使用超像素分割与图割的网状遮挡物检测算法
2018-03-20金伟正范赐恩
刘 宇,金伟正,范赐恩,邹 炼
(武汉大学 电子信息学院,武汉 430072)(*通信作者电子邮箱jwz@whu.edu.cn)
0 引言
摄影爱好者们通常遇到这样的问题:感兴趣的摄影对象被栅栏,铁丝网等物体所遮挡,无论如何挑选拍摄角度,都无法获得理想的画面。在拍摄笼子里的动物、安全护栏里的自然风景或建筑物时,或者拍摄篱笆对面的人像时,这些动辄横贯了整幅图像的遮挡物,常常喧宾夺主,将人们感兴趣的拍摄对象分割成支离破碎的小块,严重影响了画面的美观。对于图像浏览者来说,同样也不希望视野被这些恼人的障碍物所阻隔。于是,利用图像处理技术,将这些恼人的障碍物去除,还原出一个完整、干净的图像就成为了一个值得探讨的话题。
网状遮挡去除,是本文作者对英文单词“de-fencing”的意译,指的就是将上文所说的网状的遮挡物从图像或者视频中去除的过程。这个概念由Liu等[1]首次提出。他们将这个问题分解成了3个步骤:1)网状结构的感知;2)遮挡物的分割;3)去掉遮挡后图像的修复。其后的研究[2-9]也都是从这三个方面入手。
在图像中检测出网状的结构是一切的开始。网状结构的感知与分割实际上是一个前景背景的语义分割问题。不过不同于常见的前背景分割,在这个应用中,要保留的是背景,而作为前景的网状遮挡物,则是需要去除的物体。示例如图1所示。

图1 网状遮挡物去除示例
在一幅被安全护栏或者笼子遮挡的图像中,遮挡物占据的像素能够占到整幅图像的18%~53%[1],但由于其形状特点,这些像素分散分布在整幅图像中。常用的物体检测方法像行人检测[10]通常是利用一个矩形框在图像中滑动搜索,利用框内像素的颜色、纹理等特征给出预测的参考分数来实现对物体的检测,但类似这样的物体探测方法,对于这种网状中空的物体并不适用。网格状的遮挡物,在局部特征上呈现的是一种颜色较为均匀的细长形状,类似的特征在自然图像中极为常见,树木的枝干、道路边的电线杆及路灯、人衣服上的花纹以及一些动物身上的斑纹都有可能呈现出类似的特征。而假如只关注更大尺度的特征,搜索到的矩形框中不仅包括想移除的遮挡物,更多的像素属于需要保留的背景。因此,对于网状结构遮挡物的探测,本研究需要考虑其在较高尺度上的特征的同时,保留其在局部小尺度上的性质,从而实现前景与背景的正确分割。Liu等[1]和Park等[6]使用Park等[11]提出的半规则纹理探测算法来检测网状结构,该算法首先在图像中寻找可能的网格节点,再利用网格在空间上排列的规律性生长出其他网格节点,该算法在一些排列比较均匀规则的网状遮挡物的探测上准确性较高,但对于一些不那么规则或是异形的网格来说,该算法往往不能准确和完全地找到所有前景遮挡物。Farid等[3]认为遮挡物的颜色应当满足一定的概率分布,他们利用人工输入的遮挡物样本点作为颜色参考,从整幅图像中分割出前景遮挡,这种方法十分依赖人工输入的样本点的选取,并且对于前背景颜色差别不大的图像来说效果不佳。Khasare等[4]利用图割算法来分割遮挡物与被遮挡物,但需要人工对网状遮挡物和被遮挡物进行手动标记。Jonna等[5]提出了一种定位并移除颜色—深度(RGB-Depth, RGB-D)图像网状遮挡物的方法,利用深度摄像头如Microsoft Kinect获得的图像深度信息来定位并移除网状遮挡物。Zou等[8]的方法同样利用了RGB-D图像。Yamashita等[7]在同一个角度下对目标拍摄了不同焦距的图像,利用这些图像定位出网状遮挡物。Jonna、Zou、Yamashita提出的方法都需要额外的信息来实现对网状遮挡物的定位,无法实现对单张彩色图像的网状遮挡物的准确定位。为了解决这个问题,Jonna等[2]引入了卷积神经网络(Convolutional Neural Network, CNN)来实现对单张图像的网状遮挡物的精准定位,他们标注了4 000张网状遮挡物节点的正样本和8 000张负样本来训练CNN,之后利用该网络在待处理图片中寻找网状遮挡物的节点并最终获得网状遮挡物掩膜,该方法的难点在于训练样本的获取,并且该网络对于异形的网状遮挡物的探测效果存疑。
针对目前的去遮挡算法在对遮挡物的寻找上的准确性的问题,本文利用超像素分割技术,突破单个像素的特征限制,利用超像素块中多个像素的颜色及纹理的统计特征,对图像进行前背景分割。由于前景的网状遮挡物在不同的自然图像中可能会拥有不同的形状及颜色特征,因此利用图割算法将自然图像中的物体分割成几类,并将其中最接近于网状特征的一类作为该幅图像的先验知识,利用支持向量机(Support Vector Machine, SVM)分类器对图像中的超像素块进行分类,最终得到准确的遮挡物位置,最后使用文献[12]中提出的SAIST(Spatially Adaptive Iterative Singular-value Thresholding)算法恢复出原始的图像。整个算法流程如图2所示。
1 算法流程
1.1 超像素分割
为了突破单个像素的特征限制,同时保留图像的局部细节特征,本文算法使用简单线性迭代聚类(Simple Linear Iterative Clustering, SLIC)[13]算法对图像进行超像素分割预处理。SLIC算法将图像上的每个像素点n由一个五维特征向量[ln,an,bn,xn,yn]T表示,ln、an、bn是点n在CIELAB(CIEL*a*b* 1976 color space)色彩空间的L、a、b三个通道上的像素值,xn、yn为点n的坐标。图像中的每一个像素点通过K-means聚类的方法分配其最邻近的聚类中心的标号值,像素点n距离一个聚类中心Ci=[li,ai,bi,xi,yi]T的距离Ds表示为:
(1)
(2)
(3)
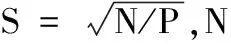
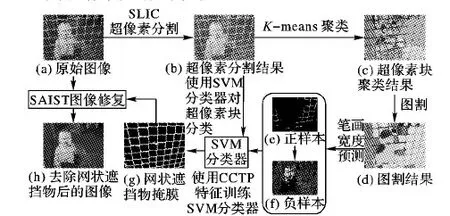
图2 算法流程
整个SLIC算法的流程如下:
1)在图像中以S为步长均匀地划分网格,以网格的中心作为初始化聚类中心点Ci=[li,ai,bi,xi,yi]T。
2)将聚类中心移至n*n邻域的最小梯度位置。
3)对于图像中的每个像素点,将其分配给2S*2S矩形范围内Ds最小的聚类中心。
4)计算新的聚类中心点。
5)计算残留率,如果残留率小于一定阈值或者像素点的标号不再改变,算法收敛。重复3)~5)直至收敛。
为了正确地分割出网状遮挡物,S就应该与网状遮挡物的宽度近似,本文取S=10。在S固定的情况下,紧凑因子m越大,Ds中空间距离所占的权重越高,颜色相似性所占的权重越小,这样生成的超像素块将会在空间上有更高的紧凑性,而对局部颜色的变化有更高的容忍度。如前文所述,网状遮挡物的颜色会受光照或者锈蚀、污点的影响,设置一个较大的m值,可在一定程度上克服这种局部的颜色变化;但m值也不可过大,过大的m值会使SLIC分割失去其边缘保持的特性,其块间的边界将不再与前景背景的边界重合,这不利于之后的超像素块特征提取和前景分割过程。令m=λ*S,相比其他超像素块算法应用,本文所需的超像素块空间大小很小(因为网状遮挡物往往很窄),所以要相应地提高空间距离dxy在Ds中的权重,应选择一个较大的λ值。经过实验,λ=100在大多数情况下能够较好地兼顾网状遮挡物的边界与局部颜色差异。图3展示了一张网状遮挡物图片通过SLIC超像素分割时不同迭代次数时的边界变化情况。在第一次聚类后,超像素块的边界未能贴合前背景的边界,经过多次迭代后,超像素块边界逐渐与网状遮挡物的边界相贴合。
通过SLIC超像素算法,本文算法将一幅由像素点构成的图像变成了由一个个超像素块拼成的图像,得益于SLIC算法优秀的边界保持性,接下来只要一一确定每个超像素块是否属于网状遮挡物,便能够实现前景与背景的分割。每一个超像素块都包括有100个左右的像素点,且同一个超像素块内的像素点大概率都属于同一个物体,所以,一个超像素块相比单个像素或单个像素及其邻域能够提供更多、更准确的颜色及纹理特征,因而获得更为准确的分类。
为了实现网状遮挡物的自动检测,本文算法需要能够自动分辨出超像素块的归属的方法。本文利用Graph Cuts图割算法[14]对超像素块进行分类,扩展网状遮挡物的颜色与纹理特征到大尺度下的总体形态特征。
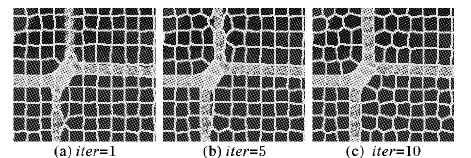
图3 SLIC聚类分割过程
1.2 使用图割算法的超像素块融合
从图2(c)中可以看到,经过超像素处理后,所有的网状遮挡物和背景都被超像素块的边界所分离开了,但新的问题是网状遮挡物自身也被分割成了小块。本文使用图割算法来解决这个问题,通过合理地构建能量函数,使网状遮挡物的小超像素块与背景的超像素块分别与其毗邻的相似超像素块进行融合,使局部的超像素块相互组合生成一个大的结构,如图2(d)所示。利用图割算法,本文算法可以在不知道网状遮挡物的颜色特征和结构特征的情况下,自动从彩色图像中提取出类似物体供后续算法进行筛选和分类。
将超像素块映射成一个带权图,为每个超像素块赋予不同的标号,构建一个能量函数来使用图割算法,能量函数的一般形式为:
E(f)=Edata(f)+γEsmooth(f)
(4)
其中:数据项Edata表示同一标号顶点的不相似性,光滑项Esmooth表示不同标号顶点的相似性,γ为平衡因子,f表示图中各顶点被赋予的标号。利用图割算法使两者之和E尽可能地小,就能够得到边界光滑分类准确的图像分割结果。在许多图割算法的应用中,都是将每个像素点作为带权图的顶点,用像素点的灰度值作为特征来计算相似性。这种做法直观且易于实现但由于其将每一个像素点都作为带权图的顶点,使得这个图的尺寸十分庞大,对其使用图割算法在时间复杂度和空间复杂度上都非常高,并且最后得到的分割结果也会由于过于追求边界的光滑性而抹去许多细节元素,不利于本文对细小的网状结构的检测需求。本文将图像超像素预处理后的超像素块作为带权图的顶点使用图割算法,解决了上述问题,并得到了令人满意的结果。
同SLIC算法一样,本文在CIELAB色彩空间中对超像素图像使用图割算法。对于每个超像素块,取其平均颜色来表示其颜色特征计算相似性。为了减弱环境光照对分割结果的影响,每个超像素块只取a、b两个颜色空间,计其平均像素值为Ia、Ib。初始标号通过K-means算法获得,将图像分为K类,每类中心点的a、b通道像素值计为Ica、Icb。令
(5)
其中:
Dp(fp)=(Ipa-Ica)2+(Ipb-Icb)2
(6)
对于光滑项Esmooth:
(7)
其中:

(8)
p,q表示不同的超像素块,fp,fq表示超像素块被分配的标号。能量函数构建完成后,利用文献[14]中提供的Graph Cuts算法,重新分配标号最小化能量函数(如图4)。在能量函数优化过程中,可能会有一些标号被完全合并,最终得到K′种标号,K′≤K。
图4 Graph Cuts分割优化过程中能量函数的数值变化
图割结果如图2(d)所示,图中将相同标号的超像素块用相同的纯色替换。仅通过聚类算法得到的超像素块分类分布十分零散,很难从中分类定位出不同的物体;经过图割算法处理后的新的超像素块分类勾勒出了图像中各个物体的轮廓,其中就包括本研究所需的网状遮挡物。
1.3 遮挡物样本超像素块的获得与CCTP特征提取
本文算法从上述处理中在自然图像中得到了K′类物体,接下来利用笔画宽度特征从K类物体中筛选出最可能的网状遮挡物。
利用Li等[15]用在字符检测中的笔画宽度检测算法,取出第k类物体中连通域面积最大的区域,求出其平均笔画宽度SWmean(k)与笔画宽度的方差SWvar(k)。通过对网状遮挡物的形状特征分析可知,其通常比较细小并且在图像中宽度变化不大,因此网状遮挡物的两种比划宽度特征应该都较小,因此对所有的k∈K,将SWmean(k)与SWvar(k)这两种特征进行升序排序,得到每类的两个排名Rm(k),Rv(k),那么最可能的网状遮挡物的标号fg就可依式(9)得到:
fg=arg min(Rm(k)+Rv(k))
(9)
上述算法筛选出来的网状遮挡物准确率较高,但召回率常常很低,这是由于为了尽可能地保存网状遮挡物和背景的边界,在使用聚类算法获得初始标号时本算法使用了一个较大的K值,而网状遮挡物可能因此被分成了多类,但式(9)只挑出了其中一类。因为其召回率太低,不能直接作为去遮挡的掩膜使用,但其准确率很高,可以将其作为分类器的正样本进行训练。同一幅图像中网状遮挡物的颜色可能会有变化,但总体而言变化不会很大。将所有属于标号fg的超像素块的像素取其R、G、B三个通道中的颜色平均值MCfg与标准差SCfg。例图2中,MCfg=[71.435 2,167.018 5,215.203 5],SCfg=[40.326 7,51.025 6,42.153 3]。
对于图像内所有的超像素块p,求出其颜色平均值MCp,根据式(10)对它们进行标记:
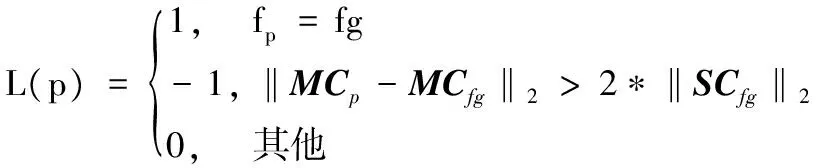
(10)
当超像素块的标号为fg时,它是已经确定的网状遮挡物对象,标记为1;当超像素块的平均颜色远离已知的网状遮挡物的颜色时,将其标记为-1。这样就将图像中的部分超像素块分为了两类:一类是网状遮挡物超像素块,如图2(e)所示;另一类是背景超像素块,如图2(f)所示。
还剩下一批标记为0的超像素块,其平均颜色与网状遮挡物接近,难以仅从颜色上进行区别。于是,本文提出了一种新的针对超像素块的特征,命名为颜色纹理联合特征(Combined Color Texture Pattern, CCTP)。由于一个超像素块内包含上百个像素,因此对一个超像素块仅用其平均颜色进行描述必然会丢失许多信息,而将每一个像素值都记录下来会使得特征过长,并且无法解决每个超像素块内像素不同的问题,因此本文算法用颜色直方图来描述超像素块内的像素颜色分布,将R、G、B三个通道的像素值分成12个区间,构成一个12×3维的向量,每个元素表示落入其中的像素个数,最后将所有元素除以该超像素块的像素个数,得到了颜色直方图ColorHist。同时引入结构特征,在三个颜色通道中计算每个像素的旋转不变局部二值模式(Local Binary Pattern, LBP)码[16-18],旋转不变LBP码的总个数是10个,记录每个超像素块中各类LBP码的总个数,最后除以超像素块的像素个数,就得到了结构直方图LBPHist。联合颜色与结构两个直方图向量,就得到了一个66维的CCTP特征向量。如图5所示,将一个超像素块内的所有像素点的颜色替换成该超像素块的平均颜色,圆圈内和方框内的两个超像素块平均颜色相近,但CCTP特征向量相差却有十分明显的区别。
1.4 SVM分类
求出所有超像素块的CCTP特征,将标记过的正负样本的CCTP特征构造一个训练样本集用于训练一个SVM二分类器。
T={(xi,yi)|yi{1,-1},i=1,2,…,n}
(11)
其中:xi是标记过的超像素块的66维CCTP特征,yi=1时表示该超像素块为已标记的网状遮挡物,yi=-1时表示该超像素块是已标记过的背景超像素块。
在线性可分的情况下,使训练样本分开的超平面描述为:
w·x+b=0
(12)
最优超平面就是能将训练样本集完全正确分开,同时满足距离超平面最近的两类点间隔最大。求解这样的超平面问题,可表示为下述的约束优化问题:
s.t.yi(w·xi+b)≥1,i=1,2,…,n
(13)

图5 CCTP特征向量示意
式(13)的拉格朗日目标函数为:
(14)
其中:αi≥0为各样本对应的拉格朗日系数。对w和b分别求其偏导函数,令其等于0,则该约束优化问题可转化为较简单的二次函数寻优问题:
(15)
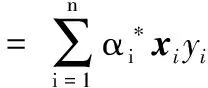
(16)
(17)
α*是式(15)求出的最优解,w*和b*为对应的最优平面参数。本文使用CCTP特征对目标超像素块进行分类的问题常常是线性不可分的,可利用核函数将该线性分类问题推广到非线性的情况,使用下述的高斯核函数:
(18)
则式(15)则可变换为求解:
(19)
则分类函数为:
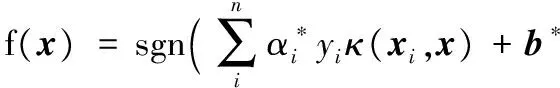
(20)
使用式(20)对所有标记为0的超像素块的CCTP特征进行分类,这样所有的超像素块就被分成了两类:网状遮挡物超像素块与背景超像素块。
最后,将所有属于网状遮挡物超像素块的像素赋值为255,剩下的赋值为0,就得到了一张标记出了网状遮挡物位置的掩膜。由于图像修补算法的基本原理就是在未被破坏的图像区域寻找与待修补区域相近的图像块来修补被破坏的位置,如果算法得到的掩膜将所有的网状遮挡物全部标记为待修补区域,那么图像修补算法将会利用背景的图像块修补原来为网状遮挡物的区域,最终得到没有网状遮挡物的图像,也就成功实现了网状遮挡物去除。
2 实验分析与对比
本文使用PSU-NRT(Pennsylvania State University Near-Regular Texture Database)数据集[19]和文献[3]项目主页中获取的图片,通过多种实验比较文献[1]和文献[3]中的算法以及本文算法对网状遮挡物的检测以及最终的去除效果进行峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)对比。实验中,超像素分割相关参数如前文所述,S=10,λ=100,m=λ*S=1 000,取聚类数量K=10,光滑项与数据项的平衡因子γ=0.35。本文实验平台为:64位Windows 10, Matlab R2016b。实验结果证明,网状遮挡物的去除的关键在于检测出准确的网状遮挡物的位置,本文在实验图片上获得了更为准确的掩膜图像。接下来,本文制作了实验图片来比较前面两种中网状遮挡物的修复效果,同时移植文献[12]中的SAIST图像修复算法用于网状遮挡物图像修复。实验结果显示,在获得准确的遮挡物掩膜的情况下,3种修复方式的修复效果区别不大,SAIST算法的效果稍好。最后,本文对比了本文算法结合SAIST图像恢复算法与当前两种算法的总体恢复效果;实验结果表明,新算法保留了更多的细节,检测出了更多的网状遮挡物结构,显著提升了恢复效果。
2.1 网状遮挡物检测结果对比
在图6中,从上至下每一行分别是测试图像Monkey、Boy、Orange rack。Farid等[3]算法中,利用人工输入参考点的方式求取图像中像素颜色值距离参考点的马氏距离来确定一个像素点是否是网状遮挡物,通过对上述过程结果提取最大连通域并进行膨胀的方法得到网状遮挡物的掩膜。该方法在精心挑选参考点且网状遮挡物在图像中一直连续的情况下能够得到较好的结果,如图6中的Monkey。当未找到好的参考点,如图6中的Boy,或是遮挡物不连续,如图6中Orange rack时,得到的网状遮挡物掩膜不甚理想,最后的恢复效果也不佳。本实验使用本文算法得到的掩膜,结合与Farid相同的恢复算法,恢复效果获得了明显的提升,并且本文算法无需人工输入参考点,显著提高了算法的可用性。
2.2 不同算法和特征的分类效果对比
对比图6(b)与图6(c)可以明显看出,本文算法得到的掩膜更为准确,保留的网状结构细节更多,这是源于超像素算法优秀的边界保持特性。同时,本文提出的CCTP特征对超像素块进行了较准确的描述。通常人们使用一个超像素块内像素的平均颜色和颜色方差来描述一个超像素块,如文献[20]和文献[21],但在本文应用中,超像素块的样本原本就是从平均颜色聚类而来,再用其训练得到的分类器必然不够准确。
分别使用超像素块的颜色均值和方差,颜色直方图和LBP直方图,使用图6的Boy图像中得到的正负样本来训练SVM分类器,最终得到的网状遮挡物掩膜如图7所示。正如本文之前所分析的那样,图7(a)中,绝大部分未被分类的超像素块被分类成了背景。而在使用颜色直方图进行分类时,效果有了明显的提升,但在画面下方一些亮度较暗的区域未能正确的分类。在使用纹理特征即LBP直方图训练的分类器时,较暗的部分被正确地分类,但画面上方亮度比较高的区域和小孩衣服上的条纹被错误的分类。融合颜色直方图和LBP直方图的CCTP结合了两者的优点,得到了令人满意的结果,证明了本文提出的CCTP的优越性。

图6 本文网状遮挡物检测算法替换Farid算法[3]中网状检测部分后的恢复效果比较

图7 使用不同的特征对超像素块进行分类的结果比较
2.3 不同算法对网状遮挡物的修复效果与质量评价参数对比
本文将经典图像处理测试图像Lena、Baboon、Sailboat人工加上网状遮挡物,来模拟网状遮挡物遮挡的人物、动物以及自然风景。使用不同的图像修补算法来进行恢复,来比较现有的图像修补算法对网状遮挡物的修补效果。本文比较了Criminisi等[22]于2004年提出的经典的图像修补算法;Farid等[23]在他的算法中使用了改进的Criminisi等算法;同时,本文还引入了文献[12]中提出的SAIST算法来进行比较。本文使用PSNR和SSIM(Structural SIMilarity)这两种最为普遍使用的有参考图像质量评价指标。PSNR的计算公式为:
PSNR=10*lg [(2n-1)2/MSE]
(21)
其中:n为处理图像的位宽,本文中为8;MSE是待评价图像与参考图像间的均方误差;PSNR值越大,待评价图像越接近于参考图像。
SSIM的计算公式为:
(22)
其中:imgx,imgy为输入的两幅图像,通常算法将图像分成小块后求出图像块的SSIM值,最终整幅图像的SSIM值由它们的均值表示;μx和μy是imgx,imgy的平均值,σx和σy是imgx、imgy的方差;σxy是imgx,imgy的协方差;c1=(k1L)2,c2=(k2L)2,L是图像像素值的动态范围,k1=0.01,k2=0.03。
从图8中可以看出,3种修复算法的修复效果从主观上讲差别并不大,表1中的图像质量评价参数证实了本文的看法。再对比图6的修复结果,可以看出,去除网状遮挡物的重点在于获得准确的网状遮挡物掩膜,这正是本文的算法所提供的。而一个合适的图像修复算法能够起到锦上添花的作用。从表1中易发现,Criminisi等[22]和Farid等[23]算法得分几乎一样,而SAIST算法得到了稍高的分数;因此,本文算法结合本文算法与SAIST修复算法,组合成完整的单幅彩色图像网状遮挡物去除算法。
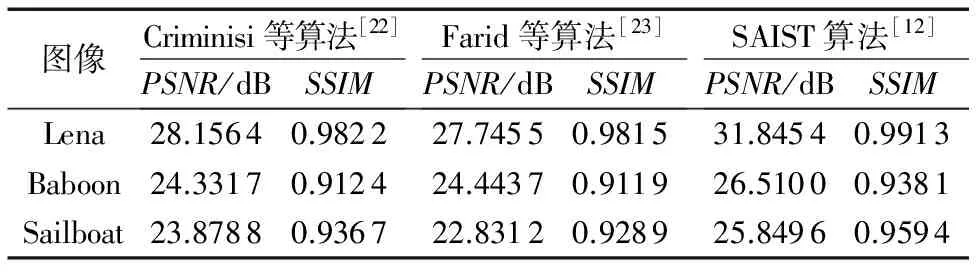
表1 3种修复算法的PSNR和SSIM得分对比
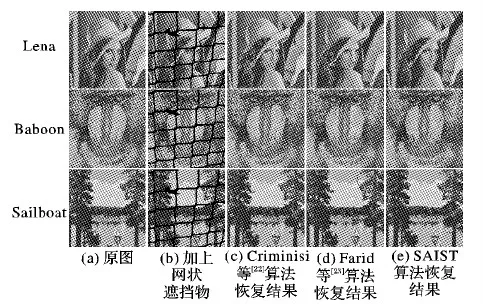
图8 3种修复算法得到的恢复结果比较
2.4 总体恢复效果对比
图9对比了本文算法与当前两种算法的去网状遮挡物的效果。本文算法明显优于其他两种算法。例如在Duck中,Liu等[1]算法完全破坏了图像,而Farid等[3]算法残留了许多遮挡物,本文算法则完全去除了图像中的网状遮挡物。Liu等[1]的算法未能在Monkey和Boy中找到网状遮挡物,所以也
无法得到恢复图像。Shadow不是传统意义上的所谓网状遮挡物,但画面中的房梁与阴影可以看作是网状遮挡物用于检测本文的算法鲁棒性。Liu等[1]的算法成功检测并去除了格子型的阴影,但在门上和地面上留下了残留的阴影,房梁也没能被识别为网状遮挡物;Farid等[3]算法检测出了所有的房梁和阴影,但恢复结果不佳。本文算法检测出了所有的阴影与部分房梁,得到了较完美的恢复效果。
3 结语
本文对于单幅彩色图像的网状遮挡物去除这一问题,提出了一种新的网状遮挡物检测方法:通过超像素分割和图割的方式在单张图像中自动寻找出网状遮挡物样本,新提出CCTP特征用于对超像素块进行分类,分割出网状遮挡物掩膜,最后结合SAIST图像修复算法,获得了比当前算法更佳的修复效果。实验结果证明,使用CCTP用于分类比使用平均颜色或者单独使用颜色直方图特征来分类能够得到更准确的分类结果,从而获得比当前算法更准确的网状遮挡物掩膜。目前,网状遮挡物的去除难点仍在于准确地分割出网状遮挡物掩膜,本文算法虽然相较其他算法检测结果更为准确,但在遮挡物与背景颜色过于相近或者网状遮挡物太细的时候,算法无法得到令人满意的结果。事实上,当前的算法都无法准确地分割所有类型的网状遮挡物图像,因此,对于该问题还有很大的改进空间。同时,对于自然图像中同网状遮挡物一样局部颜色较为均匀,形状比较统一的物体,例如字符、路牌、交通标线等可以使用本文算法类似框架进行检测;对于本文提出的描述超像素块的特征CCTP,其是否能够扩展至超像素分割的其他常用应用如图像分割、显著性检测等,都是下一步的研究目标。

图9 3种恢复算法结果对比
References)
[1] LIU Y Y, BELKINA T, HAYS J H, et al. Image de-fencing [C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2008: 1-8.
[2] JONNA S, NAKKA K K, SAHAY R R. My camera can see through fences: a deep learning approach for image de-fencing [C]// Proceedings of the 2015 3rd LAPR Asian Conference on Pattern Recognition. Piscataway, NJ: IEEE, 2015: 261-265.
[3] FARID M S, MAHMOOD A, GRANGETTO M. Image de-fencing framework with hybrid inpainting algorithm [J]. Signal, Image and Video Processing, 2016, 10(7): 1193-1201.
[4] KHASARE V S, SAHAY R R, KANKANHALLI M S. Seeing through the fence: image de-fencing using a video sequence [C]// Proceedings of the 2013 IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2013: 1351-1355.
[5] JONNA S, VOLETI V S, SAHAY R R, et al. A multimodal approach for image de-fencing and depth inpainting [C]// Proceedings of the Eighth International Conference on Advances in Pattern Recognition. Piscataway, NJ: IEEE, 2015: 1-6.
[6] PARK M, BROCKLEHURST K, COLLINS R T, et al. Image de-fencing revisited [C]// Proceedings of the 2010 Asian Conference on Computer Vision. New York: ACM, 2010: 422-434.
[7] YAMASHITA A, MATSUI A, KANEKO T. Fence removal from multi-focus images [C]// Proceedings of the 2010 20th International Conference on Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 4532-4535.
[8] ZOU Q, CAO Y, LI Q, et al. Automatic inpainting by removing fence-like structures in RGB-D images [J]. Machine Vision and Applications, 2014, 25(7): 1841-1858.
[9] XUE T, RUBINSTEIN M, LIU C, et al. A computational approach for obstruction-free photography [J]. ACM Transactions on Graphics, 2015, 34(4): 79.
[10] DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: an evaluation of the state of the art [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 743-761.
[11] PARK M, BROCKLEHURST K, COLLINS R T, et al. Deformed lattice detection in real-world images using mean-shift belief propagation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(10): 1804-1816.
[12] DONG W, SHI G, LI X. Nonlocal image restoration with bilateral variance estimation: a low-rank approach [J]. IEEE Transactions on Image Processing, 2013, 22(2): 700-711.
[13] ACHANTA R, SHAJI A, SMITH K, et al. SLIC superpixels compared to state-of-the-art superpixel methods [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11): 2274-2282.
[14] BOYKOV Y, VEKSLER O, ZABIH R. Fast approximate energy minimization via graph cuts [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(11): 1222-1239.
[15] LI Y, JIA W, SHEN C, et al. Characterness: an indicator of text in the wild [J]. IEEE Transactions on Image Processing, 2014, 23(4): 1666-1677.
[16] OJALA T, PIETIK INEN M, HARWOOD D. A comparative study of texture measures with classification based on featured distributions [J]. Pattern Recognition, 1996, 29(1): 51-59.
[17] OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987.
[18] PIETIK INEN M, OJALA T, XU Z. Rotation-invariant texture classification using feature distributions [J]. Pattern Recognition, 2000, 33(1): 43-52.
[19] PSU near-regular texture database [EB/OL]. [2017- 02- 18]. http://vivid.cse.psu.edu/index.php?/category/23.
[20] 张微,汪西莉.基于超像素的条件随机场图像分类[J].计算机应用,2012,32(5):1272-1275.(ZHANG W, WANG X L. Superpixel-based conditional random field for image classification [J]. Journal of Computer Applications, 2012, 32(5): 1272-1275.)
[21] 张矿,朱远平.基于超像素融合的文本分割[J].计算机应用,2016,36(12):3418-3422.(ZHANG K, ZHU Y P. Text segmentation based on superpixel fusion [J]. Journal of Computer Applications, 2016, 36(12): 3418-3422.)
[22] CRIMINISI A, P REZ P, TOYAMA K. Region filling and object removal by exemplar-based image inpainting [J]. IEEE Transactions on Image Processing, 2004, 13(9): 1200-1212.
[23] FARID M S, KHAN H, MAHMOOD A. Image inpainting based on pyramids [C]// Proceedings of the 2010 IEEE 10th International Conference on Signal Processing. Piscataway, NJ: IEEE, 2010: 711-715.
This work is partially supported by the National Natural Science Foundation of China (61072135).
LIUYu, born in 1991, M. S. candidate. His research interests include image restoration.
JINWeizheng, born in 1966, M. S., associate professor. His research interests include image processing.
FANCi’en, born in 1975, Ph. D., associate professor. Her research interests include image processing, computer vision.
ZOULian, born in 1975, Ph. D., research fellow. His research interests include image analysis and understanding.
