基于MapReduce的智能电网云计算并行优化研究∗
2018-04-26李晓光许广虎谢海疆
孙 帆 李晓光 张 勇 许广虎 谢海疆
(1.国网新疆电力公司电力科学研究院设备状态评价中心 乌鲁木齐 830011)(2.北京恒泰实达科技股份有限公司南京研发中心 北京 100094)
1 引言
云存储的高效存储是智能电网中多属性数据处理的重要内容[1]。智能电网中多属性数据复杂多变,且数据随时间处于动态变化中,数值差异很大[2]。基于传统的云存储技术已经无法满足日益增长的海量电网数据的客观现实需求,并行优化的数据处理模型逐渐成为未来数据挖掘存储的发展方向[3]。现有的数据并行优化模式主要分为三种:多核并行[4]、异步并行[5]和划分并行[6]。其中,常见的多核并行模式以终端硬件角度为立足点,仅通过增加处理器个数提升数据运行效率;异步并行主要针对异构数据类型采用分布式计算方式提高计算速度;而划分并行则以数据属性特征为出发点,依据数据类型通过定义划分准则分步进行数据的运算存储。针对智能电网中同一问题的不同属性数据类型,采用划分并行的优化处理方式不仅可以减少硬件成本的花费,同时又能减少云存储的时间开销。
本研究将在挑战-响应框架的基础上对智能电网云计算存储进行改进,首先采用数据的分片结构来减少数据标识的数量,同时进行分块处理计算得到哈希值和数据块标识。其次构建五个算法完成挑战数据块的完整性。最后设计相应的Map和Re⁃duce函数实现数据标识产生算法的并行化,通过计算哈希值和标识作为输出结果存储于HBase云端数据库。
2 智能电网云计算
现如今,一个云存储的数据完整性验证方案是建立在挑战-响应的方法来证明的数据占有模型方法[7],普遍的远程云存储的数据完整性验证方案的模型图就是采用该方案,如图1所示。
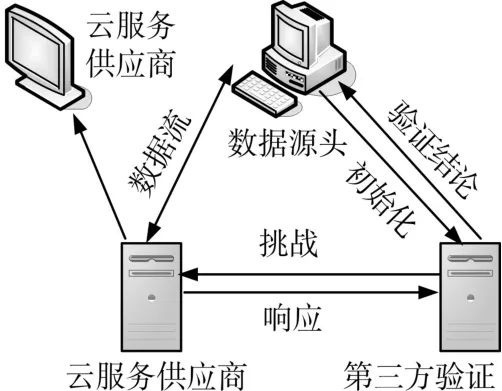
图1 远程云存储数据完整性验证方案的模型架构图
基于挑战—响应的方案中共包括三大实体:
1)DO(Data Ower,数据源头),在云存储中拥有大量的数据;
2)CSP(Cloud Service Provider,云服务供应商),对于云存储服务的用户,存储自身的数据,可以提供访问用户的数据限制;
3)VS(Third-party Auditor,第三方验证者),受DO委托有权并有能力对远程云存储中的数据进行完整性验证。
验证流程为假设VS是可靠的和独立的,它能够进行随机抽样的数据完整性验证被DO授权,并把结果反馈给DO[8]。
根据图1所提出的模型,数据完整性验证的大概流程为:
Step1:DO提出将数据存于云存储,随机生成公钥和私钥对数据的识别进行计算。
Step2:CSP承担DO要存储的数据及数据标识,用数据块的形式将数据存储。
Step3:VS存储接受的数据,DO把数据基本信息及产生的公钥发送给VS。
Step4:根据数据的基本信息VS周期性地向CSP发起验证并挑战。
Step5:CSP把挑战的证据以响应的形式回馈给VS。
Step6:DO接受VS验证数据的完整性发送出的结果。
通过对上述方案的分析,在智能电网环境下的应用会有几个方面限制的特例:
1)DO要存储的数据云服务供应商前进行数据标识计算,当数据量过大,DO会超负荷承担计算和存储的工作量,此时计算数据标识的任务应该被转移。
2)VS的安装和部署的环境不明确,缺乏安全性和可信性的有效保障。此外,上述方案对VS的需求大,VS的计算和存储工作量也会随着数据量的增长而凸显变化。
3)上述的方案未利用云计算的优势来提高验证的效率,只是针对云存储中的数据进行完整性验证。然而智能电网利用云计算进行有效的数据处理和存储是发展的趋势,所以验证方案的效率不能判断是否能在智能电网环境下应用的关键要素。
3 MapReduce算法并行
3.1 数据划分
本文采用数据的分片结构来减少数据标识的数量,如图2所示为数据分片结构详解图。首先,将文件M拆分为n个大小相同的数据块{m1,m2,…,mn}再将每一个数据块拆分为s个数据片 {mi,1,mi,2,…,mi,s} 。 通 过 安 全 参 数 a={a1,a2,…,as}产生数据分片安全参数 u={u1,u2,…,us},对于每一个数据块mi计算得到哈希值hashi,并产生数据块标识tagi,最后产生文件M的哈希值集合和数据标识集合H。

图2 数据分片结构图
3.2 算法设计
提出的数据完整性验证方案由以下五个算法构成。在进行本方案的算法设计前,首先定义算法中用到的符号。算法的符号定义如表1所示。
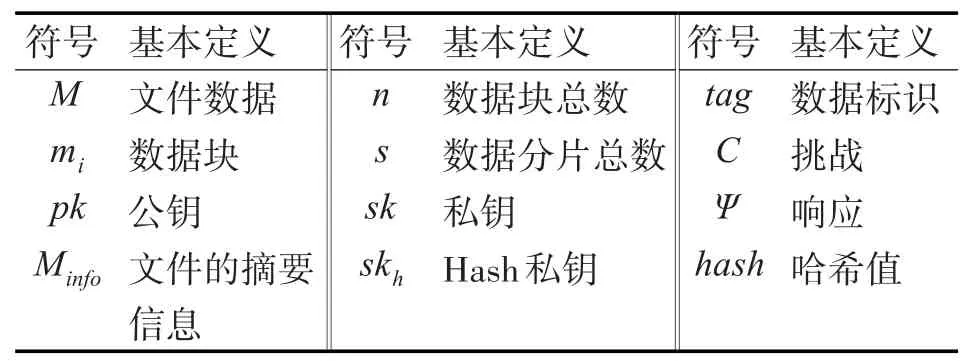
表1 算法符号
先采用数据分片结构将文件M拆分为n个数据块,每一个数据块被分为s个数据片。G1、G2和Gr分别为阶数为 p的乘法循环群,g1、g2分别是G1和G2的生成元,双线性映射为e:G1×G2→Gr。函数 h:{0,1}→G1为哈希值防止碰撞[9]。它将文件摘要信息Minf(由数据的某些属性构成)映射为G1中一点,利用上述的设计方案可以构建五个算法的具体设计:
算法一:KeyGen(1k)→(pk,sk,skh):输入 k(参数),随机选择sk,skh∈Zp作为标识私钥和哈希私钥[10],通过计算 pk=∈G2作为标识私钥;
算法二:TagGen(M,sk,skh)→Ω :选择 s个随机值 aj∈Zp,a={a1,a2,…,an},计算 uj=∈G1,得到u={uj}j∈[1,s],利用 skh得到数据块摘要信息的哈希值[11]:

其中Wi=Fname-i,代表云存储系统中标记不同文件的文件名,得到 H={hashi}i∈[1,n]。最后计算数据标识[12]:
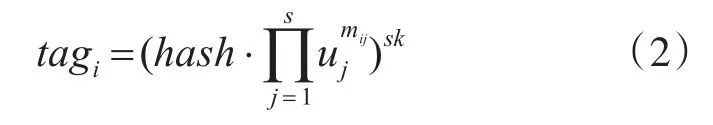
根据上式得到数据标识集 Φ ={tagi}i∈[1,n]。将P=(H,Φ,{ }miji∈[1,n],j∈[1,s],sk,skh,u)存储在 CSP 端,将 Minf={Fname,n,pk,g2}发送给 VS存储,输出Ω =(Minfo,P)。
算法三:Challenge(Minfo)→C:验证挑战阶段,VS根据文件摘要Minfo随机选取挑战集Q,随机产生Q个安全参数xi∈,将挑战集 C=({i,xi}i∈Q)发给CSP。
算法四:Proof(M,C,Φ,H)→Ψ :CSP接收到VS发来的挑战c后,随机选择安全参数r∈和s个 λj∈,根据C计算标识证据TT,并利用随机安全参数来保护数据片的线性组合,得到MMj,通过计算数据和挑战数据块分别得到证据PP和哈希值证据HH,并得到随机安全参数确认证据UU[13]:
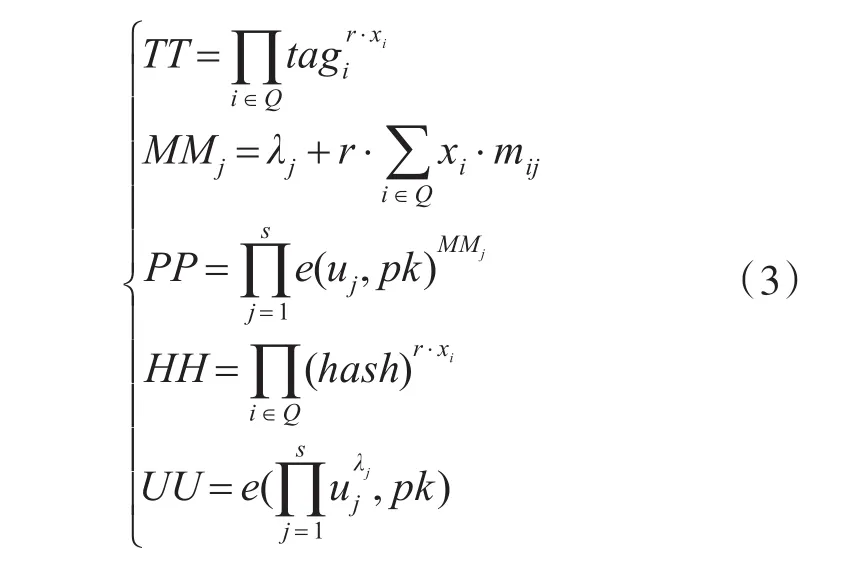
最后将验证证据Ψ=(TT,PP,HH,UU)作为应答发送给VS。
算法五:Verify(Ψ,pk)→0/1:VS 接收到应答Ψ,并通过基于双线性配对的等式来验证被挑战数据块的完整性[14],若配对成功输出为1,否则输出为0:

3.3 并行优化
在分析了智能电网环境下的数据特点及存储要求,云服务器CSP端接收了已有方案的数据标识的计算任务,解决标识产生阶段过重的计算开销的漏洞是利用已经拥有的方案云计算的优势[15],巧妙地避免了数据标识产生完整性验证算法的瓶颈扩大了其效率。
通过设计相应的Map和Reduce函数实现了数据标识产生算法的并行化,首先在数据标识阶段就应用了MapReduce的编程框架,在taggen阶段也采用了MapReduce分布式计算数据标识,下面列出了具体算法的步骤:
第一步:分块文件数据M ,将分块后的数据块存放在分布式文件系统HDFS中,把每一数据块作为Map函数的输入。
第二步:Map函数中将数据块进行分片,输出数据片并存于HBase数据库中[16]。
第三步:Map函数的输出作为Reduce函数的输入,在 Reduce函数中通过式(1)和式(2)分别计算哈希值hash和标识tag,作为输出结果存储于HBase数据库中。
4 实验模拟
4.1 实验准备
为了体现该算法验证的计算效率,实现数据完整性测试使用了Java语言编程,并调用JPBC库实现双线性配对操作,使用SHA-1算法作为哈希函数映射出的哈希值,根据来自Oracle数据库的实验数据所需要的电功率数据到HDFS,实现智能电网数据集成到处理数据完整性验证所需的步骤。然后数据生成算法计算一起存储在HBase的数据库的数据标识,数据和识别信息的识别。
使用双线性配对过程中,选用的椭圆曲线是域大小为159bits的MNT曲线,安全参数长度:|p|=160bits,其嵌入度为6。所选用的椭圆曲线安全参数|p|=160bits被实验中数据分片的大小控制,为20字节。因此数据分片的大小是确定的,分片数s与分片大小相乘得出数据分块大小,数据总大小除以数据分块大小即为数据分块数n,试验过程将选取大小从1M到64M的数据进行对比。
4.2 存储测试
现进行数据标识产生时的TagGen阶段的计算开销测试。主要测试数据从被提取后开始计算标识到存于HBase后的时间效率。规定所有大小的数据的分片数相同,都为400,即数据块大小为20B*400=8KB。相同分块大小下的单机情况和并行化情况的数据标识产生时间的对比实验结果如图3所示。
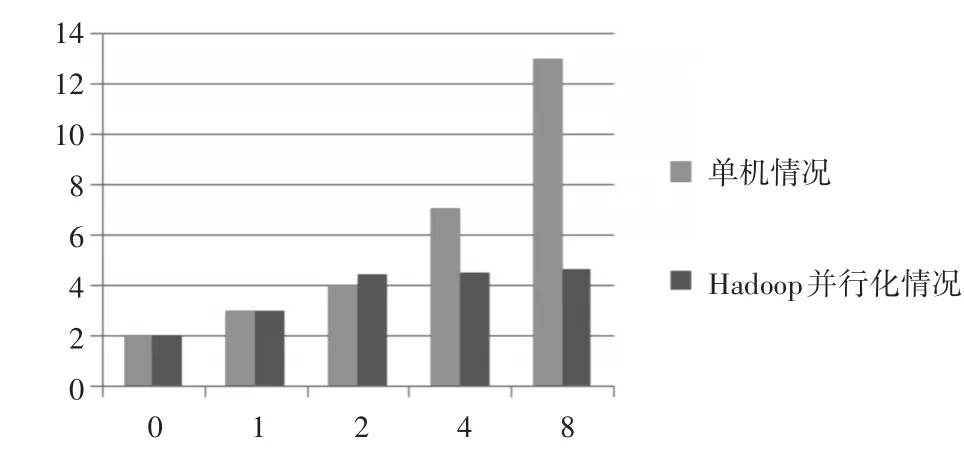
图3 固定分块带下标识产生时间对比图
由图3可看出,当数据分块大小一定时,在单机情况下TagGen阶段的计算开销随着数据大小的增大而有相同倍数的增大。而在Hadoop并行化情况下,TagGen阶段的计算开销随着数据大小的增大却增长缓慢,当数据大小达到64M时,计算开销依然很小。
通过分析,不仅在TagGen计算阶段开销时受数据分块数大小的影响,还受到数据分片数s大小的影响,所以实验选取2M的文件进行不同分片数的划分,来验证TagGen阶段的计算开销与s和n大小的关系,结果如图4所示。
由图4所示,对于大小一定的数据,分片数大小的选取不仅影响了数据分块数,也限制标识产生的时间。为了提高数据标识产生阶段的计算效率,对大小不同的数据进行不同数目的数据分类是有必要的,Hadoop并行化的结果如图5所示。
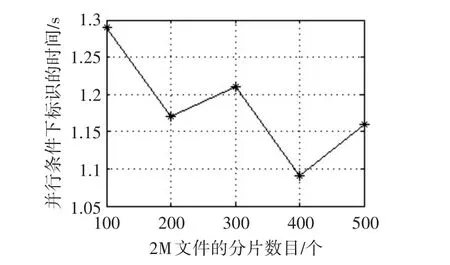
图4 固定数据大小,不同分块大小情况下标识产生时间对比图
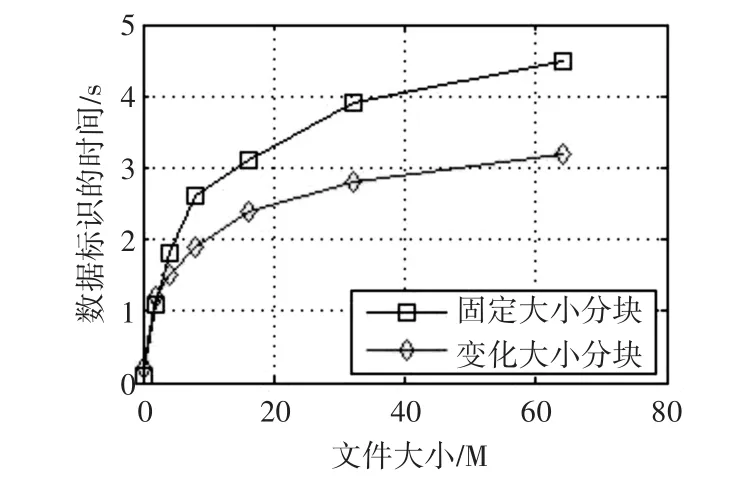
图5 固定分块大小和变化分块大小情况下标识产生时间对比
由图5可见,不同数据大小进行固定大小分块和变化大小分块情况下标识产生时间对比,可见选取合适的s值使标识产生的效率也得到了提高。
4.3 完整性测试
进行数据完整性验证过程的挑战-响应和验证等阶段的计算时间测试。数据的分块、分片情况是由标识产生阶段时决定的,所以在进行数据完整性验证时也按照分块情况进行挑战-响应。KeyGen阶段所用时间是固定的,约为18.86ms左右,因为VS端发起的挑战是根据一定的抽查比例进行的,试验中选取抽查比例为40%的情况为例进行实验,数据完整性验证过程中各阶段所用时间结果如表2所示。

表2 各阶段数据完整性的时间开销测试
由表2可见,挑战阶段的计算开销随着挑战数据块的增多而相应的增大,但是整体增长幅度很小;响应阶段的计算开销是由n和s之和决定的,随着数据大小的变化也是采用不同的数据分片数,所以此阶段的计算开销也成小幅度的增长;Verify阶段的计算开销是固定的,验证方验证时间,约为62.14ms左右,计算开销非常小。
5 结语
本研究以挑战-响应框架为基础开发了一套智能电网条件下的云计算存储并行优化模型,采用数据分片和数据分块的方式对海量电网数据进行划分,减少了数据标识的数量并计算得到哈希值和数据块标识。通过分别构建KeyGen、TagGen、Chal⁃lenge、Proof和Verify五个算法完成挑战数据块的完整性,设计相应的Map和Reduce函数实现数据标识产生算法的并行化,通过计算哈希值和标识作为输出结果存储于HBase云端数据库。实现了划分式的数据优化并行云存储处理,并且通过实验分析结果说明了挑战阶段的计算开销随着挑战数据块的增多而相应的增大,但是整体增长幅度很小;响应阶段的计算开销是由数据块数和数据片数之和决定的。因此,本研究提出的针对智能电网数据云存储的并行优化方式具有参考性意义。
[1]张少敏,李晓强,王保义.基于Hadoop的智能电网数据安全存储设计[J].电力系统保护与控制,2013(14):136-140.ZHANG Shaomin,LI Xiaoqiang,WANG Baoyi.Design of Secure Data Storage for Smart Grid Based on Hadoop[J].Power System Protection and Control,2013(14):136-140.
[2]曹军威,万宇鑫,涂国煜.智能电网信息系统体系结构研究[J].计算机学报,2013,36(22):45-45.CAO Junwei,WAN Yuxin,TU Guoyu.Research on Intelli⁃gent Power Grid Information System Architecture[J].Jour⁃nal of Computer Science,2013,36(22):45-45.
[3]剧树春,李刚.数据挖掘方法在智能电网中的应用[J].电子世界,2013(20):52-52.JU Shuchun,LI Gang.Application of Data Mining Method in Smart Grid[J].Electronic world,2013(20):52-52.
[4]袁琪,杨康,周建江.大点数FFT算法C6678多核DSP的并行实现[J].电子测量技术,2015,38(2):74-80.YUAN Qi,YANG Kang.Parallel big point FFT algorithm C6678 multicore DSP implementation[J].Electronic mea⁃surement technology.2015,38(2):74-80.
[5]杨海涛,张传斌,阮镇江.大规模云同步归集数据系统的异步并行优化[J].计算机工程与应用,2016(10):12-17.YANG Haibo,ZHANG Chuanbing,RUAN Zhenjiang.Asynchronous Parallel Optimization of Large Scale Cloud Synchronization Data System[J].Computer Engineering and Applications.2016(10):12-17.
[6]顾乃杰,赵增,吕亚飞.基于多GPU的深度神经网络训练算法[J].小型微型计算机系统,2015,36(5):1042-1046.GU Naijie,ZHAO Zeng,LV Yafei.Depth Neural Network Training Algorithm Based on Multi-GPU[J].Small micro⁃computer system,2015,36(5):1042-1046.
[7]谭霜,贾焰,韩伟红.云存储中的数据完整性证明研究及进展[J].计算机学报,2015,38(1):164-177.TAN Shuang,JIA Yan,HAN Weihong.Research and De⁃velopment of Data Integrity in Cloud Storage[J].Journal of Computer Science,2015,38(1):164-177.
[8]李琳,钱进,张永新.软件即服务模式下租户多副本数据存储完整性问题研究[J].南京大学学报(自然科学版),2016,52(2):324-334.LI Lin,QIAN Jin,ZHANG Yongxin.Research on Multicopy Data Storage Integrity of Tenants in Software-based Service Mode[J].Journal of Nanjing University(Natural Science Edition),2016,52(2):324-334.
[9]池子文,张丰,杜震洪.云环境下基于预分片的遥感数据并行重采样方法[J].上海交通大学学报,2014,48(11):1627-1632.CHI Ziwen,ZHANG Feng,DU Zhenhong.Parallel Resa⁃mpling of Remote Sensing Data Based on Pre-slicing in Cloud Environment[J].Journal of Shanghai Jiaotong Uni⁃versity,2014,48(11):1627-1632.
[10]袁勇,王飞跃.区块链技术发展现状与展望[J].自动化学报,2016,42(4):481-494.YUAN Yong,WANG Feiyue.Development Status and Prospect of Block Chain Technology[J].Journal of Auto⁃mation,2016,42(4):481-494.
[11]王丽娜,邓入弋,任正伟.基于网络编码的远程数据验证方法[J].华中科技大学学报(自然科学版),2014(11):17-22.WANG Lina,DENG Ruge,REN Zhengwei.Remote Data Verification Method Based on Network Coding[J].Jour⁃nal of Huazhong University of Science and Technology(Natural Science Edition),2014(11):17-22.
[12]陈晓,张龙军,王谦.集群重复数据删除策略的研究[J].电子制作,2016(4):40-41.CHEN Xiao,ZHANG Longjun,WANG Qian.Research on Cluster Deduplication Strategy[J].Electronic produc⁃tion,2016(4):40-41.
[13]李经纬,贾春福,刘哲理.可搜索加密技术研究综述[J].软件学报,2015,26(1):109-128.LI Jingwei,JIA Chunfu,LIU Zheli.A Review of Search⁃able Encryption Technology[J].Journal of Software,2015,26(1):109-128.
[14]周海,吴丽珍,刘鹏辉.一种基于双线性配对的移动通信认证组密钥协商方案[J].计算机应用与软件.2012,29(4):151-155.ZHOU Hai,WU Lizhen,LIU Penghui.A Key Agreement for Mobile Communication Authentication Group Based on Bilinear Pairing[J].Computer Applications and Soft⁃ware,2012,29(4):151-155.
[15]张浩,赵磊,冯博.CACDP:适用于云存储动态策略的密文访问控制方法[J].计算机研究与发展,2014,51(7):1424-1435.ZHANG Hao,ZHAO Lei,FENG Bo.CACDP:Crypto⁃graphic access control method for cloud storage dynamic policies[J].Computer Research and Development,2014,51(7):1424-1435.
[16]周相兵,马洪江,苗放.云计算环境下的一种基于Hbase的ORM设计实现[J].西南师范大学学报(自然科学版),2013,38(8):130-135.ZHOU Xiangbing,MA Hongjiang,MIAO Fang.Design and Implementation of ORM Based on Hbase in Cloud Computing Environment[J].Journal of Southwest China Normal University(Natural Science Edition),2013,38(8):130-135.
