与参考句子相比具有较大误差。
结合两种方法的优缺点,本文考虑以S2VT(sequence to sequence-video to text)为基础,设计了密集帧率采样标题生成模型(dense frame rate sampling based captioning model,DFS-CM)。不同于原有的间隔固定时间取帧,然后将其CNN特征直接送入LSTM网络的方式,本文在一定的时间间隔内提取所有视频帧的CNN特征,然后对其进行均值或最大值运算,得到固定时间间隔的均值或最大值特征;接下来将所有均值或最大值特征作为新的时间序列,按顺序送入LSTM网络,对视频特征进行“编码”,捕捉运动信息;在一定的时间步内,由LSTM输出的向量即为该视频最终的特征向量,然后在后续的时间步中,将其送入同一个LSTM网络进行“解码”,根据视频特征生成相应的句子。本文模型既能保证视频中静态和动态信息的完整性,又能降低对所有帧的CNN特征进行均值或最大值运算所造成的特征可辨别能力受损及信息丢失对性能的影响。
2 相关工作
视频标题生成系统使用了计算机视觉和自然语言处理中的多种技术,处理流程较为复杂。本文首先介绍所使用的CNN、LSTM技术,然后对与本文相关的视觉内容描述进行说明。
2.1 CNN技术
CNN技术通过使用大量的卷积核对图像进行滤波,不同的卷积核具有不同的权重,因此图像经过每个卷积核变换后,都可认为是其一种特征,将多种特征融合在一起,得到的特征更加全面;同时,CNN模型还使用多种非线性变换技术,提高特征的抽象性,增强其表达能力和可辨别能力,如修正线性单元(rectified linear unit,ReLU)、参数化修正线性单元(parameter rectified linear unit,PReLU)[13]等;此外,它还使用池化技术,如均值池化(average pooling)、最大值池化(max pooling)等,以降低参数规模和运算复杂度,同时增强特征的稳定性,适应物体可能的多种形变。
目前,已出现多个经典的CNN模型,如早期的LeNet5模型[14]、引领深度学习热潮的的AlexNet模型[4],以及近期的 VGG16/19[15]、GoogLeNet[5]和 ResNet模型[6]等,它们在计算机视觉的多个领域内被广泛应用,如图像和视频的分类与识别[4-6,15]、目标检测与追踪[8]、图像分割[7]、图像及视频描述[1-2,9-12,16-19]等。在GooLeNet模型中,Szegedy等人共使用6个“Inception”模块,深度达到22层;在每个“Inception”模块中,同一层中使用多个卷积层对不同尺度的特征进行聚类,并经过多层线性和非线性变换,增强特征的表达能力;由于使用了更小的卷积核,其参数规模更小。在ILSVRC2014中,该模型赢得了分类比赛的冠军。He等人则认为在模型加深后,其有效消息可能会逐渐丢失,使得训练变得困难。为此,他们引入了“残差(residual)”的概念,使用“跳层(short cut)”的方式将上层输出与当前层输出逐元素求和之后送入下一层。使用残差机制,他们开发了ResNet-152模型,其深度达到152层,获得了ILSVRC2015分类和目标检测两项比赛的冠军。虽然ResNet模型层次更多,但由于也采用了小卷积核技术,其参数规模仍然比VGG16/19更小。鉴于GoogLeNet和ResNet模型中参数较少,且性能优越,本文采用了这两种模型对视频帧提取CNN特征。
2.2 LSTM模型
对于具有时间序列的数据,常采用循环神经网络(recurrent neural network,RNN)来进行处理。RNN是一个神经单元,在不同的时间步上输入时间序列数据,通过跨时间的反向传播算法(back propagation through time,BPTT)对参数进行更新优化,使得网络具有一定的记忆功能。但RNN中采用了Sigmoid和Tanh激活函数,使得梯度消失(gradient vanish)和梯度爆炸(gradient explosion)现象较为严重,造成后续时间步上的节点难以记忆较长时间的信息,难以解决“长期依赖(long term dependency)”问题[20]。
LSTM模型在RNN的基础上增加了包括输入门(input gate)、遗忘门(forget gate)和输出门(output gate)在内的多个控制门。同时,通过增加记忆单元保存状态信息,使得梯度回传时能够根据需求到达特定的时间步,对该时间步上的参数进行更新,解决了RNN中所存在的问题[21]。目前,也出现了多个LSTM的变种模型,如Gated RNN Unit(GRU)[22]、Depth Gated RNN[23]、双向LSTM[24]等。为了便于对比,本文仍然使用经典的LSTM单元建立视频特征“编码”模型和语言模型。
2.3 视觉内容描述
视觉内容描述将视觉信息转换为自然语言重新表达,是一个从具体到抽象,又到具体的过程,它属于视觉信息理解中的高层任务,是理解视觉内容并跨越语义鸿沟的必经过程。目前,已有大量关于视觉内容描述的工作,主要集中于图像描述生成任务[16-19,25]和视频描述生成任务[1-2,9-12]。
其中图像描述生成流程较为简单,它不考虑运动信息,使用CNN模型提取深度特征,然后将其送入LSTM进行“解码”,生成句子即可。为了提高生成句子的准确度,丰富语义信息,人们也结合了多种视觉和自然语言处理技术,设计了多种生成模型。如Karpathy等人提出了基于局部区域的CNN模型RCNN(region based CNN)和双向LSTM的多模LSTM语言生成模型[19];Xu等人将自然语言处理的注意力机制应用到图像描述生成上,并结合CNN和LSTM技术,提出了Soft-Attention和Hard-Attention模型[18];此外,Wu等人从图像内容属性出发,使用多标签分类及迁移学习技术,设计了基于属性的生成模型,改善了生成句子的质量[25]。
视频内容描述不仅要考虑每帧中所出现的事件、物体及场景,还需要考虑前后多帧之间的关联,其数据信息更为庞大、复杂,较静态图像描述任务更具挑战性。Venugopalan等人使用深度CNN模型提取出视频中所有帧的CNN特征,然后求取所有特征的对应位置的平均值,作为该视频的特征向量,并在每个事件步上将其与前述已生成单词的嵌入式向量共同组成多模特征送入LSTM网络,生成视频标题和描述[9]。这种方法充分利用了深度CNN特征较强的抽象能力和表达能力,并使用多模特征对LSTM进行训练优化,最终生成更加灵活、语义信息更加丰富的句子。但它过于简单粗暴,将所有帧的特征进行均值运算,完全忽视了视频的运动特征,其本质仍然是采用静态图像描述的思路。为解决这一弊端,Venugopalan等人又提出了S2VT模型[1],它采取稀疏采样的方法,每隔固定帧数(10帧)提取一帧的CNN特征,然后将其按时间顺序送入LSTM网络中,由LSTM建立视频的动态特征,同时对视频进行“编码”;然后同样使用LSTM网络对“编码”后的特征向量进行“解码”,生成句子。S2VT考虑了视频的运动特性,消除了只使用均值方式所导致的缺乏运动信息的缺陷。但S2VT模型采取稀疏取帧的方式,虽然能够提供一定的正则化信息,增强系统的鲁棒性,但也丢失了很多细节信息,特别是在对象快速运动的情况下,可能使得最终特征错过部分物体及场景信息。
此外,Yao等人则采用注意力机制定位时序位置,并使用三维卷积提取视频特征,取得了较好的效果[11]。Pan等人首先将整个视频分为多个长度固定且统一的片段,使用三维卷积的方法对每个片段提取三维卷积特征,对所有卷积特征进行均值运算;然后使用LSTM网络建立语言模型,结合视频的均值特征生成视频标题[2]。使用三维卷积提取视频的视觉特征可解释性好,符合人们的理解习惯,不仅对帧内的物体、场景等信息做了深度计算,而且也对帧间的运动特征做了深度描述。但三维卷积运算量大,同时大量的实验表明,无论是在传统的视频动作识别,还是在视频标题生成领域,其性能和其他方法相比并不优越。
对比以上工作,本文以S2VT结构为基础,提出了基于密集帧率采样的模型,使得视频中的所有帧均参与运算过程,舍弃了间隔取帧的方式,防止某些关键帧中静态信息和动态信息的丢失,使特征表达能力更强。本文模型在限制复杂度的基础上,进一步改善了模型性能,提升了生成标题的质量。
3 密集帧率采样标题生成模型
3.1 模型原理
3.1.1 问题及方法概述
视觉特征是各种视觉信息理解任务的基础,同时,不同的视觉任务对特征的要求也不尽相同。对于视频而言,在数据表现上,它具有数据量大、数据冗余度高的特点;在高层语义方面,它是现实世界中一个片段,每帧之中涵盖了物体、动作、场景及位置关系等多种静态视觉信息,各帧之间则表现了物体运动、动作发生、场景切换及位置变化等多种运动信息。在人们的日常生活中,它承载着文化传播、还原现实等多种功能,已成为文明社会不可或缺的一部分。自然语言首先是对现实世界的抽象或推理,然后通过一定的语法规则将各种语料重新组织起来,对现实世界或相关推理进行描述。使用自然语言对视频中的内容进行重新表达是人类智力活动的一种,其本身对人类的语言表达能力具有一定的挑战性,它不仅要求能够将视频中的主要物体、动作和场景等视觉内容进行准确的表达,还要求对整个视频内容进行总结。使用计算机来完成这一过程,首先需要机器提取视频及语言中的多种特征,降低数据量,提升模型的泛化能力;然后将特征送入语言模型进行训练和测试。
本文首先使用深度CNN模型提取视频中每帧的特征,保证模型能够捕捉视频中的物体、场景及动作等静态信息;然后固定取帧长度,将长度内所有帧的CNN特征进行均值运算或取最大值运算,不仅保证了视频中所有帧的信息能够参与计算,而且还降低了数据量和复杂度,使得数据具有一定的稀疏性,便于提高模型的泛化能力。为提取视频中的运动信息,将所有取均值或最大值后的CNN特征送入LSTM模型,保证每个时间步上输入视频一段时间的CNN特征,由LSTM网络记忆时间序列信息,对运动特征进行描述。上述过程属于对视频进行“编码”的阶段,主要用于提取视频中的各种特征。在使用CNN提取特征之前,首先使用ImageNet大规模数据集[26]对CNN模型参数进行优化,防止模型陷入过拟合状态;然后在静态图像描述数据集MSCOCO[27]上使用该CNN模型和LSTM网络进行联合训练,对CNN模型参数进行微调,训练模型对自然语言的结构及常用词汇更为敏感,使之适应句子生成的任务。
在训练阶段,得到视频的特征向量之后,将其和相关参考句子中相应词汇的特征向量结合在一起,送入LSTM网络中特定的时间步,对其中的参数进行训练优化;在测试阶段,将视频特征向量和LSTM前一时间步上所输出的单词特征向量融合在一起,送入LSTM当前时间步,输出当前单词;最后将所有时间步上输出的单词结合在一起,组成视频的描述句子。
3.1.2 形式化描述
设V={V1,V2,…,Vn}表示视频集合,S={S1,S2,…,Sn}表示相应视频的参考句子集合,f(∙)表示系统函数,则对于某个视频(如第i个视频Vi),整个模型可表示为:

其中,V表示在训练集上生成的词汇集合(字典)。
在训练阶段,将整个模型分为四部分:第一部分为在ImageNet数据集上对CNN模型进行预训练,防止模型在训练样本较少的图像描述和视频描述数据集上陷入过拟合。第二部分为在静态图像描述数据集MSCOCO再次对CNN模型进行预训练微调,使得模型能够捕捉更多关于句子结构和相关词汇的先验信息;本部分使用视觉模型和语言模型联合训练的方式,即CNN模型和LSTM语言模型共用目标函数,防止模型陷入局部最优状态。第三部分为特征处理部分,首先使用迁移学习的方法将预训练模型中的参数迁移至视频描述任务,然后使用这些参数提取所有视频帧特征,最后对特征进行固定间隔时间均值或最大值计算。第四部分则为在视频描述数据集上进行训练,主要是优化对视频特征进行编码的模型和语言模型,本部分也是采用LSTM网络来进行。设L1pre、L2pre和Lv-lm分别表示第一部分、第二部分和第四部分的损失函数,则整个系统的损失函数可表示为:

设为ImageNet训练集中的图像集合,n1表示其样本数量表示图像对应的标签集合,表示CNN 模型函数。在ImageNet上,子模型可表示为式(2):

其中,R 表示实数域;Z 表示整数集。
在优化时,使用交叉熵函数作为代价函数,并使用随机梯度下降算法对参数进行更新,其损失函数为:
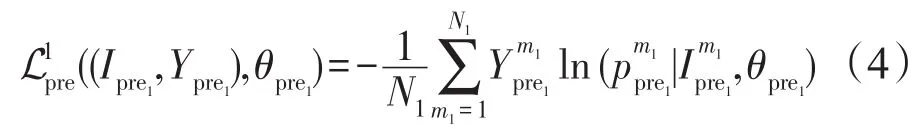
其中,N1表示一次迭代中所使用的训练样本数量;表示第m1张图像的真实标签为经过模型变换后得到的第m1张图像的概率分值;θpre1是CNN模型的参数集合。在实际操作中,除求取所有图像交叉熵的均值外,还应该包含正则化项。
在第二部分,设表示MSCOCO数据集中的训练图像集合,n2表示图像样本数量,Spre表示每张图像所对应的参考句子集合,可表示为:
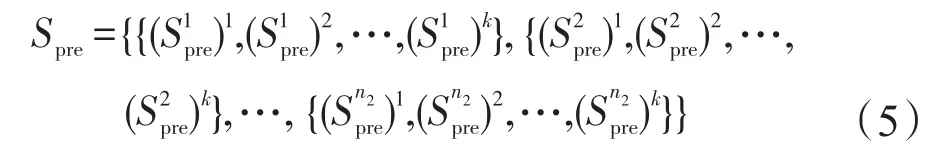
其中,k表示在MSCOCO数据集中每张图像对应的参考句子条数,k=5,即每张图像包含5条参考句子;在每条句子中,设表示第j张图像所对应的第r条参考句子中词汇的集合;ljpre表示该条句子的长度。该部分的损失函数可表示为:
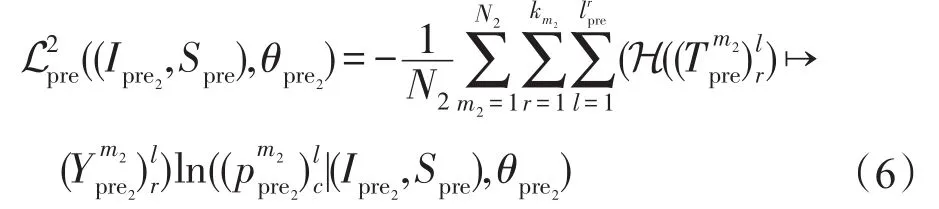
其中,N2表示一次迭代中所使用的训练图像样本数量表示CNN模型和语言模型中的参数集合;H(∙)为变换函数,它将词汇映射为在单词表中的对应标签表示在第l个时间步上所输出的候选单词的概率分值。
当模型MSCOCO数据集上收敛之后,取模型的前半部分CNN模型,将其参数迁移到视频描述任务中,用于提取视频帧的CNN特征。设第i个视频所有帧的CNN特征集合为其中ln3v表示该视频长度(总帧数)。对于每帧特征可使用下式计算得到:

式中表示视频的第t帧。得到视频中所有帧的CNN特征后,对于t时刻点,使用下式计算固定时间间隔均值或最大值特征:
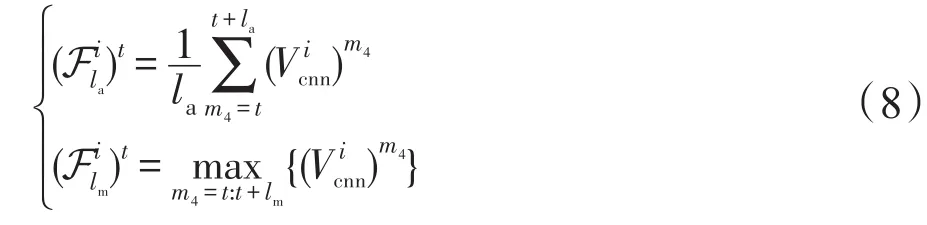
其中,la和lm表示时间间隔长度,本文设置分别表示均值计算(average computation)得到的特征和最大值计算(maximum computation)得到特征;表示取最大值函数。
得到视频的固定间隔时间的均值特征或最大值特征后,需要由第四部分建立视频的运动特征模型和语言“解码”模型。本文使用同一个LSTM网络建立该模型,前半部分用于特征“编码”,后半部分用于构建语言模型。其损失函数与第二部分类似,可表示为式(9):
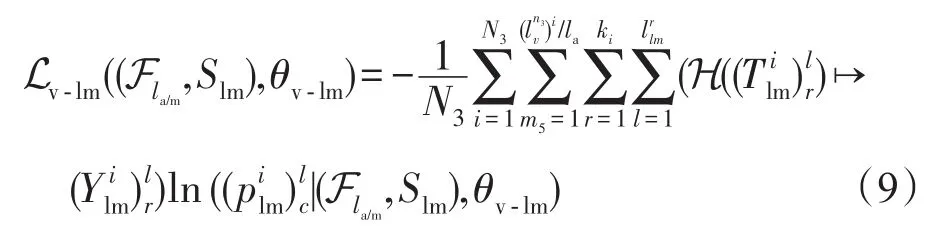
其中为视频集合固定间隔时间均值特征或最大值特征集合,n4为训练视频样本总量;视频集合中,第m5个视频片段特征由集合所构成;Slm为训练句子的集合,对于某个视频来说,其所有均值或最大值特征均对应其相应的句子;θv-lm为模型参数集合;N3为一次迭代中所使用的视频数量;为第i个视频的总长度(总帧数);ki表示该视频所对应的参考句子条数;为第r条参考句子的长度(词汇个数)用于表示第i个视频中第r条参考句子的第l个单词;为该词汇在词典中的位置标签;表示在该时间步上(第l个时间步)所输出的概率分值。
由以上各部分可知,系统的目标为不断优化更新参数集合θ={θpre1,θlmpre,θv-lm},使得 L最小。因此,其目标函数可记为:
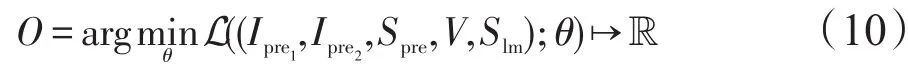
在测试阶段,只有视频及其提取的CNN特征,语言模型中没有参考句子的输入。因此,使用“BOS”作为开始符号,和视频特征一起送入语言模型,在当前时间步上生成第一个单词;然后将该单词作为下一个时间步的输入,以此类推,逐个生成单词,直到生成“EOS”结束符为止。在具体生成单个词汇时,其输出为使用Softmax函数所生成的概率分值,在当前时间步上取所有概率分值中最大者所对应的单词作为当前生成的词汇,即:wl=max1:|V|{(plm)l}↦ V1×|V|(11)其中,wl表示在第l个时间步上生成的单词;V表示词汇表;|V|表示词汇表的大小;{(plm)l}表示第l个时间步上的所有概率分值集合。
3.2 模型结构
如图1所示,首先将整个视频分成固定长度的片段(当视频尾部长度不足时,使用空白帧填补,使得la/m固定);接下来使用在ImageNet和MSCOCO两个数据集上优化完毕的深度CNN模型提取所有视频帧的特征,然后使用均值运算或最大值运算的方法,对固定片段中的特征进行进一步处理,生成的特征向量维度与原视频帧的特征向量维度相同。得到视频的固定时间间隔的均值或最大值特征以后,本文以S2VT框架为基础,构建两层LSTM网络,在(1:t1)时间步上,使用第一层LSTM网络依次接收上述步骤所生成的均值或最大值特征,对于第二层LSTM,则直接使用空白特征(0向量特征)填补;当把所有的视频特征送入LSTM后,由LSTM生成视频的唯一特征向量,在t1+1时间步上,和空白特征一起送入第一层LSTM网络,其输出和“BOS”一起送入第二层LSTM网络中,由第二层LSTM网络对特征进行“解码”。
在将视频特征送入LSTM网络之前,需要对特征进行降维,一般使用全连接层将高维特征变换为维度较低的特征向量。而在单词输入到LSTM网络之前,需要使用独热码(One-hot)对单词进行编码,再使用全连接层得到单词的嵌入式向量,然后和“编码”后的视频特征向量一起送入LSTM单元。在输出时,使用全连接层将特征映射到词汇表上,取其响应最大者作为当前时间步上的单词。
4 实验结果及分析
本文4.1节介绍了验证模型所使用的数据集,对数据集的基本情况和使用规则进行了描述。4.2节对实验模型的基本设置进行了说明,包括基准模型设计、输入特征情况、所提模型的配置、训练时的部分参数及软硬件环境等。4.3节介绍了本文所使用的评价标准。4.4节给出了实验结果及其相关分析。
4.1 数据集
本文主要使用Youtube2Text数据集[28]对模型进行验证。该数据集取自于Youtube网站,总共包含1 970段视频,每段视频描述了一件事或一个动作。其中每段视频都对应数十条人工标注的句子(条数不固定);按照使用规则,取1 200段视频及其参考句子用于训练,100段视频和参考句子用于验证,最后的670段视频及对应的参考句子用于测试。本文采用文献[1-2]中所使用的词汇表,其大小为46 167。
4.2 实验设置
本文以S2VT框架为基础,但和S2VT不同,文中不使用视频的光流特征,只使用原始的视频帧作为系统输入。其原因是光流特征是提取视频中的运动特征,而依次将视频帧特征输入LSTM进行编码,其本身也是为了捕捉视频的运动特征,因此没有必要对运动特征重复提取。而实验结果也表明,使用光流特征的方法效果并不理想。为了降低模型复杂度,提升模型性能,本文使用了GoogLeNet模型和ResNet-152模型提取视频帧的CNN特征,使用其最后的池化层特征作为输入,最终特征维度为1 024和2 048;在视频特征输入LSTM之前,使用全连接层对特征进行降维,输出维度设置为1 000;使用两层LSTM,每层LSTM的输出单元也设置为1 000,时间总步长为t2=80;在全连接层、LSTM层等两层之间,使用Dropout技术,防止模型陷入过拟合,其舍弃比率(dropout ratio)设置为0.5。在基准模型中,本文遵循文献[1]中的做法,对每段视频按照每隔10帧取一帧的方式对视频进行采样,然后使用GoogLeNet和ResNet-152提取CNN特征,并将其按顺序送入上述LSTM网络中。而在本文所提模型中,对视频进行密集采样,取出所有视频帧,然后设置la/m=10,即每隔相邻10帧做一次均值或最大值运算。其他设置与基准模型相同。
在模型训练时,设置最大迭代次数为110 000次;使用随机梯度下降算法,其Batch_size设置为32;初始学习率设置为0.01,使用逐步下降的方式,调整学习率,调整步长(step size)为30 000,调整速度为0.5。由于LSTM网络中采取梯度累加的方式,为防止梯度爆炸,需要对梯度值进行裁剪,其缩放因子设置为10。
本文采用目前流行的Caffe深度学习框架开发部署各个模型,使用了NVIDIATITAN X高性能显卡进行运算,加速模型收敛。提取视频各帧的CNN特征后,在Matlab R2015平台上计算特征的均值和最大值;同时部署了Python3将处理后的特征及其相关参考句子转换为HDF5文件,加快训练数据的读取速度。
4.3 评价标准
本文使用主观评价和客观统计评价两种评价方法。在主观评价中,通过观察视频内容及参考句子,判断生成句子的语义及合理性。在客观评价方面,使用了 BLEU(bilingual evaluation understudy)[29]、METEOR(metric for evaluation of translation with explicit ordering)[30]、ROUGE_L(recall oriented understudy for gisting evaluation)[31]和 CIDEr(consensusbased image description evaluation metric)[32]4种较为流行的方法。其中BLEU方法以n-元组(n-Gram)为基础,计算所有参考句子与生成句子之间的匹配程度,n越大,BLEU值越高,说明生成的句子单词正确率越高,句子连贯性越好(为便于表示,本文使用B@1、B@2、B@3、B@4分别表示1-Gram、2-Gram、3-Gram和4-Gram下的BLEU值)。METEOR方法同时考虑了正确率和召回率,通过计算正确率和召回率调和均值的方法得出数值,同样其值越高,说明生成的句子质量越高(为便于说明,本文使用“M”表示METEOR)。ROUGE_L方法也是基于n-Gram方法,但它使用了最长公共子序列的概念,不要求词汇的连续匹配,同样也不需要事先指定n的大小,其值越高,说明生成的句子越贴近人工标注的句子(本文使用“R”表示该指标)。以上3种方法在反映生成句子的正确度及连贯性等方面具有一定的优势,但在反映句子的语义信息的丰富程度方面则有所欠缺。CIDEr评价方法提出使用“人类共识”的概念,它通过为n-Gram赋予一定的TFIDF权值,计算候选句子与生成句子之间的余弦距离,以此表明匹配程度,其值越高,说明生成的句子与参考句子集合之间相似度越大,语义信息越丰富(本文使用“C”表示该指标)。
4.4 实验结果及分析
为视频生成的标题或描述,其服务对象是人类,目的是满足人们的需求,因此最终评价标准也是人的主观评价。4.4.1小节列出了部分采用本文模型为视频所生成的候选句子,对比了其与人工标注句子的区别,并分析了候选句子的质量。但不同人群具有不同的语言表达和接受习惯,因此主观评价易产生偏差,只能部分反映生成句子的质量,且在大规模视频标题生成任务中,人工评价耗时较长。4.4.2小节使用多种客观评价标准对模型进行了更加全面的评测。
4.4.1 生成句子及分析
如图2所示,本文列举了部分模型生成的视频标题(使用ResNet-152模型提取视频的CNN特征),同时也列举了部分参考句子,{R1,R2,R3,R4,R5}表示参考句子集合,{C}表示生成的句子集合。通过对比可以发现,在多数情况下,由本文模型所生成的句子准确度较高,连贯性较好,且语义信息非常丰富。如在第一段视频中,所生成句子质量甚至要高于多条参考句子(如R2、R4),不仅指明了所操作的对象(tomato sauce),还说明了其盛放的工具(can),而在R2和R4中,则并没有提到这一重要信息;同时生成的句子还指出了另一个操作对象(pot)所在的位置(on the stove),这是其他所有参考句子中都没有出现的内容。在第三段视频中,本文模型也准确地生成了视频的标题,较好地描述了视频中所发生的事情。
同时也需注意到,本文模型所生成的标题还同样存在着检测不准确及缺乏描述灵活性的问题。如在第二段视频中,生成的句子中出现了视频中本没有的内容(leg),在所有的参考句子中也并没有这一名词出现;而且在语义上,和参考句子相比也有所欠缺,如R1中所出现的“狗回追猴子(and is chased by dog)”、R3中出现的“戏弄(teasing)”等。同样地,在第四段视频中,其生成的句子虽然也较好地反映了视频中所发生的事情(playing with each other),但在检测对象上,和视频内容之间出现了较大偏差,不仅将“狮子(lion)”错误地认成了“小狗(puppy)”,还将数量(three)做了错误的判断(two)。出现这一问题的原因可能是在使用LSTM对视频特征进行“编码”时,虽然捕捉了运动信息,但失去了很多帧内的静态信息,导致检测对象出现了误差。
4.4.2 统计结果及分析
为更加全面而客观地评价本文模型,采用了BLEU、METEOR、ROUGE_L和CIDEr共4种自动评测方法对模型进行评价。首先,构建了基准模型(benchmark model),借助S2VT框架,使用GoogLeNet和ResNet-152模型在ImageNet和MSCOCO数据集上对其进行训练优化;然后在视频上每隔10帧提取一次CNN特征,将其送入LSTM进行“编码”和“解码”。
此后,将本文所提模型DFS-CM(包括均值方式和最大值方式)和基准模型在Youtube数据集上进行了性能对比。结果如表1和表2所示,其分别为使用GoogLeNet和ResNet-152两种CNN模型作为特征提取器得到的结果。通过对比可以发现,无论是采用GoogLeNet还是ResNet-152模型特征,使用均值方式和最大值方式,其结果总体上都要好于基准模型。尤其是在反映句子连贯性和语义丰富程度的B@4和CIDEr指标上,在使用GoogLeNet特征和均值方式时,在基准模型的基础上提升了1.4%和2.1%;在使用GoogLeNet特征和最大值方式时,其值分别提升了1.9%和5.7%,效果更加明显。在使用ResNet-152模型特征和均值方式时,B@4和CIDEr比基准模型分别提升了1.2%和0.5%;而使用最大值方式时,则分别提升了1.1%和0.9%。但在METEOR指标上,DFSCM模型优势并不明显。
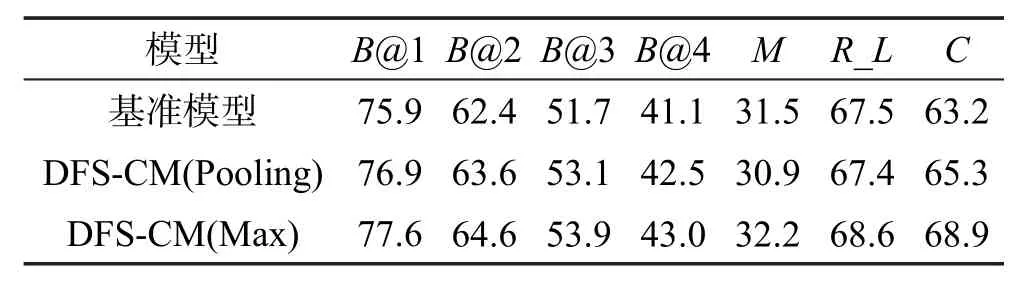
Table 1 Performance comparison with GoogLeNet feature表1 GoogLeNet特征下的模型性能对比 %
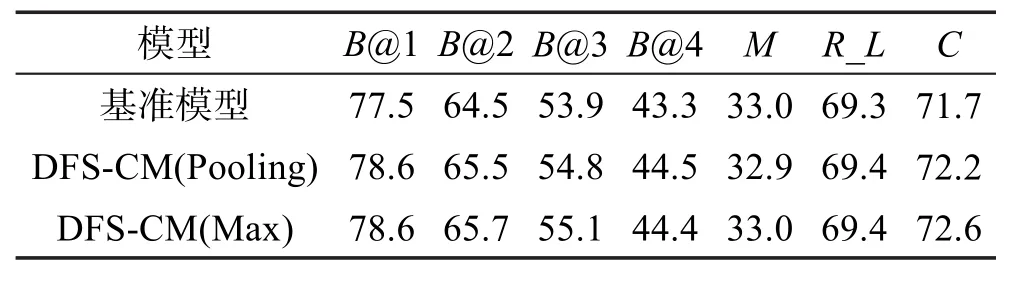
Table 2 Performance comparison with ResNet-152 feature表2 ResNet-152特征下的模型性能对比 %
此外,本文还使用了启发式集束搜索(beam search)方法生成候选句子,其集束池大小统一设置为5。各模型在GoogLeNet特征和ResNet-152特征下的实验结果分别如表3和表4所示。从统计数据可以看出,使用集束搜索后,基准模型和本文所提DFSCM模型性能均有了极大提升。在使用GoogLeNet模型特征时,无论是均值方式还是最大值方式,其模型性能在各个指标上均有所提升。如在B@4上,两种方式的性能均提升了4.5%,在CIDEr上分别提升了6.5%和8.5%,在METEOR和ROUGE_L上也表现良好。而在使用ResNet-152模型特征时,在BLEU指标上,本文模型两种方法的性能也均超过了基准模型,但在其他指标上,表现欠佳。
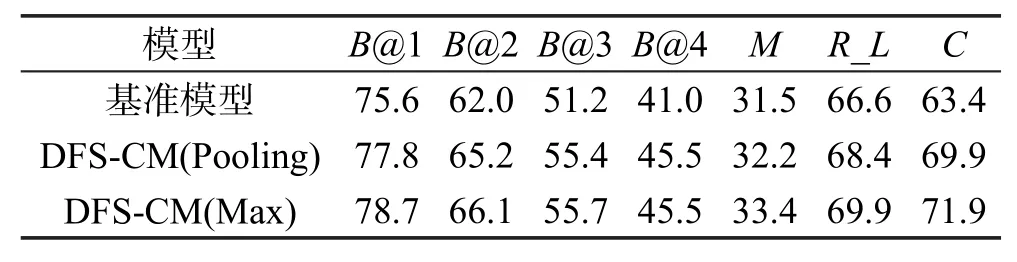
Table 3 Performance comparison with beam search(GoogLeNet feature)表3 集束搜索下的模型性能对比(GoogLeNet特征)%
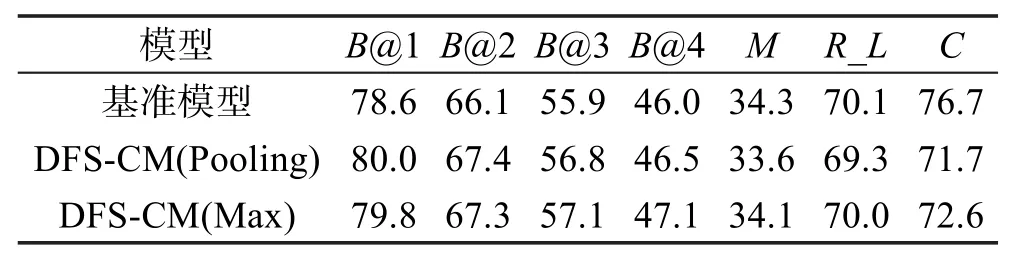
Table 4 Performance comparison with beam search(ResNet-152 feature)表4 集束搜索下的模型性能对比(ResNet-152特征)%
通过对比也可以发现,在本文模型所使用的两种特征处理方法中,无论是使用集束搜索还是不使用集束搜索,使用最大值方式的模型性能在总体上要好于使用均值方式的模型。其可能的原因是,使用最大值方式能够保留更多对词汇的响应信息,且能够保持数据的稀疏性,提升了模型的泛化能力。
本文还将所提模型与目前其他主流方法的性能进行了对比,结果如表5所示。可以发现,本文模型在所有指标上均超过了其他所列方法。在使用GoogLeNet模型特征时,其B@4指标达到了45.5%,超过了最高的LSTM-E模型;在METEOR指标上达到了33.4%,超出最高的HRNE模型0.3%。在使用ResNet-152模型特征后,其B@4和METEOR则达到了47.1%和34.1%,分别超过以上两种方法1.8%和1.0%。在B@1、B@2、B@3指标上,本文模型同样表现优越。
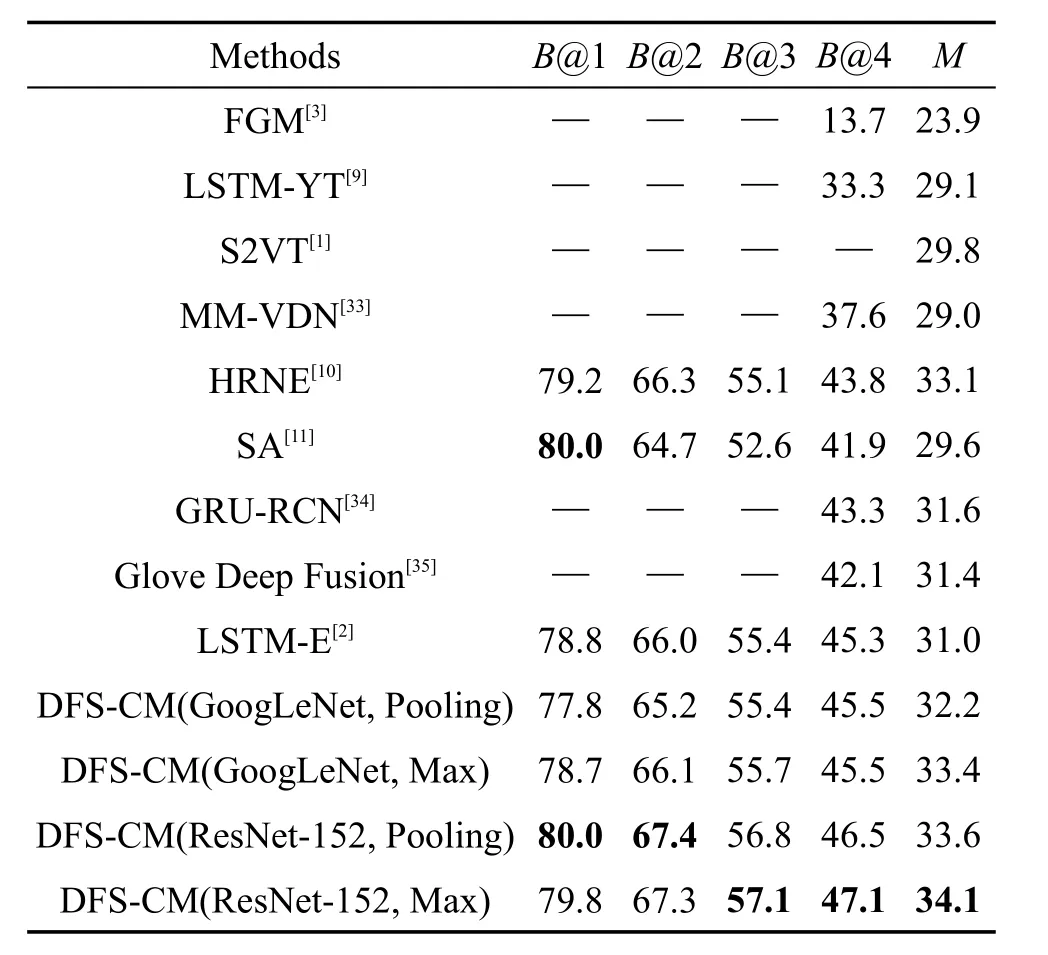
Table 5 Performance comparison between DFS-CM and other popular state-of-the-art methods表5 DFS-CM模型与其他主流方法的性能比较 %
5 结论及下一步工作
视频标题生成任务应用广泛,但由于需要使用多种计算机视觉技术和自然语言处理技术,流程较为复杂,具有较高的挑战性。随着深度学习技术在多个视觉领域中取得突破性进展,人们也开始将其应用在视频标题生成领域中,获得了良好的效果,性能超过了传统基于手工特征的模板填充方法。目前,基于深度CNN模型和LSTM相结合的框架已经成为解决该问题的主流,针对当前方法中存在的视频数据采样不足而导致的信息丢失问题,本文提出了一种使用固定间隔时间特征均值或最大值的方法,在S2VT模型的基础上,使用了性能更加优越的GoogLeNet和ResNet-152深度CNN模型,并改善了模型优化策略,进一步提升了模型性能,提高了生成句子的质量。但通过实验结果也发现,本文方法还存在着生成句子准确度不够,表达不够灵活,语义仍待提升的问题。因此,下一步工作将使用更多的视觉技术,如目标检测、属性分类等,提升描述对象的准确度;同时也将在更大的数据集上对模型做进一步的验证,使用更多的训练数据,提高句子的表达能力和语义丰富程度。
:
[1]Venugopalan S,Rohrbach M,Donahue J,et al.Sequence to sequence-video to text[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision,Santiago,Dec 13-16,2015.Washington:IEEE Computer Society,2015:4534-4542.
[2]Pan Yingwei,Mei Tao,Yao Ting,et al.Jointly modeling embedding and translation to bridge video and language[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,Jun 27-30,2016.Washington:IEEE Computer Society,2016:4594-4602.
[3]Thomason J,Venugopalan S,Guadarrama S,et al.Integrating language and vision to generate natural language descriptions of videos in the wild[C]//Proceedings of the 2014 International Conference on Computational Linguistics,Dublin,Aug 23-29,2014.Stroudsburg:ACL,2014:1218-1227.
[4]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th Annual Conference on Neural Information Processing Systems,Lake Tahoe,Dec 3-6,2012.Red Hook:CurranAssociates,2012:1097-1105.
[5]Szegedy C,Liu Wei,Jia Yangqing,et al.Going deeper with convolutions[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,Jun 7-12,2015.Washington:IEEE Computer Society,2015:1-9.
[6]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Deep residual learning for image recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,Jun 27-30,2016.Washington:IEEE Computer Society,2016:770-778.
[7]Long J,Shelhamer E,Darrell T.Fully convolutional networks for semantic segmentation[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,Jun 7-12,2015.Washington:IEEE Computer Society,2015:3431-3440.
[8]Girshick R B,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition,Columbus,Jun 23-28,2014.Washington:IEEE Computer Society,2014:580-587.
[9]Venugopalan S,Xu Huijuan,Donahue J,et al.Translating videos to natural language using deep recurrent neural networks[C]//Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Denver,May 31-Jun 5,2015.Stroudsburg:ACL,2015:1494-1504.
[10]Pan Pingbo,Xu Zhongwen,Yang Yi,et al.Hierarchical recurrent neural encoder for video representation with application to captioning[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,Jun 27-30,2016.Washington:IEEE Computer Society,2016:1029-1038.
[11]Yao Li,TorabiA,Cho K,et al.Describing videos by exploiting temporal structure[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision,Santiago,Dec 7-13,2015.Washington:IEEE Computer Society,2015:4507-4515.
[12]RohrbachA,TorabiA,Rohrbach M,et al.Movie description[J].International Journal of Computer Vision,2016,123(1):94-120.
[13]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Delving deep into rectifiers:surpassing human-level performance on ImageNet classification[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision,Santiago,Dec 7-13,2015.Washington:IEEE Computer Society,2015:1026-1034.
[14]Lecun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[15]Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[C]//Proceedings of the International Conference on Learning Representations,San Diego,May 7-9,2015:1-14.
[16]Donahue J,Hendricks L A,Rohrbach M,et al.Long-term recurrent convolutional networks for visual recognition and description[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2017,39(4):677-691.
[17]Vinyals O,Toshev A,Bengio S,et al.Show and tell:a neural image caption generator[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,Jun 7-12,2015.Washington:IEEE Computer Society,2015:3156-3164.
[18]Xu K,Ba J,Kiros R,et al.Show,attend and tell:neural image caption generation with visual attention[C]//Proceedings of the 32nd International Conference on Machine Learning,Lille,Jul 6-11,2015:2048-2057.
[19]Karpathy A,Li Feifei.Deep visual-semantic alignments for generating image descriptions[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,Jun 7-12,2015.Washington:IEEE Computer Society,2015:3128-3137.
[20]Bengio Y,Simard P Y,Frasconi P.Learning long-term dependencies with gradient descent is difficult[J].IEEE Transactions on Neural Networks,1994,5(2):157-166.
[21]Hochreiter S,Schmidhuber J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
[22]Cho K,van Merriënboer B,Gülçehre Ç,et al.Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,Doha,Oct 25-29,2014.Stroudsburg:ACL,2014:1724-1734.
[23]Yao Kaisheng,Cohn T,Vylomova K,et al.Depth-gated LSTM[J/OL].arXiv:1508.03790,2015.
[24]Bin Yi,Yang Yang,Shen Fumin,et al.Bidirectional long-short term memory for video description[C]//Proceedings of the 2016 ACM Conference on Multimedia Conference,Amsterdam,Oct 15-19,2016.New York:ACM,2016:436-440.
[25]Wu Qi,Shen Chunhua,Liu Lingqiao,et al.What value do explicit high level concepts have in vision to language problems?[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition,Las Vegas,Jun 27-30,2016.Washington:IEEE Computer Society,2016:203-212.
[26]Russakovsky O,Deng Jia,Su Hao,et al.ImageNet large scale visual recognition challenge[J].International Journal of Computer Vision,2015,115(3):211-252.
[27]Lin T Y,Maire M,Belongie S J,et al.Microsoft COCO:common objects in context[C]//LNCS 8693:Proceedings of the 13th European Conference on Computer Vision,Zurich,Sep 6-12,2014.Berlin,Heidelberg:Springer,2014:740-755.
[28]Chen D,Dolan W B.Collecting highly parallel data for paraphrase evaluation[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics,Portland,Jun 19-24,2011.Stroudsburg:ACL,2011:190-200.
[29]Papineni K,Roukos S,Ward T,et al.Bleu:a method for automatic evaluation of machine translation[C]//Proceedings of the 40thAnnual Meeting of theAssociation for Computa-tional Linguistics,Philadelphia,Jul 6-12,2002.Stroudsburg:ACL,2002:311-318.
[30]Banerjee S,Lavie A.METEOR:an automatic metric for MT evaluation with improved correlation with human judgments[C]//Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation,Ann Arbor,Jun 25-30,2005.Stroudsburg:ACL,2005:65-72.
[31]Lin C Y,Och F J.Automatic evaluation of machine translation quality using longest common subsequence and skipbigram statistics[C]//Proceedings of the 42nd Annual Meeting of theAssociation for Computational Linguistics,Barcelona,Jul 21-26,2004.Stroudsburg:ACL,2004:605-612.
[32]Vedantam R,Zitnick C L,Parikh D.CIDEr:consensus-based image description evaluation[C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition,Boston,Jun 7-12,2015.Washington:IEEE Computer Society,2015:4566-4575.
[33]Xu Huijuan,Venugopalan S,Ramanishka V,et al.A multiscale multiple instance video description network[J/OL].arXiv:1505.05914,2015.
[34]Ballas N,Yao Li,Pal C,et al.Delving deeper into convolutional networks for learning video representations[C]//Proceedings of the International Conference on Learning Representations,San Diego,May 7-9,2015:1-11.
[35]Venugopalan S,Hendricks LA,Mooney R J,et al.Improving LSTM-based video description with linguistic knowledge mined from text[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,Austin,Nov 1-4,2016.Stroudsburg:ACL,2016:1961-1966.
