基于多种群协同进化算法的数据并行聚类算法
2021-12-17孙柳
孙柳
(广东工业大学 华立学院,广州 511325)
0 引言
随着云存储空间多维资源分布数据库存储和信息传输技术的发展,云存储空间多维资源分布数据库的数据信息维数越来越多,需要结合大数据和云信息处理技术,构建云存储空间多维资源分布数据库的大数据并行聚类模型,提高云存储空间多维资源分布数据库数据的检测和识别能力。通过云存储空间多维资源数据并行聚类和特征分析,构建云存储空间多维资源数据聚类分析模型[1],提高云存储空间多维资源分布数据库的信息管理能力。相关的并行聚类方法研究,在云存储和资源分布数据库的组网设计和大数据信息管理中具有重要意义[2]。
对云存储空间多维资源数据并行聚类是建立在对数据的候选特征分析基础上,通过贝叶斯关联规则分析,进行云存储空间多维资源数据并行聚类[3]。传统方法中,对云存储空间多维资源数据并行聚类方法主要有:基于模糊信息检测的云存储空间多维资源数据并行聚类方法[4]、基于统计分析的云存储空间多维资源数据并行聚类方法[5]、基于粗糙集特征匹配的云存储空间多维资源数据并行聚类方法[6]等。由于传统方法进行云存储空间多维资源数据并行聚类存在适应度水平不高,抗干扰性不好等问题。对此,本文提出基于多种群协同进化算法的云存储空间多维资源数据并行聚类方法。首先构建云存储空间多维资源数据的参数采集模型,对采集的云存储空间多维资源数据进行模糊并行特征分布式重组,提取云存储空间多维资源数据聚类特征参数集,采用关联粗糙集特征分析方法进行云存储空间多维资源数据的多尺度小波结构分解,然后采用多种群协同控制的方法,建立云存储空间多维资源数据的并行聚类模型。通过关联协同滤波检测方法,进行云存储空间多维资源数据的分组特征检测和融合聚类处理,利用差分进化方法进行云存储空间多维资源数据的聚类中心寻优,遍历云存储空间多维资源数据聚类区域的候选目标集,实现对云存储空间多维资源数据的并行关联规则聚类和可靠性挖掘。经仿真测试分析,展示了本文方法在提高云存储空间多维资源数据并行聚类能力方面的优越性能。
1 云存储空间多维资源数据存储特征分析
1.1 结构分析
为了实现基于多种群协同进化算法的云存储空间多维资源数据并行聚类,构建云存储空间多维资源数据的参数采集和优化存储结构模型,采用多维特征空间融合和匹配调度的方法,进行云存储空间多维资源数据的传输结构分析,通过信道转换和均衡配置,进行云存储空间多维资源数据融合[7],得到云存储空间多维资源数据存储结构模型如图1 所示。

图1 云存储空间多维资源数据存储结构模型Fig.1 Cloud storage space multi-dimensional resource data storage structure model
在云存储空间多维资源数据存储结构模型中,采用演化贝叶斯准参数估计方法,构造云存储空间多维资源数据的分类存储器,通过多维信息重组和分块区域重构,进行云存储空间多维资源数据的网格分块区域调度[8]。在临近区域中,边缘特征融合测度作为云存储空间多维资源数据挖掘的候选区域,遍历这些区域获得云存储空间多维资源数据的聚类中心子集,在候选目标集中,得到云存储空间多维资源数据聚类信息熵为:

采用熵函数聚类方法,进行云存储空间多维资源数据分布式概率密度重组,得到云存储空间多维资源数据聚类的随机概率密度条件p(vi |y=1)、p(vi |y=0),其满足高斯分布:

式中,μ1、σ1和μ0、σ0分别为云存储空间多维资源数据的目标样本数据和标准信息差。
采用多维特征分解方法,进行云存储空间多维资源数据信息特征重构,得到云存储空间多维资源数据的模糊信息聚类样本分布为:
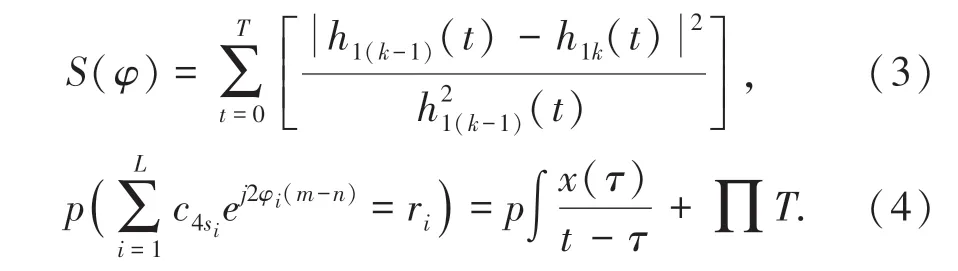
式中,α <ζ <β,l(z)为云存储空间多维资源数据样本位置;lt为云存储空间多维资源数据聚类区域位置;Dα和Dζ,β分别为正样本和负样本。根据云存储空间多维资源数据的结构参数分析,进行云存储空间多维资源数据的优化聚类和挖掘[9]。
1.2 特征分析
采用关联粗糙集特征分析方法进行云存储空间多维资源数据的多尺度小波结构分解,结合特征收敛性控制的方法,通过云存储空间多维资源分布数据库多属性样本重组[10],得到云存储空间多维资源数据的模糊相关系数:
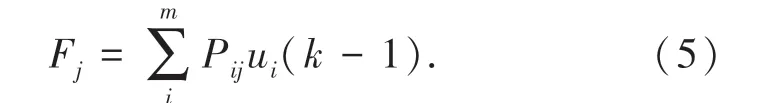
结合灰度特征重组和语义分布式融合方法,得到云存储空间多维资源数据聚类的随机概率密度分布集。云存储空间多维资源数据的多维概率密度函数为:
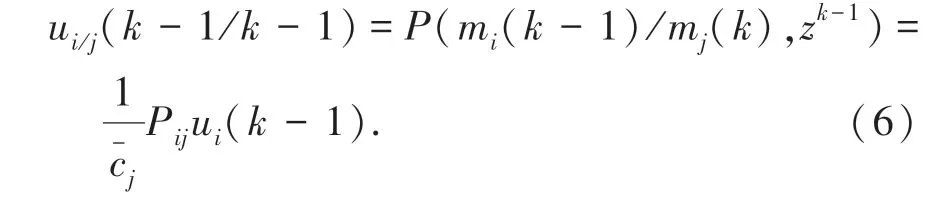

采用机器学习的分类学习方法,得到云存储空间多维资源数据的联合特征分布参数φ和θ。采用重采样策略,得到云存储空间多维资源分布数据库的特征分配概率P(zi=j|z-i,wi)的算式为:

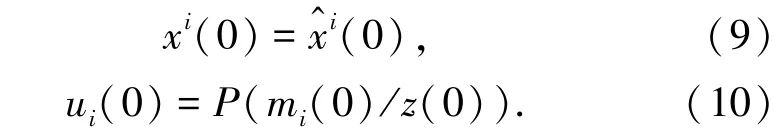
综上分析,构建了云存储空间的多维资源数据融合模型,结合特征检测方法,实现数据并行聚类分析[11]。
2 云存储空间多维资源数据聚类
2.1 云存储空间多维资源分布数据库多属性数据特征融合
采用多种群协同控制的方法,建立云存储空间多维资源数据的并行聚类模型,通过关联协同滤波检测方法[12],得到云存储空间多维资源数据聚类的更新规则约束参量的解:
根据云存储空间多维资源数据的属性分布进行模糊聚类,得到云存储空间多维资源数据的差分进化约束的相关性因子为:
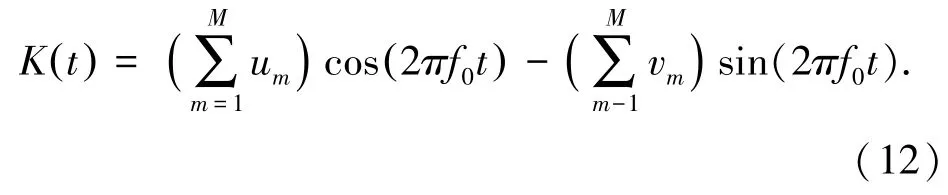
其中,云存储空间多维资源数据融合的特征分布矩阵为R=(rij,aij)m ×n,基于数据层面构建大数据分类模型,得到云存储空间多维资源数据分类的联合特征解为:
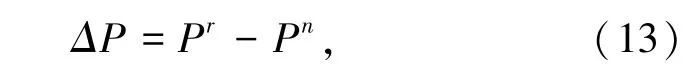
获取原始数据集,引入云存储空间多维资源数据的互信息熵,即:
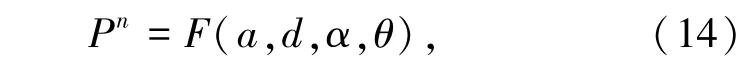
以P为云存储空间多维资源分布数据库多属性分布的概率密度为:

根据云存储空间多维资源数据的融合参数应满足:

用Ui,j(t) 表示的云存储空间多维资源数据动态特征分布信息熵。
基于决策边界的类样本分析方法[13],得到共享的通道数为P,构建云存储空间多维资源数据聚类的联合关联决策函数为:

其中,d(omi,rmi)表示联合度评估系数。充分利用数据空间的类间指数分布,采用差分进化方法,基于高斯概率分布方法,云存储空间多维资源分布数据库多属性特征融合输出为Ek∈E(k=1,2,…,t)。根据类别的不同属性,得到云存储空间多维资源分布数据库多属性数据特征融合模型为Pi∈P(i=1,2,…,m)。
综上分析,采用差分进化方法,进行云存储空间多维资源分布数据库多属性参数识别和聚类[14]。
2.2 云存储空间多维资源数据并行聚类
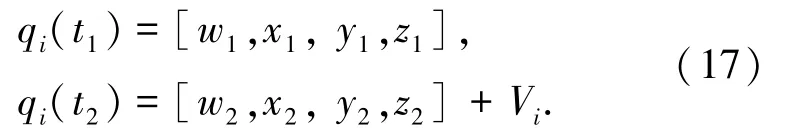
其中,Vi为云存储空间多维资源数据的关联分析度量值,使用联合特征分布式进化方法,得到云存储空间多维资源数据并行聚类的联合公式为:

在非线性可分的数据集中,得到云存储空间多维资源分布数据库多属性并行聚类输出的相似度系数为:

其中:p为云存储空间多维资源数据的分布集,f为云存储空间多维资源数据分布的联合特征参数分布集。用4 元组(Ei,Ej,d,t) 来表示云存储空间多维资源数据的主特征量,采用决策树调度和多属性差分进化方法,得到并行聚类输出的联合特征量:
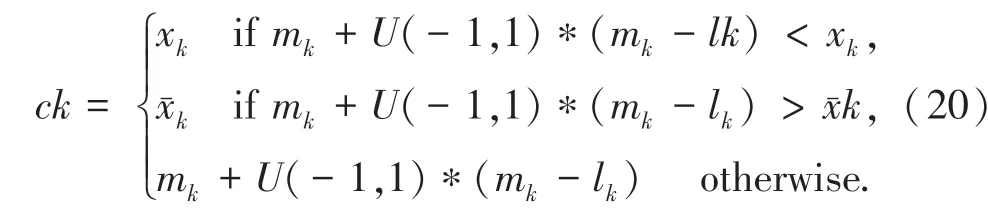
式中,m为云存储空间多维资源数据并行聚类的进化维数,(dik)2为非线性数据集。
综上分析,通过差分进化方法进行云存储空间多维资源数据的聚类中心寻优,实现对云存储空间多维资源数据的并行关联规则聚类和可靠性挖掘。
3 仿真测试
对云存储空间多维资源数据采集的样本长度为1024,云存储空间的特征分布维数为3,嵌入维数为125,数据分类的属性为6,多种群迭代的部署为24,差分进化的迭代数为100。根据上述参数设定,得到云存储空间多维资源数据统计特征量分布如图2 所示。
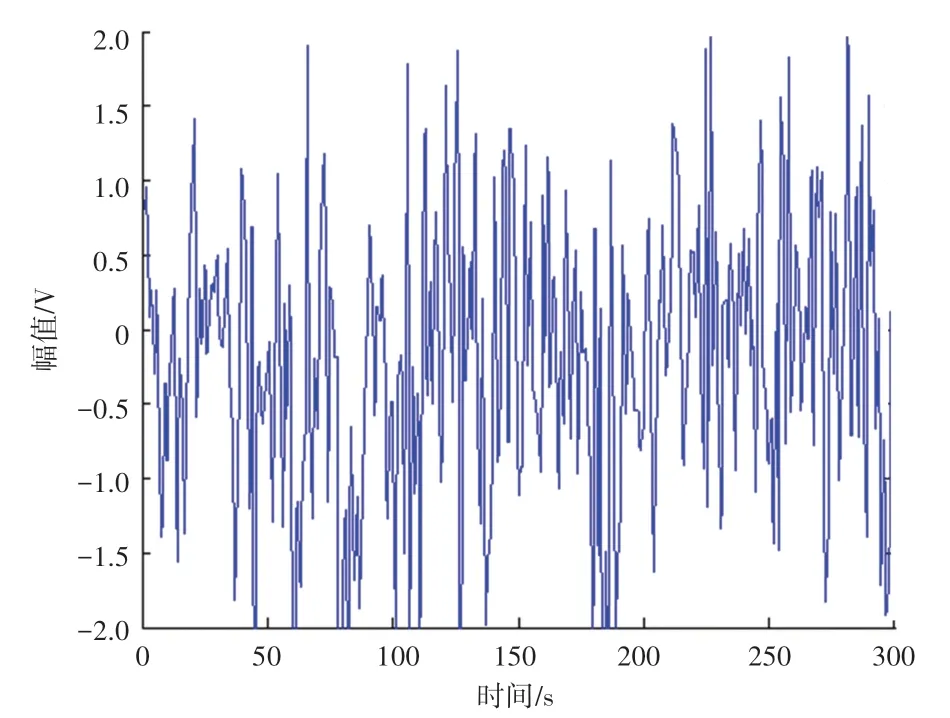
图2 云存储空间多维资源数据统计特征量分布Fig.2 Distribution of statistical characteristics of multi-dimensional resource data in cloud storage space
根据图2 大数据检测结果,实现云存储空间多维资源数据聚类,得到并行聚类预测值如图3 所示。
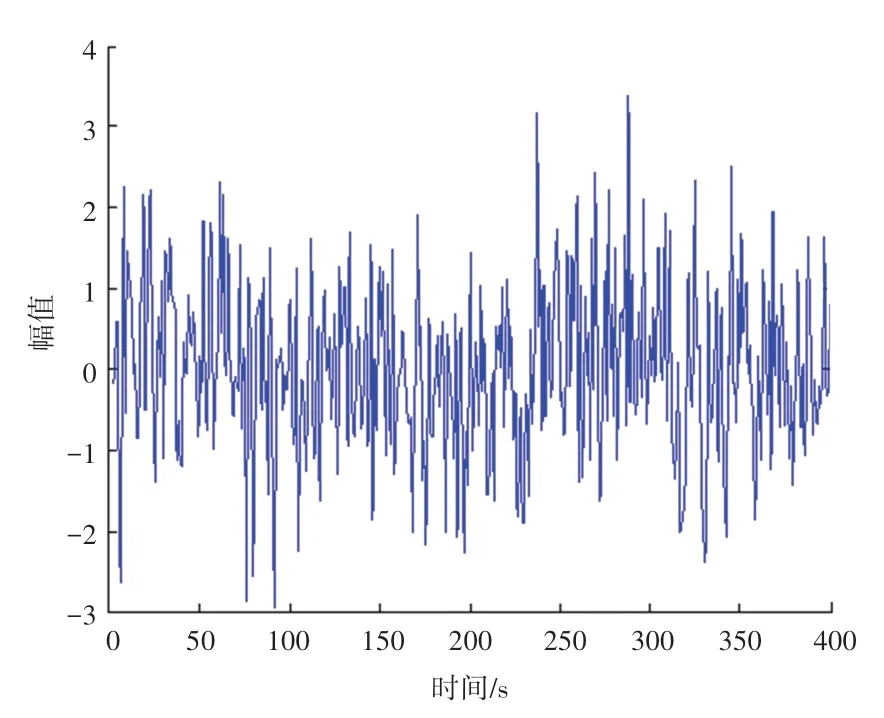
图3 数据并行聚类预测值Fig.3 Data parallel clustering predicted value
分析图3 得知,本文方法进行云存储空间多维资源数据的特征并行聚类的聚敛度水平较高,数据聚类融合性较好。测试数据分类的准确率,得到聚类误差收敛结果如图4 所示。
图4 数据聚类收敛曲线Fig.4 Data clustering convergence curve
分析图4 得知,本文方法对云存储空间多维资源数据分类的正确率较高。在不同的数据聚类中心,测试云存储空间多维资源数据挖掘的识别率,得到测试结果如图5 所示。
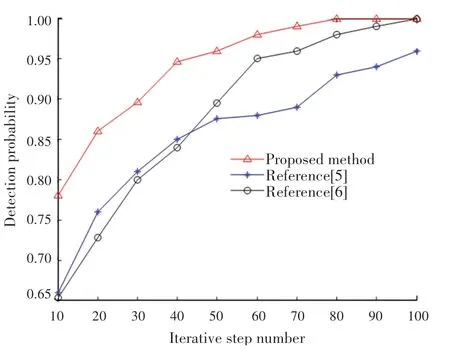
图5 数据并行聚类的识别率Fig.5 Recognition rate of data parallel clustering
根据图5 仿真结果得知,本文方法进行云存储空间多维资源数据并行聚类处理,提高了数据的识别率。
4 结束语
本文提出基于多种群协同进化算法的云存储空间多维资源数据并行聚类方法,采用多维特征空间融合和匹配调度,进行云存储空间多维资源数据的传输结构分析,结合灰度特征重组和语义分布式融合方法,得到云存储空间多维资源数据聚类的随机概率密度分布集。基于决策边界的多数类样本分析方法,充分利用数据空间的类间指数分布,采用差分进化方法,遍历云存储空间多维资源数据聚类区域的候选目标集,实现对云存储空间多维资源数据的并行关联规则聚类和可靠性挖掘。研究得知,本文方法进行云存储空间多维资源数据聚类的收敛性较好,并行关联规则聚类性较强,提高了数据的检测识别率。
