基于Spark的大规模语义规则后向链推理系统
2018-05-04王善永袁春风黄宜华
顾 荣,王善永,郭 晨,袁春风,黄宜华
(1. 南京大学 计算机软件新技术国家重点实验室,江苏 南京 210093; 2. 江苏省软件新技术与产业化协同创新中心,江苏 南京 210093)
0 引言
1998年,创建万维网联盟(W3C)的蒂姆·伯纳斯·李(Tim BernersLee)前瞻性地提出了语义网(semantic web)的概念,希望通过给万维网上的文档添加语义(meta data),使得万维网成为一个能被计算机理解的通用信息交换媒介。2001年,万维网联盟制定了语义网行动计划,经过十多年的发展,语义网相关的理论基础和技术规范逐渐得到完善,符合语义网数据模型规范的语义数据快速积累。与此同时,语义技术不断地在商业和研究等领域获得应用。例如,在商业领域,全球最大的搜索引擎公司Google创建了Google知识图谱(Google Know-ledge Graph)[1],使用语义检索从多种信息源获取信息,辅助提高Google搜索引擎的搜索质量;在医学领域,药物研究者利用语义技术来发现药物之间的联系,辅助药物开发。另一方面,语义推理技术受软硬件环境所限,还无法非常高效地推理大规模语义数据,尤其是大规模并行化的后向链语义推理问题还没有高效的处理方法。
自MapReduce[2]被提出以来,大数据处理技术在存储、查询和计算方面都取得了快速的突破性发展。近几年来,以Spark[3]为代表的内存计算技术逐渐成熟,其典型的吞吐量大、可靠性高、部署成本低廉等特点,为大规模数据处理提供了可靠的平台,成为大规模语义推理的一个新的研究方向。
传统的后向链语义推理是一种单机串行的推理方法,目前已有并行化的后向链语义推理方法出现,但大多是支持简单规则的弱推理。本文在研究了后向链语义推理算法和总结前人方法的基础之上,提出了一种基于Spark大数据计算平台的大规模并行化语义规则后向链推理方法,归纳为以下三个方面。
(1) 针对大规模推理问题,设计了实时预计算本体数据闭包的策略,避免了频繁出现的本体模式在实时推理阶段的重复计算。
(2) 在后向链语义推理的过程中设计了优化措施,进一步提高了推理的效率。在逆向推理阶段,根据推理模式在不同层次间的数据依赖关系,尽早剪除无效推理分支。在查询阶段,利用Spark SQL优化查询过程。
(3) 设计并实现了基于Spark 平台的大规模分布式RDFS/OWL后向链语义推理系统。
本文第一节简要介绍了语义推理的相关概念;第二节介绍了后向链语义推理的相关工作;第三节分析并设计了后向链语义推理的框架流程;第四节介绍了后向链推理的逆向推理和查询优化;第五节分别在LUBM和DBpedia数据集上对系统进行了实验;最后对全文进行了总结。
1 背景知识
1.1 语义推理相关概念
资源描述框架(resource description framework, RDF)是万维网联盟指定的一种灵活且领域无关的数据模型。在使用RDF描述某一特定领域知识时,需要专门定义一套领域相关的词汇表,并以某种语言来刻画词汇表的语义,这就是RDF Schema[4],简称为RDFS。RDFS在RDF的基础上,给用户描述特定领域中的类和属性提供了标准语义。
RDFS主要包含类、属性、子类、子属性、值域和定义域等几个核心概念,其表达能力相对有限,难以描述万维网中更加复杂的结构关系,于是W3C又制定了描述能力更强的网络本体语言OWL(web ontology language)[5],提供了更强大的知识表示和推理能力。但同时我们也看到,OWL的每个版本都有几个精简子集(OWL Lite,OWL2 QL,OWL2 RL等),更强的表达能力意味着更高的计算复杂度,甚至不可判定,即不能够推理出符合复杂本体描述语言语义的结论(比如 OWL Full)。目前已实现的推理引擎中,大部分是实现了对OWL精简子集的推理或者是仅支持部分语义,OWL Horst就是这样一种被广泛接受的具有较强表达能力并能大幅度降低计算复杂度的规则集。基于OWL Horst规则集的推理又称为pD*推理,涵盖了所有RDFS蕴涵(RDFS entailment)和D蕴涵(D entailment),成为语义推理中使用最广泛的规则集[6]。OWL Horst规则集包含了RDFS规则集。另外OWL Horst规则集中的某些规则,例如,规则rdfp5a: (v,p,w)=>(v, owl: sameAs,v)和rdfp5b: (v,p,w)=>(w, owl: sameAs,w)表达了任意三元组的主语和宾语都是和自身相似的,这对推理应用以及用户来说都没有意义。在大多数语义推理系统[6-8]中,都没有考虑这些没有意义的规则的推理。在此,忽略掉RDFS规则集和OWL Horst规则集中对推理没有意义的规则,把其他规则列于表1中并重新编号,便于后文对这些规则的引用,其中规则R1到规则R6属于RDFS规则集。
表1RDFSOWLHorst规则集

基于规则的推理方法又分为前向链推理和后向链推理[9]。
前向链推理就是根据规则推导出结论的过程,在推理发生时,推理机应用规则到要推理的数据上,并把推理结果存储到数据库中,一旦推理完成,知识库将是完整的,即所有隐式数据都被显式化了。这样,语义推理问题就变成了单纯的查询问题。其缺点也是显而易见的,隐式知识显式化要额外占用大量存储空间,同时数据库也不可能一直保持不变,一旦数据库有新知识插入,那么推理任务就需要重新做一遍,这是非常耗时的。
后向链推理就是反向应用规则,例如,命题A1,A2,…,An→B,要证明B只要去证明规则的前件A1,A2,…,An。从推理发生的时机来说,后向链推理就是有查询请求的时候针对这个查询请求执行的推理。后向链推理不需要额外存储隐式知识,它只是在查询时才挖掘隐含知识,这降低了存储空间开销,并且在数据库更新时不需要额外的操作。不过,处理的代价也是显然的,就是查询请求因为附带上推理而造成响应时间的延长。后向链推理特别适合应用在知识库更新频繁的场景下。本文主要研究基于Spark的并行化后向链推理算法。
1.2 分布式系统Spark介绍
Spark是由UC Berkeley AMPLab实验室于2009年发布的分布式内存计算框架,它是Berkeley Data Analysis Stack(BDAS)中的核心项目。RDD[3](resilient distributed dataset)是Spark中的核心数据结构。Spark定义了RDD上的三种操作: 转换(transformation)、动作(action)和控制(control)。转换包括map、join、filter、union等Spark内置函数,它从一个RDD计算出另一个RDD,比如模式匹配操作相当于RDD上filter操作,合并两个集合的操作相当于RDD上的union操作,而把一个数据集合内的每一个元素映射成另一种形式的操作,相当于RDD上的map操作。
RDD上的动作包含reduce、count、collect、saveAsTextFile等Spark内置函数,比如合并一个集合里所有元素的操作相当于RDD上的reduce操作,统计一个数据集合里有多少个元素的操作相当于RDD上的count操作,把数据保存到存储系统的操作相当于RDD上的saveAsTextFile操作。RDD上的转换仍然得到RDD,而RDD上的动作是返回一个本地数据类型给Driver进程,或者把RDD写入文件系统。控制操作包括cache、persist、checkpoint等Spark内置函数,控制操作不改变RDD,也不返回本地数据类型,而是缓存RDD、设置检查点等,用于Spark程序的性能调优。
2 相关工作
前向链推理在RDF数据更新后需要重新计算,计算整个闭包时间较长,但在查询时不需要查询以外的开销;而后向链语义推理是一种推理发生在查询时的推理方法,对RDF数据更新不敏感,但增加了查询的时间开销。随着RDF数据增长速度越来越快,前向链语义推理的弊端逐渐显现出来,后向链语义推理开始进入人们的视野。RDF数据管理系统Jena[10]使用一个类似于Prolog引擎的逻辑程序来提供对后向链语义推理的支持,允许自定义推理规则集,但功能较弱,单机的架构难以处理大规模RDF数据。AllegroGraph[11]是一个商用的大规模图数据库,它的后向链语义推理引擎RDFS++支持RDFS规则集和OWL规则集中的部分规则,并且有较高的性能表现。但为了提高性能,它牺牲了推理的完备性和对规则集的完整支持。Virtuoso[12]是一种基于列存储系统的后向链语义推理系统,但该系统没有进行特殊的优化,并且只支持RDFS和OWL的少部分规则。
文献[13]和文献[14]提出了一种对规则条件的执行次序进行优化选择,从而提高推理效率的方法。文献[15]提出了OLDT,这是一种避免推理树过深和避免规则扩展陷入死循环的方法。文献[16]和文献[17]提出了查询策略选择函数,并综合了规则条件执行次序的优化方法[13-14]、OLDT[15]和sameAs 优化方法,提出了一种优化的后向链推理方法。该方法是一种在单机上递归执行的方法,不能处理大规模RDF数据。文献[18]提出了一种RDF数据存储与查询系统,支持后向链推理,但只支持rdfs: subClassOf、rdfs: subPropertyOf和owl: EquivalentProperty三种语义的推理。文献[7]提出了QueryPIE,这是一种基于高性能计算平台DAS4 的后向链语义推理方法,它通过对推理树的剪枝和把RDF数据映射为数字ID来加速推理过程,支持OWL Horst规则集的后向链推理,具有很高的处理能力。但是,该方法存在两个方面的不足: (1)高性能硬件加速不具有普适性;(2)把大规模RDF数据映射为数字ID存在着更新数据开销大和推理前后的RDF数据与数字ID相互映射开销大的问题。
3 后向链语义推理分析和系统设计
3.1 后向链语义推理过程分析
后向链语义推理是一种目标驱动的推理方式。表2给出了一个简单推理规则集的例子,该规则集包含三条规则,定义了子属性关系、对称关系和传递关系。
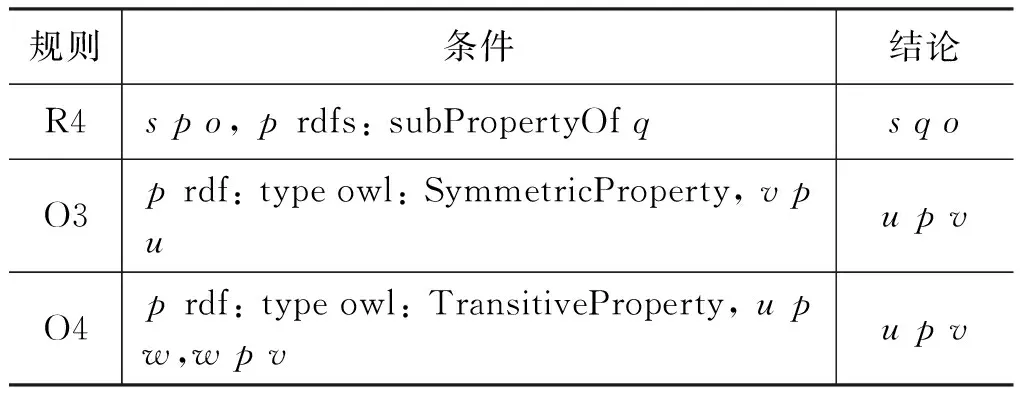
表2 简单规则集举例
假设要求解Lliy为谁工作,推理查询模式是(Lily, worksFor,?who),记为Q,推理规则使用表2的简单规则集。除了直接到知识库里查找符合结论的三元组之外,还要考虑应用规则推导出结论。首先观察规则,发现Q比规则R4的结论更具体,即Q是将R4结论三元组中的若干变量替换成具体RDF数据得到的。所以在推理过程中,有可能通过规则R4推理出三元组T,使得T比Q更具体。于是,将Q的主语、谓语和宾语与规则R4的结论一一对应,并实例化规则R4 的条件(即把变量s替换为“Lily”,把变量q替换为“worksFor”),就能得到两条新的三元组模式(Lily,?p,?who)、(?p, rdfs: subPropertyOf, worksFor),这两条三元组模式又作为新的推理查询,同时满足这两条推理查询模式的三元组将应用规则R4推导出满足模式Q的结论。同理,规则O3和O4也能用来推导出三元组模式Q。使用表2中给出的规则集进行三元组模式Q的推理,其过程可以用一颗推理树来表示(图1)。
图1中,推理树中根节点表示推理模式Q,圆角矩形框代表所运用的规则,直角矩形框代表新的推理查询模式。每条三元组模式下应用的规则属于“或”的关系,而每条规则下展开的三元组模式属于“与”的关系。这样每个推理模式从上至下依次展开,对于每个矩形节点的三元组模式,将对知识库进行查询,查询的结果从下往上使用规则推导出上层结论。在最顶层得到的推理结果就是最终的查询结果。
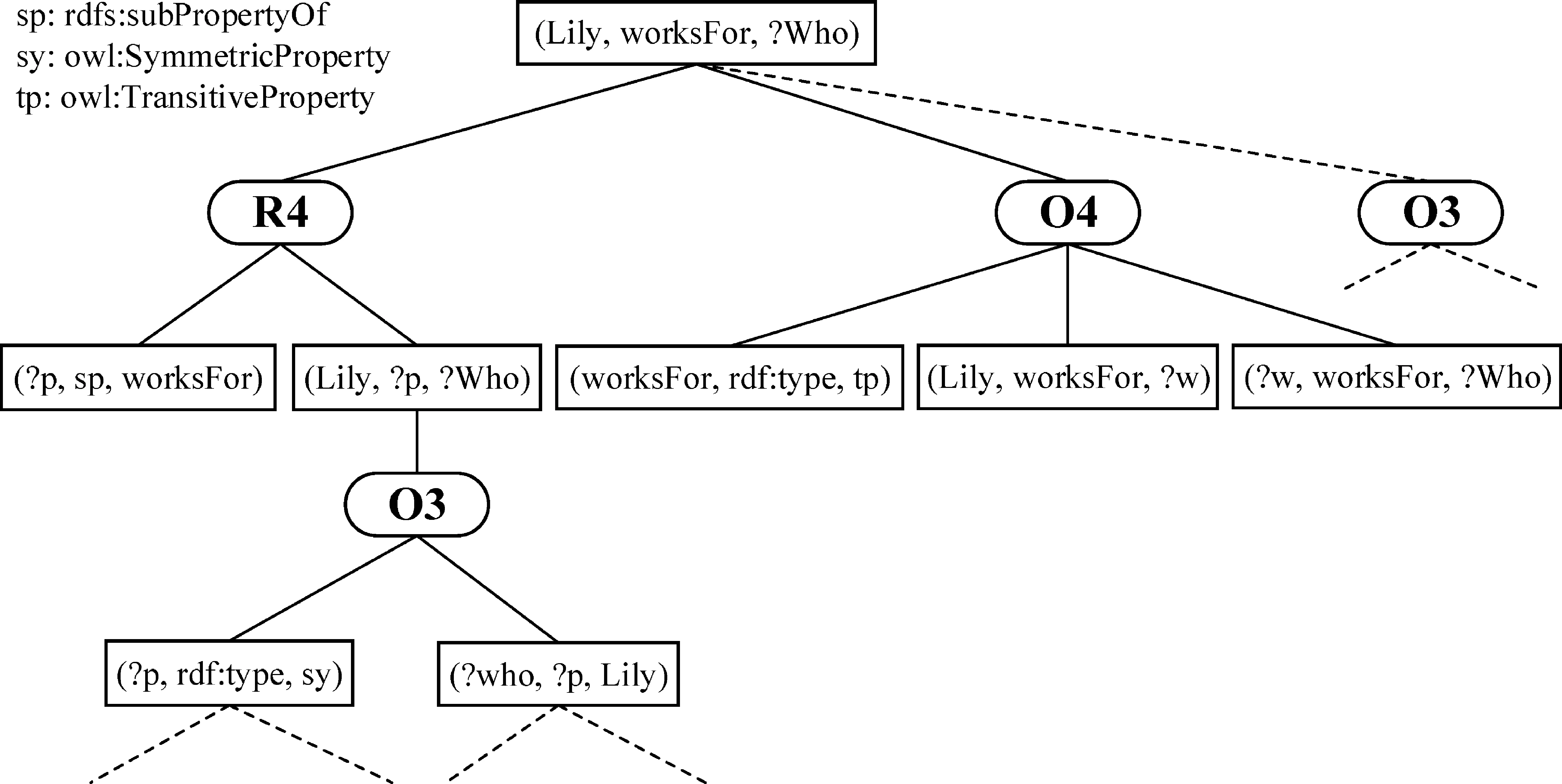
图1 简单规则集上的推理树示例
3.2 后向链语义推理的并行化和系统设计
通过3.1节对后向链推理的过程分析,我们发现整个算法可以分成三个主要阶段: (1)逆向推理(推理模式扩展); (2)查询(查询模式匹配); (3)正向推理(根据规则合并结果集)。
在逆向推理阶段,推理树被自上而下创建(图1)。逆向推理找出能够证明结论的隐式证据,这一过程根据给定的规则集扩展出新的推理模式,不需要操作大规模语义数据。在查询阶段,查询模式在大规模语义数据上匹配满足条件的三元组。这一阶段需要全局地过滤语义数据,时间开销比较大。在正向推理阶段,规则应用在查询结果集上,从而推导出结论。
结合对后向链语义推理过程的分析,我们把后向链语义推理中的查询过程用RDD上的filter操作来实现,由各个计算节点并行计算,加快查询过程。假设语义数据已经载入内存并以RDD表示,图2演示了RDD上的查询过程。
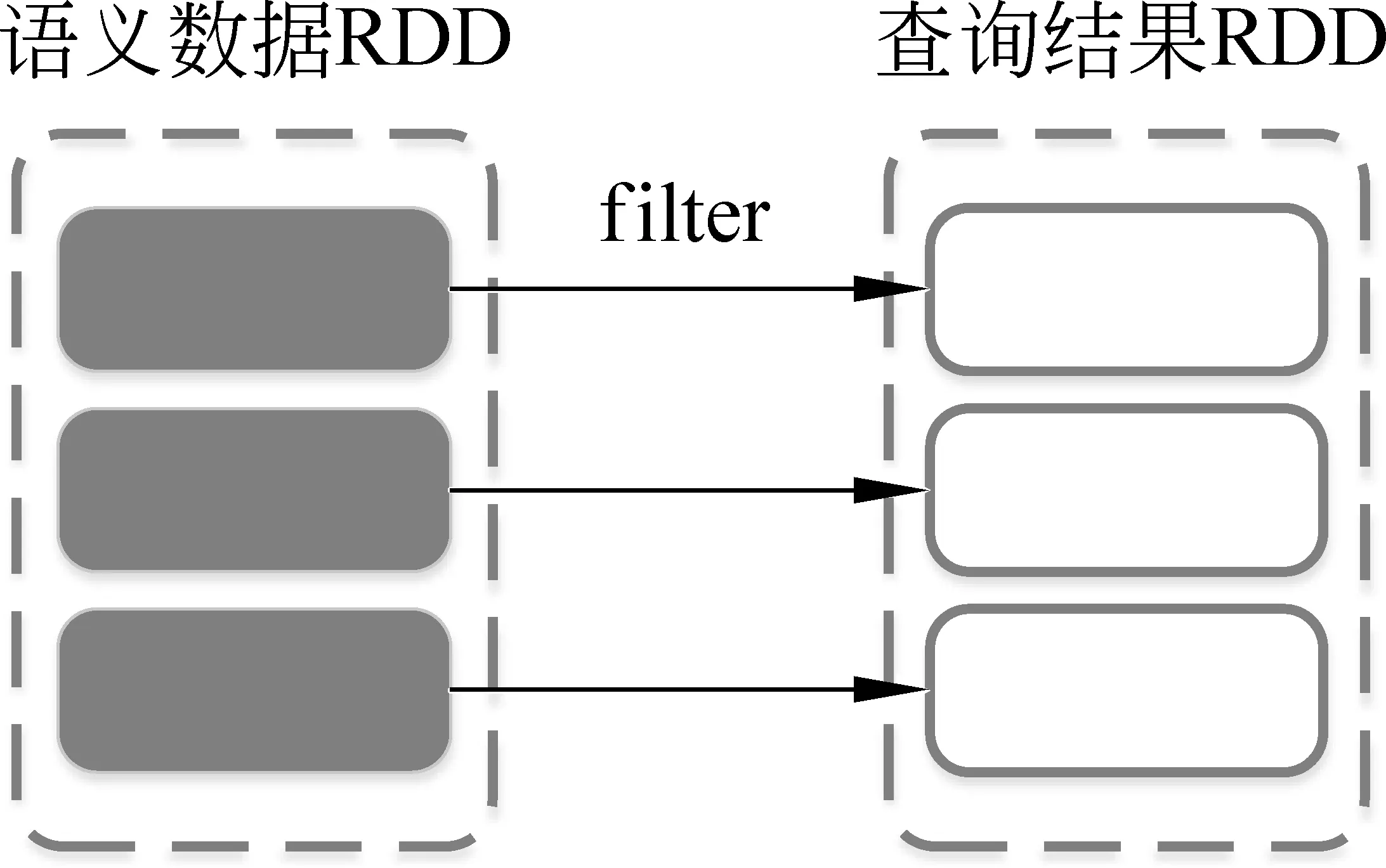
图2 用RDD表示的查询过程
查询完成之后,需要在多个查询结果上应用规则推导结论,用Spark的RDD模型来刻画的话,就是在多个结果RDD上使用join操作,如图3所示。

图3 用RDD表示的正向推理过程
结合Spark大数据计算平台的特点,本文提出了大规模并行化后向链语义推理方案,如图4所示。系统架构图中主要包含逆向推理层、存储与查询层、正向推理层。逆向推理层实现规则扩展,在Driver端串行执行,其中圆角矩形表示规则,直角矩形表示三元组模式,带阴影的直角矩形是本体三元组模式。存储与查询层实现存储与查询优化,存储上采用RDD的高级封装形式DataFrame,虚线框表示DataFrame,查询使用Spark SQL模块加速。正向推理层实现在查询结果上推导结论,根据应用的规则不同,分别使用了不同的优化方法。

图4 大规模并行化后向链语义推理系统架构
4 逆向推理与查询优化
4.1 本体数据闭包共享
表1中,不管是RDFS还是OWL规则集,每条规则的条件总是包含至少一条本体三元组输入,因此本体三元组模式在规则扩展的推理树里会频繁出现。另一方面,本体术语词汇来自于本体描述语言,数量有限,这限制了本体模式的数量,因此在大量的后向链推理请求中,本体模式会被重复推理。所以本文提出了共享本体推理查询结果的优化方法,以此降低推理查询时的计算开销。
4.1.1 RDFS规则集上的本体数据闭包算法
RDFS规则集中,规则R3推导出的结论可以作为规则R4的条件,而规则R4推导出的结论又可能是规则R1和规则R2的条件,分析RDFS规则间的这种依赖关系可以发现,推理结论是本体三元组的规则,规则条件都是本体三元组,因此RDFS本体三元组的推理不依赖于实例数据,在本体数据上即可完成。RDFS本体数据闭包的计算用伪代码描述见算法1。

算法1 RDFSOntologyClosure输入:本体三元组onto_triples输出:本体三元组闭包rdfs_closuresc=onto_triples.filter(t=>t._2.equals(“rdfs:subClas-sOf”)) .map(t=>(t._1,t._3))DO{ inferredTriples=sc.map(t=>(t._2,t._1)) .join(sc) .filter(t=>t._2._1!=t._2._2) .map(t=>(t._2._1,t._2._2)) sc=sc.union(inferredTriples) .distinct}WHILE(schaschanged)//rdfs:subPropertyOf的计算和以上类似rdfs_closure=onto_triples.union(sc).union(sp)RETURNrdfs_closure
4.1.2 RDFS规则集上的本体数据闭包算法
从表1中OWL Horst规则集来看,OWL Horst规则集的依赖关系比RDFS规则集复杂得多,不存在一个拓扑序,并且本体三元组的推理涉及实例数据,因此不能用RDFS本体数据闭包的计算方法。在OWL本体数据闭包的计算方法中,用所有的本体三元组模式做推理查询,这时候本体数据闭包可能缺失一些隐式的本体三元组,导致推理结果不完整。此时,把推理出来的本体三元组模式插入到本体闭包中,重新用本体三元组模式做推理查询,并把推理结果插入到本体闭包中,如此循环,直到推理不出更多新的本体三元组,本体数据闭包就完整地计算出来了[19]。OWL本体数据闭包的计算方法用伪代码描述如下。

算法2 OWLOntologyClosure输入:Ontologytriples:OTKnowledgeBase:KB //instancetriplesOntologytriplepatterns:Qs输出:Ontologyclosure:owl_closureDO Inferred-triples={} FORqINQsDO Inferred-triples+=Backward-chaining-reasoner(q) END OT.insertAll(Inferred-triples)WHILEInferred-triplesisnotemptyowl_closure=OTRETURNowl_closure
4.2 使用本体数据闭包优化的规则扩展过程
根据RDFS规则的输出中谓语是否是rdf: type、本体词汇或可绑定变量,可以把RDFS规则分为以下三类。
(1) 输出三元组的谓语是本体词汇的规则: R3、R6。
(2) 输出三元组的谓语是rdf: type的规则: R1、R2、R5。
(3) 输出三元组的谓语是可绑定变量的规则: R4。
在接下来的分析中,将引用4.1.1节计算的RDFS本体数据闭包rdfs_closure,并记为G1。
对于第一类规则,即规则R3 和R6,在本体三元组数据闭包已经计算出来的情况下,推理树生长到本体三元组模式的节点,可以直接从本体闭包中读取本体三元组模式的推理结果,因而推理树在扩展到本体三元组模式的节点时不需要继续扩展。
对于第二类规则,以规则R1: (p, rdfs: domain,x)&(s,p,o)=>(s, rdf: type,x)为例,根据推理模式的主语、谓语、宾语是已知还是可绑定变量,分为七种组合情况。这里,对于主、谓、宾都是自由变量的完全查询模式不予讨论。其原因一是没有限制条件的查询没有实际意义,二是这将导致后向链推理引擎推理出所有蕴涵知识,相当于做了前向链推理的事情,失去了后向链推理的意义。实际上,在应用规则扩展查询的过程中,也不会产生主、谓、宾全都是变量的模式(规则扩展过程中被优化掉了)。所以在本文中不再讨论推理模式中主、谓、宾都是变量的情况。
(1) 推理模式中只有主语为变量(?subj, pred, obj)。这种情况下,将推理模式带入规则R1,发现推理模式的谓语pred一定是rdf: type,否则无法由规则R1推出。在谓语是rdf: type的情况下,规则R1可扩展该查询,得到两个新的推理模式(?p, rdfs: domain, obj)和(?subj, ?p, ?o)。这些新的推理模式作为推理树的分支,即推理树在该分支生长,生成的分支也就是新的推理模式,可以继续递归地做推理查询。
(2) 推理模式只有谓语为变量(subj, ?pred, obj)。这种情况下,规则R1推导的结论里谓语是rdf: type,即如果规则R1对该推理模式有贡献,贡献一定是(subj, rdf: type, obj)。而(?p, rdfs: domain, obj)&(subj, ?p, ?o)=>(subj, rdf: type, obj),本体三元组模式(?p, rdfs: domain, obj)在本体闭包G1中找出所有?p的集合p_set,对每一个p∈p_set,有新的推理模式(subj, p, ?o),这些新模式作为推理树的分支,即推理树在该分支生长,生成的每个分支继续递归地做推理查询。
(3) 推理模式只有宾语为变量(subj, pred, ?obj)。这种情况下,推理模式的谓语pred等于rdf: type,否则规则R1对该推理模式没有贡献。推理模式代入规则R1后,有: (subj, pred, ?obj)<=(?p, rdfs: domain, ?obj)&(subj, ?p, ?o)。对这两个新的推理模式的处理有两种方式,一种是绑定变量方式,另一种是自由变量方式。
(4) 推理模式中主语和谓语都是变量(?subj, ?pred, obj)。这种情况下,应用规则R1把推理模式的谓语绑定为rdf: type,推理模式变为(?subj, rdf: type, obj),即退化为(1)中的情况。
(5) 推理模式中主语和宾语都是变量(?subj, pred, ?obj)。这种情况下,推理模式的谓语pred一定等于rdf: type,否则不能由规则R1推导出来。对每一个pi,rdfs: domain,obji∈G1(pi, rdfs: domain, obji)∈G1,代入规则R1后,有(?subj,pi,?o)=>(?subj,rdf: type,obji)(?subj, pi,?o)=>(?subj, rdf: type,obji),即在该节点将产生新的分支(?subj,pi,?o)(?subj, pi, ?o)。
(6) 推理模式中谓语和宾语都是变量(subj, ?pred, ?obj)。这种情况下,绑定推理模式中的谓语“?pred”为rdf: type,推理模式变为(subj, rdf: type, ?obj),即退化为(3)中的情况。
(7) 推理模式是无参三元组模式(subj, pred, obj)。这种情况下,推理模式谓语pred一定等于rdf: type,否则规则R1不能推导出该模式。代入规则R1后,有(?p, rdfs: domain, obj)&(subj, ?
p, ?o)=>(subj, rdf: type, obj)。对于每一个pi,rdfs: domain,obj∈G1(pi, rdfs: domain, obj)∈G1,有(subj,pi,?o)=>(subj,rdf: type,obj)(subj,pi,?o)=>(subj,rdf: type,obj),其中,(subj,pi,?o)(subj,pi,?o)是推理树的新分支。
对于第三类规则,即规则R4: (s,p,o)&(p, rdfs: subPropertyOf,q)=>(s,q,o),规则的结论是完全推理模式,与任意推理模式兼容。三元组推理模式pattern根据主语、谓语和宾语是已知量还是自由变量,可以分为七种情况进行类似的处理: 推理模式中只有主语为变量(?subj, pred, obj)、推理模式中只有谓语为变量(subj, ?pred, obj)、推理模式中只有宾语为变量(subj, pred, ?obj)、推理模式中主语和谓语都是变量(?subj, ?pred, obj)、推理模式中主语和宾语都是变量(?subj, pred, ?obj)、推理模式中谓语和宾语都是变量(subj, ?pred, ?obj)、推理模式是无参三元组模式(subj, pred, obj)。
4.3 快速剪枝优化
在一个三元组模式扩展的推理树中,同一条分支上的不同节点可能拥有相同的变量,同一个变量在不同节点上必须满足不同的三元组模式。如果不同节点上的三元组模式推理出的该变量集合没有交集,那么该分支不会产生最终的有效推理结果。例如,对于图1中最深层的规则O3扩展出的两个新的三元组模式(?p, rdf: type, owl: SymmetricProperty)和(?who, ?p, Lliy)。其中的变量?p 和 ?who 与上层规则R4的两个条件模式(?p, rdfs: subPropertyOf, worksFor)和(Lyli, ?p, ?who)中的变量?p 和 ?who指代相同。如果某两个模式中的同一变量的解空间没有交集,则该分支的推理结果也是空集。
对于较为容易判断的本体三元组模式(?p, rdfs: subPropertyOf, worksFor)和(?p, rdf: type, owl: SymmetricProperty),如果推理中能快速判断出没有同时满足这两个模式的RDF数据项,那么该推理分支就可以直接丢弃,省去了进一步的推理计算过程。实际上,在4.2节基于本体闭包的规则扩展优化基础上,对于同一推理分支上的两个本体三元组模式,可以快速判断结果集是否有交集。利用这一优化方案能够快速剔除一些无效的计算分支。
4.4 基于Spark SQL的查询优化
针对后向链语义推理中涉及多次查询,并且正向推理阶段需要在查询结果上做连接的需求,本节提出一种基于底层分布式计算框架Spark的RDF数据存储方案和使用Spark SQL进行查询的执行方案。
Spark SQL[20]是Apache Spark的一个组件,使得用户可以在Spark上进行数据的关系操作。Spark SQL对RDD进行了更高级的封装,称为DataFrame,用来支持数据的存储和操作。另外在查询作业的各个阶段,Spark SQL也设计了若干优化方式提升查询作业的性能。
Spark的核心数据结构是RDD,RDD可以看作是Java对象的集合,Spark并不能看到Java对象内部的细节。与RDD类似,DataFrame也是一个分布式数据容器,但是DataFrame内部除了数据以外,还维护了数据的结构信息,即Schema,两者组合使得DataFrame看起来更像传统数据库中的一张二维表。这两种组织结构的区别见图5。

图5 RDD与DataFrame结构的差异
由于Spark对RDD元素的内部细节一无所知,所以RDD包含的数据进入内存(触发计算或者cache)时是按行存储的。而DataFrame的数据进入内存时,是按列存储的,这样做有两个好处。
(1) Spark可以根据DataFrame中列的类型信息,用更有针对性的结构存储每列的数据,有利于压缩数据以提升操作性能。Spark SQL的查询优化器还能对查询列的类型进行针对性的优化。
(2) 在行存储的情况下,数据的每一行会生成一个Java对象;在大数据的情况下,行存储会生成数量繁多的小对象,对Java GC造成巨大压力。而使用列存储的方式,每列数据只会生成一个或几个对象(在大数据情况下为了防止单个对象过大,每列会生成几个对象),对象的数目显著降低,Java GC的压力也会随之减轻。
此外,Spark SQL在查询作业的不同阶段设计了若干优化方式。谓词下推是一个使得过滤操作提前进行的优化措施。由于DataFrame也具有RDD惰性计算的特性,这就使得Spark SQL可以分析整个查询作业,将过滤操作(filter等)尽可能前推,甚至可以前推到读取数据时,从而有效地减少参加运算和传输的数据量。列剪枝也是一种精简数据量的技术,由于DataFrame是按列组织的,同时具有Schema信息,使得Spark SQL可以分析查询作业,精简掉查询过程中不需要的列,减少参与运算和传输的数据量。
由于Spark SQL和DataFrame的上述优势,本文将后向链语义推理的查询和正向推理阶段表达成一系列对DataFrame的查询作业。
本系统将经过规则作用扩展出的若干相互之间为“与”关系的三元组包装为一个请求。在3.1节的例子中,三元组(Lily,?p,?who)和(?p, rdfs: subPropertyOf, worksFor)是被规则R4作用扩展出来的,于是会被包装为一个请求。当请求中的所有三元组都不能利用规则进行扩展时,就应触发查询与正向推理。若三元组中存在本体术语词,则直接在本体闭包中查询,否则应在实例数据中查询。
得到每个请求的结果后,结果就可以沿着推理树向上前进,与其他分支产生的结果进行合并。如此循环往复,直到所有结果前进到树根,原问题得解。
基于Spark SQL的查询过程用伪代码描述如下。

算法3 基于SparkSQL的查询过程输入:一个查询请求:query:Set
5 性能评估
5.1 实验环境与设置
本节我们从推理时间、数据可扩展性和计算节点可扩展性三个方面对本文提出的系统进行评估,实验使用的集群节点配置如表3所示。

表3 计算节点配置表
5.2 实验环境与设置
5.2.1 合成数据集及测试样例
The Lehigh University Benchmark(LUBM)[21]提供标准的本体数据集和用于生成实例数据集的数据生成工具,并且包含一组标准查询测试样例,可用于测试查询性能也可以用于测试后向链语义推理性能。使用LUBM可以生成任意规模的模拟数据集,给语义推理系统的性能测试带来了方便。
实验中使用了LUBM-100、LUBM-200、LUBM-400、LUBM-600、LUBM-800、LUBM-1000六种规模不同的LUBM数据,分别包含13 million、25 million、50 million、78 million、100 million、133 million条三元组。下文将此数据集简称为LUBM数据集。实验使用LUBM Benchmark提供的14条标准查询样例进行测试。
5.2.2 真实数据集及测试样例
DBpedia[22]是在社区共同努力下从Wikipedia抽取的结构化数据集,数据来源多领域、多语言,允许用户从中查询维基百科的数据以及从维基百科连接到的其他数据源。本文实验使用DBpedia英文版数据,包含DBpedia-50、DBpedia-100、DBpedia-150和DBpedia-200四组数据,分别包含50 million、100 million、150 million和200 million条三元组。下文将此数据集简称为DBpedia数据集。本文筛选了四个用于DBpedia测试的样例,包含两个简单推理模式和两个复杂推理模式。DBpQ1用于推理Alanthurai所属的国家;DBpQ2用于推理英文DBpedia中所有的游戏;DBpQ3用于推理意大利制作的所有电影;DBpQ4用于推理所有国家及其首都。
5.3 实验环境与设置
5.3.1 推理性能测试
性能实验使用的Spark和HDFS集群由一个主节点和12个计算节点组成,每个节点的软件和硬件配置见表3。本系统在LUBM数据集上的推理查询性能实验结果如图6和图7所示。

图6 在LUBM数据集上基于RDFS规则集的推理性能
由图6和图7所示的实验数据可见,在两个规则集上本系统的性能表现差异不大。在一千万条LUBM数据规模上,简单推理查询(如Q1、Q6、Q10、Q11、Q14)都可以在几百毫秒的时间级别上完成推理,复杂的推理查询(如Q2、Q4、Q9等)都可以在秒级完成;在一亿三千万条LUBM数据规模上,推理时间有所升高,但也都可以在32s内完成推理。
本系统在DBpedia数据集上的推理查询性能实验结果如图8和图9所示。
由实验数据可见,本系统在推理实验选取的四个推理模式时,可以在一两亿条三元组的真实数据集上完成秒级的后向链推理。
观察两个规则集下处理推理请求的时间,发现处理基于OWL规则集的推理请求要比基于RDFS规则集的推理请求更为耗时。这是因为OWL后向链推理是在RDFS后向链推理的基础上提出的,不仅完全包含RDFS规则集,而且OWL规则集的复杂度就像其描述能力一样比RDFS规则集高出许多。但是在实验中发现,OWL的后向链推理性能与RDFS相比虽有差异,但并没有差太多。原因有两点,一是数据集的复杂度不高,二是OWL规则集比RDFS规则集多出来的规则没有像RDFS规则集那么广泛地被应用。
对比LUBM数据集和DBpedia数据集上的实验后发现,基于Spark的并行化语义后向链推理系统不管是在合成数据集上还是在真实数据集上,都能在几秒到几十秒的时间内完成后向链语义推理,表现出了很好的推理性能。对于数据频繁更新的知识库来说,后向链语义推理每次几十秒的开销相对于前向链推理动辄几十分钟甚至几个小时[23]来说进步很大。

图7 在LUBM数据集上基于OWL规则集的推理性能

图8 在DBpedia数据集上基于RDFS规则集的推理性能

图9 在DBpedia数据集上基于OWL规则集的推理性能
5.3.2 数据可扩展性测试
一个设计良好的大规模语义推理系统应当能够处理各种规模的数据。为了考察系统的数据可扩展性,在保证计算集群的环境配置不变的情况下,测试本系统在不同数据规模下的执行时间。同时,语义推理不只对规则复杂度敏感,数据的复杂度也会对结果产生影响。实验中选用的LUBM大学数据由工具生成,数据复杂度不随规模变化。下面,本系统会基于RDFS和OWL规则集,分别进行数据扩展性实验。在LUBM数据集上,本系统的数据可扩展性如图10和图11所示。

图10 数据扩展性实验(LUBM+RDFS)

图11 数据扩展性实验(LUBM+OWL)
实验数据显示,本系统在两个规则集下再次表现出了类似的趋势。在LUBM benchmark的14条标准查询里,Q2和Q9是非常复杂的推理模式,分别包含了六条简单推理模式,在折线图中可以看出,这两条查询随着数据规模变大,推理时间明显增长。Q7和Q8属于中等难度的推理模式,Q1和Q13都是包含两条简单推理模式的复合模式,复杂度较Q7和Q8低,所以Q1的推理时间随数据规模变化最不明显,而Q13的推理时间升高应该是推理结果随着数据规模变大而变化的原因。
由此可见,基于Spark的并行化语义后向链推理系统的推理时间随着数据规模的扩大都是近线性上升,表现出了很好的数据可扩展性。
5.3.3 节点可扩展性测试
大规模语义推理使用分布式并行计算技术进行加速,一个扩展性好的系统,应该在增加节点时能提高处理速度,而在减少节点时则会增加处理时间。本文实验使用LUBM 1 000个大学数据集,在计算节点从一个增加到16个时观察系统的推理性能,得到系统推理时间随计算节点数的变化关系,实验结果见图12、图13。

图12 基于RDFS规则集的节点可扩展性

图13 基于OWL规则集的节点可扩展性
由实验数据可知,越是耗时的推理,增加计算节点获得的性能提升越明显。将实验结果整理成相对加速比,如图14和图15所示。相对加速比(S)是指同一算法在单节点环境下的执行时间(T1)和多节点(n个)环境下的执行时间(Tn)的比值,即s=T1/Tn。

图14 基于RDFS规则集的加速比
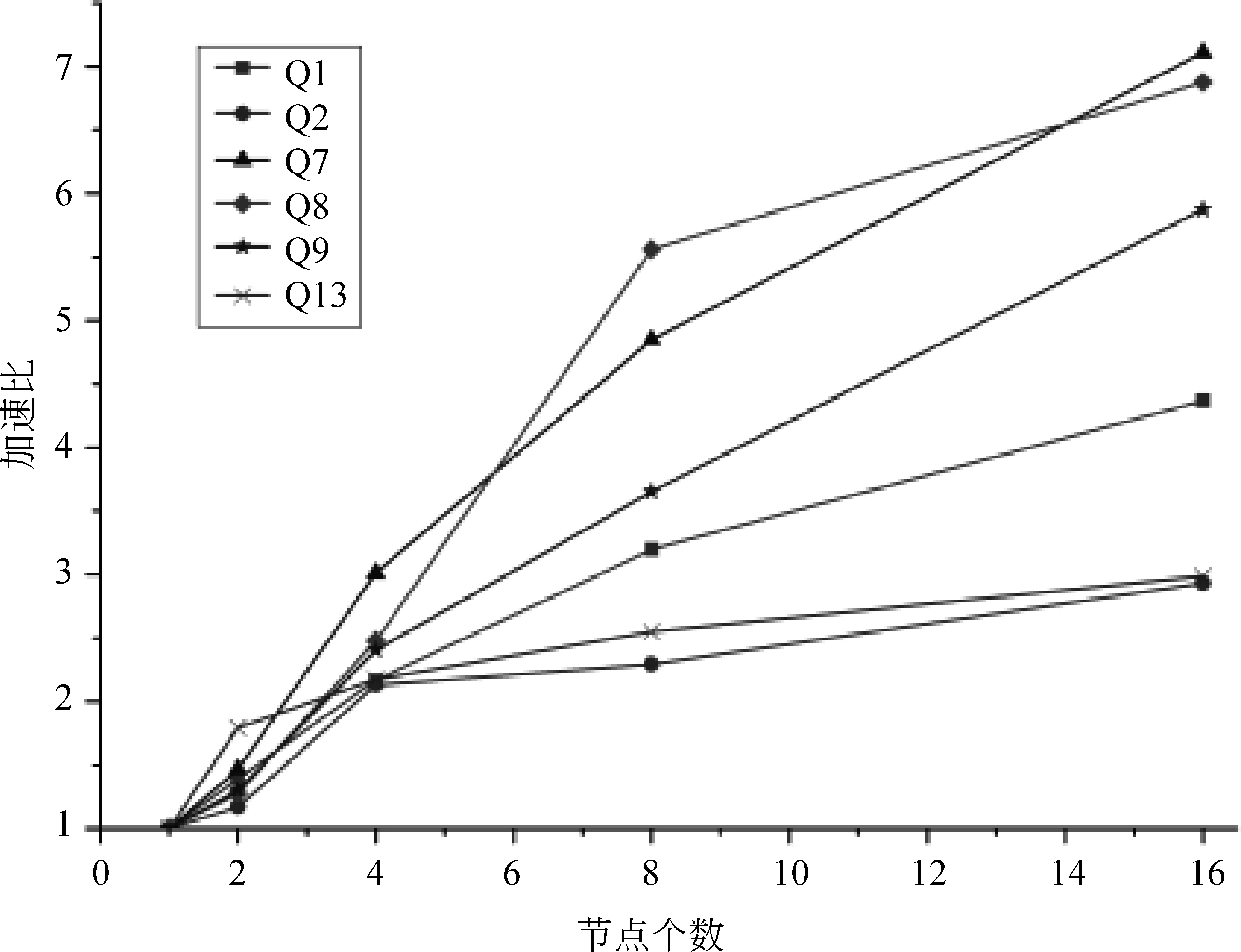
图15 基于OWL规则集的加速比
加速比曲线显示,多数推理模式随着计算节点数的增加,表现出了明显的加速趋势,所以本文提出的基于Spark的并行化语义后向链推理系统具有较好的节点可扩展性。
6 总结
语义推理是语义网技术体系中的高级分析技术,得到了工业界和学术界的广泛关注和研究,在辅助药物开发、社交关系分析等领域已经有成功应用。虽然前向链和后向链语义推理的目的相同,但到目前为止,人们提到语义推理主要还是指前向链语义推理,对语义推理的研究也主要集中在前向链方法上,后向链语义推理的研究因为推理过程复杂而进展缓慢。如今的互联网信息日新月异,前向链语义推理对于知识库更新而带来高昂代价的缺点逐渐显露,后向链语义推理的准实时推理查询、对知识库更新不敏感等特点恰好适用于知识快速更新的场景。因而设计实现高效的大规模后向链语义推理系统成为了新的研究课题。本文提出的基于Spark的大规模并行化语义规则后向链推理方法实现了并行化的后向链语义推理,并且在多方面进行了优化,实现了较好的推理性能。
在将来的工作中,我们将继续研究在更加复杂的规则集上进行后向链推理,并研究大规模RDF数据的快速编码和解码方法,进一步提高推理系统的表达能力和推理速度。
[1] Pelikánová Z. Google Knowledge Graph[DB/OL]. https: //www.google.com/intl/es419/insidesearch/features/search/knowledge.html[2014].
[2] Dean J, Ghemawat S.MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[3] Zaharia M, Chowdhury M, Franklin M J, et al. Spark: Cluster computing with working sets[J]. HotCloud, 2010(10): 10-10.
[4] W3C. RDF vocabulary description language 1.0: RDF schema[S]. https: //www.w3.org/TR/2004/REC-rdf-schema-20040210/
[5] McGuinness D L, Van Harmelen F. OWL web ontology language overview[J]. W3C Recommendation, 2004, 10(10): 10-20.
[6] Urbani J, Oren E, Van Harmelen F. RDFS/OWL reasoning using the MapReduce framework[J]. Science, 2009: 1-87.
[7] Urbani J, Van Harmelen F, Schlobach S, et al. QueryPIE: Backward reasoning for OWL Horst over very large knowledge bases[J]. The Semantic Web-ISWC 2011, 2011: 730-745.
[8] 施惠俊.基于云计算的海量语义信息并行推理方法研究[D].上海: 上海交通大学硕士学位论文,2012.
[9] 瞿裕忠,胡伟,程龚. 语义网技术体系[M]. 北京: 科学出版社, 2015: 32-60.
[10] Carroll J J, Dickinson I, Dollin C, et al. Jena: Implementing the semantic web recommendations[C]//Proceedings of the 13th International World Wide Web Conference on alternate Track Papers & Posters. ACM, 2004: 74-83.
[11] Franz Inc. Allegro graph: RDF triple database. [DB/OL] https: //franz.com/agraph/allegrograph/
[12] Erling O. Virtuoso, a hybrid RDBMS/Graph column store[J]. IEEE Data Eng. Bull., 2012, 35(1): 3-8.
[13] Marriott K, Stuckey P J. Programming with constraints: An introduction[M].Cambridge: MIT press, 1998: 4-9.
[14] Santos J, Muggleton S. When does it pay off to use sophisticated entailment engines in ILP?[M]. Inductive Logic Programming. Berlin: Springer Berlin Heidelberg, 2010: 214-221.
[15] Tamaki H, Sato T. OLD resolution with tabulation[C]//Proceedings of the 3rd International Conference on Logic Programming.Berlin: Springer Berlin Heidelberg, 1986: 84-98.
[16] Shi H, Maly K, Zeil S. Optimized backward chaining reasoning system for a semantic web[C]//Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics(WIMS14). ACM, 2014: 34.
[17] Shi H, Maly K, Zeil S. Query optimization in cooperation with an ontological reasoning service[C]//Proceedings of the fifth International Conferences on Advanced Service Computing.Valencia: SERVICE COMPUTATION, 2013: 26-32.
[18] Punnoose R, Crainiceanu A, Rapp D. Rya: a scalable RDF triple store for the clouds[C]//Proceedings of the 1st International Workshop on Cloud Intelligence. ACM, 2012: 4.
[19] Jacopo Urbani. Proof of correctness of QueryPIE closure algorithm[DB/OL]. http: //citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.419.3998
[20] Armbrust M, Xin R S, Lian C, et al. Spark SQL: Relational data processing in spark[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. ACM, 2015: 1383-1394.
[21] Guo Y, Pan Z, Heflin J. LUBM: A benchmark for OWL knowledge base systems[J]. Web Semantics: Science, Services and Agents on the World Wide Web, 2005, 3(2): 158-182.
[22] Auer S, Bizer C, Kobilarov G, et al. Dbpedia: A nucleus for a web of open data[M].Berlin: Springer Berlin Heidelberg, 2007.
[23] Urbani J, Kotoulas S, Oren E, et al. Scalable distributed reasoning using mapreduce[M].Berlin: Springer Berlin Heidelberg, 2009.
