一种高效的OpenFlow流表拆分压缩算法
2018-03-27姜腊林张亚南
姜腊林,张亚南,熊 兵
1(长沙理工大学 计算机与通信工程学院,长沙 410114) 2(长沙理工大学 综合交通运输大数据智能处理湖南省重点实验室,长沙 410114)
1 引 言
在软件定义网络(Software Defined Networking,SDN)中,南向接口协议完成控制平面与数据平面交互,实现网络的数控分离,使得SDN具有强大的可编程性.OpenFlow协议是当前SDN中最为成熟的南向接口协议之一,它使得控制平面可以完全控制数据平面的转发行为,开放了基于流表的交换机以及集中式的控制器,使得网络的编程和控制变得十分灵活,大大降低了网络创新的难度.然而OpenFlow协议还面临很多未解决的问题,流表的存储问题就是其中之一.OpenFlow将网络协议栈扁平化,各个网络字段都可以作为流表的匹配域,并通过通配符掩码支持任意字段的组合.在OpenFlow规范1.0版中定义了12元组匹配字段,OpenFlow1.4版本中则定义了41项可匹配字段.丰富的流表匹配字段实现了网络流的细粒度管理,大大提高了网络的灵活性,但也带来了流表规模庞大的问题.OpenFlow交换机通常采用三态内容寻址存储器(ternary content addressable memory,TCAM)装载流表,以支持灵活高效的查找.但其价格昂贵,能耗高,导致容量有限(4K-32K),一般为8K左右.这就导致OpenFlow流表存储成为一个严峻的挑战.因此,如何有效减少OpenFlow流表存储空间,是SDN走向实际应用部署亟待解决的问题.
针对OpenFlow交换机中TCAM资源紧缺的问题,目前有很多学者展开研究工作.Kannan[1]等人提出紧凑TCAM方案,引入流标识符来替代流表项的概念,减少在TCAM中标识流所需比特,从而减少OpenFlow流表项大小,同时降低TCAM能耗.Banerjee[2]等人利用SDN数据交换TCAM访问速率和操作特性,提出一种标签嵌套方法Tag-in-Tag,将流表项替换成两层简短标签(用于数据包路由的路径标签和将数据包关联到流的流标签),从而使TCAM容纳更多的流表项,同时降低每条流的能耗.以上两项工作可有效减小流表存储空间,但是并没有考虑到重复的流表项,优化效果还可以进一步提升.Bedhiaf[3]等人提出一种OpenFlow v1.1虚拟交换机的TCAM资源分配机制,应用遗传算法和禁忌搜索算法解决多目标问题,从而可根据最小化分配能耗和最大化切片公平性之间的用户偏好,在TCAM资源上进行灵活分配切片表来降低能耗.Veeramani[4]等人结合前缀重叠、前缀最小化和零压缩三种方法,对OpenFlow交换机中TCAM存储的转发表进行虚拟压缩,减少前缀值的长度可达50至60%.以上这些工作均是面向OpenFlow交换机TCAM提出虚拟压缩方案,来节省流表存储空间.
郭泽华[5]等人提出一个转发方案JumpFlow,使用包首部中的VLAN标识符(VID)携带路由信息,反应式地在交换机中放置流表项,从而实现SDN中低的平衡的流表使用率.冷冰[6]等人提出一个流表简化方案FTRS,根据所有流表项生成一个二叉树,进一步移除空节点,从而消除冗余流表项,但没有考虑到在SDN中,多播树的节点和链接会受到容量的约束.罗寿西[7,8]等人提出一个对非前缀规则进行快照聚合的离线方案FFTA,以聚合感知的方式将非前缀规则划分成前缀可置换的分区,进而应用最优的前缀聚合技术.在此基础上,设计增量式的流表快速聚合方案iFFTA,在原始规则更新时,利用规则的顺序无关性和结构信息,立即合并更新.该方案切实可行,极大简化了聚合规则的更新,且压缩率的损失在可接受的范围内.然而,当出现新的版本号时,所有的规则都需要复制,将会造成大量的规则空间开销.
葛敬国和陈智等人提出了一种启发式的 OpenFlow 流表存储空间优化算法H-SOFT[9],通过分析OpenFlow 流表结构中各个字段之间的共存和互斥关系,将一个 OpenFlow 流表划分成多个规模较小的子流表,进而根据字段匹配类型将子流表切分成多个字段[10],并采用合适的算法和硬件进行存储和查找,得到字段匹配结果后再结合汇总表查找得到子流表的匹配结果,从而有效减小流表规模,降低SDN交换机的TCAM资源需求与能耗.然而,这两个工作都是对于取值重复不多的字段,其存储开销可能反而会增加,优化效果有待改进.刘中金等人[11]等提出一种 OpenFlow 多级流表结构及其映射算法,将单一流表映射到多级流表中进行高效存储和查找,可节省17%以上TCAM 资源.然而,该算法在进行流表分级时,匹配集合的表项宽度会因为个别字段值的重复次数多而变大,使得总体压缩效果显著下降.针对上述问题,本文利用匹配域间共存互斥关系,将流表划分出多个规模较小的子流表,进而针对每个字段建立判定条件进行压缩,以实现OpenFlow流表的高效存储.
2 OpenFlow流表拆分压缩算法
2.1 匹配字段关系
流表是一些针对特定“流”的策略表项集合,用于数据分组的查询和转发[[12].流表往往包含大量流表项,每个流表项表征一个“流”及其对应的处理方法.匹配域作为交换机匹配数据包的依据,是流表项的关键组成部分.匹配域的字段主要来源于各层网络协议首部,提供了一层到四层的网络控制信息.以OpenFlow1.0 的12元组为例,如图1所示.交换机入口(Ingress Port)属于物理层;源MAC地址(Ether_src)、目的MAC地址(Ether_dst)、以太网类型(Ether_type)、VLAN标签(VLAN_id)、VALN优先级(VLAN_priority)属于数据链路层;源IP(IP_src)、目的IP(IP_dst)、IP协议(IP_proto)、IP服务类型(IP_ToS bits)属于网络层;TCP/UDP源端口(TCP/UDP_src port)、TCP/UDP目的端口(TCP/UDP_dst port)属于传输层.
由于各个匹配字段分布的协议层次不同、隶属的协议类型也不同,因而存在共存互斥关系.在同一层中属于同一节点的匹配字段存在共存关系,在同一层分布不同节点的匹配字段则存在互斥关系.对于两个匹配字段fi、fj,如果fi、fj同时存在或者同时不存在则为共存关系,如果字段fi存在则字段fj就不存在,反之亦然,则为互斥关系.例如,
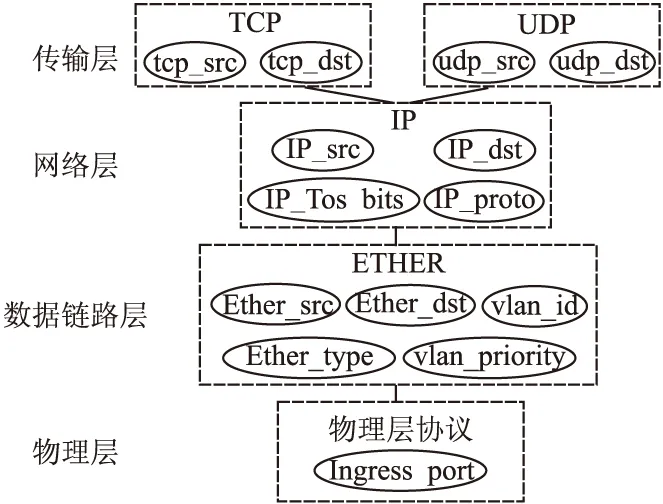
图1 OpenFlow1.0包头域分布协议树Fig. 1 OpenFlow1.0 protocol tree distribution of header fields
匹配字段之间的共存互斥关系可以用0-1矩阵描述.以8个典型字段(IPV4_SRC、IPV4_DST、IPV6_SRC、IPV6_DST、TCP_SRC、TCP_DST、UDP_SRC、UDP_DST)为例,其共存和互斥关系的二维矩阵分别如式(1)和式(2)所示.其中Cij=1代表任意两个匹配字段fi、fj存在共存关系,Mij=1则表示任意两个匹配字段fi、fj存在互斥关系.

(1)

(2)
2.2 算法思想
根据上述匹配字段之间的共存和互斥关系,将流表中的所有匹配字段划分成多个字段集合,组成多个规模较小的子流表.字段划分规则如下:对于存在共存关系的匹配字段,则将其划分到相同子流表的字段集合中;对于存在互斥关系的匹配字段,则将其划分到不同子流表的字段集合中.依据这一规则,可将规模庞大的原始流表划分为多个规模较小的子流表.在此基础上,将子流表中取值重复较多的字段划分出来单独存储,以进一步减少存储空间.为便于理解,在表1给出了下列公式中各个变量及其含义.

表1 变量及其含义Table 1 Variables and their meanings
假设现有一个流表,包含N条流表项,每条流项包含M个匹配字段,流表字段集合记为F={fi|1≤i≤M}.根据所有匹配字段之间的共存和互斥关系,将流表拆分成k(k≤M)个子流表,其中,第i个子流表的匹配字段集合Fi={fij|1≤j≤Mi},且Fij⊆F.Fi满足如下关系:
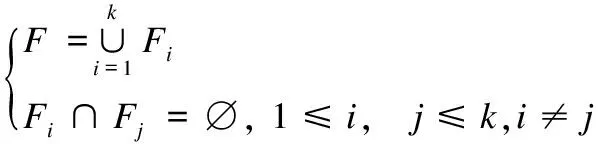
(3)
对于单个子流表,某些字段的取值可能重复次数较多,如:IP协议字段的取值主要是7(UDP)和16(TCP),因而可能存在进一步压缩的空间.下面尝试划分子流表,以进一步减少存储空间.首先,统计子流表中各个字段取值互不重复的数量,并按照从小到大排序.然后,从子流表中依次选取一个字段,将其单独存放或者和已取出的字段集合一起存放,作为二级子流表.最后,计算与原始子流表相比,各种情况下存储空间的变化量,从而找出最优的子流表存储方案.
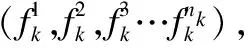
(4)
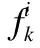
(5)
(6)

(7)
(8)
(9)
综合式(6)和式(9)可得,第k个子流表中的第i个字段取出后与第j个二级子流表组合或单独存放的存储空间变化量为:
(10)
根据式(10),可计算某个字段从子流表中取出后,不同存储方式的存储空间变化量.然后,找出所有变化量中的最小值.若该值小于零,则相应的方案即为该字段当前最优的存储方案;否则,该字段存储在原子流表中.依据上述方法,依次处理子流表中的每个字段,最终确定任意子流表的最佳存储方案.
3 算法实现
3.1 算法流程
述算法思想,本文所提的流表拆分压缩算法如表2所示.该算法分为两大步骤:(1)对于一个给定的流表,基于上述共存矩阵和互斥矩阵,将流表的所有字段划分为多个字段集合,形成多个子流表;(2)对于划分后的每个子流表,根据存储空间变化量依次考察其各个字段的存储方式,确定该子流表的最优存储方案.
对于流表ft,首先将其第一个匹配字段f1单独作为一个子流表.然后,从流表ft依次取出字段fi,判定该字段和现有子流表的字段集合是否存在共生关系或互斥关系.对于某个子流表字段集合Fj,若字段fi和字段集合Fj中的字段具有共生关系,则将该字段加入到子流表字段集合Fj中;否则,将字段fi单独作为一个子流表存放,并放入到相应新增的字段集合Fn+1中.所有字段划分完毕后,原始流表中的字段取值改为相应子流表中表项取值的存储地址,成为汇总表.
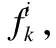

表2 OpenFlow流表拆分压缩算法.Table 2 Flow Table split and compress algorithm.
在上述算法中,流表拆分为一级子流表过程的时间复杂度为O(n),一级子流表拆分为二级子流表过程的时间复杂度为O(n*m).因此,本文所提的算法的时间复杂度为O(n*m).
3.2 流表划分过程
为简化起见,以图2所示的流表为例,描述本文所提算法的工作过程.在图2中,每条流表项包含7个匹配字段:协议类型IP_PROTO(8bit)、源IP地址IP_SRC(32bit)、目的IP地址IP_DST(32bit)、TCP源(16bit)端口TCP_SRC(16bit)、TCP目的端口TCP_DST(16bit)、UDP源端口UDP_SRC(16bit)、UDP目的端口UDP_DST(16bit).
第一步,根据式(1)和式(2)所示的字段共存和互斥关系矩阵,流表所有字段划分为三个字段集合:字段集合1(含3个字段IP_PROTO、IP_SRC、IP_DST),字段集合2(含2个字段TCP_SRC、TCP_DST),字段集合3(含2个字段UDP_SRC、UDP_DST),进而存为3个子流表.同时,原始流表中的相应字段取值改为相应子流表中对应取值的存储地址(宽度为3bit),成为汇总表1,具体划分过程如图3所示.
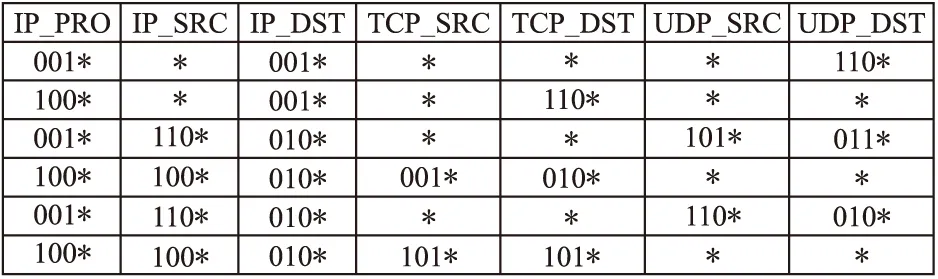
图2 流表Fig. 2 Flow table
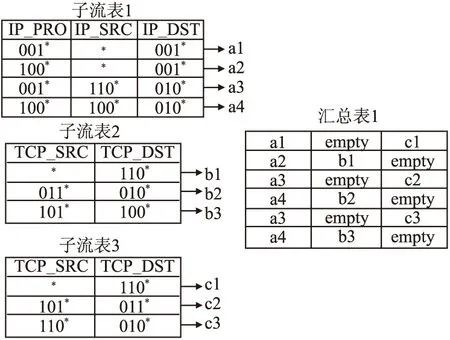
图3 流表划分结果Fig. 3 Result of flow Table splitting
第二步,对上述三个子流表依次寻求更优的存储方案.对于子流表1,其字段按互不重复取值数从小到大排序为IP_PROTO、IP_SRC、IP_DST.首先假设将字段IP_PROTO单独存放,按式(10)计算得到空间变化量为小于零,表明该划分方案可有效减少存储空间.然后继续考察字段IP_DST,计算其单独存放以及与字段IP_PROTO组合存放之后的子流表的空间变化量,可知字段IP_DST单独存放占用空间更少.最后考察字段IP_SRC,计算其单独存储以及分别与字段IP_PROTO、IP_DST组合存储的空间变化量,可知该字段与IP_DST组合存放占用空间最少.因此,子流表1的最佳存储方案是:字段IP_PROTO单独存放为一个二级子流表,IP_SRC和IP_DST组合存放为另一个二级子流表,原子流表中的字段取值改为相应二级子流表的表项取值的存储地址,成为二级汇总表2,具体划分过程如图4所示.同理可知,子流表2和子流表3的原始存储方案占用空间最少.
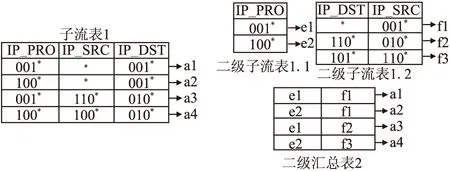
图4 子流表1划分结果Fig. 4 Result of sub-flow Table 1 splitting
4 实 验
实验借助实际网络样本,将本文所提算法的流表压缩性能分别与H-SOFT算法和多级流表映射算法进行比较.实验选取江苏省计算机网络技术中心发布的两个网络流量样本(TRACE20130418、TRACE20120922)作为测试数据集.这两个数据集是按照1:4的比例从速率为10Gbps的高速网络链路上采集而得,持续时间分别约为107秒和86秒.为了简化起见,实验选取网络层和传输层的7个字段(IP_PROTO、IP_SRC、IP_DST、TCP_SRC、TCP_DST、UDP_SRC、UDP_DST)作为匹配域.实验每10秒输出一次流表,其流表项数量如图5所示.从图5可以看出:实验选取的两个数据集输出流表的流表项个数分别为60K和80K条左右.
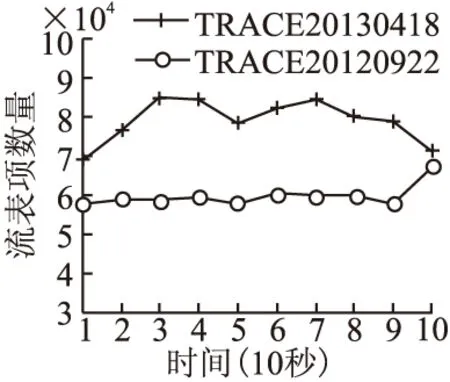
图5 流表项数量Fig. 5 Number of flow entries
用本文所提算法、H-SOFT算法和多级流表映射算法,分别对上述流表进行压缩,得到相应的流表压缩率如图6所示.H-SOFT算法主要通过压缩流表项中的通配符,从而节省存储空间.由于该算法未考虑流表项还存在重复取值这一情况,所以拆分后的流表还存在较大的可压缩存储空间.多级流表映射算法在进行流表分级时,匹配集合的表项宽度会因为个别字段值的重复次数多而变大,使得总体压缩效果显著下降.而本文所提算法,则进一步考虑到字段的不同存储方案,确定子流表最优的存储方案,从而实现更好流表压缩的性能.从图6中可以看出,本文所提算法的流表压缩率要高于多级流表映射算法和H-SOFT算法.本文所提算法的流表压缩率稳定在50%左右,H-SOFT算法的流表压缩率在30%—40%左右,而多级流表映射算法的压缩率只有25%左右.

图6 流表压缩率对比Fig. 6 Flow Table storage compression rate
5 总 结
本文提出了一种高效压缩OpenFlow流表存储空间的算法,首先基于匹配字段的共存互斥关系将流表拆分成多个规模更小、匹配字段更少的子流表,进而考虑字段的不同划分情况,根据判定条件对子流表进行优化,从而达到存储空间压缩的目的,避免引入存储地址变量会增大存储开销的问题,进而达到存储空间压缩的目的.实验结果表明本文所提算法得出的流表存储压缩率稳定在50%—60%,高于H-SOFT算法和多级流表映射算法,可有效的提高流表空间的存储效率.
由于流表存储空间优化理论和应用研究还处于初期阶段,许多问题还需要人们不断探索和解决,本文所提算法还是局限在对静态流表存储空间的压缩,如何实现动态流表的存储压缩就是进一步要做的研究工作.
[1] Kannan K,Banerjee S.Compact TCAM:flow entry compaction in TCAM for power aware SDN[C].In:Proceedings of the Distributed Computing and Networking,Springer Berlin Heidelberg,2013:439-444.
[2] Banerjee S,Kannan K.Tag-In-Tag:efficient flow
Table management in SDN switches[C].In:Proceedings of IEEE International Conference on Network and Service Management(CNSM),Rio de Janeiro,Brazil,2014:109- 117.
[3] Bedhiaf I L,Burguin R,Cherkaoui O,et al.TCAM
Table resource allocation for virtual openflow switch[C].In:Proceedings of the Annual Mediterranean on Ad Hoc Networking Workshop(MedHoc),Ajaccio,2013:128-132.
[4] Veeramani S,Kumar M,Mahammad S N.Minimization of flow
Table for TCAM based openflow switches by virtual compression approach[C].In Proceedings of Advanced Networks and Telecommuncations Systems(ANTS),Kattankulathur,2013:1-4.
[5] Guo Z,Xu Y,Cello M,et al.JumpFlow:reducing flow
Table usage in software-defined networks[J].Computer Networks,2015,92(2):300-315.
[6] Leng B,Huang L,Wang X,et al.A mechanism for reducing flow tables in software defined network[C].In:Proceedings of the 2015 IEEE International Conference on Communications(ICC),London,2015:5302-5307.
[7] Luo S,Yu H,Li L M.Fast incremental flow
Table aggregation in SDN[C].In:Proceedings of the International Conference on Computer Communication and Networks,Shanghai,2014:1-8.
[8] Luo S,Yu H,Li L.Practical flow
Table aggregation in SDN[J].Computer Networks the International Journal of Computer & Telecommunications Networking,2015,92(P1):72-88.
[9] Ge J,Chen Z,Wu Y,et al.H-SOFT:a heuristic storage space optimisation algorithm for flow
Table of OpenFlow[J].Concurrency & Computation Practice & Experience,2015,27(13):3497-3509.
[10] E Yue-peng,Chen Zhi,Ge Jing-guo.An efficient implementation of storage and lookup for flow tables in OpenFlow [J].Science China:Information Science,2015,45(10):1280-1288.
[11] Liu Zhong-jin,Li Yong,Su Li,et al.TCAM-efficient flow
Table mapping scheme for OpenFlow multiple-
Table pipelines[J].Tsinghua Univ( Sci & Technol),2014,54:437-442.
[12] Zuo Qing-yun,Chen Ming,Zhao Guang-song,et al.Research on OpenFlow-based SDN technologies[J].Journal of Software,2013,24(5):1078-1097.
附中文参考文献:
[10] 鄂跃鹏,陈 智,葛敬国,等.一种高效的OpenFlow流表存储与查找实现方法[J].中国科学:信息科学,2015,45(10):1280-1288.
[11] 刘中金,李 勇,苏 厉,等.TCAM存储高效的OpenFlow多级流表映射机制[J].清华大学学报(自然科学版),2014,54(4):437-442.
[12] 左青云,陈 鸣,赵广松,等.基于OpenFlow的SDN技术研究[J].软件学报,2013,24(5):1078-109.
