一个基于农业本体的Web知识抽取模型
2018-03-26李贯峰
李贯峰, 张 鹏
(宁夏大学信息工程学院,宁夏银川 750021)
目前,我国农村信息化建设面临从提供信息服务向提供知识服务的逐步过渡,知识服务对提高农业生产水平、增加农产品收益、创建农村和谐社会具有深远的意义。农业生产过程是生物依靠自然环境和自身生理机能而进行的自然生长发育过程,因此农业知识具有环境多样性、地域差异性和种类丰富性等特点,农业领域知识的获取和表示与其他领域相比难度更大、更具有挑战性。
随着因特网的快速发展与广泛应用,Web成为人们获取知识的重要资源库。但万维网(word wide wed,简称Web)资源结构庞杂无序,缺乏对语义信息的描述,人们需要一种自动化的方式对Web资源进行有效的处理和整合,抽取对用户有价值的知识并过滤掉不相关的信息,Web知识抽取(Web knowledge extraction)的研究是在这样的需求背景下产生的,被专家学者们广泛关注,成为研究的热点。近年来,基于本体(ontology)的Web知识抽取技术已经成为知识抽取的重要研究方向。
现有的Web知识抽取方法主要有基于超文本标记语言(hypertext markup language,简称HTML)文档结构的知识抽取方法[1]、基于自然语言处理(natural language processing,简称NLP)方式的信息抽取方法[2]和基于包装器归纳的知识抽取方法[3]等,这些方法针对特定文档结构,设置不同的抽取规则,抽取方法不能重复使用。此外,这些方法只能抽取实体信息,而无法抽取Web中包含的语义描述信息。本体作为一种有效的知识建模工具,被广泛地应用于信息科学等众多领域。本体能够提供特定领域中存在的对象类型和对象属性间的相互关系,其良好的知识组织模型能够有效地识别概念及概念之间的关系,解决传统知识抽取在非结构文本方面的不足。通过本体构建规则,不仅能通过特定类型来识别待抽取的实体,还能利用本体中的概念层次关系从语义描述上来识别实体。因此,基于本体的知识抽取技术将在未来的知识抽取发展中成为不可缺少的辅助技术。
本研究针对农业领域,构建农业本体,并在此基础上提出农业领域的Web知识抽取系统模型和关键技术,实现本体在农业知识获取过程中的相关算法,解决传统知识抽取在非结构文本方面的不足,提升知识获取的准确性和高效性。
1 基本定义
1.1 本体
在信息科学领域中本体作为一种有效描述概念结构和语义模型而被广泛应用,它是通过领域专家的积极参与和通力协作而构建的领域概念、关系和公理体系的集合,以计算机能理解的语言和形式描述、表示和组织知识,促进知识重用、知识共享和知识服务[4]。农业本体是将农业学科领域内概念、概念与概念间的相互关系用机器能理解的形式化语言表示的知识模型。农业本体为农业领域提供统一的术语和概念,在农业知识库构建、知识共享服务及智能检索等方面具有广泛的应用前景。
1.2 RDF
为让语义Web上的应用程序准确方便地应用本体,须要定义通用的本体语言来对本体进行描述。目前常见的本体语言有资源描述框架模式(resource description framework scheme,简称RDFS)[5]、网络本体语言(web ontology language,简称OWL)等。其中RDFS是目前广泛使用的本体表示语言之一,能够对包括网页在内的任何资源进行陈述,1个资源描述框架(rseource description framework,简称RDF)陈述由主体(subject)、谓词(predicate)和客体(object)组成,被称为三元组。1个RDF三元组集合可以表示成RDF图模型,图中节点可以表示三元组的主体和客体,而有向边则表示从主体指向客体的谓词。
1.3 知识抽取
Web知识抽取即从无语义信息的Web文档中识别和抽取知识,并以一定形式存入知识库中,进而实现对Web数据充分、有效的利用。基于领域本体的知识抽取是指利用给定的领域本体从无语义标注的信息资源中识别并抽取与领域本体匹配的事实知识,它既可以为实现知识服务系统而抽取事实知识,也可以为语义Web的构建提供相应的语义内容。因此知识抽取技术对于充分利用现有Web数据是非常必要的[6]。
2 基于本体的Web知识抽取模型
基于本体的Web知识抽取是指以所构建的领域本体为核心,利用本体中已定义的概念、分类层次、关系和实例及一些必需的外部资料对Web页面进行知识提取,得到结构化知识并保存的过程[7]。由图1可知,基于本体的Web信息抽取系统模型包括数据采集模块、预处理模块、领域本体构建和解析模块、分词与命名实体识别模块以及知识抽取模块等5个模块。

2.1 文档采集模块
文档采集模块的主要功能是找到对应的源文档,并保证源文档能够被系统检索到。源文档可来自本地、局域网或互联网,其类型是HTML,对基于农业本体Web知识抽取系统的研究主要以HTML结构为出发点,完成对知识的抽取工作。本研究使用主题爬虫来发现和获取有关农业方面的HTML文档集。
2.2 预处理模块
Web页面上的信息存在结构灵活、语义性差、标记错误等情况,可通过预处理去噪,并生成编码和格式统一的格式化文档。
2.3 领域本体库构建与解析模块
本体是整个知识抽取系统的核心,它规定了知识抽取中的目标知识形式,定义了农业领域中的相关概念、层次关系、实体及属性集合,能够让不同用户对领域知识达到共同的理解,从而实现知识的共享和重用。该模块可以按照知识抽取的需求,构建合理的领域本体,并使用该本体作为知识抽取的基础。本体解析是利用本体解析工具,对建好的在领域本体中所表述概念以及概念之间的层次关系进行解析,并把解析出来的概念和关系等结构存入记录表中的过程,本研究通过Jena的应用程序编程接口(application programming interface,简称API)来实现本体解析过程。
2.4 分词与命名实体识别模块
分词操作是知识抽取的前提。根据抽取模块的需要,系统首先要对抽取的文本文档进行分词操作。本研究主要对中文信息进行处理,因此分词软件采用的是中国科学院计算技术研究所的汉语词法分析系统(institute of computing technology Chinese lexical analysis system,简称ICTCLAS)分词系统[8],并在此基础上进行二次开发,使分词结果达到预期效果。
2.5 知识抽取模块
知识抽取即使用实体识别工具对文档进行语义标注,然后对实体及实体间的关系进行抽取得到知识,并根据实例和属性构建RDF三元组知识形式,返回给相应的用户。
3 基于本体的Web知识抽取关键技术
3.1 本体构建
基于本体的Web知识抽取实质是以所构建的本体为核心的知识抽取,因此相关领域本体的建立是非常重要的工作。从本质上说,本体是一个客观事实的集合,而这些集合是实现语义信息检索的基础。本体的构建是一项复杂的系统工程,目前没有统一的本体构建方法和规则,Studer等提出本体构建的5个原则,即本体的定义具备清晰性、完整性、一致性、最大单向可扩展性和最小编码相关性[9]。对于领域本体的构建,还应遵循标准化建设原则、本体的复用原则、协作原则及评建结合原则。本研究借鉴相关本体的构建方法,依据农业领域知识的特点,确定农业领域本体的构建方法,其流程如图2所示。
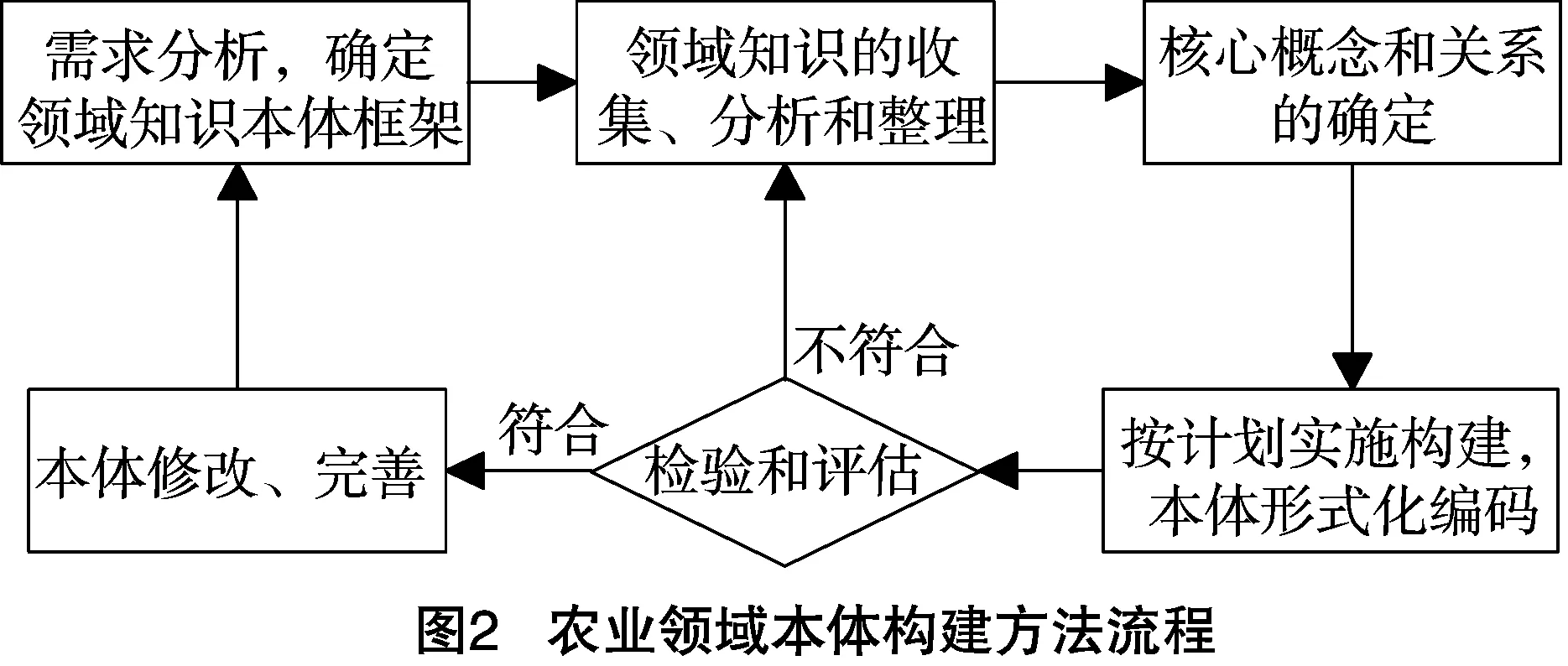
(1)在本体构建之前,进行需求分析,确定领域本体框架,明确领域本体的应用目标和范畴,对于限定本体范围,增强本体针对性,缩短本体构建的时间,降低构建本体的难度具有重要的意义。
(2)通过相关专业书籍、文献资料、权威网站信息等途径获取领域知识,结合农业领域的专家建议,对领域知识进行分析、整理和归纳,得到所需领域的概念和关系。
(3)在对领域知识充分了解的基础上,结合需求分析,将领域中的主要概念和关系列举出来,在农业领域专家的指导下,确定领域的核心概念和关系。
(4)基于(3)中划分的概念层次结构,使用本体构建工具对类、属性和实例等本体元素进行编码及形式化,实施本体构建。
(5)本体建立后,领域内术语的定义是否清晰,概念及关系是否完整,则须要运用推理工具自动判断和检验,并对有逻辑错误的地方进行修改,以满足用户的实际需求。
(6)本体构建是一个迭代的过程,须要在具体的应用中不断地修改、优化和完善,从而更好地适应实际使用情况。
根据上述的构建步骤,在学习了很多相关枸杞病虫害书籍和大量文献资料的基础上,结合枸杞病虫害领域的专家建议,以宁夏地区常见的枸杞蚜虫、枸杞红瘿蚊、枸杞瘿螨等51种枸杞害虫和根腐病、炭疽病、白粉病等15种枸杞病害为研究对象,以诊断和防治为研究目标,抽取领域中的重要概念、属性及实例,用Protégé工具构建一个内容丰富、层次清晰、体系完善的枸杞病虫害本体库。枸杞病虫害本体类结构如图3所示。其中Things是超类,其他的类都是Things的子类,共计37个本体类,图3是其中的25个基本类(含子类、副类),涵盖了实际生产中的主要枸杞病虫害种类。该本体中有7个数据属性和12个一级对象属性,用于描述枸杞病虫害的基本信息,还包括51个害虫实例,15个病害实例和其他本体类实例。

3.2 文档预处理
目前,大部分Web文档是基于HTML的。但HTML文档有局限:首先,HTML页面结构灵活,缺少语义,机器难以理解信息的结构和模式,因此获取隐藏在其中的知识非常困难;其次,HTML页面中可能存在标记格式不匹配甚至空标记的情况,对抽取工作影响很大;最后,直接对HTML页面内容进行抽取处理会占用大量的空间,处理时间比较长。预处理过程是知识抽取的前提,在知识抽取前,须要对源文档进行预处理。本研究参考现有的处理方法经验,使用页面清洗工具Tidy[10]纠正HTML文档中常见的错误标记,去掉空标记,并生成编码和格式统一的格式化文档。此外对页面中的一些明显噪声进行处理,为简化问题,笔者直接从Web页面过滤掉