专利查询扩展的词向量方法研究*
2018-06-19林鸿飞
许 侃,林 原,曲 忱,徐 博,林鸿飞+
1.大连理工大学 计算机科学与技术学院,大连 116024
2.大连理工大学 科学学与科技管理研究所,大连 116024
1 引言
专利信息广泛存在并渗透于科技、经济和社会生活的各个领域,具有集多种信息于一体,数量巨大,学科范围广,公布快捷,内容新颖,高度标准化,以及揭示发明创造内容完整详尽等优点,已成为人们从事科学研究、技术开发和法律规范等社会经济活动必不可少的重要信息。
从海量的专利文献或专利数据库中可以检索得到有价值的专利文献或信息,经过分析处理后可以了解所需求的专利信息。其作用在于避免重复开发,规避他人专利保护范围,利用他人的专利技术,洞悉竞争对手研发方向,完善已有技术方案等。因此,在开发新产品、技术难题攻关、进行技术贸易、引进专利技术前,专利检索是十分重要的。但是专利数据如此海量,如何从庞大的数据中得到重要的信息,已经使专利检索成为专利信息利用的焦点。
查询扩展方法被广泛地应用于提高信息检索结果的准确率[1-3]。其中,伪相关反馈(pseudo relevance feedback,PRF)方法作为一种查询扩展方法被证明是十分有效的[4-5]。查询扩展过程实际上是对用户提交的原始查询关键字进行修改,从而更好地表达用户的潜在意图,并将重构后的查询作为关键词输入搜索引擎。因而查询重构的首要目的是为了提升整体排序质量,并将其展现给用户。Wang等人[6]采用了一种基于语义的查询扩展技术来丰富专利查询,并更加准确地理解用户的专利查询意图。Khuda-Bukhsh[7]等人提出了一种基于主动学习的查询分类方法,并取得了较好的分类效果。Wu等人[8]提出了一种构建伪查询的方法来进行查询意图检测。Potey等人[9]则充分利用查询日志信息,并且基于查询日志构建了查询意图识别模型。Rashidghalam等人[10]利用BabelNet概率和访问概率算法提出了一种非监督的查询意图识别算法。用户的查询意图识别是搜索引擎必需完善的技术,而在专利检索中用户往往关注某一特定领域的专利,将用户的查询意图准确地映射至某一特定的专业领域对于提高专利检索系统的用户体验显得更加重要。
查询重构过程需要从特定的语料资源中挖掘各词项与原始查询之间的某种关联属性,进而选择关联程度较高的词项作为扩展词加入查询。查询重构技术的两个关键环节在于扩展资源的选取以及词项间关联属性的挖掘。在扩展源一致的情况下,词项之间的关联挖掘对于查询扩展过程显得尤为重要。
近年来,深度学习作为一种有效的机器学习方法使得文本挖掘领域得到了进一步发展。专利检索也是文本挖掘领域的一个重要研究任务,因此深度学习方法有着很好的应用基础。本文将深度学习模型融入到专利检索中,提高专利领域内检索方法的准确率与召回率。
目前,深度学习在自然语言处理方向主要有两个分支:第一个是以Srivastava[11]为代表的主要使用深度置信网络RBM(restricted Boltzmann machine)对文档进行主题建模,其结果优于传统的主题模型LDA(latent Dirichlet allocation);另一分支是以Hill[12]为代表的使用多层感知机CNN(convolutional neural network)、RNN(recurrent neural network)等对文档建模。前者不考虑文档内词语的出现顺序,仅仅从文档维度考虑词语之间的主题关系。而后者更多以滑动窗口或反馈的形式对短文本进行建模。词向量表示方法是一种有效的将不同的词项表示为相同维度向量的方法,基于该向量,可以计算词项之间的相似度,本文基于该相似度计算查询词与候选词之间相关度,借此改善查询扩展方法的检索性能。本文综合考虑专利文档多文本域以及各个域的不同特征,使用不同的检索模型,充分利用专利的特性和深度学习中的词向量模型在自然语言处理中的优势,将其应用于查询扩展方法的候选词选择过程当中,用以提高专利检索的准确率。
本文组织结构如下:第2章给出相关工作;第3章探索词向量方法对专利检索查询扩展候选词选择的影响,并提出基于词向量模型的专利查询扩展方法;第4章给出实验结果;第5章总结全文。
2 相关工作
近年来,专利检索研究得到极大关注,这些研究主要着眼于探索基于主题的查询重构方法。查询重构过程需要从特定的语料资源中挖掘各词项与原始查询之间的某种关联属性,进而选择关联程度较高的词项作为扩展词加入查询。查询重构技术的两个关键环节在于扩展资源的选取以及词项间关联属性的挖掘。
当前扩展资源的选取主要分为三大类,即全局信息、局部信息和外部数据,通常不同的扩展资源的选取也对应了不同的词项间关联属性挖掘方法。在早期的工作中,关键字被抽取用于新的查询[13-14];目前流行的局部分析方法主要是伪相关反馈,它是在相关反馈的基础上发展起来的。文献[1]首度提出扩展词只从排名靠前的初次检索结果中抽取,其基本思想是利用初次检索得到的与原查询最相关的N篇文章(伪相关文档集)作为扩展词项的来源。
最近研究表明[15],使用来自于所检索文本不同域的词作为查询扩展词可以获得较好的检索结果。本文将采用域信息来选择候选扩展词,提升专利检索结果,同时将域作为一种有效的信息来源探索其对专利检索中查询扩展的影响。
对于查询扩展方法,查询扩展词选择尤为重要。该方法主要是对各种查询扩展资源采用对应的关联挖掘算法,挖掘各资源中与原查询相关的词项,并对每个相关词项按其信息源分别给出关联度分值,结合原始查询词提高检索的准确率。目前,神经网络模型在自然语言处理方面得到了广泛的应用,尤其是RNN[16]模型与CNN[17]模型。RNN模型可以有效地捕捉句子当中蕴涵的语法与语义关系,通过使用反馈边以及memory cell和gate等方式,使其具有处理时间序列标注任务的能力。CNN模型通过卷积核可以求出句子当中的某些特定词之间蕴涵的特征,不但减少了模型的复杂度,而且提高了特征提取的纯度。这两个模型的共同点在于它们必须首先把数据集中的每个单词映射到连续的实数空间中,用d维词向量来表示每一个词。训练词向量的方法采用较多的是连续词袋(continuous bag of words,CBOW)、Skip-gram[18]模型。Mikolov等人[18]发现CBOW和Skip-gram方法训练出来的词矢量支持代数的向量加法操作,发现vec(“Russia”)+vec(“river”)和vec(“Volga River”)两个词向量具有较高的相似度,并且将这种性质应用到短语识别任务。由于该方法可以有效地表示词与词之间的关系,目前已有相关研究将其应用于查询扩展任务当中[19]。本文也将采用这种方法基于伪相关反馈文档构造扩展词向量,用于计算候选扩展词与原始查询词的关系。
3 基于词向量的查询扩展方法
本文采用查询扩展方法优化专利检索结果;采用Rocchio模型作为多专利文本域扩展的基础;采用原始数据集进行伪相关反馈;采用多种扩展词选择方法从原始数据集中提取查询扩展词,加入原始查询中,提高专利检索准确率。查询扩展通常包含两个步骤:第一步选择伪相关文档集合;第二步评估扩展词的权重。
3.1 伪相关文档的选择
本文的伪相关文档集合来自于TREC专利数据集查询返回的结果。第一步是伪反馈文档集合的选择,因为专利是一种存在多个不同内容文本域的文档,所以本文采用BM25F来选择前n篇文档。
BM25(BM stands for best matching)方法的一种改进方法BM25F(BM25 for text field)[20]是在多文档域上进行扩展,该方法的一个关键属性就是非线性,当只有一个域需要计算时,BM25F退化为BM25方法。本文将二者均看作BM25F方法,这里的F是对文档描述中包含的特定域的说明。本文使用BM25F作为初次检索获取反馈文档的方法,初次检索中考虑了多个域。对于给定查询q,包含文档域描述F的文档d,其BM25F计算方式如下:

公式中的求和是对于查询q中的所有词t进行的,It是词项t的逆文档频率的Robertson-Sparck-Jones形式,其计算方法如下:

其中,N是文档集合中文档的总数;df是词项t的文档频率。TFt是一个简单的词频饱和公式,它能限制同一文本域中的词频对整体的影响,定义如下:

f的计算方法是:

其中,tfF是词项t在文本域F中的词频;k是饱和度参数,能控制TFt的非线性程度;wF是训练得到的文本域权重参数;βF是文本域长度的函数,定义如下:
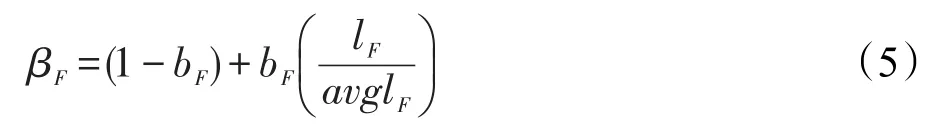
其中,bF是长度调节参数;lF是文本域长度;avglF是文档集合中所有文本域的平均长度。本文应用BM25F作为初次检索的方法,选择在初次检索中排序最为靠前的n个位置的文档作为第二阶段候选扩展词选择的扩展词来源。
3.2 基于TF-IDF的查询扩展方法
该方法首先使用原始查询及BM25F方法获得n篇相关专利文档,再抽取n篇文档中的TF-IDF特征排序高的词作为查询扩展词,合并原始查询词与查询扩展词后再使用BM25F方法进行检索。其中TFIDF[21]包含两个变量,词频和逆文档频率,有很多种方式来确定这两个变量的值。对于词频,最简单的方式就是选择一个词在一篇文档中出现的频率,即该词在文档中出现的次数。

其中,tft,d是词t在文档d中出现的次数;nt是文档集合中包含词t的文档数;N是文档集合中文档的总数。
3.3 基于词向量的查询扩展方法
本文采用专利文本进行词向量的构建。首先把专利文档中所有的关键词通过d维的实数向量进行表示,之后再通过词语之间的相似度计算方法,计算扩展候选词与原始查询词之间的关系,选择与原始查询相似度高的候选词作为查询扩展词。
词向量:作为利用深度学习训练语言模型过程中获得的中间产物,在自然语言处理领域获得了大量的关注。它可以把一个词表示成任意维度(常见为50~200维)的实数向量,同时赋予了每个词向量语义信息。本文选择Skip-gram模型进行词向量的构造。该模型最大化的目标函数如下所示:
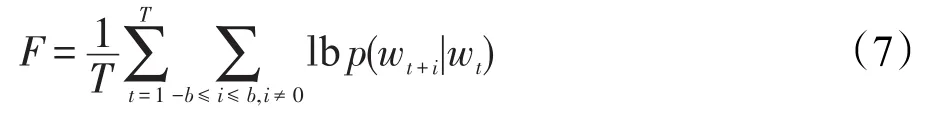
其中,b是决定上下文窗口大小的常数,b越大训练时间会增加,同时精确度也会提高。同时选择了Negative-Sampling[22]方法去训练Skip-gram模型,最终训练出的词语向量维度为200维。词向量能够将两个词之间的语义相似度映射到空间中两个向量的距离上,使用该向量进行查询扩展可获得各个词之间在语义上的关联程度信息。该向量可以用于计算候选词与查询词之间的相似度,本文采用向量的余弦相似度来计算扩展词c与原始查询词qi的相似度。计算公式如下所示:
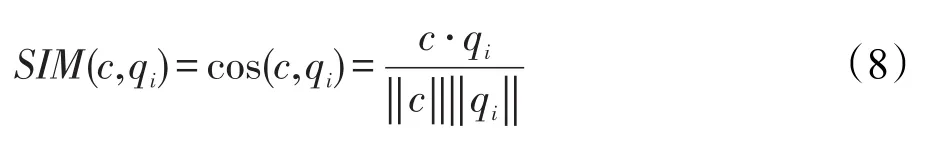
其中,qi为原始查询中的词项。
本文采用4种方法利用词向量模型所得到的原始查询与候选词的相似度进行专利文档检索的查询扩展。
(1)Word2Vec查询扩展:通过词向量余弦相似度的计算,直接选取和原始查询相关度最高的n个候选词作为扩展词加入到原始查询当中。
(2)层级式扩展方法Word2Vec-TFIDF:对原始查询词进行词向量(Word2Vec)扩展后得到查询A,再对A进行TF-IDF查询扩展得到查询B,将B作为扩展后的查询。
(3)层级式扩展方法TFIDF-Word2Vec:对原始查询词进行TF-IDF查询扩展后得到查询词集合A,再对A进行Word2Vec查询扩展得到查询词集合B,将B作为扩展后的查询。
(4)合并式扩展方法TFIDF+Word2Vec:对原始查询词进行Word2Vec扩展得到查询A,对原始查询词进行TF-IDF扩展得到查询B,取A和B的并集作为扩展后的查询。
4 实验及结果
本文所使用的数据集是TREC-CHEM数据集,其中语料包括从USPTO、EPO和WIPO获取的专利文档,共1 266 771篇,该数据集包含2009年以来化学领域的专利文献。采用TREC-CHEM2010和TREC-CHEM2011中技术研究(TS)任务的全部查询作为查询集合,该集合包含由专家构造的部分含标注的技术研究查询12个,每个查询都包括一个基于专利文档数据利用自然语言表达的信息需求描述。系统的任务是返回一个尽可能好并能回答该信息需求的文档集合。这些查询构造都十分有价值,从而更能符合专家搜索过程中的真实信息需求。本文使用数据中的专利文档,一篇专利文档包括若干文本域,如标题、摘要、描述和权力要求,这些特定的文本域被用于提升扩展词的质量。专利检索结果评价指标采用平均准确率MAP和P@n。
4.1 实验参数设置
设输入查询为Q1,含有t个查询词,首先采用BM25F方法获取原始查询Q1在TREC-CHEM数据集中的前n篇相关文档(n取1 000到10 000)。将这n篇相关文档作为训练语料,使用词向量模型训练得到Q1所对应的词向量模型M1,在词向量模型M1中,使用两种查找扩展词的方法,分别如下。

方法1为Q1中每个词查找最相近的100个词作为扩展出的查询词,则共扩展出100×q个查询词,将该集合描述为E1。合并原始查询Q1与扩展出的查询词集合E1,其中将Q1的权重设置为1,E1中各词的权重设置为:其中,e1为E1中各个词的词向量;q1为在Q1中找到的与e1最近的词的词向量;α为衰减系数,值为0.1~1.0。对于E1中的扩展词,按权重对其进行降序排序,对于重复的扩展词进行去重处理,将其权重相加,作为该词的最终权重。在排序并去重的E1集合中选取前k个词(k取5~80)加入原始查询中。
方法2对于每一个候选词c,计算c与查询中每个查询词的相似度,进行求和,选取相似度之和最大的前k个词(k取5~80)加入到原始查询当中。将该集合描述为E2,输入查询中Q1的权重仍设置为1,E2中各词的权重设置为:

其中,e2为E2中各个词的词向量;-q为Q1中原始查询词的词向量的平均向量;α为衰减系数,值为0.1~1.0。
在实验中测试所有参数组合,使各种方法的性能达到最好(方法对应的MAP值达到最高)。方法1最优参数设置如表1所示,方法2最优参数设置如表2所示。
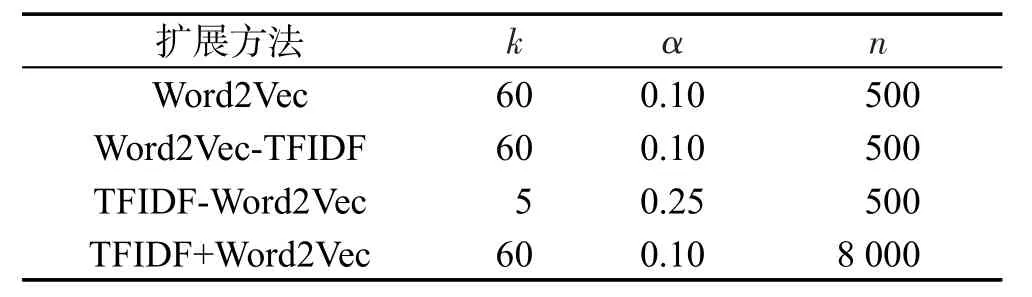
Table 1 Parameter setting for Method 1表1 方法1参数设置
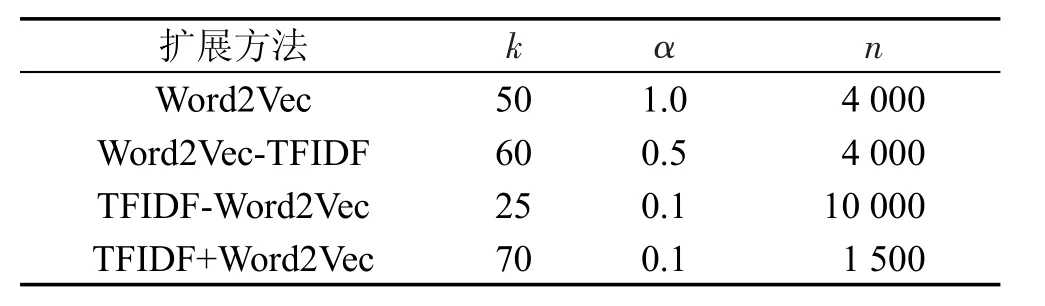
Table 2 Parameter setting for Method 2表2 方法2参数设置
4.2 实验结果
表3和表4列出了3.2节提出的基于TF-IDF的专利查询扩展方法以及3.3节提出的基于词向量的专利查询扩展方法。Baseline方法是将BM25F作为检索模型采用原始查询对数据集进行检索的方法,以及相关性模型RM方法[23]。
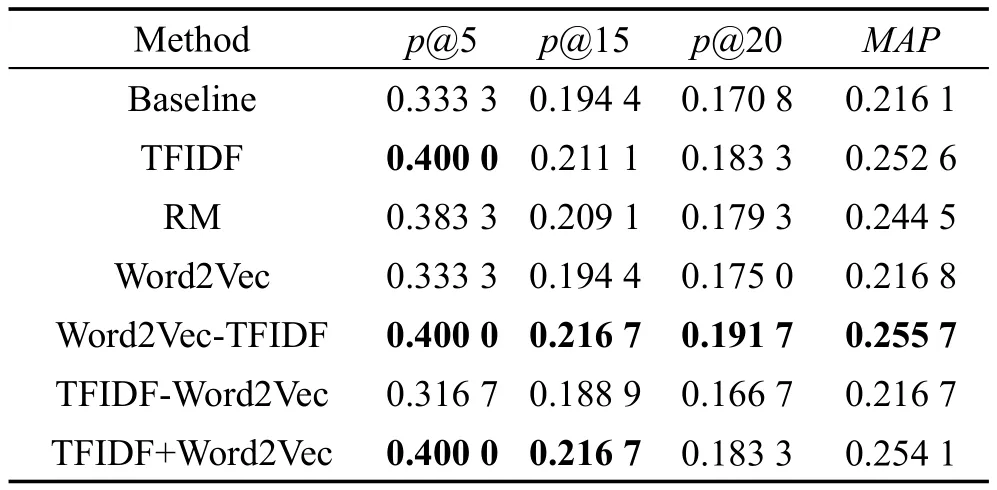
Table 3 Results of patent query expansion(Method 1)表3 专利查询扩展方法实验结果(方法1)
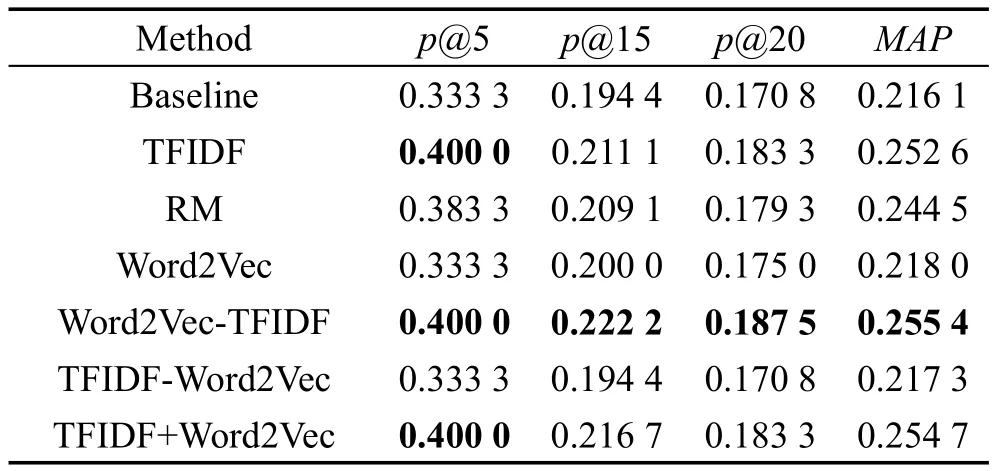
Table 4 Results of patent query expansion(Method 2)表4 专利查询扩展方法实验结果(方法2)
TFIDF方法为3.2节提出的查询扩展方法;Word2Vec、Word2Vec-TFIDF、TFIDF-Word2Vec 和TFIDF+Word2Vec是3.3节提出的基于词向量进行查询扩展的专利检索方法。
图1~图3显示的是方法1中Word2Vec-TFIDF在不同参数设置下的实验结果。
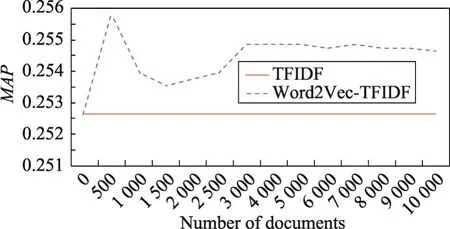
Fig.1 Relation of documents number nandMAP(Method 1)图1 文档数量n与MAP值之间的关系(方法1)
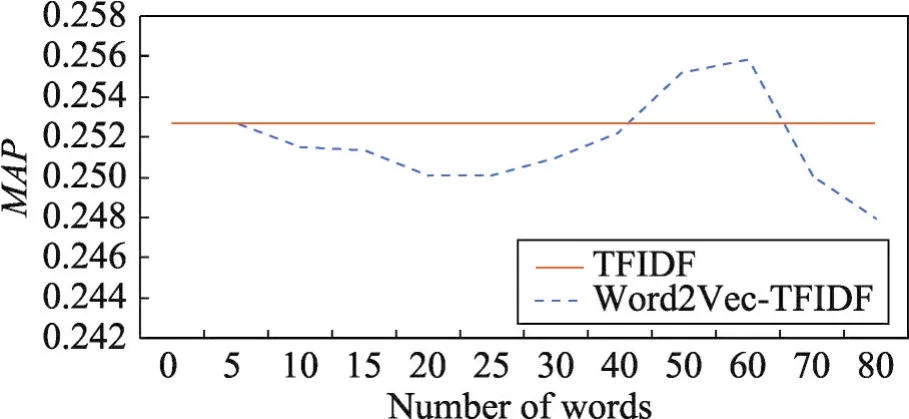
Fig.2 Relation of expansion words number kandMAP(Method 1)图2 扩展词数k与MAP值之间的关系(方法1)
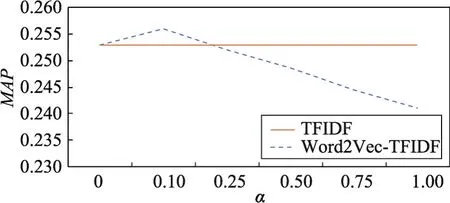
Fig.3 Relation of decay factorα andMAP(Method 1)图3 衰减系数α与MAP值之间的关系(方法1)
从图1的实验结果可以看出,当文档数量为500时,专利检索的MAP值取得峰值。当文档数量大于3 000时,MAP变得较为稳定,但仍未超过峰值。因此方法1中参数n即相关文档数量本文设置为500。
从图2的实验结果可以看出查询词选择数量k与检索结果评价指标MAP之间的关系。当k达到60时,专利检索的MAP值取得峰值,较BM25相比有明显提升,而超过60时,检索结果会有明显下降。因此方法1中参数k即扩展词数本文设置为60。
图3显示了原始查询与扩展词查询的衰减系数α的变化对于专利检索结果MAP值的影响。当α值为0.1时,方法1的实验效果最好,同时可以看到参数α达到0.1后如果继续增加,会导致检索结果下降,因此为保证Word2Vec-TFIDF方法的检索性能达到最佳,设置α值为0.1。
其他几种方法的实验参数设置与Word2Vec-TFIDF方法类似,都是在其他两个参数不发生变化的情况下对于单一参数进行调优,保证查询扩展方法的实验结果MAP值达到最大。
图4~图6显示的是方法2中Word2Vec-TFIDF在不同参数设置下的实验结果。
从图4的实验结果可以看出,随着文档数量增长,MAP值在波动中先上升后下降,并在文档数量为4 000时取得最大值。因此方法1中参数n即相关文档数量本文设置为4 000。
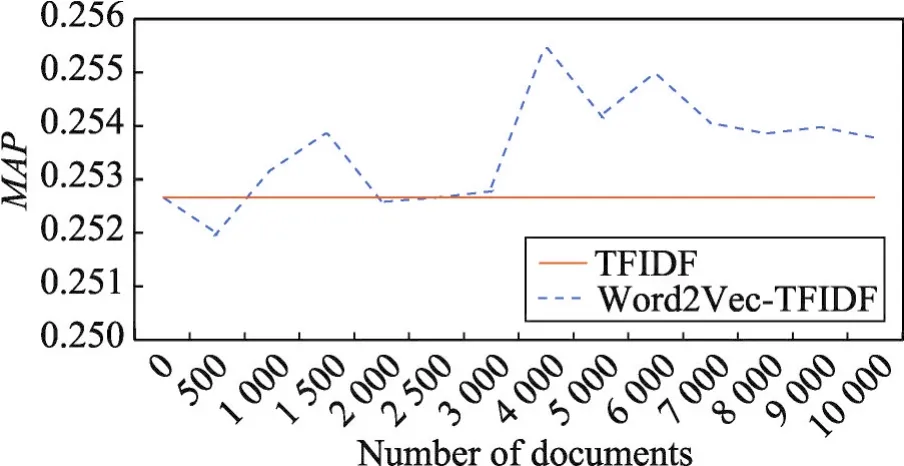
Fig.4 Relation of documents numbern andMAP(Method 2)图4 文档数量n与MAP值之间的关系(方法2)
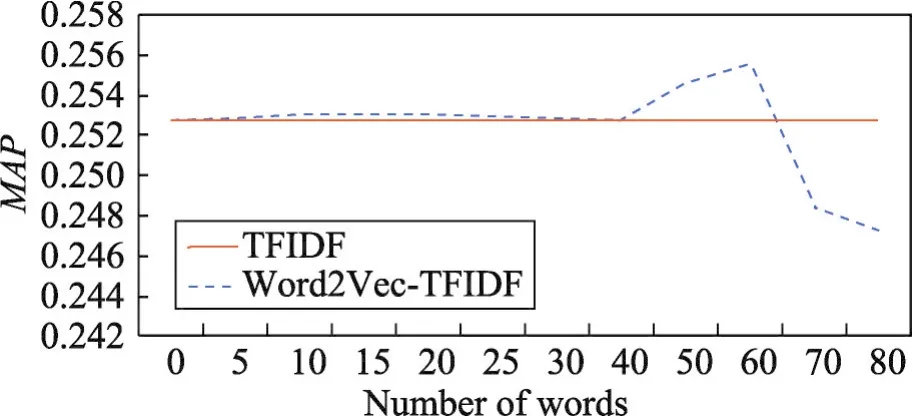
Fig.5 Relation of expansion words number kandMAP(Method 2)图5 扩展词数k与MAP值之间的关系(方法2)
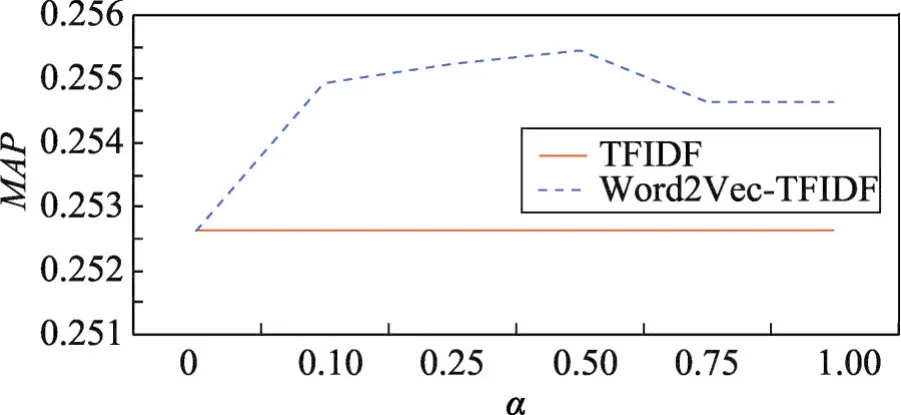
Fig.6 Relation of decay factorα andMAP(Method 2)图6 衰减系数α与MAP值之间的关系(方法2)
从图5的实验结果可以看出查询词选择数量k与检索结果评价指标MAP之间的关系。当k大于40时,MAP相对于BM25才有显著增长,当k到60时MAP达到峰值,而文档个数超过60以后检索结果会有明显下降。因此方法2参数k即扩展词数本文设置为60。
图6显示了原始查询与扩展词查询的衰减系数α的变化对于专利检索结果MAP值的影响。可以看出检索结果随衰减系数的增大呈现先增长、后下降的走势,但总体变化趋势较为平缓,并在衰减系数为0.5时达到峰值。因此为保证Word2Vec-TFIDF方法的检索性能达到最佳,设置α值为0.5。
其他几种方法的实验参数设置与Word2Vec-TFIDF方法类似,都是在其他两个参数不发生变化的情况下对于单一参数进行调优,保证查询扩展方法的实验结果MAP值达到最大。
5 结论
本文采用词向量模型对于专利检索的查询扩展方法进行改进,提出4种方法将词向量模型融入到查询扩展词选择过程当中,进而改进查询扩展模型的性能。在TREC数据集上的实验表明,本文的查询扩展方法对于专利检索十分有效,能够有效地提高专利检索的准确率,对于理解用户的查询意图有着很好的促进作用。实验显示,单独使用词向量模型进行扩展词的选择不能够直接有效地提高专利检索的准确率,但是与传统的TF-IDF扩展词选择方法相融合则能够有效地提高查询扩展模型的性能,整体实验结果指标显示Word2Vec-TFIDF是一种较为有效的查询扩展融合方法。
:
[1]Xu Jinxi,Croft W B.Query expansion using local and global document analysis[C]//Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Zurich,Aug 18-22,1996.New York:ACM,1996:4-11.
[2]Cronen-Townsend S,Zhou Yun,Croft W B.A framework for selective query expansion[C]//Proceedings of the 2004 ACM International Conference on Information and Knowledge Management,Washington,Nov 8-13,2004.New York:ACM,2004:236-237.
[3]Metzler D,Croft W B.Latent concept expansion using Markov random fields[C]//Proceedings of the 30thAnnual Inter-national ACM SIGIR Conference on Research and Development in Information Retrieval,Amsterdam,Jul 23-27,2007.New York:ACM,2007:311-318.
[4]Tao Tao,Zhai Chengxiang.Regularized estimation of mixture models for robust pseudo-relevance feedback[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Seattle,Aug 6-11,2006.New York:ACM,2006:162-169.
[5]Lee K S,Croft W B,Allan J.A cluster-based resampling method for pseudo-relevance feedback[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,Singapore,Jul 20-24,2008.New York:ACM,2008:235-242.
[6]Wang Feng,Lin Lanfen,Yang Shuai,et al.A semantic query expansion-based patent retrieval approach[C]//Proceedings of the 10th International Conference on Fuzzy Systems and Knowledge Discovery,Shenyang,Jul 23-25,2013.Piscataway:IEEE,2013:572-577.
[7]Khuda-BukhshAR,Bennett P N,White R W.Building effective query classifiers:a case study in self-harm intent detection[C]//Proceedings of the 24th ACM International Conference on Information and Knowledge Management,Melbourne,Oct 19-23,2015.NewYork:ACM,2015:1735-1738.
[8]Wu Zongda,Shi Jie,Lu Chenglang,et al.Constructing plausible innocuous pseudo queries to protect user query intention[J].Information Sciences,2015,325:215-226.
[9]Potey M A,Patel D A,Sinha P K.A survey of query log processing techniques and evaluation of web query intent identification[C]//Proceedings of the 3rd International Advance Computing Conference,Ghaziabad,Feb 22-23,2013.Piscataway:IEEE,2013:1330-1335.
[10]Rashidghalam H,Mahmoudi F.Web query classification using improved visiting probability algorithm and babelnet semantic graph[C]//Proceedings of the IEEE AI&Robotics,Qazvin,Apr 12,2015.Piscataway:IEEE,2015:1-5.
[11]Srivastava N,Salakhutdinov R,Hinton G.Modeling documents with deep Boltzmann machines[C]//Proceedings of the 29th Conference on Uncertainty in Artificial Intelligence,Bellevue,Aug 11-15,2013.New York:ACM,2013:616-624.
[12]Hill F,Cho F,Korhonen A,et al.Learning to understand phrases by embedding the dictionary[J].Transactions of the Association for Computational Linguistics,2016,4:17-30.
[13]Konishi K.Query terms extraction from patent document for invalidity search[C]//Proceedings of the 5th NTCIR Workshop Meeting on Evaluation of Information Access Technologies:Information Retrieval,Question Answering and Cross-Lingual Information Access,Tokyo,Dec 6-9,2005.Tokyo:NTCIR,2005:1-6.
[14]Itoh H,Mano H,Ogawa Y.Term distillation in patent retrieval[C]//Proceedings of the ACL-2003 Workshop on Patent Corpus Processing,Sapporo,2003.Stroudsburg:ACL,2003:41-45.
[15]Wanagiri M Z,Adriani M.Prior art retrieval using various patent document fields contents[C]//LNCS 6360:Multilingual and Multimodal Information Access Evaluation,International Conference of the Cross-Language Evaluation Forum,Padua,Sep 20-23,2010.Berlin,Heidelberg:Springer,2010:1-6.
[16]Chung J,Gulcehre C,Cho K H,et al.Empirical evaluation of gated recurrent neural networks on sequence modeling[J].arXiv:1412.3555,2014.
[17]Farabet C,Couprie C,Najman L,et al.Learning hierarchical features for scene labeling[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(8):1915-1929.
[18]Mikolov T,Sutskever I,Chen Kai,et al.Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 27th Annual Conference on Neural Information Processing Systems,Lake Tahoe,Dec 5-8,2013.Red Hook:CurranAssociates,2013:3111-3119.
[19]Diaz F,Mitra B,Craswell N.Query expansion with locallytrained word embeddings[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,Berlin,Aug 7-12,2016.Stroudsburg:ACL,2016:367-377.
[20]Robertson S,Zaragoza H,Taylor M.Simple BM25 extension to multiple weighted fields[C]//Proceedings of the 2004 ACM CIKM International Conference on Information and Knowledge Management,Washington,Nov 8-13,2004.New York:ACM,2004:42-49.
[21]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the ACM,1975,18(11):613-620.
[22]Mikolov T,Sutskever I,Chen Kai,et al.Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 27th Annual Conference on Neural Information Processing Systems,Lake Tahoe,Dec 5-8,2013.New York:ACM,2013:3111-3119.
[23]Lavrenko V,Croft W B.Relevance based language models[C]//Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New Orleans,Sep 9-13,2001.New York:ACM,2001:120-127.
