一种片上网络拥堵感知的自适应容错路由算法
2018-03-27杭彦希徐金甫南龙梅
杭彦希,徐金甫,南龙梅
1(解放军信息工程大学,郑州 450001) 2(复旦大学 专用集成电路与系统国家重点实验室,上海 200433)
1 引 言
随着大数据和云计算等大批量、高速数据处理应用的出现,单核处理系统已经远远不能满足数据处理的需求,基于片上网络互连的多核系统逐渐成为高性能数据处理系统发展的趋势.而随着片上核数的增加以及工艺尺寸的不断缩小,由生产缺陷、工艺偏差和老化等原因导致的片上故障问题越来越突出,文献[1]指出,天河、神威等超级计算机系统中处理器的核数已达到百万量级以上,其平均无故障时间达到数小时已十分困难,高可靠性已成为多核处理系统发展的重要方向.而容错路由算法对于在故障条件下仍能保证系统的性能有着重要的作用,对容错路由算法的研究是多核系统可靠性研究的一个重要方面.
目前已有大量的文献展开了对容错路由算法的研究,文献[2]提出了一种较为经典的容错的分布式可重构路由算法,每个节点感知其周围8个邻节点的故障状态,采取绕行路由的方式避开故障节点,并禁止东北角转向来避免死锁,但是其存在流量不均衡的问题,并且只能容忍一个节点故障.文献[3]提出了一种适应性容错路由算法Gradient,将目的节点分为8个区域,对于每个区域当前节点采用不同的输出端口优先级顺序路由数据包,但是这种方法输出端口优先级固定,且未充分考虑网络的拥堵状态.文献[4]提出了一种高度可靠的容错路由算法,但其需要在路由器中设置路由查找表,虽然增大了灵活性,但是面积开销大且扩展性不强.文献[5]提出了一种两跳内故障信息感知的方法,但是其对于部分双链路故障无法覆盖,且算法实现较复杂.文献[6]提出了一种基于逻辑电路实现的分布式容错路由uLBDR,减少了面积开销,但是故障覆盖率不高,且其中的LBDRfork+dr算法只适用于虚拟直通交换方式,通用性不强.文献[7]也提出了一种基于逻辑电路实现的成本节约的路由算法,解决了LBDRfork+dr算法只能在虚拟直通交换方式中使用的限制,但是其故障覆盖率仍然不高.
在实际的片上网络应用中,经常会发生通道拥堵情况进而阻止数据包的路由,而拥堵感知路由算法可以缓解片上拥堵状态.按照拥堵信息感知区域,可以将其分为本地拥堵信息感知算法、区域拥堵信息感知算法以及全局拥堵信息感知算法.对于本地拥堵信息感知算法,文献[8]利用当前节点输出端口可用缓存数作为拥堵度量值.文献[9]提出了一种DyAD路由算法,其利用下游路由器输入端口可用缓存槽数来判断拥堵状况.文献[10]提出利用候选通道一定时间内路由的微片数量来量化每个通道的带宽进而判断拥堵.对于区域拥堵信息感知算法,文献[11]提出一种RCA区域拥堵感知算法,其收集各节点本地拥堵状态并通过一个监控网络传输,但是其面积开销过大.文献[12]提出利用邻节点在目的节点方向的候选通道的可用缓存槽总数来判断当前节点的各个候选输出端口的拥堵状态,其性能高于DyAD路由算法,但是其并未考虑邻节点的拥堵状态.文献[13]提出利用下游节点的通道状态和交叉开关状态来判断拥堵信息.文献[14]提出利用下游节点状态和可用路径数来判断拥堵信息,但是这些方法仍存在拥堵信息判断不充分且未考虑故障等问题.对于全局路由感知算法.文献[15]提出了一种片上网络全局拥堵感知的方法(Global Congestion Awareness,GCA),该方法提出在头微片空闲位中增加流量向量,并在路由器中加入拥堵记录及映射单元,通过头微片与路由器的交互进而获得整个网络的拥塞状态,但其受到微片大小的限制,实用性并不强.根据文献[16]大量的仿真实验,可以发现拥堵主要发生在本地区域的部分节点,并不需要通过文献[15]提出的方法去感知全局的拥堵信息,相反会带来更大的开销.以上的这些拥堵感知的路由算法并未考虑到故障发生的情况,这对于路由算法的研究是不完善的.文献[17]提出了一种粗粒度和细粒度的前瞻性容错路由算法,设定各端口输出优先级,利用下游节点输入端口的缓存数作为拥堵判断值,采取一种故障编码与解码方案,可以感知当前节点周围36条链路的故障情况,最后计算各个端口的权重值,选择权重值最小的端口路由数据包,这种将故障信息和拥堵信息统一考虑的方法,不但计算复杂效率低下,而且面积开销很大.文献[18]基于LBDRdr算法提出了一种拥堵感知的二维片上网络容错路由算法,但是其故障覆盖率低,且采用的拥堵感知方法面积开销很大.目前对于片上路由算法的研究主要存在两个问题:①缺少高效的故障与拥堵感知方法;②在故障和拥堵都存在的情况下,缺少一种高效的路由算法.
综合以上问题,本文提出了一种高效的拥堵与故障信息感知的片上网络容错路由算法.文章有以下几点创新之处:①结合故障实时检测方法,提出一种新颖的节点邻32链路故障感知机制;②根据路由器延时模型,提出了一种高效的拥堵信息感知机制;③对故障处理与拥堵处理进行优先级划分,提出一套完备的自适应容错机制,并基于逻辑电路设计了故障处理模块和相应的拥堵处理模块.
2 故障及拥塞感知机制建立
为节约片上资源,本文算法的实现基于传统的五端口无虚通道路由器,该路由器由东(E)、南(S)、西(W)、北(N)和本地(L)五端口、各端口输入缓存、路由计算模块(Routing Compute,RC)、交叉开关分配模块(Switch Allocate,SA)以及相应的连接线路组成.传统的无虚通道路由器容易引起死锁,本文采取的死锁避免方式将在下文进行介绍,首先介绍本文提出的故障及拥塞感知机制.
2.1 故障感知机制
故障感知机制主要包括故障模型建立、故障检测与感知方法设计及故障感知区域建立.故障感知机制对于路由算法的容错性能至关重要,一个好的故障感知机制能极大的增加算法对故障的覆盖率且能最大程度得减小因容错给片上网络带来的性能损失.结合文献[5,19,20]的故障感知机制,本文提出一种新颖的节点邻32链路故障实时感知机制.
2.1.1 故障感知区域
本文提出的故障感知机制是一种粗粒度的区域故障感知机制,其故障模型为将单向链路故障等效为双向链路故障,将节点故障等效为与之相连的四条双向链路故障.采用一种周期性故障检测方法,每个路由节点在一定周期内发送测试向量给邻节点,获取到响应向量后,与存储在发送节点内的正确向量做对比,若相同则认为链路无故障,否则认为链路发生故障.通过这种方法,每个节点能实时掌握与之相连的四条链路状态,但是通过这种方法定义的故障感知区域较小,对故障的覆盖率较小.文献[5,19]提出了一种两跳范围的故障感知区域,在一定程度上能覆盖大部分的单链路故障,但对部分双链路故障无法容忍.本文提出一种故障信息传播机制,将故障感知区域扩大到图1所示的区域.假设图中节点11为当前节点,此时节点11可以感知到虚线框内链路①②③④⑤⑥⑦⑧共8条链路状态,将这些链路定义为当前节点的北部邻链路,其故障状态分别表示为FN,FNW,FNE,FNWN,FNN,FNEW,FNNW,FNNE,当其值为1时表示未发生故障,为0时表示无故障发生,并将①定义为北部直接邻链路,②③⑤定义为北部初级邻链路,④⑦⑥⑧定义为深级邻链路.
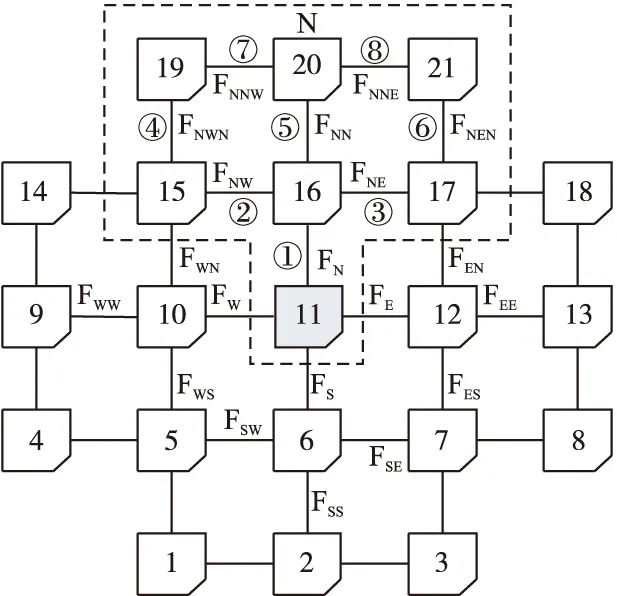
图1 节点邻32链路故障实时感知区域示意图Fig.1 Schematic diagram of the node′s adjacent 32 link online fault-aware region
2.1.2 故障信息传播方案
为实现这种节点邻32链路故障实时感知机制,本文设计了如图2所示的故障信息传播方案,在每个路由器内部增加两级故障感知信息传播模块(Fault-Aware Propagating,FAP),第一级为FAP1,第二级为FAP2,FAP1用于传递初级邻链路故障信息,FAP2用于传递深级邻链路故障信息,而直接邻链路信息可直接通过邻节点得到.
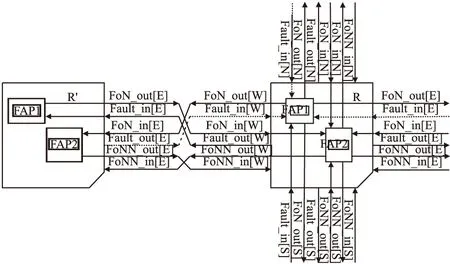
图2 故障信息传播方案Fig.2 Scheme of propagating of fault information
以图2中节点R的西部端口为例为例,Fault_in[W]和Fault_out[W]是西部直接邻链路R-R′的故障输入和输出信息,位宽都为1比特;FoN_in[W]代表R′的N,S,W端口的西部初级邻链路故障信息,位宽为3比特;FoN_out[W]为R的N,S,E端口的东部初级邻链路故障信息,位宽也为3比特;FoNN_in[W]代表R的西部深级邻链路故障信息,位宽为4比特;FoNN_out[W]为R的东部深级邻链路故障信息,位宽也为4比特.每个节点的各个端口只需存储8条邻链路信息,故在各端口增加3比特的故障状态寄存器即可存储节点周围32条链路的故障状态.
2.2 拥塞感知机制
片上拥堵会极大影响片上网路的性能,不仅在出现故障时会发生片上拥堵,在处理大数据应用时也会出现片上拥堵,常用的拥堵感知方案成本高,通用性不强,如何高效的避免片上拥堵是片上网络性能研究的重要方面.为此,本文提出了一种区域性低成本的片上网络拥塞感知机制,其设计相应的路由器延迟模型来衡量某一通道拥堵情况,并提出相应的拥塞信息计算方案.
2.2.1 路由器延迟模型
文献[21]指出路由器延时指数据包包头从接受路由器服务到存储在下游路由器的输入缓存的时间,也即数据包包头从上游路由器输出端口输出开始到下游路由器输出端口输出结束的时间,主要分为两部分,其结构如图3所示.
第一部分延时是通道延时,指数据包从路由器R输出端口输出到存储在路由器R′中的时间,由缓存恒定延迟(τ′)以及缓存发送延迟(βo2i)构成,第二部分是交叉开关延迟,由路由器服务时间(τ)以及端口分配延时(ρi2o′)构成,则路由器总的延时可以描述为
L=τ′+βo2i+τ+ρi2o′
(1)
(1)式中τ′指输入缓存空时,包头存储到缓存中的时间,是固定延时.τ指路由器无拥堵时,路由器转发一个微片所需的延时,也为固定值.βo2i指从本地路由器O端口输出的数据包等待下游路由器输入方向i缓存空的时间,其值为下游路由器输入端口i输入缓存排空的时间,其值可近似为

(2)
(2)式中NBj指下游路由器端口j处的输入缓存占用数,j指端口i处的输入缓存占用数,fijp指输入端口i与输入端口j向同一端口p输出的概率,其值为
fijp=fip×fjp,i≠j
(3)

图3 路由器延迟模型Fig.3 Delay model of router
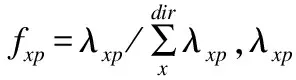
(4)
ρi2o′指数据微片平均等待得到下游路由器分配的输出端口O′的时间,如果其输出端口分配失败就会被堵塞直至得到交叉开关的确认信号.其值可表示为
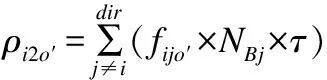
(5)
在这里,因为下游路由器输入端口i的微片的输出端口O′固定,O′∈COC,所以fio′=1,则
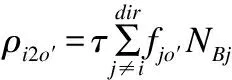
(6)

COC′指下游节点候选输出通道集合,N(COC′)为下游节点候选输出通道的数量,NC代表除下游节点的输入通道和候选输出通道外的竞争通道的数量,一般为1/3.则路由器的延时可以描述为
dir={E,S,W,N,L}
(7)
其中O为本地路由器的输出方向,i为与O相对的下游路由器的输入方向,O′为下游路由器的输出方向.
2.2.2 拥塞信息计算方案
本文利用下游路由器的延迟时间来衡量某一通道的拥塞程度,即对任一当前节点,分别计算出下游节点的预测延迟时间,选择延迟时间最短的下游节点路由数据包.可通过(8)中判别式进行判断.
(8)
因为τ′,τ在路由器设计好后即为固定值,则(8)式可转化为:
(9)
本文定义δo为某当前节点输出端口O的拥塞度量值,其值为
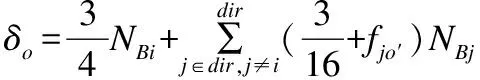
(10)
其中
o′∈coc′
为计算出当前节点各端口的δo,各节点需实时获得各方向下游节点的输入缓存占用数,需要增加多余的链路线来传输这些拥堵计算信息,其传输方法如图4所示.

图4 拥堵信息传输方法示意图Fig.4 Schematic diagram of method for the fault information propagation
NB[i][j]为当前节点方向i处的邻节点的缓存占用信息,i指下游邻节点的方向,i∈{E,S,W,N},j指位于下游邻节点j方向的缓存数,j∈{E,S,W,N,L},如图所示,假设图中R为当前节点,NB[E][E]_out指当前节点向其E方向的邻节点发送其E端口的缓存占用数,NB[E][E]_in为当前节点接收的在其E方向的邻节点E端口的缓存占用数,每条链路需增加2*5*log2(NS)的链路,NS为输入FIFO中的缓冲槽数目,若NS为4,则每条链路共需增加20bits的线.通过这种拥堵信息传输方法,只需增加少量链路线并在路由器中增加少量计算单元,即可保证每个节点都实时掌握其邻节点各输入端口的缓存占用情况.
通过这种拥堵感知机制,拥堵选择策略可建模为
SOC=argminδo,o∈COC
其中SOC代表当前节点选择的输出通道(Selected Output Channel),COC代表当前节点的候选输出通道(Candidate Output Channel).每个节点在无故障的情况下,均可根据目的节点与当前节点的关系,算出各个候选通道的拥堵度量值,并选择拥塞程度低的端口路由数据包,能有效缓解拥堵情况.由文献[19]可知,拥堵主要发生在本地区域的部分节点,因此采用这种区域性拥塞感知机制可以覆盖大部分的片上网络拥堵情况,对于片上资源有限的多核互连结构来说,这种方法是高效能的.
3 路由算法设计
3.1 算法描述
结合前文提出的故障及拥塞感知机制,本文实现了一种基于逻辑电路的拥堵感知的分布式容错路由算法,能同时处理故障以及拥塞情况,并且通过设置路由转向允许位Rpq来避免网路死锁的发生.算法主要思想是根据故障优先级大于拥堵优先级的原则,先利用故障逻辑电路处理片上故障情况,再通过拥塞处理模块评估拥堵情况,最后得到数据包转发方向.整个路由计算逻辑由组合电路构成,主要分为故障处理逻辑和拥堵处理模块,其整体框图如图5所示.

图5 路由计算框图Fig.5 Diagram of routing computing
故障处理逻辑根据当前地址和目的地址的关系以及故障状态,得到数据包输出的候选端口,再由拥塞处理模块根据拥塞信息计算出最终的数据包转发路径.
其算法描述如图6所示.算法输入包括目的节点信息、当前节点信息、链路故障信息以及路由转向允许位,根据故障逻辑得出候选端口信息COC(N2,S2,W2,E2),N(COC)指候选端口数目,如果N(COC)为0,即因故障无可用输出通道,则根据绕路逻辑采用非最短路径路由数据包;如果N(COC)为1,即只有唯一的候选输出通道,则无需考虑拥堵情况,以数据包能正确路由到目的节点为原则,选择唯一可用的输出通道;如果N(COC)为2,即存在两个候选输出通道,根据前文的拥堵度量方法,选择拥堵值低的通道路由数据包,若拥堵值相同,任意选择一候选通道路由数据包.

ProcedureoftheCAFTAlgorithm1CAFT(in:cur,des,Flink,Rpqout:SQC)2{COC←Fault_processing_logic(cur,des,Flink)3ifN(COC)=0 thenSOC←Deroute_logic(cur,des)4ifN(COC)=1 thenSOC←Avaliable(COC)5ifN(COC)=26 δ[]←07 forallch1∈COCdo8 δo[ch1]←NBi9 COC_d←Competingchannelsindownstreamrouter10 forallj∈COC_ddo11 NBj←inputbufferdepthofjdirectionindownstreamrouter12 δ1[chl]+=(3/16+fjo′)×NBj13 endfor14 δ[ch1]=δo[ch1]+δ1[ch1]15 endfor16 C[]←chs.t.δ[ch]=min(δ[])17 ifC[].size()=1 then SOC←C[0]18 elseSOC←Random()}
图6 CAFT算法
Fig.6 Algorithm of CAFT
3.2 故障处理逻辑设计
故障处理逻辑首先提取出当前节点及目标节点的坐标信息,经由一个比较器电路计算出目标节点与当前节点的相对位置,其示意图如图7所示.
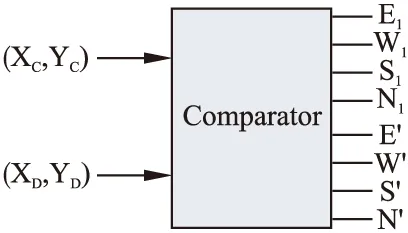
图7 比较器电路Fig.7 Comparator circuit
此电路输出8个位置信息,前四个信息dir1代表目的节点是否在当前节点的dir方向且在dir方向上的距离差恰好为1,当dir1为1时表示目的节点在当前节点dir方向上且距离为1,否则为0;后四个信息dir′代表目的节点是否在当前节点的dir方向,当dir′为1表示目的节点在当前节点dir方向上,否则为0.
故障处理逻辑最终是为了计算出候选端口N2、E2、S2、W2,而为了实现有效的路由转向及避免死锁,本文还在节点各端口增加路由转向允许位(Routing bits),表示为Rpq,其代表从当前节点p端口输出的数据包是否可以在下游节点的q方向进行转向.当Rpq为1时,表示允许转向,为0则表示禁止转向.例如在某节点的N端口,存储有RNW及RNE,其代表从当前节点N端口输出的数据包能否能在下一节点进行向N或向E的转向.
利用前文定义的故障信息及转向允许位得到初步的无故障端口转发信息,各端口具体逻辑如下.
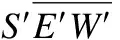


图8 N2端口故障处理逻辑Fig.8 Fault processing logic of N2 port
3.3 拥堵处理模块
由故障处理模块得到一个4比特的候选端口信息(Candidate Output Channel,COC),分别为N2、E2、S2、W2,为1表示可以转发,为0表示禁止转发.拥堵处理模块的功能就是根据拥塞感知机制,计算出可转发候选端口的各个方向的拥塞值,选择拥堵程度最低的方向路由数据包,整个拥堵处理模块示意图如图9所示.
图中候选解码模块(Candidate Decoder,CD)用于解析COC信息,因为COC一共有三种状态,分别为全为0状态,只有一个为1的状态及只有两个为1的状态,当COC出现全0时表示无可用转发通道,则通过绕路由模块选择输出通道;当COC只有一个为1时,选择只能转发的通道即图中的C0进行转发;当COC只有两个为1时,由CD模块选出为1的候选端口C1及C2,输入到图中虚线框内的拥堵值计算模块,选择拥堵值最小的端口进行数据包转发.
3.4 死锁及活锁避免方法
死锁及活锁避免是路由算法需要考虑的重要方面,本文通过设置路由转向允许位来禁止一些特定的转向以达到死锁避免,主要方法是将转向模型中一些禁止的转向转换成转向允许位,1表示允许转向,0表示禁止转向,常用的转向模型由XY转向模型,OE转向模型.为提高片上网络性能本文利用文献[22]提出的RTM转向模型,列数非3能整除的列中的所有节点禁止NW和SW转向,即设置这些节点的N端口的RNW及S端口的RSW为0,其余均为0;列数能被3整除的列中的所有节点禁止ES和EN转向,即设置这些节点的E端口的RES及E端口的REN为1,其余均为0,通过这种方式可以大大增加因禁止转向导致的片上网络性能的损失.为了避免产生活锁,本文在拥堵处理模块中增加绕路由模块(Deroute Logic),保证在无最短路由时通过采用非最短路由方式完成路由功能.
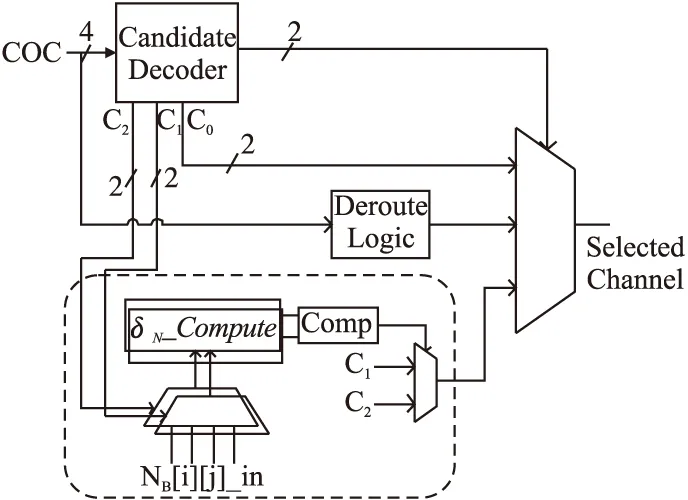
图9 拥堵处理模块示意图Fig.9 Schematic diagram of congestion processing module
4 实验结果
在路由算法性能评估方面,本文修改了开源的周期精确的片上网络仿真器作为实验平台,搭建8*8的2D-mesh拓扑结构,路由器设置为无虚通道,端口缓存深度为4个数据微片,数据包大小为8个微片,设置仿真总时间为23000个周期,前3000个周期为warmup时间;在路由器面积开销方面,本文采用SMIC 55nm CMOS标准单元库对本文所提出的路由器进行综合.
4.1 性能评估
本文实验对象主要是基准XY维序路由算法,文献[12]提出的NoP算法,文献[13]提出的PCAS(DWSA)算法,文献[7]提出的CERI算法,以及本文提出的(Congestion-aware Fault-Tolerant routing,CAFT)算法.实验方案为在不同故障模式下测试5种算法在不同流量场景下的平均延时和吞吐率.如图10所示,为无故障、均匀流量模式下各算法的延迟和吞吐率对比图.均匀流量模式一般在仿真时会用到,在实际的应用中这种流量情况不会出现,从图10中可以看出,XY维序路由算法以及CERI-XY算法的性能最优,CAFT算法性能次之,NoP算法性能最差.这是因为尽管XY维序路由算法不是自适应的,但是在均匀流量模式下,各个节点的流量状态相似,相当于XY路由算法掌握了全局性的长远流量信息,并且其采取的先X方向后Y方向的路由方式使得片上的网络流量分布更加均匀,减少了拥堵的发生.而CERI-XY算法在无故障下等效于XY算法,性能也较高,CAFT算法因为采用了RTM转向模型,在一定程度上能均匀一定的流量,提高在均匀流量模式下的性能,且在低注入率下,CAFT算法的数据包平均延时还是比较小的.对于NoP和PCAS(DWSA)适应性路由算法,其路径较多采用了Z字形的路由方式,使得流量分布随着注入率增加而越来越不均衡,增加了拥堵情况的发生进而减小了性能.
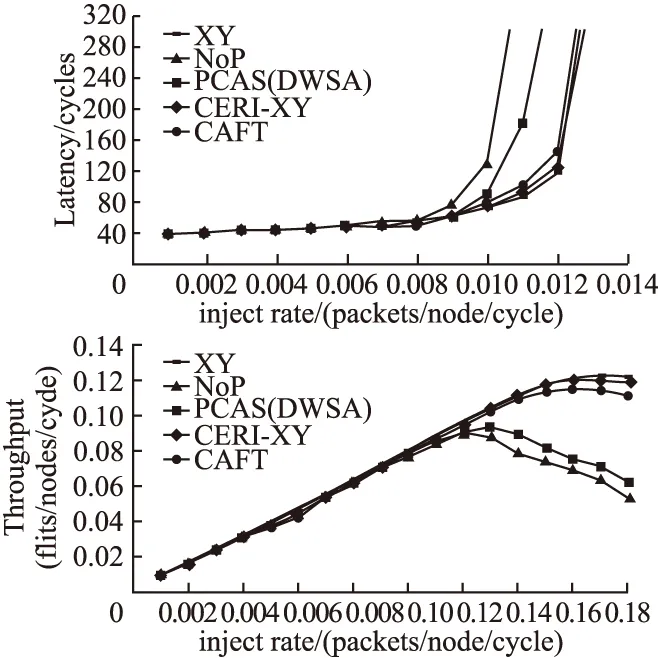
图10 无故障、uniform流量模式下延时与吞吐率对比图Fig.10 Contrast diagram of delay and throughput in the mode of no-fault transope traffic
图11是在无故障,transope流量模式下各算法的延时和吞吐率对比图,transope是一种非均匀流量模式,源节点与目的节点的关系为Di=Si+b/2 mod b,其中Si(Di)指源地址(目的地址)的第ibits.从图中可以看出,在非均匀流量模式下,XY和CERI-XY路由算法的性能最差,因为它们缺少对网络拥堵状态的感知,适应度很低;NoP和PCAS(DWSA)算法的性能居中,因为其能感知到网络的拥堵状态,具有一定的自适应度;CAFT算法的性能最佳,主要原因在于其考虑的拥堵因素比PCAS(DWSA)算法更充分,且采用了RTM转向模型.CAFT算法相比较于NoP算法饱和吞吐率改善约为12.78%,相比较于PCAS(DWSA)算法饱和吞吐率改善约为3.34%.
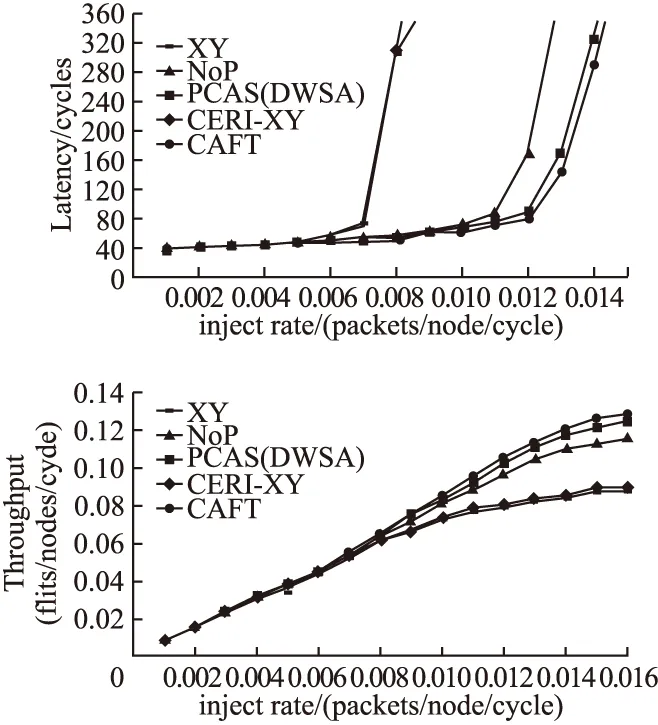
图11 无故障、transope流量模式下延时与吞吐率对比图Fig.11 Contrast diagram of delay and throughput in the mode of no-fault transope traffic
为比较算法在故障模式下的适应性,设定固定位置,固定数目的链路故障,并且假设故障已经被检测到且在系统运行中不会改变,设定故障比例约为总链路的5%,同时为更接近于实际片上应用环境,设定流量模式为transope.实验结果如图12所示,从图中可以看出,XY算法的性能最差,在实际的实验中也可以发现XY算法的丢包率非常严重,这是因为XY并未采取任何容错措施,适应性最差,为体现CERI算法的容错性,选用CERI-OE,虽然其能容忍一定的错误,但是性能还是不高,NoP和PCAS(DWSA)算法因为采取了一定的拥堵判断措施,可以容忍部分的链路故障,但是性能仍然很差,对于CAFT算法,将故障和拥堵情况都考虑在内,其性能明显优于上述的算法.

图12 5%链路故障,transope流量模式下延时与吞吐率对比图Fig.12 Constrast diagram of delay and throughput in the mode of 5% fault transope traffic
4.2 面积开销与分析
为实现本文所提出的路由算法,需要在路由器中增加相应的故障与拥塞感知模块以及相关的路由计算逻辑,在评估时不考虑故障实时检测模块.利用SMIC 55nm CMOS标准单元库对路由器进行综合,与基准路由器进行比较,并计算出其与基准路由器的相对面积比(Relative Area),其实验结果如表1所示.
表1 CAFT路由器面积开销
Table 1 Comparison of different routing algrithms on area

RouterArea/μm2RelativeAreaXY15730.161CAFT20291.911.29
本文路由器面积开销主要集中于故障感知模块以及拥堵处理模块,将本文所提路由器与NoP、PCAS(DWSA)、CERI路由器的面积开销进行对比,引入性能提高与面积开销比(Ratio of Performance improvemet and Area overhead,RPA),其代表在不同模式下路由器相对于基准路由器的性能提升百分比与面积开销增加百分比的比值,性能比较对象是饱和吞吐率.注:本文路由器面积或性能对比都是相同的时钟频率下,其对比结果图如表2所示.
表2 各路由器能效对比图
Table 2 Comparison fo different routers on RPA
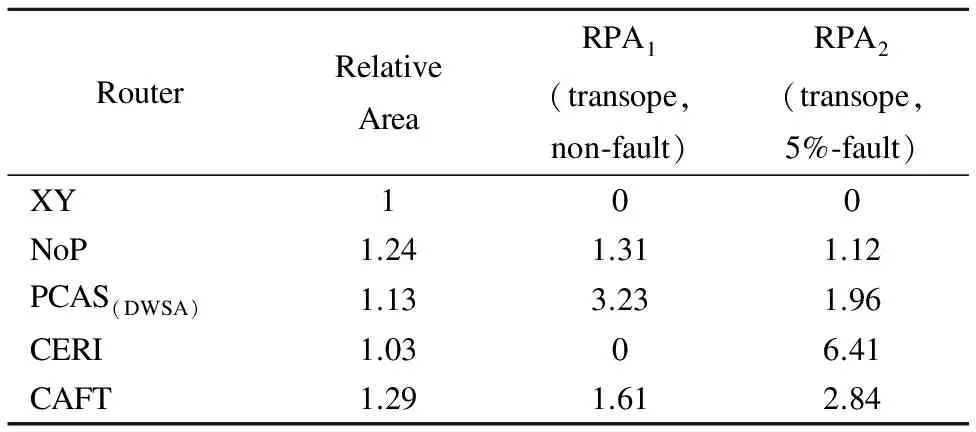
RouterRelativeAreaRPA1(transope,non⁃fault)RPA2(transope,5%⁃fault)XY100NoP1.241.311.12PCAS(DWSA)1.133.231.96CERI1.0306.41CAFT1.291.612.84
从表2中可以看出,CAFT算法在无故障和故障模式下都有着较好的性能提高与面积开销比,是一种能适应复杂模式的高效的自适应容错路由算法.
5 结 语
本文选取片上网络自适应容错路由算法作为研究对象,针对目前片上路由算法处理复杂故障与拥堵情况能力不足且面积开销大的缺点,设计了节点周围32条链路故障状态感知的方法,并扩展路由器延迟模型,根据邻节点各端口的缓存占用数,计算出当前节点各候选通道的拥塞度量值,按照故障处理优先级大于拥塞处理优先级的顺序,基于逻辑电路设计出高效的能适应复杂片上状态的路由算法.在无故障模式下,能确保数据包按拥堵值最低的方向路由;在故障模式下,以完成数据包正确路由为基本目标,能实现对片上故障的容忍,并在一定程度上均衡网络流量,同时为节省片上资源,引入一种RTM转向模型,在无虚通道的情况下既能保证算法无死锁也能保证网络性能达到最大.
[1] Ge Wei,Guo Li,Li Jing-hai,et al.The thinking about supercomputing development strategic direction[J].Proceedings of the Chinese Academy of Sciences,2016,31(6):614-623.
[2] Zhang Z,Greiner A,Taktak S.A reconfigurable routing algorithm for a fault-tolerant 2D-mesh network-on-chip[C].ACM/IEEE Design Automation Conference(DAC),Anaheim,California,USA,2008:441-446.
[3] Pratomo I,Pillement S.Gradient-an adaptive fault-tolerant routing algorithm for 2D mesh network-on-chips[C].Proceedings of the 2012 Conference on Design and Architectures for Signal and Image Processing(DASIP),Karlsruhe,Germany,2012.
[4] Fick D,Deorio A,Chen G,et al.A highly resilient routing algorithm for fault-tolerant NoCs[C].Design,Automation & Test in Europe Conference & Exhibition(DATE),Nice,France,2009:21-26.
[5] Feng C C,Lu Z H,Jantsc A,et al. FoN:fault-on neighbor aware routing algorithm for networks-on-chip[C].23rd IEEE International SOC Conference,2010:441-446.
[6] Rodrigo S,Flich J,Roca A,et al.Addressing manufacturing challenges with cost-efficient fault tolerant routing[C].NOCS 2010,Fourth ACM/IEEE International Symposium on Networks-On-Chip,Grenoble,France,2010:25-32.
[7] Bishnoi R,Laxmi V,Gaur M S,et al.CERI:cost-effective routing implementation technique for network-on-chip[C].International Conference on Vlsi Design,2015:59-64.
[8] Singh A,Dally W J,Gupta A K,et al.GOAL:a load-balanced adaptive routing algorithm for torus networks[C].Proceedings of the 30th Annual International Symposium on Computer Architecture(ISCA′03),2003:194-205.
[9] Hu J,Marculescu R.DyAD-smart routing for networks-on-chip[C].ACM/IEEE Design Automation Conference(DAC),San Diego,California,USA,2004:260-263.
[10] Lin Y,Xiang D.An effective congestion-aware selection function for adaptive routing in interconnection networks[C].International Conference on Parallel and Distributed Computing,Applications and Technologies,2010:156-165.
[11] Gratz P,Grot B,Keckler S W.Regional congestion awareness for load balance in networks-on-chip[C].IEEE 14th International Symposium on High Performance Computer Architecture(HPCA),2008:203-214.
[12] Ascia G,Catania V,Palesi M,et al.Implementation and analysis of a new selection strategy for adaptive routing in networks-on-chip[J].IEEE Transactions on Computers,2008,57(6):809-820.
[13] Chang E J,Hsin H K,Lin S Y,et al.Path-congestion-aware adaptive routing with a contention prediction scheme for network-on-chip systems[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2014,33(1):113-126.
[14] Tsai P A,Kuo Y H,Chang E J,et al.Hybrid path-diversity-aware adaptive routing with latency prediction model in network-on-chip systems[C].International Symposium on Vlsi Design,Automation,and Test,2013:1-4.
[15] Ramakrishna M,Kodati V,Gratz P,et al.GCA:global congestion awareness for load balance in networks-on-chip[J].IEEE Transactions on Parallel & Distributed Systems,2016,27(7):2022-2035.
[16] Tang M,Lin X,Palesi M.Local congestion avoidance in network-on-chip[J].IEEE Transactions on Parallel & Distributed Systems,2016,27(7):2062-2073.
[17] Liu J,Harkin J,Li Y,et al.Fault-tolerant networks-on-chip routing with coarse and fine-grained look-ahead[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2015,35(2):260-273.
[18] Gupta N,Sharma A,Laxmi V,et al.σnLBDR:generic congestion handling routing implementation for two-dimensional mesh network-on-chip [J].IET Computers & Digital Techniques,2016,10(5):226-232.
[19] Bahrebar P,Stroobandt D.Online reconfigurable routing method for handling link failures in NoC-based MPSoCs[C].International Symposium on Reconfigurable Communication-Centric Systems-on-Chip,2016:1-8.
[20] Ouyang Yi-ming,He Xin-cheng,Liang Hua-guo,et al.A fault-tolerant routing algorithm aiming at a path fault and local congestion in NoC[J].Acta Electronica Sinica,2016,44(4):920-925.
[21] Foroutan S,Thonnart Y,Petrot F.An iterative computational technique for performance evaluation of networks-on-chip[J].IEEE Transactions on Computers,2013,62(8):1641-1655.
[22] Tang M,Lin X,Palesi M.The repetitive turn model for adaptive routing[J].IEEE Transactions on Computers,2017,66(1):138-146.
[23] Tang M,Lin X,Palesi M.Routing pressure:a channel-related and traffic-aware metric of routing algorithm[J].IEEE Transactions on Parallel & Distributed Systems,2015,26(3):891-901.
[24] Tang M,Lin X,Palesi M.An offline method for designing adaptive routing based on pressure model[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2015,34(2):307-320.
[25] Radetzki M,Feng C,Zhao X,et al.Methods for fault tolerance in networks-on-chip[J].Acm Computing Surveys,2013,46(1):28-36.
附中文参考文献:
[1] 葛 蔚,郭 力,李静海,等.关于超级计算发展战略方向的思考[J].中国科学院院刊,2016,31(6):614-623.
[20] 欧阳一鸣,何鑫城,梁华国,等.针对路径故障与局部拥塞的NoC容错路由算法[J].电子学报,2016,44(4):920-925.
