基于细胞因素的癌症Logistic回归预测
2018-05-18方梓涵张焕明朱家明
方梓涵,张焕明,朱家明
(安徽财经大学统计与应用数学学院,安徽 蚌埠 233000)
*通讯作者:张焕明(1973— ),男,湖北蕲春人,安徽财经大学统计与应用数学学院教授,博士.研究方向:宏观经济数量分析
回归分析可用于评估预测变量对响应变量的预期效果.而Logistic回归模型是根据单个或多个连续性或离散型变量来分析和预测离散型变量的多元分析方法.通过对Logistic回归模型的预测、参数估计、回归系数的统计推断、模型的评价使我们对Logistic回归模型有了更加深入的了解.同时,我们也看到了logistic在生物学、化学、物理学等多种交叉学科方面有广阔的应用前景[1].
1 数据来源
本文的所用数据集较大,表1仅是部分数据,具体的部分数据来源于网站http://archive.ics.uci.edu/ml/datasets/.

表1 数据来源
2 Logistic回归预测模型
2.1 研究思路
本文要建立癌症预测的模型.表1的数据集是横截面数据,而且其因变量(诊断结果)是二分类变量,自变量诱发癌症的各种因素为连续变量.自变量和因变量之间存在较强的线性关系.鉴于logistic回归分析的基本原理,在此尝试运用该数据集建立logistic回归模型对因变量进行预测.
2.2 评价指标体系结果分析
以癌症发病情况为例,通过logistic回归分析,可以得到自变量的权重,从而可以大致了解哪些因素是乳腺癌的危险因素.首先,我们利用SPSS对数据集中的各种因素进行相关系数分析,其结果如表2所示:
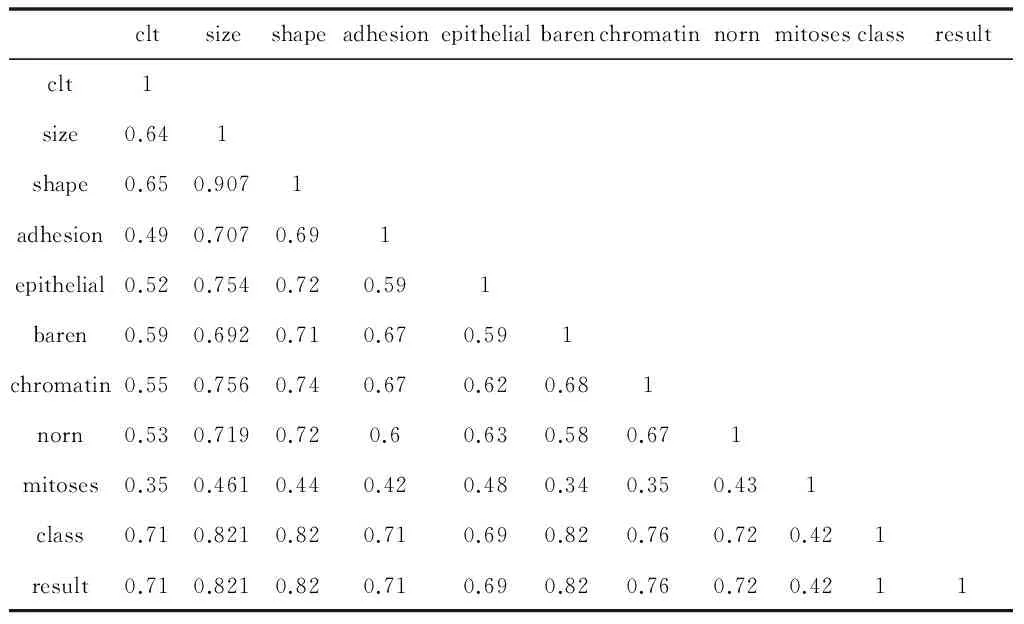
表2 相关系数表
以result为因变量,以其他变量为自变量,采取依据似然比——向前引入变量法,建立Logistic回归模型,得到的结果如表3所示:

表3 模型摘要
a. 估计在叠代号 8 处终止,因为参数估计的变更小于 .001.
由模型的拟合优度检验表中的数据分析(表3)可以看出,模型的Nagelkerke R Square 值在0.9以上,Cox Snell R Square 值也将近0.7,说明模型的拟合优度有良好的效果.

表4 分类表a
a. 分割值为 .500
利用以上模型对原数据集进行诊断预测,由表4可以看出,其正确率为97.1%,预测效果良好.

表5 方程式中的变数
a. 步骤 6 上输入的变数:[%1:, 6:
最终的模型结果如表6所示,模型为:

0.338*adhesion+0.379*baren+0.471*chromatin+0.243*norn

3 基于Logistic回归模型估计的实证分析
3.1 研究思路
为了更好地研究各种因素对癌症的影响.当模型满足假设条件时,先由SPSS的回归结果选取主成分作为解释变量进行Logistic回归预测分析.其次利用Wald检验计算出Wald统计量判断自变量是否会对结果产生影响[2].
3.2 实证分析
用最大似然估计法进行参数估计:
在本数据集中,由SPSS的回归结果可知,shape,clt, adhesion,chromatin,norn, baren对result影响较大,故选取这6个变量作为解释变量,将它们分别命名为X1,X2,X3,X4,X5,X6,用y表示result,则反应结果可以用有条件的均值E(yX)来表示:
E(y|X)=β0+β1X1+β2X2+β3X3+β4X4+β5X5+β6X6
π(X)=
则:

对于y=π(X)+ε,当y=0时,ε=π(X);当y=1时,ε=1-π(X).ε分布的平均值为π(X)1-π(X).对于观测值(Xi,yi),得到一组观测值的概率:
P(yi)=π(Xi)yi1-π(Xi))1-yi
记β=(β0,β1,β2,β3,β4,β5,β6)其似然函数为:

表6 方程式中的变数
a. 步骤 6 上输入的变数:[%1:, 6:
其对数似然函数为:

称为对数似然函数,为了顾及能使lnL(θ)最大的总体参数β0,β1,β2,β3,β4,β5和β6值,先分别对它们求偏导数,然后令其等于0.
从而得出表6拟合结果:

4 Logistic回归系数的统计推断
4.1 研究思路
当模型满足假设条件时,我们可以由样本的结果对总体参数进行统计推断,我们将其定义为假设检验和参数估计.我们主要讨论在Logistic回归模型中自变量Xk对Logistic作用的显著性检验.模型估计完成后,需要评价模型是否有效地描述反应变量及模型匹配观测数据的程度.拟合优度(Goodness of Fit)是指回归直线对观测值的拟合程度,度量拟合优度的统计量是可决系数(亦称确定系数)R2,通过R2的值来判断模型拟合程度的优劣[3].
4.2 数据处理
假设原假设H0为:βk=0表示自变量Xk对时间发生可能性无影响作用.我们需要选择一个显著性水平∂,一般情况下常取0.05.如果原假设被拒绝,说明事件发生的可能性依赖于Xk的变化.对于规模很大的样本,检验其总体系数是否为0可以采用Z统计量:
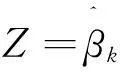


在原假设条件下,如果每一个回归系数都等于0,那么这个单变量Wald统计量为自由度为1的χ2分布.在自由度为1的条件下,∂=0.05的χ2临界值为3.841,所以当Wald在∂=0.05的χ2值大于3.841于是就拒绝原假设H0:βk=0
Wald统计量的一般形式为:
Qβ=r
定义本题的Wald统计量为:
其中,W为χ2分布其自由度为约束的数目(即Q中的行数).
我们得到Wald检验统计量:
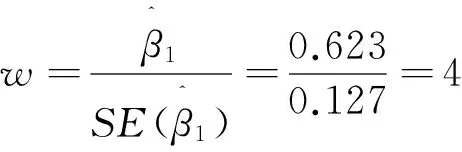
W=4.547>3.841,同理算出βk对应的W值,均是大于3.841,这样拒绝原假设,说明自变量对结果有影响,即回归系数对模型是显著的[4].
4.3 结果分析
皮尔逊χ2是用来通过比较模型预测和观测的事件发生和不发生的频数检验模型成立的假设.通过表7我们可以看出改善后的χ2统计量为5.422,p值为0.02,拒绝原假设,即模型的回归系数是显著的,自变量对结果有影响.

表7 逐步摘要a,b
a. 无法在现行模型中删除或新增任何更多变数。
b. 结束区块:1
从表6和表7的数据可以得出χ2统计量是大于临界值3.841的,故该Logistic预测模型是合理有效的.
5 总结
本文巧妙地利用SPSS简单对该699个数据集建立模型,并对参数做了最大似然估计,发现与建立的模型基本一致;之后对模型做了回归系数的显著性检验,结果是拒绝不显著的原假设,即回归系数对模型是有显著影响的[5].最后给出皮尔逊χ2统计量来验证模型的拟合优度,结果表明模型是合理的.
参考文献:
[1]贾俊平,郝静.统计学案例与分析[M].北京:中国人民大学出版社,2010.
[2]尹建杰.Logistic回归模型分析综述及应用研究[D].哈尔滨:黑龙江大学硕士学位论文,2011.
[3]张婷婷. Logistic回归及其相关方法在个人信用评分中的应用[D].太原:太原理工大学硕士学位论文,2017.
[4]许汝福.Logistic回归变量筛选及回归方法选择实例分析[J].中国循证医学杂志,2016,(11):1360-1364.
[5]胡桂华,武洁.人口普查质量评估中Logistic回归模型的应用[J].数量经济技术经济研究,2015,(4):106-122.
