基于排列熵与IFOA-RVM的汽轮机转子故障诊断
2018-03-28石志标曹丽华东北电力大学机械工程学院吉林30东北电力大学能源与动力工程学院吉林30
石志标, 陈 斐, 曹丽华(.东北电力大学 机械工程学院,吉林 30; .东北电力大学 能源与动力工程学院,吉林 30)
汽轮机转子是机械设备中重要零部件,在实际运行中,转子通过高频振动传感器来进行状态信息的监测。由于转子在高温、高压、疲劳等复杂工况下运行,其故障特征往往会被强背景噪声所淹没,影响诊断结果。因此,在复杂环境下实现精准、快速的故障识别对汽轮机转子故障诊断具有十分重要的意义[1-3]。
排列熵[4]作为一种检测信号复杂程度和随机程度的方法,其对非平稳、非线性信号的变化非常敏感。由于自适应完备的集合经验模态分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN)分解得到的固有模态分量(Intrinsic Mode Function,IMF)包含不同复杂程度的故障特征信息,因此可以计算其排列熵值作为故障特征向量。相关向量机(Relevance Vector Machine,RVM)作为一种智能识别器目前已在手写数字识别[5]、电力负荷预测[6]、故障检测[7-8]、医疗[9-10]、数字图像处理[11]等领域得到了广泛的应用,但在汽轮机转子故障诊断方面应用较少。RVM算法相比支持向量机(Support Vector Machine,SVM)算法具有更好的稀疏性和泛化能力,且不需要对惩罚因子进行设置,不需要设置超参数,并且核函数的选择不受Mercer条件的限制,对小样本具有很好的分类效果[12]。但是由于其核函数学习过程中易陷入局部最优,核参数的选取缺乏理论依据指导,对故障诊断识别结果和识别效率造成影响。基于此,提出一种基于排列熵与IFOA-RVM的汽轮机转子故障诊断方法。采用CEEMDAN与排列熵构建特征样本集;利用结构简单,全局寻优能力高的IFOA算法对RVM核参数进行优化;建立“二叉树”IFOA-RVM分类器,将得到的特征样本集输入到“二叉树”IFOA-RVM分类器进行转子故障诊断。
1 基本原理
1.1 “二叉树”相关向量机
针对多分类问题,相关向量机[13-14]一般有“一对一”方法、“一对多”方法、“二叉树”方法和“有向无环图”法。“一对一”方法对于类别较多的故障,会导致分类器个数增多而产生分类速度下降。“一对多”方法要将多分类归为一个大类,导致训练时间过长且易产生测试误差。“有向无环图”中节点顺序的排列对分类结果的影响很大,具有局限性。“二叉树”算法由于其需要的训练样本少,分类速度比其他方法要快。故选用“二叉树”RVM算法。
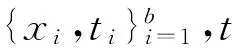
(1)
式中:K(x,xi)表示核函数,wi表示权值。
整个数据样本集的似然函数表示为
(2)
式中:ci=y(xi,w)+εi,
η(xi)=[1,k(xi,x1),k(xi,x2),…,k(xi,xn)]
虽然在贝叶斯学习理论下,通过极大似然法可以获得权值w,但为保证获得稀疏性模型,避免产生过适应,RVM通过高斯先验概率分布定义权重
(3)
式中:α表示N+1维超参数
令式(2)中B=[η(x1),η(x2),…,η(xn)],则分类器可以表示为
(4)
1.2 改进的果蝇算法
2011年台湾学者潘文超提出一种基于果蝇觅食行为推演出寻求全局优化的新方法:果蝇优化算法(Fruit Fly Optimization Algorithm,FOA)[15]。果蝇优化算法的基本理论为:① 果蝇群体利用其嗅觉来判别食物的位置方向;② 然后根据味道浓度确定食物的准确位置,从而完成果蝇迭代寻优过程。FOA具有结构简单、计算量少、参数易调节和寻优精度高等优点,但是FOA也存在一定的缺点,易陷入局部收敛,导致过早的收敛,使收敛精度降低。改进的果蝇优化算法(Improvement of Fruit Fly Optimization Algorithm,IFOA)[16]是针对FOA存在的缺点所提出的。
其基本思想和步骤如下:
步骤1 确定果蝇算法的基本参数。
步骤2 初始化果蝇个体的飞行方向和位置,通过设置可调参数increase与decrease用于增大和缩小果蝇群体的搜寻范围。
步骤3 计算果蝇个体与初始位置的距离和味道浓度判定值。
步骤4 代入适应度函数计算果蝇个体此时的味道浓度值。
步骤5 保留味道浓度最大(小)的位置并进行记录。
步骤6 进入迭代寻优阶段,当第一次迭代时,增大果蝇个体的搜寻范围,参数increase>1,重复步骤2~5,将味道浓度值与前一迭代获得的味道浓度值进行比较,如果优于前一代,执行步骤6,反之执行步骤2进行下一次迭代,直至满足最大迭代次数maxgen/2结束;进入第二寻优阶段,减小果蝇个体搜寻范围,参数decrease<1,重复执行步骤2~5,将味道浓度值与前一迭代获得的味道浓度值进行比较,如果优于前一代,执行步骤6,反之执行步骤2进行下一次迭代,直至满足最大迭代次数maxgen时结束。
1.3 排列熵基本原理
排列熵(Permutation Entropy,PE)是Bandt等提出的一种检测信号复杂性和随机性的方法,排列熵具有很好的抗噪能力,且对于非平稳、非线性信号的变化非常敏感,因此广泛应用于非线性数据的处理。
排列熵依据Shannon熵的形式定义为
(5)
当Pg=1/m时,取得最大值为Hp(m),利用In(m!),将排列熵进行归一化处理,即:
Hp=Hp(m)/In(m!)
(6)
处理后排列熵的取值范围是0≤Hp≤1,其值的大小代表时间序列的不规则程度。值越小,说明时间序列越稳定,越规则,反之,则说明时间序列越复杂。
2 实验研究
2.1 故障数据获取
采用ZT-3转子振动实验台模拟汽轮机转子常见故障实验,获得转子不对中、碰磨、不平衡的故障振动信号以及正常状态下的振动信号。实验台选用直流并励电动机驱动方案,电动机通过联轴器对转子进行直接驱动,电动机的额定电流为2.5 A,输出功率250 W。调速器可使电动机在0~10 000 r/min范围内进行无级调速。通过光电传感器来计量转速。采用φ8 mm电涡流传感器把模拟实验所得的振动信号转换成电信号,每个转子在水平和垂直方向上各安装一个测点。采用阿尔泰USB5936的数据采集器将电信号通过A/D转换器变成计算机能够处理的数字信号。最后通过计算机软件进行数据信号的采集。
设置采样频率为5 000 Hz,采样个数为100 000个。实验装置如图1所示。

图1 转子数据采集实验装置
为了使实验更接近实际工况,对采集信号加入高斯白噪声来模拟现场背景噪声。得到的时域信号如图2所示。
2.2 基于“二叉树”IFOA-RVM故障诊断
基于“二叉树”IFOA-RVM故障诊断的基本步骤如下:
步骤1 基于奇异值去噪的数据预处理;
步骤2 CEEMDAN与排列熵构造故障特征样本集;
步骤3 “二叉树”IFOA-RVM分类器进行故障识别。
2.2.1 基于奇异值去噪的数据预处理
为了避免奇异样本数据的出现和后续数据方便处理,对转子振动信号进行归一化处理,使得所有样本的输入信号服从标准正态分布。然后,对时间序列进行相空间重构,采用C-C算法[17]来确定相空间重构最优的嵌入维数m和最佳延迟时间τ。对重构后的相空间进行奇异值去噪[18]。对转子振动信号进行奇异值去噪的流程如图3所示。

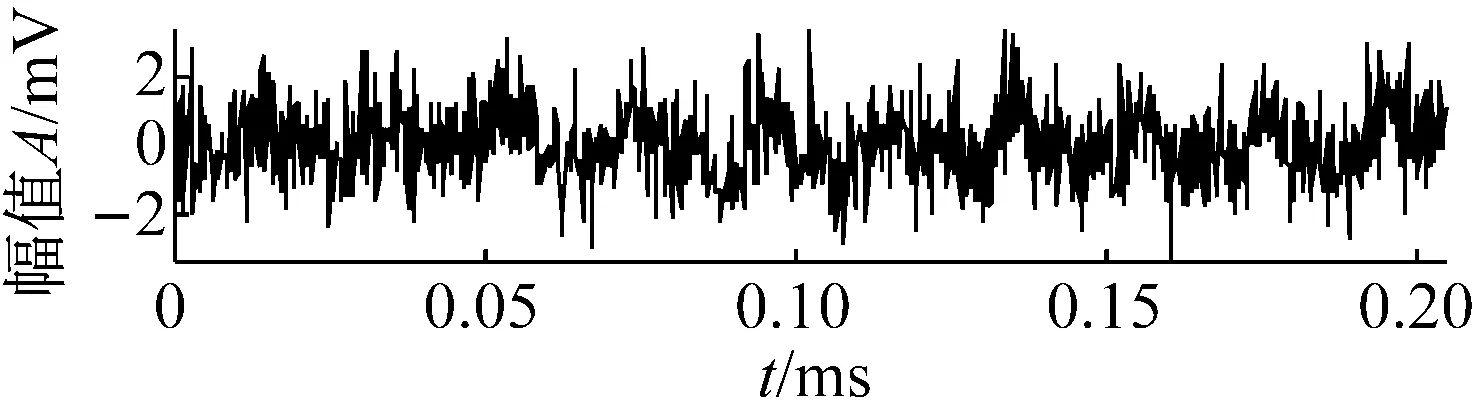


图2 振动信号时域图
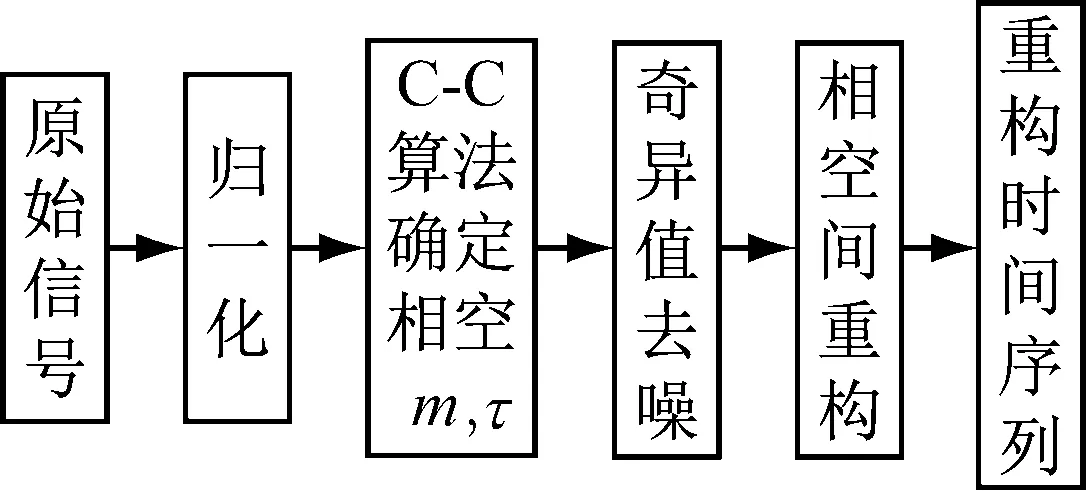
图3 去噪流程图
通过信噪比改善量ΔSNR(Signal Noise Ratio,SNR)[19]表示信号的去噪效果,正常状态、不对中、不平衡、碰磨去噪后,信噪比分别为:18.763 0 dB、19.587 3 dB、21.745 5 dB、19.757 3 dB。
2.2.2 基于CEEMDAN与排列熵的故障样本集构造方法
自适应完备的集合经验模态分解[20]是为了抑制经验模态分解(EMD)发生模态混叠现象所提出的一种自适应处理非线性非平稳性振动信号的数据预处理方法。这种方法是通过在分量分解的每一阶段自适应添加高斯白噪声,由唯一的余量信号来获得各个IMF。转子不对中故障振动信号CEEMDAN分解图如图4所示。
图4中:C6为二倍频即转子不对中的主要故障特征频率,C5、C7分别为转子不对中的三倍频、一倍频即转子不对中故障的常伴频率,准确的反应了转子的故障频率特性。根据转子故障特征机理和相关性分析,选取故障特征敏感的IMF分量组成相应的倍频,计算其排列熵,经主成分分析降维后作为IFOA-RVM分类模型的输入向量。表1为4种转子振动信号所得的一部分排列熵值。







时间t/ms
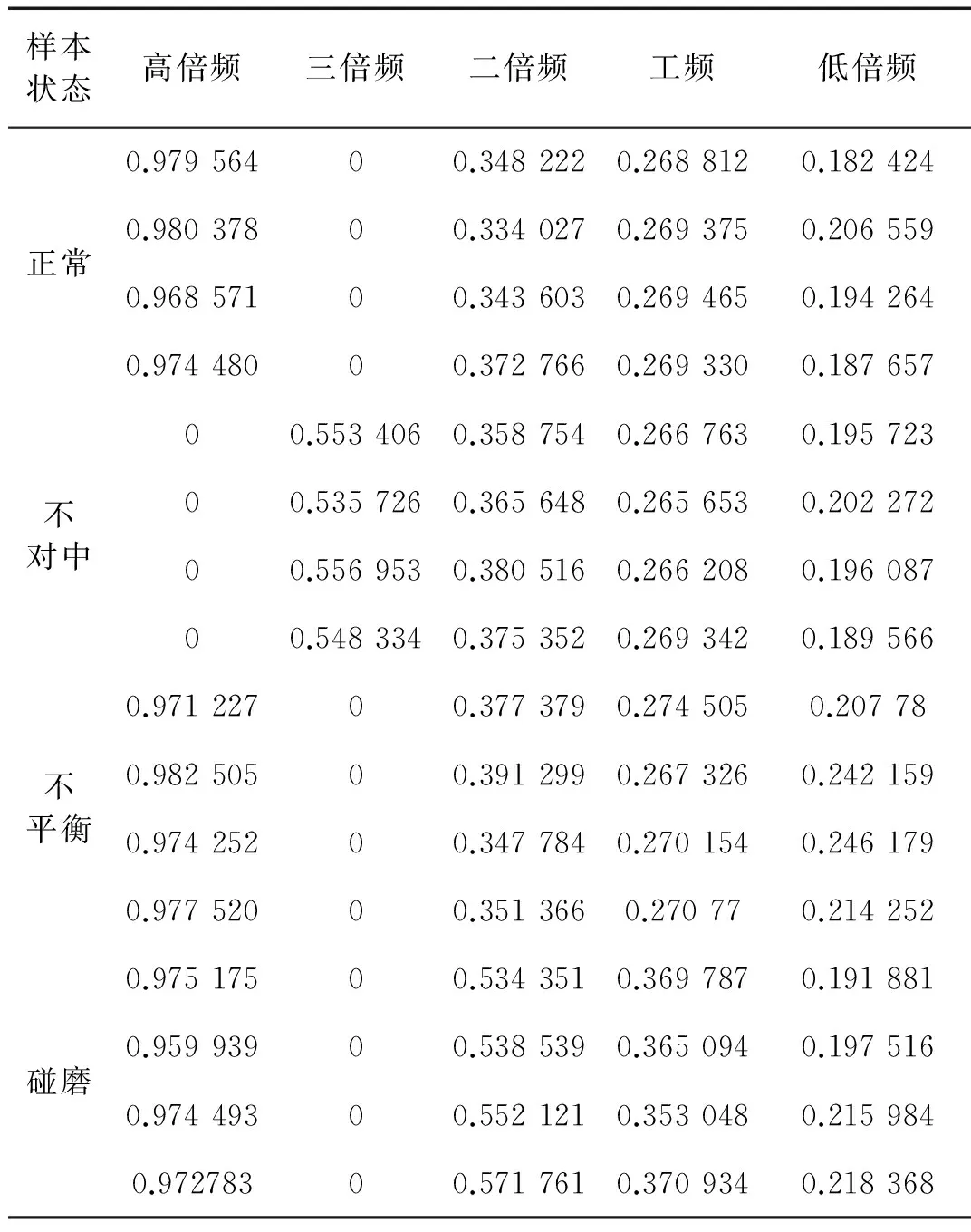
样本状态高倍频三倍频二倍频工频低倍频正常不对中不平衡碰磨0.97956400.3482220.2688120.1824240.98037800.3340270.2693750.2065590.96857100.3436030.2694650.1942640.97448000.3727660.2693300.18765700.5534060.3587540.2667630.19572300.5357260.3656480.2656530.20227200.5569530.3805160.2662080.19608700.5483340.3753520.2693420.1895660.97122700.3773790.2745050.207780.98250500.3912990.2673260.2421590.97425200.3477840.2701540.2461790.97752000.3513660.270770.2142520.97517500.5343510.3697870.1918810.95993900.5385390.3650940.1975160.97449300.5521210.3530480.2159840.97278300.5717610.3709340.218368
由表1可以看出正常状态下,高倍频排列熵值高于工频状态下的排列熵值,这是因为高倍频部分时间序列比较复杂,不具有完全周期性,随机性大,而工频状态下时间序列较规则,具有周期性。由排列熵的定义可知:时间序列的不规则程度越大则排列熵值越大,时间序列越规则排列熵值越小。因此高倍频下排列熵值大,而工频下排列熵值小。
2.2.3 基于“二叉树”IFOA-RVM的故障识别
(1) 基于IFOA优化RVM核参数
RVM常用的核函数有:线性核函数,多项式核函数,高斯核函数,Sigmoid核函数和复合核函数。通过对比分析,高斯核函数具有结构简单,泛化性能力好的优点。故采用高斯核函数。同时为了避免其学习过程中陷入局部最优,拟采用结构简单,全局优化能力强的IFOA算法对高斯核函数核参数进行迭代优化,得到最优核参数。文献[21]中也说明了核参数的优化对RVM分类结果具有的重要的影响。IFOA优化RVM核参数的流程如图5所示。

图5 IFOA优化RVM核参数的流程图
(2) 构建“二叉树”RVM模型
由于的转子特征样本有转子不平衡,不对中,碰磨及正常4种,针对该问题,设置4个“二叉树”RVM二分类器,按照如图6所示的方式进行排列组合,输入多种故障测试样本时,通过第一个RVM分类器时,如果输出的结果为1,则为正常,同时这类故障诊断结束,如果输出结果为0,则进行第二个RVM分类器的诊断,逐个进行,直至分类结束。因此“二叉树”RVM可以解决多种类的转子故障诊断问题。

图6 “二叉树”RVM分类图
2.3 结果与讨论
通过CEEMDAN与排列熵得到转子不对中,碰磨,不平衡及正常状态下的特征样本集各90组,选取其中45组作为训练样本集,45组作为测试样本集。为了验证IFOA算法的性能,分别用FOA-RVM、IFOA-RVM对特征样本进行识别。运用训练数样本集分别通过IFOA、FOA算法优化相关向量机核参数得到最优核参数。构建IFOA-RVM、FOA-RVM分类模型,以建立正常状态下的分类器为例,IFOA、FOA优化RVM核参数的适应度曲线及对应的核参数值如图7所示。
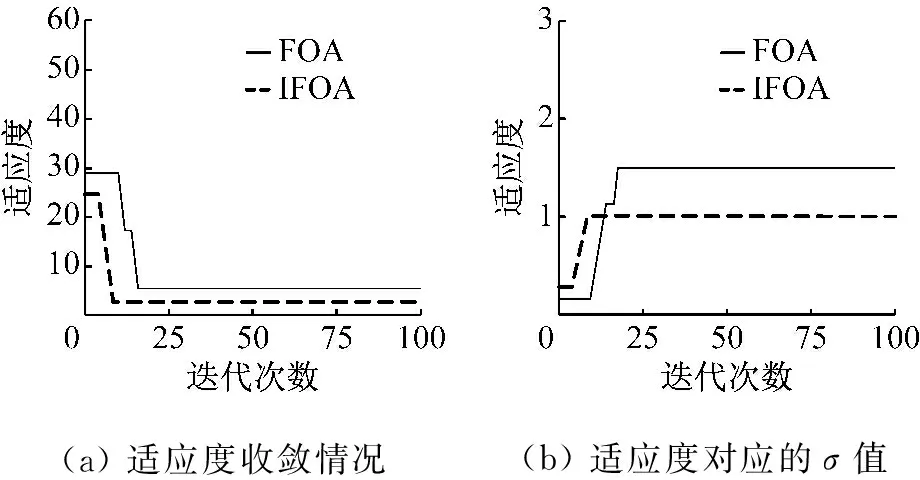
(a)适应度收敛情况(b)适应度对应的σ值
图7 100代适应度曲线及对应的σ值
Fig.7 100 generation fitness curves and the corresponding values
由图7可知,在种群数量、迭代次数和故障数据相同的前提下,FOA算法在9代到达第一个局部最优解,之后在第13代,15代等多次跳出局部最优,但适应度曲线较为曲折。IFOA算法第8代就达到了全局最优值一样的适应度(2.3),虽然IFOA在第5代进入局部最优值,但IFOA能成功跳出。而且在整个收敛过程中IFOA适应度曲线阶梯更少,说明在寻优过程中IFOA不容易陷入局部最优。与FOA方法相比,IFOA在收敛速度和参数最优值方面都能达到较为理想的程度。
根据训练所获得的不同最优核参数,构建4个RVM分类模型,将故障特征样本集输入“二叉树”RVM分类器进行故障分类识别。为了验证排列熵能够得到较高质量的特征样本集与模糊熵进行对比。以RVM1分类模型为例,图8、图9分别为排列熵、模糊熵组成的特征样本集IFOA-RVM1分类结果图。IFOA-RVM分类器与FOA-RVM分类器以及由网格寻优算法优化的SVM分类器的故障识别结果与所运行时间如表2,3所示。

(a)排列熵IFOA-RVM训练模型(b)排列熵IFOA-RVM测试结果

图8 排列熵IFOA-RVM分类图
图9 模糊熵IFOA-RVM分类图
Fig.9 IFOA-RVM classification of fuzzy entropy
由图8与图9对比可知,排列熵获得的各种故障类型的样本集聚类性好,能够明显区分不同故障,有利于分类器的故障识别;而模糊熵获得的样本集分散程度较大,聚类性较差。因此,排列熵与模糊熵相比能够获得更高质量的特征样本集,在区别转子各种故障类型方面更具优越性。
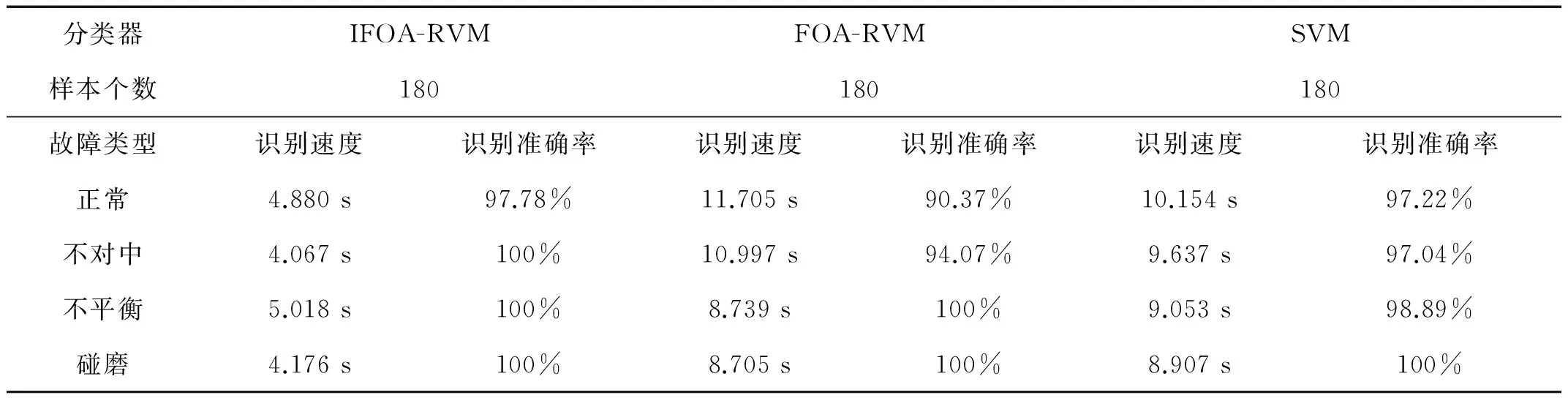
表2 基于排列熵的故障分类结果
通过表2分析:虽然在正常样本故障识别方面,网格寻优算法优化的SVM与IFOA-RVM识别准确率都达到了较高识别准确率,但是在识别速度方面,IFOA-RVM要明显优于FOA-RVM及SVM,且对其它的故障识别率都达到了100%。这说明IFOA优化的RVM识别准确率更高,识别速度更快。

表3 基于模糊熵的故障分类结果
对比表2、3可知,采用排列熵构建的特征样本比模糊熵构建的样本集识别准确率更高,这说明了排列熵在区分转子故障方面具有很好的效果。
综合表2与表3说明了基于排列熵与IFOA-RVM汽轮机转子故障诊断方法的有效性。
3 结 论
(1) CEEMDAN与排列熵构建的转子故障样本集和模糊熵对比,在区别各种故障类型方面更具优越性,因此CEEMDAN与排列熵的故障样本构造方法更适用于转子故障诊断。
(2) 通过分析可知,在实际的RVM优化应用方面IFOA算法其收敛速度和参数最优值方面都明显优于FOA算法。
(3) IFOA-RVM分类器识别准确率和运行时间方面要明显于优于FOA-RVM分类器、网格寻优算法优化的SVM分类器。
[1] 杨宇,王欢欢,喻镇涛,等. 基于ITD改进算法和关联维数的转子故障诊断方法[J]. 振动与冲击,2012, 31(23): 67-70.
YANG Yu, WANG Huanhuan, YU Zhentao, et al. A rotor fault diagnosis method based on ITD improved algorithm and correlation dimension[J]. Journal of Vibration and Shock, 2012, 31(23): 67-70.
[2] 石志标,苗莹. 基于FOA-SVM的汽轮机振动故障诊断[J]. 振动与冲击,2014, 33(22): 111-114.
SHI Zhibiao, MIAO Ying. Vibration fault diagnosis for steam turbine by using support vector machine based on fruit fly optimization algorithm[J]. Journal of Vibration and Shock, 2014, 33(22): 111-114.
[3] 陈向民,于德介,李蓉. 基于信号共振稀疏分解与重分配小波尺度谱的转子碰摩故障诊断方法[J]. 振动与冲击, 2013, 32(13):27-33.
CHEN Xiangmin, YU Dejie, LI Rong. Rub-impact diagnosis of rotors with resonance-based sparse signal decomposition and reassigned wavelet scalogram[J]. Journal of Vibration and Shock, 2013, 32(13): 27-33.
[4] BANDT C, POMPE B. Permutation entropy: a natural complexity measure for time series[J]. Physical Review Letters, 2002, 88(17): 174102(1-4).
[5] 王立昆. 基于RVM的手写体数字识别[D]. 西安:西安电子科技大学,2011.
[6] 段青,赵建国,马艳. 优化组合核函数相关向量机电力负荷预测模型[J]. 电机与控制学报, 2010, 14(6): 33-38.
DUAN Qing, ZHAO Jianguo, MA Yan. Relevance vector machine based on particle swarm optimization of compounding kernels in electricity load forecasting[J]. Electric Machines and Control, 2010, 14(6):33-38.
[7] 易辉, 梅磊,李丽娟,等. 基于多分类相关向量机的水电机组振动故障诊断[J]. 中国电机工程学报,2014, 34(17): 2843-2850.
YI Hui, MEI Lei, LI Lijuan, et al. Vibration fault diagnosis for hydroelectric generating units using the multi-class relevance[J]. Proceedings of the CSEE, 2014, 34(17): 2843-2850.
[8] 王波,刘树林,蒋超,等. 基于量子遗传算法优化RVM的滚动轴承智能故障诊断[J]. 振动与冲击,2015, 34(17): 207-212.
WANG Bo, LIU Shulin, JIANG Chao, et al. Rolling bearings’ intelligent fault diagnosis based on RVM optimized with Quantum genetic algorithm[J]. Journal of Vibration and Shock, 2015, 34(17): 207-212.
[9] 姚畅, 陈后金,YANG Yongyi,等. 基于自适应核学习相关向量机的乳腺X线图像微钙化点簇处理方法研究[J]. 物理学报,2013, 62(8): 088702(1-11).
YAO Chang, CHEN Houjin, YANG Yongyi, et al. Microcalcification clusters processing in mammograms based on relevance vector machine with adaptive kernel learning[J]. Acta Physica Sinica, 2013, 62(8): 088702(1-11).
[10] LIMA C A M, COELHO A L V, CHAGAS S. Automatic EEG signal classification for epilepsy diagnosis with relevance vector machines[J]. Expert Systems with Applications, 2009, 36(6): 10054-10059.
[11] 金理钻,屠珺,刘成良. 基于迭代式RELIEF和相关向量机的黄瓜图像识别方法[J]. 上海交通大学学报,2013, 47(4): 602-606.
JIN Lizuan,TU Jun,LIU Chengliang. A method for cucumber indentification based on iterative-RELIEF and relevance vector machine[J]. Journal of Shanghai Jiaotong University, 2013, 47(4): 602-606.
[12] 柳长源. 相关向量机多分类算法的研究与应用[D]. 哈尔滨: 哈尔滨工程大学,2013.
[13] TIPPING M E. The relevance vector machine[J]. Neural Networks & Machine Learning, 1999, 1(3): 652-658.
[14] TIPPING M E. Sparse Bayesian learning and the relevance vector machine[J]. Journal of Machine Learning Research, 2001, 1(3): 211-244.
[15] PAN W T. A new fruit fly optimization algorithm: taking the financial distress model as an example[J]. Knowledge-Based Systems, 2012, 26(2): 69 -74.
[16] 徐富强, 陶有田,吕洪升. 一种改进的果蝇优化算法[J]. 苏州大学学报(自然科学版),2014, 29(1): 16-23.
XU Fuqiang, TAO Youtian, LÜ Hongsheng. Improved fruit fly optimization algorithm[J].Journal of Soochow University(Natural Siencei Edition), 2014, 29(1): 16-23.
[17] 徐自励,王一扬,周激流. 估计非线性时间序列嵌入延迟时间和延迟时间窗的C-C平均方法[J]. 四川大学学报(工程科学版),2007, 39(1): 151-155.
XU Zili, WANG Yiyang, ZHOU Jiliu. C-C average method for estimating the delay time and the delay time window of nonlinear time series embedding[J]. Journal of Sichuan University(Engineering Science Edition), 2007, 39(1): 151-155.
[18] WALTON J, FAIRLEY N. Noise reduction in X-ray photoelectron spectromicroscopy by a singular value decomposition sorting procedure[J]. Journal of Electron Spectroscopy and Related Phenomena, 2005, 148(1): 29-40.
[19] 侯平魁,龚云帆,杨毓英,等.水下目标辐射噪声时间序列的非线性降噪处理[J].声学学报,2001, 26(3): 207-211.
HOU Pingkui, GONG Yunfan, YANG Yuying, et al. Nonlinear noise reduction of the underwater target radiated noise time series[J]. Acta Acustica, 2001, 26(3): 207-211.
[20] COLOMINAS M A, SCHLOTTHAUER G, TORRES M E. Improved complete ensemble EMD: a suitable tool for biomedical signal processing[J]. Biomedical Signal Processing & Control, 2014, 14(1): 19-29.
[21] 王波, 刘树林,张宏利,等. 相关向量机及其在机械故障诊断中的应用研究进展[J]. 振动与冲击,2015, 34(5): 145-153.
WANG Bo, LIU Shulin, ZHANG Hongli, et al. Advances about relevance vector machine and its applications in machine fault diagnosis[J]. Journal of Vibration and Shock, 2015, 34(5): 145-153.
