结合语音融合特征和随机森林的构音障碍识别
2018-06-14张雪英段淑斐闫密密
李 东, 张雪英, 段淑斐, 闫密密
(太原理工大学 信息工程学院,山西 太原 030024)
构音障碍是指由于中枢神经系统受损导致的发音运动不协调,从而产生语音混乱的现象[1].神经肌肉的器质性病变会造成发音器官的肌肉无力、肌张力异常或运动不协调,从而导致发声、韵律以及共鸣等方面的异常.构音障碍的严重程度决定于神经肌肉受损的程度.脑瘫是构音障碍的一种典型病例,于发育早期形成,病变部位在脑部,除肢体运动障碍之外,大部分患者存在呼吸道和声道的中枢性神经运动异常[2].据世界卫生组织的数据统计,在脑瘫患者中,有88%左右存在构音障碍问题.语音信号处理是检测构音障碍的有效方式之一,通过提取语音中的特征参数并进行模式分类,可以有效地将正常人和构音障碍人进行区分,结合相关的病理学知识,可进一步对病情严重程度进行判断[3].因此,进行基于声学特征的病理语音识别研究具有十分重要的社会意义.在目前的病理语音研究中,使用最为广泛的数据库是麻省眼耳医院(Massachusetts Eye and Ear Infirmary ,MEEI)开发的病理嗓音数据库.此数据库收集了正常人以及各种由神经、器官病变或外伤导致的发音障碍患者的语音数据.此外,还有由阿姆斯特丹大学开发的NKI-CCRT数据库,记录了头颈部癌症患者的语音数据,语言为荷兰语;由多伦多大学开发的TORGO数据库[4]记录了脑瘫或肌萎缩性脊髓侧索硬化症患者的语音数据,语言为英语.相比之下,汉语普通话的病理语音数据库十分缺乏,很大程度上阻碍了相关研究的进展.
目前,进行病理语音识别的主要方法是: 先从语音中提取所需特征,再运用机器学习的方法进行识别和分类[5].文献[6]选用了MEEI病理嗓音数据库,并提取梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)作为特征参数,分别采取F检验和费雪判别比的方法进行降维,选取高斯混合模型(Gaussian Mixture Model, GMM)作为识别系统,对比了两种特征选择方法的优劣.在四川大学与四川大学华西口腔医院的合作研究中,提取了MFCC作为特征,运用隐马尔科夫模型(Hidden Markov Model,HMM)对腭裂语音辅音省略情况进行识别,达到了86.9%的识别正确率[7].文献[8]对于MEEI数据库中的语音数据提取了MFCC特征,使用高斯混合模型建立模型,在语音模型的相似性度量中,对KL距离和巴氏距离进行了改进,使用支持向量机(Support Vector Machine, SVM)进行识别,分别取得了96.5%和95.5%的识别正确率.文献[9]使用高斯混合模型作为统计模型,从语音中提取出小波域能量谱系数的统计学特征后进行识别,对病理语音的识别率达到97.45%.文献[10]基于声音强度提取出一种新特征,即修改语音轮廓(Modified Voice Contour,MVC),并运用支持向量机进行识别,在使用作者自行采集数据库作为实验数据时,达到了100%的识别率.虽然目前已经有较多对于由不同疾病导致的构音障碍的研究,但是大多数都采用了经典的MFCC和共振峰等单一特征,缺少将多种类型的特征融合后进行识别的方法.此外,识别的模型也大多局限于支持向量机、隐马尔科夫模型和高斯混合模型等.
韵律特征在表现语音的流畅程度、声调和节奏等方面性能较好[11],能在很大程度上弥补MFCC在进行语音识别时性能上的不足.随机森林(Random Forest,RF)作为一种集成学习算法,在处理大量数据和高维特征时具有良好的性能,训练速度快、模型泛化能力强[12].因此,笔者提出了一种结合MFCC与韵律特征的融合特征(Fusion Feature of Prosody and MFCC, FFPM),并采用随机森林算法,将两者应用于脑瘫导致的构音障碍识别中.
文中首先针对不同性别的被试,分别采用单一特征与融合特征进行对比研究,验证融合特征对于单一特征的优化作用.在此基础之上,去除性别差异,在整体数据上再次实验,测试不同分类器下单一特征与融合特征的分类精度,从而匹配出最优特征与分类器组合.
1 基于MFCC和韵律特征的FFPM特征提取
1.1 韵律特征
韵律特征,又名超音段特征,体现了语音信号强度和语调的变化.韵律作为语音识别研究中常用的特征,已经取得了一些理想的识别结果.构音障碍说话人在表达较长语句时,其声音强度和流畅度与正常说话人差别明显.常用的韵律特征主要有:
(1) 语速(speed).即时长和发音音节数的比值.
(2) 过零率(zero crossing rate).一帧语音中语音信号波形穿过零电平的次数称为过零率.定义语音信号x(m)的过零率为
(1)
(3) 能量(energy).设第n帧语音信号的短时能量用En表示,则
(2)
(4) 共振峰(formant).当元音激励进入声道时会引起共振特性,产生一组共振频率,即共振峰.它反映了声道谐振特征.
(5) 基频(pitch).即发浊音时声带振动的频率,人在发音过程中,由于声门瞬时闭合,声道被强烈激励,表现在语音波形上就是此瞬间幅度剧增,产生突变.相邻两个声门闭合之间的时间长度的倒数就是该处的基音频率.
1.2 梅尔频率倒谱系数
梅尔频率是一种根据人耳听觉特性构造的一种语音特征参数.由于人耳所听到的声高与频率并不是线性对应关系,而是更接近于对数关系,因此梅尔频率尺度更能准确地对应人耳的听觉特性.它与频率的关系可表示为
Fmel=2 595 lg(1+fHz/700) .(3)
提取MFCC时,步骤如下:
(1) 进行预加重.首先使信号通过一个高通滤波器:H(Z)=1-μz-1,其中μ取0.97.
(2) 进行分帧和加窗.帧长设定为256,帧移为128.每一帧都乘以Hamming窗,窗函数为
w(n)=0.54-0.46 cos[2πn/(N-1)] , 0≤n≤N.(4)
(3) 进行快速傅里叶变换,得到各帧的频谱.设输入信号为x(n),则语音信号的离散傅里叶变换(Discrete Fourier Transform,DFT)为
(5)
得到频谱后再对频谱取模平方得到功率谱.
(4) 将功率谱通过一组梅尔尺度的三角滤波器组,滤波器阶数为24.再将结果取对数,即
(6)
(5) 经离散余弦变换后,可得到MFCC系数为

(7)
1.3 FFPM特征的构成
文中提取了语音的语速、过零率、能量、基频以及第1、第2和第3共振峰(F1,F2,F3)作为韵律特征,然后计算其统计函数,并融合了MFCC的统计函数,组成最终的融合特征,即FFPM特征.特征集合表示为
Fu={s,z,E,P,F1,F2,F3,M1,M2,…,Mk} ,(8)
其中,s为语速;z为过零率;E表示由能量的统计参数构成的向量,即
(9)
其各量依次为最大值、最小值、均值以及一阶差分的最大值、最小值和均值;P表示由基频的统计参数构成的向量,即
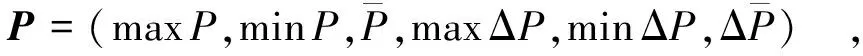
(10)
其各量依次为最大值、最小值、均值以及一阶差分的最大值、最小值和均值;F1、F2和F3表示由第1、第2和第3共振峰的统计参数构成的向量,即
其各量依次为最大值、最小值、均值、方差以及一阶差分的最大值、最小值、均值和方差;Mk表示第k阶MFCC的统计参数构成的向量,即
(14)
其各量依次为偏度、峰度、均值、方差和中值;式(14)中,偏度计算公式为
S(Mk)=E(Mk-μ)σ3.(15)
峰度计算公式为K(Mk)=E(Mk-μ)σ4-3 .(16)
在文中,k值取12,最终构成98维的FFPM融合特征.
2 随机森林分类器
随机森林是一种集成学习方法,其基本思想是每次从训练样本中随机选取部分特征来构建独立的决策树,然后重复这个过程,且保证每次都是等概率地抽取特征,直到构建了足够多且相互独立的树,分类结果由这些树通过特定的规则共同决定[8].随机森林以K棵决策树{h(X,θk),k=1,2,…,K}作为基分类器进行集成学习,其中{θk,k=1,2,…,K}是一个随机变量序列, 其构成方式遵循以下思想:
(1) Bagging: 从原始样本集X有放回地随机抽取K个与原始样本集同样大小的训练样本集{Tk,k=1,2,…,K},并且由每个训练样本集Tk构造一棵决策树.
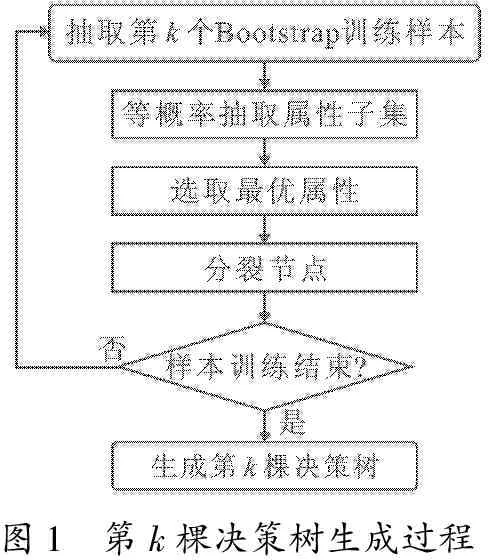
图1 第k棵决策树生成过程
(2) 特征子空间:对决策树的每个节点进行分裂时,从全部属性中等概率抽取一个子集,再从此子集中选取一个最优属性来分裂节点.
在构建每棵决策树时,抽取训练样本集和属性子集的过程各自独立,且总体相同,所以{θk,k=1,2,…,K}为独立同分布的随机变量序列.第k棵决策树的训练过程如图1所示.
把以同样的方式训练得到的k棵决策树组合起来,就可以得到一个随机森林.当输入待分类的样本时,由每个决策树的输出结果进行投票(取众数),就会得到随机森林的最终分类结果.相比于单个决策树,随机森林具有更强的分类能力,且有效地避免了过拟合.此外,随机森林作为分类器时,不需要对特征进行降维,且在处理大量数据时也比支持向量机识别率更高,速度更快.文中,不限制随机森林的决策树深度,树的数量选择为100.
3 TORGO数据库
3.1 数据库概况
选用由加拿大多伦多大学计算机科学与语音病理学系联合Holland-Bloorview Kids Rehab hospital共同开发的TORGO脑瘫病人数据库[9],此数据库包含了总时长为 23 h 左右的英文语音数据,同时含有与声音数据同步的发音动作数据.构音障碍患者类型为脑瘫或肌萎缩性脊髓侧索硬化症(Amyotrophic Lateral Sclerosis,ALS).数据库基本构成情况如表1所示.

表1 TORGO数据库概况
3.2 数据库筛选
从数据库中选择了短语和限制句作为语料来源,两者的构成情况如表2所示.
其中,对于不需要探究词界的语音声学研究来说,短语是非常有用的,它可体现出说话人对单个词汇的发音能力.选用限制句是为了评判说话人利用词汇、语法和进行语义处理时的能力,构音障碍人在这方面的能力与正常人存在较大差距.

表2 短语及限制句来源

表3 筛选后数据构成情况
文中选择来自全部15位被试的限制句和短语语音数据.在原有数据中,有一小部分数据存在被试发音错误,录制设备发出噪音和治疗师发出声音的问题,此类情况在构音障碍患者的音频数据中尤为突出.为避免因音频数据的质量影响实验,在进行实验之前对原始数据库进行了筛选,以求将客观因素影响减到最小.同时使用了改进的相位补偿语音增强算法[14]对筛选后的语音数据进行了处理,目的是最大限度地减少噪声干扰.表3中显示了筛选后的数据构成情况.
4 实 验
进行了单一类型特征以及FFPM特征在不同分类器下的识别率对比实验,共有9种组合形式,分类器选取了支持向量机,C4.5决策树和随机森林.其中,支持向量机使用线性核函数,C4.5决策树置信因子设置为0.25,每个叶的最小实例数量设置为2.然后,从筛选后的数据中,选取66%作为训练集,34%作为测试集,并采用10折交叉验证法来检验特征和识别网络的性能.
4.1 基于性别的融合特征性能测试
为测试所提FFPM融合特征针对不同性别的识别性能,设计了2组试验,分别测试在使用限制句和短语作为语料时,单一特征和FFPM特征的识别率.
从图2可以得出,在语料为限制句时,无论是对于男性还是女性,提出的FFPM识别准确率都比单独使用MFCC和韵律特征时更高; 无论使用何种分类器,FFPM的识别正确率都高于另外两个单一特征;在仅使用韵律特征时,对女性声音的识别率明显低于男性,韵律特征在表现女性语音特征时性能不佳.在女性声音的识别上,FFPM相比于单一的韵律特征和MFCC特征都有显著提升,使用随机森林分类器后识别率达到99.62%.说明相较于单一特征,融合特征在识别性能上确实有优化作用.此项实验为后续分类器选择的实验奠定了基础.
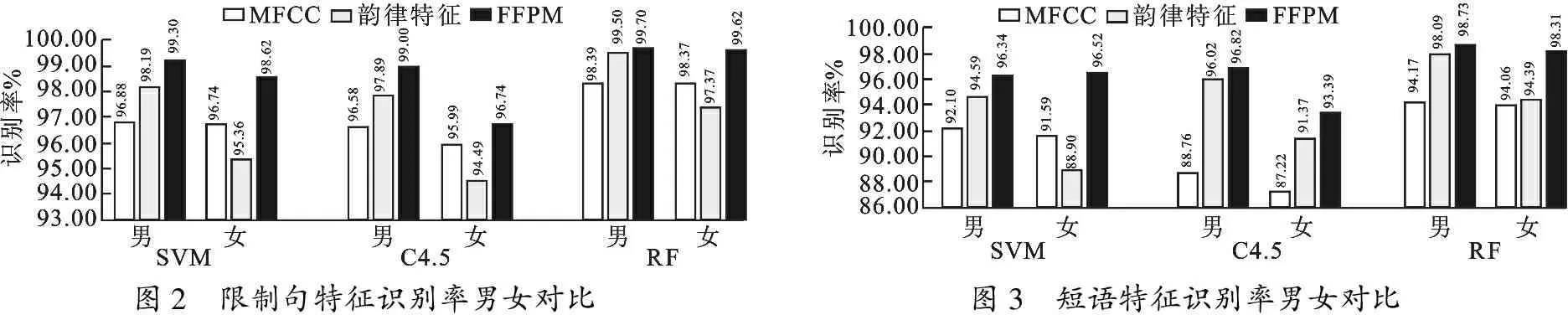
图2 限制句特征识别率男女对比图3 短语特征识别率男女对比
从图3可以看出,与限制句的识别率相比,短语的识别率整体偏低.这个现象反映出,相比于句子,构音障碍患者能够较为正确地对短语进行发声,因此在进行识别时,其语音特征与正常说话人之间差异较小,一定程度上会影响分类结果.同样,韵律特征在进行女性语音的识别时表现不佳,但FFPM将女性声音的识别率提升到了98.31%.上述两个实验中,对于男性声音的平均识别率达到99.21%,对女性声音的平均识别率达到98.97%.
4.2 综合对比测试
设计了两组对比实验,去除性别因素,只针对两种语料类型分开实验,目的为测试不同分类器下单一特征与融合特征的分类精度,从而匹配出最优特征与分类器组合.
从图4可以看出,在语料为限制句时,韵律特征和随机森林的组合达到了96.49%的识别率,比MFCC和随机森林的组合高出了3.57%,但是考虑到在4.1节的实验中,韵律特征在女性声音的识别中表现不佳,若增加实验中女性被试的人数,识别率必定会明显下降;使用FFPM特征和随机森林算法的组合所达到的识别准确率最高,比MFCC和C4.5的组合高出12.16%,比韵律特征和支持向量机的组合高出11.71%.从分类器的角度出发进行对比,随机森林比另外两个分类器的识别率高出约6%,优势较为显著.

图4 限制句特征识别率对比图5 短语特征识别率对比
从图5可以看出,短语的特征识别率类似于限制句,但是整体略低.其中,支持向量机作为识别网络、MFCC作为特征时识别率都相对较低,相比之下,当FFPM和随机森林组合时,识别率达到了97.95%,体现了将频谱特征和时域特征结合后的性能优势,以及随机森林分类器对高维特征向量的良好识别率.上述两个实验的平均识别率达到98.00%.
综上所述,文中提出的包含韵律特征和MFCC的FFPM与随机森林算法组合的方式所表现出的性能最优.由此可以说明,FFPM特征可以更好地诠释患者与正常人之间的差异,同时选用随机森林算法进行分类识别,可以取得理想的效果.
5 结 束 语
基于语音数据和机器学习进行的构音障碍评估和诊断日益重要,但传统的单一声学特征往往并不能很好地表现患者与正常人之间的差异,同时,传统的支持向量机在处理大数据量时表现不佳,并且运算速度慢;决策树极易发生过拟合的现象.鉴于此类情况,文中对语音数据提取了包括MFCC和韵律特征在内的FFPM特征;并引入随机森林作为分类器,实现了对样本的集成学习.在实验中,首先通过针对不同性别的被试,分别采用单一特征与融合特征进行对比研究,验证了融合特征对于单一特征的优化作用.在此基础之上,去除性别差异,在整体数据上再次实验,测试不同分类器下单一特征与融合特征的分类精度,从而发现了FFPM和随机森林为性能最优的组合.同时经过实验发现,相比于句子,构音障碍患者对短语的发音能力更强,发音较为准确.在今后的研究中,将考虑寻找更好的特征融合方式,以期实现更高的识别率.除此之外,建立普通话说话人的数据库,用现有方法进行训练和识别,也是未来的研究方向.
[1] DOYLE P, LEEPER H, KOTLER A L, et al. Dysarthric Speech: a Comparison of Computerized Speech Recognition and Listener Intelligibility[J]. Journal of Rehabilitation Research and Development, 1997, 34(3): 309-316.
[2] 刘伟, 陈刚, 迟广明. 脑瘫治疗的现状[J]. 中国康复理论与实践, 2007, 13(12): 1118-1120.
LIU Wei , CHEN Gang , CHI Guangming. Current Treatment of Cerebral Palsy [J]. Chinese Journal of Rehabilitation Theory and Practice, 2007, 13(12): 1118-1120.
[3] BAGHAI-RAVARY L, BEET S W. Automatic Speech Signal Analysis for Clinical Diagnosis and Assessment of Speech Disorders[M]. Springerbriefs in Electrical and Computer Engineering. Berlin: Springer, 2013.
[4] RUDZICZ F, NAMASIVAYAM A K, WOLFF T. The TORGO Database of Acoustic and Articulatory Speech from Speakers with Dysarthria [J]. Language Resources and Evaluation, 2012, 46(4): 523-541.
[5] GUPTA R, CHASPARI T, KIM J, et al. Pathological Speech Processing: State-of-the-art, Current Challenges, and Future Directions[C]//Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2016: 6470-6474.
[6] GODINO-LLORENTE J I, GOMEZ-VILDA P, BLANCO-VELASCO M. Dimensionality Reduction of a Pathological Voice Quality Assessment System Based on Gaussian Mixture Models and Short-term Cepstral Parameters[J]. IEEE Transactions on Biomedical Engineering, 2006, 53(10): 1943-1953.
[7] 袁亚南, 何凌, 龚晓峰, 等. 基于MFCC和HMM的腭裂语音辅音省略识别算法[J]. 计算机工程与设计, 2014, 35(2): 615-619.
YUAN Ya’nan, HE Ling, GONG Xiaofeng, et al. Recognition Algorithm of Consonants Omission for People with Cleft Palate Based on MFCC and HMM [J]. Computer Engineering and Design, 2014, 35(2): 615-619.
[8] AMARA F, FEZARI M, BOUROUBA H. An Improved GMM-SVM System Based on Distance Metric for Voice Pathology Detection[J]. Applied Mathematics and Information Sciences, 2016, 10(3): 1061-1070.
[9] 常静雅, 张晓俊, 顾玲玲, 等. 小波域能量谱和非线性降维的病理嗓音识别[J]. 计算机工程与应用, 2017, 53(2): 166-171.
CHANG Jingya, ZHANG Xiaojun, GU Lingling, et al. Wavelet Domain Energy Spectrum and Nonlinear Dimensionality Reduction in Pathological Voice Recognition[J]. Computer Engineering and Applications, 2017, 53(2): 166-171.
[10] ALI Z, ALSULAIMAN M, ELAMVAZUTHI I, et al. Voice Pathology Detection Based on the Modified Voice Contour and SVM[J]. Biologically Inspired Cognitive Architectures, 2016, 15: 10-18.
[11] 姚慧, 孙颖, 张雪英. 情感语音的非线性动力学特征[J]. 西安电子科技大学学报, 2016, 43(5): 167-172.
YAO Hui, SUN Ying, ZHANG Xueying. Research on Nonlinear Dynamics Features of Emotional Speech[J]. Journal of Xidian University, 2016, 43(5): 167-172.
[12] BREIMAN L. Random Forests[J]. Machine Learning, 2001, 45(1): 5-32.
[13] WRENCH A. The MOCHA-TIMIT Articulatory Database [DB/OL]. [2017-05-06]. http://www. cstr. ed. ac. uk/artic/mocha. html.
[14] 王栋,贾海蓉. 改进相位谱补偿的语音增强算法[J]. 西安电子科技大学学报, 2017, 44(3): 83-88.
WANG Dong, JIA Hairong. Speech Enhancement Using Improved Phase Spectrum Compensation[J]. Journal of Xidian University, 2017, 44(3): 83-88.
