面向新闻评论的短文本增量聚类算法*
2018-06-19刘晓琳曹付元梁吉业
刘晓琳,曹付元,梁吉业+
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
1 引言
随着Web2.0技术的快速发展,民众获取新闻信息的方式已经转移到了网络媒体。互联网成为新闻的舆论源头,新闻评论成为网民自发聚集的舆论平台。新闻的议论话题虽然庞杂,但是网民对新闻的关注点却非常集中,其态度有时也表现出一致性。从新闻评论中总结出网民的观点,为政府和相关部门提供决策参考,具有非常重要的意义。因此,如何有效地从评论中发现网络舆情话题,即对新闻评论进行快速准确的聚类,是舆情分析领域面临的重要问题。
受新闻评论篇幅限制,新闻评论常以短文本的形式出现,短文本特征稀疏,描述信息能力较弱,因此很难准确提取主题信息。针对这一问题,通常的做法是对短文本进行语义概念扩展和关联[1]。一种有效的方法是借助外部资源,比如语义词典等[2],对短文本进行语义扩充,丰富短文本的特征语义,但这种方法严重依赖于知识库的质量,计算量大,计算复杂度高[3-4]。另一种方法是使用基于关联规则的频繁词集文本表示模型,在大规模语料中,如果两个词经常共同出现在文本同一窗口单元,则认为这两个词在意义上相互关联,频繁词集反映了特征项之间的关联性,包含更多潜在语义的同时还起到降维的作用,但该模型在聚类质量上并没有得到明显改善[5]。近年来,随着主题模型的广泛使用,Blei等人在2003年提出了隐含狄利克雷分布(latent Dirichlet allocation,LDA)主题模型[6],可以深度挖掘文本内部语义知识和隐含话题[7-8],但从大量离散短文本中发现话题的效果不佳,因为大规模短文本的词数量很大,表示潜在结构矩阵的维度非常大。另外,如果只用文档的主题分布作为特征,特征粒度较粗,对于短文本的主题刻画比较模糊。
新闻评论话题发现的主要方法是对新闻评论的主题进行聚类,国内外研究者多采用基于划分的K-means聚类算法和基于层次的聚类算法对文本进行聚类[9]。李胜东等人[10]利用基于划分的K-means聚类算法实现话题监测,但是对于网络话题的捕捉,难以事先确定待划分类簇数目,不能保证聚类结果是最优解,而且K-means算法本身对噪声数据较为敏感,因此K-means算法对流数据的话题监测存在一定的局限性。Gao等人[11]利用报道内容的时间和地点信息度量文本间的相似度,基于组平均距离的凝聚层次聚类算法对大规模新闻报道进行话题监测,但层次一旦确定就不能更改,有新的数据到来时必须重新计算当前整个文本集合,无法满足实时话题监测的需求。因此,传统的聚类算法已经不能适应网络信息增量式文本挖掘的需求,适应增量式数据输入的聚类算法渐渐得到学者的广泛关注。典型的增量式聚类算法为Single-Pass算法,也是话题发现中最常用的聚类算法,其在动态聚类和速度上表现良好。该算法按数据输入的顺序每次处理一个数据,因此可以实现流式数据的增量聚类。不足之处主要表现在该算法具有输入次序依赖特性,即对于同一聚类对象按不同的次序输入,会出现不同的聚类结果。近年来,国内相关学者对此算法进行了改进,取得了不错的结果。税仪冬等人[12]提出一种周期性分类和Single-Pass聚类结合的话题识别和跟踪方法,为解决Single-Pass的顺序敏感问题,在聚类阶段引入“代”的概念,对文本不再是一次一个地输入,而是按批次添加,并且在每一批数据到来时先进行初步聚类,然后再将初步聚类结果与已有话题类簇进行Single-Pass聚类,一定程度上缓解了算法本身的缺点,但是初步聚类算法的选择会影响最终的聚类效果。
本文针对新闻评论文本表示与文本聚类两方面开展研究。首先,构建一种多特征组合的短文本表示模型,从而比较全面地包含短文本主题信息。其次,在已有研究基础上,提出一种基于待定循环策略的增量聚类算法(uncertain cyclic Single-Pass,UCSP),有效避免因文本输入顺序对聚类结果产生影响,以此整合网络上大量舆论观点,达到自动发现话题的目的。在爬取的5个腾讯新闻评论数据集上进行实验,并与传统的文本表示模型和聚类算法进行对比分析,结果表明,本文算法能更有效地提高聚类质量。
2 面向新闻评论的短文本表示模型
2.1 基于TF-IDWF特征权重向量空间模型
短文本聚类的首要任务就是将非结构化的文本数据表示成计算机容易处理的结构化数据。Salton等人提出的向量空间模型(vector space model,VSM)[13]常被应用于文本建模。现将一条新闻评论作为一个文本,该模型将文本中包含的词项作为表示文本的基本单位,将文本数据表示成向量空间中的一个向量,建模过程如下所示:
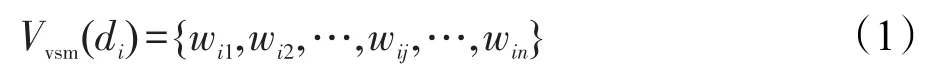
其中,Vvsm(di)为文本di的特征权重向量表示;wij表示文本di的第j个特征项tij所对应的权重,即文本话题表达的贡献度,文本的特征项互不相同,且无顺序关系;n为文本di特征项的个数。
如果将文本中所有词项作为特征项来表示文本内容,会造成特征空间维度灾难,因此需对文本进行特征选择。传统特征选择算法是Salton等人提出的TF-IDF(term frequency/inverse document frequency)[14],其主要思想为:假设某个词项在一个文本中出现的频率高,在其他文本中出现的频率低,就认为该词项对文本有较强的区分性,计算公式如式(2)所示:

其中,tfij表示词项tij在文本di中出现的绝对词频(term frequency,TF);idfij表示词项tij的倒排文档频度(inverse document frequency,IDF),常见的计算公式如式(3)所示:

其中,N表示集合中文本的总数;nj表示包含词项tij的文本数。
TF-IWF(inverse word frequency)算法[15]是在TFIDF算法的基础上由Basili等人提出的,TF-IWF算法中用特征频率倒数的对数平方值IWF代替IDF,如式(4)所示:

其中,ntj表示词项tij在文本集合中出现的次数;∑ntj表示所有词项频数之和。
事实上,两种方法在确定特征项权重时都存在不足。TF-IDF虽然表现出词项在文本中的重要程度,又能有效区别其他文本,但是IDF函数没有考虑词项在整个文本集合中分布的情况,认为词项在不同文本中出现一次和出现多次的计算效果相同,这显然不够准确。TF-IWF方法中IWF函数虽然考虑了词项在整个文本集合的分布情况,但是忽略了词项频繁出现在一个文本和稀疏出现在整个文本集合的差异,这也是片面的。因此,针对新闻评论语言特点,本文提出了一种新的计算公式,如式(5)所示:
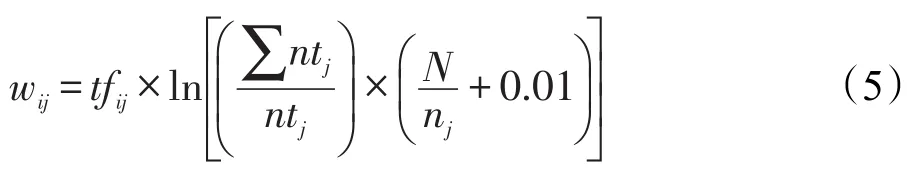
为了使不同长度的文本具有可比性,对文本长度进行归一化处理,删除文本中出现频率较低的词项,从而实现特征选择,计算公式如式(6)所示:
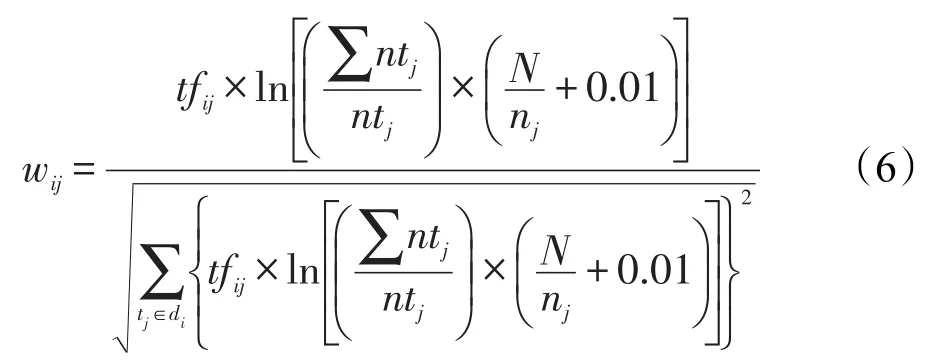
2.2 基于神经网络的文本语义词向量模型
随着深度学习的发展,基于神经网络训练的词向量模型越来越受到业界研究者的广泛关注,Mikolov等人在2013年提出了一种词向量计算工具——word2vec,作为谷歌一款基于深度学习的开源工具,word2vec利用语料库中的上下文信息,将每个词转化成一个固定维数的向量,语义越相似的词在向量空间中越相近[16]。
通过借鉴Bengio等人提出的NNLM(neutral network language model)[17]和 Hinton 等人提出的 Log_Linear模型[18],Mikolov等人提出的word2vec主要有CBOW(continuous bag-of-words model)和Skip-gram(continuous Skip-gram model)两种模型[19]。
本文首先使用2.1节提出的方法对文本建模,然后使用Skip-gram模型在大规模无标注新闻评论语料中学习特征项的语义表示,将其训练成200维实数向量,并计算每条评论的句向量,计算公式如下所示:
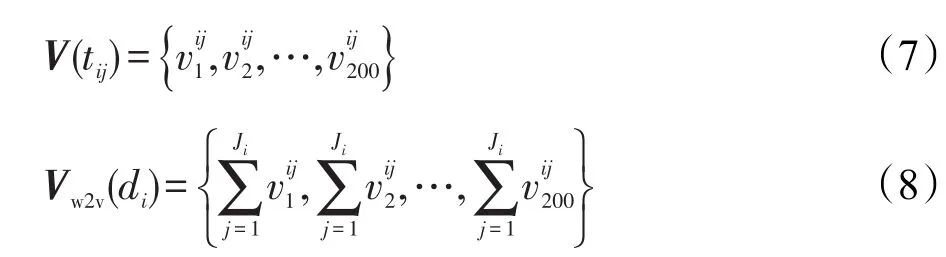
其中,V(tij)表示特征项tij的词向量;vij k(k=1,2,…,200)表示tij词向量的第k维;Vw2v(di)表示第i条评论的语义句向量;Ji表示di中特征词的个数。
2.3 基于多特征组合的短文本表示模型
由于词汇是构成句子的基本单元,受短文本篇幅所限,细粒度的词汇可以对文本信息表达产生较大的贡献,特征权重向量空间模型重点考虑词频、词性、权重等浅层信息,因此Vvsm(di)是浅层词汇级特征向量;其次,词汇所蕴含的义项对于文本的整体语义具有重要影响,利用神经网络训练得到的词向量,涵盖了特征项的语义信息,因此Vw2v(di)是深层语义级特征向量。为全面度量两个短文本之间的相似度,将两种向量表示进行组合,Vmerge(di)即多特征组合的短文本特征向量表示模型,多特征组合的短文本表示如式(9)所示:
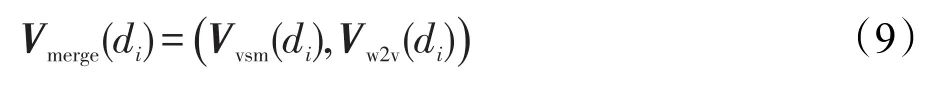
3 面向新闻评论的增量聚类算法
传统的Single-Pass算法又称单通道法或单遍法,是流式数据聚类经典算法之一。对于依次到达的数据,该算法按输入顺序每次处理一条数据,依据当前数据与已有类簇的相似度,判断该数据属于已有类或自成新类,从而实现流式数据增量聚类。传统的Single-Pass聚类算法简单,运行速度快,满足动态聚类的需求,但是对文本的输入顺序敏感。本文在传统Single-Pass聚类算法的基础上,提出了一种面向新闻评论的UCSP增量聚类算法。
噪声评论,即离群节点的错误聚类,会导致话题中心发生漂移。观点模糊评论是指介于两个类簇之间的数据,如果对这些数据进行硬划分会直接影响最终的聚类结果。噪声话题,即内部节点个数极少的少数类,一般定义所含节点个数少于所有评论总数0.25%的类簇,表明该话题不具有普遍性。本文提出的基于待定循环策略的增量聚类算法,引入待定列表机制,在聚类过程中,极大地消除由数据输入顺序对聚类结果产生的影响,同时对噪声簇进行筛选,避免新闻评论话题聚类出现类别长尾现象。
在网络舆论的形成过程中,意见领袖的影响非常重要,局部观点在意见领袖的引导下也会演化成为舆论话题,针对新闻评论这一特殊的舆论平台,意见领袖的观点往往能极大地概括网民的群体意见,也能潜移默化地影响其他网民的观点向自己靠拢,因此具有强大的观点代表性。现考虑意见领袖对话题簇的影响,将腾讯新闻评论定义的热门评论视为意见领袖,在增量聚类实现话题发现的过程中,将意见领袖权重设置为0.6,从而动态强化类簇所表达的话题。
本文使用如式(10)~(12)的3个相似度计算公式。
Vi=(vi1,vi2,…,vik,…,vin)和Vj=(vj1,vj2,…,vjk,…,vjn)表示两个向量,则两个向量间的相似度定义为:
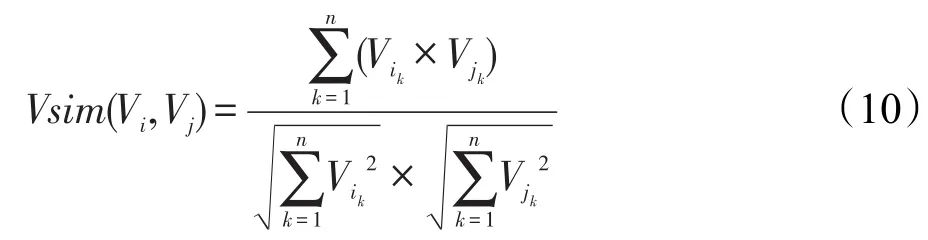
Vmerge(d)=(Vvsm(d),Vw2v(d))表示一条新闻评论,则两个短文本间的相似度计算公式如式(11)所示:
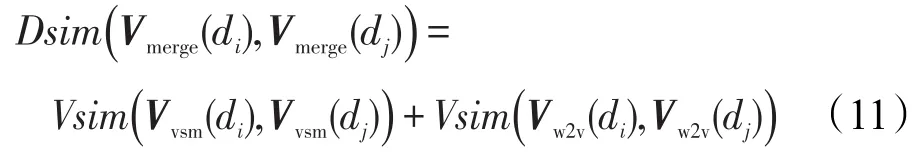
给定一个话题类ck={d1,d2,…,d|ck|},则文本di与话题类ck之间的加权平均相似度计算公式如式(12)所示:
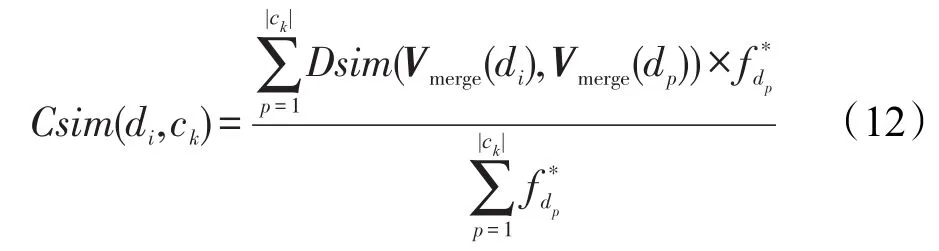
其中,fd*p为话题类ck中dp的意见权重,意见领袖的值为0.6,一般评论的值为0.4。
算法UCSP增量聚类算法
输入:文本集合D;相似度对比阈值T1、T2、T3。
输出:话题类簇集合CT。
初始化:i=2,MaxSim=0,SecSim=0,L=0,L′=0,maxIndex=0,创建簇c1=∅ ,创建类簇集合CT=∅ ,创建待定列表LoopList=∅ 。
步骤1输入d1,c1=c1⋃{d1},CT=CT⋃{c1}。
步骤 2输入di,di∈D,计算(Csim(di,ck)),返回当前k值,maxIndex=k,新建临时簇 集 合
步骤3判断:
若MaxSim≤T1,将di视为噪声数据,LoopList=LoopList⋃{di},i=i+1;
若MaxSim>T1&&MaxSim 若MaxSim≥T2&&MaxSim-SecSim≥T3,则将di加入与其相似度最大的类簇cmaxIndex=cmaxIndex⋃{di},i=i+1; 若MaxSim≥T2&&MaxSim-SecSim≤T3,di视为观点模糊数据,LoopList=LoopList⋃{di},i=i+1。 步骤4若i≤ ||D,转至步骤2。 步骤5待定列表集合LoopList,∀dg∈LoopList,计算返回当前k值,maxIndex=k,新建临时簇集合 步骤6L′=|LoopList|,判断: 若MaxSim>T1&&MaxSim 若MaxSim≥T2&&MaxSim-SecSim≥T3,cmaxIndex=cmaxIndex⋃{dg},LoopList=LoopList-{dg},L=|LoopList|。 步骤7若L′≠L,转至步骤5。 步 骤 8 ∀ck∈CT,若 |ck|<|D|×0.25%,CT=CT-{ck},即过滤噪声评论簇。 步骤9输出CT集合,算法结束。 本文采用JSON页面解析技术爬取新闻评论数据。通过输入腾讯新闻评论页面的请求链接,获取JSON字符串数据,利用Java版本的Gson工具,解析字符串并采用正则表达式匹配规则获取所需数据集。解析并提取到的新闻评论数据结构如表1所示。 Table 1 Data structures of news comments表1 新闻评论的数据结构 鉴于单条评论所包含的上下文信息及语义信息匮乏,本文将当前评论与其跟帖评论进行合并,从而扩充文本内容。本文实验所采用的数据集均为腾讯热门新闻下的评论数据,如表2所示。 新闻评论口语化严重,包含大量干扰性的特殊字符,可以采用启发式规则匹配的方法过滤噪声数据。本文采用中科院张华平等人开发的汉语词法分析系统NLPIR(ICTCLAS2016版)对文本数据进行分词,并添加用户词典,导入分词系统切分不准确的网络新词。 Table 2 Data sets of news comments表2 新闻评论数据 为提高分词的准确性和特征选择的有效性,本文提出一种两阶段去除停用词的方案。首先构建虚词停用词表,在分词处理之前对新闻评论进行第一次清洗,经验表明,分词前去除虚词的方法可以有效提高分词的准确性;分词处理之后,构建实词停用词表,并人工添加网络不规范用语产生的新停用词,从而进一步提高分词的准确性。 本文采用无监督聚类算法,因此使用内部评价指标紧密性和间隔性来评价聚类结果[20]。 集合CT表示所有话题簇的集合;ck为CT中第k个话题簇的文本集合,ck中的每条文本dckp均为基于多特征组合的短文本表示 ck类的中心向量表示为计算类内平均相似度越大意味类内相似度越大,聚类效果越好,重新定义,计算公式为: 其中: SP计算类间平均相似度,SP越小意味类间相似度越小,聚类效果越好,重新定义----SP,计算公式为: 其中: 为了使不同的文本表示模型和聚类算法具有可比性,定义Ratio为的比值,计算公式为:Ratio越大说明聚类效果越好。 为验证本文方法的有效性,设计了两类对比实验:使用相同聚类算法,比较不同短文本表示模型对聚类效果的影响;使用相同短文本表示模型,比较不同聚类算法的结果。另外,考虑相似度阈值对聚类算法的影响,进行了阈值分析实验。 实验1对比实验。 表3是基于UCSP聚类算法采用不同文本表示模型的实验结果,语义表示模型和多特征组合表示模型设置阈值T1=0.3,T2=0.55,T3=0.07。由于向量空间模型特征稀疏,设置相似度阈值T1=0.1,T2=0.25,T3=0.005,以确保与多特征组合的文本表示的聚类个数基本一致。 通过对比表3中Ratio的值可以看出,基于特征权重向量空间模型的聚类效果最好,但是该模型没有结合语义信息,会产生大量噪声类,并且造成相同话题的评论分至不同类的现象。例如:两条关于家庭教育的评论“有些当家长的溺爱孩子!不明白当父母的怎么教育孩子的!”和“教育不当,关心不够!家庭教育做人其实是重中之重”,虽然评论主题相同,却被划分至不同类簇。基于神经网络构建的表示模型虽然结合了语义信息,但是大部分评论围绕新闻内容阐述,语义空间下相似度十分接近,Ratio值最小,聚类效果略差。本文提出的基于多特征组合的短文本表示模型,将两种模型优势互补,总体来说,更符合话题发现的要求。 Table 3 Clustering results of different representation models for short texts using UCSP clustering algorithm表3 基于UCSP聚类算法在不同短文本表示模型上的聚类结果 综上所述,本文提出的基于多特征组合的短文本表示模型具有一定的可行性与有效性,因此在采用该模型对新闻评论进行表示的基础上,对3种聚类算法UCSP、K-means和Single-Pass进行了实验对比,其中将UCSP算法自动生成的类簇个数作为K-means聚类算法的预设K值。 由表4的实验数据可知,本文提出的UCSP增量聚类算法类内平均相似度最高,类间平均相似度最低,Ratio比值最大,聚类结果最好。 实验2阈值对聚类算法的影响。 本文对多个数据集进行了相似度阈值分析实验,以新闻“17岁高中生刀砍老师后被老师群殴抢救无效死亡”的数据为例,在不考虑观点模糊数据的情况下(即T3=0),在[0.15,0.35]范围内,以步长0.05选取T1,在[0.35,0.60]范围内,以步长0.05选取T2,进行实验。 T1为判定噪声评论的阈值,T1设置太小,起不到过滤噪声评论的目的,设置太大,将导致一般评论错误划分;T2为判断评论是否归入相似类簇的阈值,T2设置太小,导致聚类质量不高,设置太大,导致聚类划分过于详细。 由表5和表6的实验数据可知,T1在0.3±0.05的范围内,聚类效果最好;T2≥0.55时,聚类效果趋于稳定。因此,本文选取T1=0.3,T2=0.55。 T3为区分模糊观点评论的阈值,本文在[0.001,0.01]范围内,以步长0.001选取T3,进行实验。 Table 4 Clustering results of different algorithms by using improved texts representation model表4 基于改进的文本表示模型使用不同算法的聚类结果 Table 5 Influence ofT1andT2to the value of 表5 T1和T2对的影响 Table 5 Influence ofT1andT2to the value of 表5 T1和T2对的影响 ? Table 6 Influence ofT1and T2to the value of表6 T1和T2对的影响 Table 6 Influence ofT1and T2to the value of表6 T1和T2对的影响 ? Fig.1 Effect ofT3on clustering result图1 T3对聚类效果的影响 Fig.2 Effect ofT3on clustering result图2 T3对聚类结果的影响 由图1和图2的实验数据可知,随着T3的增大,簇个数由多变少,并趋于稳定,被过滤的文本个数增多,类内平均相似度----CP逐渐增大,类间平均相似度逐渐减小。综合图1和图2的实验结果,T3=0.07时簇个数稳定,被过滤的文本个数小于评论总数10%差值最大,聚类效果最好。 通过对多个数据集的阈值进行实验分析,T1=0.3,T2=0.55,T3=0.07时多个数据集聚类效果表现良好,说明不同的新闻评论话题分布是相似的。 聚类算法结束之后,得到的是一个文本簇,并不能直观地获得类内主题,针对这一问题,本文采用基于TextRank[21]的关键词抽取算法,自动生成主题词概述类内主题,并使用开源工具Tagxedo生成词云,将主题词可视化展示。 以新闻“17岁高中生刀砍老师后被老师群殴抢救无效死亡”为例,抽取其中有代表性的5个类簇将主题词可视化展示。由图3可以直观地看出,网民的观点主要围绕在:严惩凶手,社会风气,家庭教育,法理人情和传统道德等几方面。因此,通过智能化的信息处理,政府对互联网建立网络民意的监测、汇集、分析、反馈和吸纳机制,及时回应与疏导,对于提高政府回应与决策能力,提高决策的科学性和准确性,实现开放型、服务型、责任型政府具有重要意义。 Fig.3 Visual representations of clustering results图3 聚类效果展示 本文针对新闻评论主题聚类过程中主题提取困难的问题,首先提出了一种基于多特征组合的短文本表示模型,由浅入深、由粗到细地挖掘多层次、多粒度的特征表示,从而比较全面地包含短文本的主题信息。针对传统的主题增量聚类算法对文本输入顺序敏感的缺点,本文提出了一种UCSP增量聚类算法,可以有效地处理噪声数据和观点模糊数据,聚类效果明显提升。本文所实现的是离线式的增量聚类算法,如何将算法应用于在线实时发现话题,将是未来的重点研究方向。 : [1]Xiao Yonglei,Liu Shenghua,Liu Yue,et al.Semantic concept linking and extension for social media short texts[J].Journal of Chinese Information Processing,2014,28(4):21-28. [2]Zhu Xinhua,Ma Runcong,Sun Liu,et al,Word semantic similarity computation based on HowNet and CiLin[J].Journal of Chinese Information Processing,2016,30(4):29-36. [3]Batet M.Ontology-based semantic clustering[J].AI Communications,2011,24(3):291-292. [4]Xun Guangxu,Gopalakrishnan V,Ma Fenglong,et al.Topic discovery for short texts using word embeddings[C]//Proceedings of the 16th IEEE International Conference on Data Mining,Barcelona,Dec 12-15,2016.Piscataway:IEEE,2016:1299-1304. [5]Peng Min,Huang Jiajia,Zhu Jiahui,et al.Mass of short texts clustering and topic extraction based on frequent itemsets[J].Journal of Computer Research and Development,2015,52(9):1941-1953. [6]Blei D M,Ng AY,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022. [7]Wang Zhongyuan,Cheng Jianpeng,Wang Haixun,et al.Short text understanding:a survey[J].Journal of Computer Research and Development,2016,53(2):262-269. [8]Xu Jiajun,Yang Yang,Yao Tianfang,et al.LDA based hot topic detection and tracking for the forum[J].Journal of Chinese Information Processing,2016,30(1):43-49. [9]Peng Zeying,Yu Xiaoming,Xu Hongbo,et al.Incomplete clustering for large scale short texts[J].Journal of Chinese Information Processing,2011,25(1):54-59. [10]Li Shengdong,Lv Xueqiang,Shi Shuicai,et al.Adaptive incrementalK-means algorithm for topic detection[J].Journal of Chinese Information Processing,2014,28(6):190-193. [11]Gao Ni,Gao Ling,He Yiyue,et al.Topic detection based on group average hierarchical clustering[C]//Proceedings of the 2013 International Conference on Advanced Cloud and Big Data,Nanjing,Dec 13-15,2013.Washington:IEEE Computer Society,2013:88-92. [12]Shui Yidong,Qu Youli,Huang Houkuan.A new topic detection and tracking approach combining periodic classification and Single-Pass clustering[J].Journal of Beijing Jiaotong university,2009,33(5):85-89. [13]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[M]//Jones S K,Willett P.Readings in Information Retrieval.San Francisco:Morgan Kaufmann Publishers Inc,1997:273-280. [14]Salton G.The SMART retrieval system:experiments in automatic document processing[M].Upper Saddle River:Prentice Hall,1971. [15]Zong Chengqing.Statistical natural language processing[M].Beijing:Tsinghua University Press,2008. [16]Zhang Dongwen,Xu Hua,Su Zengcai,et al.Chinese comments sentiment classification based on Word2Vec and SVMperf[J].Expert Systems with Applications,2015,42(4):1857-1863. [17]Bengio Y,Ducharme R,Vincent P,et al.A neural probabilistic language model[J].Journal of Machine Learning Research,2003,3(6):1137-1155. [18]Mnih A,Hinton G E.Three new graphical models for statistical language modelling[C]//Proceedings of the 24th International Conference on Machine Learning,Corvallis,Jun 20-24,2007.New York:ACM,2007:641-648. [19]Mikolov T,Sutskever I,Chen Kai,et al.Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 27th Annual Conference on Neural Information Processing Systems,Lake Tahoe,Dec 5-8,2013:3111-3119. [20]Liu Yanchi,Li Zhongmou,Xiong Hui,et al.Understanding of internal clustering validation measures[C]//Proceedings of the 10th IEEE International Conference on Data Mining,Sydney,Dec 14-17,2010.Washington:IEEE Computer Society,2010:911-916. [21]Li Peng,Wang Bin,Shi Zhiwei,et al.Tag-TextRank:a Webpage keyword extraction method based on tags[J].Journal of Computer Research and Development,2012,49(11):2344-2351. 附中文参考文献: [1]肖永磊,刘盛华,刘悦,等.社会媒体短文本内容的语义概念关联和扩展[J].中文信息学报,2014,28(4):21-28. [2]朱新华,马润聪,孙柳,等.基于知网与词林的词语语义相似度计算[J].中文信息学报,2016,30(4):29-36. [5]彭敏,黄佳佳,朱佳晖,等.基于频繁项集的海量短文本聚类与主题抽取[J].计算机研究与发展,2015,52(9):1941-1953. [7]王仲远,程健鹏,王海勋,等.短文本理解研究[J].计算机研究与发展,2016,53(2):262-269. [8]徐佳俊,杨飏,姚天昉,等.基于LDA模型的论坛热点话题识别和追踪[J].中文信息学报,2016,30(1):43-49. [9]彭泽映,俞晓明,许洪波,等.大规模短文本的不完全聚类[J].中文信息学报,2011,25(1):54-59. [10]李胜东,吕学强,施水才,等.基于话题检测的自适应增量K-means算法[J].中文信息学报,2014,28(6):190-193. [12]税仪冬,瞿有利,黄厚宽.周期分类和Single-Pass聚类相结合的话题识别与跟踪方法[J].北京交通大学学报,2009,33(5):85-89. [15]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008. [21]李鹏,王斌,石志伟,等.Tag-TextRank:一种基于Tag的网页关键词抽取方法[J].计算机研究与发展,2012,49(11):2344-2351.4 实验过程及结果分析
4.1 数据采集

4.2 数据预处理

4.3 评价指标

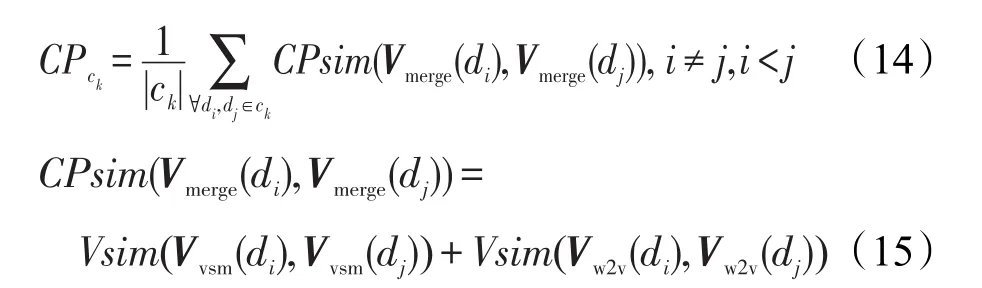
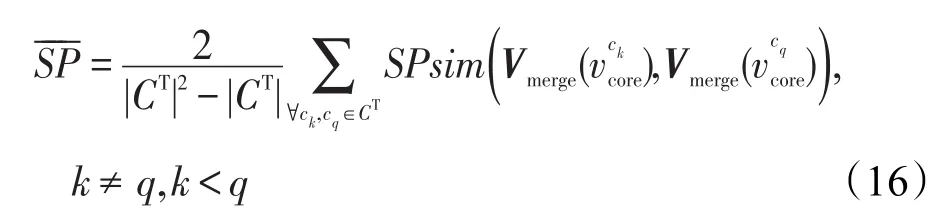
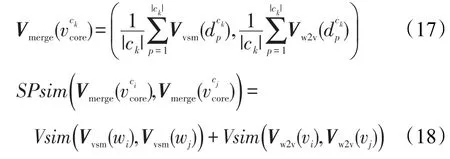

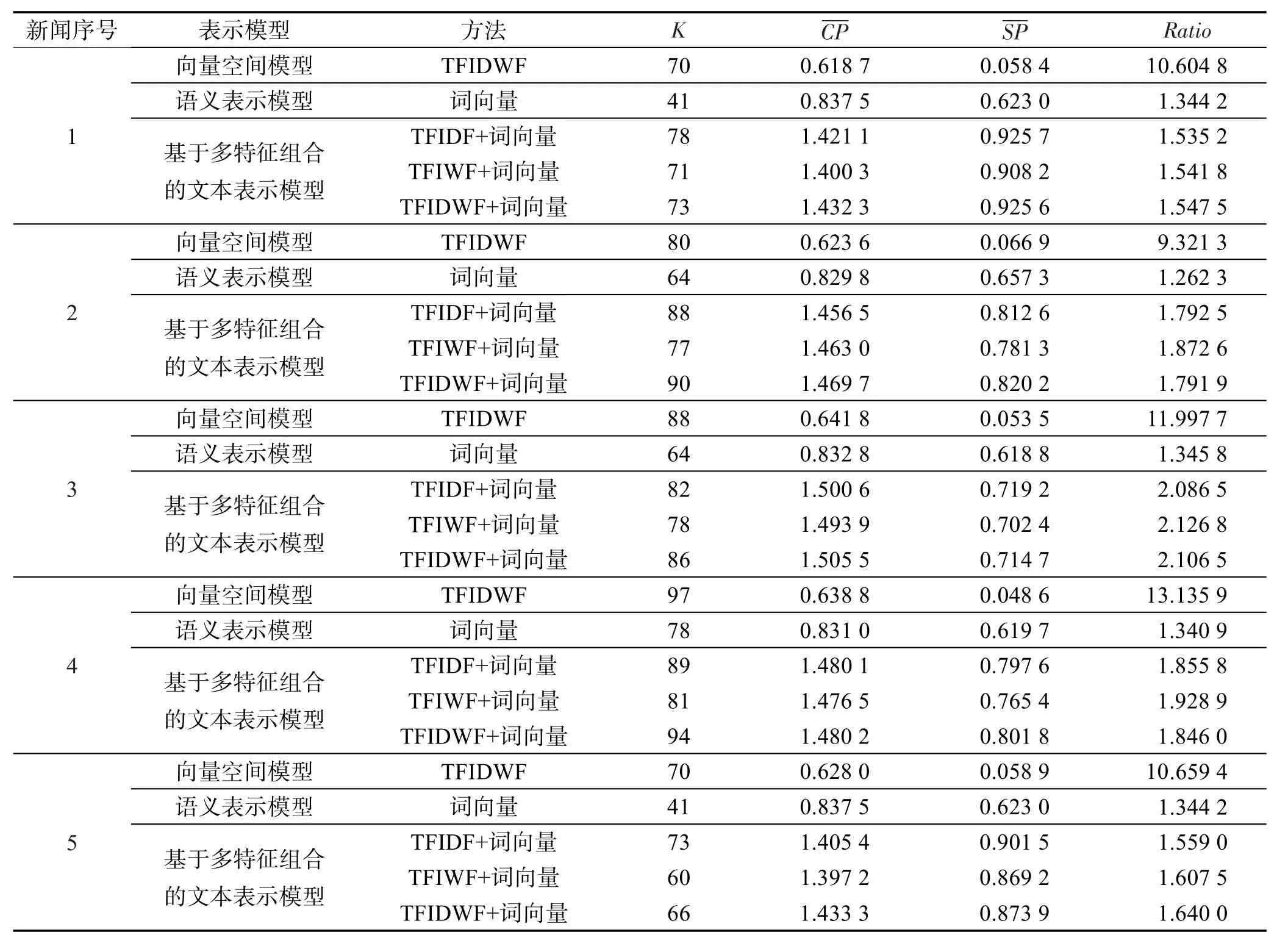
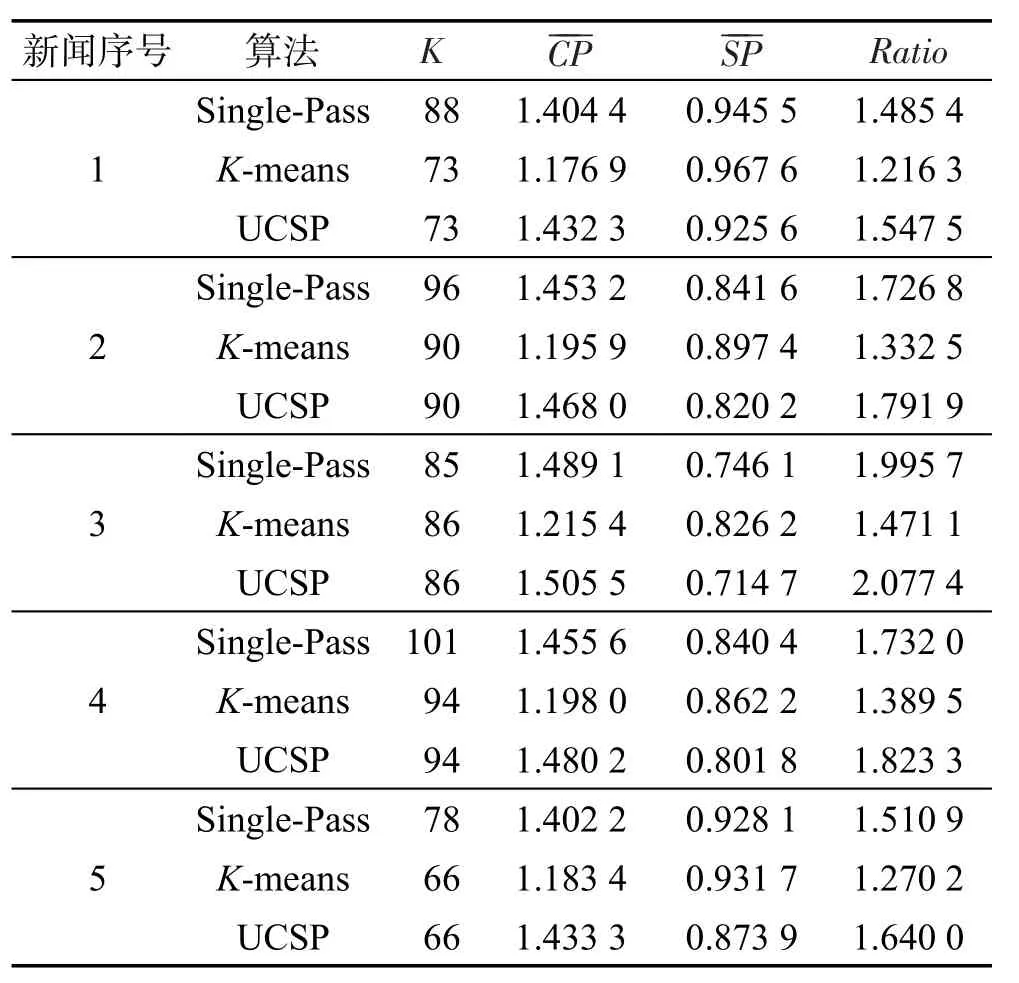
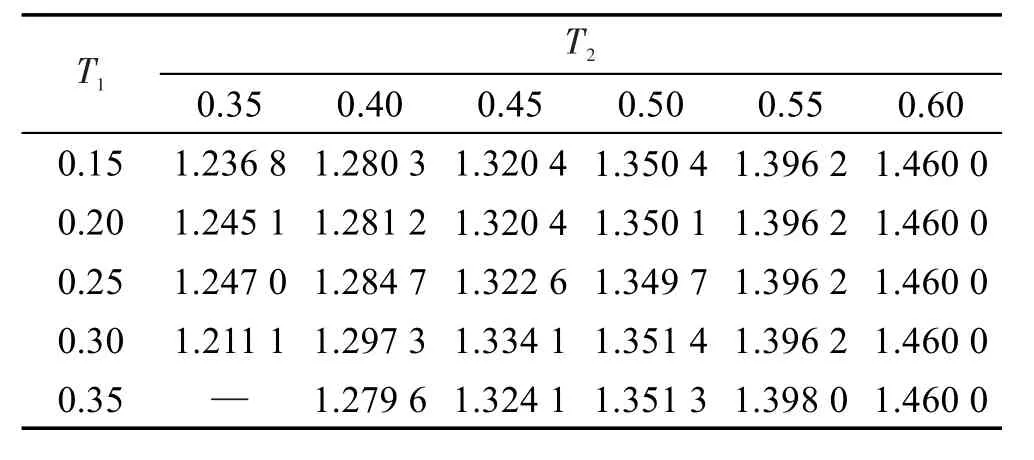
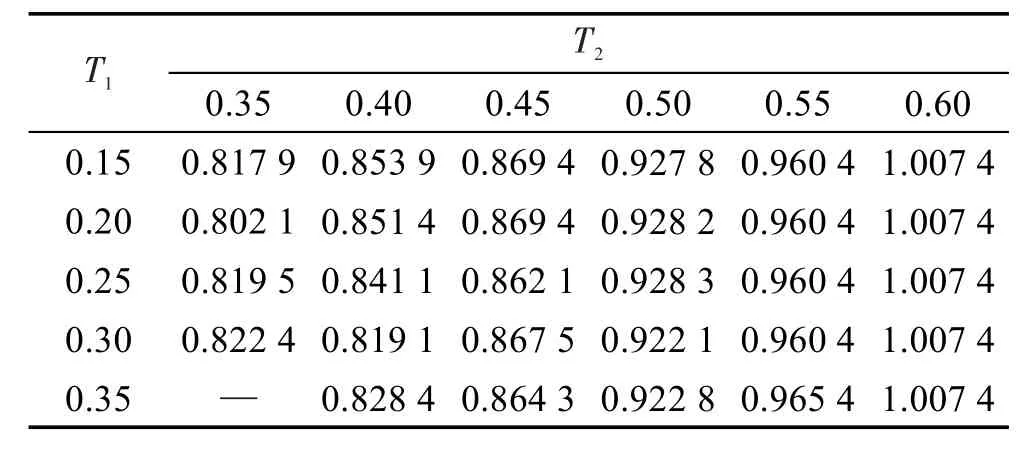
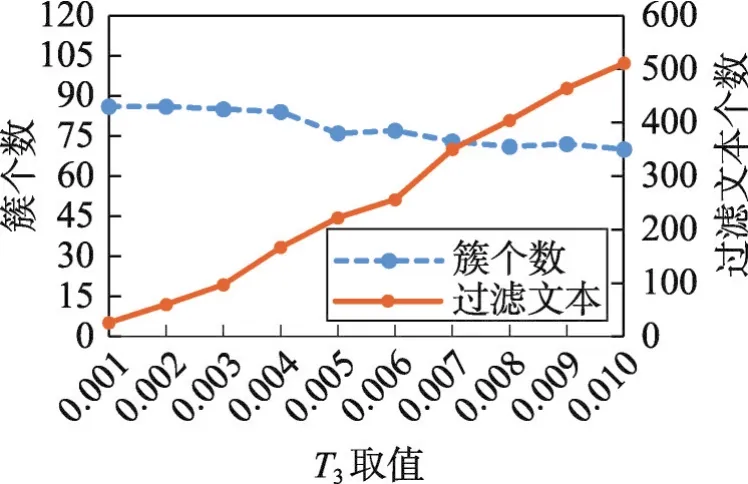
4.4 实验设置
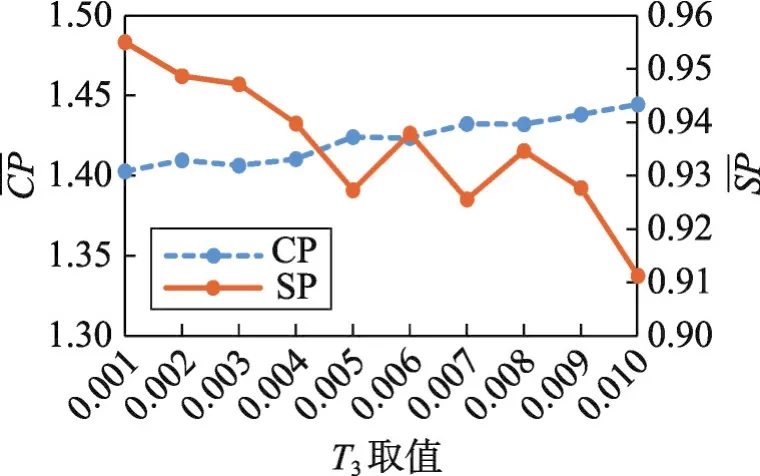
4.5 结果可视化展示

5 结束语
