基于深度卷积神经网络的羽绒图像识别
2018-04-13杨文柱王思乐崔振超张宁雨
杨文柱, 刘 晴, 王思乐, 崔振超, 张宁雨
(河北大学 网络空间安全与计算机学院,河北 保定 071002)
0 引言
正确识别监控图像中的羽绒类型,是基于机器视觉[1-2]的羽绒分拣技术的关键.在羽绒监控图像中,同一类型的羽绒形态千差万别,不同类型的羽绒形态也有相似,这使得传统的图像识别技术难以正确识别监控图像中的羽绒类型,其识别精度也难以达到实际生产的要求(正确率不小于90%).深度卷积神经网络[3](deep convolutional neural networks,DCNN)是一种基于特征学习的图像识别方法,其泛化能力较传统的图像识别方法有了明显提高,因此在最近几年,基于DCNN的图像识别方法取得了举世瞩目的成绩.基于特征学习的图像识别方法不需要事先指定应该提取的特征,而是通过迭代学习的方式寻找最适合分类的特征.将DCNN应用于图像识别任务时,不仅可以提高识别精度,还可以避免人工提取特征造成的人力和时间浪费,同时满足在线检测的需要.
近年来识别效果好的DCNN结构有AlexNet[4]、VGGNet[5]、GoogleNet[6]、ResNet[7]等.DCNN在图像识别分类[8]、目标检测[9]、目标跟踪[10]、文本识别[11]、语音识别[12]等方面都取得了很好的成绩.这些网络中权值初始化方法大部分采用随机初始化,如小随机数初始化[4]、Xavier初始化[13]、MSRA初始化[14]等.DCNN的训练方式是有监督训练,所以训练时需要大量有类标的数据来进行权值的更新调整.但当图像数据集较小时容易造成网络的前几层无法得到充分训练等问题,针对该问题的主要解决方案是对网络的卷积核进行无监督预训练,以得到尽可能符合数据集统计特性的卷积核集合.文献[15]通过训练一个稀疏自动编码器,对网络第一层卷积核权值进行初始化,在原图随机切取小块作为稀疏自动编码器的输入,训练得到的权值就是对随机切取小块的一种稀疏表达;同时,小块的选取极为重要,若识别目标在原图中占比较小,随机切取的小块取到背景的可能性较大,这样训练得到的卷积核对网络收敛贡献甚微.
针对以上问题,设计实现了一种用于识别羽绒图像的DCNN,并利用视觉显著性模型和无监督预训练的方法对其权值进行预训练,以提高网络收敛速度和对羽绒图像的识别精度.首先利用视觉显著性模型从原始图像中提取其显著部分,将显著部分截取指定规格的小块输入至稀疏自动编码器中进行无监督预训练,得到DCNN第一层的卷积核,将训练好的卷积核集合输入到针对羽绒图像识别的DCNN中;网络结构采用了Inception模块及其变种模块[6,16]来提高网络的效率,并通过增加网络的宽度和深度来提高网络识别精度;最后利用softmax分类器实现对羽绒类型的识别.
1 网络权值初始化及其改进
1.1 常用的权值初始化方法
DCNN的权值初始化主要是对卷积层和输出层的卷积核参数和偏置进行初始化.权值初始化关系到DCNN的训练时长,优秀的初始权值会使网络以较快的速度达到权值最优,从而提高训练速度.偏置项通常初始化为一个较小的常数或0,卷积核参数初始化通常采用随机初始化方法.目前常用的随机初始化方法有小随机数初始化、Xavier初始化和MSRA初始化等.小随机数初始化是将参数初始化为小的随机数,打破对称性,使得权值服从均值为0、标准差为0.01的高斯分布,但当随机数取值太小时,就会有明显的弊端——反向传播过程中梯度很小,对较深的网络更是会造成梯度弥散的问题,同时参数收敛速度也会降低.针对小随机数初始化方法存在的问题,Xavier等人提出权值服从均值为0、方差为1/n的均匀分布(n为输入神经元的数量),可以提高网络训练的收敛速度.为了使其更适用于ReLU激活函数,MSRA初始化对Xavier初始化进行了改进,其权值服从均值为0、方差为2/n的高斯分布.
利用无监督预训练对DCNN的卷积核权值进行初始化也是常用的权值初始化方法之一.通过构造一个稀疏自动编码器(sparse autoencoder,SAE)对网络权值参数进行预训练,使得输入层和输出层尽可能保持一致;在SAE训练过程中参数得以更新,形成符合数据特性的初始值.自动编码器是一种用于尽可能复现输入信号的神经网络[17].稀疏自动编码器则是在自动编码器的基础上加入了稀疏限制,对隐含层进行了约束,使其变得稀疏.
自动编码器的网络结构如图1所示.L1、L2、L3层分别代表网络输入层、隐含层和输出层.若稀疏自编码输入层维度为6维,隐含层节点数量设置为3,这样迫使隐含层节点学习得到输入数据的压缩表示方法,即用3维数据重构出6维数据.
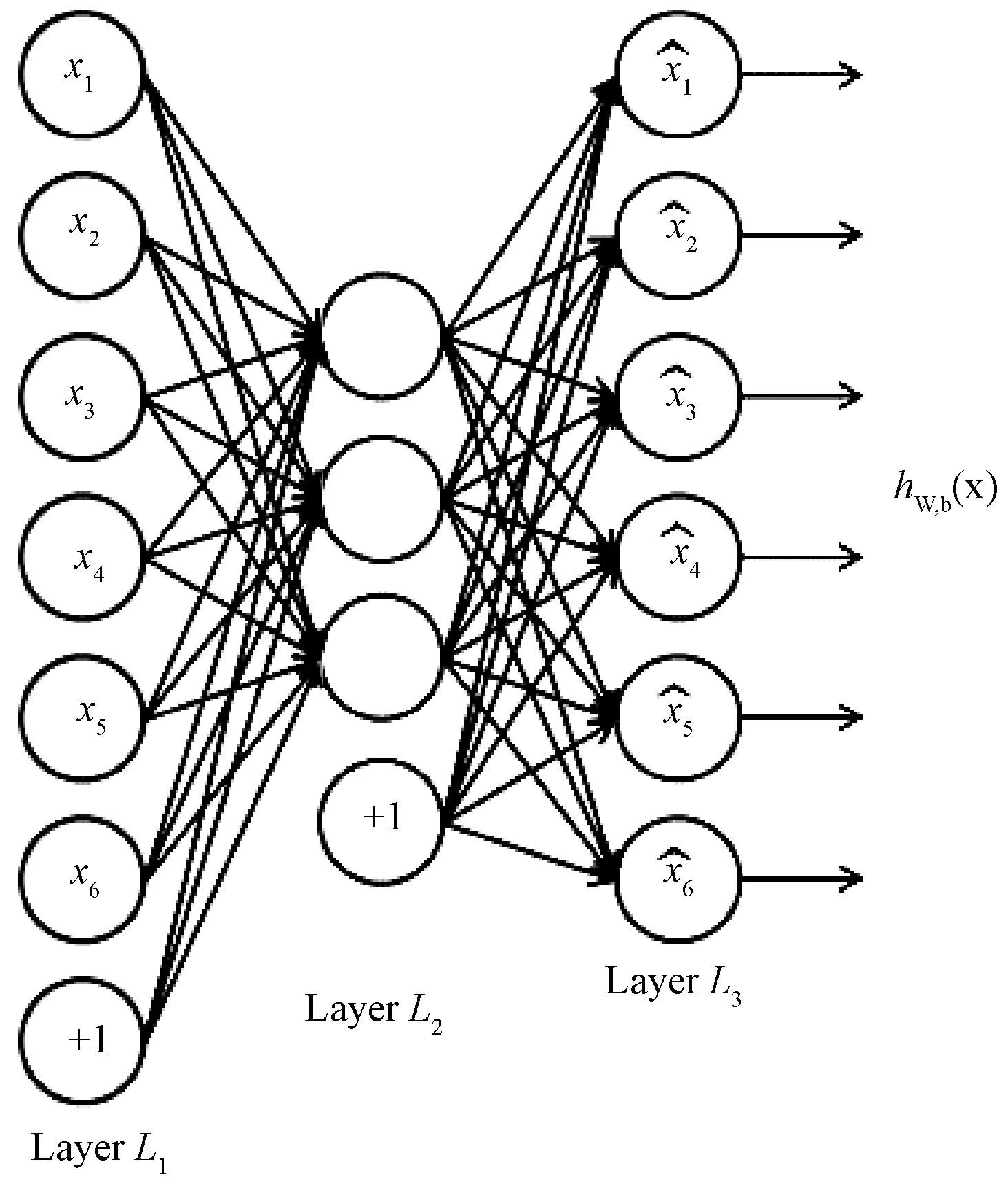
图1 自动编码器的网络结构Fig.1 Network structure of autoencoder
自动编码器损失函数如下:
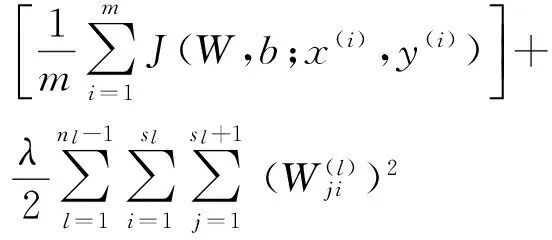
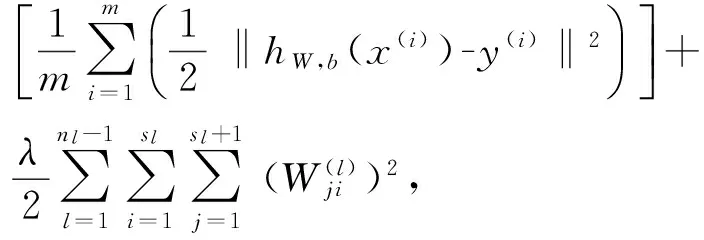
(1)
其中:第1项为均方差项;第2项是权重衰减项,用于减小权重以防止过拟合.
在计算过程中,上述损失函数常导致网络收敛很慢,计算复杂度过高.稀疏自编码在自动编码器的基础上加入L1正则化限制,使得大部分神经元处于抑制状态,少数处于激活状态,使隐含层节点的输出均值尽可能为0.稀疏自动编码器的损失函数表示为:
(2)
其中,KL(Kullback-Leibler)距离表达如下
(3)
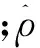
(4)
1.2 基于视觉显著性和无监督预训练的权值初始化方法
首先利用视觉显著性算法来提取图像的显著部分,然后随机截取显著部分图像输入至稀疏自动编码器中进行无监督预训练.采用谱残差算法
(spectral residual approach,SRA)来获取图像的显著部分,其主要原理是在原图中将背景剔除,即可得到图像的前景,也就是图像的显著部分[18],如图2所示.若CNN的第一层卷积操作需要8个5×5大小的卷积核,那么首先在显著图上随机截取N个5×5的小块作为稀疏自编码的输入层,隐含单元个数设置为8,经过稀疏自编码的预训练得到的W大小为25×8,再将W变为8×5×5即可得到卷积神经网络第一层卷积核集合W.

图2 基于视觉显著性和SAE预训练框架Fig.2 Training framework based on visual significance and SAE

图3 Inception模块及其变种Fig.3 Inception module and its variants
2 基于DCNN的羽绒图像识别网络结构
深度卷积神经网络的网络结构对最终的识别精度有着重要的影响.本文数据集为在生产线上实际采集的羽绒图像经过剪裁后的子图像,子图像大小均为100×100,比MNIST和CIFAR数据集中图像的分辨率要大很多.为提高网络效率和识别精度,采用Inception及其变种模块来构建基本网络结构.
Inception模块的主要特点是在加大了网络深度和宽度的同时不增加计算量,还提高了计算资源的利用率.Inception模块结构如图3(a)所示,由1×1、3×3、5×5的卷积操作和3×3的池化操作组成,通过设定1×1卷积核的数量,实现通道数的降维或升维,同时对不同通道的特征进行融合.Inception模块的优势主要体现在两个方面:①使用小卷积核在减少网络训练参数的同时降低了网络计算复杂度;②使用不同大小的卷积核对同一特征图进行特征提取.随后研究者又提出将较大的卷积核分解成2个小卷积核,如图3(b)所示,用2个3×3的卷积核代替5×5的卷积核,节约了计算时间,为增加卷积核数目提供便利条件.图3(c)为Inception模块的另一个变形,经过卷积和池化操作后的特征图大小是前一层的1/2,该方法使用了2个并行化的模块,不仅减少了网络的计算量,还有效地避免了池化所造成的信息损失.
针对羽绒图像识别构造的DCNN结构如图4所示.输入层图像大小为100×100;C1层是步长为2的卷积层,其卷积核大小为3×3,本层产生32个大小为50×50的特征图;C2层为步长为1的卷积层,卷积核大小为3×3,本层产生64个大小为48×48的特征图;S1为池化层,采样窗口大小为3×3,窗口滑动步长设置为2,本层产生64个大小为24×24的特征图.Inception_1层具体结构如图3(b)所示.采用padding方式进行卷积运算,得到的特征图大小与前一层特征图大小相同,即得到164个大小为24×24的特征图.Inception_2层具体结构如图3(c)所示,得到114个大小为12×12的特征图;C3层是步长为1的卷积层,卷积核大小为3×3,本层产生64个大小为10×10的特征图;FC1层为全连接层,将C3层的64个特征图连接成一个特征向量;FC2层由8个神经元构成特征向量,对应8种类别输出,FC2全连接层和输出层构成一个softmax分类器.
3 试验设计与结果分析
试验环境采用河北大学信息技术中心的超算平台,使用其中一个独立的计算节点,该计算节点配置64个GPU,可大幅提升训练速度.DCNN程序采用基于Python的Tensorflow深度学习框架,而基于视觉显著性和无监督预训练的过程采用MatlabR2016a实现.数据集为经过剪裁的2 300张羽绒图像,图像像素大小均为100×100,共8类(5个单独类和3个混合类)如图5所示.
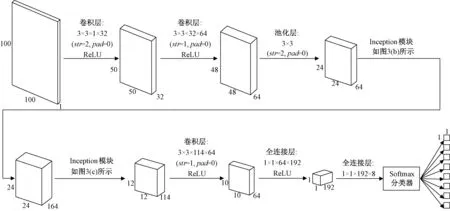
图4 网络结构Fig.4 Structure
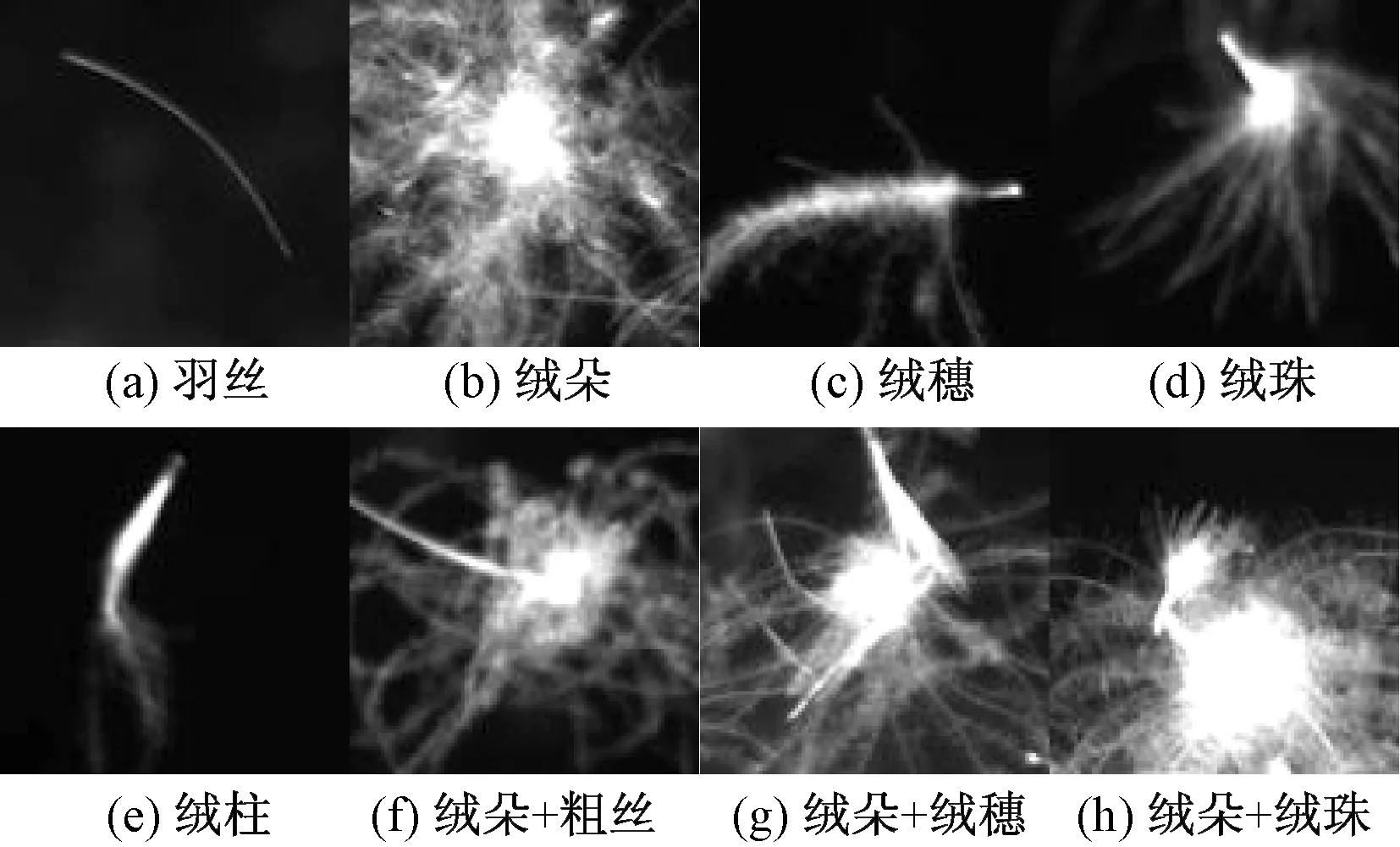
图5 羽绒图像类别Fig.5 Categories of down image
3.1 试验步骤
步骤1:首先利用谱残差模型提取原图显著部分并切割,提取若干张图像显著区域,如图6所示.

图6 提取图像显著区域Fig.6 Extracting saliency area from image
步骤2:因为针对羽绒图像识别提出的框架第一层卷积层需要32个3×3的卷积核,故将上一步中得到的若干显著区域随机切取N个3×3的小块,输入至稀疏自动编码器中,其中,稀疏自动编码器的隐含单元个数设置为32,训练得到的稀疏自动编码器的权值系数大小为6×32,将其格式转换为32×3×3即可得到DCNN第一层卷积核集合W,图7为训练的卷积核集合.

图7 卷积核集合Fig.7 Convolutional kernels
步骤3:将数据集输入至图4的深度卷积神经网络中训练并测试,得到识别错误率.其中训练集包含2 000张羽绒图像,测试集包含300张羽绒图像.
3.2 试验结果与分析
本试验利用支持向量机(support vector machine,SVM)作为传统图像识别分类的代表进行对比试验.将待识别的图像进行小波变换和图像分割,提取变换系数的主成分以及分割得到的目标形状特征作为特征向量,该特征表示能力强、特征维数较低,对笔者试验数据集有较好的表示能力,且计算效率较高.但其计算错误率和训练时长相较于LeNet-5卷积神经网络仍然较高,如表1所示.
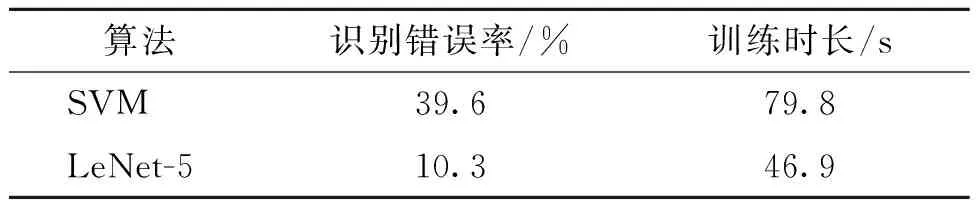
表1 支持向量机与卷积神经网络对比实验
为了验证图4网络结构及笔者提出的基于视觉显著性和稀疏自编码预训练的权值初始化方法的有效性,设计了6种不同的试验,如表2所示.
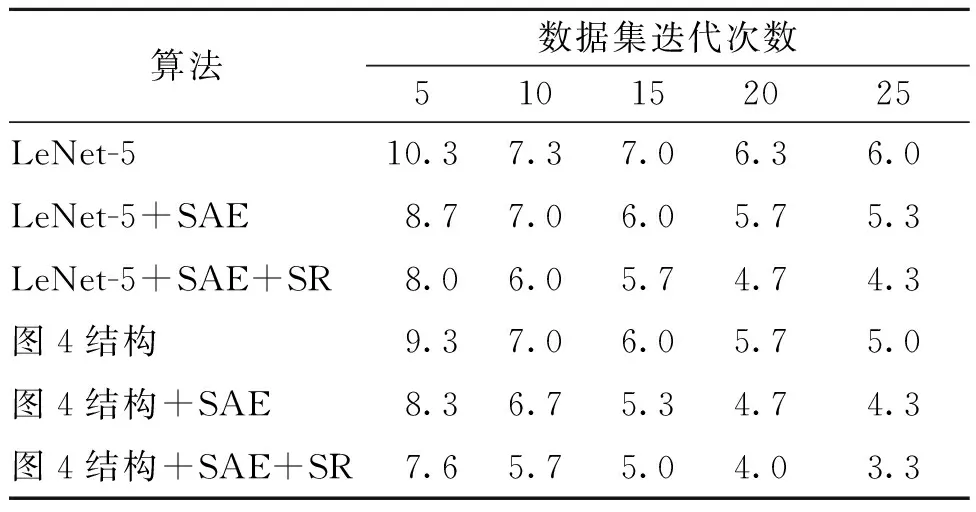
表2 识别错误率对比
由表2可以看出,利用稀疏自编码预训练算法对LeNet-5网络初始权值进行改进,较未加入LeNet-5的网络降低了对羽绒图像的识别错误率,说明稀疏自编码预训练对卷积神经网络训练有一定的贡献.对比加入稀疏自编码预训练算法的LeNet-5网络与利用视觉显著性和稀疏自编码算法对LeNet-5网络初始权值进行改进,可以看出加入了视觉显著性和稀疏自编码预训练算法的LeNet-5网络进一步降低了识别错误率,并随着数据集迭代次数的增加而降低.
由表2还可以看出,通过对比图4网络结构和经典LeNet-5网络对羽绒图像的识别训练,图4网络结构对羽绒图像的识别效果更好,对比经过稀疏自编码预训练的LeNet-5网络,在数据集迭代25次后,图4网络结构对羽绒图像识别有较低的错误率,说明笔者提出网络结构对羽绒图像识别的有效性;同时,在图4网络结构中加入稀疏自编码预训练算法,识别效果也有了一定的提高;在此基础上加入谱残差算法和稀疏自编码预训练算法对网络权值进行初始化,在数据集迭代25次后,该网络对羽绒图像的识别正确率达到了96.7%.
图8为LeNet-5网络与笔者提出的网络结构针对羽绒图像训练的时间对比曲线.因羽绒图像易混,若图像分辨率小将更难区分,所以本数据集分辨率大小均为100×100.由图8可以看出,在网络训练中,笔者提出的网络结构较LeNet-5训练时间更短,收敛速度更快,且与本机(Linux Ubuntu-16)训练速度相比,在超算平台上的训练速度更快.

图8 训练时长Fig.8 Training time
4 结论
针对羽绒图像识别构造了一个深度卷积神经网络,并对权值初始化方法进行了改进,主要贡献如下:①利用视觉显著性模型提取原图显著区域,并利用显著区域进行无监督预训练,训练得到的权值系数即为DCNN卷积核的初始权值.利用这种初始化方法,在样本数较小的情况下,DCNN也能以较快速度达到权值最优,且识别精度有所提升;②网络结构主要采用Inception模块,适当加大了网络深度和宽度,提高了网络效率和识别精度.本试验的数据集是经过裁剪的子图像,而实际生产中的图像分辨率极高且图像内容更复杂,如何实现高分辨复杂图像的识别,是下一步将要进行的工作.
参考文献:
[1]陈继华,李勇,田增国,等. 基于机器视觉的机械式表盘自动读表技术的实现[J]. 郑州大学学报(工学版), 2015, 36(3):101-105.
[2]张震,刘博,李龙. 一种多特征提取及融合的虹膜识别方法[J]. 郑州大学学报(工学版), 2017, 38(1):63-67.
[3]LECUN Y, BOSER B, DENKER J S, et al. Backpropagation applied to handwritten zip code recognition [J]. Neural computation, 1989, 1(4):541-551.
[4]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems (NIPS).California: MIT Press 2012:1097-1105.
[5]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]//International Conference on Learning Representations (ICLR). San Diego: arXiv:1409.1556v6 [cs.CV], 2015.
[6]SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston: IEEE computer society, 2015:1-9.
[7]HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE computer society, 2016:770-778.
[8]IOANNOU Y, ROBERTSON D, SHOTTON J, et al. Training convolutional neural networks with low-rank filters for efficient image classification[J]. Journal of bacteriology, 2016, 167(3):774-783.
[9]QU L, HE S, ZHANG J, et al. RGBD salient object detection via deep fusion [J]. IEEE transactions on image processing, 2017, 26(5):2274-2285.
[10] WANG L, OUYANG W, WANG X, et al. STCT: sequentially training convolutional networks for visual tracking[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE computer society, 2016:1373-1381.
[11] WU Y C, YIN F, LIU C L. Improving handwritten Chinese text recognition using neural network language models and convolutional neural network shape models [J]. Pattern recognition, 2016, 65(C):251-264.
[12] MITRA V, FRANCO H. Time-frequency convolutional networks for robust speech recognition[C]// IEEE Automatic Speech Recognition and Understanding (ASRU). Scottsdale: IEEE computer society, 2015:317-323.
[13] GLOROT X, BENGIO Y. Understanding the difficulty of training deep feedforward neural networks [J]. Journal of machine learning research, 2010, (9):249-256.
[14] HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification [C]// IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE computer society,2015:1026-1034.
[15] 王冠皓,徐军. 基于多级金字塔卷积神经网络的快速特征表示方法[J]. 计算机应用研究, 2015, 32(8):2492-2495.
[16] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the Inception architecture for computer vision[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE computer society, 2016:2818-2826.
[17] ZENG K, YU J, WANG R, et al. Coupled deep autoencoder for single image super-resolution [J]. IEEE transactions on cybernetics, 2016, 47(1):27-37.
[18] HOU X, ZHANG L. Saliency detection: a spectral residual approach[C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Minneapolis: IEEE computer society, 2007:1-8.
