时间权重递增的协同过滤算法
2018-03-27史长琼夏广伟刘井平何湘妮
史长琼,夏广伟,刘井平,何湘妮
1(长沙理工大学 智能交通大数据处理湖南省重点实验室,长沙 410114) 2(长沙理工大学 计算机与通信工程学院,长沙 410114)
1 引 言
随着信息技术的发展,推荐技术逐渐成为各领域重要的研究内容.目前,基于协同过滤的推荐系统不仅广泛应用于电商网站,包括 Amazon、Netflix、Taobao,而且也应用于其他领域,如:电视节目推荐、网页个性化推荐等.
协同过滤技术主要可分为两大类:基于内存的协同过滤和基于模型的协同过滤[1].其中,基于内存的协同过滤又分为基于用户的和基于项目的.基于用户的协同过滤是通过寻找目标用户的邻近用户,根据邻近用户对项目的评分,向目标用户推荐预测评分为Top-N的项目;基于项目的协同过滤根据用户对相似项目的评分,预测用户对目标项目的评分,当需要预测某个目标项目的评分时,可以通过用户对目标项目的若干近邻项目进行估计来实现.
基于项目的协同过滤推荐算法(Item-based Collaborative Filtering,ItemCF)无论在研究中还是在实际应用中都有着重大的突破.然而传统的协同过滤算法并没有考虑用户的兴趣随时间的推移而发生变化,认为评分数据在不同时期对于当前的影响是等同的,导致推荐的信息可能是过时的或者不是用户当前感兴趣的信息,影响了算法的准确性.针对传统协同过滤算法存在推荐信息低时效性这个问题,文献[9-15]在对数据的处理过程中考虑到了时间权重的变化,认为评分信息所起到的作用随着时间的变化而变化,且这种变化是严格递增的,即近期的评分信息必然比以往的评分信息更具有参考作用.在对项目的评分进行预测过的程中,将越接近当前的数据所赋予的权重更大,忽略了用户访问资源的具体时间段以及特殊非正常情况下的数据对预测的影响.显然,这是不合理的.例如:今年春节是在1月,此时人们会更喜欢看贺岁片,但是春节过后,人们对贺岁片的喜爱程度会归于常态.如果要对今年2月贺岁片的评分进行预测,显然去年12月的数据比今年1月的数据更具有参考意义,该被赋予更高的权重.又如:在中国喜庆节日时,人们对恐怖电影的关注程度会急剧下降,如果因为其时间距离预测时段很接近而将此特殊情况赋予很高的权重,来作为其他用户的推荐标准,显然会使推荐效果不理想.因此,本文提出一种模糊递增的概念,认为越靠近当前时刻的评分,其参考作用的走向是波浪式循序上升的.例如,来自电影租赁网站的Netflix电影评分随时间的变化趋势如图1所示,图1(a)描述了某一部电影其评分随着时间的推移,在总体上呈上升趋势;图1(b)描述了数据集中拥有不同年龄的电影的评分情况,可以看出,年龄越大的电影的评分趋于越高.图1从两个不同的角度来反映电影的评分变化规律,即项目的评分总体呈上升趋势.然而我们发现,该数据集却存在特殊情况,如图1(a)中第500天、1000天、1500天等,电影的评分突兀下降.从整个时间戳看,项目评分虽然呈上升趋势,但却出现上下波动的现象,并不符合严格递增规律.
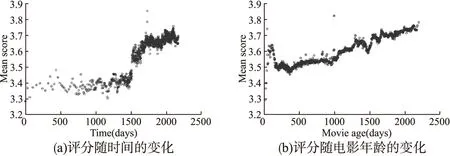
图1 Netflix数据集电影的评分趋势Fig.1 Two temporal effects emerging within the Netflix movie-rating dataset
2 相关工作
传统的协同过滤算法[1-3]存在推荐信息低时效的问题,大多数没有考虑时间因素的影响,然而时间属性又是反映用户兴趣规律的重要特性之一,很多学者对此进行了改进.Liu等人[4]提出了一种基于时间的K近邻协同过滤算法,结合用户行为的时间信息和K近邻算法提出了新颖的相似性度量方式.Liang等人[5]提出了Session-based Temporal Graph(STG)算法和Injected Preference Fusion(IPF)推荐算法,刻画了用户随时间变化的偏好.Yan等人[6]在预测过程中引入了时间属性,提出了一种时分协同过滤算法,并采用不同策略对其进行处理,有效提高了系统的推荐质量.顾亦然等人[7]采用添加时间维度的方式将推荐过程由二部图迁移到三部图上进行处理,虽然有效提高了推荐的准确新型,却在一定程度上增加了算法的复杂度.Gultekin等人[8]提出了一种基于协同卡尔曼过滤的动态模型,解析了用户/项目的漂移参数随时间推移的无规则变化.
虽然上述算法考虑到了时间因素在预测过程中的重要性,却都平等地对其进行评级,忽略了用户的兴趣可能随时间改变的事实,没有在预测过程中对时间属性赋予合适的权重.对此,另外一些学者进行了如下研究,Adibi等人[9]从用户间相互影响力不同的角度出发,提出了基于用户时间权重的最近邻建模方法,有效缓解了批量资源的实时推荐问题,更好地预测用户评分.为了适应用户偏好随时间的动态变化,Ding等人[10]提出了一种时间权重的协同过滤算法,对评分进行时间加权,降低了过时信息的重要性,有效缓解了项目评分老化的问题.Koren等人[11]提出了基于时序的因式分解算法和基于时间变化的基线预测,解析了项目历史评分信息对当前时刻的瞬时影响和长期影响.An等人[12]提出了基于用户访问时间的数据权重和基于加速度的数据权重,并将两种权重引入协同过滤算法的推荐过程中,动态反映了用户兴趣的变化过程.Hu等人[13]建立了以最新信息为依据的时间序列反馈模型,结合协同过滤实现用户偏好的动态推荐.为了解析项目历史评分信息对当前时刻的影响,Zhao等人[14]提出了一种时间分布的协同过滤算法,通过引用时间因子将用户评分信息划分不同的时间段,有效缓解了用户兴趣的动态变化问题.Jin等人[15]结合了权重随时间和项目相似系数,解析了用户兴趣偏好的变化过程.
上述文献认为用户的兴趣并不是静态的,而是符合一种递增规律的,在对数据的处理过程中,虽然考虑到了时间权重的变化,但是都认为数据是严格递增的,即越接近当前的数据对预测的影响越大,忽略了用户访问资源的具体时间段以及特殊非正常情况下的数据对预测的影响,这显然也是不合理的.本文在现有研究的基础上做出了改进,创新点主要体现在以下方面:1)在计算项目相似度阶段引入时间属性,提出一种基于时间窗口的相似度算法;2)在预测阶段,结合权重的模糊递增提出一种新颖的评分预测算法.3)对于符合模糊递增的参数,提出一种新颖的多参数优化策略.
3 基于时间窗口的相似性度量
在协同过滤推荐中[16,17],相似性度量用于发现相似的用户或项目,能否准确发现近邻用户或项目,影响推荐结果的准确性.相似性主要是通过基于对象的特征或属性,利用特征向量间的相似系数、相关系数及距离等来计算.为了反映项目各历史时期评分的变化规律,本文利用项目评分[18]和项目访问时间对项目的评分时间划分时间窗口,并根据时间窗口相似度和链式结构度量项目的相似性.
3.1 传统ItemCF算法
协同过滤算法根据项目特征产生目标用户的推荐列表,它基于这样的假设:根据用户对不同项目的评分存在相似性,需要预测目标项目的评分时,可通过用户对目标项目的若干近邻项目进行估计.因此,传统ItemCF算法[19,20]主要分为两大阶段.
Phase1. Top-K近邻查找:对于目标项目,需搜寻其近邻集合,最近邻数量K可直接给定,即择取相似性Top-K的项目.近邻项目主要通过项目相似性进行度量,例如,Pearson相关系数如式(1)所示:
(1)

Phase2. 评分预测:近邻集合产生后,对于目标用户u尚未评分的项目n,按公式(2)加权计算得到u对n的预测评分Pun,并选择预测评分最高的若干个项目作为推荐结果反馈给目标用户.
(2)
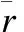
3.2 时间窗口相似性
若给定用户集U=u1,u2,…,uM,则项目n的评分和访问时间可表示为二元组

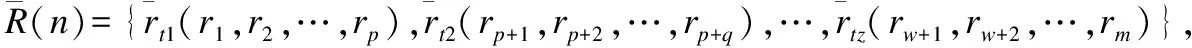


(3)
(4)
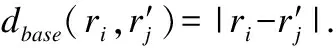
3.3 基于链式结构的项目相似性
项目相似度可通过项目之间对应的时间窗口进行衡量.时间窗口的对应关系应满足两个条件:一是由于每个时间窗口的评分对项目相似性的度量都起到了一定作用,项目的每个时间窗口皆要有对应关系;二是由于越接近当前时刻的评分对预测所起的作用越大,且项目评分符合递增规律,项目之间时间窗口的对应关系应按时间顺序进行匹配.因此,本文提出基于链式结构的项目相似性度量算法.
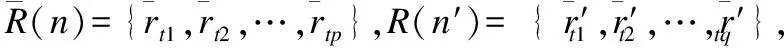
1)若p=q;则项目n、n′的相似度为:
(5)
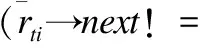
(6)
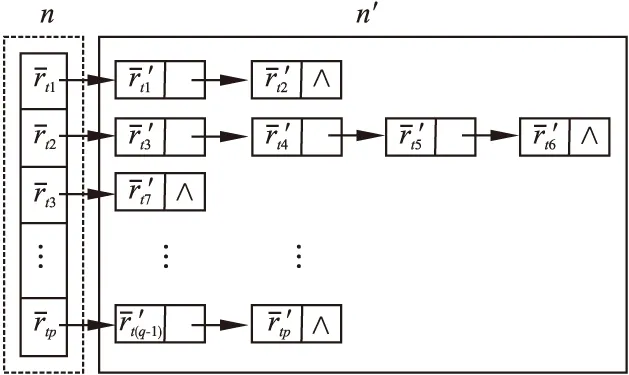
图2 链式法示例Fig.2 Item-based chain structure
Note 1.相似性具有对称性,D(n,n′)=D(n′,n).
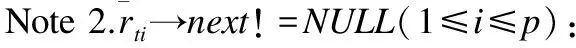
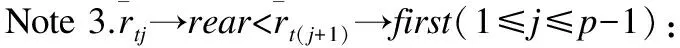
为了使项目相似性得到更好的体现,本文将计算的项目相似度结果规约到(0,1]之间,如式(7)所示.
(7)
4 基于模糊递增的评分预测

4.1 目标函数构造
随着时间的推移,项目各历史时期的评分所起到的作用存在一定的变化规律.因此,我们提出结合时间权重的预测评分公式:
(8)
其中,h(t)的计算方式如式(9)所示.
h(t)=(α1r1+α2r2+…+αmrm)
(9)
s.t.α1+α2+…+αm=1
其中,αi(1≤i≤m,0≤αi≤1)表示历史时刻ti的用户评分对当前预测评分起到的作用,即权重大小.
同一用户对于关联度较强的项目具有相同的兴趣变化趋势,以单个用户和单个项目相似集作为计算单位,进行各时期权重的求解.针对每一相似集,采用交叉验证的方式进行各时期权重序列的求解,每次从相似集中取出一个项目作为测试,并采用平均绝对误差(mean absolute error,MAE)作为推荐精度的度量标准,如式(10)所示:
(10)
其中,pn表示预测评分,qn表示实际评分,N为测试集大小.显然,MAE值越小,预测评分效果越佳.因此,各时期权重的求解可用最优化的形式表示,如下式所示:
arg minMAE(α1,α2,…,αm)
(11)
对于目标函数的求解,由于参数之间的关系不明确,较为模糊,难以用普通的参数优化算法进行优化.本文提出一种新颖的多参数最优化的求解策略.由第1节可知,评分与评分的权重的变化存在一定的相似程度.因此,根据评分划分时间窗口的方式,同样地对评分权重划分时间窗口.评分权重(α1,α2,…,αm)可划分成(βt1,βt2,…,βtz),其中,|βti|称之为βti的窗口权重,|βti-1|<|βti|(i=1,2,…,tz).因此,对于评分权重的求解可以从全局到局部,即先计算窗口权重,使得窗口权重参数的解达到全局最优,再根据窗口权重与评分权重的关系计算窗口内的评分权重,使得各评分权重达到最优.具体可以分为以下两个阶段,第一个阶段是求解符合严格递增关系的窗口权重参数|βti|(i=1,2,…,tz);第二个阶段是求解时间窗口内具有随机波动特性的评分权重参数αi(i=1,2,…,m).
4.2 严格递增参数求解
由于权重序列的时间窗口参数符合严格递增关系,则第一阶段中本文通过平均年限法表示各时间窗口的参数关系,如式(12)所示.
(12)
因此,目标函数可表示为:
arg minMAE(βt1,βt2,…,βtz)
(13)
构造拉格朗日函数
(14)
其中β(t)=(βt1,βt2,…,βtz)T,μ1和μ2是拉格朗日参数.
分别对变量βtk、μ1和μ2求偏导:
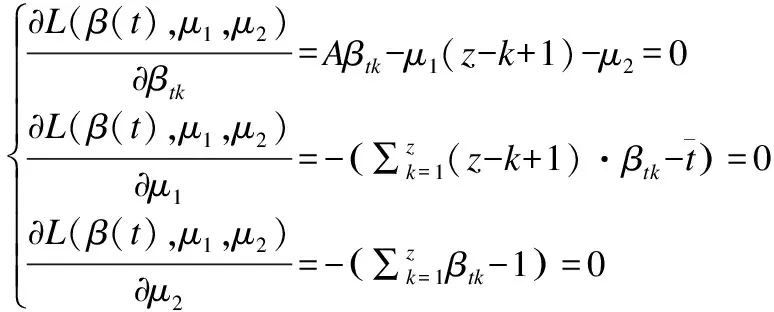
(15)


(16)
因此
(17)
tk=t1,t2,…,tz
由于βtk>0,有

(18)
tk=t1,t2,…,tz
因此

(19)


(20)
因此
(21)
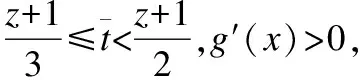
4.3 随机波动参数求解
针对预测过程的第二阶段,本文逐一考虑具有随机波动性的各个时间窗口内的参数,假设某一时间窗口参数(βtk(αa,αa+1,…,αa+b)),目标函数如式(22)所示.
arg minMAE(βt1,…,βtk-1,αa,αa+1,…,αa+b,βtk+1,…,βtz)
s.tαa+αa+1+…+αa+b=(b+1)βtk
(22)
其中,αi≥0,(a≤i≤a+b).
考虑到粒子群优化算法(Particle Swarm Optimization,PSO)对于多参数的优化具有稳定、高效的性能,本文采用PSO算法[21]来优化窗口内的随机参数.因此,可以得到单一时间窗口的最优解空间(αa,αa+1,…,αa+b).以此类推,逐一对所有权重求解,可得到权重序列的最优解空间(α1,α2,…,αm).
4.4 算法过程
对于符合模糊递增规律的参数求解,本文提出了一种新颖的多参数优化策略.以某项目评分时间权重为(α1,α2,…,α10)为例,阐述参数求解的步骤:
1)对时间权重(α1,α2,…,α10)划分时间窗口,假设划分结果如下:窗口1包含参数(α1,α2,α3),其中窗口权重与评分权重的关系为βt1=(α1+α2+α3)/3,窗口2包含参数(α4,α5,α6),其中βt2=(α4+α5+α6)/3,窗口3包含参数(α7,α8,α9,α10),其中βt3=(α7+α8+α9+α10)/4,窗口权重βt1<βt2<βt3;
2)利用公式(12)将窗口权重不等式转化成等式,作为目标函数argminMAE(βt1,βt2,βt3)的约束条件;
3)将公式(13)转化成标准的拉格朗日函数,分别以βtk(k=1,2,3)、μ1和μ2作为变量进行求偏导;
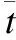
5)利用窗口权重与评分权重的关系,逐一分解窗口权重,通过PSO算法求解目标函数公式(22).
5 实验结果及分析
为了验证本文提出的算法有效性,进行了一系列的仿真实验,主要有以下三个方面:
1)相似度过程中,讨论时间窗口的划分方式以及时间窗口的个数对平均准确率(Mean Average Precision,MAP)的影响,以及比较基于时间窗口的相似性算法(Time Window-based Item Similarity,TWIS)与传统ItemCF算法的相似性度量算法的推荐精度.
5.1 实验设计
实验采用Netflix数据集,含480,189个用户对17,770部电影的100百万条评分,时间1999年11月11日至2005年12月31日.随机抽取5,000部电影作为实验数据(简称NF5M),其中80%作为训练集,20%作为测试集,Top-K设为30,并采用MAP值作为推荐质量的度量标准(MAP=1-MAE).
表1 NF5M数据集的特点
Table 1 Characteristics of data set NF5M

NameofdatabaseNF5MNumberofusers472542Numberofitems5000Numberofratings5Timespent2001.01.08-2005.12.31
5.2 不同时间窗口划分方式的MAP对比
本小节分析了不同时间窗口划分方式对推荐精度MAP值的影响,并与传统ItemCF进行比较.
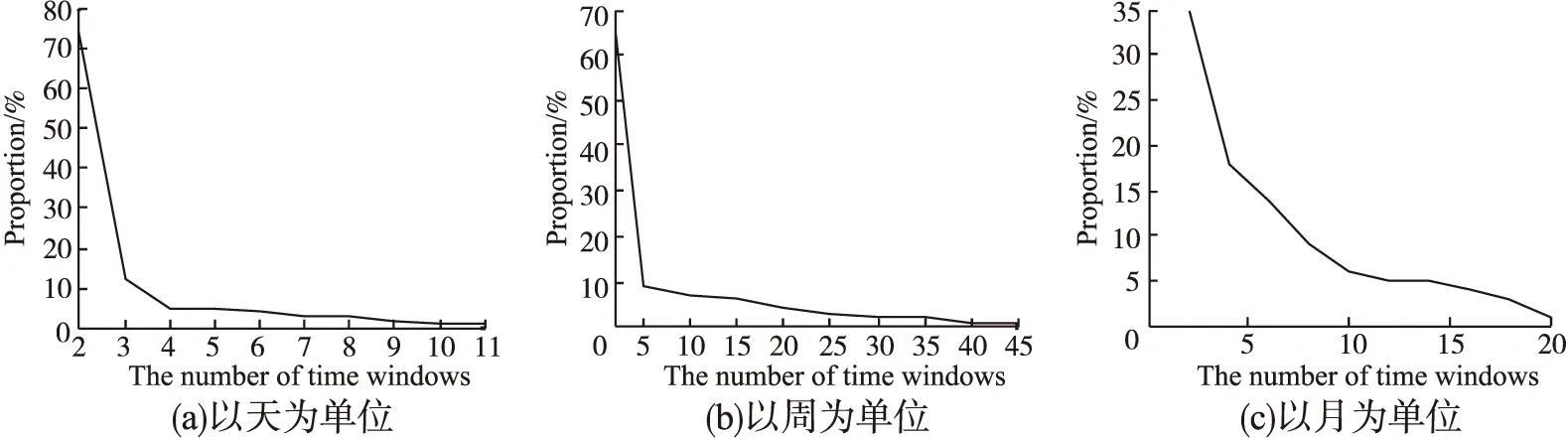
图3 不同单位的时间窗口划分Fig.3 Partition time windows in different units
实验统计,以天为单位,每部电影平均有503天存在评分;以周为单位,每部电影平均有126周存在评分;以月为单位,每部电影平均有36个月存在评分.单位不同,导致评分序列时间窗口划分的数量也不同.图3(a)中,由于评分个数较多,较难满足划分条件.图3(b)中时间窗口数达到45,能较好满足时间窗口划分的条件.图3(c)中时间窗口数虽占评分个数的1/2,但时间窗口数量较少.时间窗口数越少,划分方式就越多,因此,以不同单位划分时间窗口对窗口数有很大的影响.为了使相似度更加准确,选择同一时间窗口数中项目之间对应时间窗口的最小距离作为衡量项目相似的基础.
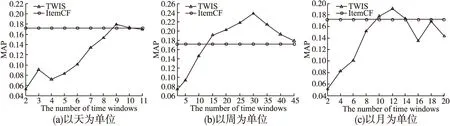
图4 不同单位的MAP值Fig.4 MAP in different units
图4中,本文TWDS算法以不同单位划分时间窗口,并与传统ItemCF算法对比MAP值.图4(a)中,随时间窗口数的增加,MAP值也随之提高.当窗口数为9时,MAP值达到最高值0.179,比传统ItemCF算法高0.007.图4(b)中,当窗口数多于15时,MAP值均高于传统ItemCF算法,当窗口数为30时,MAP值达到0.238.图4(c)中,当窗口数多于8时,MAP值在0.172上下波动,与ItemCF算法相差不大.因为,时间窗口数占评分个数的比例较低时,MAP值会较低,所以,时间窗口数较少时,无法描述历史不同阶段评分的变化规律.例如,时间窗口数为2时,MAP均低于0.08.因此,划分时间窗口的个数对MAP的值有很大的影响,当选择合适的窗口数时,本文算法的推荐精度均会高于传统的协同过滤算法.
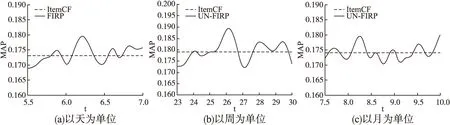
图5 非模糊递增值的MAP值Fig.5 MAP of un-FIRP in different units
5.3 不同参数的MAP对比
图5给出随机权重与传统ItemCF预测算法推荐精度MAP值的比较.图5(a)中随机权重推荐算法的精度最高为0.179,最低为0.169,与传统ItemCF预测算法的MAP值相差不大.图5(b)随机权重的MAP值最高为0.189,最低为0.172,传统ItemCF预测算法的MAP值0.179相差0.007.图5(c)中随机选取的权重MAP值在0.174上下波动,与传统预测算法推荐精度差别较小.可以看出,随机分配的权重与各时期评分权重相等的推荐效果相似.因此,本文算法与传统ItemCF中预测算法在推荐效果上差别较小.

图6 模糊递增值的MAP值Fig.6 MAP of FIRP in different units
5.4 参数z和的关系及文献对比

ztMAP15[16/3,8)0.221±0.02220[7,21/2)0.228±0.02325[26/3,13)0.239±0.03230[31/3,31/2)0.251±0.03335[12,18)0.233±0.03140[41/3,41/2)0.225±0.023
图7对本文FICF算法与文献[10]TWCF算法、文献[13]TSFCF算法和文献[15]TCICF算法进行了对比.文献[10] TWCF算法认为项目的评分规律符合严格递增的规律,忽略了特殊事件的发生,其MAP的平均值和最大值分别为0.229和0.235;文献[13] TSFCF算法主要使用时间序列模型,通过最后的事件反馈修正预测值,忽略了历史各时期的评分规律,其MAP的平均值和最大值分别为0.239和0.271;文献[15] TCICF算法通过利用了艾宾浩斯的遗忘曲线规律,判断用户兴趣的遗忘趋势,但忽略特殊时期的波动性,其MAP的平均值和最大值分别为0.242和0.267;而本文中FICF算法的平均和最高MAP值分别为0.251和0.284,均高于其它三种算法.显然,本文FICF算法能更好的把握项目评分随时间推荐的变化趋势,及为用户提供更精确的推荐列表.
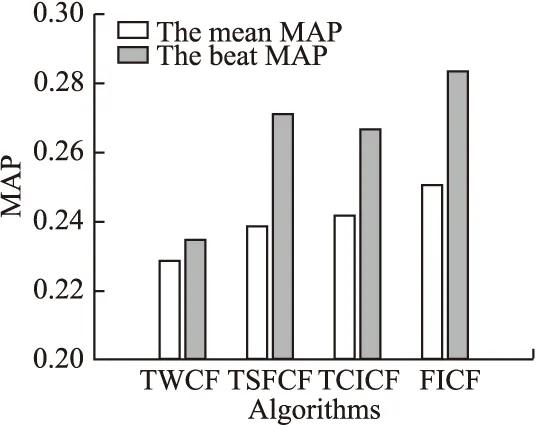
图7 不同推荐算法的MAP值Fig.7 MAP in different recommended algorithms
6 结 论
本文针对传统协同过滤数据的静态性,提出了一种权重递增的协同过滤算法.在Top-K近邻的查找阶段,利用项目评分的时间属性提出了一种时间窗口的相似性分析算法;在预测阶段,假设权重序列符合模糊递增的规律,并通过两阶段进行求解.与以往文献相比,本文更加注重项目评分的时序性以及项目评分随时间推移的变化趋势.多组实验表明,本文算法能更有效的捕捉项目评分的变化规律,为用户提供更精准的产品参考.
[1] Jiang S,Qian X,Shen J,et al.Author topic model-based collaborative filtering for personalized POI recommendations[J].IEEE Transactions on Multimedia,2015,17(6):907-918.
[2] Zou J,Fekri F.A belief propagation approach to privacy-preserving item-based collaborative filtering[J].IEEE Journal of Selected Topics in Signal Processing,2015,9(7):1306-1318.
[3] Yang H,Ling G,Su Y,et al.Boosting response aware model-based collaborative filtering[J].Knowledge & Data Engineering IEEE Transactions on,2015,27(8):2064-2077.
[4] Liu Y,Xu Z,Shi B,et al.Time-based k-nearest neighbor collaborative filtering[C].IEEE,International Conference on Computer and Information Technology,2012:1061-1065.
[5] Liang X,Quan Y,Shiwan Z.Temporal recommendation on graphs via long- and short-term preference fusion[C].ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,New York,USA,2010:723-732.
[6] Yan Y,Long Y.Notice of retraction collaborative filtering based on time division[C].IEEE International Conference on Computer Science and Information Technology.IEEE,2010:312-316.
[7] Gu Yi-ran,Chen Min.One Tag Time-weighted recommend approach on tripartite graphs networks[J].Computer Science,2012,
39(8):96-98.
[8] Gultekin S,Paisley J.A collaborative kalman filter for time-evolving dyadic processes[C].IEEE International Conference on Data Mining,Shenzhen,China,2014:140-149.
[9] Adibi P,Ladani B T.A collaborative filtering recommender system based on user′s time pattern activity[C].Information and Knowledge Technology,2013:252-257.
[10] Ding Y,Li X.Time weight collaborative filtering[C].ACM CIKM International Conference on Information and Knowledge Management,Bremen,Germany,October 31 - November,2005:485-492.
[11] KOREN Y.Collaborative filtering with temporal dynamics[C].ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,New York,USA,2009:89-97.
[12] An X,Su N.A dynamic filtering recommendation algorithm based on topic[C].International Conference on Electronic and Mechanical Engineering and Information Technology.IEEE,2011:3959-3962.
[13] Hu Y,Peng Q,Hu X,et al.Web service recommendation based on time series forecasting and collaborative filtering[C].IEEE International Conference on Web Services.IEEE,2015:233-240.
[14] Zhao J,Yu X,Sun J.TDCF:time distribution collaborative filtering algorithm[C].International Symposium on Information Science and Engineering.IEEE,2008:98-101.
[15] Jin X,Zheng Q,Sun L.An optimization of collaborative filtering personalized recommendation algorithm based on time context information[J].Advances in Information & Communication Technology,2015,449:146-155.
[16] Li B,Zhu X,Li R,et al.Rating knowledge sharing in cross-domain collaborative filtering[J].IEEE Transactions on Cybernetics,2014,45(5):1054-1068.
[17] Xiao Y,Peng Q A I,Hsu C H,et al.Time-ordered collaborative filtering for news recommendation[J].Communications China,2015,12(12):53-62.
[18] Hu Y,Peng Q,Hu X,et al.Time aware and data sparsity tolerant web service recommendation based on improved collaborative filtering[J].IEEE Transactions on Services Computing,2015,8(5)782-794.
[19] Rafailidis D,Nanopoulos A.Modeling users preference dynamics and side information in recommender systems[J].IEEE Transactions on Systems Man & Cybernetics Systems,2016,46(6)782-792.
[20] Sun Guang-fu,Wu Le,Liu Qi,et al.Recommendations based on collaborative filtering by exploiting sequential behaviors[J].Journal of software,2013,24(11):2721-2733.
[21] Li YL,Shao W,You L,et al.An improved PSO algorithm and its application to UWB antenna design[J].IEEE Antennas and Wireless Propagation Letters,2013,12(3):1236-1239.
附中文参考文献:
[7] 顾亦然,陈 敏.一种三部图网络中标签时间加权的推荐方法[J].计算机科学,2012,39(8):96-98.
[20] 孙光福,吴 乐,刘 淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013,24(11):2721-2733.
