基于神经网络的片段级中文命名实体识别
2018-05-04周俊生顾彦慧曲维光
王 蕾,谢 云,周俊生,顾彦慧,曲维光
(南京师范大学 计算机科学与技术学院,江苏 南京 210046)
0 引言
命名实体识别(NER)是指从文本中识别出人名、地名和机构名等专有名词,是自然语言处理的关键技术之一,也是信息抽取、问答系统、句法分析、机器翻译等应用的重要基础工作[1]。随着互联网的飞速发展和大数据时代的到来,文本数据规模越来越大,领域变得更多,本文内容也变得更复杂。探索更具实用性的新的有效识别方法,成为学术界和工业界关注的热点问题。
目前,解决命名实体识别问题的主流方法是基于统计学习模型的方法,包括基于最大熵(ME)模型、隐马尔可夫(HMM)模型、条件随机场(CRF)模型等命名实体识别方法[2-4]。传统方法通常依赖特征工程保证系统性能。然而,特征模板的制定需要人工设计和大量专家知识。特征设计需要实验进行反复修改、调整和选择,非常费时费力。传统方法中数据采用稀疏表示,容易导致参数爆炸等问题。在面对大规模多领域复杂的文本数据时,传统方法则暴露出更多不足。
对于中文命名实体识别任务,现有的方法通常将该任务看作一个字符序列标注问题,通过对字符分配标记完成命名实体识别[5-6]。由于中文句子中单词间没有分隔符号,相比于字符序列标注模型,直接对中文句子中的片段进行标记分配更为合理,可以避免字符序列标注方法中依赖局部标记区分实体边界的问题。Zhou等人[7]提出中文命名实体边界识别与实体类别识别集成的算法模型,引入片段特征解决中文命名实体识别问题。但该方法采用传统统计学习模型,仍然严重依赖具体任务的特征工程。
近几年,深度学习为解决自然语言处理问题提供了一种新的方法和途径,受到广泛关注。深度学习可以实现特征的自动学习,采用低维、稠密的实值向量表示数据,避免对人工和专家知识的严重依赖。基于深度学习的命名实体识别方法受到关注。现有研究工作中,Collobert和Weston构建SENNA系统为多项自然语言处理任务提供统一的神经网络底层结构,包括命名实体识别任务[8];Turian等人使用神经网络预先训练的词向量作为额外特征,与传统基于CRF的方法结合解决命名实体识别问题[9];Lample等人针对命名实体识别任务提出双向长短期记忆模型(Bi-LSTM)和CRF模型的组合结构[10];Ma等人将Bi-LSTM、卷积神经网络(CNN)与CRF模型结合构建了序列标记模型[9];Chiu和Nichols利用Bi-LSTM和CNN对输入信息进行处理,完成命名实体识别任务[11];Liu等人以片段信息表示作为输入,采用神经网络与半马尔可夫条件随机场(semi-CRF)模型结合完成英文命名实体识别任务[12]。目前,基于神经网络的中文命名实体识别研究较少,且主要采用字符序列标注模型[13],还没有基于神经网络的片段级中文命名实体识别研究工作。
因此,我们主要对基于神经网络的片段级中文命名实体识别方法进行探索研究,减弱对人工特征设计和专家知识的依赖,避免字符序列化标注模型的不足。在Liu等人的研究工作[12]基础上,我们结合中文语言特性和中文命名实体识别任务的特点,除片段内部字符和片段整体表示之外,引入离散特征与稠密向量表示结合的片段扩展特征表示,改进解码算法获取片段级上文信息,通过对片段整体分配标记完成中文命名实体识别任务。
1 基于神经网络的片段级中文命名实体识别
中文句子中词与词之间没有分隔符号,中文命名实体识别需要完成实体边界识别和实体分类任务。片段级的中文命名实体识别方法基于片段获取表示信息,对于输入的句子序列进行片段切分并对切分序列中的片段整体进行标记分配。相比于字符序列化标注方法,对片段整体进行标记分配更为合理,可以避免识别过程中依赖局部标记来区分实体边界的问题。
我们采用“PER”“LOC”和“ORG”分别表示人名、地名和组织机构名。以句子“中华人民共和国主席习近平在北京接受中央电视台采访。”为例作为输入序列,对片段分配标记后为“中华人民共和国/LOC 主席/O 习近平/PER 在/O 北京/LOC 接受/O 中央电视台/ORG 采访/O 。/O”。例子中,“中华人民共和国”“主席”“习近平”等看作是句子序列中的片段。在标记集合T={PER, LOC, ORG, O}中选取具体的标记分配给当前片段。
Semi-CRF模型是一种典型的对片段整体分配标记的方法[14],但基于semi-CRF的命名实体识别方法具有传统统计学习模型的不足。因此,选用基于神经网络和semi-CRF结合的片段神经网络结构实现特征的自动学习,可以避免繁琐的人工特征设计和对大量语言先验知识的依赖。
对于输入的句子序列x,有相应的切分片段序列s=(s1,s2,…,sp)。对于片段sj=
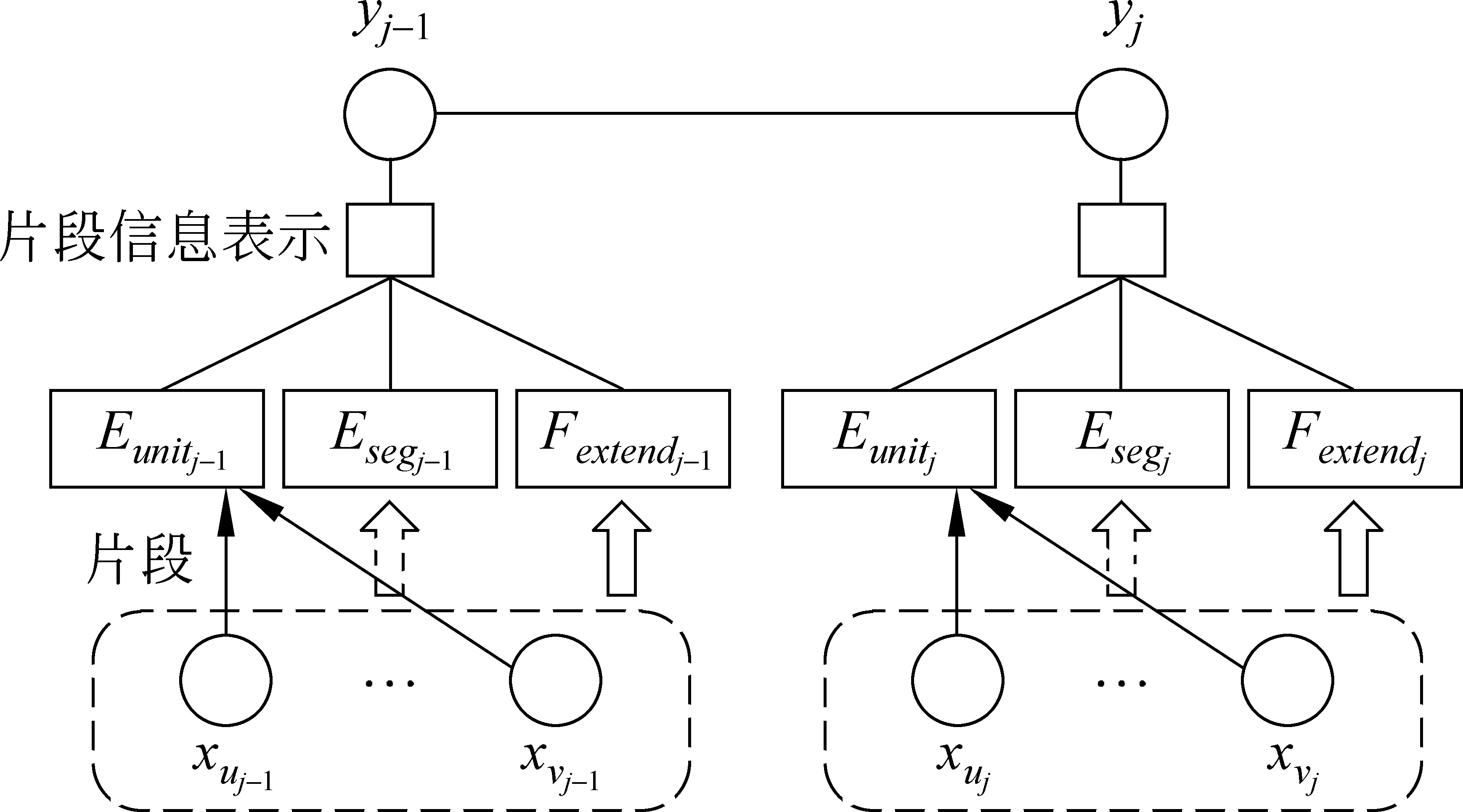
图1 片段级中文命名实体识别模型结构
具体的,我们研究两种神经网络模型结构: (1)Bi-LSTM和标准神经层构成的神经网络结构;(2)Bi-LSTM、双向循环神经网络(Bi-RNN)和标准神经层构成的组合神经网络结构。
1.1 基于Bi-LSTM的片段级中文命名实体识别
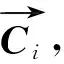
(1)
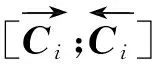
片段内字符单元的向量表示按序连接形成片段内部特征表示Eunitj,即对于片段sj,Eunitj具体表示如式(2)所示。
Eunitj=[Cuj;Cuj+1;…;Cvj]
(2)
其中,[;;…;]表示各个向量依次连接构成一个向量。
由于切分片段序列中的片段长度不统一,为了使输入下一层计算的向量长度固定,模型设置最大片段长度为L。设dC表示向量Ci的维数,若当前片段长度小于L则对Eunitj向量进行末尾填充至长度为D=L×dC维的向量。
片段sj的整体向量表示Esegj通过lookup操作从片段向量表中获得,如果片段向量表中不存在当前片段的向量,则选用特殊符号“UNKSEG”的向量表示,“UNKSEG”的初始向量取随机值。
片段相关的其他特征向量表示Fextendj主要包含片段长度信息和片段上文已完成切分的片段相关信息,当前处理片段的前文切分片段通过查询片段向量表获得,片段长度特征向量通过查询片段长度特征向量表获得。通过神经网络模型处理输出片段的最终表示Esj,如式(3)所示。
Esj=relu(WS[Eunitj;Esegj;Fextendj;Eyj]+bS)
(3)
式(3)中,[;;]表示其中各向量连接构成一个向量,WS是权值参数,bS是偏置项,Eyj是标记yj的向量表示。Esj是当前片段sj通过神经网络模型输出的特征表示,也是替代传统基于semi-CRF模型的方法中片段特征表示的向量。图2是神经网络模型获得片段表示的具体结构。
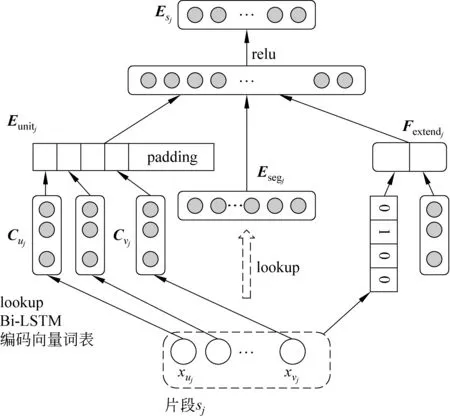
图2 基于Bi-LSTM的神经网络获取片段向量的结构图
模型训练采用极大似然估计,神经网络模型优化选用SGD算法,初始学习率设为η0,正则化方法采用dropout技术。预测过程中,处理当前切分片段时,通过神经网络模型获取片段信息的向量表示,结合semi-CRF模型进行解码。
1.2 基于组合神经网络的片段级中文命名实体识别
为了避免向量填充(padding),减少人工设置参数对系统的影响和限制,我们进一步研究采用Bi-LSTM模型与其他神经网络模型的组合模型结构获取片段信息。随着不同的神经网络模型的组合和模型结构的加深,模型对输入的信息表示可以获得更抽象的特征信息,模型的刻画能力更强。双向循环神经网络(Bi-RNN)是序列模型,能考虑上下文信息,因此我们选用Bi-LSTM、Bi-RNN和普通神经层的组合神经网络结构。
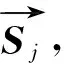

图3 组合神经网络获得Eunitj的模型结构图
对于当前片段sj,通过lookup操作从片段向量表中获得该片段整体向量表示Esegj,若当前片段在片段向量表中不存在,则选取特殊符号“UNKSEG”的向量表示,“UNKSEG”的初始值选取随机值。
片段相关的其他特征向量表示Fextendj主要是包含片段上文切分片段相关信息和片段本身长度信息的特征。处理当前片段时,对于前文切分产生的片段通过查询片段向量表获得前一个切分片段的向量表示,若片段向量表中不存在查询的片段,则选用特殊符号“UNKPSEG”的向量表示,“UNKPSEG”取随机值初始化。片段长度特征信息通过查询片段长度特征表获得,每个长度值对应唯一的长度表示向量,初始向量值为随机值。
基于当前片段获取的信息表示,通过神经网络模型输出片段的最终表示Esj,具体计算如式(3)所示。Esj是对于当前片段sj通过神经网络模型输出的片段信息表示向量。图4是获得片段向量表示的组合神经网络模型结构。

图4 获取片段表示向量的组合神经网络结构
模型训练采用似然估计,选用SGD优化算法,初始学习率设为η0,正则化方法采用dropout技术。预测时,与传统semi-CRF方法中的解码算法结合获得句子的切分片段序列和相应的片段标记序列。
1.3 片段特征表示
1.3.1 片段内部字符单元特征
中文字符是构成中文句子的最小单元,也是片段内部的基本组成单元。对于当前处理片段,针对片段内部组成单元即各字符信息提取的特征表示,本文称为片段内部单元特征,记为Eunit。
具体实现过程中,对于输入序列x,序列中的每个元素xi有相应的字符向量表示exi,字符xi通过Bi-LSTM编码计算后得到向量表示Ci。对于片段sj=
1.3.2 片段整体特征
为了从片段整体获取片段语义信息,我们采用低维、稠密的片段向量表示片段整体,称为片段整体特征,记为Eseg。
对于当前处理的片段sj=
1.3.3 片段相关扩展特征
中文命名实体的上下文信息具有相应的特点。如“老师”“书记”等词常出现于人名的上下文中,“奔赴”“境内”等词常出现在地名的上下文中。为了获取更丰富的片段信息,我们在当前片段信息基础上,引入上文片段信息。结合片段长度信息,将离散特征与稠密向量表示结合构成片段相关扩展特征,记为Fextend。
具体的,由于处理到当前片段时下文还未进行切分,所以我们关注当前处理片段的上文信息,选取当前处理片段的前一个切分片段。通过查询预先训练的片段向量表获取向量表示,若不存在当前片段,则采用特殊符号“UNKPSEG”的向量,该符号向量选取随机值初始化。关于片段长度特征则构建额外的特征向量表,不同长度对应唯一的离散特征向量。上文片段向量与长度特征向量连接构成Fextend。
1.4 解码算法
片段表示引入上文片段信息时,采用传统semi-CRF的解码算法无法满足获取前一个已切分片段的信息[13]。解码算法需要将原解码过程中的0阶动态规划算法修改为1阶动态规划算法[15],使得在子问题计算过程中,当前片段的前一个切分片段的信息可见。图5给出了算法的简要描述。

图5 片段级中文命名实体识别方法1阶动态规划解码算法
2 相关工作比较
近十几年来,对于中文命名实体识别研究主要基于传统统计学习模型,通常将任务看作一个字符序列标注问题。如廖先桃讨论了中文命名实体识别的几种方法[2],包括规则、HMM、ME和CRF。史海峰以CRF模型为基础实现在字一级对于命名实体的识别[5]。对于中文命名实体识别任务,对片段整体分配标记更为合理,可以避免字符序列化标注方法需要依赖局部标记区分实体边界的问题。Zhou等人提出中文命名实体边界识别与类别识别集成的算法模型[7],引入片段级特征,同时完成实体边界识别和类别识别两个子任务。但该方法仍然基于传统统计学习模型,依赖具体任务相关的特征工程。
为了避免具体任务的特征工程,Kong等人将神经网络与semi-CRF结合,提出一种片段级的循环神经网络(SRNN)模型,对于输入序列进行片段切分和片段标记分配[16]。Liu等人在Kong等人的研究基础上提出SCONCATE模型[12],采用片段级神经网络结构,通过获取片段内部字符特征表示和片段整体表示对片段分配标记,解决英文命名实体识别问题。
目前还没有基于神经网络的片段级中文命名实体识别研究。由于中文句子单词间没有明显分隔符号,相比于英文命名实体识别,中文命名实体更加复杂且缺少明显的词形变化等特征,任务更困难。只考虑字符或当前片段表示不能很好地解决中文命名实体识别问题。为了更有效地获取片段信息,我们引入离散特征与稠密向量表示结合的片段扩展特征表示,改进解码算法获取片段级上文信息,通过对片段整体分配标记完成中文命名实体识别任务。
3 实验
3.1 数据
实验数据使用MSRA语料,基于神经网络的片段级中文命名实体识别模型利用MSRA训练集进行训练,在MSRA测试集上完成测试。针对语料在实验中的实际应用,首先对训练集进行相应的语料预处理工作。将训练集中的句子转化为“训练集句子-片段标记序列”作为模型输入的训练数据集。模型的测试集是MSRA测试集,是不包含任何切分信息和标记信息的中文句子。
关于模型初始输入的字符向量和片段向量,我们采用Word2Vec工具对无标注语料进行预训练[17]。初始输入向量预训练的语料集额外引入新华社2000~2004年和《人民日报》2000年语料。向量预训练语料规模主要分为两种: (1)MSRA训练集;(2)MSRA训练集、新华社和《人民日报》共六年语料数据集合。以上两种预训练语料记为pre1和pre2。
3.2 参数设置
实验包含多个超参数,关于神经网络模型的超参数设置具体数值如表1所示。

表1 用于实验的神经网络模型超参数设置
表1中,第1组超参数是基于Bi-LSTM的片段级中文命名实体识别模型实验的参数。第2组是在基于组合神经网络的片段级中文命名实体识别模型中所需的参数,第1组和第2组共同组成基于组合神经网络的片段级中文命名实体识别模型的参数。第3组是神经网络模型初始输入包含片段扩展特征时,实验中所需的超参数。
3.3 基于神经网络的片段级中文命名实体识别方法有效性验证
为了验证基于神经网络片段级中文命名实体识别方法的有效性,我们基于神经网络的字符级中文命名实体识别方法实现了一个基线(Baseline)系统。Baseline采用基于Bi-LSTM模型的字符序列标注模型结构,对于输入的句子序列,采用“BIEOS”标注体系通过对每个字符分配标记完成中文命名实体识别。我们利用MSRA训练集进行模型训练,在MSRA测试集上进行测试。对比实验结果如表2所示。实验初始输入的向量预训练语料采用pre1。从片段内部单元和片段整体两方面表示片段,基于Bi-LSTM的神经网络片段级模型记为Bi-LSTMpre,基于组合神经网络的片段级模型记为Combpre。为了获取更丰富的片段信息提升系统性能,另一组实验选用大规模的预训练语料pre2,同时从片段内部字符、片段整体以及片段扩展特征三个方面获取片段信息,模型记为Bi-LSTMpre2+ext和Combpre2+ext,实验结果如表3所示。
实验结果显示,与Baseline系统方法相比,基于神经网络的片段级中文命名实体识别方法识别效果显著提升。采用大规模预训练语料,字符向量、片段向量表示包含更丰富的语义信息[18],可以更有效地获取片段信息提升系统性能。我们提出的两种基于不同神经网络的片段级方法获得相当的系统性能。

表2 与Baseline实验结果对比

表3 采用大规模预训练语料的实验结果
3.4 不同片段级中文命名实体识别方法实验比较
为了验证本文基于神经网络的片段级中文命名实体方法的有效性,我们选择与Zhou等人工作的实验结果进行对比。该方法集成命名实体边界识别和分类任务,针对片段级中文命名实体识别进行研究,相比于传统字符序列标注模型,在MSRA上获得较好的性能[7]。该方法基于传统统计学习模型,需要依赖人工特征设计和专家知识。
表4是在MSRA测试集上的测评结果对比,基于Bi-LSTM的片段级中文命名实体识别系统和基于组合神经网络的片段级中文命名实体识别系统分别记为Our1和Our2。实验结果显示,与Zhou等人基于传统统计学习方法的片段级中文命名实体识别方法[7]相比,本文提出的基于神经网络的片段级中文命名实体识别方法中基于Bi-LSTM的片段级中文命名实体识别方法获得较好的系统性能,基于组合神经网络的片段级中文命名实体识别方法获得与之相当的实验结果。我们的系统在人名和地名的识别结果上分别提升了0.9%、0.95%。
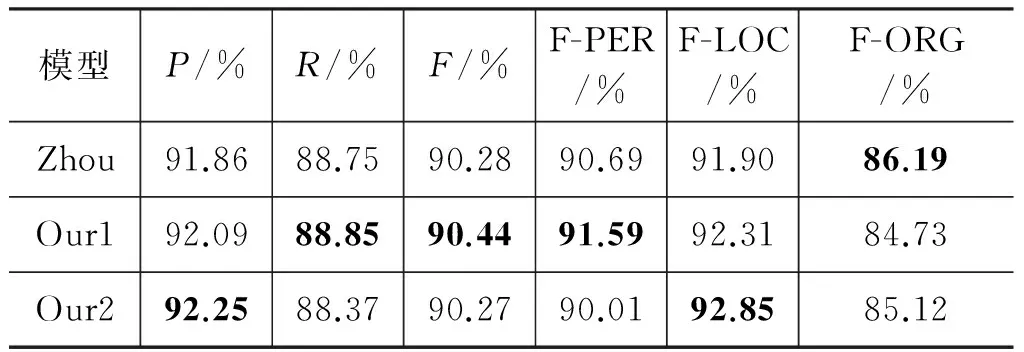
表4 不同方法的实验结果对比
4 结束语
中文命名实体识别是中文自然语言处理领域中的重要基础任务之一。本文针对传统统计学习方法和字符序列化标注模型的不足,主要研究基于神经网络的片段级中文命名实体识别方法,采用两种神经网络模型结构与半马尔可夫条件随机场模型结合,通过对片段整体分配标记完成中文命名实体识别。据我们所知,这是首次针对基于神经网络的片段级中文命名实体识别进行研究。实验结果显示,该算法的识别效果明显优于Baseline,并且获得与当前其他最优的中文命名实体识别系统相当的识别性能。
在下一步的研究工作中,我们将继续研究获取表示片段信息的方法,使得输入的片段信息表示可以更加完整有效,提升系统性能;另外,我们将探索不同的神经网络模型或不同神经网络模型的组合模型调整现有的模型结构,设计更适用于中文命名实体识别任务的模型结构,从而获得更好的识别性能。
[1] 宗成庆. 统计自然语言处理[M].北京: 清华大学出版社, 2008: 150-178.
[2] 廖先桃. 中文命名实体识别方法研究[D],哈尔滨: 哈尔滨工业大学硕士学位论文, 2006.
[3] McCallum A, Li W.Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons[C]//Proceedings of HLT-NAACL, 2003: 188-191.
[4] 俞鸿魁, 张华平, 刘群, 等. 基于层叠隐马尔可夫模型的中文命名实体识别[J]. 通信学报, 2006, 27(2): 87-94.
[5] 史海峰, 姚建民. 基于CRF的中文命名实体识别研究[D]. 苏州: 苏州大学硕士学位论文, 2010.
[6] 王志强.基于条件随机域的中文命名实体识别研究[D].南京: 南京理工大学硕士学位论文,2006.
[7] Zhou J, Qu W, Zhang F. Chinese named entity recognition via joint identification and categorization[J]. Chinese Journal of Electronics, 2013: 225-230.
[8] Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research, 2011(12): 2493-2537.
[9] Turian J, Ratinov L, Bengio Y. Word representations: A simple and general method for semi-supervised learning[C]//Proceedings of ACL, 2010: 384-394.
[10] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[C]//Proceedings of NAACL-HLT, 2016: 260-270.
[11] Ma X, Hovy E. End-to-end sequence labeling via bi-directional LSTM-CNNs-CRF[C]//Proceedings of ACL, 2016: 1064-1074.
[12] Liu Y,Che W, Guo J, et al. Exploring segment representations for neural segmentation models[C]//Proceedings of IJCAI, 2016: 2880-2886.
[13] 王国昱. 基于深度学习的中文命名实体识别研究[D].北京: 北京工业大学硕士学位论文, 2015.
[14] Sarawagi S, Cohen W W. Semi-Markov conditional random fields for information extraction[C]//Proceedings of NIPS, 2004(17): 1185-1192.
[15] Zhang Y, Clark S. Syntactic processing using the generalized perceptron and beam search[J]. Computational Linguistics, 2011, 37(1): 105-151.
[16] Kong L, Dyer C, Noah A. Segmental recurrent neural networks[C]//Proceedings of ICLR, 2016.
[17] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[C]//Proceedings of Workshop at ICLR, 2013.
[18] Lai S, Liu K, He S, et al. How to generate a good word embedding[J]. IEEE Intelligent Systems, 2016, 31(6): 5-14.
