面向比特流的链路层未知帧分析技术综述
2018-03-27曹成宏雷迎科
曹成宏,雷迎科
(电子工程学院,合肥 230037)
1 引 言
在OSI协议体系结构[1]中,链路层介于物理层和网络层之间,高层协议识别工作必须建立在链路层协议解析的基础上,因此对于侦察得到的比特数据流,首先要解决的就是如何识别分析出其使用的链路协议.当前研究在通信系统的不同层次实现了协议识别,但方法多局限于已知协议,如基于端口映射[2]和静态特征匹配[3]的方法等,对已知协议识别方法的总结综述较全面,但对实际的未知协议的相关研究不多,方法技术总结则更少.
近年来,国外对于协议分析的研究主要集中在基于测度的、基于固定字符串的和基于正则表达式的协议识别技术.从2005年开始,Moore[4]等人给出了网络流的249种属性,通过几个属性的不同组合得到最简洁的特征子集,作为后续研究的依据.Bernaille[5]等按照数据包到达的先后顺序将每个数据流中的前五个数据包的大小作为特征,采用无监督算法进行聚类,但这种方法在协议识别中的准确率不高.在2010年,Cai[6]等人提出了基于机器学习和固定字符串匹配的协议识别方法,首先对数据流量进行分流处理,然后采用离线的方式进行训练,提取出固定的字符串作为特征关键字,但是由于缺乏相应规范,对未知协议并不适用.Veritas[7]系统对抓取的协议消息实现3-gram划分,将经过筛选之后的单元进行拼接得到协议的关键词,最终将协议关键词作为模式实现了协议的类别划分,但这种方法仅适用于单一协议.2011年,Y.Wang[8]等人提出的 Biprominer就是利用数据挖掘的相关技术,提取比特流的特征信息,通过正则表达式,最终以有限状态自动机的形式表现出来.Antunes[9]等人将生物信息中的序列比对算法用于协议识别中,通过偏序比对算法提取协议的正则表达式,建立自动机,进行协议识别,但过程中需要对构建的自动机进行重复匹配,这样会造成较大的资源消耗.
该文所研究的无线网络数据环境是指通过侦察设备对无线信号进行物理层的截获,并通过一系列解调、解码和解密以后的比特流数据.实际中,截获数据多为加密的,针对加密算法识别及解密问题有专门的研究,文章未做考虑.该文所提的未知协议是指协议双方商定的、未公开且具有一定固定格式的协议,这种协议并非完全没有规律可寻,当同种未知协议的比特流数据大量积累时,寻找其中规律便成为可能.该文将链路未知协议分析分为频繁序列统计、关联规则挖掘、链路帧切分到获取其他帧格式信息四个方面进行总结,即总结了从数据的预处理到还原帧结构整个过程的方法,国外最近的相关研究很少,因此该文主要总结了国内的相关研究.
2 链路层协议知识和数据特点
2.1 链路数据成帧原理及结构
依据OSI协议体系结构理论,物理层和数据链路层属于网络底层,网络数据传输过程中,发送方将网络层的IP数据包传送到数据链路层后,在数据的前后分别添加首部和尾部,封装成帧如图1,再交由物理层以比特流的形式传输出去,接收方从收到物理层上交的比特流后,在链路层就能根据首部和尾部的标记,从收到的比特流中识别出帧的开始与结束.

图1 封装成帧Fig.1 Encapsulated frame
帧格式一般包括帧头部字段与数据字段.帧头包含帧同步序列,以及地址域、控制域等常用域.一种链路协议的同步序列在通信过程中始终不变,地址域、控制域等常用域的长度以及在特定帧的帧头中的位置通常是固定的.帧头部字段如图2,包含固定域与可变域,其中固定域是帧头中内容和位置均固定的比特字段,可变域的内容在通信过程中往往会发生改变.这种在链路帧帧头间隔出现固定域和可变域的现象普遍存在,这也是从比特流中识别链路帧头结构的基础.

图2 数据帧帧头结构Fig.2 Data frame header structure
如图3是简单的以太网帧格式,其中有前导字段(包括同步码和开始标识符等,用于帧同步)、目的地址字段、源地址字段、帧内容(数据链路层所承载的信息)、校验字段(用于差错控制).

图3 以太网帧格式Fig.3 Ethernet frame format
2.2 链路帧比特流数据特点
目前采取的各类解析帧结构的方法都是要考虑到比特流数据特点[10]的,具体如下:
“01”性:即比特流中包含的元素非0即1,不可能出现其他元素.这是由通信和存储介质本身特点决定的,比纷繁复杂的数据库信息要简单得多.
有序性:由于比特流的传输遵循时间的顺序,因此比特的出现顺序是默认不可改的,体现为比特与比特之间的排列顺序不满足交换律.举例来说,如序列“0101”不同于“1010”,也不能等同于“1100”.这对选取怎样的算法统计频繁序列很重要.比如数据挖掘中强调的是“集合”的概念,不对元素之间的顺序做要求,{a,b}与{b,a}等都是等同的.
无界性:在获得的比特流数据中,无法确定哪个比特是一个字节或一个帧的开始和结束.
关联性:每段比特流数据承载不同的内容,涉及到数据帧的同步序列、帧头、负载、校验等,其相互之间也存在着一定的关联特性.
2.3 链路未知帧分类
本文总结当前学术界对于数据链路层的未知协议分析、解析工作的研究成果,将其分为两类[11]:
1)基于经典协议匹配库的未知协议分析:对于给定的一串帧比特流且无法确定采用何种链路层协议,但可以肯定的是采用的这种协议是经典的链路协议之一.这种情况在电子对抗场景中经常发生,作为窃听一方由于无法获知通信双方的预先沟通消息,缺乏通信的协议格式,这就需要与经典的规范协议库先做比对后判断.
2)完全未知协议特征的未知协议分析:实际上,链路层协议种类复杂、数目繁多、数据量大,在军方、商业应用中多是未被公布出的协议.对于由这类完全未知协议特征构建的比特流数据在实际应用中越来越普遍,而基于经典协议匹配库的未知协议分析方法显然不能奏效.即使这样,对这种完全未知的协议仍有分析的必要,这也是今后研究的重点.
3 频繁序列统计算法
3.1 模式匹配技术
从大量的“01”码流数据中寻找特征序列或匹配关键字段最常用的方法就是模式匹配技术,这也是检索方法中最基本的策略.模式匹配算法就是在目标串中查询出指定模式串出现的位置的算法,结合比特流数据特点的定义,就是在物理层处理后获取的链路帧数据中查询出特征序列.模式匹配算法由于使用需求不同可分为三类:精确匹配算法、近似匹配算法和正则表达式匹配算法.在协议分析研究实际中,默认模式串集合是已知的,目标串中也存在与之完全相同的目标子串,因此釆用的是精确匹配算法,其中又包括单模式匹配和多模式匹配.
1)单模式匹配:比较经典且适用的有BF、KMP、BM算法,同时王和洲等人在2014年提出更高效、更适用于比特流数据的QS算法,关于四种算法的具体内容不再赘述,主要对四种算法从算法思路、时空间复杂度、算法效率三个方面作总结比较如表1.时空复杂度由C代码实现算法后计算得出,算法效率由4组仿真实验,即2元字符集组、4元字符集组、20元字符集组以及自然语言字符集组验证.(注:目标串长度为n,模式串长度为m,σ为目标串和模式串字符集大小)
然而,单模式匹配对于已知协议的分析具有较好的效果,而未知协议的特征寻找由于有大量模式串要匹配,单模式匹配算法需要重复扫描源数据,效率很低,不能适用.
2)多模式匹配:多模式匹配算法主要有Aho-corasick、 Wu-Manber,即AC和WM两种算法,前者是基于有限自动机,后者基于Hash函数.详细比较如表2(注:M表示所有模式串长度总和,B为块字符长度,n,m同表1)
未知协议的比特流特征寻找最大特点就是多候选模式,与多模式匹配算法所解决的问题完全一致.利用成熟的多模式匹配算法,可以通过一遍扫描得到各候选序列出现的位置以及次数,以便进一步筛选.但要应用于比特数据流环境,则需要对它们进行改进.
3.2 改进的多模式匹配算法
改进的多模式匹配算法更专注于如何快速、准确且适合比特流数据进行匹配.如文献[12]中提出的AC-BM算法,就是将经典的AC算法和BM算法结合,它综合了两个算法的特点,即沿用AC算法建立模式树,而树的检索方法则是BM算法.在之后的文献[13],张楠等则继续对AC-BM算法进行改进以适应协议分析的数据环境.
2011年上海交通大学金凌等人提出从减少数据库操作次数和对频繁序列筛选的两方面考虑,融入剪枝思想,考虑在统计过程中对有限状态自动机进行“剪枝”,进而提出了面向比特流的枚举树剪枝算法.算法分为几个主要环节:建树、计数和剪枝,是一个自我调节的反馈过程.通过剪枝达到了两个目的:
1)尽早排除一些不可能是频繁序列的模式,以减少以后统计过程中的数据库操作次数,提高统计的效率.
2)统计结束的同时给出频繁序列的挖掘结果,不必进行二次计算,当然该算法也存在缺点,即如果剪枝过早,容易造成频繁序列丢失,剪枝过晚提升效率又不明显.
表1 四种单模式匹配算法
Table 1 Four kinds of single pattern matching algorithm

四种算法算法思路时/空间复杂度算法效率BF算法该算法是使用内外两重循环对数据进行遍历.外层循环控制窗口在目标串中从左向右移动,该窗口与模式串长度等长,窗口从目标串中获得目标子串,内层循环用于逐位比较目标子串与模式串是否相同.缺点:没有利用到每次内循环已匹配部分的信息,有重复的字符比较,导致效率低.最好时空间复杂度分别为On(),O1().最坏情况下时空间复杂度分别为Omn(),Om()效率最差KMP算法鉴于BF算法缺点,避免重复比较,定义“前缀”:模式串中发生不匹配字符的前面那一段字符中最长的重复子字符串.算法利用程序外循环控制窗口移动,内循环比较模式串与目标子串;内循环从左向右匹配过程中,如发生失配,通过查询“前缀”确定外部循环推进步伐.时空间复杂度分别为Om+n(),Om()次于BM,好于BFBM算法算法提出在匹配的过程中,采用从后向前比较的方式,对模式串的后缀进行匹配,在完成一次(包括匹配失败或成功)后,利用两个根据模式串预处理好的移动表坏字符移动与好后缀移动来进行位置后移.最好时空间复杂度分别为Om/n(),Om+σ()最坏时间复杂度On-m+1()m+σ)次于QS,好于KMPQS算法算法思想核心与KMP、BM算法类似,不同的是发生失配时,不是去找匹配中失配字符在模式串的位置、子串(前缀、后缀)的自包含,而是直接寻找当前窗口在目标串中右一位的那个字符在模式串的位置,利用这个字符的信息进行跳跃.时空间复杂度为O(n/(m+1)),Om+σ().最坏时间复杂度为Omn()QS最优
表2 两种多模式匹配算法
Table 2 Two multi pattern matching algorithms
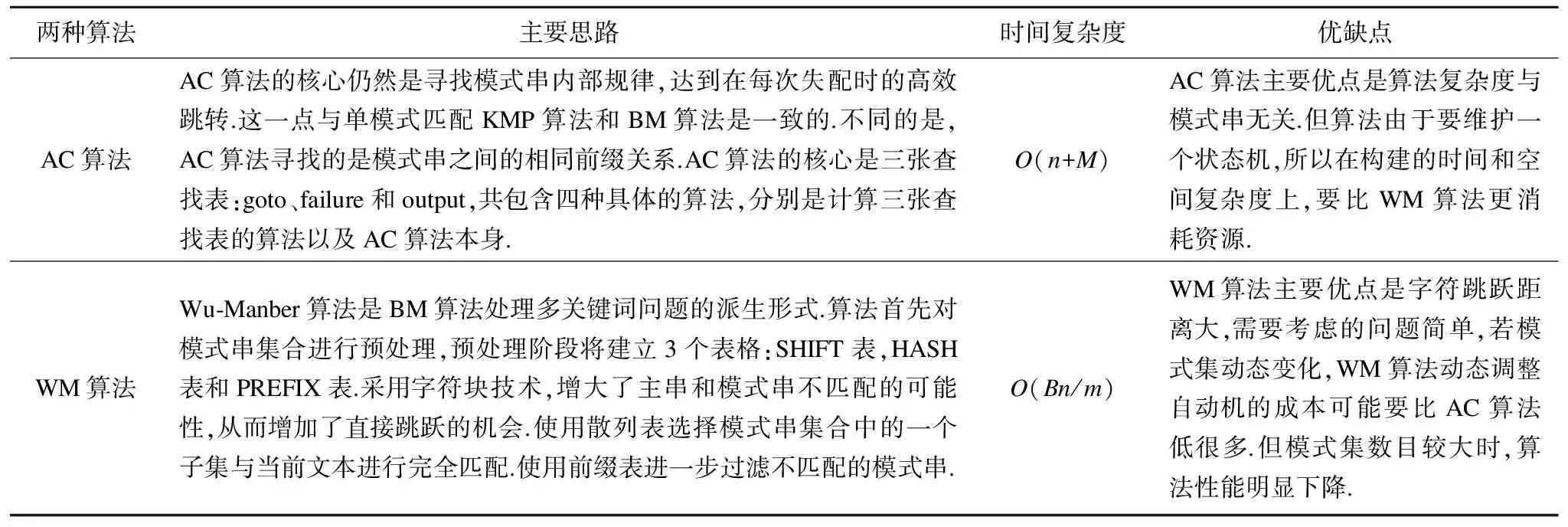
两种算法主要思路时间复杂度优缺点AC算法AC算法的核心仍然是寻找模式串内部规律,达到在每次失配时的高效跳转.这一点与单模式匹配KMP算法和BM算法是一致的.不同的是,AC算法寻找的是模式串之间的相同前缀关系.AC算法的核心是三张查找表:goto、failure和output,共包含四种具体的算法,分别是计算三张查找表的算法以及AC算法本身.O(n+M)AC算法主要优点是算法复杂度与模式串无关.但算法由于要维护一个状态机,所以在构建的时间和空间复杂度上,要比WM算法更消耗资源.WM算法Wu⁃Manber算法是BM算法处理多关键词问题的派生形式.算法首先对模式串集合进行预处理,预处理阶段将建立3个表格:SHIFT表,HASH表和PREFIX表.采用字符块技术,增大了主串和模式串不匹配的可能性,从而增加了直接跳跃的机会.使用散列表选择模式串集合中的一个子集与当前文本进行完全匹配.使用前缀表进一步过滤不匹配的模式串.O(Bn/m)WM算法主要优点是字符跳跃距离大,需要考虑的问题简单,若模式集动态变化,WM算法动态调整自动机的成本可能要比AC算法低很多.但模式集数目较大时,算法性能明显下降.
目前采用较多的是张楠提出的改进AC算法,使其按位读取原始数据,非常好的适应了二进制比特流环境.改进AC算法之后,原始的根节点root仍保持为空,保留AC算法的转移函数,但失效函数不再使用,由于比特流数据的单一性,只存在“0”和“1”,且改进后建立的AC字典树包含了所有的n位以内的状态,不会出现匹配失效的情况.同样,不再需要输出函数.改进后的AC算法是按比特位读取数据的,第一步起始读入1位比特序列后,根据读入内容,转入相应的状态,然后每读入一位都根据读入内容转移状态,直到转移到字典树的最末端叶子节点时,在其状态相应的序列出现次数加1.但基于改进AC算法的比特流频繁序列挖掘方法仅适用于长度较短的频繁模式,当候选模式长度m较大时,便无法进行.
最近,琚玉建[14]等提出一种基于Trie树结构的频繁统计方法,为了减少帧数据段冗余的干扰并考虑到处理大量数据时带来的时空复杂度,同时保证算法的有效性,琚玉建提出利用Trie树[15]结点对应路径字符串的特性存储统计比特流数据.利用Trie树结构改进对比特流进行存储统计,在兼顾比特流数据特点、保证算法有效性的同时,降低算法复杂度,扫描一次源数据即可获得所有的序列及其统计结果.具体算法描述:输入比特流数据、最短序列长度min、最长序列长度max;输出序列集合、出现次数、出现的位置;流程:1)枚举符合长度的待统计序列,建立深度为max的Trie树.2)分别建立长度为length=min,min+1,…,max的buffer,存储长度为length的最新序列.3)读入下一比特,更新buffer和Trie树中的节点计数count(即该buffer序列出现的次数),并以数组形式存储序列首位位置.
4 频繁模式和关联规则挖掘
从比特流数据统计出特征序列,包括基本的特征位如4位、8位和16位的出现次数,紧接着就是要挖掘出频繁序列,判定寻找合适的频繁序列集,然后通过关联拼接获得长频繁序列,进一步筛选有效的频繁序列并扩充长度;最后通过基于位置差的关联规则验证,寻找上述频繁序列之间种最有效的关联,并作为同步特征切割比特流数据.

关联规则作为数据挖掘的主要技术之一,主要用于在数据库的大量数据中发现有价值的数据项之间的相关关系,找到频繁项集,其次是挖掘出满足设定置信度的关联规则.关联规则是形如X⟹Y的蕴含式,X、Y是数据库中的项,在比特流中则为模式串.其置信度[17]计算如下:

(1)
当置信度在用户设定的最小置信度阈值与最大置信度阈值之间时,则认为该关联规则是有趣的,即该关联关系有效.目前主流的有Apriori算法[18]与FP-growth算法[19].孙海霞[20]使用关联规则中的经典算法Apriori算法来提取候选特征码,从而建立了网络数据的流量识别模型.但算法在关联规则挖掘中,会产生大量的频繁集,并会重复的扫描,执行效率很低且造成很大的I/O开销.J.Han[21]等人于2000年提出FP-Growth算法,FP-growth算法采用一种分治策略,将代表频繁项集的数据库压缩到一棵频繁模式树(FP-tree),以避免代价较大的候选产生过程.采用自底向上的搜索策略,对FP-tree各分支所包含的频繁模式进行搜索,该算法不产生候选频繁项集.文献[22]中就基于FP-tree研究了最大项集挖掘算法DMFIA,文献[23]中为FP-Growth总结出了三条发展方向,其中挖掘最长频繁项集被广泛应用于数据流的挖掘中.而文献[24]中就根据数据流的特点,将FP-tree改进后应用于数据流的关联规则挖掘中,同理还有文献[25]和文献[26].
5 数据帧切分
从未知的链路层比特流中寻找能指示帧起始的序列标识,其目的就是能够对比特流链路帧进行准确切分,切分帧头.只有准确切分数据帧,才使得后续对未知帧的解析成为可能.因此,关于帧切分的方法总结也是该文的重点.
吴艳梅[27]等详细介绍了基于相关法、基于最大自然法、基于似然比检验三种主流的方法,但其针对的是帧同步码已知的情况.目前较为主流的方法还是上文提到的基于频繁模式挖掘与关联规则挖掘的方法挖掘帧同步序列,该方法具有普遍适用性,尤其是针对格式未知的协议.文献[28]能够提取出帧同步序列,针对设定的结果门限给出了多种可能的帧切分方案.杨晓静[29]等人提出了基于偏三阶相关函数峰值特性的识别方法分析和判断帧长,该方法首先对同步码各位上的序列进行偏三阶相关函数运算,然后利用m-序列采样后的偏三阶相关函数峰值相似度高的特性区分信息码和同步码,最后通过进一步运算得到同步码的码长和起始位,并通过仿真实验表明了该方法能够利用较少的数据快速准确地识别出帧同步码,具有良好的容错性能,但仅局限在对m-序列帧同步码的分析识别.该文着重总结了电子科学技术大学温爱霞[30]等人在2015年提出的基于生成n-gram的帧切分技术及2016年中国科学技术大学薛开平[31]等人提出的在数据挖掘的基础上利用有向图构建多重关联规则进行帧切分的方法,并进行了实验验证.
基于生成n-gram的帧切分.该方法关键的两个问题是n值的确定和n-grams的筛选,对应的两个解决方案分别是齐夫分布和Jaccard参数,采用齐夫分布来确定合适的n值,首先对n取(1,2,3,4)不同值时分别对原始数据集进行切分,对每个n-gram按其出现的次数进行排序,出现次数最多的排名为1,其次为2,一直到排名最后.用x轴表示n-gram的排序,y轴表示对应n-gram出现的次数,两个轴都用对数来表示,根据画出的曲线来决定n值的大小.根据齐夫分布,选择更接近于直线的n值.对于所得到的grams,为了防止拼接过程中产生过多的冗余串,需要对其进行筛选.该方法利用Jaccard参数作为选择阈值的指标.首先将原始数据集随机的平均分成A,B两部分,用n-gram进行切分,分别统计每一部分中每一个n-gram出现的次数,进行排序,利用Jaccard参数选择出来的阈值对所有的n-grams进行过滤.计算Jaccard值的公式如下所示:
(2)
T1i和T2i分别表示A和B中的第i个特征.通过改变阈值来计算不同的Jaccard值,将第一次达到最高点的Jaccard值所对应的阈值作为所求,利用该阈值对所得到的grams进行过滤即可得到所需要的grams.
利用有向图构建多重关联规则进行帧切分.主要步骤是:
1)设定频繁度门限区间,从比特流中筛选出满足频繁度要求的序列,然后两两考察频繁序列,寻找序列间的关联规则;
2)为充分考虑关联规则间的联系,将得到的所有关联规则按一定方式组织成有向图;
3)为有向图的序列节点分配坐标,整合参与形成有向图的二重关联规则,获得多重关联规则;
4)根据多重关联规则在比特流中出现的频率判断其合理性,根据判断结果调整频繁度门限区间,确保获得的结果正确可信.

图4 实验帧切分1Fig.4 Experimental of frame segmentation 1
该文采用wireshark抓取以太网实际测试数据对该方法进行实验验证,获取的每帧数据转为二进制后帧头部添加7*10101010+10101011字段作为前导码,合成64帧数据保存入Ethernet.txt.频繁度下限设为0.5,上限设为0.65,使用QtCreator平台实现算法,如图4和图5结果正确切分成64帧.

图5 实验帧切分 2Fig.5 Experimental of frame segmentation 2
6 解析其他帧格式信息
由图3可知解析帧格式信息包括很多内容,但从网络攻击的角度说最重要就是地址信息,目前研究也多集中在帧地址解析上.当然经过帧切分后的不完整数据帧,由于是混合的未知多协议,首先要进行的就是将其分离成单帧协议,再继续寻址.郑杰[32]提出用聚类算法中的Kmeans将混合未知多协议数据帧分为单协议,并用评估算法确定所得到的类簇是比较可信的单协议数据帧,后构造多维矩阵求解地址信息,该方法有效地简化地址信息寻找流程,减少了频繁计数和判断过程,大大节省了寻找地址信息所需要的时间,经实验验证,采用该方法可以对ARP数据帧的地址列信息达到2/3以上的匹配,同时,对TCP数据帧的地址列信息的识别达到100%.温爱霞等采用基于机器学习的无监督聚类算法实现数据帧的归类操作,将数据帧的 MAC地址作为聚类的特征集,用实际数据设计对比实验,比较了几种常用的如Kmeans、DBSCAN、EM算法的性能.针对聚类算法对未知混合多协议分类,林荣强[33]提出了基于半监督聚类集成,该方法利用流的相关性实现对标记样本的扩展,提高标记样本比例,引入集成学习辅助半监督聚类对扩展后训练集进行聚类分析,实现对未知协议样本的识别,最后对得到的混合未知协议样本集进行细分类,并实际网络数据集进行仿真实验,有效地识别未知协议数据并实现细分类,提高了聚类结果的稳定性.
目前对帧地址的解析主要思路都是先采用聚类算法将切分后多数据帧进行分离,对单帧协议再进行寻址分析.但对于协议的其他信息如类型、校验位等则没有研究的方法,结合聚类算法的思想,该文认为可以对切分后的数据帧分别以不同字段信息的特征为簇聚类中心进行聚类,最后解析出其他帧格式信息.
7 今后研究方向展望
随着无线网络通信技术的不断发展,未知协议在军民上的应用也越来越广泛.作为侦察方,寻找解析出未知协议的方法的需要也越来越强烈,该文从最初的链路层比特流未知帧的数据处理出发到解析出帧格式信息,归纳总结了解析过程中每一部分的研究方法、技术,但对于链路层未知协议的解析仍有很多问题亟待解决,关于今后的研究方向概略总结如下:
1)数据挖掘的准确性问题.帧切分和帧格式信息的解析前提都是要有准确的频繁序列和关联规则挖掘,要提高准确率就需要挖掘大量的比特流数据,这无疑会损耗巨大的计算资源,但同时又要保证计算效率,因此剪枝算法等被提出,这样准确率又会受到影响,目前主要还是靠人工经验提高挖掘准确率,这存在很大的随机性.在今后的的研究中需要考虑如何实现自动的调整来代替人工经验.
2)加强其他格式信息解析的算法研究.当前的帧格式分析多集中在寻址上,但协议的其他字段同样重要,比如协议类型等,对于完整的还原帧结构很关键.同时协议包括语义和语法信息,现有的研究属于基本的语义解析,考虑到构建协议语法的逻辑模型和协议各消息之间存在的逻辑关系,后续还需要分析协议的语法信息以及帧数据段的内容.
8 结束语
面向比特流的链路层未知帧,如何在缺乏先验知识的情况下,获取其中承载的有用信息是一项重要的研究课题.该文确定研究的无线网络数据环境主要是指通过侦察设备对无线信号进行物理层的截获,且通过一系列解调、解码和解密以后,得到的比特流数据这一对象后,从频繁序列统计、关联规则挖掘、链路帧切分到解析其他帧格式信息4个方面总结归纳了相关的研究算法及最新的研究成果.给出了各算法优缺点,对部分算法进行了实际数据实验验证.同时指出了当前研究算法一些亟需解决的问题,如频繁序列挖掘中的阈值选择对挖掘准确率的影响问题等.最后给出了链路层未知协议解析领域进一步的研究方向.
[1] Xie Xi-ren.Computer network (Sixth Edition)[M].Beijing:Electronic Industry Publishing House Press,2007.
[2] Wu Peng-chong.Research and implementation of non default port network protocol identification system [D].Beijing:Beijing University of Posts and Telecommunications,2009.
[3] Madhukar A,Williamson C.A longitudinal study of P2P traffic classification[C].The 14th IEEE International Symposium on Modeling,Analysis,and Simulation of Computer and Telecommunication Systems,Washington,2006:179-188.
[4] Kim M S,Won Y J,Hong J W K.Application-level traffic monitoring and an analysis on IP networks[J].Journal of Electronics Telecommunications Research Inst,2005,27(1):22-42.
[5] Bernaille L,Teixeira R,Akodkenou I,et al.Traffic classification on the fly[J].ACM SIGCOMM Computer Communication Review,2006,36(2):23-26.
[6] Cai X,Zhang R,Wang B.Machine learning and keyword-matching integrated protocol identification [C].The 3th IEEE International Symposium on Broadband Network and Multimedia Technology,Beijing,2010:164-169.
[7] Wang Y,Zhang Z,Yao D,et al.Inferring protocol state machine from network traces:a probabilistic approach[M].Springer Berlin Herdelberg,2011,67(15):1-18.
[8] Wang Y,Li X,Meng J,et al.Biprominer:automatic mining of binary protocol features[C].The 12th International Conference on Parallel and Distributed Computing,Applications and Technologies,Gwangju,2011:179-184.
[9] J.Antunes N Neves,Verissimo P.Reverse engineering of protocols from network traces [J].IEEE Computer Society 2011,5(21):169-178.
[10] Jin Ling.Study on bit stream oriented unknown frame head identification [D].Shanghai:Shanghai Jiao Tong University,2011.
[11] Wang He-zhou,Xue Kai-ping,Hong Pei-lin,et al.The bit- stream cutting algorithm for unknown link-layer protocol based on frequent statistics and association rules [J].Journal of University of Science & Technology of China,2013,43(7):554-560.
[12] Cole R.Tight bounds on the complexity of the Boyer-Moore string matching algorithm[J].SIAM Journal on Computing,1994,23(5):1075-1091.
[13] Zhang Nan.Identification and analysis of unknown protocol fingerprint characteristics in wireless network environment [D].Chengdu:University of Electronic Science and Technology of China,2014.
[14] Ju Yu-jian,Xie Shao-bin,Zhang Wei.Fingerprint identification and discovery of data based on the adaptive weight data[J].Computer Measurement and Control,2014,22(7):2288-2294.
[15] Fredkin E.Trie memory[J].Communication of the ACM,1960,3(9):490-499.
[16] Lei Dong,Wang Tao,Zhao Jian-peng,et al.Survey of bit stream oriented unknown protocol identification and analysis techniques [J].Application Research of Computers,2016,33(11):3206-3210.
[17] Chen Geng,Zhu Yu-quan,Yang He-biao,et al.Study of some key techniques in mining association rule references[J].Computer Research and Development,2005,42 (10):1785-1789.
[18] Liu Qi,Bu Jun-jia,Chen Chun.Application of keyword recommendation based on apriori algorithm in topic oriented user personalized search [J].Pattern Recognition and Artificial Intelligence,2006,19 (2):186-190.
[19] Gast M S.802.11 wireless networks - the definitive guide:creating and administering wireless networks[M].Digital Bibliography & Library Project,2002.
[20] Sun Hai-xia.Research on traffic identification method based on association rules [D].Hefei University of Technology,2009.
[21] Han J,Kamber M.Data mining:concepts and techniques(2nd ed)[M].Morgan Kaufmann,Machine Press,2007.
[22] Song Wei-lin.Research on data mining association rules algorithm based on maximal frequent item sets [D].Beijing:Beijing University of Posts and Telecommunications,2006.
[23] Hu Jun.Association rule mining algorithm based on FP- tree [J].Silicon Valley,2010,10(21):175.
[24] Yang Yi-zhi.Research on association rule mining method based on data stream [D].Xi′an: Xi′an University of Science and Technology,2011.
[25] Huang Wei.Data stream frequent pattern mining algorithm research [D].Xi′an: Xi′an University of Science And Technology,2010.
[26] Chen Yan.Data stream of the largest frequent pattern mining research [D].Xi′an: Xi′an University of Science and Technology,2010.
[27] Wu Yan-mei.Positioning and characteristic analysis of bit stream protocol in wireless environment [D].Chengdu: University of Electronic Science and Technology of China,2014.
[28] Wang He-zhou,Xue Kai-ping.Research on bit-stream oriented link protocol identification and analysis techniques [D].Hefei: University of Science & Technology China,2014.
[29] Bai Yu,Yng Xiao-jing,Zhang Yu.A recognition method of m-sequence synchronization codes using higher-order statistical processing[J].Journal of Electronics & Information Technology,2012,34(1):33-37.
[30] Wen Ai-xia.Research on feature discovery technology of unknown protocol in bit-stream data [D].Chengdu: University of Electronic Science and Technology of China,2015.
[31] Xue Kai-ping,Liu Bin,Wang Jin-song,et al.Unknown frame correlation analysis for link bit streams [J].Journal of Electronics and Information Technology,2016,39 (2):374-380.
[32] Zheng Jie,Zhu Qiang.Analysis and research on addresses of unknown single protocol data frames [J].Computer Science,2015,42 (11):184-187.
[33] Lin Rong-qiang,Li Ou,Li Qing,et al.Unknown network protocol identification method based on semi-supervised ensemble [J].Journal of Chinese Computer Systems,2016,37 (6):1234-1239.
附中文参考文献:
[1] 谢希仁.计算机网络(第六版)[M].北京:电子工业出版社,2007.
[2] 吴鹏冲.非默认端口网络协议识别系统的研究与实现[D].北京:北京邮电大学,2009.
[10] 金 凌.面向比特流的未知帧头识别技术研究[D].上海:上海交通大学,2011.
[11] 王和洲,薛开平,洪佩琳,等.基于频繁统计和关联规则的未知链路协议比特流切割算法[J].中国科学技术大学学报,2013,43(7):554-560.
[13] 张 楠.无线网络环境下未知协议指纹特征识别与分析[D].成都:电子科技大学,2014.
[14] 琚玉建,谢绍斌,张 薇.基于自适应权值的数据报指纹特征识别与发现[J].计算机测量与控制,2014,22(7):2288-2294.
[16] 雷 东,王 韬,赵建鹏,等.面向比特流的未知协议识别与分析技术综述[J].计算机应用研究,2016,33(11):3206-3210.
[17] 陈 耿,朱玉全,杨鹤标,等.关联规则挖掘中若干关键技术的研究[J].计算机研究与发展,2005,42(10):1785-1789.
[18] 刘 琦,卜俊佳,陈 纯.基于Apriori算法的关键词推荐在面向主题的用户个性化搜索中的应用[J].模式识别与人工智能,2006,19(2):186-190.
[20] 孙海霞.基于关联规则的流量识别方法研究[D].合肥:合肥工业大学,2009.
[22] 宋卫林.基于最大频繁项目集的数据挖掘关联规则算法研究[D].北京:北京邮电大学,2006.
[23] 胡 俊.基于FP-树的关联规则挖掘算法浅谈[J].硅谷,2010,10 (21):175-175.
[24] 杨溢之.基于数据流的关联规则挖掘方法的研究[D].西安:西安科技大学,2011.
[25] 黄 威.数据流的频繁模式挖掘算法研究[D].西安:西安科技大学,2010.
[26] 陈 艳.数据流的最大频繁模式挖掘研究[D].西安:西安科技大学,2010.
[27] 吴艳梅.无线环境下比特流协议帧定位与特征分析[D].成都:电子科技大学,2014.
[28] 王和洲.面向比特流的链路协议识别与分析技术[D].合肥:中国科学技术大学,2014.
[29] 白 彧,杨晓静,张 玉.基于高阶统计处理技术的m-序列帧同步码识别[J].电子与信息学报,2012,34(1):33-37.
[30] 温爱霞.比特流数据未知协议特征发现技术研究[D].成都:电子科技大学,2015.
[31] 薛开平,柳 彬,王劲松,等.面向链路比特流的未知帧关联分析 [J].电子与信息学报,2016,39 (2):374-380.
[32] 郑 杰,朱 强.未知单协议数据帧的地址分析与研究[J].计算机科学,2015,42(11):184-187.
[33] 林荣强,李 鸥,李 青,等.基于半监督聚类集成的未知网络协议识别方法[J].小型微型计算机系统,2016,37(6):1234-1239.
