改进的DBSCAN聚类和LAOF两阶段混合数据离群点检测方法
2018-03-28石鸿雁马晓娟
石鸿雁,马晓娟
(沈阳工业大学,沈阳 110870)
1 引 言
离群点[1]检测的目的是在大量的、复杂的数据集合中消除噪声数据或发现潜在有意义的规律.当今人类社会每时每刻都产生大量的数据,这些数据大多同时具有数值属性和分类属性,于是混合属性数据的离群点检测问题便引起了研究学者的关注.聚类和离群点检测紧密相关,DBSCAN聚类算法[2]具有一定的离群处理能力,它可以在较少的先验知识下进行无监督的分类,获得对象有效的聚类结果,而不被聚类的点则是离群点,但其聚类半径ε和参数阈值Minpts设置困难;Breuing等人提出了局部离群因子的概念LOF[3,4],它是基于密度的一种方法,基于密度的局部离群点检测方法[5]不再将离群点看做一个二值属性,而是量化地描述数据对象的离群程度,其能在数据分布不均的情况下准确发现离群点,但由于离群点在数据集中所占的比重较小,直接计算数据对象的离群度会增大计算量;文献[6]提出了FCBOD算法,它是一种能够处理混合属性数据集的离群点检测方法,它将数值属性的质心和分类属性的频率信息作为差异性度量的主要方式,但需要进一步研究新的距离定义来准确度量不同对象间的差异性;Chen[7]等人提出了基于粗糙集理论的混合数据离群点检测算法,首先指定数据对象每个属性的粗糙邻域,再利用属性值的差异性计算对象的离群程度,但该算法的检测效果对人工指定的属性粗糙邻域范围参数非常敏感;针对上述存在的问题,现提出了一种改进的DBSCAN聚类和新局部离群因子LAOF两阶段混合数据离群点检测算法.在第一阶段中对DBSCAN聚类算法设定唯一参数k近邻[8]对数据集进行初步筛选;在第二阶段中由于LOF算法重复计算k距离的计算量较大,因此构造了新的离群因子LAOF度量筛选后数据的异常程度.
2 混合数据对象的距离度量
2.1 除一化信息熵
信息熵[9]可用于度量数据集无序和杂乱的程度.熵值越大,说明数据集无序和杂乱程度越高;反之,说明数据集越有序和纯净.基于此可以通过熵值的变化来确定数据对象的属性权重,突出离群属性.设x为随机变量,其取值集合为s(x),p(x)表示x可能取值的概率,则x的信息熵定义为:
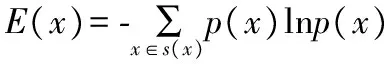
(1)

(2)
(3)
式(3)中Δ(Ai)为集合A除去对象Ai后的信息熵增量,Δ(Ai)越大表示把对象Ai从集合A中除去后使得整个数据集的混乱或不确定性减少得越多.本文则用Δ(Ai)表示属性Ai的权重.
2.2 混合数据加权距离
在混合数据进行距离度量时采用了属性加权距离,提高离群属性在距离度量中的作用.给定混合数据对象p={pi|i∈[1,m]},q={qi|i∈[1,m]},m为属性数,两个对象p,q间的距离dist(p,q)为:
(4)
其中A[i]为属性权重,由于每一个数值属性的取值范围不同,为了防止具有较大初始值域的数值属性与具有较小初始值域的数值属性相比权重过大的情况发生,对于数值属性采用Min-max标准化处理[10],距离度量值为d(pi,qi)=|pi-qi|;
3 改进的聚类和局部离群因子LAOF两阶段算法的介绍
由于混合数据中离群点的个数占总体数据集的比重较小,为了使离群点挖掘更有针对性,首先通过聚类的方法对总体数据集进行初步的筛选.基于密度聚类的方法不需要预先指定聚类的簇数,而且能够在含有噪声的数据集中发现任意数量和形状的簇,DBSCAN是一种经典的基于密度的聚类算法,但该算法需要用户在没有先验知识的情况下设定参数ε和Minpts,参数对于最终聚类结果的质量影响很大,为了克服输入参数的敏感性,采用了输入K近邻代替参数ε和Minpts的方法.在对筛选后的混合数据进行离群点判断时,由于局部离群因子LOF计算复杂且计算量较大,为此构造新的局部离群因子LAOF对筛选后的数据进行异常度的度量.
3.1 DBSCAN输入参数的处理
在DBSCAN算法聚类的过程中我们发现,聚类结果的好坏直接受参数ε和Minpts的影响,参数的确定往往需要专家的分析或大量的实验验证,这样会造成时间的消耗和资源的浪费,为了提高聚类质量降低资源消耗,将k近邻的思想引入到DBSCAN聚类算法中,在计算k距离(k-dist)的同时获取数据集的分布情况,在获得数据集的先验知识时通过分析输入k邻居数代替密度阈值Minpts,并取一定数目数据对象的k-dist来计算均值k-mean代替空间半径ε,减少多参数输入对聚类结果的影响并根据改进的方法对核心点进行了新的定义.数据对象数目的选取根据数据集获取的先验知识确定.
3.2 DBSCAN新核心点的定义
改进前的DBSCAN聚类算法判断核心点的参数需要人为输入,在改进后的聚类算法中则根据计算每个数据对象的K距离有依据性的确定核心点.
定义1.(新的核心对象)对于数据集中任意一个数据对象p∈D,如果p的第k距离k-dist (p)小于k-mean,则p为核心对象.
利用定义1对数据集进行聚类.在对新的核心对象进行判断的过程中设计了以空间换时间的算法,将每个已经计算数据对象的k-dist值保存起来作备用,在算法的执行过程中凡是用到k-dist的地方直接使用预先计算好的值.在该优化中,算法需要增加规模为N的空间存储,而计算数据对象的第k距离邻域时算法需要增加规模为N2级的空间开销,这一步优化可以极大的降低时间复杂度.
3.3 LAOF的定义
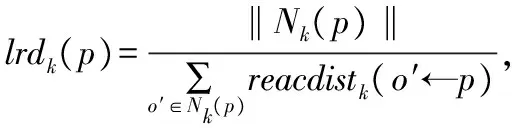
定义2.对象p的局部密度
(5)
对象p的局部密度是在以p为圆心以k-dist(p)为半径的圆面积内,计算单位面积含有数据点的个数,与LOF算法中计算数据对象的局部可达密度相比极大的降低了计算的时间复杂度.
根据LOF算法中局部离群因子求解公式,类推LAOF算法中局部离群因子的计算公式.
定义3.对象p的局部离群因子
(6)
对象p的局部离群因子表示为LA(p)与它的k个邻居局部密度均值比值的倒数.显然p的局部密度越小,p的k个邻居的局部密度均值越大,p的局部异常因子越大,数据对象p的离群程度越高.
3.4 混合数据离群点检测算法的描述
输入数据:数据集D,聚类中最近邻居个数k,计算离群因子邻居个数k1.
输出数据:特定数据对象的离群因子.
a)遍历数据集D,利用加权距离计算每个数据对象p的k-dist(p)和邻域Nk(p).
b)升序排列数据对象的k-dist,选取适当数目数据对象的k-dist,计算这些数据对象k-dist的均值k-mean,根据定义1确定数据集中的核心点.
c)从任意一个核心点出发找出k-mean邻域中所有直接密度可达点,通过直接密度可达点找到密度相连对象集合.递归循环直到没有可以处理的核心对象为止.
d)计算未被聚类的数据对象二次加权距离的k1-dist(p)和邻域Nk1(p).
e)根据新构造的局部异常因子计算每个数据对象的局部密度LA(p).
f)由定义3得数据对象p的LAOF(p)降序排列输出.
3.5 算法的实现流程
第一阶段:利用改进的DBSCAN聚类算法对混合数据做初步的筛选.
Init(char *filename,int k,int t)//读入数据输入K近邻和分类属性;
Shujubiaozhunhua() // 数据集属性预处理
Entropy()// 属性权重除一划处理
DoDBSCANrecursive()//执行聚类操作采用递归的方法
Keypointcluster() //深度优先聚类数据
第二阶段利用新构造的局部离群因子LAOF计算数据对象的离群度
Cin k2// 输入最近邻
Eentropy1()// 二次权重确定
DensityLAOF() //计算筛选后数据的离群度
Writetofile(char *filename) //将已经处理后的结果写入并输出.
4 实验分析
为了检验提出改进的DBSCAN聚类和LAOF两阶段混合数据离群点检测方法的有效性,下面进行性能测试.实验数据来自UCI标准数据库,实验与改进的LOF算法的检测结果进行了比较.所有算法均在VS2010中实现,运行环境为Win7下英特尔酷睿TMi3 3240处理器.由于离群点在数据集中数量较少,所以为了符合数据集的分布规律,故将heart和liverdisorder数据集中某一类的部分对象删除作为离群点.表1为数据集的相关信息描述.
表1 数据集信息描述
Table 1 Information description of data set

数据集样本个数数值属性分类属性类数heart 143762Liverdisorder143512
首先通过改进的DBSCAN算法对上述的数据集进行初步聚类,通过输入不同的k近邻得到不同的聚类结果,表2为聚类结果的详细描述.
通过表2发现k近邻的不同取值直接影响着聚类的个数,本阶段的聚类主要是对数据集做初步的筛选,即把数据集中最为稠密的数据簇去掉并尽可能使待检测数据的数量达到最小,如果邻居数不断增加可能将部分离群点聚类并增大计算量,由此可知当k=8时聚类数目和待检测数据个数均达到最优状态.然后对待检测的数据利用新的局部离群因子LAOF计算每一个数据对象的离群程度,图1和图2显示了当聚类的邻居个数取定时,不同邻居个数k1对LAOF和改进的LOF算法检测精度的影响,在离群点个数固定的情况下检测出真正的离群点占总数的百分比.
表2 聚类结果
Table 2 Clustering results

数据集liverdisorderheartk近邻456789456789聚类数4223221022211待测数938887848282877980716667
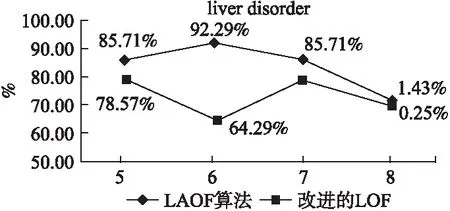
图1 Liver disorder 检测精度对比Fig.1 Comparison of detection accuracy on liver disorder
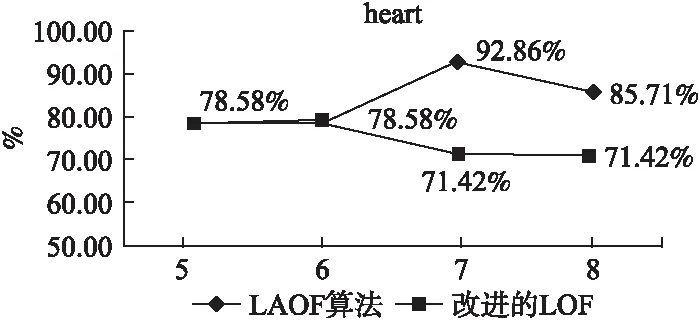
图2 heart 检测精度对比Fig.2 Comparison of detection accuracy on heart
通过图1可以看出在liverdisorder数据集中,当k1取6时检测结果达到最优,在图2中k1=7时检测效果最好.表3为基于聚类和LAOF的离群点检测算法效果最好时参数的取值.
表3 参数的取值描述
Table 3 Parameter value description

数据集聚类k近邻离群点检测k1近邻Heart 87Liverdisorder86
根据图1与图2的检测结果,表4列出了在输出离群因子值最高的前十四个数据对象中,正确找到的离群点占离群点总数的百分比,LAOF算法对数据集的检测精度均达到90%以上与改进的LOF算法相比具有较高的准确率.由此可知该算法能够很好地处理既含有数值属性又含有分类属性的混合数据.
表4 检测结果
Table 4 Detection results

数据集数据集大小异常数据本文算法改进的LOF算法Heart 1431492.86%71.42%liverdisorder1431492.86%64.29%
5 结束语
本文在最近邻的基础上提出了改进的聚类和局部离群因子的两阶段混合数据的离群点检测方法,通过改进的DBSCAN聚类算法对数据集进行预处理,通过输入邻居的个数代替参数ε和Minpts的输入,降低人为因素对聚类结果的影响,进而得到初步的异常数据.通过构造新的局部异常因子LAOF代替LOF计算数据的异常程度降低计算量,在进行距离度量时引入除一化信息熵,并对离群点检测的数据集进行二次权重确定.经过实验验证该算法能够有效提高离群点检测精度,降低计算复杂度.但该算法中参数k值的选取直接影响聚类结果.因此,下一步将研究参数的确定方法,找到能够自动提供合理的参数值的方法.
[1] Han Jia-wei,Micheling Kamber.Data mining concepts and techniques[M].Beijing:Mechanical Industry Press,2014.
[2] An Ji-yong,Han Hai-ying,Hou Xiao-li.An improved DBscan clustering algorithm[J].Microelectronics and Computer,2015,32(7):68-71.
[3] Breuning M,Krigegel H P,Ng R,et al.LOF:identifying density based local outliers[C].Proceeding of the ACM SIGMOD International Conference on Management of Data,Dallas,TX USA,2000:93-104.
[4] Li Lu,Huang Liu-sheng,Yang Wei.Privacy-preserving LOF outlier detection[J].Knowledge and Information Systems,2015,42(3):579-597.
[5] Hu Cai-ping,Qin Xiao-lin.A local outlier detection algorithm based on density DLOF[J].Computer Research and Development,2010,47(12):2110-2116.
[6] Salman Ahmed,Shaikh Hiroyuki Kitagawa.Top-k outlier detection from uncertain data[J].International Journal of Automation and Computing,2014,11(2):128-142.
[7] Chen Yu-min,Miao Duo-qian,Zhang Hong-yun.Neighborhood outlier detection [J].Expert Systems with Applications,2010,37(12):8749-8750.
[8] Wang Qian,Liu Shu-zhi.Improvement of local outlier mining method based on density [J].Computer Application Research,2014,31(6):1693-1696.
[9] Wang Jing-hua,Zhao Xin-xiang,Zhang Guo-yan.NLOF:a new local outlier detection algorithm based on density [J].Computer Science,2013,40(8):181-185.
[10] Gautam Bhattacharya,Koushik Ghosh,Ananda S.Chowdhury.Outlier detection using neighborhood rank difference[J].Pattern Recognition Letters,2015,60(4):24-31.
附中文参考文献:
[1] Jiawei Han,Micheling Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2014.
[2] 安计勇,韩海英,侯效礼.一种改进的DBscan聚类算法[J].微电子学与计算机,2015,32(7):68-71.
[5] 胡彩平,秦小麟.一种基于密度的局部离群点检测算法DLOF[J].计算机研究与发展,2010,47(12):2110-2116.
[8] 王 茜,刘书志.基于密度的局部离群数据挖掘方法的改进[J].计算机应用研究,2014,31(6):1693-1696.
[9] 王敬华,赵新想,张国燕.NLOF:一种新的基于密度的局部离群点检测算法[J].计算机科学,2013,40(8):181-185.
