基于关键区域的二值化场景特征快速提取方法
2018-03-19姚萌贾克斌萧允治
姚萌,贾克斌,萧允治
1.北京工业大学信息学部,北京100124
2.香港理工大学电子资讯工程学系,香港999077
3.先进信息网络北京实验室,北京100124
4.未来网络科技高精尖创新中心,北京100124
基于关键区域的二值化场景特征快速提取方法
姚萌1,2,贾克斌1,3,4,萧允治2
1.北京工业大学信息学部,北京100124
2.香港理工大学电子资讯工程学系,香港999077
3.先进信息网络北京实验室,北京100124
4.未来网络科技高精尖创新中心,北京100124
1 引言
近年来,高级驾驶辅助系统(Advanced Driver Assistance Systems,ADAS)被广泛应用于车辆控制系统,以提高车辆行驶的安全性。其中,定位模块作为ADAS的重要组成部分,是其他高级功能的基础。城市轻轨列车运行环境包含隧道、楼宇之间甚至建筑物内部,基于全球定位系统(Global Positioning System,GPS)的ADAS系统因信号不稳定造成的位置误差将对列车行驶和调度造成巨大安全隐患。因此,基于视觉信息的定位技术成为研究的热门领域[1-2]。

图1 轻轨定位系统拓扑地图
基于视觉信息的定位系统在车辆行驶过程中不间断地采集视觉信息并转化成拓扑地图(Topological map)[3]存储在数据库中,拓扑地图由节点和边构成,其中,节点包含定义的历史场景,边反映了场景之间的位置关系。当车辆再次驶入相同的场景,定位系统根据摄像机拍摄的当前视频帧,使用场景匹配在拓扑地图中找到最相似的节点,从而定位当前位置。在轻轨定位系统中,拓扑地图可简化为单向一维场景链,如图1所示,并使用基于路径的场景跟踪算法获取位置信息[4]。
在基于视频信息的定位系统中,场景匹配易受运动物体遮挡、光照变化以及场景内容变化等噪声干扰,如图2所示。针对光照变化问题,由激光雷达获取的场景三维信息[5]、红外传感器获得的长波热成像[6]以及双目摄像机获得的深度信息[7]具有较强的光照鲁棒性,被广泛用于车辆定位系统。然而这些方法都依赖特殊的传感器,不利于算法向手机等移动平台移植。因此基于单目摄像机的视觉定位系统仍然是目前研究的热门领域[8-16]。

图2 场景匹配中的噪声干扰
通过机器学习的方式可以获取稳定的视觉特征描述符[17-19],例如旋转与尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[20]和加速稳健特征(Speeded-Up Robust Feature,SURF)[21],或移除阴影等场景中对光线敏感的成分以获得稳定的场景特征[8-11]。近年来,随着深度学习方法的兴起,卷积神经网络(Convolutional Neural Networks,CNNs)[22]被应用到了视觉定位系统中以获取稳定的场景信息[12-13]。场景变换学习[14-16,19]可以预测场景变化以实现不同条件下的场景匹配。然而这些基于机器学习的方法往往需要采集大量视频序列并进行人工标定生成训练数据。因此基于单参考序列的定位系统仍然面临着诸多挑战[7]。
基于视频信息的定位精度由参考视频序列帧率决定,高帧率参考序列记录了更多的地理位置信息,因此通过逐帧匹配可获得精确度较高的位置信息。然而高帧率铁路视频序列(如25帧/s)中的场景相似度高,如图1所示,因而在时域上被降采样至1帧/s[4,13],在提高了场景匹配成功率的同时降低了定位精度。因此,如何利用高帧率参考序列获取高精度定位信息成为研究的难点。
为解决定位系统训练数据大、定位精度低以及计算复杂度高等问题,本文基于单目视频序列,提出了一种面向高精度场景匹配的关键区域检测及二值化特征提取方法。与其他方法相比,该方法创新点在于:(1)仅使用一个高帧率单目视频序列作为参考序列与训练数据,针对该序列提出一种关键区域提取方法,以提高系统对连续高相似度视频帧(如图1所示)的区分能力;(2)提出一种基于关键区域的二值化特征,利用该二值化特征可实现场景特征快速提取与匹配,满足了场景跟踪系统对实时性的需求。
2 关键区域提取
关键区域包含了高相似度视频帧之间的差异信息。为减少分析计算量并提高算法稳定性,首先在视频帧中建立感兴趣区域,进而在感兴趣区域中进一步检测关键区域。
2.1 感兴趣区域设置
对于基于视频信息的定位系统而言,轻轨视频中的感兴趣区域(Region Of Interest,ROI)不包含三类无用区域,如图3所示。被移除的区域包括:容易产生临时遮挡的矩形区域(图3(a))、长时间无明显变化的铁轨区域(图3(b))以及边缘模糊区域(图3(c))。最终的感兴趣区域如图3(d)所示。
2.2 显著性分数与关键区域提取
视频帧中的关键区域由显著性较高的像素组成,显著性分数被用来衡量像素的显著程度。像素的显著性分数反映了该像素与其他帧相同位置像素之间的差别。标记某时刻的视频帧ft中位于(x,y)位置的像素为p(x,y,ft),其邻近视频帧组成的集合为Fk(t)。p(x,y,ft)的视觉信息由周围区域内的梯度方向直方图(Histogram of Oriented Gradients,HOG)[23]特征Dpt(x,y,ft)表示。则像素的显著性分数Sp(p(x,y,ft))可由公式(1)计算获得:
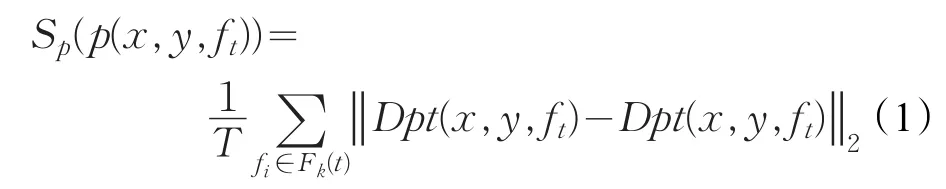
其中,T为Fk(t)集合中邻近帧的数量,Fk(t)由公式(2)定义:
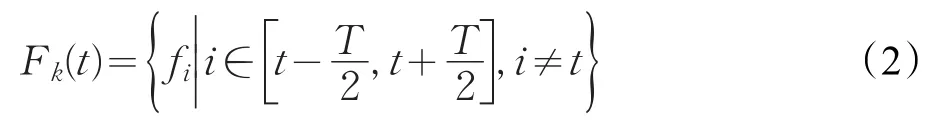
计算得到感兴趣区域内所有像素的显著性分数后,通过设定显著性分数阈值Tk得到ft中显著性较高的关键区域。图4展示了某帧ROI内像素的显著性分数以及该帧提取的关键区域。图4(a)中红色区域代表显著性较高的区域,反之由蓝色表示。图4(b)包含2个关键区域,阈值Tk为ROI内显著性分数平均值的1.05倍,外接矩形小于40×40像素的单连通区域容易受到噪声干扰,不作为关键区域。

图3 感兴趣区域提取

图4 关键性区域提取
3 关键区域的二值化特征描述符
与传统特征描述方法相比,以BRIEF[24]与ORB[25]等为代表的二值化特征的提取及匹配计算复杂度较低,被广泛应用到实时系统中。然而传统的二值化特征描述符用于较小的规则区域,不适用于面积较大且形状不规则区域。本文为每一个参考帧的关键区域生成二值化特征提取模式,用于场景匹配时计算参考帧与当前帧的二值化特征。
二值化特征向量由级联的比特位构成,其每一个比特位反映了特征描述区域内某一对像素之间的亮度关系,如公式(3)所示:
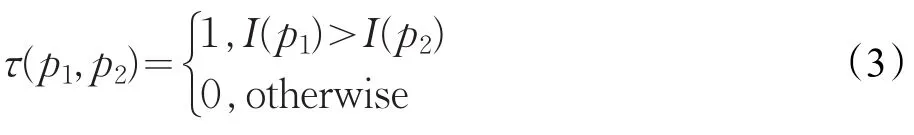
其中I(⋅)为像素亮度值,τ(⋅)为二值化函数。
针对视频帧ft,建立其关键区域的像素集合Pk,该集合包含了关键区域内的所有像素。在Pk中反复随机抽取N个像素对P(pm,pn)建立ft的二值化提取模式H(ft),级联H(ft)在ft中提取二值化结果,得到ft的二值化特征描述符B(ft),如公式(4)所示:

其中,(pm,pn)∈H(ft)。
从Pk中提取的像素对可分为两种类型,分别为区域内像素对和区域间像素对,如图5所示,图中每条直线代表一个像素对,像素由直线的端点表示。蓝色直线为区域内像素对的示意图,其两个端点位于同一个关键区域,这种类型的像素对记录了某个关键区域的局部纹理信息。绿色的直线为区域间像素对的示意图,其端点位于两个不同的关键区域,因此该种像素对记录了关键区域之间的位置信息。
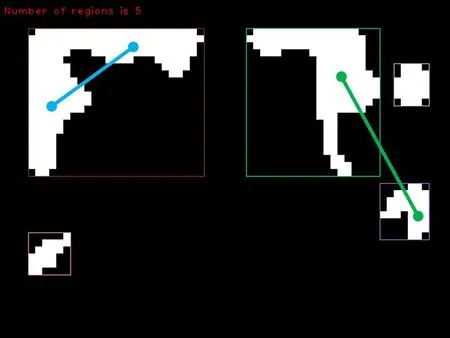
图5 区域内像素对和区域间像素对
4 实验结果与分析
为评价本文提出的关键区域以及二值化特征提取方法的有效性,本章使用自行录制的香港轻轨数据集和公开的Nordland数据集进行实验,并统计分析了实验结果。
4.1 数据库
香港轻轨数据集中的两段视频序列采集自安装在轻轨车辆中的单目摄像机,视频分辨率为640×480,采集帧率为每秒25帧。由于采集时间不同,本文使用的5 731帧中相同位置的光照、路况与车速等皆不相同。两段视频中的所有帧被人工标定了对应关系。Nordland数据库包含四段视频,分别采集自春夏秋冬四个季节,视频分辨率为1 920×1 080,采集帧率为每秒25帧。本文使用夏季与秋季视频中的6 000帧作为训练与测试数据,为保持与香港数据集的一致性,视频分辨率被降采样为640×480,两段视频中列车保持相同速度运行,因此相同序号的视频帧采集自同一位置。
4.2 基于关键区域的单场景匹配评价
为验证本文提出的关键区域的有效性,本文基于HOG特征,测试了4种不同区域生成的场景特征在单场景匹配中的准确率。(1)全局HOG特征,使用一个HOG特征描述整个视频场景;(2)局部HOG特征,将视频帧分割成40×40宏块,分别计算每个宏块内的HOG特征向量;(3)基于感兴趣区域的HOG特征,该方法只计算位于感兴趣区域内宏块的HOG特征向量;(4)基于关键区域的HOG特征,在本文提出的关键区域内计算HOG特征向量。
匹配参考序列中的单帧场景与当前序列中具有高相似度的连续的场景,将匹配结果与人工标定结果之间的差作为匹配偏差。4种方法的平均计算时间与偏差如表1所示。
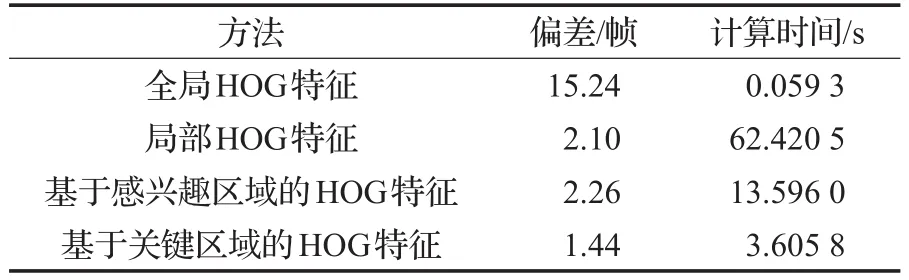
表1 场景匹配计算时间与错误率
基于全局HOG特征的场景匹配计算速度最快,但同时其匹配精度最差,平均匹配偏差为15.24帧。虽然基于局部HOG特征的场景匹配错误偏差下降至2.10帧,但是其过长的计算时间无法在实际系统中应用。同时,基于感兴趣区域的场景匹配计算时间下降了78.22%,匹配偏差比基于局部HOG特征的方法上升了0.16帧。基于本文提出的关键区域的场景匹配方法将匹配偏差降低至1.44帧,相对于局部HOG特征方法,匹配偏差下降了31.43%,并节约了94.22%的匹配时间。
实验结果表明,基于全局的HOG特征只提取视频帧整体的HOG特征,虽然其时间复杂度较低,但是因为缺乏场景细节信息,从而导致匹配偏移过大。基于局部HOG特征的方法能够记录场景细节与整体信息,然而大量的HOG特征计算以及特征匹配使得该方法无法用于实际系统中。基于感兴趣区域的方法减少了计算HOG特征的宏块数量,因而大幅降低了场景匹配的时间复杂度。基于关键区域的方法使得场景匹配模块只计算场景内最具有显著信息的区域,一方面降低了场景特征计算与场景匹配的计算复杂度,同时减少了非关键区域给场景匹配带来的噪声干扰。
4.3 基于二值化特征的场景跟踪评价
实验使用场景跟踪测试所提出的二值化特征的匹配性能。参考序列为Nordland数据集中的秋季序列,夏季序列作为当前序列。作为一种较为新颖的场景序列匹配算法,SeqSLAM[4]被广泛应用于基于路径的场景跟踪算法中[26-27]。本实验对于每个当前帧,首先使用SeqSLAM在所有参考帧中筛选出候选帧,利用二值化特征在候选帧中选出与当前帧最匹配的参考帧。本文比较了SeqSLAM以及本文方法的场景跟踪精确率。场景匹配得到的实际结果与理想结果(Ground truth)之间的差别小于3帧则被认为是正确匹配,反之则为错误匹配。在统计了所有的正确匹配数量和错误匹配数量后,匹配精确率可使用公式(5)计算获得。实际结果与理想结果之间的偏差平均值被统计为匹配偏移。

表2展示了SeqSLAM以及本文算法的匹配精确率与运行时间。与SeqSLAM相比,在不显著增加时间代价的前提下,本文方法的场景跟踪精确率提高了9.84%,匹配偏移下降了39.79%。
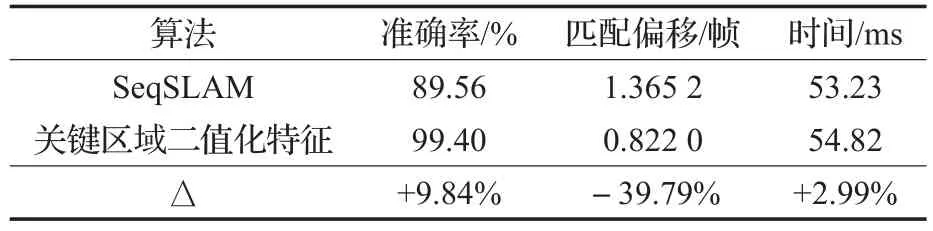
表2 场景跟踪精确率与运行时间
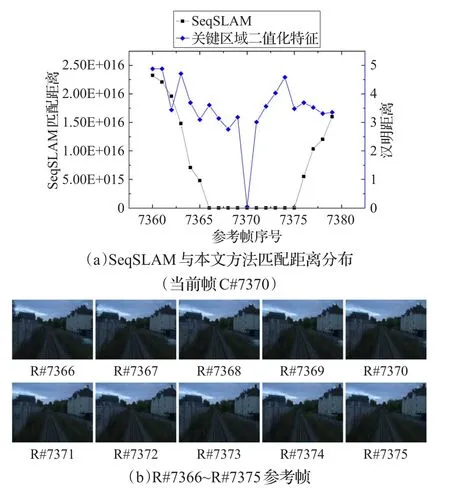
图6 C#7370当前帧与参考帧及其匹配距离
图6(a)展示了当前帧C#7370在理想匹配结果(R#7370参考帧)领域内的匹配距离分布。图中横轴为参考帧序号,左侧纵轴为SeqSLAM方法的匹配距离,右侧纵轴为基于本文的关键区域二值化特征匹配的汉明距离。在SeqSLAM匹配结果中,包括R#7366与R#7375的10个参考帧与当前帧C#7370匹配距离为0,如图6(a)中黑线所示。与此相对,基于本文提出的二值化特征在理想匹配结果处(横轴7370处)达到匹配距离极小值,如图6(a)中蓝线所示。
图6(b)为SeqSLAM中10个匹配距离为0的参考帧,这10个参考帧包含高度相似的场景。这表明SeqSLAM所使用的全局特征仅仅保留场景整体大致信息,无法区分这些高度相似的场景。本文方法中的二值化特征在关键区域中生成,而关键区域包含该帧相对邻近帧最突出的视觉信息,实验结果表明本文提出的二值化特征保留了这些突出特征,对高度相似的连续场景有较强的区分力。
5 结束语
本文提出了一种面向高精度实时场景匹配的关键区域与二值化特征提取方法。针对高帧率下连续场景相似度高的问题,该方法逐帧分析并提取了包含场景显著性信息的关键区域。同时,为满足实时系统对匹配速度的需求,针对不规则关键区域提取了二值化特征。在香港轻轨数据集以及Nordland数据集中的实验结果表明,所提出的关键区域及二值化特征在保证场景跟踪系统运行效率的同时,有助于提高场景识别的精确率。
[1] Lowry S,Sünderhauf N,Newman P,et al.Visual place recognition:A survey[J].IEEE Transactions on Robotics,2016,32(1):1-19.
[2] Dornaika F,Assoum A,Moujahid A.Place recognition using image retrieval with covariance descriptors[C]//ISAT International Symposium on Electronic Imaging,2016:1-6.
[3] Shatkay H,Kaelbling L P.Learning geometrically-constrained hiddenmarkovmodelsforrobotnavigation:Bridging the topological-geometrical gap[J].Journal of Artificial Intelligence Research,2002,16(1):167-207.
[4] Milford M J,Wyeth G F.SeqSLAM:Visual route-based navigation for sunny summer days and stormy winter nights[C]//2012 IEEE International Conference on Robotics and Automation(ICRA).Saint Paul,MN,USA:IEEE,2012.
[5] Mcmanus C,Furgale P,Barfoot T D.Towards lightinginvariant visual navigation:An appearance-based approach using scanning laser-rangefinders[J].Robotics and Autonomous Systems,2013,61(8):836-852.
[6] Maddern W,Vidas S.Towards robust night and day place recognition using visible and thermal imaging[C]//RSS 2012:Beyond Laser and Vision:Alternative Sensing Techniques for Robotic Perception,2012.
[7] Linegar C,Churchill W,Newman P.Made to measure:Bespoke landmarks for 24-hour,all-weather localisation with a camera[C]//International Conference on Robotics and Automation(ICRA).Stockholm,Sweden:IEEE,2016.
[8] Ross P,English A,Ball D,et al.A novel method for analysing lighting variance[C]//Australian Conference on Robotics and Automation,Sydney,NSW,2013.
[9] Ross P,English A,Ball D,et al.A method to quantify a descriptor’s illumination variance[C]//Australian Conference on Robotics and Automation,Melbourne,VIC,2014.
[10] Corke P,Paul R,Churchill W,et al.Dealing with shadows:Capturing intrinsic scene appearance for imagebased outdoor localisation[C]//2013 IEEE/RSJ International Conference on Intelligent Robots and Systems.Tokyo,Japan:IEEE,2013.
[11] Mcmanus C,Churchill W,Maddern W,et al.Shady dealings:Robust,long-term visual localisation using illuminationinvariance[C]//2014IEEEInternationalConference on Robotics and Automation(ICRA).Hong Kong,China:IEEE,2014.
[12] Chen Z,Lam O,Jacobson A,et al.Convolutional neural network-based place recognition[C]//2014 Australasian Conference on Robotics and Automation,2014.
[13] Sünderhauf N,Shirazi S,Dayoub F,et al.On the performance of convnet features for place recognition[C]//2015 IEEE/RSJ International Conference on Intelligent Robots and Systems(IROS).Hamburg,Germany:IEEE,2015.
[14] Achanta R,Shaji A,Smith K,et al.SLIC superpixels compared to state-of-the-art superpixel methods[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(11):2274-2282.
[15] Lowry S M,Milford M J,Wyeth G F.Transforming morning to afternoon using linear regression techniques[C]//2014 IEEE International Conference on Robotics and Automation(ICRA).Hong Kong,China:IEEE,2014.
[16] Lowry S,Wyeth G,Milford M.Unsupervised online learning of condition-invariant images for place recognition[C]//AustralasianConferenceonRoboticsand Automation,Melbourne,Australia,2014.
[17] Neubert P,Sünderhauf N,Protzel P.Superpixel-based appearance change prediction for long-term navigation across seasons[J].Robotics and Autonomous Systems,2015,69:15-27.
[18] Milford M,Vig E,Scheirer W,et al.Vision based simultaneous localization and mapping in changing outdoor environments[J].Journal of Field Robotics,2014,31(5):780-802.
[19] Lowry S,Milford M J.Supervised and unsupervised linear learning techniques for visual place recognition in changing environments[J].IEEE Transactions on Robotics,2016,32(3):600-613.
[20] Lowe D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[21] Bay H,Ess A,Tuytelaars T,et al.Speeded-up robust features(SURF)[J].Computer Vision and Image Understanding,2008,110(3):346-359.
[22] Krizhevsky A,Sutskever I,Hinton G E.Imagenet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems 25(NIPS 2012),Curran Associates Inc,2012.
[23] Dalal N,Triggs B.Histograms of oriented gradients for human detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Diego,CA,USA:IEEE,2005.
[24] Calonder M,Lepetit V,Strecha C,et al.Brief:Binary robust independent elementary features[C]//Proceedings of the 11th European Conference on Computer Vision,2010:778-792.
[25] Rublee E,Rabaud V,Konolige K,et al.ORB:An efficient alternative to SIFT or SURF[C]//2011 IEEE International Conference on Computer Vision(ICCV).Barcelona,Spain:IEEE,2011.
[26] Bresson G,Alsayed Z,Yu L,et al.Simultaneous Localization and Mapping:A survey of current trends in autonomous driving[J].IEEE Transactions on Intelligent Vehicles,2017,2(3):194-220.
[27] Kim P,Coltin B,Alexandrov O,et al.Robust visual localization in changing lighting conditions[C]//IEEE International Conference on Robotics and Automation.Singapore:IEEE,2017.
YAO Meng,JIA Kebin,SIU Wanchi.Key region identification with binary feature extraction for high accurate scene matching.Computer Engineering andApplications,2018,54(6):14-18.
YAO Meng1,2,JIAKebin1,3,4,SIU Wanchi2
1.Faculty of Information Technology,Beijing University of Technology,Beijing 100124,China
2.Department of Electronic and Information Engineering,Hong Kong Polytechnic University,Hong Kong 999077,China
3.Beijing Laboratory ofAdvanced Information Networks,Beijing 100124,China
4.Advanced Innovation Center for Future Internet Technology,Beijing 100124,China
As one of the most important component in advanced driver assistance systems,the visual-based localization techniques have been widely studied in recent years.Dealing with the problems of high accurate scene matching caused by the extremely similar scene appearances in the high frame rate reference sequence,a new and powerful method of key region and binary feature extraction is proposed in this paper.The key regions with discriminative information are extracted from the similar reference frames.The binary patterns of these key regions are generated to reduce the computational complexity of online scene matching procedure.The proposed method is evaluated on the Hong Kong light railway dataset and Nordland dataset.With the proposed key regions,the error and the computation time of scene matching are reduced by 31.43%and 94.22%.The precision rate of scene tracking with proposed method is 9.84%higher than that of SeqSLAM.The experimental results show that the proposed method has high performance.
fast scene matching;key region extraction;binary feature extraction
近年来,驾驶辅助系统中基于视频信息的车辆定位技术受到广泛关注。针对轻轨系统高精度场景匹配中场景相似度过高导致定位困难的问题,提出了一种关键区域及二值化特征提取方法。该方法以离线处理的方式在高相似度的参考序列帧内提取具有显著性信息的关键区域,并在这些区域中生成二值化特征描述符以提高实时场景匹配的速度与准确率。在香港轻轨数据集以及公开的Nordland数据集中,相对于局部场景特征,基于提出的关键区域特征的场景匹配方法错误偏差下降31.43%,同时节约了94.22%的匹配时间;与SeqSLAM场景跟踪算法相比,在不显著增加运行时间的前提下,基于关键区域二值化场景特征的场景跟踪正确率提高了9.84%。实验结果表明,提出的关键区域以及二值化特征提取方法在降低了场景匹配计算时间的同时,提高了匹配精确度。
快速场景匹配;关键区域提取;二值化特征提取
2017-12-18
2018-02-08
1002-8331(2018)06-0014-05
A
TP391.4
10.3778/j.issn.1002-8331.1712-0243
国家自然科学基金面上项目(No.61672064);北京市自然科学基金重点项目(No.KZ201610005007)。
姚萌(1988—),男,博士研究生,研究领域为图像处理、基于视觉信息定位技术;贾克斌(1962—),通讯作者,男,博士,教授,研究领域为图像/视频信号与信息处理技术、生物信息处理与计算技术、基于Internet网的多媒体系统等,E-mail:kebinj@bjut.edu.cn;萧允治(1950—),男,博士,教授,研究领域为图像处理、小波变换、模式识别等。
