邻域决策错误率的局部约简方法研究
2018-03-19王长宝杨习贝窦慧莉陈向坚王平心
王长宝,杨习贝,2,窦慧莉,陈向坚,王平心
1.江苏科技大学计算机科学与工程学院,江苏镇江212003
2.南京理工大学经济管理学院,南京210094
3.江苏科技大学数理学院,江苏镇江212003
邻域决策错误率的局部约简方法研究
王长宝1,杨习贝1,2,窦慧莉1,陈向坚1,王平心3
1.江苏科技大学计算机科学与工程学院,江苏镇江212003
2.南京理工大学经济管理学院,南京210094
3.江苏科技大学数理学院,江苏镇江212003
CNKI网络出版:2017-02-28,http://kns.cnki.net/kcms/detail/11.2127.TP.20170228.1820.002.html
1 引言
众所周知,粗糙集[1-2]从数据自身出发,不依赖于其他先验知识,利用下、上近似集之差所刻画的边界区域来描述不确定性。经典粗糙集是建立在等价关系基础上的,可被用于处理符号型数据。但现实世界中广泛存在着类型复杂、结构迥异的数据[3-6],鉴于此,为了将粗糙集推向实用,已有很多学者提出了诸如模糊粗糙集[7]、邻域粗糙集[8]、决策粗糙集[9]、多粒度粗糙集[10]等扩展模型。
在众多的扩展粗糙集模型中,关于邻域粗糙集理论与方法的研究近年来得到了众多学者的广泛关注[6,8,11-15]。邻域粗糙集借助距离的概念构建邻域信息粒,其主要特点表现在:(1)因为使用了距离技术,所以邻域粗糙集既可以用来分析连续型数据,也可以用于处理连续和符号型并存的混合数据;(2)利用半径来控制邻域信息粒的大小,随着半径的变化,邻域信息粒的大小亦随之变化,因而势必引起诸如近似集、不确定性度量等相关变化,从而自然地形成了一个多粒度[12,16]动态变化趋势。
无论研究何种粗糙集方法,属性约简都是一个核心内容,各类研究的区别在于不同的粗糙集可能会产生不同的度量标准,因而可以给出不同的属性约简定义。在邻域粗糙集的理论研究中,除了可以探讨关于近似质量、条件熵、近似分布等经典粗糙集下的约简形式,亦可从分类学习的视角研究属性约简:例如Hu等人[4]将邻域分类器与近邻分类器的性能进行了对比分析,验证了邻域分类相比于近邻分类的优势,并在此基础上,给出了基于邻域决策错误率的约简定义[6];朱鹏飞等人[17]依据集成学习理论,通过随机化邻域约简,产生一簇分类学习规则,并且验证了该方法具有较强的鲁棒性。
经过梳理与分析,不难发现以往关于邻域粗糙集约简的研究大多是从全局的角度来考虑问题的,如基于邻域决策错误率所设计的约简,其目的就是为了提升邻域分类模型的总体分类精度。但值得注意的是,这一理念往往会带来局部信息的丢失,如造成单个类别的分类精度提升程度不足,甚至是分类精度有所降低。为解决这一问题,笔者在文献[18-19]所示工作的基础上,从单个类别标记[20]的视角,定义了局部邻域决策错误率及相应的属性约简概念,并给出了求解局部邻域决策错误率约简的算法。
2 邻域粗糙集
类似于经典粗糙集方法,邻域粗糙集的处理对象依然可以表示为信息系统。不失一般性,一个决策信息系统可以记为一个二元组DS=<U,AT⋃{}d>,其中U是论域,表示一个非空有限的对象集合;AT描述了所有条件属性集合,而d是决策属性且满足AT⋂{}d=∅。
在决策信息DS中,Δ:U×U→R为一距离度量函数,∀x,y∈U,Δ(x,y)表示对象x与y之间的距离。若假定邻域半径为σ,则可以定义如下所示的0-1函数:
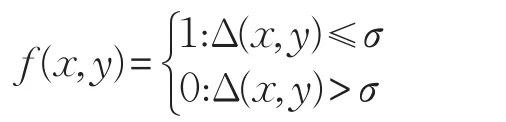
函数f(x,y)用以判断x与y之间的距离是否大于给定半径σ,据此,对于决策信息系统中的任意对象x,不难得到的邻域邻域系统是决策信息系统中所有对象的邻域所构成的集合。记录了所有与x之间的距离小于给定半径σ的对象,可以认为是所有与x在半径σ下相似的对象集合,以粒计算的视角来看,是一种信息粒的表现形式,因而也可称为邻域信息粒。显然,若则有成立,也就是说半径越大,邻域中所包含的对象也越多。利用邻域信息粒,可构建如下所示的近似集。
定义1[4]令DS=<U,AT⋃{}d>为一决策信息系统,∀A⊆AT,根据属性集合A可得到距离度量ΔA,∀X⊆U,X的邻域下近似集与上近似集分别定义如下:

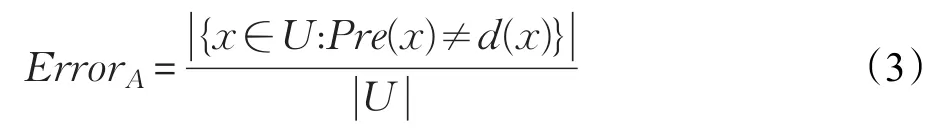
3 属性约简
3.1 全局和局部约简
属性约简是粗糙集理论的核心研究内容。因为在分类学习研究中,往往期望通过删除冗余的属性或特征以得到较高的分类精度,所以文献[6]在邻域决策错误率的基础上,提出了用以降低邻域决策错误率的属性约简定义。
定义2[6]令DS=<U,AT⋃{}d>为一决策信息系统,,A被称为一个邻域错误分类率约简当且仅当:

由定义2可以看出,基于邻域决策错误率的约简实际上是使得决策信息系统中邻域决策错误率能够被降低的最小属性子集。值得注意的是,定义2所示约简考虑的是U中所有对象被错误分类的程度,从而忽视了数据中各个类别的分类情况。如果仅仅追求式(3)所示的邻域决策错误率降低,那么有可能造成某些类中对象被错分的可能性增加。所以一种合理的考虑应该是将每一类别的决策错误率单独分析,由此可以定义如下所示公式:

公式(4)描述的是在决策信息系统中,第i类对象的邻域决策错误率,即第i类对象中被错分的百分比,这是一种基于类别标记的局部错误率。借助公式(4),可以定义如下所示的局部约简。
定义3令DS=<U,AT⋃{}d>为一决策信息系统,∀A⊆AT,针对第i个类别标记,A被称为一个局部邻域决策错误率约简当且仅当:

定义3所示约简,其目的不是为了降低由全体对象所得到的邻域决策错误率,而是为了降低具有第i类标记的对象的邻域决策错误率,这是一种局部约简的定义形式,与此对应的,定义2所示的约简可称为全局约简。
3.2 启发式算法
示将属性a加入到条件属性集A中后邻域决策错误率的变化情况,即:
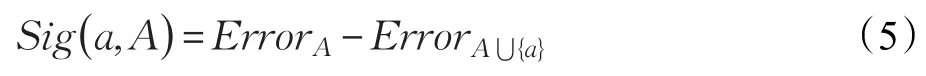
式(5)所示的属性重要度是针对由全体对象所得到的邻域决策错误率而设计的,是一种全局重要度,类似地,针对第i个类别标记,可以给出如下所示的局部属性重要度Sig()a,A,i:

根据上述属性重要度的定义,不难给出如下所示的两个启发式算法,分别用于求解定义2和定义3所示的约简。
算法1启发式算法求解全局约简
输入:决策信息系统DS。
输出:一个全局约简red。
步骤1利用交叉验证计算ErrorAT;
步骤2令
步骤3若Errorred≤ErrorAT,则转步骤4,否则执行以下循环;
(1)∀a∈AT-red,计算属性a的重要度Sig()a,red;
(3)利用交叉验证计算Errorred;
步骤4输出red。
算法2启发式算法求解局部约简
输入:决策信息系统DS,类别标记i。
输出:一个针对第i类标记的局部约简red。
步骤1利用交叉验证计算
步骤2令
步骤3若则转步骤4,否则执行以下循环;
(1)∀a∈AT-red,计算属性a的重要度Sig()a,red,i;
步骤4输出red。
4 实验分析
为了对比全局约简及局部约简对于分类性能所产生的影响以及验证笔者所提出局部约简的有效性,选取了8组UCI数据集进行实验分析,数据信息的基本描述如表1所列。实验环境为PC机,双核2.60 GHz CPU,16 GB内存,Windows10操作系统,MATLAB R2010a实验平台。
在算法1和算法2中计算邻域所采用的距离度量为欧式距离,计算邻域决策错误率时均采用了十倍交叉验证。表2列出了邻域分类器在各个类别标记上所求得的分类精度,这些分类精度分别是在原始数据、根据算法1所求得的全局约简和根据算法2所求得局部约简的基础上,利用十倍交叉验证方式求得。受篇幅所限,邻域的大小σ选取了3个不同的参数,分别是0.1、0.2和0.3。
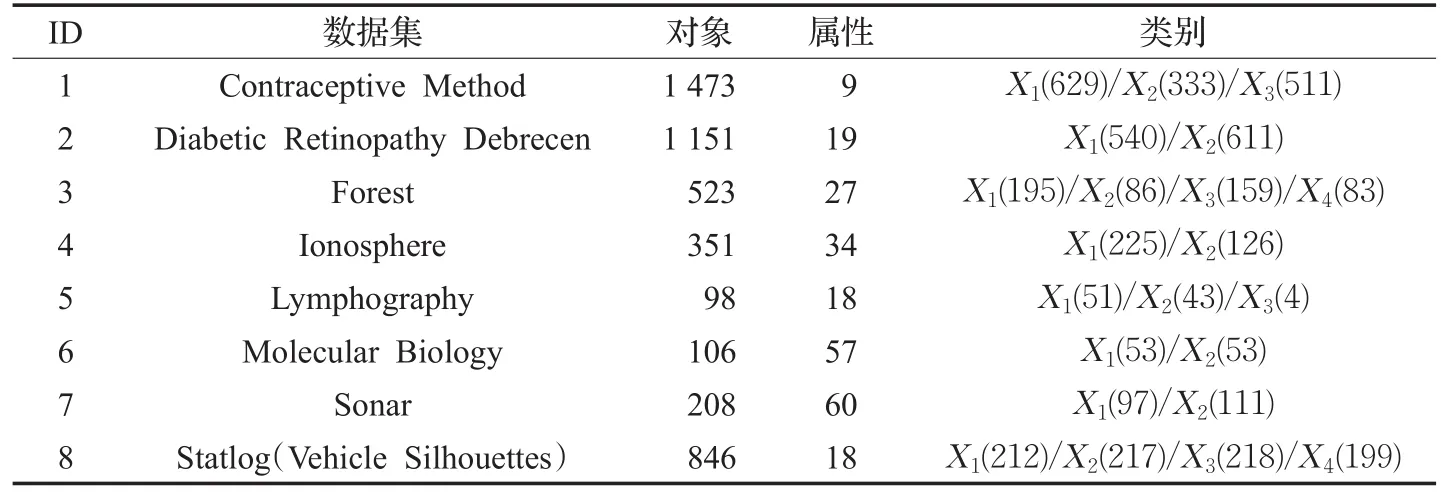
表1 数据集描述
观察表2可以发现,在绝大多数的类别标记上,相较于原始数据和全局约简来说,利用局部约简所求得的属性子集可以获得较高的分类精度。除此以外,局部约简还能够在一定程度上缓解由全局约简引起的某一类别精度下降问题。例如,考虑Forest数据集的类别X1,当σ=0.1时,原始数据下该类别的分类精度为0.936 8,而根据全局约简,该类别的分类精度仅为0.883 0,明显低于原始精度,利用局部约简,分类精度可以提升至0.995 7。每一个数据集都有至少一个类别标记出现了类似的情形,这反映了全局约简对于单个类别上的分类性能提升存在不尽人意之处;而相较于全局约简来说,局部约简所追求的目标是使得单个类别的分类精度尽可能地有所提高,故具有良好的表现力。
进一步的,图1展示了不同σ参数下根据全局约简得到的总体分类精度、各类别分类精度的平均值以及根据局部约简得到的各类别分类精度平均值。
通过观察图1,不难得出如下结论。
(1)在各个邻域半径σ下,相较于原始数据,根据全局约简所得到的总体分类精度能够有所提升,这符合定义2中全局约简的追求目标。
(2)根据全局约简所得到各类别分类精度均值的提升效果不够明显,有时甚至低于原始数据下各类别分类精度的均值,如Contraceptive Method数据中当σ=0.1至σ=0.5都出现了这一情形,这说明全局约简在针对单独某一类别时性能有所欠缺。
(3)根据局部约简所得到的各类别分类精度均值要高于由原始数据和全局约简所得到的各类别分类精度的均值,这一结果说明了在提升局部分类效果时,局部约简相比于全局约简来说,具有更为明显的优势。

图1 邻域分类器的类别精度和总体精度
5 结束语
针对基于邻域决策错误率的属性约简仅考虑提升数据的总体分类精度而忽视了对具体类别分类精度的考虑这一不足之处,引入了基于局部邻域决策错误率的属性约简,并利用启发式算法求解这种局部约简。与传统全局约简的侧重点不同,局部约简更加关注如何对某一具体类别的分类效果进行提升,从而有助于解决由全局约简所引起的局部精度提升不足甚至下降的问题。
本文仅仅考虑了如何利用约简提升局部邻域粗糙分类器的分类精度,而没有对约简本身的性能进行分析,笔者下一步将就局部约简的鲁棒性问题进行进一步的探讨,以期能够进一步完善局部属性约简理论与方法。
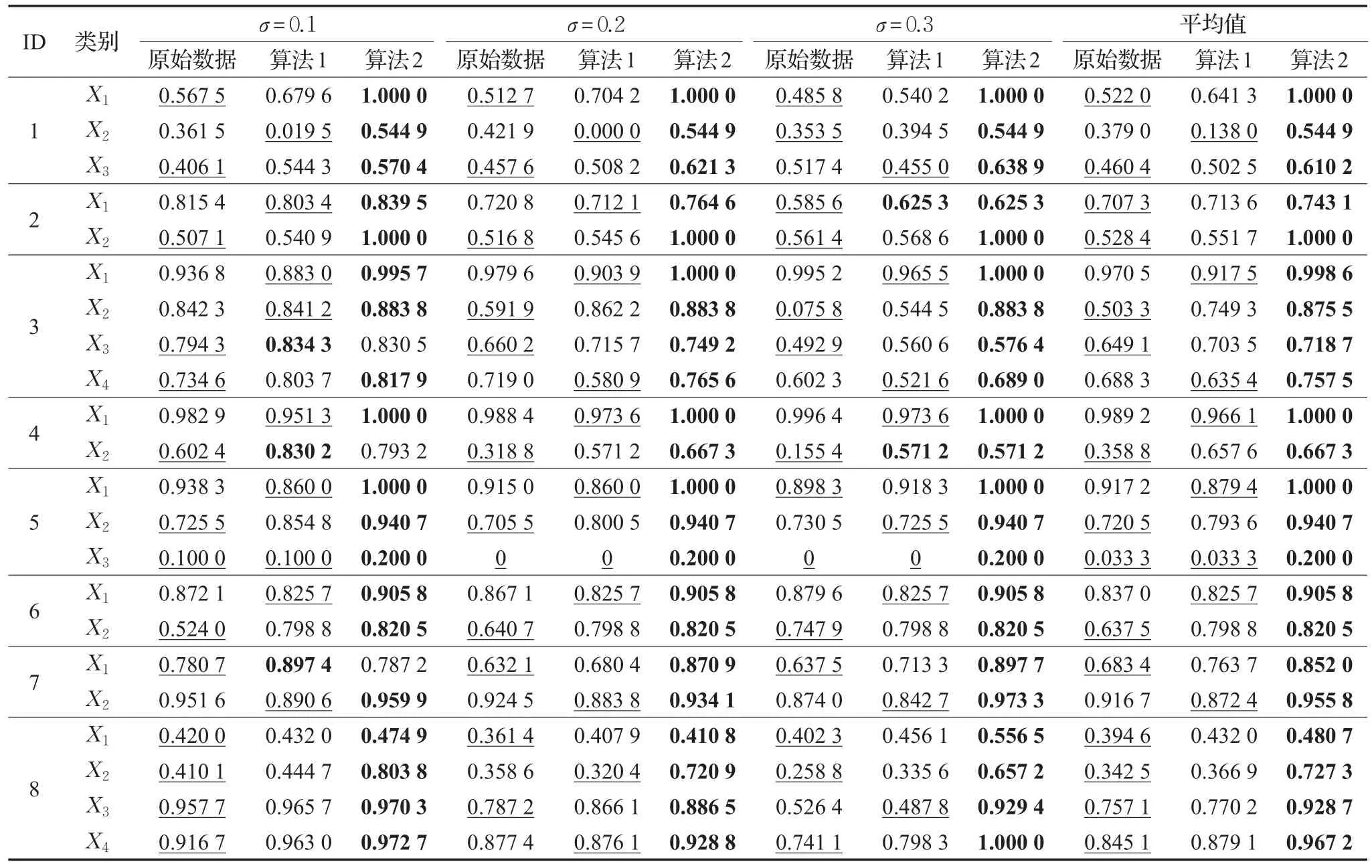
表2 邻域分类器分类精度对比
[1] Pawlak Z.Rough sets-theoretical aspects of reasoning about data[M].Dordrecht,Boston,London:Kluwer Academic Publishers,1991.
[2] Pawlak Z.Rough sets[J].International Journal of Computer&Information Sciences,1982,11(5):341-356.
[3] Zhang X,Mei C L,Chen D G,et al.Feature selection in mixed data:A method using a novel fuzzy rough setbased information entropy[J].Pattern Recognition,2016,56:1-15.
[4] Hu Q H,Zhang L,Zhang D,et al.Measuring relevance between discrete and continuous features based on neighborhood mutual information[J].Expert System with Applications,2011,38:10737-10750.
[5] Wang X,Tsang E C C,Zhao S,et al.Learning fuzzy rules from fuzzy samples based on rough set technique[J].Information Sciences,2007,177(20):4493-4514.
[6] Hu Q H,Pedrycz W,Yu D R,et al.Selecting discrete and continuous features based on neighborhood decisionerrorminimization[J].IEEETransactionsonSystems,Man,and Cybernetics,Part B,2010,40:137-150.
[7] Dubois D,Prade H.Rough fuzzy sets and fuzzy rough sets[J].International Journal of General Systems,1990,17:191-209.
[8] 胡清华,于达仁.应用粗糙计算[M].北京:科学出版社,2012.
[9] Yao Y Y.Three-wang decisions and cognitive computing[J].Cognitive Computing,2016,8:543-554.
[10] Liang J Y,Wang F,Dang C Y,et al.An efficient rough feature selection algorithm with a multi-granulation view[J].InternationalJournalof ApproximateReasoning,2012,53:912-926.
[11] Lin Y J,Hu Q H,Liu J H,et al.Multi-label feature selection based on neighborhood mutual information[J].Applied Soft Computing,2016,38:244-256.
[12] Zhu P F,Hu Q H,Zuo W M,et al.Multi-granularity distance metric learning via neighborhood granule margin maximization[J].Information Sciences,2014,282:321-331.
[13] Yang X B,Chen Z H,Dou H L,et al.Neighborhood system based rough set:Models and attribute reductions[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2012,20(3):399-419.
[14] 段洁,胡清华,张灵均,等.基于邻域粗糙集的多标记分类特征选择算法[J].计算机研究与发展,2015,52:56-65.
[15] 张维,苗夺谦,高灿,等.邻域粗糙协同分类模型[J].计算机研究与发展,2014,51:1811-1820.
[16] Yang X B,Qian Y H,Yang J Y.Hierarchical structures on multigranulation spaces[J].Journal of Computer Science and Technology,2012,27:1169-1183.
[17] 朱鹏飞,胡清华,于达仁.基于随机化属性选择和邻域覆盖约简的集成学习[J].电子学报,2012,40:273-279.
[18] Chen D G,Zhao S Y.Local reduction of decision system with fuzzy rough sets[J].Fuzzy Sets and Systems,2010,161:1871-1883.
[19] 王宇,杨志荣,杨习贝.决策粗糙集属性约简:一种局部视角方法[J].南京理工大学学报:自然科学版,2016,40:444-449.
[20] 杨习贝,徐苏平,戚湧,等.基于多特征空间的粗糙数据分析方法[J].江苏科技大学学报:自然科学版,2016,30:370-373.
[21] Wu X D,Kumar V,Quinlan J R,et al.Top 10 algorithmsindatamining[J].KnowledgeandInformation Systems,2008,14(1):1-37.
WANG Changbao,YANG Xibei,DOU Huili,et al.Research on local attribute reduction approach via neighborhood decision error rate.Computer Engineering and Applications,2018,54(6):95-99.
WANG Changbao1,YANG Xibei1,2,DOU Huili1,CHEN Xiangjian1,WANG Pingxin3
1.School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang,Jiangsu 212003,China
2.School of Economics&Management,Nanjing University of Science and Technology,Nanjing 210094,China
3.School of Mathematics and Physics,Jiangsu University of Science and Technology,Zhenjiang,Jiangsu 212003,China
Traditional criteria of attribute reduction for neighborhood decision error rate is designed for improving overall classification accuracy,it does not take the variation of accuracy of each class into consideration when reduction finding is executed.From this point of view,the concepts of local neighborhood decision error rate and local attribute reduction are introduced for improving the classification accuracy of single class.Furthermore,a heuristic algorithm to compute local neighborhood decision error rate based reduction is presented.The experimental results on 8 UCI data sets show that the local reduction can not only improve the classification accuracy of single class,but also overcome the limitation of accuracy’s decreasing for single class,which may be caused by global reduction.
attribute reduction;global reduction;heuristic algorithm;local reduction;neighborhood rough set
传统基于邻域决策错误率的属性约简准则是针对总体分类精度的提升而设计的,未能展现因约简而引起的各类别精度变化情况。针对这一问题,引入局部邻域决策错误率以及局部属性约简的概念,其目的是提升单个类别的分类精度。在此基础上,进一步给出了求解局部邻域决策错误率约简的启发式算法。在8个UCI数据集上的实验结果表明,局部约简不仅是提高各个类别精度的有效技术手段,而且也解决了因全局约简所引起的局部分类精度下降问题。
属性约简;全局约简;启发式算法;局部约简;邻域粗糙集
2016-10-11
2016-12-01
1002-8331(2018)06-0095-05
A
TP18
10.3778/j.issn.1002-8331.1610-0109
国家自然科学基金(No.61572242,No.6150316,No.62502211);江苏省高校哲学社会科学基金(No.2015SJD769);中国博士后科学基金(No.2014M550293);江苏省青蓝工程人才项目。
王长宝(1963—),男,实验师,主要研究方向为智能信息处理;杨习贝(1980—),通讯作者,男,博士(后),副教授,主要研究方向为粗糙集理论、粒计算、机器学习,E-mail:zhenjiangyangxibei@163.com。
