激发更大的“社会学想象力”
2018-06-11唐斌斌付双乐刘林平
唐斌斌 付双乐 刘林平
[摘要]基于130篇SSCI社会学大数据文献,本文从文章类型、引用次数、作者信息、大数据类型、处理工具、分析方法和研究价值等方面进行了分析。研究发现,社会学大数据实证研究偏少;作者活跃度不高;使用比较多的大数据类型包括网络社交数据、行政数据、企业数据和谷歌图书语料库数据;利用R、Python和Gephi等编程语言和软件进行大数据挖掘、分析和可视化;传统的统计分析方法仍占一定比例,但机器学习方法开始得到运用。大数据给社会学研究注入了新的活力,有助于激发更大的“社会学想象力”、获得更好的社会测量和开展更深入的实证研究。
[关 键 词]社会学 大数据 计量分析 前沿进展
[中图分类号]C91 [文献标识码]A [文章编号]1008-7672(2018)05-0050-16
一、 引言
Savage和Burrows在《实证社会学即将面临的危机》一文指出,以抽样理论、调查设计、定性访谈为标志的实证社会学在方法论上严重落后,这与当代社会学家固守常规方法、忽视现代生活激增的数据洪流有关。他们认为,尽管抽样调查和定性访谈仍然是重要的研究手段,但这种状况在未来会慢慢被边缘化甚至被抛弃。因此,他们呼吁,社会学家必须对实证社会学的方法论进行彻底反思,必须更多地思考如何才能更好地与大量的社会数据联系起来。
他们在文中并没有明确提出“大数据”概念,但该文是近10年来社会科学讨论大数据相关议题被引用最多的文献之一。社会学家对大数据及其研究的看法争议不断,有学者对此提出严厉批评,代表性人物有Boyd和Crawford等。他们认为,与其他社会技术现象一样,大数据存在六大挑战:(1)改变了知识的定义,但提供的是缺乏哲学力量的知识和信息;(2)声称客观和准确是有误导性的;(3)并不总是更好的数据;(4)脱离上下文,失去意义;(5)挑战研究伦理;(6)制造更大的数据鸿沟。
另有研究者从更具体的角度提出批评。在他们看来,大数据研究中的数据、方法和理论都值得怀疑。首先,数据有可能是偏倚的或者是不完整的,这些数据只捕获了某些活动,特别是某些人使用特定的设备和应用程序来记录特定信息的活动;其次,大数据分析过于依赖计算方法和“黑盒”分析工具,伴随一些几乎无意义的问题或概念解释;更重要的是,对模式(算法)和相关性的强调忽视了理论上值得探究的问题,并取代了社会学核心的解释学和批判分析。
尽管批评者诘难颇多,但社会学界及更多社会学家仍然以宽广的胸襟拥抱大数据。首先,众多的公共资助机构、私人基金会和数十家大学推动了“大数据”或“数据科学”的项目发展。例如,2014年,欧洲PMC赞助商集团(Europe PMC Funders Group)赞助举办了一个名为《大数据与社会》(Big Data & Society)的新学术期刊,该期刊主要为社会科学和相关交叉学科讨论大数据对社会的影响提供一个辩论空间,向公众传播大数据如何重新配置学术、社会、工业、商业和政府关系等专业知识。其次,更多社会学家认为,忽视大数据是抛弃了对社会研究至关重要的一系列问题,不利于社会学方法和理论的不断发展。现代社会是一个数字信息社会,社会学与数字结合是恰当的,社会学家还在学习和改进他们的方法和计算技能,随着时间的推移,相关的大数据研究将会提供新的知识。
因此,本文试图综述大数据在社会学研究中的情况,以拓宽人们对社会学大数据研究的理解。具体而言,本文的目标是:
第一,描述社会学领域发表的大数据文献基本情况;
第二,探讨社会学大数据文献中使用的数据类型、处理工具和分析方法;
第三,分析社会学领域的大数据研究价值;
第四,总结和讨论社会学领域的大数据研究现状和未来发展建议。
总之,本文将对社会学领域的大数据文献进行较为全面的综述。本文主要分为六个部分:第二部分,主要介绍本文的数据来源和大数据在社会学中的定义;第三部分是对大数据文献的基本情况进行分析,包括文献类型、引用情况和作者信息等,以期为读者勾勒出一个整体性的社会学大数据文献图景;第四部分则着重介绍大数据文献使用的数据类型、处理工具和分析方法,让读者对社会学大数据研究有一个更为细致的了解;第五部分则是阐述大数据研究价值,具体包括对社会学的理论发展、方法突破和实证研究深入等方面的巨大机遇;第六部分是结论和讨论,指出社会学大数据研究现状和未来发展建议。
二、 数据来源和大数据定义
(一) 数据来源
2018年5月,笔者利用科学引文索引(Web of Science)数据库检索大数据文献。首先,选择Web of Science核心合集数据库中的社会科学引文索引子数据库,以保证搜索的期刊全部来自SSCI核心期刊;然后,将搜索主题限定在“大数据”(“Big Data”)。为了比较社会科学和社会学的大数据发文量变化趋势,笔者将搜索领域限定在社会科学和社会学领域,所搜索的文献里只要标题、摘要、关键词涉及到大数据一词就会被检索出来。搜索结果显示,社会科学大数据文献有3305篇,社会学大数据文献有130篇,可以看出,社会学大数据文献所占份额有限,仅占4%。具体情况见表1。
大數据作为一个新兴术语,进入社会科学和社会学视野并不算早。从搜索结果来看,社会学SSCI期刊在2011年才开始出现与大数据相关的研究主题,这与Burrows和Savage通过谷歌趋势(Google Trends)分析所得到结果差不多。此后,大数据文献数量随着时间的发展而增多,所讨论的主题也从最开始的大数据介绍、争论到大数据分析、方法改进等,从整个发展脉络来看,社会学大数据研究经历了“从争议到改善”的发展态势,显示社会学开始积极关注大数据研究。
(二) 大数据在社会学中的定义
大数据是强大且流行的概念,它已经被广泛应用于各个领域,但这种“共同出处导致了多重的、模糊的、甚至常常矛盾的定义”。大数据最开始作为一个商业术语,是由甲骨文、英特尔、微软和IBM等信息技术公司根据其特征来定义的,其中使用比较广泛的定义是美国高德纳公司的分析师道格拉斯·兰尼提出的“3V”(容量大、速度快、多样性)概念,后来又拓展到“4V”(容量大、速度快、多样性、低价值密度)、“5V”(容量大、速度快、多样化、低价值密度、准确性)。
社会学对大数据的界定也是含混不清的。一些学者从大数据特征出发,认为社会学中的大数据也具有庞大、快速、异构和数字化四个特征,与大数据的商业概念不同的是,这一定义将焦点从数据本身的特征转移到大数据收集和分析的社会过程,即强调数据环境。例如,这里的重点不是关注大数据的“多样性”,而是强调从不同的机构数据源收集大数据。
另一些学者从大数据的表现形式出发,认为除了体量大之外,“大数据是一个非常多样化的术语”、“大数据有多种形式”。这些数据包括文本内容(如推文、博客)、多媒體内容(如视频、图像、音频)以及多种平台数据(如机对机通信、社交媒体网站、传感器网络、网络物理系统和物联网)。Kshetri声称,“社交媒体、手机和其他数字通信工具产生的大量数据……,是真正的大数据形式”。
还有一些学者则将大数据视为一种复杂的现象,它是由文化、技术和学术相互作用构成:在技术方面,最大限度地提高计算能力和算法精度,收集、分析、链接和比较大型数据库;在分析层面,利用大数据识别模式,实现“经济、社会、技术和法律主张”;在观念神话方面,普遍相信大数据可以产生以前无法获取的知识,这些知识被认为是真实、客观、准确的。
可以看出,尽管大数据的定义是多样化的,但至少有一点可以肯定,社会学领域的大数据是关于社会生活数字化所产生的大数据,或者是一种大数据分析、大数据技术。这些定义将大数据的讨论从其起源重要性的问题中脱离出来。
三、 大数据文献基本情况
为了勾勒出一个大致的社会学大数据研究图景,笔者首先对获得的130篇社会学SSCI大数据文献进行了类型分析;其次,对这些文献的引用和被引情况做了一个梳理;再次,进一步对这些文献的作者基本情况进行了一个描述。
(一) 文献类型
从表2可以看出,社会学SSCI大数据文献中理论类文献最多,超过50%,其次是实证类文献和方法类文献。这可能是因为,大数据作为一种新型数据,当社会学打算探讨大数据并利用大数据来开展研究时,必然要回答两个基本问题:(1)什么是大数据?(2)利用大数据从事研究有什么利弊?为了回应这些问题,许多期刊刊发了大量文章,比如《社会学》(Sociology)、《社会学年评》(Annual Review of Sociology)、《媒体、文化与社会》(Media, Culture & Society)等重要刊物从大数据定义、大数据来源、大数据潜力和不足等方面进行了较为全面的理论探讨和观点碰撞。
同时,大数据在数据获取、管理和处理方面是常规的方法和软件工具所不及的,这引发了学者进一步探索、开发新的方法和工具的热潮。比如,如何用迭代的方式自动分析大量文本;如何使用 APP技术对使用社交媒体的组织收集和分析数据等。
从百分比来看,大概有27%是使用大数据进行实证研究的文献。但细致分类下来,探索性研究比较多,占了实证类文献的89%,而验证类的文献仅仅占11%,说明目前的社会学大数据研究还处在摸索阶段。值得注意的是,实证类文献中有48.5%的研究不仅仅是停留在对大数据的描述统计上,而是将描述和分析两者结合起来,这在一定程度上可以看出,大数据研究开始往深入分析方向发展。
总之,社会学的大数据研究,不管是理论上的探讨、观点上的碰撞、还是方法上的创新,抑或是利用大数据开展的经验研究,已经吸引了越来越多的学者加入阵营。且不论学者们对大数据是支持还是反对,对开展的大数据实证研究是赞扬还是批评,那些睿智的学术观点、严谨的研究方法,最终丰富和发展了社会学的大数据研究。
(二) 文献引用和被引
笔者对这130篇社会学SSCI大数据文献的引用和被引现象进行了分析。引用是指文献引用其他学者文献的情况,被引是指文献被其他学者引用的情况。一般来说,一篇文献要引用其他学者的研究,是想要和对方进行文献对话,从而发现新知,而文献被他人引用,则可能是该文献具有重要的学术价值。因此,通过对文献的引用和被引情况分析,特别是对高引和高被引文献的分析,既可以评价该文献的学术影响力,也可以客观反映该研究领域的研究基础和发展走向。
为了分析130篇社会学SSCI大数据与哪些学者进行对话,笔者利用CiteSpace软件提取了这些文献中共5897条参考文献。通过分析,获得了引用次数10次及以上的6篇高引用文献,并对其进行了可视化处理,见图1。
此外,笔者整理了这130篇社会学SSCI大数据文献被引用的情况。从表3可以看出,截至目前,完全没有被引用的文献有32.3%,被引1-10次的文献有55.4%,被引11次以上的文献加起来只有12.3%,可见大部分文献的被引用次数不高,这可能是因为这些文献大部分集中在2014年至2017年发表的,公开发表时间还不长,还没有完全传播开来。
接下来,笔者具体分析引用和被引比较高的若干篇文献。发现,Boyd和 Crawford发表的《大数据的关键问题》(Critical Questions For Big Data)一文引用次数非常高,累计引用905次,其中被其他社会学SSCI大数据文献引用超过38次,表明该文具有重要的学术价值。正如前文所述,该文认为大数据时代已经开始,各类专家学者都热烈呼吁获取大数据,但大数据是否能帮助人们创建更好的工具、服务和公共产品?作者对这个问题的回答是悲观的,他们认为大数据是一种基于技术、分析和神话相互作用的现象,它存在“六大挑衅”,引发广泛的乌托邦和反乌托邦式的讨论。
其他引用和被引用较高的文献大致可以分为两类,一类是对大数据的介绍和讨论;一类是对大数据方法和分析工具的改进和完善。可以看出,目前的社会学大数据研究在大数据讨论和方法上关注颇多,而利用大数据进行的相关经验研究暂时还没有得到足够的关注。
(三) 文献作者信息
另外,笔者对文献作者的基本情况进行分析。这样做可以从整体上了解社会学大数据研究的分布和合作状况。
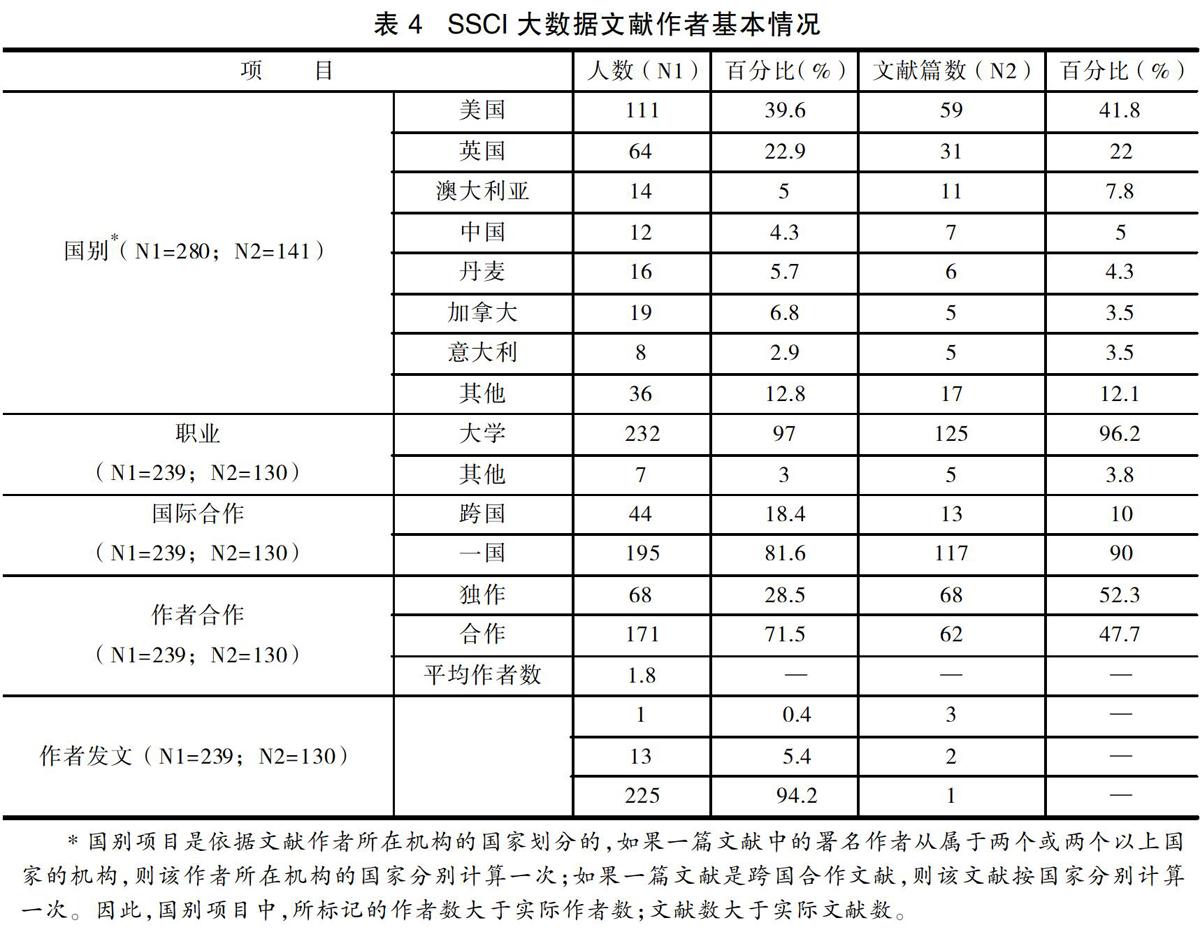
从表4可以看出,在这130篇社会学SSCI大数据文献中,在国家分布方面,美国在SSCI期刊发表社会学大数据文献的研究人员有111人,遥遥领先英国、澳大利亚、中国、丹麦、加拿大和意大利等国,发表文献数量占总文献数量的41%。紧接着的是英国,有64位研究员在SSCI期刊发表了占总文献的22%的大数据文献。可见,美国、英国在社会学大数据研究领域有着众多的科研人才和强大的科研能力。值得注意的是,在社会学SSCI期刊发表大数据文献的作者中,占4.3%的研究人员来自中国,他们参与发表了7篇大数据相关文献,占全部文献的5%,这表明中国在国际大数据研究舞臺上开始崭露头角。事实上,中国庞大的人口和多元化的产业组合可以产生大量的数据,对学者而言,无疑是一个珍贵的数据宝藏。
在职业分布方面,大学等教育机构是研究人员主要的任职机构。232位作者在教育机构任职,他们依托教育机构发表了大量文章,发表文献总数超过120篇,但也有7位作者是在一些研究中心或者公司企业任职,他们也发表了具有重要学术价值的文章,比如,上文提及到的Boyd和Crawford,他们来自微软研究院新英格兰研究所,2012年在《信息、沟通与社会》期刊上发表了一篇高被引文章。
在国际合作方面,学者们对跨国合作的兴趣好像并不高,只有18.4%的研究人员参与了跨国合作,发表的文献数量也只有13篇,只占全部文献的10%。但作者合作方面,只有一位作者的文章数量有52.3%,有两个或两个以上作者的文章数量有47.7%,两者几乎平分秋色,将作者总数量和文章总数量平均下来看,一篇文章大概可以达到2位作者,说明在社会学SSCI大数据文献中,多位作者合作发表文章是一个趋势。
总体来看,研究大数据主题的研究人员还是比较多的,数量达到了329名。但值得注意的是,发表3篇大数据文献的研究人员只有1名,发表2篇文献的研究人员只有13名,剩下225名研究人员都只发表1篇文献,可见,相关的研究人员活跃度不高,离散度很大,迄今为止,主导社会学大数据研究领域的专家并不多。
综上,笔者从文章类型、引用次数和作者信息等方面进行了较为全面的描述和分析,笔者认为,目前社会学大数据研究还处于起步阶段。尽管大数据研究文献数量呈上升态势,但大部分文章属于介绍、讨论类的,实证类、方法类文章偏少,而且在实证类文献中,又以探索类居多、验证类偏少;那些高引用和高被引文章表明,目前对大数据本身的讨论和方法改善方面关注颇多,而利用大数据进行的经验研究暂时还没有得到更多的关注;大部分作者和研究文献来自美国、英国等欧美国家,中国在这个领域才刚刚有所展示;这些作者更多的是在教育机构任职的老师、研究员,他们跨国合作不多,但同一国家或地区多作者合作发表文章已经成为了常态,只是活跃度不高,离散度大,主导社会学大数据研究领域的专家不多。
四、 大数据应用分析
社会学家使用什么样的大数据?采用什么样的工具处理大数据?常用的统计分析方法又有哪些?通过进一步对大数据在社会学应用研究情况的分析,有助于我们对社会学大数据研究现状有一个更为细致的了解。
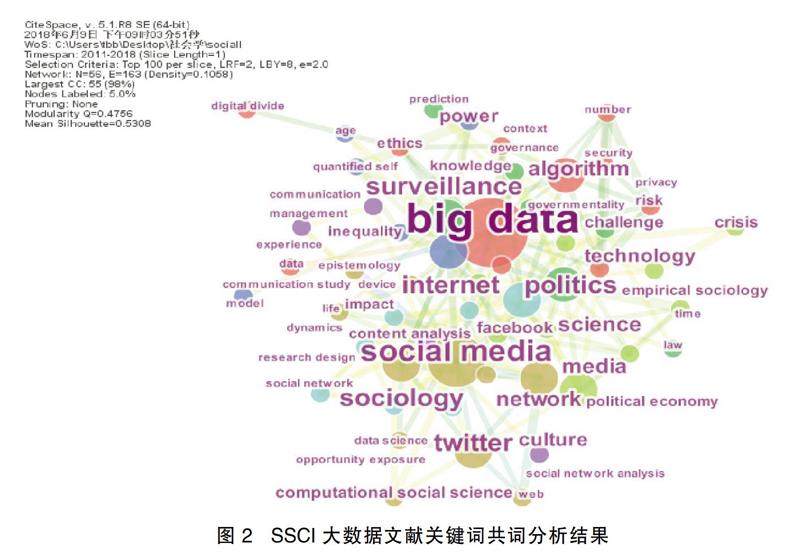
笔者首先通过关键词共词分析来了解大数据在社会学中的应用情况。关键词是一种自然语言的索引语言,它是从文献标题、摘要和正文中抽取出来,用以揭示和描述文献内容信息的词语或术语。共词分析是一种文本内容分析技术,旨在通过分析同一文本主题的款目对(单词或名词短语)共同出现形式来探究文本所代表的学科发展。本文通过对社会学130篇SSCI大数据文献进行关键词共词分析,分析结果见图2。需要说明的是,图中显示字体的大小代表了该关键词出现频次的多少,字体越大说明相应的关键词出现次数越多。
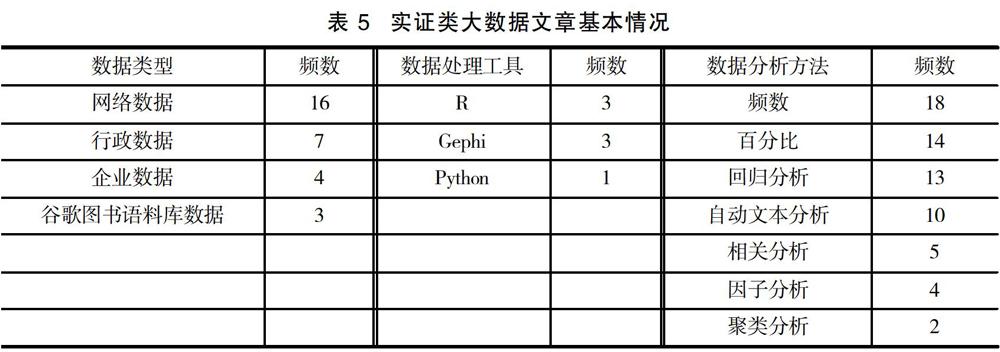
从图2可以看出,出现次数比较多的关键词有 “大数据”、“社会媒体”、“社会学”、“政策”、“监视”、“网络”、“推特”、“脸书”、“算法”、“文本分析”、“社会网络”等词语。为了更进一步分析,笔者对130篇社会学SSCI大数据文献中有报告数据类型、数据处理工具和统计方法的实证研究做了一个不完全统计。见表5。
(一) 数据类型
大数据类型多种多样,包括文本、几何图形、图像、视频、声音以及每个组合。Lazer和Radford认为,大数据可能来自三个方面:数字生活,本质上是数字化的行为数据;数字痕迹,是一种行为记录而不是行为本身的数据;数字化生活,以数字形式捕捉非本质数字生活的数据。从表5来看,社会学家经常使用的大数据类型包括Twitter、Facebook等网络行为数据;城市管理、政治选举等行政记录数据;电子商务、酒店耗能等企业记录数据;谷歌图书语料库等数字化数据。
1. 网络数据
网络数据是社会学家经常使用的大数据类型之一,其中又以Twitter、Facebook这类网络行为数据为主。Twitter是一个信息传播平台,有超过3亿活跃用户,注册用户每天发布5亿条推文,是世界上访问量第8大的网站,被描述为“互联网的短信”。Twitter允许用户选择在每条推文中包含地理元数据(VGI),当他们发布推文时,每条推文包含了发送消息的城市、州和国家以及纬度和经度坐标。这给了一个观察人们何时何地讨论特定话题的机会。推文本身很小,每条推文只有140个字符,但随着时间的推移,大量的用户和推文迅速积累,构成了Twitter微观内容“大数据”。研究者利用大量推文集合,可以提供描述性内容分析、情感分析、影响分析等话题。
与Twitter注重信息传播、观点表达不同,Facebook是世界上最大的社交媒体网站,主要提供社交服务,月活跃用户数量达到22亿。Facebook在2009年推出的Like按钮是Facebook上最常用的功能,“喜欢”可以用于多种不同的目的,包括运动、娱乐、社交和公民表达。因此,Facebook Like被证明是各种属性的可靠预测者,如幸福、种族、宗教和政治观点、性取向和一系列个性特征。此外,Facebook以各种方式影响人们的社交、生活、沟通和情绪健康,许多研究者利用Facebook大数据探索用户行为研究。
2. 行政数据
行政数据一般可以被描述为源自行政系统运行的数据,这些数据可以来自广泛的管理系统,如教育、医疗、税收、住房或车辆许可等,还包括来自登记注册的信息,如出生、死亡和婚姻通知、选举登记和全国人口普查等。行政数据不是为研究目的而被收集的;它可能是大而复杂的,但又没有社交媒体、交易数据那么大;它本质上是多维度的,通过数据链接将数据集连接在一起来获得回答社会科学研究问题所需的所有信息;它通常是总体数据,从整个人口中检索信息,而不是从样本中检索。Connelly等认为,行政数据完全符合大数据定义,也是一种大数据。
一些学者使用行政大数据开展了相关和有影响力的研究。Heerwig使用来自美国官方联邦选举委员会(FEC)披露的超过1500万捐款记录构建的原始大数据集,分析了个人捐赠对众议院候选人的募款影响。该研究为重新评估个体捐赠者在竞选募款中扮演的角色多样性以及系统地分析捐赠者捐款策略变化提供了一个有说服力的案例。Brien利用波士顿市收到的超过60万份政府服务请求数据,来探究个人是如何增益城市社区福利的。研究表明,无论是报告城市社区的自然恶化还是公共不文明行为,个体的服务申请都是捍卫社区的一种表达,不同之处在于,报告公共领域问题表达的是个人对空间的爱护,报告他人越轨行为问题表达的是对空间的维护。
行政数据对社会不平等、人类行为和社会政策的研究提供了深刻的见解。对于特殊群体、小群体和某些罕见事件的研究具有明显的优势。
3. 企业数据
近些年來,学界和商界对企业大数据,尤其是对电子商务、连锁酒店等领域的企业大数据表现出越来越浓厚的兴趣。
在电子商务领域,所谓的大数据是指通过消费者浏览和交易点收集的记录数据。电子商务公司大数据大致可分为四类:交易或业务活动数据,点击流数据,视频数据,语音数据。一些研究者利用电子商务大数据研究消费者偏好、行为,帮助电子商务公司改善决策过程、降低成本并产生效益。
同样,连锁酒店每月产生的用电量和用水量构成了一个大型数据集。研究者利用这样的“大数据”对住宅、商业和工业部门的能源消耗进行了深入了解,利用这些数据实现减少经营支出和广泛的可持续性盈利的共同目标,提高并改善酒店能源效率。
4. 谷歌图书语料库数据
谷歌图书语料库是谷歌数字化图书的产物,大部分的书都来自世界上40多所大学的图书馆,这个语料库使用光学字符识别(OCR)对文本进行数字化,超过1550万册图书被数字化。在2009年第一版谷歌图书语料库中,质量较好的数字化文集超过500万本,由此产生的语料库包含超过5000亿个单词,包括英语(3610亿)、法语(450亿)、西班牙语(450亿)、德语(370亿)、汉语(130亿)、俄语(350亿)和希伯来语(20亿)。在2012年第二版谷歌图书语料库中质量较好的数字化文集扩充到811万本,其中英语语料库就有450万册图书和大约5000万字。谷歌书籍语料库的一个核心特征是,语料库反映了一个图书馆,在这个图书馆中,每本书都是可用的,谷歌图书语料库主要利用n-gram模型计算词汇出现的频率,因此,语料库更类似于文本集合的词典,而不是集合本身。
国外利用谷歌图书语料库进行了多项研究,在国内,陈云松利用谷歌图书语料库对19 世纪中期以来社会学的发展和近三百年中国城市的国际知名度进行了分析。从这些研究中可以看出,谷歌图书语料库有助于对长时间、大空间跨度的社会变迁、宏观社会文化发展开展定量分析,为文化社会学相关议题的研究提供全新的研究资料。
(二) 处理工具
由于大数据容量庞大且复杂,如何处理大数据一直是社会学家首要面临的问题之一。传统的数据处理软件不足以解决,需要开发新的工具。数据科学家利用其专业知识开发了许多大数据处理工具,从表5来看,目前社会学家更多的是借用R、Python、Gephi等编程语言和软件对大数据进行数据挖掘、数据分析和数据可视化。
R是统计计算和图形的语言和环境,它提供各种统计(线性和非线性建模,经典统计测试,时间序列分析,分类,聚类……)和图形技术,并且具有高度可扩展性。标准R可以很容易地处理包含100万记录的数据集,如果要处理更多的数据记录,比如10亿及以上的数据集,R需要和Hadoop数据处理应用程序框架交互使用,其方法有两种:第一,首先使用Hadoop将PB、TB量级的数据压缩到GB量级,然后再加载到R中进行分析;第二,直接利用支持Hadoop软件的R包来处理TB、PB量级的大数据。Python与R一样是优秀的处理大数据的编程语言,由于python很容易学习、使用,只要写少量的编程就能解决复杂的问题,而且python对数据处理量没有限制,因此,在大数据处理过程中备受社会学家们的青睐。
同样,数据可视化是大数据处理的一项重要内容,特别是利用大数据研究社交网络时,为了理解网络,许多重要的研究都采用数据可视化手段来帮助研究者对庞大而复杂的数据集进行深入洞察。可视化对利用人类的感知能力在网络结构和数据中发现特征是有用的,然而,这个过程本质上是困难的,需要深入探索。
Gephi软件则提供了很好的大数据可视化策略,它是一个社交网络可视化和操作网络软件,可以处理超过20,000个节点大型网络。所开发的模块可以导入、可视化、空间化、过滤、操作和导出所有类型的网络。而且,那些不会图论的社会科学家也能通过Gephi软件分析社交网络,因此,Gephi在社会学、生物学、基因组学等学科得到广泛应用。
总之,大数据作为规模超出一般数据库的数据集,对于传统的数据处理工具来说未免太大、太快、太复杂,一般的统计软件无法对其进行数据处理;需要新的处理技术来处理大数据,这实际上意味着,使用大数据开展相关研究需要向新的技术过渡。目前,社会学家借用的大数据处理工具更多的是数据科学家开发出来的,未来,社会学家需要进一步与数据科学家建立合作,不断改进和开发新工具。
(三) 统计分析方法
大数据的兴起对传统的统计分析提出了新的挑战。一些学者认为,由于大数据容量庞大,几乎等于总体样本,可以放弃对因果关系的追逐,仅仅采用频数和百分比等描述统计就能准确说明研究问题。从表5可以看出,目前社会学大数据研究采用频数、百分比、回归分析等传统的统计分析方法仍然占有一定比例,但由于大数据75%以上是非结构化的数据,其中主要是文本数据,如何对其进行统计分析是一个重要问题。在机器学习的推动下,对文本数据进行自动文本分析是大数据研究中发展比较快的数据分析方法。因此,本节主要对自动文本分析做简要介绍。
自动文本分析的核心任务是分类。在大数据时代,基于机器学习的自动文本分析有两种新兴技术:监督学习法和非监督学习法。监督学习方法和非监督学习方法具有不同的研究渠道,通过这些渠道,非结构化数据(如文本)转换为结构化数据,进而利用这些数据创建新的价值形式。
所谓的监督学习方法,就是研究人员事先阅读并编写训练文本,然后使用计算机自动对大量未阅读文本进行分类。具体而言,分析员从文本示例开始,在这些示例中,概念由他们自己或其他人标识和编码。这些概念可以是从先前的理论中获得的,从先前的争论中推导出来,或者在编码的过程中由研究者发现。然后将该示例分为训练子样本和测试子样本,监督学习方法利用与训练样本中的实例相关的特征来估计统计模型或调整算法。然后使用经过训练的模型或算法来预测测试样本中已识别但未标记的实例,以评估其成功与否。最后,使用成功的模型或算法来推断无标记的文本数据。监督学习方法包括K-近邻分析、简单贝叶斯估计、决策树等多种算法,这些算法可以最大限度地提高文本分析的可解释性、准确性。
无监督学习方法,即研究人员不需要手动对训练集进行分类,而是使用计算机根据所观察到的文本特征和一组假设自动对所有文本进行分类。无监督学习方法从无注释文本的语料库开始,然后发现并表示新的解释结构。它主要有4种常见的算法:聚类、网络分析、主题建模和向量空间嵌入。聚类通常用于发现文本的分类情况,而网络分析通常用于识别文本之间的关系位置。主题建模被用于粗略地描述文本内容,向量空间嵌入模型是把对文本内容的处理简化为向量空间中的向量运算,通过计算向量之间的相似性来度量文档间的相似性。
在社会学分析中,由监督学习方法或非监督学习方法派生的基于文本的变量通常作为自变量,从文本外部预测已建立的因变量。例如,Goldberg等从文本中提取出员工在公司中的文化嵌入程度,然后用它来预测员工的个人绩效评级和任期。
五、 大数据研究价值
大数据在工业上的成功应用引起了学术界的注意。研究者认为这种新型的数据类型对于学术研究来说更是不可错过的机遇。从数据特性来看,理论上,大数据可以为学术研究提供巨大价值:比如,大数据容量庞大可以看作全样本来分析,保证统计分析的稳健性;大数据多种多样,包含了复杂、可能是潜在变量之间的相关性,可以作为研究复杂现象的一种信息来源;大数据获取速度快,获取成本低且数据几乎可以实时生成,用实时可用的大数据研究现象不仅可以提高效率,还能避免统计调查中存在的观察与分析之间的滞后性。
Lazer和Radford对大数据在社会科学领域可能存在的潜力进行了相关总结。他们认为,首先,与自我行为报告相比,大数据提供实际行为的测量,它更能捕捉到真实的一面;其次,大数据可以作为监测社会现象的传感器,这种数字化数据提供了降低成本,提高准确性和增加社会监测的能力;再次,大数据是以系统方式研究人类系统的机会,可以用以回答跨空间、跨时间等长期性问题;另外,大数据可以模拟自然或野外实验,通过数据链接捕捉实地实验的效果;最后,大数据往往内部包含着小数据,可以使用大数据对传统上难以接触的人群,或者比较罕见的事件进行研究。
同样,通过大数据分析,还可以进一步总结社会规律,帮助我们更好地预测未来。比如,在公共卫生方面,Ginsberg等发现,如果某一地区利用谷歌等搜索引擎搜索“流感症状”、“流感治疗”等关键词增多,那么几周后,相应地区医院急诊室的流感患者数量将相应增加,这一发现有助于预测流感的爆发并提前部署应对措施。在经济发展方面,联合国利用自然语言处理软件分析社交网站上的短信,以预测特定地区的失业率、支出削减和疾病爆发等社会问题,希望利用大数据防止地区再次陷入贫困困境。在社会安全方面,大数据分析可以通过预测“下一次恐怖袭击”,并可能在犯罪分子发动袭击前将其抓获,从而确保未来的安全。因此,大数据预测分析被用于社会治理目的,以解决越来越多的社会问题。
除此之外,在社会学领域,大数据对社会学有着更为特殊的意义。从130篇SSCI社会学大数据文献来看,大数据对社会学的理论发展、方法突破和实证研究拓展等方面提供了巨大潜力。
(一) 激发更大的“社会学想象力”
有学者认为,大数据的兴起意味着“理论的终结”,只要有了足够的数据和足够的测量维度,就可以找到答案,无需提出任何研究问题和研究假设。Halavais认为这种观点在很多方面都是错误的,理论的作用不仅仅是提供一个重要的启发式函数、可供验证的假设或可预测结果的能力,理论最重要的是解释社会结构和变化的能力。社会学的一个核心问题是社会如何塑造了个体行为以及被个体行为所塑造。或者说,微观的个体行为是如何整合并且在更大范围上塑造了社会规则、期望、价值、欲望以及结构?Mills将这种个人与社会联系起来的能力称之为“社会学想象力”。大数据虽然可以将变量的大规模映射作为发现世界的归纳工具,但大数据代表了理解世界过程的一部分,大数据方法本身不是目的,而是形成解释理论的过程。从根本上说,社会如何塑造以及被个体行为所塑造这一问题是一个关于大社会数据的问题,是关于理解大规模社会结构的动态演变以及如何與日常生活关联的相关问题。
大数据要求激发更大的“社会学想象力”,思考抽象与具体之间的关系,将宏大的社会理论融入到日常生活中去。正如Manovich所指出的那样,大的社会数据提供了在微观层面上对相互作用进行实证观察的可能,这种观察将得到广泛而深入的收集。
(二) 获得更好的社会测量
传统的社会调查往往需要花费大量的人力、物力、财力来收集研究数据,这些数据的收集周期长,数据发布滞后,很多情况下数据的真实性难以保证,有一些地区囿于现实条件甚至无法开展调查统计活动,这对社会治理、政策制定、社会研究有很大影响。由于大数据比传统数据来源范围更广泛、更新更及时,容量更庞大,在构建新的社会指标或优化/替代现有指标方面有天然的优势。大量的文献表明,大数据可以很好地近似社会指标,利用大数据有可能对相关的社会指标有更好、更快、更低廉的估计。
Di Bella等通过审查Scopus数据库中的大数据文献后指出,基于大数据的社会测量在发达国家和发展中国家有不同的目标。在发达国家,大数据是创建可靠的社会指标代理的高质量信息库。例如,Yazdani和Manovich在美国20个城市使用一年内的Twitter图像预测社会经济特征,发现与自我报告的社会福利、房屋均价、收入和教育水平之间高度相关性,Marchetti等利用私人车辆的GPS数据,发现意大利一个地区的流动性和贫困程度之间有很好的相关性;在发展中国家,大数据可能是传统的调查统计替代方案,是对某些地区难以取得监测数据的一种有力补充。例如,Mao等和Blumenstock等使用手机通话记录数据很好地预测出科特迪瓦和卢旺达无监测数据地区的公司收入水平,Elvidge等应用DMSP/OLS夜间灯光数据绘制世界贫困地图,并建立了一个可供计算的贫困指数。Wesolowski等利用手机通话记录数据建立了疟疾风险地图,估计疟疾寄生虫如何在肯尼亚各地传播。
(三) 开展更深入的实证研究
由于大数据包含了传统意义上难以获取或统计的数据、传统调查可能难以观察到的复杂变量的相关性,一方面使得以往很难进行的实证研究有了新的研究可能。例如,对于政治社会学家来说,有关朝鲜核危机的研究是非常重要的议题,但鉴于朝鲜严厉的信息封锁,几乎很难开展实证研究,Whang等基于大数据分析技术,使用1997年至2014年朝鲜中央通讯社(KCNA)的大量文本数据发现,就核试验而言,金正恩政权与金正日政权开展核计划的目的是不同的,就核挑衅而言,“有其父必有其子”的说法也并不正确。同样,对于文化社会学家来说,他们的研究总是局限于微观层面的分析,大数据在更大的层次上提供了新的可能。Murthy将17世纪的数字化日记和来自谷歌书籍的5100万本数字化书籍与当代的Twitter数据在大尺度下进行对比,一项重要的发现是,精英历史日记和当代社交媒体对日常生活的管理有相似之处,尽管从历史文本到当代推文,内容的可访问性和内容量已经随着时间的推移发生了变化,但几个世纪以来,人们对某些与公共情绪相关的词汇有着明显的偏好。
另一方面,一些经典的社会学理论也将得到进一步检验。Golder和Macy在《数字痕迹:在线网络研究的机遇和挑战》一文中较为详细地介绍了一些研究者使用网络大数据对某些经典社会学理论进行检验和修正。他们指出,在经典理论检验方面,Eagle等利用全国6500万用户的电话记录证实了Granovetter的弱关系理论和Burt的结构洞理论,Leskovec和Horvitz利用2.4亿用户的全球即时通讯网络数据证实了Milgram针对小世界现象提出的“六度分割”理论。在经典理论修正方面,Ugander等通过对全球Facebook网络的分析发现,随着Facebook规模的扩大,用户之间的“六度分隔”步骤从2008年的5.3个减少到2011年的4.7个,Cha等研究了17亿条推文,对Katz和Lazarsfeld提出的两级传播理论提出质疑,认为那些网络“意见领袖”对推文的转发和话题热度提高并不一定有影响,这让人们对Twitter上受广泛关注的用户的影响力产生了怀疑。
六、 结论与讨论
从130篇SSCI社会学大数据文献的计量分析来看,社会学大数据研究才刚刚开始起步。尽管相关的研究文献逐年增多,但目前实证类的研究文献偏少。社会学家们使用比较多的大数据类型包括网络社交数据、行政数据、企业数据和谷歌图书语料库数据,利用R、Python和Gephi等编程语言和软件进行大数据挖掘、分析和可视化。在统计分析方面,目前的大数据研究依然会采用频数、百分比、回归等传统的统计分析方法进行描述统计分析,但在机器学习的推动下,有监督学习和无监督学习的自动文本分析法已经开始得到运用。
在许多研究者看来,大数据为社会学研究提供了新的资源,注入了新的活力。与传统的统计调查相比,大数据在数据收集方面更方便、成本更低、速度更快,分析结果更稳健。对于社会学家来说,大数据更能激发更大的“社会学想象力”、更能协助获取有效的社会测量指标、更能帮助克服研究中的问题,进行更深入的研究分析。
然而,大数据在社会学中的应用仍然面临一些挑战:比如,大数据带来一种新的数据鸿沟,由于大数据的产生、收集和分析是割裂的,能获得大数据的人与无法获得大数据的人之间可能产生不平等,能分析大数据的人更可能决定如何使用大数据以及谁能参与其中。其次,使用大数据、对大数据进行分析都需要专门的专业知识,社会学家对传统社会调查、统计分析比较擅长,但对数据挖掘、机器学习等数据处理方法相对陌生,要很好地掌握这些专业知识的入门成本相对较高,这在一定程度上限制了大数据在社会学研究中的应用。再次,大数据引发了较大的研究伦理争议,传统的社会调查需要得到被调查者的知情同意才能收集数据,但大数据获取一般不直接与产生数据的个体发生接触,而是通过第三方平台获取或抓取数据,数据收集过程未获得许可、数据使用目的未被告知,在一定程度上來说,侵犯了用户隐私。
因此,在数字媒介社会活动日益增多、社会生活日益数字化的今天,如何理解日益数字化的世界、如何更好地利用大数据开展社会研究,对社会学而言是非常重要的。其一,应当鼓励社会学家与拥有大数据资源的企业、政府、社会组织展开合作,特别是与数据科学家合作,以降低大数据获取、大数据分析的难度。其二,开展社会学大数据研究技能培训项目,培养高质量复合型社会学家,以适应大数据时代的社会学研究工作。三是探讨解决大数据社会学研究存在的隐私侵犯等道德伦理问题,建立使用大数據资源的机制和渠道。四是继续加强对大数据基础理论工作的研究,夯实基于大数据的社会学理论基石。
Inspire Greater “Sociological Imagination”
— Based on the Quantitative Analysis of 130 SSCI Literatures on Big Data of Sociology
TANG Binbin, FU Shuangle, LIU Linping
(School of Social and Behavior Sciences, Nanjing University, Nanjing 210023, Jiangsu, China)
Abstract:Based on 130 SSCI sociology big data literatures, this paper analyzes the types of articles, citations, author information, big data types, processing tools, analytical methods and research values. The study found that there are few empirical studies on big data in sociology; the authors are not active; big data types used more include online social data, administrative data, enterprise data, and Google Books corpus data. Traditional statistical analysis methods still account for a certain proportion, but machine learning methods are beginning to be applied. Big data has injected new vitality into sociology research, helping to stimulate greater “sociological imagination”, gaining better social measurement and conducting more in-depth empirical research.
Key words:sociology; big data; quantitative analysis; frontier progress
