一种改进的点云局部几何特征匹配方法
2018-04-24史魁洋
史魁洋
(1.四川大学计算机学院,成都 610065;2.四川大学视觉合成图形图像技术国防重点学科实验室,成都 610065)
0 引言
三维几何匹配是计算机视觉与模式识别中的一个重要研究方向。近年来,廉价便携式点云获取设备的发展,极大地带动了点云数据处理技术的研究;三维几何匹配因其在姿态估计和场景重建中的重要性等需要更高性能的方法。
传统手工构造的低级几何特征描述子,如Spin Im⁃ages[2]、Geometry Histograms[3]、Feature Histograms[4]、FP⁃FH[5](Fast Point Feature Histogram)等。它们大多数都是基于静态几何属性的直方图信息,在具有完整曲面的三维模型上可以取得很好的效果,但在面对只有部分曲面信息的三维数据时就会出现表现不稳定,这类算法对杂乱和遮挡的抗干扰力不强,在新场景下的应用缺乏鲁棒性。
Guo Y等提出了一种叫ROPS(Rotational Projec⁃tion Statistics)描述子[6],在关键点处建立局部坐标系,通过旋转关键点的邻域并投影到xy,xz,yz三个2D平面上,并在三个平面上划分“盒子”,根据落到每个盒子的数量,来计算每个投影平面上的一系列分布数据(熵值、低阶中心矩等)从而进行描述。K.Simonyan[1]等提出了一种使用凸优化的方法把局部图像块非线性映射为一种二维局部特征描述子,该描述子主要是用于图片的二维对应关系上,当多视点立体图像缺少纹理时容易造成对应关系缺失。Samuele[7]等提出了SHOT描述子,在特征点处建立局部坐标系,将邻域点的空间位置信息和几何特征统计信息结合起来描述特征点,Cirujeda P[9]等提出一种综合颜色信息和几何信息的协方差描述子,在三维场景的匹配中达到了很好的效果,这两种描述方法都存在着描述子维数过大,计算速度慢等问题。
近年来,随着深度学习在计算机视觉与模式识别领域的广泛应用,深度学习也被引入到三维几何匹配上。3D Shape Nets[8]把三维深度学习引入到三维形状建模上面,通过计算三维数据的深层特征来实现物体的检索与分类,它们是从整个三维物体提取出一个全局特征,这些工作具有启发意义,但全局特征容易受到点云数据分辨率低,噪声、遮挡等影响,难以发挥很好的效果。Guo[10]等使用一个2D卷积神经网络学习到的描述子来进行局部几何特征匹配,但是他们的只是把图像块特征向量连接起来作为网络的输入数据因而缺少空间关联性,故只适用在合成的且具有完整曲面的三维模型上。Andy Zeng[11]等人提出一种叫做3DMatch的自监督特征学习方法,通过一个3D卷积神经网络对训练样本的学习,得到一种局部体积块描述子,该描述子在关键点匹配上达到很好的效果且在新场景下具有很好的鲁棒性。本文在其基础上通过对其使用的3D卷积神经网络的修改,训练得到的新的描述子在相同测试集下准确率达到一定的提升。
1 3DMatch方法介绍
1.1 局部几何特征学习
3DMatch方法的核心是创建一个函数ψ,可以把点云数据表面的一个兴趣点及局部区域映射成一个描述子(向量表示),即给定任意两个点,函数ψ把它们的局部三维体积块转换成两个描述子表示。再计算这两个描述子向量的L2范数,通过L2范数的距离来判断两个描述子的相似度,L2距离越小表示两者的相似度越高。为得到该函数,3DMatch使用一个3D卷积神经网络,通过训练集学习把三维立体图像中某一个兴趣点及其局部区域映射成一个512维的特征表示向量,此特征表示向量即是该局部区域的特征描述子。训练时通过使训练样本中对应的两个匹配点的局部几何描述子的L2距离最小以及两个不匹配点的L2距离最大来优化卷积神经网络的权值参数从而得到该函数模型。
1.2 三维数据表示
3DMatch使用的卷积神经网络的输入数据为大小为 30×30×30 的 TDF(Truncated Distance Function)值的体素网格(Voxel Grid)。
TSDF(Truncated Distance Function)[12]值等于此体素到物体表面的最小距离值,其值范围-1~1之间。TS⁃DF将整个三维空间划分成立体网格,每个网格中存放的是其到物体表面的距离。TSDF值的正负分别代表被遮挡区域与可见区域,当TSDF值大于零,表示该体素在物体表面之前,属于可见区域;当TSDF小于零时,表示该体素在物体表面后,属于遮挡区域;当TSDF值越接近于零,表示该体素越贴近于物体的真实表面。如图1所示的是重建的一个人的脸(网格模型中值为0的部分,红线表示重建的表面),重建好的表面到相机一侧都是正值,另一侧都是负值,在网格模型中从正到负的穿越点表示重建好的场景的表面。其大致原理如图1所示。

图1 TSDF网格表示原理示例:图中的人脸轮廓表示其物体表面
3DMatch使用TDF与TSDF的区别在于TDF舍去了TSDF的正负符号,把值截断并归一化为0~1之间,TDF值越接近1,表示该体素越贴近物体的真实表面,越接近0,表示该体素距表面越远。之所以选择使用TSDF是因为TDF相比TSDF有几项优点:TDF去掉正负号使可见区域与遮挡区域的不再加以区分,使得体素值的最大梯度值从相机视景的可见区域与遮挡区域的阴影边界处集中到物体表面附近,从而使得描述子即使在不完整的数据上也具有鲁棒性;此外当拍摄物体的相机视角不可知时,TDF可以减少物体遮挡空间的不确定性。
实验的局部三维图像块空间跨度为0.3m3,体素大小为0.01m3,体素网格相对于相机视角坐标对齐,如果相机位置信息不可知,则体素网格通过物体坐标对齐。
1.3 训练数据集
3DMatch通过RGB-D重建数据集生成对应点的训练样本。该训练样本由3D图像块以及表示它们是否匹配的对应关系标签组成。生成训练样本的方法如下:首先,在从重建场景中随机选取兴趣点并提取兴趣点周围不同扫描视角的局部3D图像块,再把兴趣点在重建场景的3D位置投影到相机视景内的所有RGB-D帧上,要确保该兴趣点没有被遮挡,此外这些RGB-D帧的相机位置要相距1m以外,再分别从这两个RGBD帧选取该兴趣点的两个局部图像块,这两个局部图像块就作为一对匹配对;从重建物体表面随机采样两个兴趣点(至少相距0.1m),并从随机挑选的两个深度帧上选取这两个兴趣点对应的局部3D图像块,这两个局部图像块用来作为不匹配对。最后把这些匹配与不匹配的图像块转换成TDF体素网格表示。训练集样本总共为16,000,000个,其中正负样本各为8,000,000。部分RGB-D重建数据集场景如图2所示。


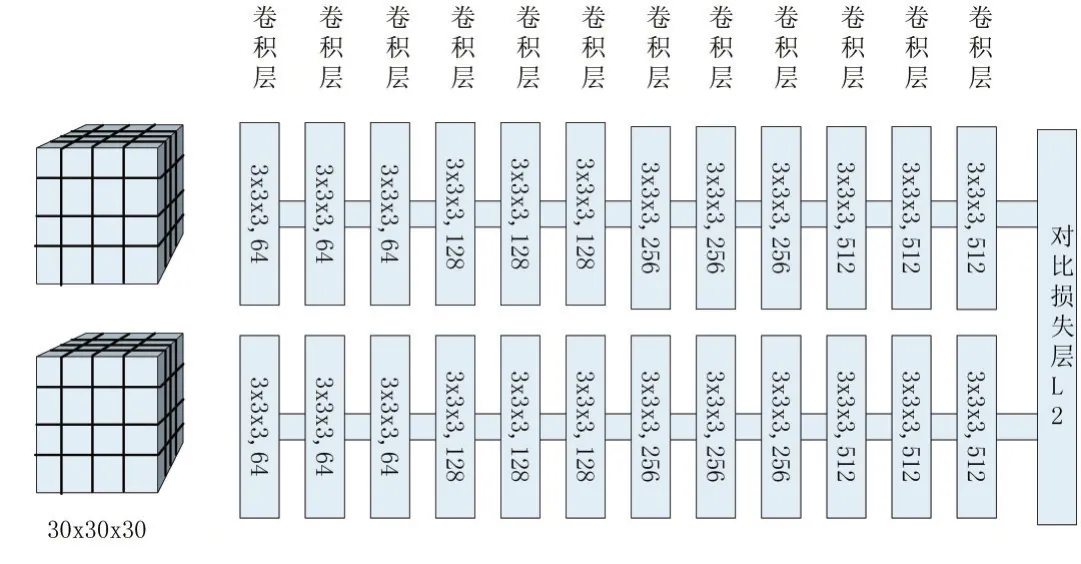
图3 网络结构示意图
2 改进的网络结构
根据Lan Goodfellow[15]等,使用池化是一个无限强的先验,即每一个单元都具有少量平移不变性,与任何其他先验类似,卷积和池化只有当先验的假设合理且正确时才有用,如果一项任务依赖于保存精确的空间信息,那么在所有特征上使用池化将会增大训练误差,受到Szegedy[16]等的卷积网络结构启发,为了保证当平移不变性不合理时不会导致欠拟合的特征,而且由于初始输入的TDF体素网格维度比较小,为了防止子采样造成关键信息损失,本文对3DMatch的网络结构进行修改,设计成在通道上不使用池化;此外受到微软ResNet[13]具有152层网络的的启发,在训练集样本足够多的情况下,更深的卷积网络结构往往能取得更好的训练效果,因此本文也适当的加深了网络结构的深度,由原来的8个卷积层(每一个都有线性修正单元激活函数进行非线性化)增加到12个卷积层,在最后的卷积层输出一个512维的特征表示向量,该特征表示向量作为一个特征描述子。其中网络结构如图3所示,卷积层表示为(kernel size,number of filters)。
网络的训练参数设置如下:
3 实验结果与分析
3.1 关键点匹配测试
通过测试三维局部描述子在区分关键点的局部三维图像块匹配与不匹配的能力可以衡量三维局部描述子的性能。测试采用了3DMatch使用的基准,该测试基准包含30,000个3D图像块,其中匹配与不匹配的正负样本数量比为1:1。评估结果是在95%召回率的条件下的错误率,结果越低说明效果越好。实验主要与 Spin-Images、FPFH、2D ConvNet on Depth、3DMatch描述子在基准上进行比较。其中Spin-Images、FPFH描述子使用PCL[14](Point Cloud Library)提供的代码实现进行测试。比较结果如表1所示。


表1 关键点匹配测试错误率(在95%召回率的情况下)
3.2 实验分析
本文通过对3DMatch卷积网络结构的优化与改进,获得了更好的训练效果。通过训练可以的到一个优秀的局部体积块描述子,该描述子对噪声、新场景的变化具有鲁棒性,可以获得了良好的关键点匹配效果。此外实验也存在着许多不足之处,如在显卡上进行训练时占用显存大,训练速度比较慢等,这些都有待进一步对实验进行优化改进,如采用新的数据表示方法以及新型网络结构等。
4 结语
深度学习是一种有效且方便的新方法,而且效果会随着更多的数据集样本、新型的更深的神经网络结构出现获得进一步的提升。在大数据的支持下,相信深度学习以后将在场景重建、形状匹配等领域得到广泛的使用。
参考文献:
[1]Simonyan K,Vedaldi A,Zisserman A.Learning Local Feature Descriptors Using Convex Optimisation[M].IEEE Computer Society,2014.
[2]Johnson A E,Hebert M.Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2002,21(5):433-449.
[3]Frome A,Huber D,Kolluri R,et al.Recognizing Objects in Range Data Using Regional Point Descriptors[J].Lecture Notes in Computer Science,2004,3023:224-237.
[4]Rusu R B,Blodow N,Marton Z C,et al.Aligning Point Cloud Views Using Persistent Feature Histograms[C].Ieee/rsj International Conference on Intelligent Robots and Systems.IEEE,2013:3384-3391.
[5]Rusu R B,Holzbach A,Blodow N,et al.Fast Geometric Point Labeling Using Conditional Random Fields[C].Ieee/rsj International Conference on Intelligent Robots and Systems.IEEE,2009:7-12.
[6]Guo Y,Sohel F,Bennamoun M,et al.Rotational Projection Statistics for 3D Local Surface Description and Object Recognition[J].International Journal of Computer Vision,2013,105(1):63-86.
[7]Salti S,Tombari F,Stefano L D.SHOT:Unique Signatures of Histograms for Surface and Texture Description☆[J].Computer Vision&Image Understanding,2014,125(8):251-264.
[8]Wu Z,Song S,Khosla A,et al.3D ShapeNets:A Deep Representation for Volumetric Shapes[J],2014:1912-1920.
[9]Cirujeda P,Cid Y D,Mateo X,et al.A 3D Scene Registration Method via Covariance Descriptors and an Evolutionary Stable Strategy Game Theory Solver[J].International Journal of Computer Vision,2015,115(3):306-329.
[10]Guo K,Zou D,Chen X.3D Mesh Labeling via Deep Convolutional Neural Networks[J].Acm Transactions on Graphics,2015,35(1):1-12.
[11]Zeng A,Song S,Niebner M,et al.3DMatch:Learning Local Geometric Descriptors from RGB-D Reconstructions[J].2017:199-208.
[12]Curless B,Levoy M.A Volumetric Method for Building Complex Models from Range Images[C].Conference on Computer Graphics and Interactive Techniques.ACM,1996:303-312.
[13]He K,Zhang X,Ren S,et al.Deep Residual Learning for Image Recognition[J],2015:770-778.
[14]http://pointclouds.org/.
[15]Lan Goodfellow等著.深度学习[M].赵申剑,黎彧君等译.北京:人民邮电出版社,2017.8.
[16]Szegedy C,Liu W,Jia Y,et al.Going Deeper with Convolutions[C].Computer Vision and Pattern Recognition.IEEE,2015:1-9.
