基于关联规则的运动训练生化指标数据挖掘系统设计
2018-04-04张辉
张辉
摘 要: 传统数据挖掘系统存在挖掘速率慢、时间长、数据可靠度低等问题,无法达到运动训练生化指标精准数据挖掘的标准,为此,对基于关联规则的运动训练生化指标数据挖掘系统进行设计。采用三层结构B/S模式,将后台的数据库存储以及挖掘的数据作为参考,设计系统硬件框架;选取数据并对数据进行预处理,采用关联规则数据挖掘算法完成系统软件部分设计;进行实验,验证系统设计的合理性。实验结果表明,该系统数据挖掘速率快、耗费时间短、可信度高,为运动生化指标数据挖掘提供了更加合理的评定标准。
关键词: 关联规则; 运动训练; 生化指标; 数据挖掘; B/S模式; 数据可靠度
中图分类号: TN02?34; G80?32 文献标识码: A 文章编号: 1004?373X(2018)07?0183?04
Design of association rules based data mining system
for exercise training biochemical indexes
ZHANG Hui
(Xinlian College of Henan Normal University, Zhengzhou 450000, China)
Abstract: The traditional data mining system has the problems of slow mining speed, long mining time and low data reliabi?lity, and can′t reach the accurate data mining for biochemical indicators of exercise training. Therefore, an association rule based data mining system of exercise training biochemical indexes was designed. The three?layer B/S mode is adopted to design the system hardware framework by storing the background database and taking the mined data as a reference. The data is selected for preprocessing. The data mining algorithm based on association rules is used to design the system software. The experiment was performed for the system to verify the rationality of the system design. The experimental results show that the data mining system has fast mining rate, short time consumption and high reliability, and provides a more reasonable evaluation standard for the data mining of sports biochemical indexes.
Keywords: association rule; exercise training; biochemical indicator; data mining; B/S mode; data reliability
0 引 言
隨着数据库技术的突飞猛进,人们对于数据的获取途径越来越多,人类所拥有的数据也急剧增加,但是对于数据的分析与处理方式却很少,人们通过数据而获取的信息仅仅占整个系统所有信息中较小的一部分,隐藏在数据之后的是更加重要的特征以及未来的发展趋势,这些信息在决策过程中具有重要意义。数据挖掘能够给决策者带来重要的参考价值,进而产生不可估量的效益,成为运动竞赛的关键环节。但是传统的数据挖掘系统存在挖掘速率慢、时间长、数据可靠度低等问题,无法满足运动训练生化指标精准数据挖掘的标准。
针对该问题,对基于关联规则的运动训练生化指标数据挖掘系统进行设计。实验结果表明,该系统数据挖掘速率快、耗费时间短、可信度高,为运动生化指标数据挖掘提供了更加合理的评定标准,也为今后的训练方案提供了依据。
1 数据挖掘系统设计
1.1 系统结构和功能框架设计
基于关联规则的运动训练生化指标数据挖掘系统结构与功能框架的设计需要建立一个分布式的数据挖掘平台,关联规则集成数据库、数据挖掘的模型以及知识挖掘表达等功能。该系统选择将数据仓库中的数据作为挖掘的对象,并采用关联规则原理和方法提取拓扑关系的信息,使用具体数据模型进行处理与挖掘,根据图形结果的表达来探询关联规则的内在信息,通过传统分析功能获取抽象规则[1]。
为了满足该系统的需求,采用三层结构的B/S模式,将后台的数据库存储以及挖掘的数据作为参考,将关联规则的数据引擎SDE作为连接器[2]。在该应用服务器上与相应的数据进行配置,并将数据挖掘的客户端与文件和描述文件存放在服务器上,使多个客户机能同时访问Web页面,并激发下载与之相关的数据挖掘客户端。该系统功能框架主要由以下三部分构成,如图1所示。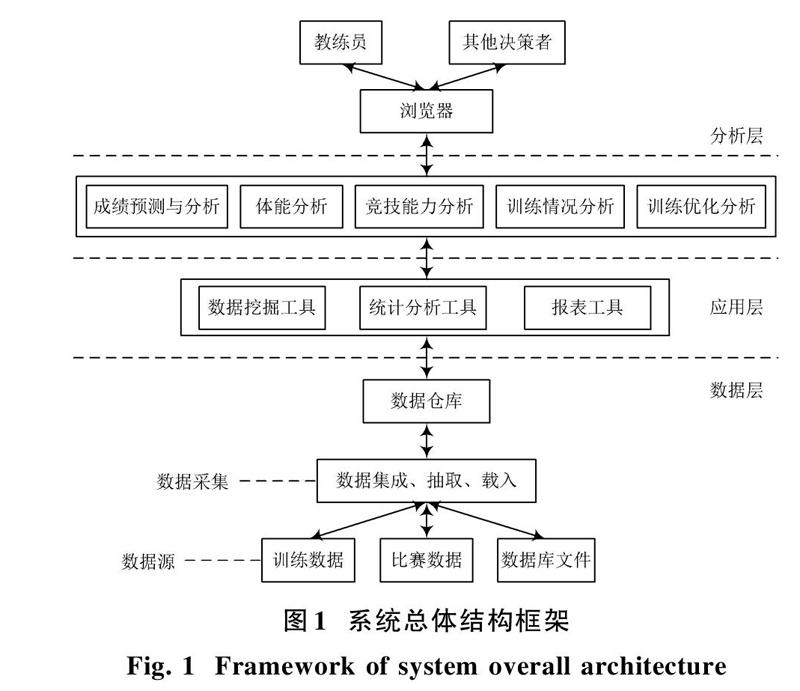
由图1可知:基于关联规则的运动训练生化指标的数据管理和人机交互模块是整个系统的核心模块,采用ArcSDE完成数据挖掘的信息抽取,而模块中的组件用于对原始数据挖掘,其中,应用层Web的服务器负责接收教练员、训练中心和体育局的决策人员经过浏览器发送的请求,然后根据数据库服务器获取的数据再传送回浏览器[3],进而实现系统框架的设计。
1.2 数据挖掘系统模块设计
运动训练生化指标数据挖掘对运动员来说具有重大意义,也是关注的焦点。
1.2.1 数据选取
从数据库中选择运动训练的生化指标,主要包括:血色素(HB)、血肌酸激酶(CK)、血尿素氮(BUN)以及睾酮(T),除去性别与年龄[4],原始数据如表1所示。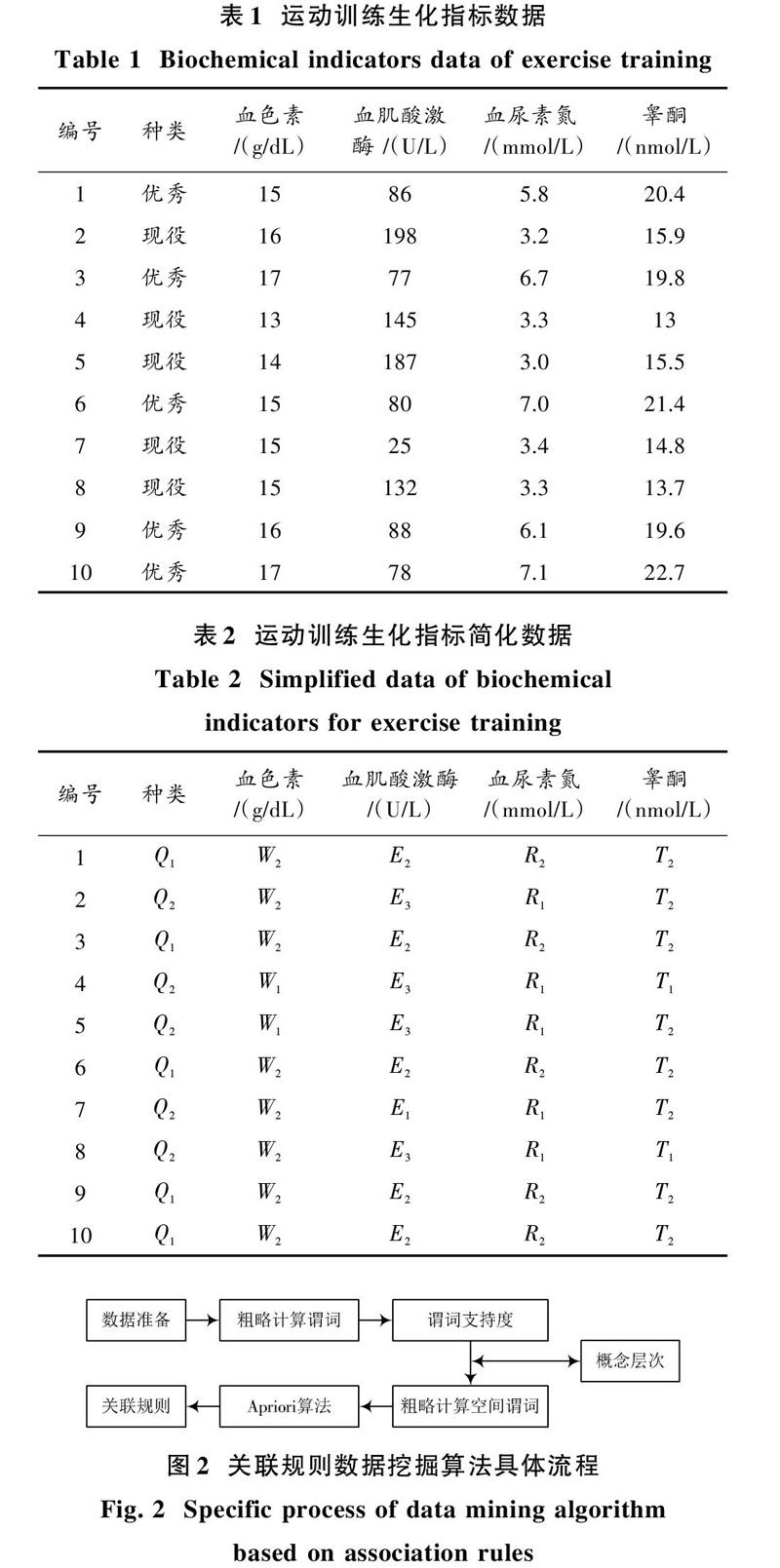
1.2.2 数据预处理
对数据进行预处理时,需要将大量具有属性指标的数据进行记录,假设考虑每一个指标,那么就会存在以下问题:指标多、无代表性;指标存在不同程度的关联性,容易造成数据维数祸害而导致数据挖掘效率降低[5]。主成分分析方法能够将这类指标的维数降低,通过综合指标表示原有的指标,并将复杂指标简化为简单的综合指标[6],如表2所示。
) 经过对数据的查询与分析,需要将目标有关的对象与参照集合共同收集到数据库当中[7]。数据库中的关联规则[X?Y,]所有事物所包含的百分比称之为[X?Y]的期望置信度[8];将置信度与期望的置信度进行对比,获取兴趣度[(f)]为:
[f=置信度X?Y期望置信度X?Y] (1)
兴趣度能度量所有事物所包含的[X,Y]相关度。
2) 在粗略层次上进行谓词计算,将目标设定为最小的限定矩形,抽取距离落在预定阈值之内作为对象,将对象关系的谓词存储在数据库当中,属性值被设定为单个值或一组值。
3) 不同谓词具有不同的支持度,即:
[支持度X,Y=f×支持度X×支持度Y] (2)
将支持度较小的阈值排除,进而形成常用数据库。
4) 在常用数据库中执行准确的空间计算,采用MBR技术对谓词之间的关系进行检查,排除掉与实际不符合的谓词关系,进而形成拓扑数据表,由此计算谓词的支持度,排除支持度较小的项目进而形成最优的数据库[9?10]。
5) 对步骤4)的拓扑关系进行概化,形成新的拓撲关系数据表,进而完成对数据的挖掘。
2 实 验
为了验证基于关联规则的运动训练生化指标数据挖掘系统设计的合理性,进行了如下实验。首先需要对实验参数进行设置,选取某体育学院50名学生运动训练的生化指标:血色素(HB)、血肌酸激酶(CK)、血尿素氮(BUN)以及睾酮(T),在GoogleAppEngine平台上进行数据挖掘,将数据集作为输入的标准,根据不同的数据量分成5组,分别在传统和基于关联规则的数据挖掘设计的系统上进行数据挖掘,以此验证该系统设计的合理性。
2.1 数据挖掘速率结果与分析
对50名学生的训练生化指标数据进行分组,共分为5组,分别在传统数据挖掘系统与基于关联规则的数据挖掘系统进行实验,并记录数据挖掘所耗费的时间,结果如表3所示。
由表3可知:当数据采集量为2 000时,传统数据挖掘系统所耗费的时间为8.25 s,而基于关联规则数据挖掘系统所耗费的时间为2.31 s;当数据采集量为10 000时,传统数据挖掘系统所耗费的时间为821.45 s,而基于关联规则数据挖掘系统所耗费的时间为65.78 s;当数据采集量为18 000时,传统数据挖掘系统所耗费的时间为2 015.68 s,而基于关联规则数据挖掘系统所耗费的时间为91.65 s。明显看出,传统数据挖掘系统所耗费的时间较长。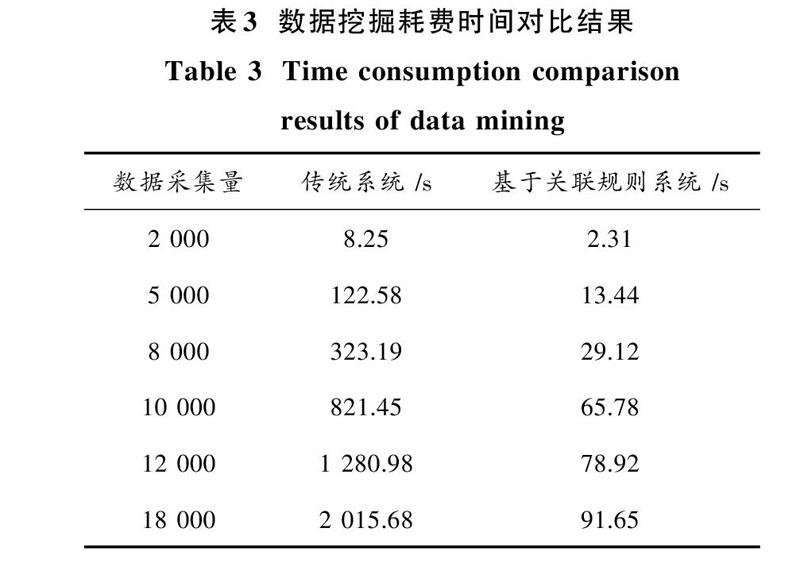
根据数据挖掘系统所耗费的时间绘制两种系统进行数据挖掘时所运行的速率,结果如图3所示。
由图3可知:基于关联规则的运动训练生化指标数据挖掘系统的速率明显比传统数据挖掘速率要快,且随着数据采集量的增加,该系统数据挖掘速率优势更加明显;而传统的数据挖掘系统存在不能对大数据进行快速分析等问题,导致大量数据积压,不能及时处理,进而降低了系统挖掘数据的速率。
2.2 数据挖掘的可信度结果与分析
基于本文采用的关联规则算法对运动训练生化指标的数据挖掘,从表2中选取支持度为20%的频繁1项,由频繁1项按照步骤进行挖掘,选取可信度为70%的进行挖掘,挖掘结果如表4所示。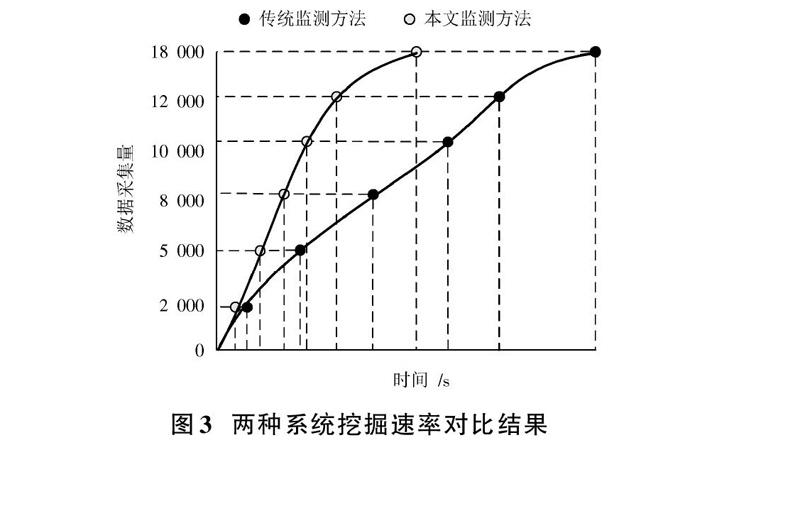
根据表4中第2个规则说明了血色素(HB)指标大小范围在13~17 g/dL的运动员可信度为77.9%;第4个规则说明了血色素(HB)指标大小范围在14~18 g/L的运动员可信度为82.1%;第6个规则说明了血肌酸激酶(CK)指标大小范围在50~130 U/L的运动员可信度为85%;对于其他运动员来说,血肌酸激酶(CK)大小为[80~150 U/L]的运动员的可信度为100%。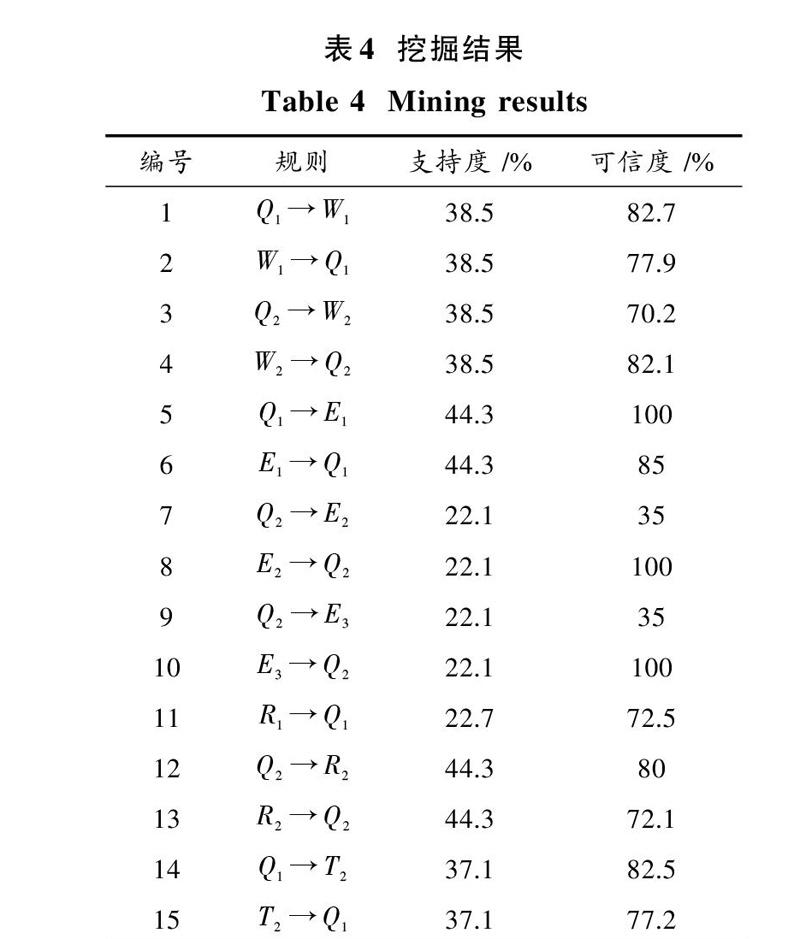
基于关联规则的运动训练生化指标数据挖掘系统的设计对数据挖掘的可信度较高,能够为运动训练模式与训练计划的制定提供依据。
2.3 实验结论
根据上述实验内容得出实验结果:基于关联规则的运动训练生化指标数据挖掘系统的速率明显比传统数据挖掘速率要快,且随着数据采集量的增加,该系统数据挖掘速率优势更加明显;而传统的数据挖掘系统存在不能对大数据进行快速分析等问题,导致大量数据积压,不能及时处理,进而降低了系统挖掘数据的速率。而且该系统对数据挖掘的可信度较高,能够为运动训练模式与训练计划的制定提供依据。
3 结 语
为了能够更好地为运动項目提供决策,针对关联规则的数据挖掘研究进行了深入的分析与设计,将各种指标因素与成绩好坏的关系结合起来,在关联规则数据挖掘算法的分析基础上,制定更加合理的科学评价方法,为运动生化指标数据挖掘提供更加合理的评定标准,也为今后的训练方案提供了依据。
参考文献
[1] 李悦,孙健,邱志祺.基于关联规则的数据挖掘技术的研究与应用[J].现代电子技术,2016,39(23):121?123.
LI Yue, SUN Jian, QIU Zhiqi. Application and research on data mining technology based on association rules [J]. Modern electronics technique, 2016, 39(23): 121?123.
[2] 唐晓东.基于关联规则映射的生物信息网络多维数据挖掘算法[J].计算机应用研究,2015,32(6):1614?1616.
TANG Xiaodong. Biological information network multidimensional data mining algorithm based on association rules mapping [J]. Application research of computers, 2015, 32(6): 1614?1616
[3] 谢修娟,莫凌飞,朱林.基于关联规则的滥用入侵检测系统的研究与实现[J].现代电子技术,2017,40(2):43?47.
XIE Xiujuan, MO Lingfei, ZHU Lin. Research and implementation of misuse intrusion detection system based on association rules [J]. Modern electronics technique, 2017, 40(2): 43?47.
[4] 徐开勇,龚雪容,成茂才.基于改进Apriori算法的审计日志关联规则挖掘[J].计算机应用,2016,36(7):1847?1851.
XU Kaiyong, GONG Xuerong, CHENG Maocai. Audit log association rule mining based on improved Apriori algorithm [J]. Journal of computer applications, 2016, 36(7): 1847?1851.
[5] 王宏,于勇,印璞,等.基于关联规则的MBD数据集定义研究与实现[J].北京航空航天大学学报,2015,41(12):2377?2383.
WANG Hong, YU Yong, YIN Pu, et al. Research and implementation of MBD dataset definition based on association rules [J]. Journal of Beijing University of Aeronautics and Astronautics, 2015, 41(12): 2377?2383.
[6] 林颖华,陈长凤.基于关联规则的企业财务风险评价研究[J].会计之友,2017,22(1):32?35.
LIN Yinghua, CHEN Changfeng. Research on enterprise financial risk assessment based on association rules [J]. Friends of accounting, 2017, 22(1): 32?35.
[7] 梁路,王彪,王剑辉.一种结合OCAT逻辑方法的细粒度的关联规则数据挖掘[J].小型微型计算机系统,2015,36(12):2667?2670.
LIANG Lu, WANG Biao, WANG Jianhui. A fine?gained association rule data mining based on OCAT logical method [J]. Journal of Chinese computer systems, 2015, 36(12): 2667?2670.
[8] 王文槿,刘宝旭.一种基于关联规则挖掘的入侵检测系统[J].核电子学与探测技术,2015,21(2):119?123.
WANG Wenjin, LIU Baoxu. Association rule?based network intrusion detection system [J]. Nuclear electronics & detection technology, 2015, 21(2): 119?123.
[9] 邹元君,姜彤伟.基于改进关联规则的图像挖掘技术研究[J].现代电子技术,2017,40(16):109?111.
ZOU Yuanjun, JIANG Tongwei. Research on image mining technology based on improved association rules [J]. Modern electronics technique, 2017, 40(16): 109?111.
[10] 周芳.基于关联规则Apriori算法的物联网海量数据挖掘系统研究[J].河北北方学院学报(自然科学版),2015,32(1):15?18.
ZHOU Fang. Mass data mining system for Internet of Things based on association rules Apriori algorithm [J]. Journal of Hebei North University (natural science edition), 2015, 32(1): 15?18.
