基于Mask R-CNN的回环检测算法
2021-06-16林钊浩徐颖
林钊浩 徐颖
(深圳大学机电与控制工程学院 广东省深圳市 518061)
1 引言
近年来,随着家用机器人、自动驾驶、无人机、AR/VR 等产业的发展。SLAM(Simultaneous Localization and Mapping,同步定位与建图)技术也呈现出了一个快速发展的态势。SLAM 技术为可移动设备提供了实时可靠的定位功能。其中,使用摄像头作为传感器的视觉SLAM,凭借其远低于激光雷达的成本,获得了市场和研究人员的青睐,得到了快速的发展。
回环检测是视觉SLAM 中的一个重要组成部分,其目的是消除移动机器人在长时间的工作下产生的位姿估计的累计误差。它通过计算图像之间的相似度检测回环。在得到了回环信息之后,SLAM 后端优化算法便可以根据回环约束对位姿进行优化,得到更加精确的定位。
目前,在回环检测问题中已经比较成熟且广泛应用的算法是基于BOW(BagofWords,词袋模型),并使用无监督学习算法K-means 和TF-IDF 加 权 方 式(Term Frequency-Inverse Document Frequency)[1]的算法[2]。但是,BOW 存在一些缺点。它需要计算SIFT,SURF,ORB 等人工设计的图像特征,这通常比较消耗计算资源且效率低下。而且,这些人工设计的特征对于光线强度的变化都比较敏感[3]。
近年来,随着深度学习技术的发展,CNN(Convolutional Neural Network,卷积神经网络)在图像处理上的应用也越来越广泛,并且取得了超过传统算法的效果。而回环检测问题,本质上就是一个图像间的特征匹配问题,属于图像处理的范畴,所以,可以借用CNN 的技术对回环检测算法进行提高。

图2:City Centre 数据集0326.jpg

图3:City Centre 数据集0508.jpg
2 算法结构
本文提出的算法称为LOM(ListofMasks,掩膜列表),通过Mask R-CNN[4]得到图像中可识别物体的掩膜,利用掩膜表示图像特征。它通过计算两张图像所有掩膜之间的相似程度来判断两张图像是否构成回环。为了提高该算法的通用性,本文还将该算法与经典的词袋模型进行融合。
2.1 LOM
2.1.1 特征表示
LOM 使用Mask R-CNN 提取的掩膜来表示图像特征。一幅图像可以表示为若干个物体掩膜的列表:

其中,Mi表示第i 张图像,miu表示Mi的第u 个掩膜,其表现形式是和图像同等大小的矩阵,若图像中某一个像素属于miu,则miu的矩阵中该位置的值为1,否则为0。|Mi|是图像Mi中检测得到的物体掩膜的个数。
2.1.2 相似度计算
本文通过计算两张图像的同类别的物体掩膜之间的交并比IOU(Intersection over Union,交并比)来衡量两张图像的相似度。

表1:子数据集信息标表

表2:实验结果
但是,由于一张图像中存在的1 个类别的掩膜可能不止1 个,所以,需要确定Mi中的每一个掩膜是匹配Mj中的哪一个掩膜。匹配的原则是要尽量保证Mi与Mj对应的掩膜来自于物理世界中的同一个物体。
如果Mi和Mj存在回环,那么Mi和Mj匹配的每两个掩膜之间应该存在比较大的IOU,因为此时两张图像是极为相似的。而且,掩膜之间应该一一匹配,不能出现1 个掩膜匹配2 个掩膜的情况。那么,掩膜匹配问题就可以抽象成一个指派问题,即如何找到一个最优的匹配关系,使得使用该匹配关系计算得到的IOU 的和最大,且每一个Mi掩膜只能与一个Mj掩膜匹配。解决指派问题的经典算法之一就是匈牙利算法[5]。匈牙利算法应用在掩膜匹配问题中的算法流程图如图1 所示。
其中,第2 步要交换Mi,Mj是为了保证|Mi|≥|Mj|,这样便于编程实现。
第4 步要使用1 减去矩阵T 的每一个元素是因为匈牙利算法的最优值是代价的最小值,而掩膜匹配问题的最优值是IOU 的最大值,所以使用1 减去矩阵T 的每一个元素,再利用匈牙利算法进行求解,才可以得到掩膜匹配问题的最优解,求解得到的结果是一个形如P的由二元组组成的集合。

其中,一个匹配对是一个二元组,第一个元素表示Mi中的掩膜序号,第二个元素表示与之匹配的M_j 中的掩膜序号,0 表示“未找到匹配”,因为|Mi|≥|Mj|,所以只有二元组的第二个元素可能为0。
得到匹配关系之后就可以计算两张图像之间的总IOU 作为LOM 的相似度:
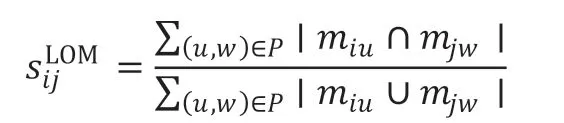
其中,|miu∩mjw|表示miu和mjw的交集的像素个数。|miu∪mjw|表示miu和mjw的并集的像素个数。假如w 为0,即miu没有匹配的Mi掩膜,则|miu∩mjw|=0,|miu∪mjw|=|miu|
得到相似度之后,通过设置阈值就可以判断两张图片是否存在回环。

2.2 算法融合
LOM 依赖于Mask R-CNN 检测到的物体掩膜,只能识别场景中的部分物体。当场景中可识别的物体比较少时,LOM 的性能就会下降。所以,为了提高LOM 的通用性,本文将其与BOW 进行融合,并提出了两种算法融合的方式,分别是线性组合和使用双阈值。
2.2.1 线性组合
本文首先考虑的是使用线性组合。由于LOM 在物体较多的时候更为可靠,所以,利用图像中的物体个数对LOM 分配权重。物体数量多时给予LOM 更大的权重,反之给予BOW 更大的权重。公式如下。

其中,max|M|表示整个数据集中在一张图像中能检测出来的最大物体掩膜个数。λ 是LOM 的权重。表示使用线性组合融合LOM 和BOW 的相似度。表示判断结果。
2.2.2 设置双阈值
另外一种融合LOM 和BOW 的方式是使用两个阈值。分别利用BOW 和LOM 对Mi和Mj是否存在回环进行判断,只有当两个算法同时判定Mi和Mj存在回环,才判断Mi和Mj存在回环。公式如下:

3 实验
3.1 数据集
实验使用两个开放的数据集New College 和City Centre。以图像中的最少物体数为筛选条件,本文筛选出6 个子数据集,全部子数据集的信息如表1 所示,其中,nc0 和cc0 等价于原数据集。nc2由于图像张数过少,所以不使用它进行实验。
3.2 模型训练
本文使用谷歌发布的预训练网络。该网络基于InceptionV2 并在MSCOCO 数据集上完成训练。BOW 的实现使用DBoW3 库 。在New College 和City Centre 数据集上使用的词袋模型字典分别是使用New College 和City Centre 数据集进行训练的。
3.3 实验结果
本文使用100%精确度下的最高召回率作为系统性能的指标。实验结果如表2 所示,fusion 表示使用线性组合融合的算法,fusion2 表示使用双阈值融合的算法。在计算精确度和召回率的过程中,所有的阈值都是从0 以最大值的1/500 增加到最大值。加粗字体是在同一个子数据集下得到的最好性能。
表2 中LOM 没有数据是因为无论取任何一个阈值,LOM 都无法达到100%精确度,所以不存在100%精确度下的最高召回率。LOM 之所以性能这么差,是因为它只考虑了图像的高层特征,而不考虑图像的低层特征。如图2 和图3,高层特征,也就是图像中可识别物体的类别和占据的像素位置,都很相似,但是低层特征,如颜色,纹理等,很不相似。
表2 中,从横向来看,无论是在哪一个数据集上,使用双阈值融合LOM 和BOW 的性能在各个数据集上都是最好的。这得益于该融合方式存在2 个阈值,将BOW 相似度和LOM 相似度分开计算和判断,同时考虑了图像的高层特征和低层特征,只有在高层特征和低层特征都相似的时候,才会判定为存在回环。从纵向来看,不论是New College 还是City Centre,随着图像中的可识别物体数越来越多时,2 种融合算法相对于BOW 的提升越来越大。
4 结论
本文使用Mask R-CNN 提取图像中的物体掩膜,并利用物体掩膜表示图像特征,定义了一种基于物体掩膜计算图像相似度的方法。本文还提出了两种融合LOM 和BOW 的方法。通过实验,可以看到融合算法在New College 和City Centre 数据集上的表现优于BOW,而且随着图像中物体掩膜个数的增加,与BOW 的性能差距也逐渐增大。
