基于深度学习的多声源并行化声纹辨别方法
2018-04-11范远超
刘 镇, 吕 超, 范远超
(江苏科技大学 计算机科学与工程学院, 镇江 212003)
随着智能感知和机器学习的快速发展,声纹辨别技术在实时人机交互中占有重要地位,被广泛应用于民用和军事领域,具有良好的发展前景.当前人们对机器智能性、实时性和鲁棒性的要求越来越高,随着数据量的不断增加,如何在大数据量的样本中快速提取特征,简单而有效地辨别声纹已经成为了语音领域的研究热点之一.
目前声纹辨别的常用方法有模式匹配与动态时间规整[1]、矢量量化[2]、高斯混合模型[3]、支持向量机[4]、人工神经网络等.近年来,随着深度学习技术的发展,深度神经网络在语音识别、声纹辨别等多类应用中取得突破性进展,在国内外引起了广泛关注[5].
传统声纹识别技术存在一定的不足:一方面单拾音器无法用于多声源环境,其在抗噪声方面效果较差,对语音信号的特征提取具有片面性[6];另一方面语音信号处理的计算量大、运算过程复杂,传统的PC机或DSP等设备都采用串行计算模式,其运算速度严重制约了系统实时性[7].
为此,文中提出一种基于深度学习的多声源并行化声纹辨别方法,整体流程如图1.首先利用拾音阵列获取目标声源的位置和时频域信息,构造掩蔽函数进行信号的数据级融合,然后将各通道信号的MFCC(mel-frequency cepstral coefficients)参数进行特征级融合,形成高维的声纹向量输入深度信念网络(deep belief network,DBN)进行训练和识别.针对样本数据量大的特点,文中基于NVIDIA Jetson TK1的GPU嵌入式平台,利用CUDA(compute unified device architecture)[8]分别对目标声纹提取和DBN的训练方法进行了并行优化.
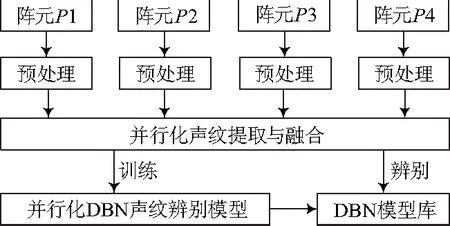
图1 并行化声纹辨别流程
1 基于拾音阵列的声纹提取与融合
1.1 多通道声纹提取与融合原理
在实际应用的多声源环境中,存在着混响、噪声等各种干扰源,文中设计了一种平面四元拾音阵列模型,使用基于目标声源位置和时频域信息的掩蔽方法[9],从而提取目标语音的声纹,如图2,以拾音器阵列y轴上的两个阵元P1和P2为例来说明提取融合目标声纹的方法.
假设环境中有3个声源X、Y、Z,其中X为目标语音声源,其余为干扰噪声源.此时,拾音器P1和P2接收到的信号经过预处理后分别为:
p1(t)=x1(t)+y1(t)+z1(t)
(1)
p2(t)=x2(t)+y2(t)+z2(t)
(2)
假设:
p2(t)=p1(t)×Δp(t)
(3)
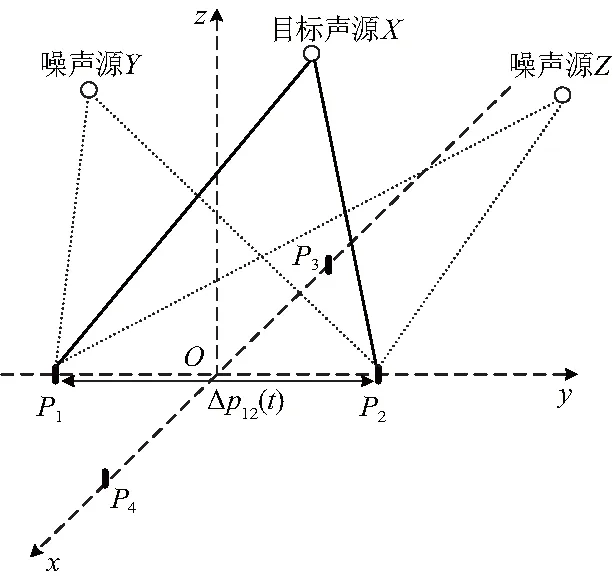
图2 拾音阵列模型
式中,Δp(t)为差异滤波器[10],代表了两通道信号之间的相关性和差异性,其中包含了声源的位置和声纹信息,Δp(t)的频响为ΔP(ω).根据傅里叶变换的卷积特性,在某一时频点(ωk,tτ)上可具体表示为:
(4)
ΔP(ωk,tτ)反映了混合声源在时频点(ωk,tτ)上的方位信息.由于目标声源与拾音阵列的位置相对固定,可以根据两信号每个时频点的相对时延,由聚类算法[11]得到目标语音的方位信息ΔX(ω).而独立信号在时频域上具有近似稀疏性,混合信号中的某个时频点仅属于某个声源[10],所以可以通过扫描混合声源各时频点ΔP(ωk,tτ)和目标声源对应频率点ΔX(ωk)的差异大小,判断该时频点是否属于目标语音的声纹.
将该时频点ΔP(ωk,tτ)和目标声源某频率点ΔX(ωk)之间差异记为α:
(5)
式中,α反映了该时频点与目标语音声纹的差异大小,α越大说明差异越大,此时需要加大对该时频点的衰减抑制.采用式(6)的非线性函数计算每个α对应的衰减系数,从而构成掩蔽矩阵M(ω,t),最后由式(7)即可通过掩蔽矩阵求出两通道融合后的目标声源频谱:
M(ω,t)(α)=(1+(2α)10)-1
(6)
(7)
用一组按Mel频率分布的三角窗滤波器对上式信号的频谱进行滤波,得到Mel频率上的频谱,然后对Mel频谱求其对数频谱,再通过离散余弦变换将对数频谱转变为倒谱系数,从而得到MFCC参数.为了进一步减小语音帧与帧之间的相关性,根据人耳感知能力对声音动态特性更为敏感的特点,文中采用MFCC及其1阶、2阶差分系数各12维的组合作为特征参数来描述目标声纹,即每个通道取36维MFCC特征向量.
同理,以拾音阵列x轴上的阵元P3和P4为一组,按照上述方法可提取出P3、P4通道中的目标声纹.最后将4个通道中对同一目标声源提取的4组MFCC组合,进行特征级融合,便得到多通道融合后的高维声纹向量.使用上述方法亦可以提取其他目标声源的声纹.
1.2 声纹提取与融合的并行化实现
在CUDA平台上利用GPU并行计算时,各个线程所执行的计算任务之间需要具有很高的独立性,线程之间的通讯尽量避免.每个线程所执行计算的数据被称为单位数据,这种单位数据间能够被并行处理的性质被称为数据并行性.
由以上分析可知,整个模型在声纹提取与融合阶段有大量的数据计算,存在并行性,文中主要研究了基于CUDA的线程级并行计算:
(1) 由公式(5)可知,在基于拾音阵列提取目标声源频谱时,要对每个时频点逐一扫描计算,而各时频点的差异参数α相互独立,互不干扰;
(2) 由公式(7)可知,在声纹信号融合时,该步骤为两个矩阵相乘,矩阵乘法作为CUDA并行计算的典型操作之一,可直接调用CUDA平台CUBLAS库中的相关函数完成.
假设某一通道信号经过预处理后的时域范围为0≤t≤T,频域范围为0≤ω≤K,时频掩蔽函数M(ω,t)为一个K×T维的矩阵.CUDA调用GPU资源并行处理时,核函数一次启动K个线程块,一个线程块内又划分为T个线程,每个线程完成某一时频点(ωk,tτ)下α及其衰减系数的计算,每个线程块完成某频率点ωk中所有时频点的计算.当本次任务完成后,再调用cublasSgemm库函数完成掩蔽矩阵与原始矩阵的乘法,从而得到目标声纹的频谱,以便提取MFCC参数进行特征级融合.提取声纹频谱的GPU并行化实现算法描述如下:
输入:ΔP(ω,t),ΔX(ω)
输出:X′(ω,t)
(1) MemcpySync(ΔP(ω,t), host->device);
(2) MemcpySync(ΔX(ω), host->device);
(3)M(ω,t)(α)←MaskMatrixKernel <<
(4) _syncthreads();
(5) cublasSgemm(′n′, ′n′,T,K,T, 1,M(ω,t)(α),K, ΔP(ω,t),T, 0,X′(ω,t),T);
(6) _syncthreads();
(7) MemcpySync(X′(ω,t),device->host);
2 基于深度神经网络的并行化声纹辨别
2.1 声纹辨别模型
DBN是深度神经网络的一种代表模型,是深度学习和人工神经网络不断发展并结合的产物[12].DBN由多层受限玻尔兹曼机(restricted Boltzmann machines,RBM)堆叠组成,逐层训练,其中每层都是捕捉底层隐藏特征的一个高阶相关过程,然后对权重和偏置等参数进行反向传播调整.
其中,RBM是一类具有两层结构的随机神经网络模型,主要由可视层(v层)和隐藏层(h层)所组成,其层与层之间通过权值全连接,而层内无连接,其结构如图3.RBM中的h层结点均为二值单元,v层可以是二值单元也可以不是;当v层和h层均为二值单元时,称为伯努利-伯努利RBM模型,当v层是高斯型数据时,称为高斯-伯努利RBM模型.文中所提取的MFCC声纹向量是服从高斯分布的连续实数,因此显层和第一隐层之间是高斯-伯努利RBM模型;隐层与隐层之间则是伯努利-伯努利RBM模型.
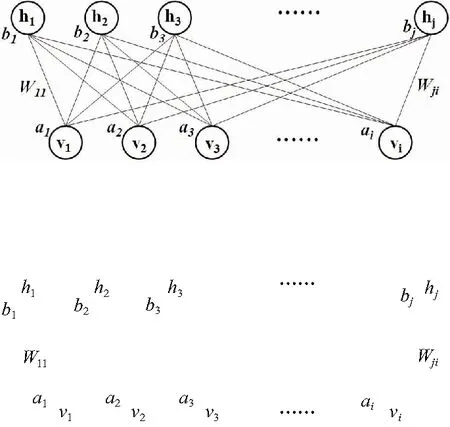
图3 受限玻尔兹曼机结构
以伯努利-伯努利RBM模型为例,其能量函数为:
(8)
式中:I为可视层单元个数;J为隐藏层单元个数;θ={W,a,b}为参数模型集合;Wji为可视层与隐藏层之间的权重系数;ai,bj分别为可视层和隐藏层的偏置项.
由于RBM是一个二部图,层内无链接,在给定其中一层各单元状态时,另一层各单元的激活条件是独立的.所以,在己知v层的情况下,h层的概率分布可以表示为:
(9)
同理,在己知h层的情况下,v层的概率分布为:
(10)
式中,g(x)为sigmoid函数.
高斯-伯努利RBM的能量模型与条件概率的计算方法与伯努利-伯努利RBM类似.
RBM通过梯度下降法进行极大似然学习来更新参数,通常采用对比散度(contrastive divergence,CD)的方法来近似完成.首先将v层输入矢量通过网络权重映射到h层输出矢量,之后对h层输出矢量进行Gibbs采样,并利用所得到的采样结果重建v层目标矢量,最后将这些新的v层矢量再次进行映射,得到新的h层输出矢量,反复执行以上过程,进行k步交替采样完成对模型分布数学期望的近似,从而得到RBM网络权重更新准则:
ΔWij=γ(
(11)
Δai=γ(
(12)
Δbj=γ(
(13)
式中:γ为CD-k算法的学习率;<·>0为样本数据集上的期望;<·>k为k步重构后模型分布上的期望.
DBN的训练过程分为两个阶段:① 无监督预训练,根据CD-k算法,由低到高逐层训练每个RBM,使模型得到一个较优的初始参数值;② 有监督微调,利用带标签的训练样本通过误差反向传播算法对DBN性能进行优化调整.
如图4,在训练神经网络时,按照上文介绍的声纹提取方法,将融合后的声纹向量作为输入层送入DBN模型中,经过上述训练流程迭代得到DBN模型的逐层参数,完成训练过程.

图4 基于DBN的声纹辨别流程
在辨别测试时,按照同样的方法对测试样本进行特征提取,得到声纹输入数据,然后通过已训练好的DBN模型,得到测试样本的预测结果.将预测结果与已知的样本标签进行对比,如果相同则辨别的结果正确,反之则辨别错误,通过批量测试即可得到声纹辨别系统的准确率.
2.2 基于CUDA的DBN并行化实现
DBN采用分层训练的方法,同一层的神经元之间无连接,不存在相互依赖的关系,本层神经元只与上一层神经元传递过来的输入有关,即本层各神经元的计算相互独立,可以并行执行.
DBN声纹辨别模型在CUDA上实现的整体流程如下:① 在CPU主机端初始化参数,在GPU设备端分配显存空间;② 把训练样本和网络初始参数等数据从主机端传入到设备端;③ 在设备端调用CUDA平台上的kernel函数分别完成对各层神经元的计算,同时更新权值和偏置值;④ 根据设置的迭代次数或误差大小反复调用相关kernel函数,直至训练结束,得到DBN模型;⑤ 将DBN的模型参数由设备端传递回主机端.
基于CUDA优化的DBN分层训练方法可以使得在GPU上的并行部分尽量最大化,减少并行和串行反复交替执行的次数,节约了数据在CPU内存与GPU显存之间传递的时间.
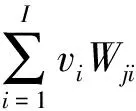
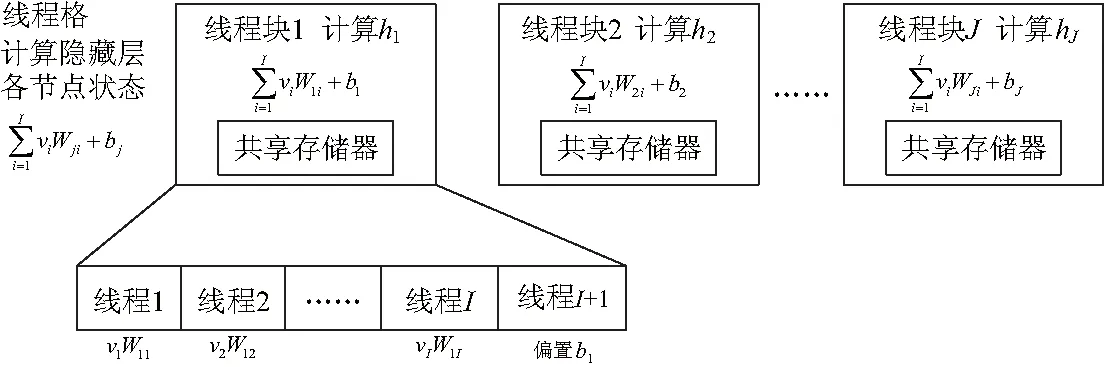
图5 计算隐藏层状态的GPU资源划分
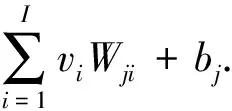
以上具体分析了RBM中计算隐藏层节点状态的并行化方法,同理可得计算可视层节点状态、修正权值和偏置值等步骤的并行化方法.由此可总结出基于CUDA的并行RBM训练算法(CD-k)如下:
输入:训练样本集S
输出:受限玻尔兹曼机参数θ={ΔWji,Δai,Δbj}
(1) random init ΔWji=0, Δai=0, Δbj=0;
(2) forx∈Sdo
(3)v(0)←x;
(4) MemcpySync(θ={ΔWji, Δai, Δbj},v(0),host->device);
(5) fort=1,2,…,kparallel do
(6)hj(t)←ComputeHiddenKernel<<
(7) _syncthreads();
(8)vi(t+1)←ComputeVisibleKernel<<
(9) _syncthreads();
(10) ΔWji←ΔWji+p(hj=1|v(0))·vi(0)-p(hj=1|v(k))·vi(k)
(11) Δai←Δai+vi(0)-vi(k)
(12) Δbj←Δbj+p(hj=1|v(0))-p(hj=1|v(k))
(13) end for
(14) MemcpySync(θ={ΔWji, Δai, Δbj},
device->host);
(15) end for
3 实验与分析
3.1 实验环境
使用NVIDIA公司的Jetson TK1嵌入式开发组件作为实验平台.该设备具有四核ARM(Cortex-A15 CPU,包含192个CUDA核心的Kepler GPU)、2GB内存、8路信号输入接口.系统环境为Ubuntu14.04和CUDA6.5开发平台.
实验的语音样本选自Timit国际语音库,按照图2建立拾音阵列,在含有干扰噪声源的环境下分别播放Timit库中100个目标说话人的语音,并同步采集.所有样本均为16 kHz采样频率,单声道.经过加窗分帧后,每人即每类标签约有2 000帧声纹样本,其中一半作为训练样本,另一半作为测试样本.
为了将神经网络的规模控制在合理范围内,文中将10个说话人分为一组,共10组并行训练;先分别训练并测试每组的辨别准确率,再将各组DBN模型联合起来进行测试.由于DBN根据测试样本的最大似然估计概率选定辨别结果,故联合模型的辨别结果就是所有组中估计概率最大值对应的标签类别.
3.2 实验结果与分析
每段语音首先通过传递函数为H=1-0.95z-1的预加重滤波器,随后采用汉明窗进行加窗分帧处理,接着使用双门限法进行端点检测,去除静音段;然后使用文中提出的目标声纹提取融合的方法,将各通道的36维特征参数融合形成144维的高维声纹向量,作为深度神经网络的输入层单元进行训练.
测试经过信号融合后高维MFCC声纹的辨别准确率,并将其与单通道提取的MFCC特征作了对比,实验结果如图6.可知,通过掩蔽融合的方法将声源频谱中的干扰时频点滤除,并将多通道的MFCC参数融合形成高维特征,使得声纹辨别的准确率有了明显提高.
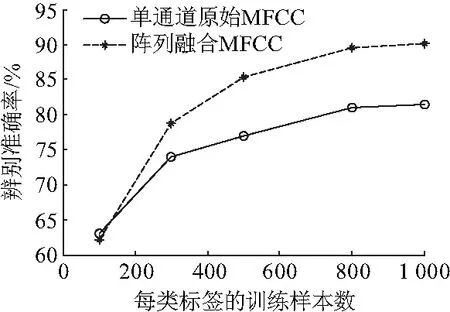
图6 声纹融合前后的性能对比
使用不同数量的训练样本分别对传统BP神经网络和深度神经网络DBN进行测试,分析其对声纹辨别系统准确率的影响,实验结果如图7.可见深度神经网络DBN的识别性能优于传统的BP神经网络,但需要更多的样本来训练模型.因此,DBN模型更加需要并行化的方法加快训练速度,提高效率.
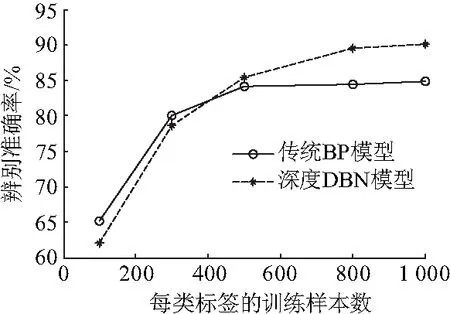
图7 两种神经网络的性能对比
表1对比了在不同样本人数下,串行传统DBN算法与并行优化DBN算法的训练时间,以及GPU并行加速比和辨别准确率.可知,在GPU并行模式下的训练时间远小于CPU串行模式,并行化加速效果明显,加速比在5倍左右;而且随着训练样本数量的增加,GPU并行化的加速优势越明显;而声纹辨别准确率基本保持在90%左右.
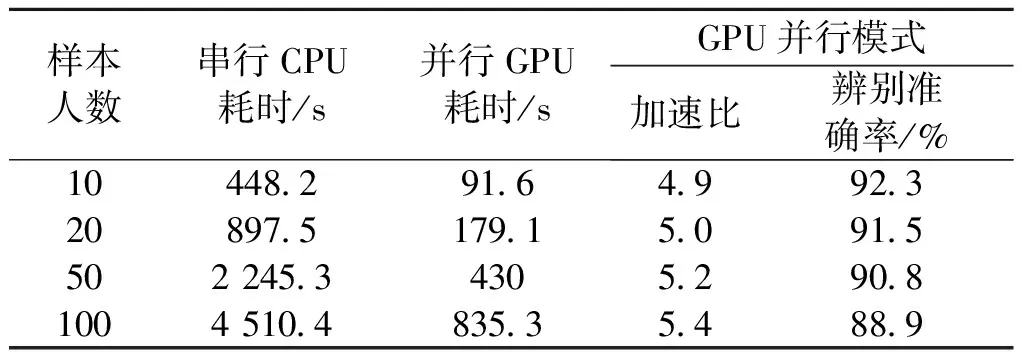
表1 DBN串行训练时间与并行训练时间比较
4 结论
(1) 在大数据语音处理的背景下,提出了一种基于深度学习的多声源并行化声纹辨别方法.通过拾音阵列分析目标声源的位置和时频域信息,提取目标声纹,实现信号的数据级融合,然后将各通道中提取的MFCC声纹参数进行特征级融合,形成高维的声纹向量,输入DBN进行训练和辨别;
(2) 使用CUDA平台分别对声纹融合和DBN的训练方法进行了并行优化.实验证明,该方法在多声源环境下能全面地提取目标声纹,有效提高声纹辨别准确率,减少数据处理时间,提高了系统实时性.
References)
[1] 宋大杰. 基于DTW的说话人识别及其在DSP上的实现[D]. 南昌: 东华理工大学, 2012.
[2] WANG Y, TANG F, ZHENG J. Robust text-independent speaker identification in a time-varying noisy environment[J]. Journal of Software, 2012, 7(9). DOI:10.4304/jsw.7.9.1975-1980.
[3] HANILÇI C, ERTAF. Comparison of the impact of some Minkowski metrics on VQ/GMM based speaker recognition[J]. Computers & Electrical Engineering, 2011, 37(1): 41-56. DOI:10.1016/j.compeleceng.2010.08.001.
[4] MAK M W, RAO W. Utterance partitioning with acoustic vector resampling for GMM-SVM speaker verification[J]. Speech Communication, 2011, 53(1): 119-130. DOI:10.1016/j.specom.2010.06.011.
[5] YU D, DENG L. Deep learning and its applications to signal and information processing [exploratory DSP][J]. IEEE Signal Processing Magazine, 2011, 28(1): 145-154. DOI:10.1109/msp.2010.939038.
[6] 何朝霞, 潘平. 说话人识别中改进的MFCC参数提取方法[J]. 科学技术与工程, 2011, 18(18): 4215-4218,4227. DOI:10.3969/j.issn.1671-1815.2011.18.022.
HE Zhaoxia, PAN Ping. An improved method of MFCC parameter extraction in speaker recognition[J]. Science Technology and Engineering, 2011, 18(18): 4215-4218,4227. DOI:10.3969/j.issn.1671-1815.2011.18.022.(in Chinese)
[7] 陈丽萍, 王尔玉, 戴礼荣, 等. 基于深层置信网络的说话人信息提取方法[J]. 模式识别与人工智能, 2013, 26(12): 1089-1095. DOI:10.3969/j.issn.1003-6059.2013.12.001.
CHEN Liping, WANG Eryu, DAI Lirong, et al. Deep belief network based speaker information extraction method[J]. Pattern Recognition and Artificial Intelligence, 2013, 26(12): 1089-1095. DOI:10.3969/j.issn.1003-6059.2013.12.001.(in Chinese)
[8] 张庆科, 杨波, 王琳, 等. 基于GPU的现代并行优化算法[J]. 计算机科学, 2012, 39(4): 304-310. DOI:10.3969/j.issn.1002-137X.2012.04.071.
ZHANG Qingke, YANG Bo, WANG Lin, et al. Research on parallel modern optimization algorithms using GPU[J]. Computer Science, 2012, 39(4): 304-310. DOI:10.3969/j.issn.1002-137X.2012.04.071.(in Chinese)
[9] YILMAZ O, RICKARD S. Blind separation of speech mixtures via time-frequency masking[J]. IEEE Transactions on Signal Processing, 2004, 52(7): 1830-1847. DOI:10.1109/tsp.2004.828896.
[10] 夏秀渝, 何培宇. 基于声源方位信息和非线性时频掩蔽的语音盲提取算法[J]. 声学学报, 2013, 38(2): 224-230.
XIA Xiuyu,HE Peiyu. Speech blind extraction algorithm based on sound source azimuth information and nonlinear time-frequency masking[J]. Acta Acustica, 2013,38(2):224-230. (in Chinese)
[11] 徐舜, 陈绍荣, 刘郁林. 基于非线性时频掩蔽的语音盲分离方法[J]. 声学学报, 2007, 32(4): 375-381. DOI:10.3321/j.issn:0371-0025.2007.04.015.
XU Shun, CHEN Shaorong, LIU Yulin. Blind speech source separation via nonlinear time-frequency masking[J]. Acta Acustica, 2007, 32(4): 375-381. DOI:10.3321/j.issn:0371-0025.2007.04.015.(in Chinese)
[12] SCHMIDHUBER J. Deep learning in neural networks: an overview[J]. Neural Netw, 2014, 61: 85-117. DOI:10.1016/j.neunet.2014.09.003.
