一种改进的HDFS副本放置策略
2018-04-25陈伟
陈 伟
(宿州职业技术学院计算机系,安徽宿州 234101)
随着大数据时代的到来,信息数据呈指数极增长,传统的文件存储方式已无法满足海量数据的存储需求,分布式文件系统的应用越来越广泛。HDFS(Hadoop Distribute File System)作为分布式文件系统的典型代表,以其低成本、高可靠性、大数据处理等优势,成为海量数据存储的理想方案。HDFS采用副本技术把数据副本存放在集群中多个不同节点上,当某个节点发生故障时,可通过副本进行恢复,不会影响数据的读取,保证了数据的可靠性。
在HDFS默认副本放置策略中,部分副本存放节点是随机选择的,对节点的实时负载和节点间网络距离没有充分考虑,容易导致集群系统负载不均衡,节点距离较远时会降低数据传输效率,影响MapReduce的运算性能,集群系统整体性能下降。刘艳[1]通过节点负载与计算性能相匹配原则副本节点的选择,实现副本放置。邵秀丽[2]选择集群中存储使用率较低的节点作为数据副本存放节点。刘党朋[3]在数据副本存放时综合考虑磁盘使用情况、节点性能、文件重要性等因素,优先选择负载较小的数据节点进行存放。林伟伟[4]结合节点负载和网络距离计算评价值,基于评价值选择副本放置节点,但是文中节点负载仅表示节点当前存放的数据块数量,没有考虑其他各项指标。
本文在已有研究基础上,综合考虑磁盘使用率、CPU使用率、内存使用率、网络距离等各项因素,对HDFS副本放置策略进行改进,以提高集群系统的存储性能和负载均衡效果。
1 HDFS概述
HDFS是开源云计算平台Hadoop的核心组件,为海量数据提供存储。HDFS对硬件的要求较低,可以部署在廉价设备上,采用流式数据访问,能够满足海量数据的处理需求[5]。

图1 HDFS体系结构
1.1 HDFS架构
HDFS采用主/从(Mater/Slave)体系结构[6],类似传统文件系统,可以通过目录路径执行文件的创建、读取、删除等操作。在HDFS集群中有1个主节点(NameNode)和多个从节点(DataNode),NameNode是集群管理者,负责管理元数据等,真正实现数据存储的是DataNode。客户端访问文件先要与NameNode交互获取文件元数据,然后直接与DataNode建立通讯进行文件操作。HDFS体系结构如图1所示。
1.2 文件写入过程
客户端把要写入的文件进行分块(默认大小64M),向NameNode发起文件写入请求,并把数据块信息写入NameNode,NameNode根据集群中节点状态选择可用的DataNode,并返回DataNode列表给客户端用来存放数据块副本。客户端得到节点信息后,开始以数据块形式向第一个DataNode写入数据,然后以流水线方式依次向其他节点复制数据,最后把各个存放副本的DataNode的最新信息反馈给NameNode。HDFS文件写入过程如图2所示。

图2 HDFS文件写入过程
2 HDFS副本放置策略
2.1 默认副本放置策略
HDFS分布式文件系统中把文件分为多个数据块,每个数据块存在多个副本进行冗余存储,采用机架感知[7]的副本放置策略,使同一数据块的多个副本存储在多个不同的机架上。HDFS中数据块默认的副本数为3,通常尽可能把2个副本放置在相同机架数据节点上,1个副本在不同机架上,相同机架可获得较好的网络传输性能,而放置在不同机架可以保证数据的安全性。默认的副本放置策略如图3所示。
如果客户端为集群中节点,则把副本1放置在客户端所在数据节点,副本2放置在和副本1相同机架不同节点,副本3则随机选择不同机架中节点进行存放;如果客户端不在集群中,则在集群中随机选择一个节点进行副本1放置。把副本1和副本2放置在同一机架,减少了机架间数据传输,提高了文件的读写速度,保证了读写数据的带宽;副本3随机放置在不同远端机架上,当本地节点失效时,系统会自动从远端机架副本进行恢复,提高了数据的可靠性和安全性。
2.2 默认副本放置策略缺陷
HDFS默认副本放置策略中,权衡了数据传输的带宽和数据的可靠性,但是由于副本节点的随机选择,使得集群系统在负载均衡和传输性能等方面仍然存在一些问题,有待进一步改进。(1)由于HDFS大都部署在廉价机器上,各个节点的硬件性能存在差异,而默认策略中认为集群中节点同构,会导致性能高的节点利用率低,性能低的节点负载较高,使得集群系统性能下降。(2)随机选择节点进行副本存放,未考虑节点负载情况,会导致副本放置在高负载的节点,而低负载节点可能会闲置,导致集群负载不均衡,影响整体性能。(3)由于存放节点的随机选择,未考虑节点间的网络距离,当本地节点出现故障需要从远程节点进行恢复时,如果远程节点网络距离过远,则会消耗过多时间进行数据传输。
3 改进的HDFS副本放置策略
3.1 基本思想
在进行副本放置时要尽可能保证集群系统负载均衡和数据传输性能,因此在改进默认副本放置策略时要注意以下几个方面:(1)数据可靠性。与默认策略相同,要把副本放置在不同机架,确保节点故障时仍可自动恢复。(2)网络距离。HDFS中节点失效时常发生,副本恢复是系统运行时常态,为了提高数据传输性能,减小数据传输的时间消耗,应尽可能地确保副本存放节点距离较近。(3)负载均衡。建立节点负载模型,副本放置时考虑节点负载,尽可能使集群负载均衡。
可见,副本放置时要综合考虑节点实时负载和节点网路距离。结合节点负载和网络距离,建立节点综合评价值,并对评价值进行排序,选择评价值较高的节点进行副本放置,兼顾系统负载均衡和数据传输,尽可能提高集群系统性能。
3.2 节点综合评价
3.2.1 节点负载
通常情况下,衡量节点负载的指标主要包括CPU使用率、内存使用率、网络带宽使用率等。在HDFS集群中,客户端对节点进行文件的读取和写入会给节点造成一定的负载压力,因此,考虑把磁盘的I/O访问率作为节点负载指标。另外,磁盘剩余空间较大的节点需存储较多的数据文件,磁盘剩余空间较小的节点存储较少的数据,副本随机放置时如磁盘空间不足则需重新选择节点进行存放,会造成不必要的开销,所以,需要把磁盘使用率作为衡量节点负载的首要考虑因素。
综合考虑,本文使用CPU使用率、内存使用率、网络带宽使用率、磁盘空间使用率、磁盘I/O访问率五项指标来衡量节点的负载情况[8]。第i个节点的负载L(i)可表示为:
(1)
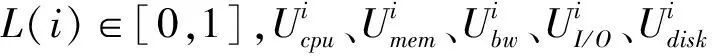
(2)
3.2.2 网络距离
存放数据的节点与副本节点间网络距离的大小直接影响了数据传输的带宽,网络距离越小则带宽越大,数据传输效率越高,数据读写时间越短。在Hadoop中,将网络描述成树形拓扑结构,叶节点为Data Node,内部节点为路由器、交换机等网络设备,在网络拓扑中,子节点与父节点的距离为1,任意两个Data Node的距离是它们到最近共同祖先的距离总和[10]。
假设节点i与存放数据节点网络距离为d(i),最大距离为dmax,则可使用式(3)描述网络距离。
(3)
D(i)表示节点i的网络距离系数,与实际网络距离成正比,且D(i)∈[0,1]。
3.2.3 综合评价值
通过节点的实时负载和网络距离对节点进行综合评价,衡量节点是否适合作为存放节点进行副本放置。节点i综合评价值Eval(i)如式(4)所示。
Eval(i)=αL(i)+βD(i).
(4)
其中,α和β分别用于描述节点负载和网络距离在评价中的比重,由系统管理员根据系统对负载均衡和数据传输性能的需求指定[4],且α+β=1。综合评价值Eval(i)的值越大,则节点性能越低;反之,则性能越高。
3.3 算法描述
(1)客户端为集群中节点时,把客户端所在机架作为本地机架,判断当前节点磁盘使用率是否超出阈值,未超出则选择当前节点进行副本放置,超出则说明磁盘剩余空间不足,在本地机架对综合评价值Eval排序,选择评价值较低的两个节点分别作为第一个副本和第二副本的存放节点。
从远程机架选择综合评价值Eval最低的节点作为第三副本存放节点。把三个副本节点保存到目标节点数组。
(2)客户端为集群外节点时,对集群中节点进行综合评价值排序,选择评价值最低的两个节点作为第一个副本和第二副本的存放节点,并将这两个节点存入目标节点数组,同时加入到不可选节点列表中,防止其他副本继续放置在已选择节点。
判断第一副本和第二副本是否在同一机架,如果为同一机架,则在远程机架选择综合评价值Eval最低的节点作为第三副本存放节点;否则,在第一副本所在机架,选择Eval最低的节点作为第三副本存放节点。把第三副本节点加入目标节点数组。
(3)将目标节点数组返回给客户端,由客户端与节点进行交互实现副本写入操作,同时清空目标节点数组和不可选节点列表。
4 实验分析
4.1 实验环境
采用VMware虚拟机部署Hadoop集群实验环境,包含5个机架,分别为R1、R2、R3、R4、R5,每个机架包括5个DataNode,分别为DN1、DN2、DN3、DN4、DN5,集群共由25台PC构成,所有节点操作系统使用ubuntu14.04LTS并安装JDK和Hadoop分布式环境,并进行相应配置,如环境变量、IP地址、开发环境等。实验所用集群中使用机架R1中节点作为客户端进行数据提交,其他机架与机架R1网络距离大小排序依次为R2、R3、R4、R5,即R1与R2网络距离最近,与R5距离最远。
4.2 结果分析
假设初始状态集群中各节点都没有存放数据块,把机架R1中节点DN1作为客户端进行文件写入,该文件大小为20G,默认副本数据块大小64M,默认副本数为3,可把该文件分为320个数据块,按照默认副本放置策略,本地机架存放2个副本,远程机架存放1个副本,则机架R1上存放640个数据块,远程机架存放320个数据块。
4.2.1 副本数量分布
本地机架各节点的数据块分布如图4所示。
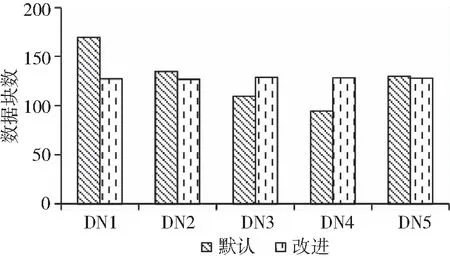
图4 本地机架节点副本分布

图5 默认策略下远程机架节点副本分布
默认副本放置策略下,本地机架随机选择节点进行副本存放,各节点副本分布数量差异较大。改进的策略下,考虑了节点性能以及剩余磁盘空间等因素,根据综合评价值进行节点选择,使得各节点副本数分别相对较均匀。
默认副本策略未考虑节点网络距离对数据传输的影响,远程机架无论网络距离远近,其存放副本数量没有太大差异,一定程度上耗费了更多的带宽,导致系统传输性能下降,如图5所示。改进策略中,通过网络距离和节点负载对节点进行性能评价,判断是否适合存放副本。为了兼顾网络距离对带宽的影响和集群系统负载均衡,平衡因子α和β取值均为0.5,改进策略下远程机架节点副本分布如图6所示。此时网络距离所占权重较高,网络距离较近的机架节点在负载相同情况下优先进行副本存放,提高了数据传输带宽,减少了数据副本放置的时间。

图6 改进策略下远程机架节点副本分布
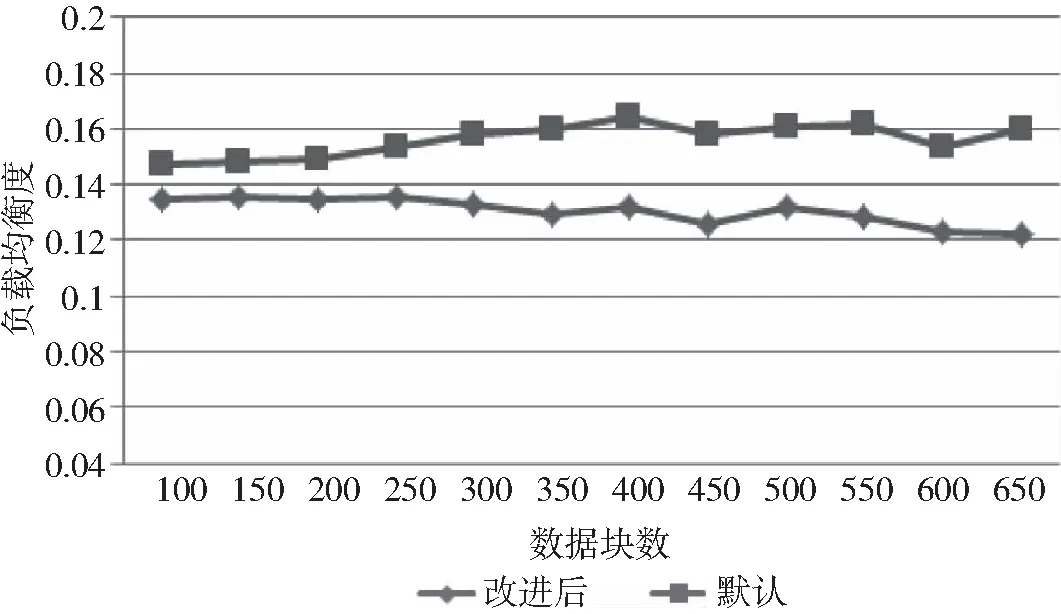
图7 改进策略前后负载均衡对比
4.2.2 负载均衡测试
利用式(5)计算出Hadoop集群系统节点负载标准差S,用来表示集群系统负载均衡度,S值越小则表明集群中节点间负载差异越小,系统负载均衡效果越好。
(5)
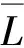
可见,在改进策略下,集群系统负载均衡度相对较低,节点负载差异相对较小,负载均衡效果较默认策略有一定的提高,较好地实现了系统负载均衡。
5 结语
HDFS默认副本放置策略中由于副本存放节点随机选择且未考虑节点网络距离对带宽的影响,易导致负载集群系统负载不均且影响数据传输效率。针对这一问题,本文提出了一种改进的默认副本放置策略,该策略中把节点实时负载、网络距离作为主要指标对节点进行评价,从而选择合适节点进行副本放置。实验分析表明,本文策略可防止高负载节点继续放置副本,有效地实现集群负载均衡,提高数据传输效率,集群系统整体性能得到一定的提升。
[参考文献]
[1]刘艳,蔡燕冬,谢晓东,等.异构Hadoop集群中数据副本放置策略优化[J].华中科技大学学报:自然科学版,2016(7):63-68.
[2]邵秀丽,王亚光,李云龙,等.Hadoop副本放置策略[J].智能系统学报,2013(6):489-496.
[3]刘党朋.不均衡环境下面向Hadoop的负载均衡算法研究[D].北京:北京邮电大学,2015.
[4]林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报:自然科学版,2012(1):152-158.
[5]胡锐,胡伏原,陈丽春.基于Hadoop的高校公共数据平台的构建[J].苏州科技学院学报:自然科学版,2015(3):52-55.
[6]李明明,李伟.基于HDFS的高可靠性存储系统的研究[J].西安科技大学学报,2016(3):428-433.
[7]Apache.Rack aware HDFS proposal [EB/OL].(2017-12-04)[2017-12-21].https://issues.apache.org/jira/secure/attachment/12345251/.2017.
[8]康承昆,刘晓洁.一种基于多衡量指标的HDFS负载均衡算法[J].四川大学学报:自然科学版,2014(6):1163-1169.
[9]徐玖平,吴巍.多属性决策的理论与方法[M].北京:清华大学出版社,2006.
[10]罗鹏,龚勋.HDFS数据存放策略的研究与改进[J].计算机工程与设计,2014(4):1127-1131.
