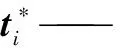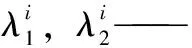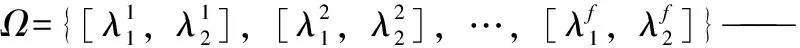基于模式识别和谱图映射的通用油品调合模型
2018-06-01杜中元李泽飞
王 莹,杜中元,李泽飞
(中国科学院 自动化研究所,北京 100190)
传统油品调合优化模型一般直接从油品的各个性质出发建立质量约束,无论是汽油、柴油还是原油,需要分析的油品性质指标都很多,而且某些性质在成品油与组分油之间是较为复杂的非线性关系,并没有一个统一的模型能用来描述,不同炼油厂必须根据自己的生产情况去寻找适用的模型[1]。相关文献中有很多关于油品性质调合关系的模型,如柴油凝点性质,有指数模型、换算因子法、换算指数法等[1-2];汽油辛烷值性质,有Stewart法、调合因素法、指数对数模型、ETHYL RT-70法等[1-3]。在实际应用中,当生产条件变化导致组分油波动时,原有的模型很可能不再具有适用性,需要再采集新的样本去拟合新的模型,这就造成了油品调合任务的繁杂和高成本。
针对以上问题,笔者提出了一种通用的基于模式识别和谱图映射的油品调合优化模型,将不统一、繁杂的非线性性质卡边约束转化为训练集特征空间上成品油与组分油得分向量间的线性调合约束,这种建模思想适用于包括汽油、柴油、原油等不同油品的调合,适用于不同的炼油厂,也适用于同一个炼油厂生产条件的波动。
油品的性质是由各类烃化合物的各种X—H结构基团的特征和含量决定的,而油品的近红外谱图是一种能直接反映油品烃类化合物的组成、结构信息的数据[4-5]。油品调合是组分油的分子扩散达到完全均匀的混合为止[1],没有化学反应的产生。成品油中各种C—H、N—H和O—H键结构基团的含量与组分油中各种C—H、N—H和O—H键结构基团含量的线性加和基本一致,所以成品油的近红外光谱图的吸收度也是组分油谱图吸收度的线性加和。用主成分分析法对油品的谱图提取出特征向量——得分向量,经过推导也可以得出成品油与组分油的得分向量间存在线性加和关系。
基于上述理论依据,笔者提出基于模式识别和谱图映射的油品调合优化模型,训练集最大限度的覆盖炼油厂正常生产条件下的所有工况,包含各种代表性组分油和成品油样本的近红外谱图,用主成分分析法运算后在特征空间形成分类模型;将参与调合的组分油谱图投影到特征空间,并用朴素贝叶斯分类器进行分类判别到训练集的某类样本中;在成品油类中用核密度估计方法量化样本的分布并确定一个约束区域;最后利用组分油和成品油得分向量之间的线性加和关系建立调合油品的质量约束。
1 成品油与组分油得分向量之间的线性加和关系
成品油的近红外光谱图与组分油近红外谱图的线性加和关系用数学表达式表示,如式(1)所示。
(1)
对训练集样本以及上述成品油和组分油样本谱图进行主成分分析法运算,可以得到式(2)。
(2)
将式(2)代入式(1),两边同时乘以L并化简得到式(3)。
(3)
选择前f个主成分上的得分,用式(4)表示。
(4)
从式(4)可以看出,成品油的得分向量与组分油的得分向量是线性加和关系。
2 训练集样本在特征空间的分类和调合组分油样本的分类判别
对训练集样本作主成分分析,确定能涵盖原始样本信息98%左右的主成分个数f,这样不仅能得到反映每个油品特征的得分向量,而且在主成分构成的特征平面或特征空间上不同油品落入不同的区域,不同油品各自分开,属于不同的类别[4-8]。
采集参与调合的组分油近红外谱图,并投影到训练集样本构成的特征空间上,采用朴素贝叶斯分类器[9-10]对组分油样本进行分类判别到训练集的某类样本中。生产条件的波动会导致组分油落在所属类区域的不同位置,得到不同的得分向量,将对应的得分向量带入到下文中的式(8)用于建立调合油品质量约束。
用D=(D1,D2,…,Df)表示样本属性集(得分向量),C表示类变量(油品类别),朴素贝叶斯分类器用先验概率P(D)、P(C)和类条件概率P(D|C)通过式(5)表示后验概率,并将样本判别到后验概率最大的类别中,对于确定的属性集分母P(D)是相同的,只需判别到分子取最大值的类别中。
(5)
朴素贝叶斯分类器假设样本属性条件独立,所以对于给定的类别c,特定的属性值d=(d1,d2,…,df),类条件概率可以用式(6)表示。

(6)
类的先验概率可以通过训练集的各类样本出现的次数来估计(c类先验概率=c类样本的数量/样本总数)。为了估计属性的分布参数,可以假设训练集数据满足高斯分布或核密度分布,用样本值估计出属性分布函数后计算某个属性值上的概率。
3 核密度估计方法确定调合油品的落入区域
要使得某几种组分油按一定比例调合出满足质量指标要求的成品油,调合油品的得分向量也必须落入对应的成品油所属区域的类中。因此,在成品油类中确定一个子区域作为调合油品得分向量必须落入的区域,以此建立成品油的质量约束。
核密度估计[9-12](Kernel density estimation)又名Parzen窗(Parzen window),用于所研究的样本概率密度函数形式未知的场合,直接利用训练数据对概率密度进行估计。设s1,s2…sn为一元独立同分布F的n个样本点,F的概率密度函数用核密度估计的公式如下:
(7)
K(x)为核函数,h>0为一个平滑参数,称作带宽(Bandwidth),也叫窗口。由于高斯内核方便的数学性质,经常使用K(x)=φ(x),φ(x)为高斯核函数。
笔者选用的核函数也是高斯核函数,窗宽采用可使平均积分平方误差最小的最优窗宽,在各主成分上分别进行一维的核密度函数估计。确定调合油品落入区域的方法如下:
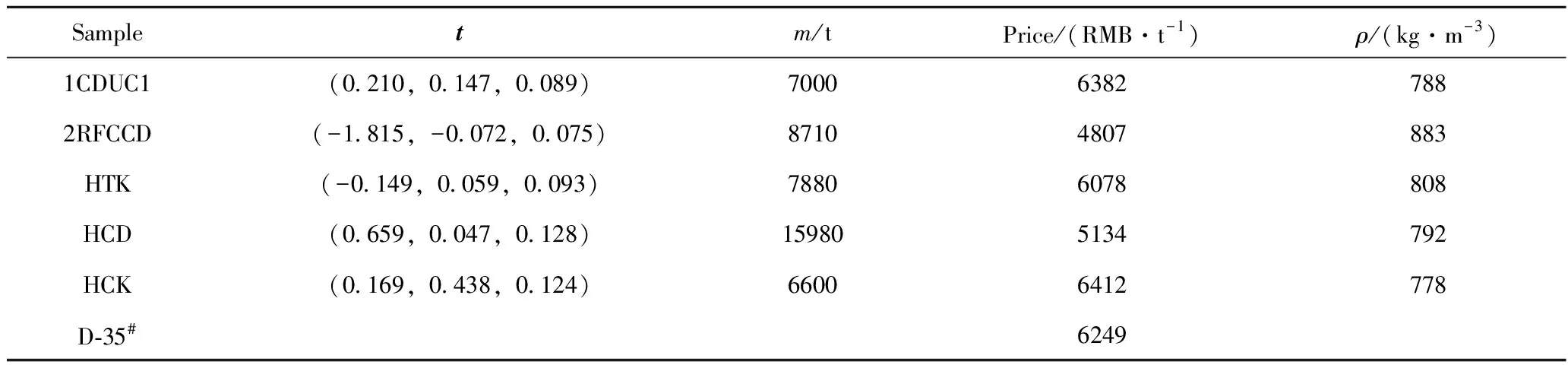
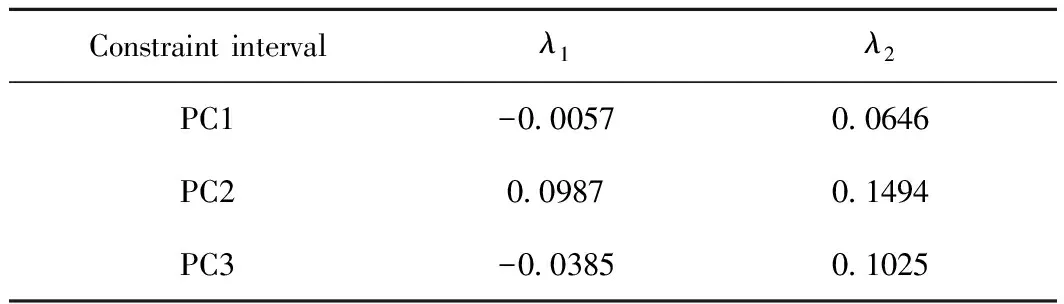
分别在第1到第f主成分轴上按2个步骤确定区间范围:(1)根据样本的核密度函数确定样本最集中的点,即核密度函数最大值对应的点a;(2)设定概率水平β,在a两侧确定上、下分位数λ1、λ2,λ1 假设调合一种成品油(调合多种成品油时对每种成品油用相同的方法分别建立质量约束),在组分油和成品油样本确定的特征空间上,根据组分油和成品油的得分向量以及按第3节中介绍的方法确定的约束区域,建立质量约束表达式如式(8)。 (8) 同时构建模型中物料平衡、产量需求等其他约束条件,并且与目标函数一起构成了整个优化模型。借助于优化软件即可求解。 主成分个数f的大小影响得分向量代表原始谱图信息的能力,进而影响不同油品的分类效果,如在二维特征平面有交叠的不同油品可能在三维特征空间就是完全分开的。因此,应该选择较大的f使得得分向量包含原始数据的信息多,不同油品在特征空间中的区分效果好;但f也不能太大,以免包含噪音信息。f的大小同时影响着解的可行域的大小。f偏小时,解的自由度较大,得出的配方可能使得调合油品质量不合格或质量过剩太多;当f偏大时,解的自由度较小,可能导致所求问题无解。 当主成分个数确定后,约束区域的大小和形状都会对求解结果产生影响。概率水平β取值的大小直接影响约束区域的大小。当β取值太小时,可行解的范围就会缩小,优化问题可能会无解;β取值太大时,约束区域较大,边界部分对应的样本点可能较稀疏,所求出的优化配方调合出的成品油可能是不合格的或质量过剩较多。 采集的某炼油厂的柴油数据,训练集数据是包含0#柴油(D-0#,国Ⅳ标准)、-35#柴油(D-35#,国Ⅳ标准)、一套常压蒸馏装置侧一线(1CDUC1)、一套常压蒸馏装置侧二线(1CDUC2)、二套重油FCC装置轻柴油(2RFCCD)、加氢裂化柴油(HCD)、加氢精制柴油(HTD)、加氢裂化煤油(HCK)、加氢精制煤油(HTK)9种油品312个近红外数据。 有2个-35#成品油样本是由5个组分油:一套常压蒸馏装置侧一线、二套重油FCC装置轻柴油、加氢精制煤油、加氢裂化柴油、加氢裂化煤油,分别按φ(1CDUC1)=25%、φ(2RFCCD)=10%、φ(HTK)=20%、φ(HCD)=15%、φ(HCK)=30%,以及φ(1CDUC1)=25%、φ(2RFCCD)=5%、φ(HTK)=15%、φ(HCD)=10%、φ(HCK)=45%两组体积分数调合出来的。采集这5个组分油和2个调合成品油样品的近红外谱图并投影到训练集样本确定的特征空间中,得到各自的得分向量。将5个组分油的谱图按照这两组比例线性加和得到2个调合谱图,也投影到特征空间中。图1显示了训练集样本在前2个主成分轴确定的特征平面上的分类,其中7个空心圆圈()为5个组分油和2个调合成品油的谱图对应的投影,2个星()为2个线性加和的调合谱图对应的投影。由图1可以看出,调合成品油的谱图与线性加和的调合谱图的得分向量偏差很小。 用上述5个组分油调合-35#柴油,组分油得分向量、产量、价格、密度和调合成品油的价格列于表1。当主成分个数为3时,能涵盖训练集97.9%的信息,因此在问题求解中选择的主成分个数为3,得分向量只列出了前三维的数据。 调合要求为:调合出满足国Ⅳ指标要求的-35#柴油(训练集样本的-35#柴油满足的是国Ⅳ指标),质量过剩尽量小,组分油用量不超过产量,在满足这些条件的同时,要求收益最大。 调合问题中,二套重油FCC装置轻柴油(2RFCCD)、加氢裂化柴油(HCD)是凝固点较高的组分油,产量较大,价格较便宜,追求收益大就会多消耗这2种组分油,但用量太多会使得调合出的成品油不合格,因此用量应适当。 图1 训练集样本在特征平面上的分类以及成品油谱图和调合谱图在上面的投影Fig.1 Classification of training samples on feature plane and projection of product oil spectra and blended spectra on itPC1—The first principal components;PC2—The second principal components; Projection of the components and blended product oils spectra; Projection of blended spectra;(1) Projection of blended product oil spectrum and blended spectrum with φ(1CDUC1)=25%, φ(2RFCCD)=10%, φ(HTK)=20%, φ(HCD)=15%, φ(HCK)=30%; (2) Projection of blended product oil spectrum and blended spectrum with φ(1CDUC1)=25%, φ(2RFCCD)=5%, φ(HTK)=15%, φ(HCD)=10%, φ(HCK)=45% Sampletm/tPrice/(RMB·t-1)ρ/(kg·m-3)1CDUC1(0.210,0.147,0.089)700063827882RFCCD(-1.815,-0.072,0.075)87104807883HTK(-0.149,0.059,0.093)78806078808HCD(0.659,0.047,0.128)159805134792HCK(0.169,0.438,0.124)66006412778D-35#6249 选择的主成分个数f=3。采用核密度法估计-35#柴油样本的分布情况来确定约束区域。由于高凝点组分油的产量较充裕而且价格便宜,所以求解时令概率水平稍微小一些,以免可行解范围较大时得出的配方不合格,取概率水平β=40%。图2为用核密度估计方法在第一主成分轴上确定的约束区间。图3为在特征空间-35#柴油样本类中确定的约束区域。 表2列出了在前3个主成分轴上根据样本的分布确定的约束区间[λ1,λ2]。 按照式(8)建立质量约束不等式,同时列出组分油用量约束表达式和目标函数。模型建立好之后,调用MATLAB的linprog函数进行优化求解,得出5种组分油的用量配方为m(1CDUC1)=7000 t,m(2RFCCD)=3248 t,m(HTK)=7880 t,m(HCD)=7560 t,m(HCK)=2692 t,对应的5种组分油的体积分数为φ(1CDUC1)=25%,φ(2RFCCD)=10%,φ(HTK)=28%,φ(HCD)=27%,φ(HCK)=10%。按照该用量配方调合出的成品油性质:凝固点-36℃,冷滤点-31℃,闪点54℃,十六烷值49,十六烷值指数48、馏程50%为218℃、馏程90%为273℃,密度804 kg/m3,达到-35#柴油国Ⅳ标准指标要求。 图2 采用核密度估计法在第一主成分轴上确定约束区间Fig.2 Constraint interval determined by kernel density estimation method on first principal components(a) Kernel density function;(b) Inverse cumulative probability function;a—Point corresponding to the maximum of kernel density function;λ1, λ2—Lower and upper limits of constraint interval;pa, p1, p2—Probability corresponding to a, λ1, λ2;the difference between p1 and p2 is β 图3 采用核密度估计法在特征空间成品油样本类中确定的约束区域Fig.3 Constraint region determined by kernel density estimation method in the product oil samples group in the feature space Points correspond to the product oil samples;Cross corresponds to the point which has maximum value of kernel density function on each of the first three principal components; Cuboid corresponds to the constraint region. Constraint intervalλ1λ2PC1-0.00570.0646PC20.09870.1494PC3-0.03850.1025 进一步考察了主成分个数和约束区域的选择对调合结果的影响。当选择主成分个数分别为2、3、4时,涵盖的训练集信息依次为94.5%、97.9%、98.9%,其他条件不变,仍取β=40%。经过计算,当主成分个数f=4时求解出的结果与f=3时相同。所以,表3列出的是主成分个数f分别为2和3时的模型优化求解的调合配方。 表3 主成分个数(f)分别为2和3时用模型进行优化求解得到的配方Table 3 Formula optimized by the model choosing two or three principal components 根据该优化配方调合出的成品-35#柴油性质:f=2时,凝固点为-33℃,冷滤点为-28℃;f=3时,凝固点为-36℃,冷滤点为-31℃。当f=2时,得分向量包含的原始样本信息不够充分,信息有损失,而且可行解的范围较大,高凝点组分油产量足够多而且价钱便宜,所以优化求解得到的结果中用的高凝点组分油量较多,根据各组分油用量调合出的成品柴油的凝固点和冷滤点较高,不能满足-35#柴油国Ⅳ标准指标要求。 仍取f=3,建立质量约束区域时,依次取概率水平β为30%、35%、40%、50%调用模型算法进行求解。当β为30%时约束区域太小,模型没有可行解。表4列出了β为35%、40%、50%的优化用量。表5为根据优化配方调合出的成品柴油的凝固点和冷滤点。 表4 概率水平(β)分别为35%、40%、50%时模型求解的优化配方Table 4 Formula optimized by the model choosing the probability (β) equals 35%, 40% or 50% 表5 概率水平(β)分别为35%、40%、50%时根据模型优化求解的配方调合出的成品柴油的凝固点和冷滤点Table 5 Solidifying point and cold filter plugging point of the blended diesel based on the formula optimized by the model choosing the probability (β) equals 35%, 40% or 50% 由实验可以看出,约束区域较小时,模型可能无解;约束区域较大时,边界部分对应的样本点较稀疏,根据所求出的优化配方调合出的成品油可能不合格,对于其他调合问题也可能质量过剩较多。 (1)基于模式识别和谱图映射的油品调合优化模型,以油品的近红外谱图为基础,在特征空间上根据成品油和组分油得分向量间的线性调合关系来建立模型,解决了传统上从油品性质出发建立调合模型时面临的非线性、不统一、复杂等问题。笔者所提出的建模思想能适应生产条件波动导致的组分油性质波动,适合不同的炼油厂,也适合柴油、汽油、原油等不同油品的调合。 (2)在模型中影响求解结果的因素和参数有主成分个数、谱图投影的特征空间、确定约束区域的概率水平、每个主成分轴上的约束区间;这些影响因素反映了炼油厂正常生产工况下组分油和成品油性质波动的特征,反映了组分油和成品油的组成结构,针对具体调合问题应该合理确定。 符号说明: A=(a1,a2,…,af)——在特征空间的成品油类中确定的一个中心点; ai——第i个主成分轴上核密度函数最大值对应的点; a——某个主成分轴上核密度函数最大值对应的点; b*——成品油的得分向量,k维向量; b——成品油取f个主成分的得分向量,f维向量; C——类变量(油品类别); c——特定的某个类别; D——样本属性集(得分向量); d——特定的某个属性值; ex——残差光谱; et*,et——得分向量偏差; f——主成分个数; f*(x)——密度估计函数; h——核密度函数的窗宽; K(x)——核函数; k——光谱数据的维数; L=(l1,l2,lf,…,lk)——训练集样本进行主成分运算后在特征空间的基; LT——L的转置; M——组分油个数; m——用量(质量),t; P(C)——类别的先验概率; P(D)——属性的先验概率; P(C|D)——类的后验概率; P(D|C)——类条件概率; s1,s2…sn——用于估计核密度函数的样本点,n为样本点个数; ti——组分油i取f个主成分的得分向量,f维向量; x——成品样光谱或中心化后的光谱,k维向量; yi——组分油i的光谱或中心化后的光谱(减去平均光谱后的光谱),k维向量; β——设定的概率水平,样本在约束区间[λ1,λ2]分布的概率为β; φ(x)——高斯核函数; φ——体积分数,%; φi,φj——组分油i、j调入的体积分数,%; λ1,λ2——某个主成分轴上确定的约束区间的上、下限; ρ——密度,kg/m3; [1] 蔡智,黄维秋,李伟民,等.油品调合技术[M].北京:中国石化出版社,2005. [2] 谢可堃, 王志刚, 张晓光, 等. 汽柴油调合常用质量指标的设计计算方法[J].炼油技术与工程, 2009, 39(9): 57-60.(XIE Kekun, WANG Zhigang, ZHANG Xiaoguang, et al. Design and calculation method of common quality index for gasoline and diesel blending[J].Petroleum Refinery Engineering, 2009, 39(9): 57-60.) [3] 王伟, 李泽飞, 黄燕. 基于油品性质的汽油调合辛烷值模型的选取[J].石油学报(石油加工), 2006, 22(6): 39-44.(WANG Wei, LI Zefei, HUANG Yan. Choice of octane number models for gasoline based on feedstock quality[J].Acta Petrolei Sinica (Petroleum Processing Section), 2006, 22(6): 39-44.) [4] 陆婉珍, 袁洪福, 徐广通, 等. 现代近红外光谱分析技术[M].北京: 中国石化出版社, 2000. [5] 冯新沪, 史永刚. 近红外光谱及其在石油产品分析中的应用[M].北京: 中国石化出版社, 2002. [6] 禇小立, 袁洪福, 陆婉珍. 光谱结合主成分分析和模糊聚类方法的样品聚类与识别[J].分析化学研究报告, 2000, 28(4): 421-427.(CHU Xiaoli, YUAN Hongfu, LU Wanzhen. Sample clustering and identification based on spectral principal component analysis and fuzzy clustering method[J].Chinese Journal of Analytical Chemistry,2000, 28(4): 421-427.) [7] 刘倩, 孙培艳, 高振会, 等. 衰减全反射傅里叶变换红外光谱技术结合模式识别进行油品鉴别[J].光谱学与光谱分析, 2010, 30(3): 663-665.(LIU Qian, SUN Peiyan, GAO Zhenhui, et al. Attenuated total reflectance FTIR spectroscopy and pattern recognition for oil identification [J].Spectroscopy and Spectral Analysis, 2010, 30(3): 663-665.) [8] 刘颖荣, 许育鹏, 杨海鹰, 等. 汽油样品类型的模式识别研究与应用[J].色谱,2004, 22(5): 482-485.(LIU Yingrong, XU Yupeng, YANG Haiying, et al. Investigation and application of gasoline sample identity technique[J].Chinese Journal of Chromatography, 2004, 22(5): 482-485.) [9] SERGIOS T H, KONSTANTINOS K. 模式识别[M].李晶皎译. 第4版. 北京:电子工业出版社, 2016. [10] 谢中华. MATLAB统计分析与应用: 40个案例分析[M].北京: 北京航空航天大学出版社, 2010. [11] 徐东斌, 黄磊, 刘昌平. 自适应核密度估计运动检测方法[J].自动化学报,2009, 35(4): 379-385.(XU Dongbin, HUANG Lei, LIU Changping. Adaptive kernel density estimation for motion detection[J].Acta Automatica Sinica, 2009, 35(4): 379-385.) [12] 淦文燕, 李德毅. 基于核密度估计的层次聚类算法[J].系统仿真学报, 2004, 16(2): 302-309.(GAN Wenyan, LI Deyi. Hierarchical clustering based on kernel density estimation[J].Journal of System Simulation, 2004, 16(2): 302-309.)
4 谱图调合优化模型
4.1 主成分个数对求解结果的影响
4.2 约束区域对求解结果的影响
5 谱图调合优化模型应用实例
5.1 调合问题

5.2 问题求解


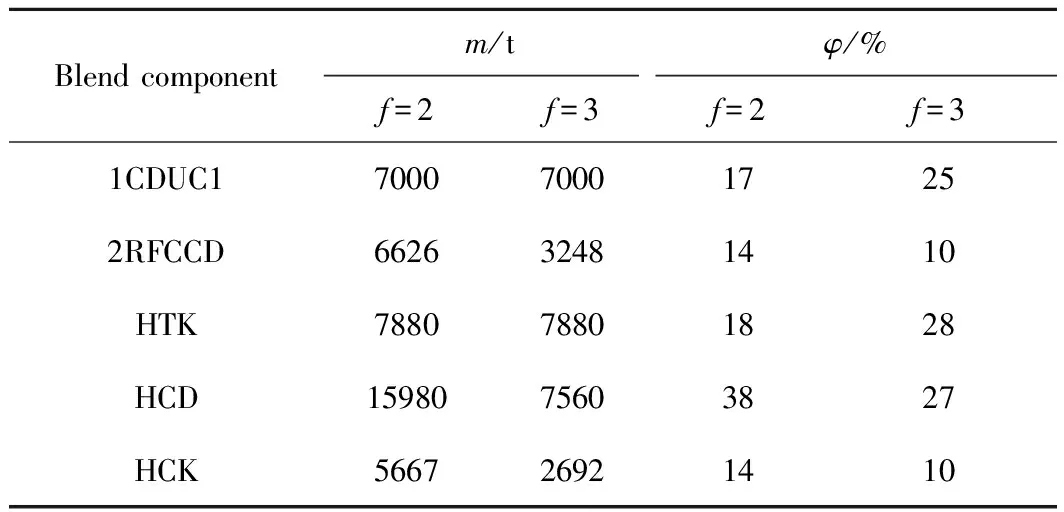
5.3 主成分个数和约束区域的选择对调合结果的影响
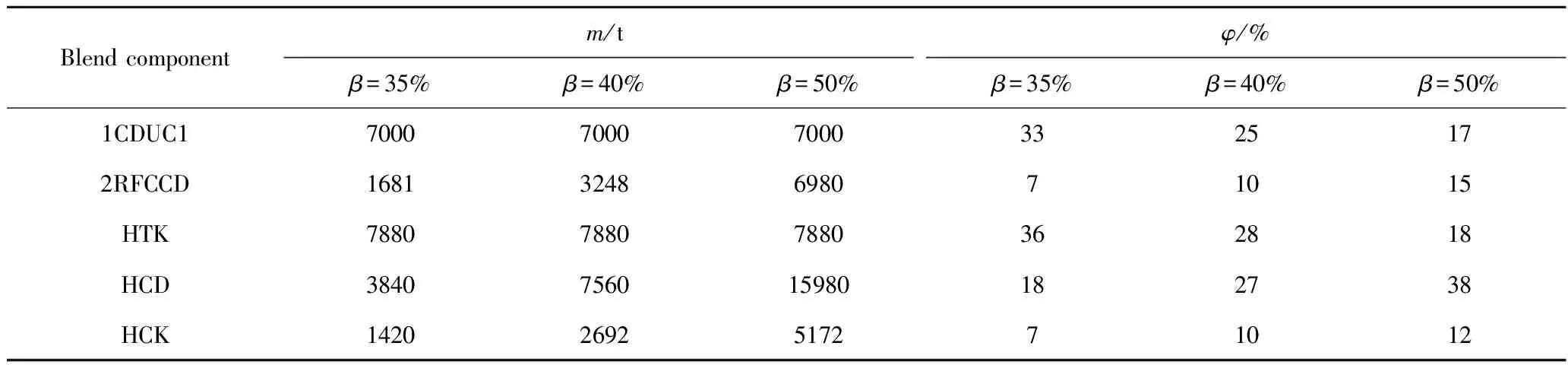

6 结 论