一种基于用户标签的社交网络好友推荐算法
2018-05-18何广达杨安桔张臣坤
汪 强,何广达,杨安桔,张臣坤
(安徽新华学院信息工程学院, 安徽 合肥 230088)
随着互联网中的增加,用户需要从不同的互联网平台中获取大量信息,但如何快速地获取用户目标信息是目前互联网信息获取急需解决的问题[1].而且随着信息量的不断增加,信息分类混乱的现象也日趋严重,即使是搜索引擎也很难检索到用户的目标信息[2].因此,推荐系统[3,4]应运而生,信息推荐系统是一种可以通过用户在互联网中产生的历史数据信息,分析用户个性化偏好,向用户推荐感兴趣的物品或信息的系统.
推荐系统采用的主要推荐算法是协同过滤算法[5,6],协同过滤推荐算法分为:
(1)基于用户的协同过滤算法
如果用户对项目、产品等的评分比较相近,则他们可能有相同的兴趣、爱好,那么他们可能对没有产生评分的项目评分也比较相近.寻找相似兴趣用户作为最近邻居,把最近邻居的项目推荐给目标用户.
(2)基于项目的协同过滤算法
与用户之间的性质类似,项目之间也具有相似特征,根据已知用户对项目的评分来预测用户对未知相似项目的评分,将评分排序,按序将项目推荐给目标用户.
协同过滤算法主要不足[7,8]有三个方面:
(1)数据稀疏问题.由于目前的应用系统中用户和项目数据规模较大,用户对项目产生的评分有限,造成评分数据稀疏,给相似性的计算和项目的推荐带来困难;
(2)冷启动问题.目前的应用系统产生新数据量巨大,每一个新项目进进入系统时,还没有产生用户评价,采用传统的协同过滤算法就没有办法对新项目产生推荐.
(3)可扩展性问题.应用系统中的用户和项目快速增长,推荐算法的复杂度也随之快速增长,算法的时间复杂度大大增加,导致可扩展性较差.
现在大多数社交网络的系统好友推荐都是基于共同好友的推荐.但对于新用户,无法解决冷启动的问题.然而社交网络都为用户提供标签,由于标签由用户本人标记,所以标签可以反映用户的真实兴趣,同时标签不依赖已有的朋友圈,可以一定程序上解决冷启动的问题.本文以新浪微博数据为基础进行研究,提出一种基于用户标签的协同过滤算法,建立用户推荐模型,为社交网络用户推荐具有相同兴趣爱好的好友.在体现用户兴趣的同时,解决推荐系统冷启动的问题.
1 基于用户标签的协同过滤算法
1.1 基于用户的协同过滤算法
基于用户的协同过滤推荐又称为最近邻(Nearest-Neighbor)协同过滤推荐或者 KNN(K-Nearest-Neighbor)算法,该推荐算法主要有以下步骤:
(1)数据初始化
根据用户的评分信息建立用户-项目评分矩阵,如表1所示:

表1 用户-项目评分表
用户与项目评分的关系用二部图表示,令G={V,E}为用户-项目二部图,该图是一个无向图,其中 V=VU∪VI , 其中VU是由用户所构成的顶点集,VI是由物品构成的顶点集,且用户对项目的评分作为用户与项目顶点连边上的权重,构成用户-项目二部图,如图1所示:
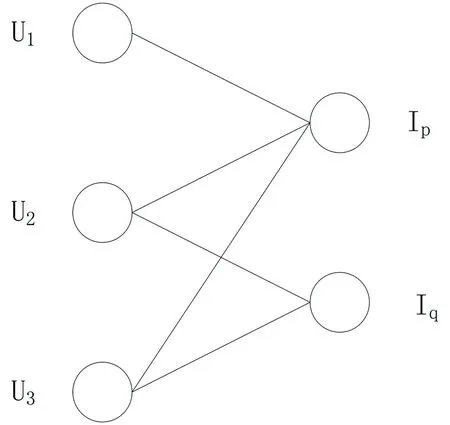

(a) 不带权重的二部图 (b)带权重的二部图
表1中,U1,U2,U3为用户,p,q为项目,表1中的数值为用户对项目的评分,若数值为空则表示用户没有对项目评分.图1的二部图由表1转换而来,图的两侧为项目和用户,图1(a)和图1(b)分别对应不带权重和带权重的二部图,前者不考虑评分多少,只要有评分则连接对应的用户和项目,后者在连接对应用户和项目的时候需要加上评分.
(2)最近邻居集的计算
采用相似度计算方法寻找目标用户的最近邻居集,主要选择:Pearson相关系数[9]和约束Pearson 相关系数[10],表示如下:
1)Pearson相关系数
Pearson相关系数是一种衡量两个变量之间的线性相关性的方法.用户u、v的 Pearson 系数相似性可由公式(1)表示:
sim(u,v)=
(1)

2)约束 Pearson 相关系数
约束 Pearson相关系数是在Pearson相关系数计算的基础上改进得到,由公式(2)表示:
sim(u,v)=
(2)
其中Rmed表示系统设定的评分中值,如MovieLens系统中设置电影的评分区间为1~5,那么Rmed的值即为3.
(3)预测评分及产生推荐结果
首先计算目标用户u的最近邻居集,表示为: N (u)= {u1,u2,…uK},然后选择最近邻居已评分项目,再预测目标用户对这些项目的评分,最后预测评分按序推荐给目标用户.
评分预测计算如公式(3)所示:

(3)
其中Ru和Rv为用户u、v各自所有评分项目的打分均值.
1.2 基于用户标签的协同过滤算法
由于标签由用户手动产生,具有较强的主观意愿,可以表示用户的兴趣,所以本文选择应用系统中的用户标签数据,将标签数据作为算法中的项目进行分析、建模,目标是为了发现相同兴趣用户圈子,较准确地建立基于用户兴趣的好友推荐算法.本文主要采用语义+标签的数据分析方法,为系统中的用户推荐更高质量的好友服务.
2 实验及结果分析
2.1 数据来源
新浪微博为数据研究人员开放了数据平台的API[11]接口,采用Python语言抽取标签数据存入文件便于下一步的分析.数据获取流程步骤如下:
(1)获取用户的标签数据;
(2)定时获取数据中的数据;
(3)读数据进行处理;
(4)将处理好的数据分别写入对应的文件中.
如图2所示:
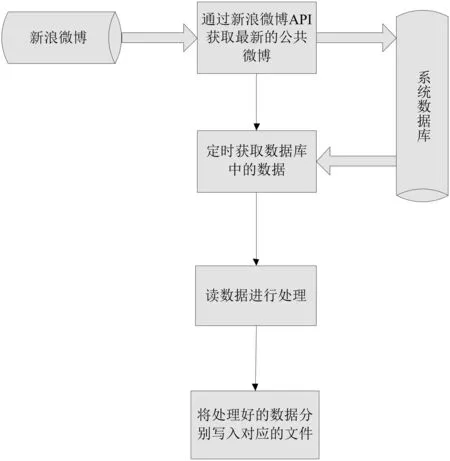
图2 数据获取流程图
根据图2,设定特定的微博用户帐号(uid)为实验帐号,抽取实验帐号已经关注的好友(friendid)标签.由指定实验帐号登陆微博平台,进入信息抽取页面;再获取用户的关注列表(即follow表)和用户标签(即tag表).
2.2实验步骤
本文中实验帐号用户的标签有: 旅行、出租车、美食、服装、机器学习等9个标签.下面是数据预处理的步骤:
(1)计算语义距离
由词语之间的相近程序来表示语义距离,相似程度反映两个词之间关联度.用户标签一般由若干个短语构成.本文实验帐号用户的标签由9个短语构成,由这9个短语构成一个9×9相似度矩阵M9×9,矩阵中的每个值表示两个短语间的相似度,即语义距离.
本文采用用Xsimilarity[12]语义距离计算软件进行计算,计算结果如下矩阵:
图3 相似度矩阵
其中标签集合为C={class1,class2,class3,…,class9},|C|=9.
(2)合并标签
语义距离体现了短语之间的关联程度,所以两个关联程度较高的短语可以合并为一类短语,可以降低数据维度.因此,在本文中,定义语义距离的阈值为0.5,当语义距离>=0.5时将两个短语合并成一个短语.
本文实验中的短语经合并后变为7个标签,对应一个R'7×7的相似矩阵,即C'={class1,class2,class3,…,classn},|C'|=7.如图4所示:

图4 合并后的相似矩阵
(3)计算各层用户之间的相似度
1)求0层和第1层的相似度
2)取1层用户的每一个标签与第0层的一个标签计算相似度
3)取1层用户id
4)取1层用的每一个标签
5)计算1、2层用户间的相似度
6)计算1、2层用户间的标签相似度
7)取2层用户id
8)计算1层用户所有的标签与1层用户的某一个用户的所有2层用户标签的权重.

图5 Top-3推荐结果
经过以上计算,最终将用户的相似矩阵导入到txt文件中,通过排序取出相似度排前三的用户作为推荐对象.推荐结果如图5(见上一页)所示.
图5中,1230663070、1664207987、1197930844为与目标用户1191042674相似度前三的用户,用户下方向为推荐结果.根据图5可以看出,本文中所采用的推荐算法,可以根据标签信息发现朋友圈,在推荐系统中对好友进行有效推荐.
3 总结
本文以新浪微博的标签数据作为推荐分析数据源,抽取了部分用户标签表(即tag表)和用户关注表(即follow表)中的10个标签作语义分析,建立基于用户标签的推荐算法.通过实验验证,通过标签的相似计算,可以寻找到有相似兴趣爱好的朋友圈,从而进行好友推荐,该方法可以在推荐系统中应用推广.但由于数据的抽取受到限制,对推荐的准确性无法进一步衡量,下一步工作将继续抽取大量数据进行实验,进一步提高推荐的准确率.
参考文献:
[1]吕本富, 张崇. “互联网+”环境下信息安全的挑战与机遇[J]. 中国信息安全, 2015,(6):34-36.
[2]王元卓,贾岩涛,刘大伟,等.基于开放网络知识的信息检索与数据挖掘[J]. 计算机研究与发展, 2015, (2):456-474.
[3]朱郁筱,吕琳媛.推荐系统评价指标综述[J]. 电子科技大学学报, 2012, (2):163-175.
[4]孟祥武,刘树栋,张玉洁,等.社会化推荐系统研究[J]. 软件学报, 2015, (6):1356-1372.
[5]丁少衡,姬东鸿,王路路. 基于用户属性和评分的协同过滤推荐算法[J].计算机工程与设计, 2015,(2):487-491.
[6]硕良勋,柴变芳,张新东. 基于改进最近邻的协同过滤推荐算法[J].计算机工程与应用, 2015,(5):137-141.
[7]于洪,李俊华.一种解决新项目冷启动问题的推荐算法[J].软件学报, 2015,(6):1395-1408.
[8]盛伟,王保云,何苗,等. 基于评分相似性的群稀疏矩阵分解推荐算法[J]. 计算机应用, 2017,(5):1397-1401.
[9]王红.改进Pearson相关系数的个性化推荐算法[J]. 山东农业大学学报(自然科学版), 2016,(6):940-944.
[10]滕少华,麦嘉俊,张巍,等.一种基于混合相似度的用户多兴趣推荐算法[J]. 江西师范大学学报(自然版),2016,(5):481-486.
[11]程广东,秦一方.基于新浪微博API的话题分析系统[J].山东交通学院学报, 2015,(4):78-86.
[12]Silva M E V D,Nunes E. XSimilarity : Uma Ferramenta para Consultas por Similaridade embutidas na Linguagem XQuery[R]. 2008.
